 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Combining Generative Artificial Intelligence (AI) and the Internet: Heading towards Evolution or Degradation?
Feb 17, 2023
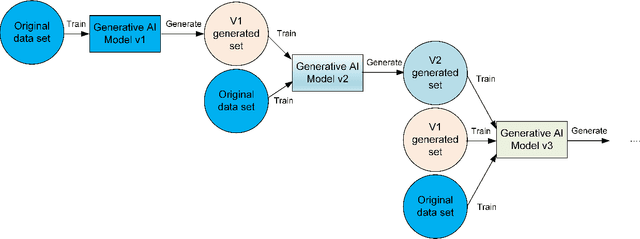



In the span of a few months, generative Artificial Intelligence (AI) tools that can generate realistic images or text have taken the Internet by storm, making them one of the technologies with fastest adoption ever. Some of these generative AI tools such as DALL-E, MidJourney, or ChatGPT have gained wide public notoriety. Interestingly, these tools are possible because of the massive amount of data (text and images) available on the Internet. The tools are trained on massive data sets that are scraped from Internet sites. And now, these generative AI tools are creating massive amounts of new data that are being fed into the Internet. Therefore, future versions of generative AI tools will be trained with Internet data that is a mix of original and AI-generated data. As time goes on, a mixture of original data and data generated by different versions of AI tools will populate the Internet. This raises a few intriguing questions: how will future versions of generative AI tools behave when trained on a mixture of real and AI generated data? Will they evolve with the new data sets or degenerate? Will evolution introduce biases in subsequent generations of generative AI tools? In this document, we explore these questions and report some very initial simulation results using a simple image-generation AI tool. These results suggest that the quality of the generated images degrades as more AI-generated data is used for training thus suggesting that generative AI may degenerate. Although these results are preliminary and cannot be generalised without further study, they serve to illustrate the potential issues of the interaction between generative AI and the Internet.
Multitemporal and multispectral data fusion for super-resolution of Sentinel-2 images
Jan 26, 2023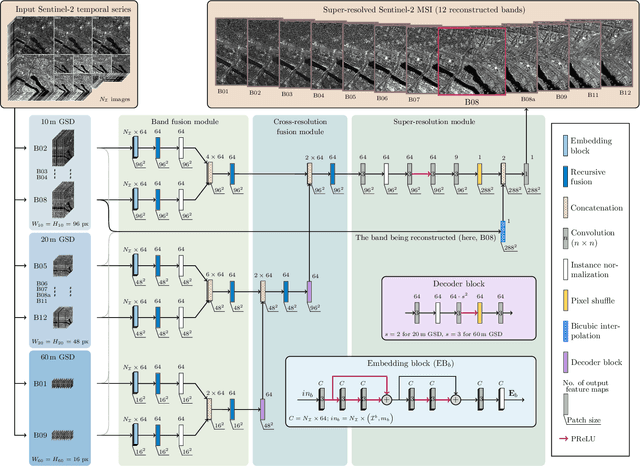
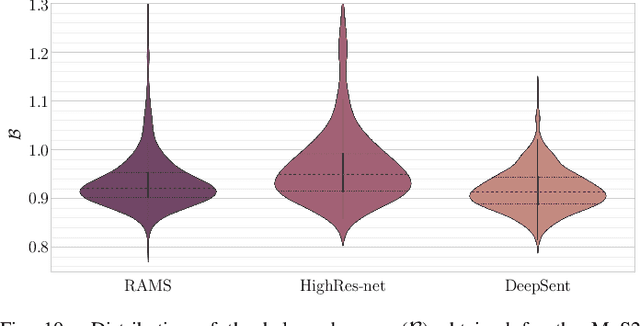
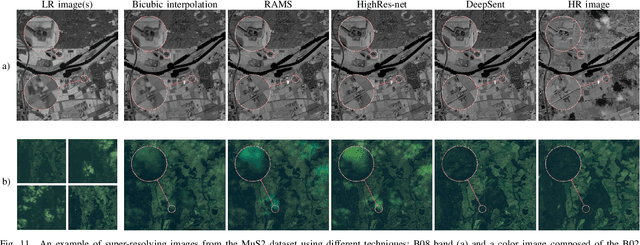
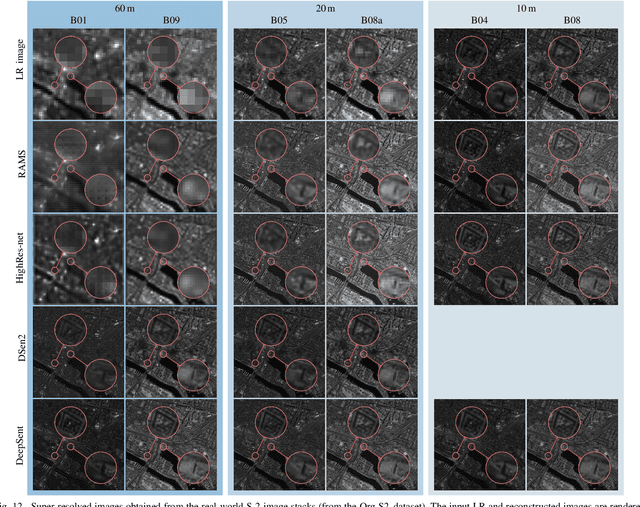
Multispectral Sentinel-2 images are a valuable source of Earth observation data, however spatial resolution of their spectral bands limited to 10 m, 20 m, and 60 m ground sampling distance remains insufficient in many cases. This problem can be addressed with super-resolution, aimed at reconstructing a high-resolution image from a low-resolution observation. For Sentinel-2, spectral information fusion allows for enhancing the 20 m and 60 m