 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLIPtone: Unsupervised Learning for Text-based Image Tone Adjustment
Apr 01, 2024
Recent image tone adjustment (or enhancement) approaches have predominantly adopted supervised learning for learning human-centric perceptual assessment. However, these approaches are constrained by intrinsic challenges of supervised learning. Primarily, the requirement for expertly-curated or retouched images escalates the data acquisition expenses. Moreover, their coverage of target style is confined to stylistic variants inferred from the training data. To surmount the above challenges, we propose an unsupervised learning-based approach for text-based image tone adjustment method, CLIPtone, that extends an existing image enhancement method to accommodate natural language descriptions. Specifically, we design a hyper-network to adaptively modulate the pretrained parameters of the backbone model based on text description. To assess whether the adjusted image aligns with the text description without ground truth image, we utilize CLIP, which is trained on a vast set of language-image pairs and thus encompasses knowledge of human perception. The major advantages of our approach are three fold: (i) minimal data collection expenses, (ii) support for a range of adjustments, and (iii) the ability to handle novel text descriptions unseen in training. Our approach's efficacy is demonstrated through comprehensive experiments, including a user study.
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024
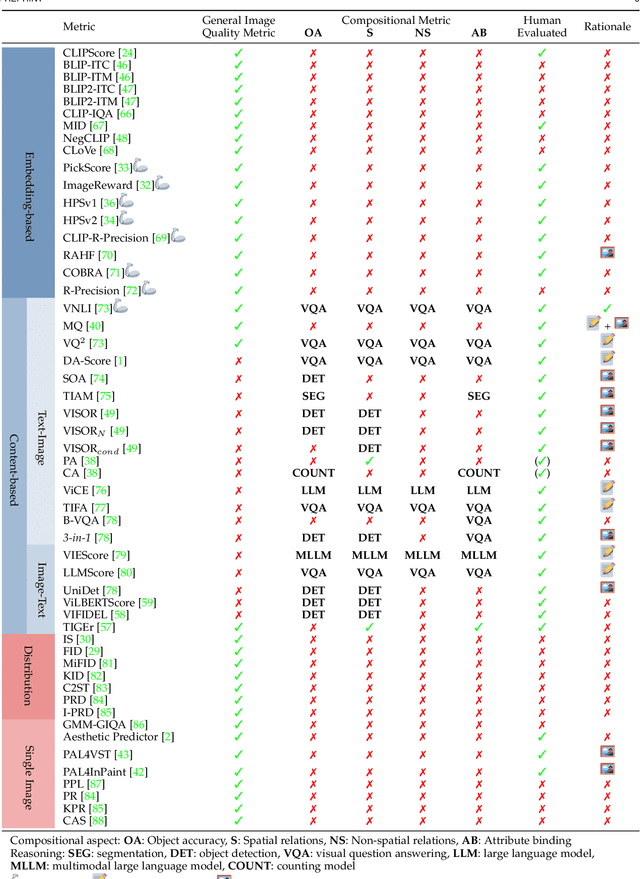
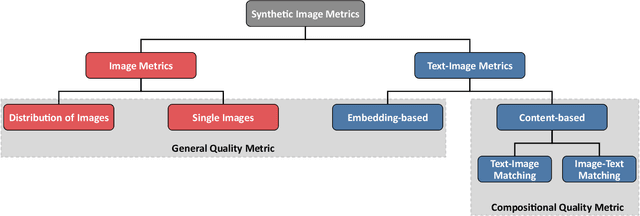
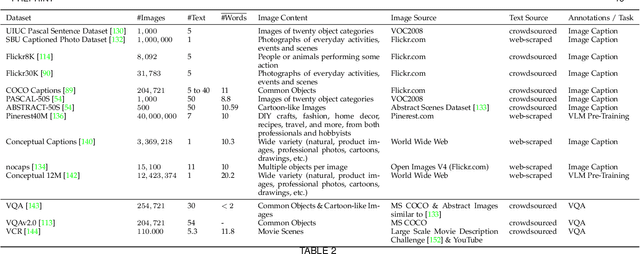
Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
On the Convergence of Continual Learning with Adaptive Methods
Apr 15, 2024One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
* Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence (UAI 2023), see https://proceedings.mlr.press/v216/han23a.html
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Apr 07, 2024Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
DetCLIPv3: Towards Versatile Generative Open-vocabulary Object Detection
Apr 14, 2024Existing open-vocabulary object detectors typically require a predefined set of categories from users, significantly confining their application scenarios. In this paper, we introduce DetCLIPv3, a high-performing detector that excels not only at both open-vocabulary object detection, but also generating hierarchical labels for detected objects. DetCLIPv3 is characterized by three core designs: 1. Versatile model architecture: we derive a robust open-set detection framework which is further empowered with generation ability via the integration of a caption head. 2. High information density data: we develop an auto-annotation pipeline leveraging visual large language model to refine captions for large-scale image-text pairs, providing rich, multi-granular object labels to enhance the training. 3. Efficient training strategy: we employ a pre-training stage with low-resolution inputs that enables the object captioner to efficiently learn a broad spectrum of visual concepts from extensive image-text paired data. This is followed by a fine-tuning stage that leverages a small number of high-resolution samples to further enhance detection performance. With these effective designs, DetCLIPv3 demonstrates superior open-vocabulary detection performance, \eg, our Swin-T backbone model achieves a notable 47.0 zero-shot fixed AP on the LVIS minival benchmark, outperforming GLIPv2, GroundingDINO, and DetCLIPv2 by 18.0/19.6/6.6 AP, respectively. DetCLIPv3 also achieves a state-of-the-art 19.7 AP in dense captioning task on VG dataset, showcasing its strong generative capability.
