 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-to-Image MLP-mixer for Image Reconstruction
Feb 04, 2022
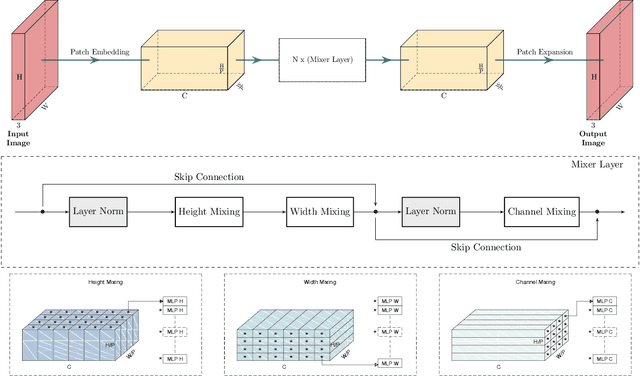
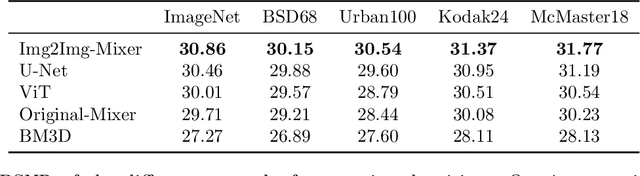
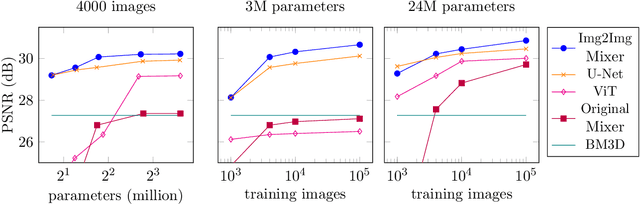

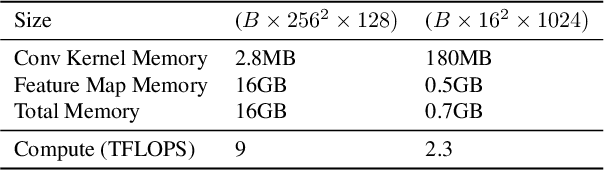
Neural networks are highly effective tools for image reconstruction problems such as denoising and compressive sensing. To date, neural networks for image reconstruction are almost exclusively convolutional. The most popular architecture is the U-Net, a convolutional network with a multi-resolution architecture. In this work, we show that a simple network based on the multi-layer perceptron (MLP)-mixer enables state-of-the art image reconstruction performance without convolutions and without a multi-resolution architecture, provided that the training set and the size of the network are moderately large. Similar to the original MLP-mixer, the image-to-image MLP-mixer is based exclusively on MLPs operating on linearly-transformed image patches. Contrary to the original MLP-mixer, we incorporate structure by retaining the relative positions of the image patches. This imposes an inductive bias towards natural images which enables the image-to-image MLP-mixer to learn to denoise images based on fewer examples than the original MLP-mixer. Moreover, the image-to-image MLP-mixer requires fewer parameters to achieve the same denoising performance than the U-Net and its parameters scale linearly in the image resolution instead of quadratically as for the original MLP-mixer. If trained on a moderate amount of examples for denoising, the image-to-image MLP-mixer outperforms the U-Net by a slight margin. It also outperforms the vision transformer tailored for image reconstruction and classical un-trained methods such as BM3D, making it a very effective tool for image reconstruction problems.
