 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Computation with Elastic Input Sequence
Jan 30, 2023
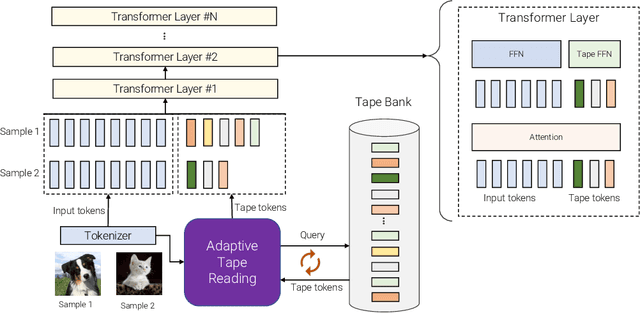
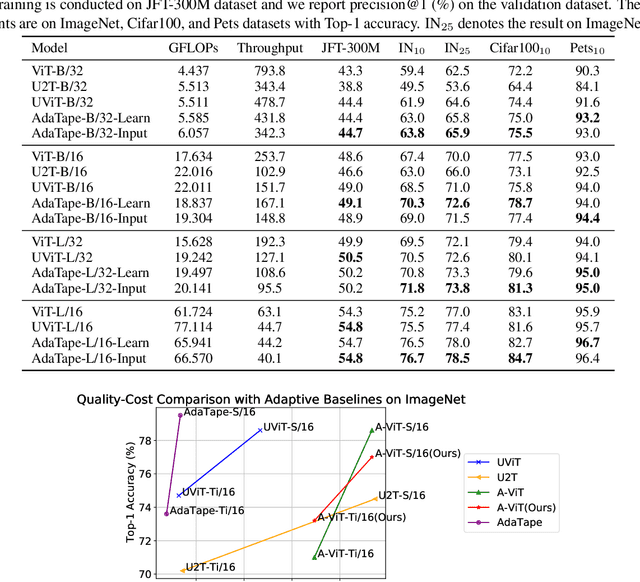
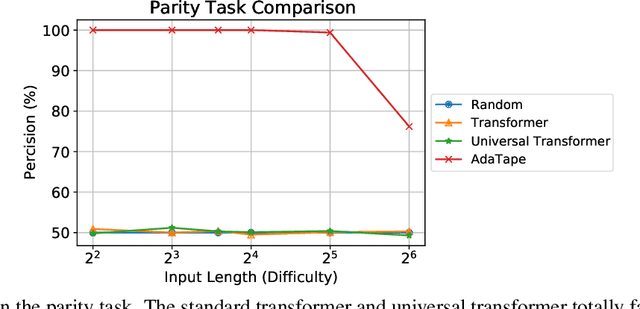
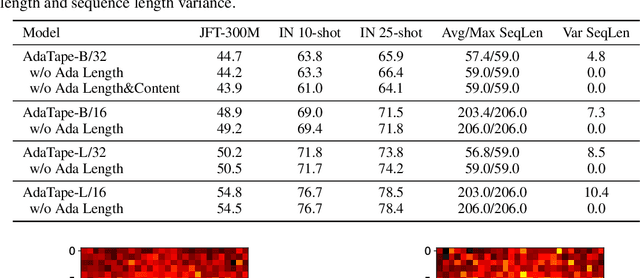
When solving a problem, human beings have the adaptive ability in terms of the type of information they use, the procedure they take, and the amount of time they spend approaching and solving the problem. However, most standard neural networks have the same function type and fixed computation budget on different samples regardless of their nature and difficulty. Adaptivity is a powerful paradigm as it not only imbues practitioners with flexibility pertaining to the downstream usage of these models but can also serve as a powerful inductive bias for solving certain challenging classes of problems. In this work, we propose a new strategy, AdaTape, that enables dynamic computation in neural networks via adaptive tape tokens. AdaTape employs an elastic input sequence by equipping an existing architecture with a dynamic read-and-write tape. Specifically, we adaptively generate input sequences using tape tokens obtained from a tape bank that can either be trainable or generated from input data. We analyze the challenges and requirements to obtain dynamic sequence content and length, and propose the Adaptive Tape Reader (ATR) algorithm to achieve both objectives. Via extensive experiments on image recognition tasks, we show that AdaTape can achieve better performance while maintaining the computational cost.