Diffusion Models Meet Remote Sensing: Principles, Methods, and Perspectives
Apr 13, 2024As a newly emerging advance in deep generative models, diffusion models have achieved state-of-the-art results in many fields, including computer vision, natural language processing, and molecule design. The remote sensing community has also noticed the powerful ability of diffusion models and quickly applied them to a variety of tasks for image processing. Given the rapid increase in research on diffusion models in the field of remote sensing, it is necessary to conduct a comprehensive review of existing diffusion model-based remote sensing papers, to help researchers recognize the potential of diffusion models and provide some directions for further exploration. Specifically, this paper first introduces the theoretical background of diffusion models, and then systematically reviews the applications of diffusion models in remote sensing, including image generation, enhancement, and interpretation. Finally, the limitations of existing remote sensing diffusion models and worthy research directions for further exploration are discussed and summarized.
Uncovering the Text Embedding in Text-to-Image Diffusion Models
Apr 01, 2024The correspondence between input text and the generated image exhibits opacity, wherein minor textual modifications can induce substantial deviations in the generated image. While, text embedding, as the pivotal intermediary between text and images, remains relatively underexplored. In this paper, we address this research gap by delving into the text embedding space, unleashing its capacity for controllable image editing and explicable semantic direction attributes within a learning-free framework. Specifically, we identify two critical insights regarding the importance of per-word embedding and their contextual correlations within text embedding, providing instructive principles for learning-free image editing. Additionally, we find that text embedding inherently possesses diverse semantic potentials, and further reveal this property through the lens of singular value decomposition (SVD). These uncovered properties offer practical utility for image editing and semantic discovery. More importantly, we expect the in-depth analyses and findings of the text embedding can enhance the understanding of text-to-image diffusion models.
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Apr 03, 2024We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.80, inception score (IS) from 80.4 to 356.4, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
Practical Region-level Attack against Segment Anything Models
Apr 12, 2024Segment Anything Models (SAM) have made significant advancements in image segmentation, allowing users to segment target portions of an image with a single click (i.e., user prompt). Given its broad applications, the robustness of SAM against adversarial attacks is a critical concern. While recent works have explored adversarial attacks against a pre-defined prompt/click, their threat model is not yet realistic: (1) they often assume the user-click position is known to the attacker (point-based attack), and (2) they often operate under a white-box setting with limited transferability. In this paper, we propose a more practical region-level attack where attackers do not need to know the precise user prompt. The attack remains effective as the user clicks on any point on the target object in the image, hiding the object from SAM. Also, by adapting a spectrum transformation method, we make the attack more transferable under a black-box setting. Both control experiments and testing against real-world SAM services confirm its effectiveness.
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
Apr 06, 2024Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.