simple diffusion: End-to-end diffusion for high resolution images
Jan 26, 2023

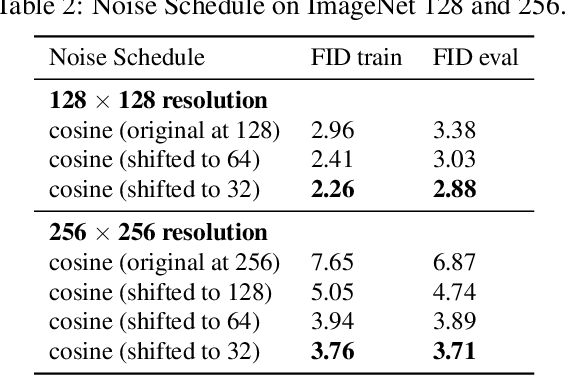
Currently, applying diffusion models in pixel space of high resolution images is difficult. Instead, existing approaches focus on diffusion in lower dimensional spaces (latent diffusion), or have multiple super-resolution levels of generation referred to as cascades. The downside is that these approaches add additional complexity to the diffusion framework. This paper aims to improve denoising diffusion for high resolution images while keeping the model as simple as possible. The paper is centered around the research question: How can one train a standard denoising diffusion models on high resolution images, and still obtain performance comparable to these alternate approaches? The four main findings are: 1) the noise schedule should be adjusted for high resolution images, 2) It is sufficient to scale only a particular part of the architecture, 3) dropout should be added at specific locations in the architecture, and 4) downsampling is an effective strategy to avoid high resolution feature maps. Combining these simple yet effective techniques, we achieve state-of-the-art on image generation among diffusion models without sampling modifiers on ImageNet.
CorrI2P: Deep Image-to-Point Cloud Registration via Dense Correspondence
Jul 12, 2022
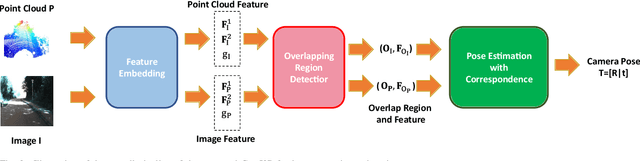
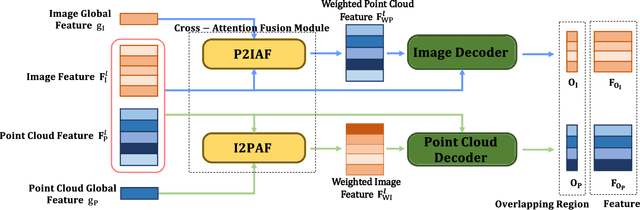
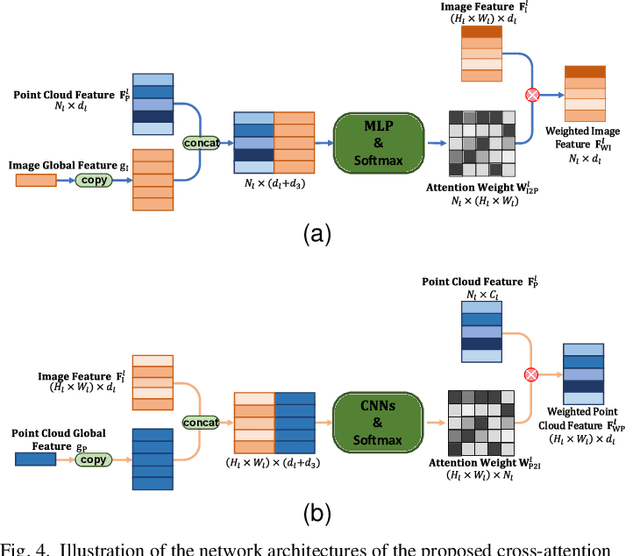
Motivated by the intuition that the critical step of localizing a 2D image in the corresponding 3D point cloud is establishing 2D-3D correspondence between them, we propose the first feature-based dense correspondence framework for addressing the image-to-point cloud registration problem, dubbed CorrI2P, which consists of three modules, i.e., feature embedding, symmetric overlapping region detection, and pose estimation through the established correspondence. Specifically, given a pair of a 2D image and a 3D point cloud, we first transform them into high-dimensional feature space and feed the resulting features into a symmetric overlapping region detector to determine the region where the image and point cloud overlap each other. Then we use the features of the overlapping regions to establish the 2D-3D correspondence before running EPnP within RANSAC to estimate the camera's pose. Experimental results on KITTI and NuScenes datasets show that our CorrI2P outperforms state-of-the-art image-to-point cloud registration methods significantly. We will make the code publicly available.