Progressive Deblurring of Diffusion Models for Coarse-to-Fine Image Synthesis
Jul 16, 2022

Recently, diffusion models have shown remarkable results in image synthesis by gradually removing noise and amplifying signals. Although the simple generative process surprisingly works well, is this the best way to generate image data? For instance, despite the fact that human perception is more sensitive to the low frequencies of an image, diffusion models themselves do not consider any relative importance of each frequency component. Therefore, to incorporate the inductive bias for image data, we propose a novel generative process that synthesizes images in a coarse-to-fine manner. First, we generalize the standard diffusion models by enabling diffusion in a rotated coordinate system with different velocities for each component of the vector. We further propose a blur diffusion as a special case, where each frequency component of an image is diffused at different speeds. Specifically, the proposed blur diffusion consists of a forward process that blurs an image and adds noise gradually, after which a corresponding reverse process deblurs an image and removes noise progressively. Experiments show that the proposed model outperforms the previous method in FID on LSUN bedroom and church datasets. Code is available at https://github.com/sangyun884/blur-diffusion.
ICRICS: Iterative Compensation Recovery for Image Compressive Sensing
Jul 19, 2022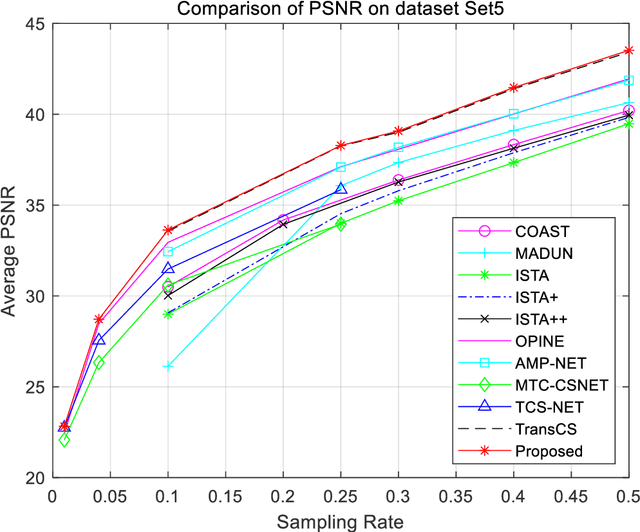
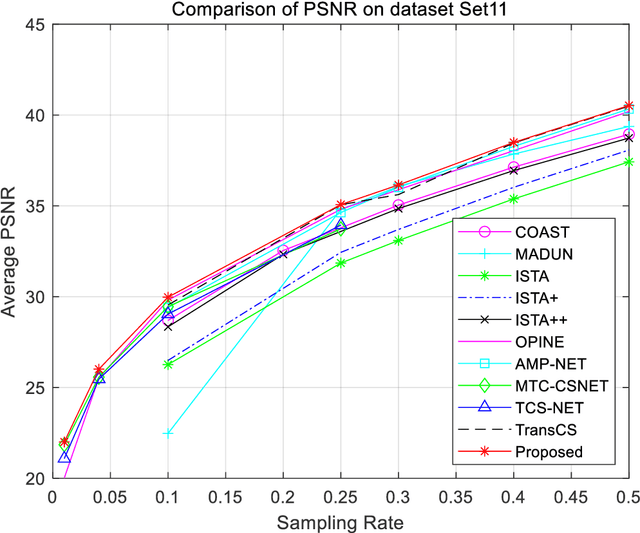
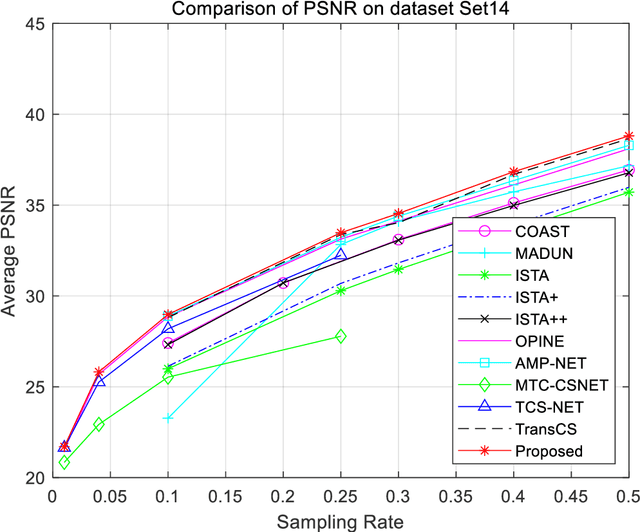
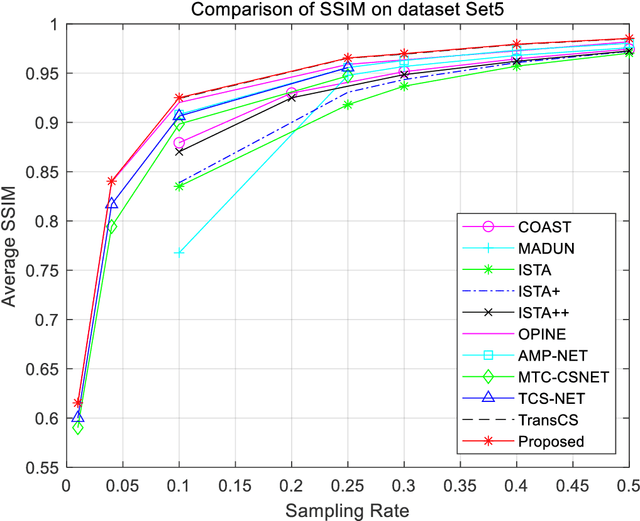
Closed-loop architecture is widely utilized in automatic control systems and attain distinguished performance. However, classical compressive sensing systems employ open-loop architecture with separated sampling and reconstruction units. Therefore, a method of iterative compensation recovery for image compressive sensing (ICRICS) is proposed by introducing closed-loop framework into traditional compresses sensing systems. The proposed method depends on any existing approaches and upgrades their reconstruction performance by adding negative feedback structure. Theory analysis on negative feedback of compressive sensing systems is performed. An approximate mathematical proof of the effectiveness of the proposed method is also provided. Simulation experiments on more than 3 image datasets show that the proposed method is superior to 10 competition approaches in reconstruction performance. The maximum increment of average peak signal-to-noise ratio is 4.36 dB and the maximum increment of average structural similarity is 0.034 on one dataset. The proposed method based on negative feedback mechanism can efficiently correct the recovery error in the existing systems of image compressive sensing.
OpenMedIA: Open-Source Medical Image Analysis Toolbox and Benchmark under Heterogeneous AI Computing Platforms
Aug 11, 2022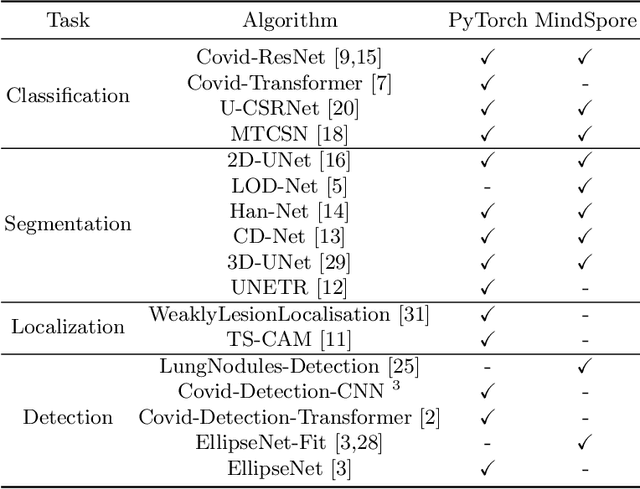
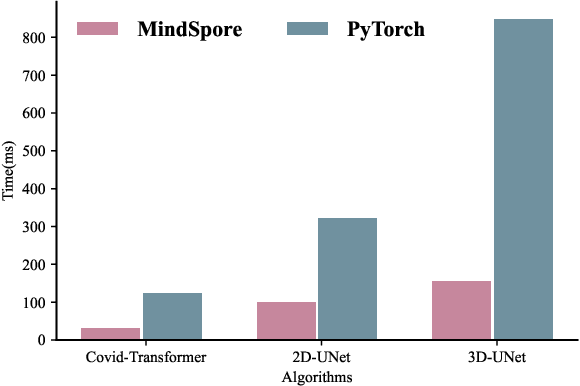
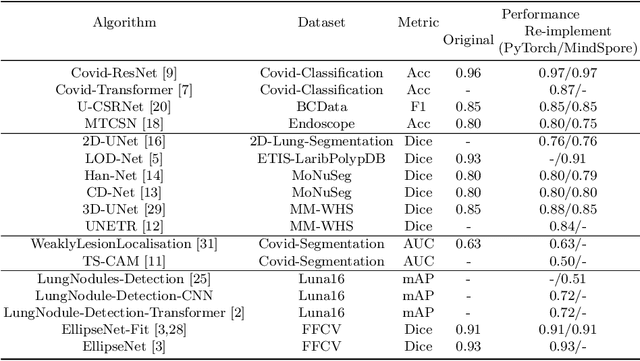