Foveated Thermal Computational Imaging in the Wild Using All-Silicon Meta-Optics
Dec 13, 2022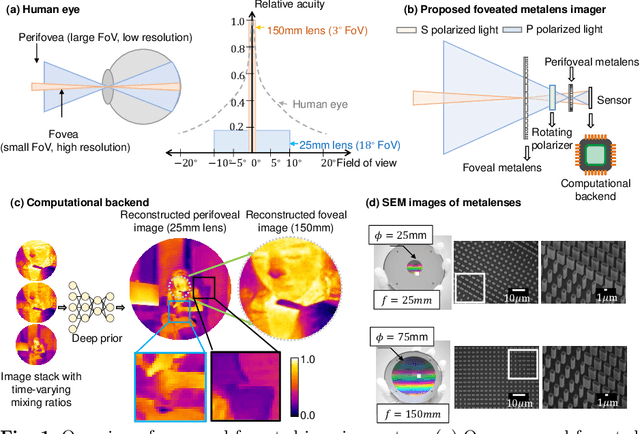
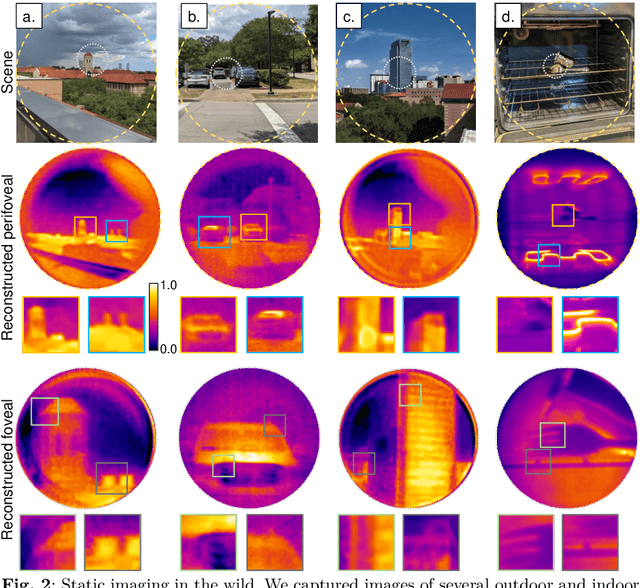
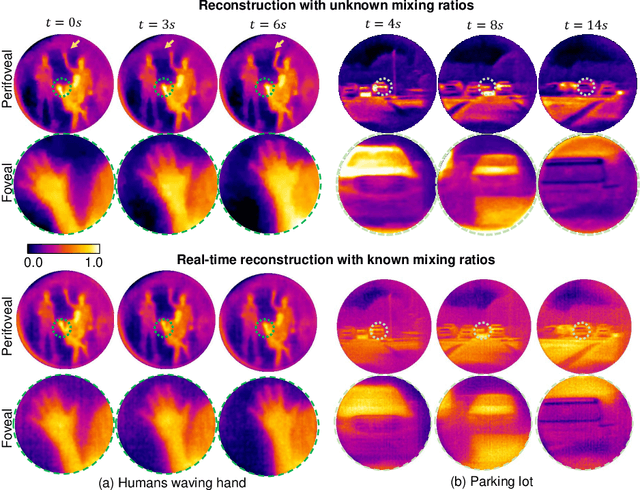
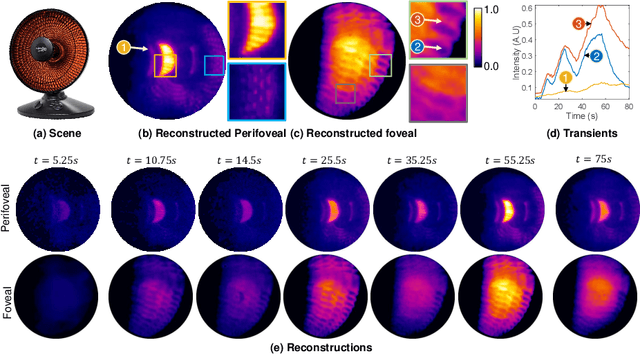
Foveated imaging provides a better tradeoff between situational awareness (field of view) and resolution and is critical in long-wavelength infrared regimes because of the size, weight, power, and cost of thermal sensors. We demonstrate computational foveated imaging by exploiting the ability of a meta-optical frontend to discriminate between different polarization states and a computational backend to reconstruct the captured image/video. The frontend is a three-element optic: the first element which we call the "foveal" element is a metalens that focuses s-polarized light at a distance of $f_1$ without affecting the p-polarized light; the second element which we call the "perifoveal" element is another metalens that focuses p-polarized light at a distance of $f_2$ without affecting the s-polarized light. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. Both the foveal element (focal length = 150mm; diameter = 75mm), and the perifoveal element (focal length = 25mm; diameter = 25mm) were fabricated as polarization-sensitive, all-silicon, meta surfaces resulting in a large-aperture, 1:6 foveal expansion, thermal imaging capability. A computational backend then utilizes a deep image prior to separate the resultant multiplexed image or video into a foveated image consisting of a high-resolution center and a lower-resolution large field of view context. We build a first-of-its-kind prototype system and demonstrate 12 frames per second real-time, thermal, foveated image, and video capture in the wild.
Bi-directional Weakly Supervised Knowledge Distillation for Whole Slide Image Classification
Oct 10, 2022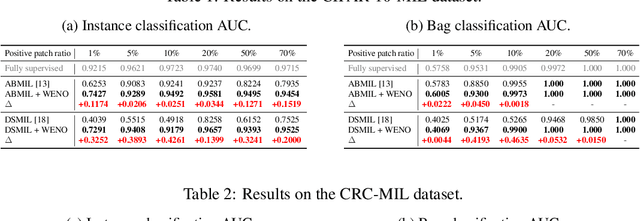

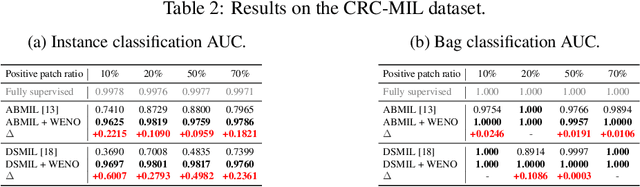

Computer-aided pathology diagnosis based on the classification of Whole Slide Image (WSI) plays an important role in clinical practice, and it is often formulated as a weakly-supervised Multiple Instance Learning (MIL) problem. Existing methods solve this problem from either a bag classification or an instance classification perspective. In this paper, we propose an end-to-end weakly supervised knowledge distillation framework (WENO) for WSI classification, which integrates a bag classifier and an instance classifier in a knowledge distillation framework to mutually improve the performance of both classifiers. Specifically, an attention-based bag classifier is used as the teacher network, which is trained with weak bag labels, and an instance classifier is used as the student network, which is trained using the normalized attention scores obtained from the teacher network as soft pseudo labels for the instances in positive bags. An instance feature extractor is shared between the teacher and the student to further enhance the knowledge exchange between them. In addition, we propose a hard positive instance mining strategy based on the output of the student network to force the teacher network to keep mining hard positive instances. WENO is a plug-and-play framework that can be easily applied to any existing attention-based bag classification methods. Extensive experiments on five datasets demonstrate the efficiency of WENO. Code is available at https://github.com/miccaiif/WENO.