In this paper, we present OpenMedIA, an open-source toolbox library containing a rich set of deep learning methods for medical image analysis under heterogeneous Artificial Intelligence (AI) computing platforms. Various medical image analysis methods, including 2D$/$3D medical image classification, segmentation, localisation, and detection, have been included in the toolbox with PyTorch and$/$or MindSpore implementations under heterogeneous NVIDIA and Huawei Ascend computing systems. To our best knowledge, OpenMedIA is the first open-source algorithm library providing compared PyTorch and MindSp
DeltaGAN: Towards Diverse Few-shot Image Generation with Sample-Specific Delta
Jul 21, 2022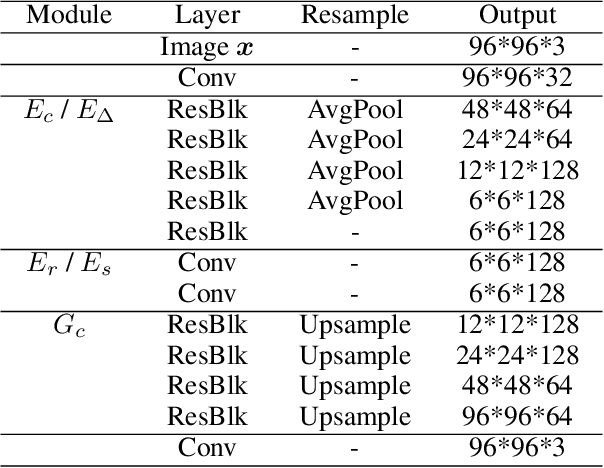

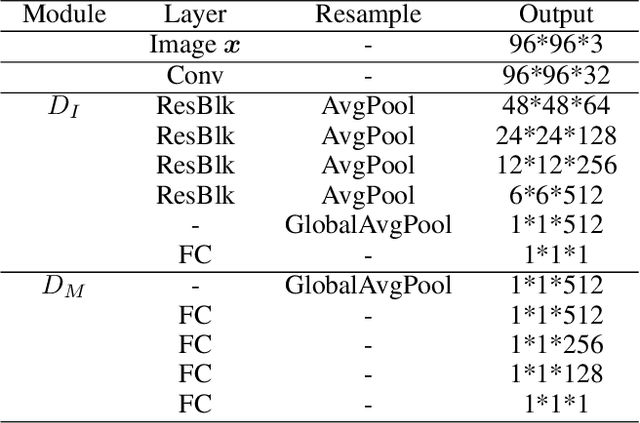

Learning to generate new images for a novel category based on only a few images, named as few-shot image generation, has attracted increasing research interest. Several state-of-the-art works have yielded impressive results, but the diversity is still limited. In this work, we propose a novel Delta Generative Adversarial Network (DeltaGAN), which consists of a reconstruction subnetwork and a generation subnetwork. The reconstruction subnetwork captures intra-category transformation, i.e., delta, between same-category pairs. The generation subnetwork generates sample-specific delta for an input image, which is combined with this input image to generate a new image within the same category. Besides, an adversarial delta matching loss is designed to link the above two subnetworks together. Extensive experiments on six benchmark datasets demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/bcmi/DeltaGAN-Few-Shot-Image-Generation.