CLIP2GAN: Towards Bridging Text with the Latent Space of GANs
Nov 28, 2022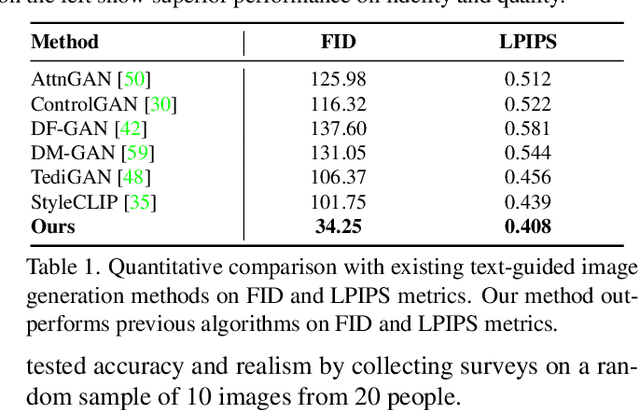
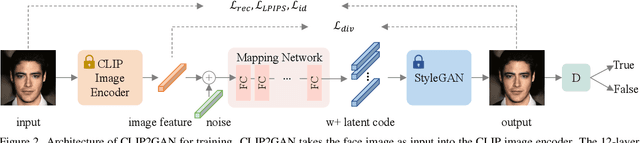
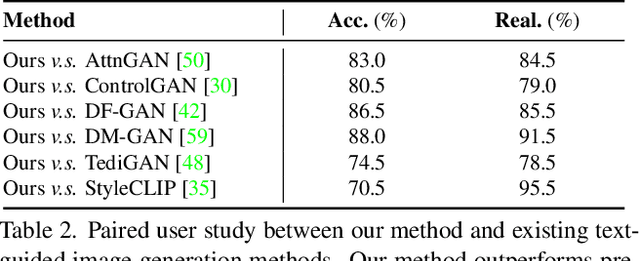
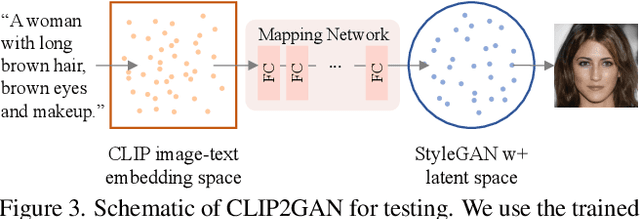
In this work, we are dedicated to text-guided image generation and propose a novel framework, i.e., CLIP2GAN, by leveraging CLIP model and StyleGAN. The key idea of our CLIP2GAN is to bridge the output feature embedding space of CLIP and the input latent space of StyleGAN, which is realized by introducing a mapping network. In the training stage, we encode an image with CLIP and map the output feature to a latent code, which is further used to reconstruct the image. In this way, the mapping network is optimized in a self-supervised learning way. In the inference stage, since CLIP can embed both image and text into a shared feature embedding space, we replace CLIP image encoder in the training architecture with CLIP text encoder, while keeping the following mapping network as well as StyleGAN model. As a result, we can flexibly input a text description to generate an image. Moreover, by simply adding mapped text features of an attribute to a mapped CLIP image feature, we can effectively edit the attribute to the image. Extensive experiments demonstrate the superior performance of our proposed CLIP2GAN compared to previous methods.