Polarized Color Image Denoising using Pocoformer
Jul 01, 2022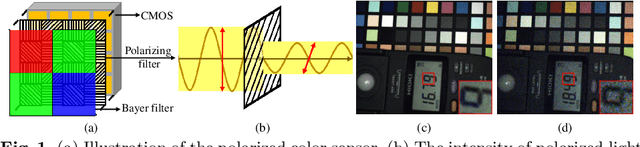
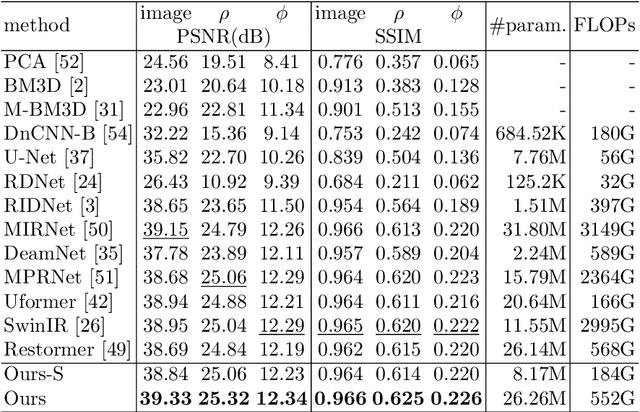
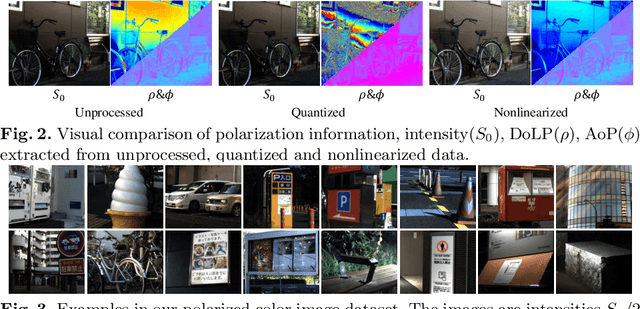
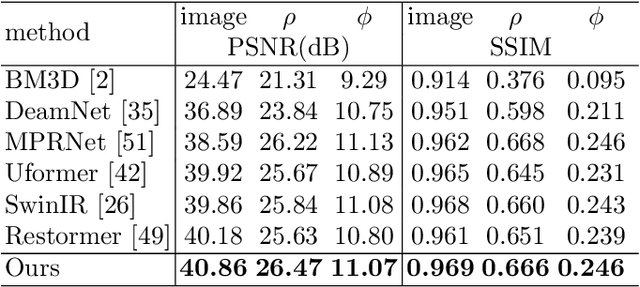
Polarized color photography provides both visual textures and object surficial information in one single snapshot. However, the use of the directional polarizing filter array causes extremely lower photon count and SNR compared to conventional color imaging. Thus, the feature essentially leads to unpleasant noisy images and destroys polarization analysis performance. It is a challenge for traditional image processing pipelines owing to the fact that the physical constraints exerted implicitly in the channels are excessively complicated. To address this issue, we propose a learning-based approach to simultaneously restore clean signals and precise polarization information. A real-world polarized color image dataset of paired raw short-exposed noisy and long-exposed reference images are captured to support the learning-based pipeline. Moreover, we embrace the development of vision Transformer and propose a hybrid transformer model for the Polarized Color image denoising, namely PoCoformer, for a better restoration performance. Abundant experiments demonstrate the effectiveness of proposed method and key factors that affect results are analyzed.