A novel adversarial learning strategy for medical image classification
Jul 07, 2022
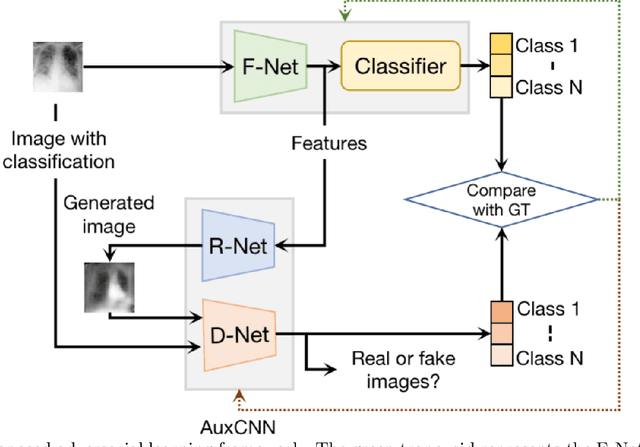
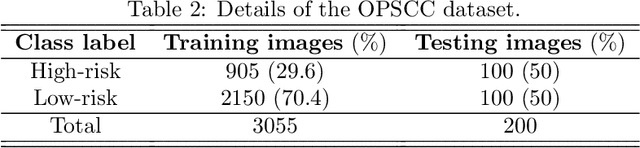
Deep learning (DL) techniques have been extensively utilized for medical image classification. Most DL-based classification networks are generally structured hierarchically and optimized through the minimization of a single loss function measured at the end of the networks. However, such a single loss design could potentially lead to optimization of one specific value of interest but fail to leverage informative features from intermediate layers that might benefit classification performance and reduce the risk of overfitting. Recently, auxiliary convolutional neural networks (AuxCNNs) have been employed on top of traditional classification networks to facilitate the training of intermediate layers to improve classification performance and robustness. In this study, we proposed an adversarial learning-based AuxCNN to support the training of deep neural networks for medical image classification. Two main innovations were adopted in our AuxCNN classification framework. First, the proposed AuxCNN architecture includes an image generator and an image discriminator for extracting more informative image features for medical image classification, motivated by the concept of generative adversarial network (GAN) and its impressive ability in approximating target data distribution. Second, a hybrid loss function is designed to guide the model training by incorporating different objectives of the classification network and AuxCNN to reduce overfitting. Comprehensive experimental studies demonstrated the superior classification performance of the proposed model. The effect of the network-related factors on classification performance was investigated.
A Comprehensive Review on Digital Image Watermarking
Jul 07, 2022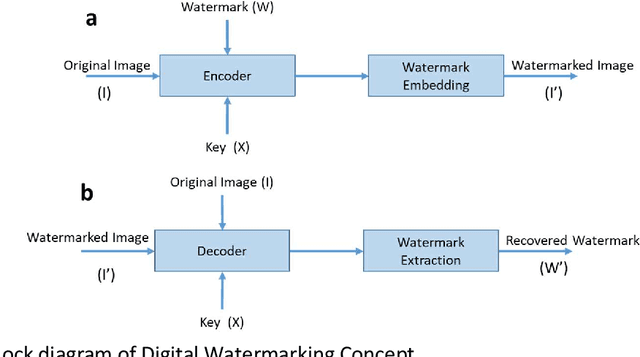
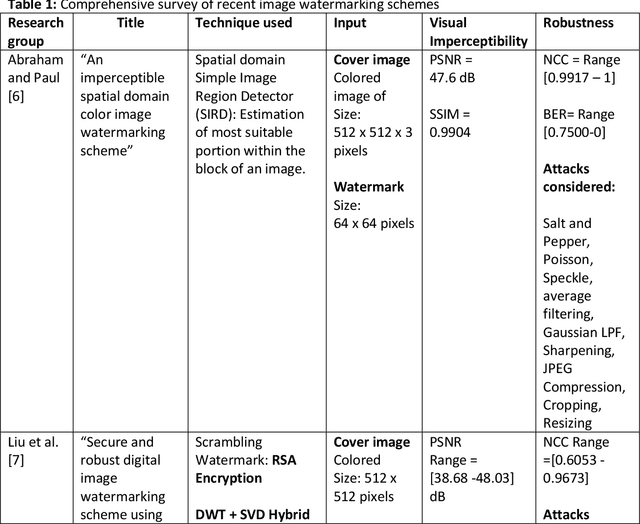
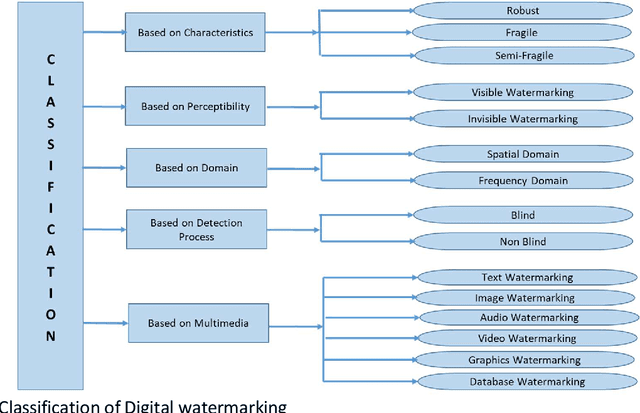
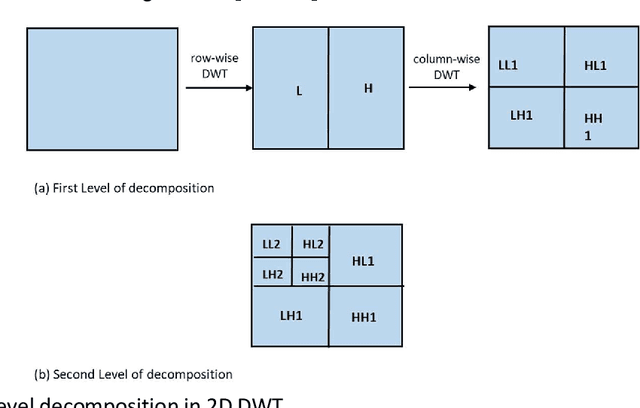
The advent of the Internet led to the easy availability of digital data like images, audio, and video. Easy access to multimedia gives rise to the issues such as content authentication, security, copyright protection, and ownership identification. Here, we discuss the concept of digital image watermarking with a focus on the technique used in image watermark embedding and extraction of the watermark. The detailed classification along with the basic characteristics, namely visual imperceptibility, robustness, capacity, security of digital watermarking is also presented in this work. Further, we have also discussed the recent application areas of digital watermarking such as healthcare, remote education, electronic voting systems, and the military. The robustness is evaluated by examining the effect of image processing attacks on the signed content and the watermark recoverability. The authors believe that the comprehensive survey presented in this paper will help the new researchers to gather knowledge in this domain. Further, the comparative analysis can enkindle ideas to improve upon the already mentioned techniques.
A novel state connection strategy for quantum computing to represent and compress digital images
Dec 14, 2022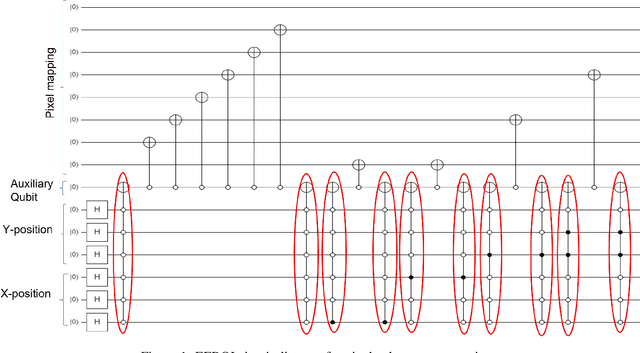
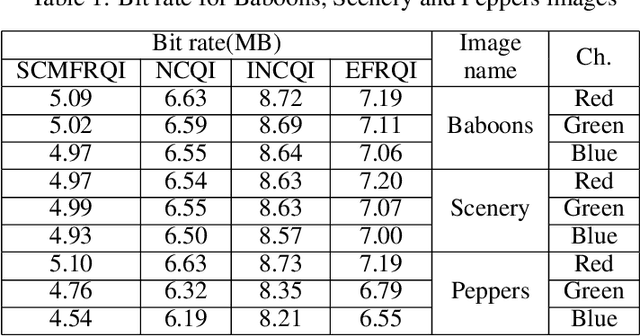
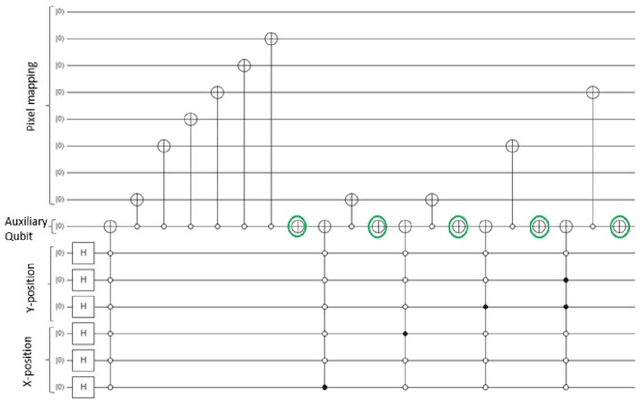
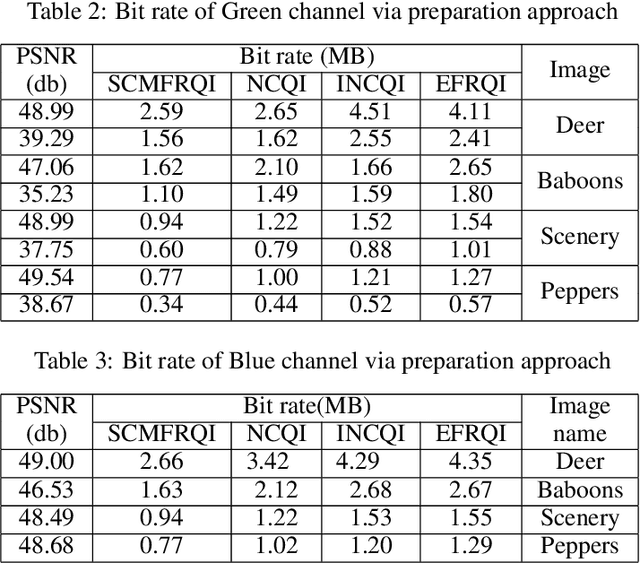
Quantum image processing draws a lot of attention due to faster data computation and storage compared to classical data processing systems. Converting classical image data into the quantum domain and state label preparation complexity is still a challenging issue. The existing techniques normally connect the pixel values and the state position directly. Recently, the