CoopHash: Cooperative Learning of Multipurpose Descriptor and Contrastive Pair Generator via Variational MCMC Teaching for Supervised Image Hashing
Oct 09, 2022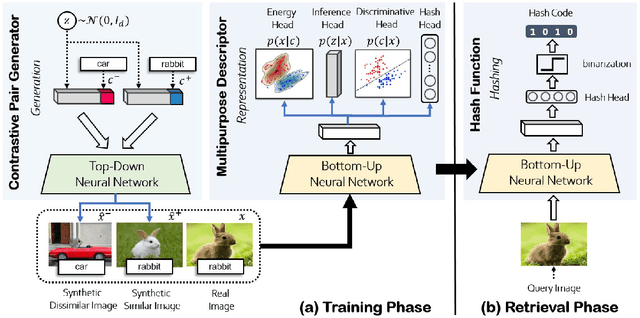
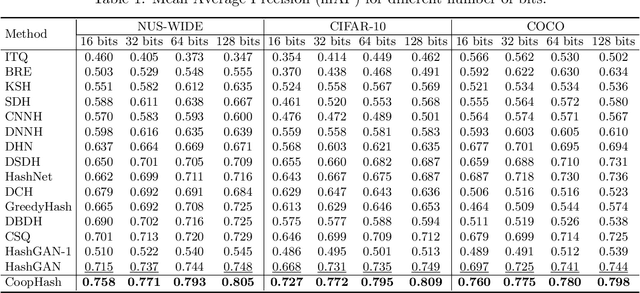
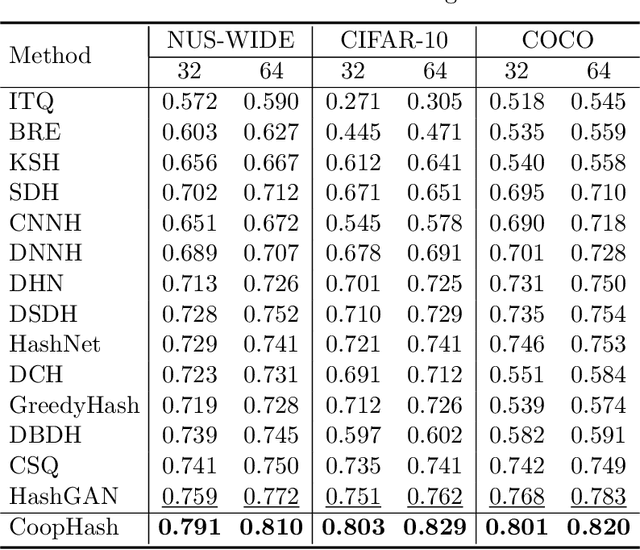
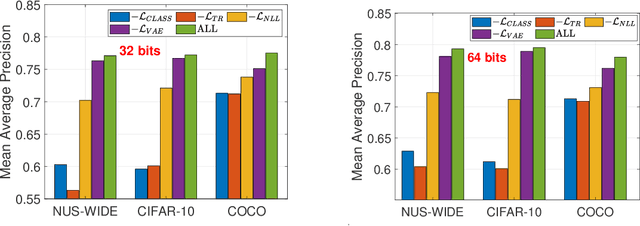
Leveraging supervised information can lead to superior retrieval performance in the image hashing domain but the performance degrades significantly without enough labeled data. One effective solution to boost the performance is to employ generative models, such as Generative Adversarial Networks (GANs), to generate synthetic data in an image hashing model. However, GAN-based methods are difficult to train and suffer from mode collapse issue, which prevents the hashing approaches from jointly training the generative models and the hash functions. This limitation results in sub-optimal retrieval performance. To overcome this limitation, we propose a novel framework, the generative cooperative hashing network (CoopHash), which is based on the energy-based cooperative learning. CoopHash jointly learns a powerful generative representation of the data and a robust hash function. CoopHash has two components: a top-down contrastive pair generator that synthesizes contrastive images and a bottom-up multipurpose descriptor that simultaneously represents the images from multiple perspectives, including probability density, hash code, latent code, and category. The two components are jointly learned via a novel likelihood-based cooperative learning scheme. We conduct experiments on several real-world datasets and show that the proposed method outperforms the competing hashing supervised methods, achieving up to 10% relative improvement over the current state-of-the-art supervised hashing methods, and exhibits a significantly better performance in out-of-distribution retrieval.
Unified Interactive Image Matting
May 17, 2022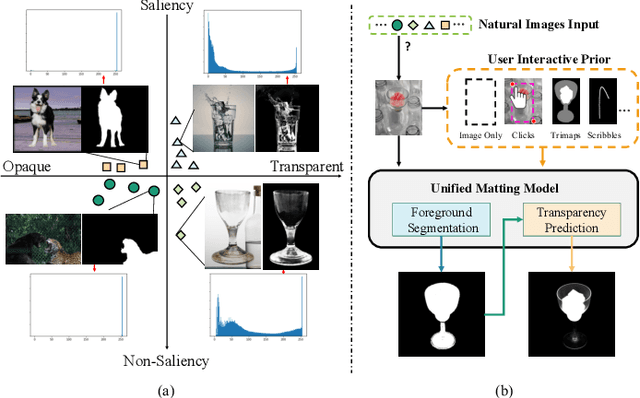

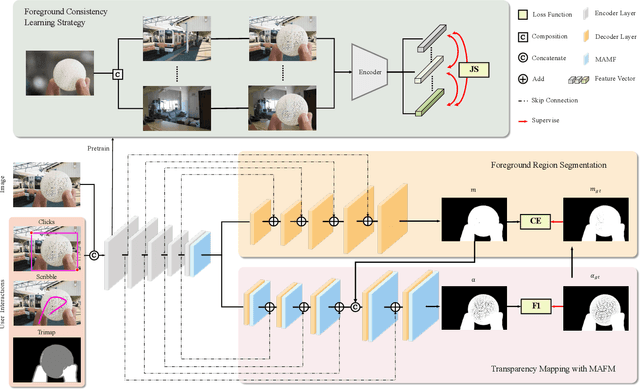
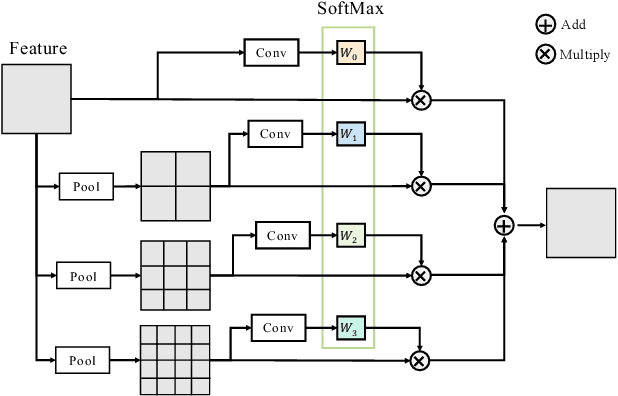
Recent image matting studies are developing towards proposing trimap-free or interactive methods for complete complex image matting tasks. Although avoiding the extensive labors of trimap annotation, existing methods still suffer from two limitations: (1) For the single image with multiple objects, it is essential to provide extra interaction information to help determining the matting target; (2) For transparent objects, the accurate regression of alpha matte from RGB image is much more difficult compared with the opaque ones. In this work, we propose a Unified Interactive image Matting method, named UIM, which solves the limitations and achieves satisfying matting results for any scenario. Specifically, UIM leverages multiple types of user interaction to avoid the ambiguity of multiple matting targets, and we compare the pros and cons of different annotation types in detail. To unify the matting performance for transparent and opaque objects, we decouple image matting into two stages, i.e., foreground segmentation and transparency prediction. Moreover, we design a multi-scale attentive fusion module to alleviate the vagueness in the boundary region. Experimental results demonstrate that UIM achieves state-of-the-art performance on the Composition-1K test set and a synthetic unified dataset. Our code and models will be released soon.