EFRQI (efficient flexible representation of the quantum image) approach uses an auxiliary qubit that connects the pixel-representing qubits to the state position qubits via Toffoli gates to reduce state connection. Due to the twice use of Toffoli gates for each pixel connection still it requires a significant number of bits to connect each pixel value. In this paper, we propose a new SCMFRQI (state connection modification FRQI) approach for further reducing the required bits by modifying the state connection using a reset gate rather than repeating the use of the same Toffoli gate connection as a reset gate. Moreover, unlike other existing methods, we compress images using block-level for further reduction of required qubits. The experimental results confirm that the proposed method outperforms the existing methods in terms of both image representation and compression points of view.
Evolution of a Web-Scale Near Duplicate Image Detection System
Sep 18, 2022
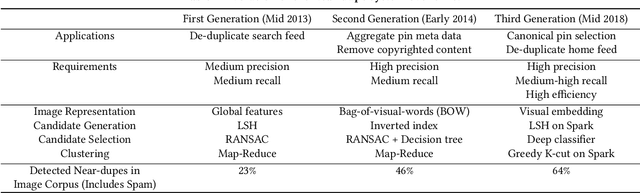


Detecting near duplicate images is fundamental to the content ecosystem of photo sharing web applications. However, such a task is challenging when involving a web-scale image corpus containing billions of images. In this paper, we present an efficient system for detecting near duplicate images across 8 billion images. Our system consists of three stages: candidate generation, candidate selection, and clustering. We also demonstrate that this system can be used to greatly improve the quality of recommendations and search results across a number of real-world applications. In addition, we include the evolution of the system over the course of six years, bringing out experiences and lessons on how new systems are designed to accommodate organic content growth as well as the latest technology. Finally, we are releasing a human-labeled dataset of ~53,000 pairs of images introduced in this paper.