Guaranteed Tensor Recovery Fused Low-rankness and Smoothness
Feb 04, 2023
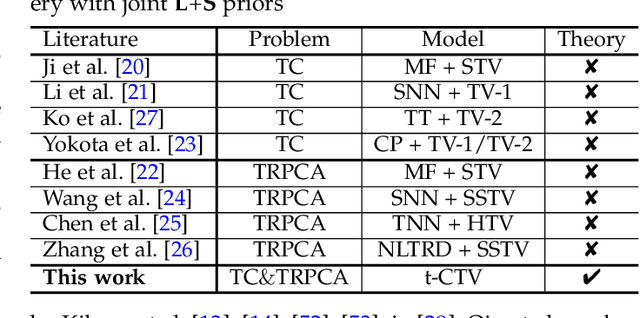


The tensor data recovery task has thus attracted much research attention in recent years. Solving such an ill-posed problem generally requires to explore intrinsic prior structures underlying tensor data, and formulate them as certain forms of regularization terms for guiding a sound estimate of the restored tensor. Recent research have made significant progress by adopting two insightful tensor priors, i.e., global low-rankness (L) and local smoothness (S) across different tensor modes, which are always encoded as a sum of two separate regularization terms into the recovery models. However, unlike the primary theoretical developments on low-rank tensor recovery, these joint L+S models have no theoretical exact-recovery guarantees yet, making the methods lack reliability in real practice. To this crucial issue, in this work, we build a unique regularization term, which essentially encodes both L and S priors of a tensor simultaneously. Especially, by equipping this single regularizer into the recovery models, we can rigorously prove the exact recovery guarantees for two typical tensor recovery tasks, i.e., tensor completion (TC) and tensor robust principal component analysis (TRPCA). To the best of our knowledge, this should be the first exact-recovery results among all related L+S methods for tensor recovery. Significant recovery accuracy improvements over many other SOTA methods in several TC and TRPCA tasks with various kinds of visual tensor data are observed in extensive experiments. Typically, our method achieves a workable performance when the missing rate is extremely large, e.g., 99.5%, for the color image inpainting task, while all its peers totally fail in such challenging case.
Counterfactual Image Synthesis for Discovery of Personalized Predictive Image Markers
Aug 03, 2022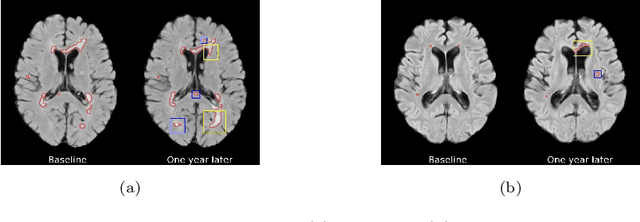

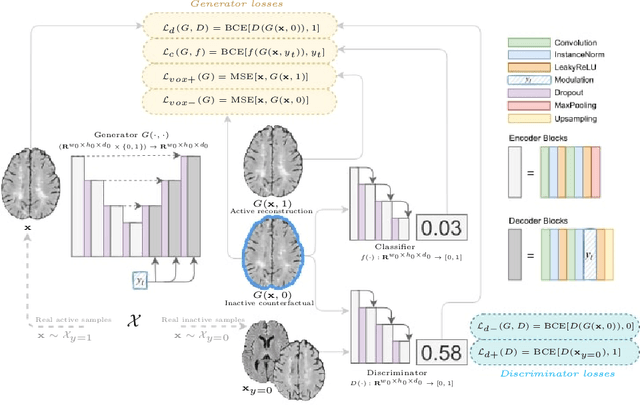

The discovery of patient-specific imaging markers that are predictive of future disease outcomes can help us better understand individual-level heterogeneity of disease evolution. In fact, deep learning models that can provide data-driven personalized markers are much more likely to be adopted in medical practice. In this work, we demonstrate that data-driven biomarker discovery can be achieved through a counterfactual synthesis process. We show how a deep conditional generative model can be used to perturb local imaging features in baseline images that are pertinent to subject-specific future disease evolution and result in a counterfactual image that is expected to have a different future outcome. Candidate biomarkers, therefore, result from examining the set of features that are perturbed in this process. Through several experiments on a large-scale, multi-scanner, multi-center multiple sclerosis (MS) clinical trial magnetic resonance imaging (MRI) dataset of relapsing-remitting (RRMS) patients, we demonstrate that our model produces counterfactuals with changes in imaging features that reflect established clinical markers predictive of future MRI lesional activity at the population level. Additional qualitative results illustrate that our model has the potential to discover novel and subject-specific predictive markers of future activity.