bands to the 10 m resolution. Also, there were attempts to combine multitemporal stacks of individual Sentinel-2 bands, however these two approaches have not been combined so far. In this paper, we introduce DeepSent -- a new deep network for super-resolving multitemporal series of multispectral Sentinel-2 images. It is underpinned with information fusion performed simultaneously in the spectral and temporal dimensions to generate an enlarged multispectral image. In our extensive experimental study, we demonstrate that our solution outperforms other state-of-the-art techniques that realize either multitemporal or multispectral data fusion. Furthermore, we show that the advantage of DeepSent results from how these two fusion types are combined in a single architecture, which is superior to performing such fusion in a sequential manner. Importantly, we have applied our method to super-resolve real-world Sentinel-2 images, enhancing the spatial resolution of all the spectral bands to 3.3 m nominal ground sampling distance, and we compare the outcome with very high-resolution WorldView-2 images. We will publish our implementation upon paper acceptance, and we expect it will increase the possibilities of exploiting super-resolved Sentinel-2 images in real-life applications.
We are Going to the Space -- Part 1: Which device to deploy in a satellite?
Jan 12, 2023
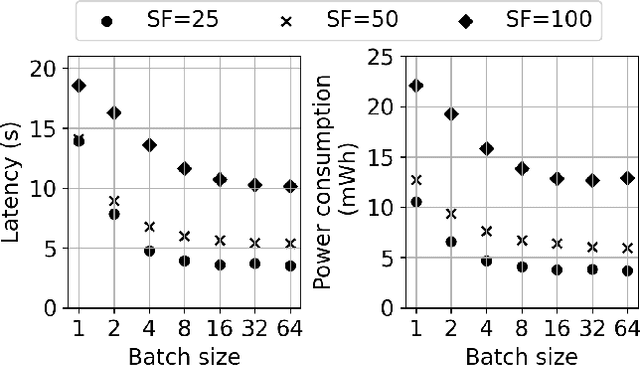


The shrinkage in sizes of components that make up satellites led to wider and low cost availability of satellites. As a result, there has been an advent of smaller organizations having the ability to deploy satellites with a variety of data-intensive applications to run on them. One popular application is image analysis to detect, for example, land, ice, clouds, etc. However, the resource-constrained nature of the devices deployed in satellites creates additional challenges for this resource-intensive application. In this paper, we investigate the performance of a variety of edge devices for deep-learning-based image processing in space. Our goal is to determine the devices that satisfy the latency and power constraints of satellites while achieving reasonably accurate results. Our results demonstrate that hardware accelerators (TPUs, GPUs) are necessary to reach the latency requirements. On the other hand, state-of-the-art edge devices with GPUs could have a high power draw, making them unsuitable for deployment on a satellite.
Self-Supervised Endoscopic Image Key-Points Matching
Aug 24, 2022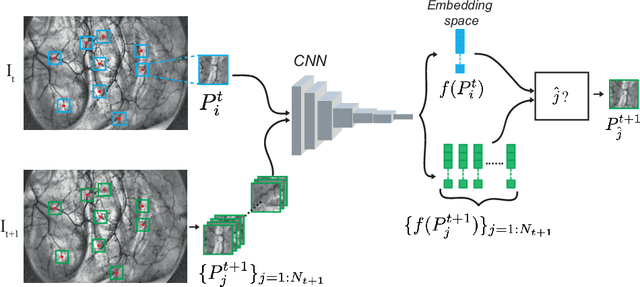
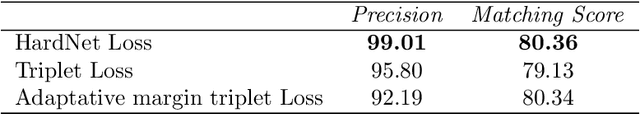
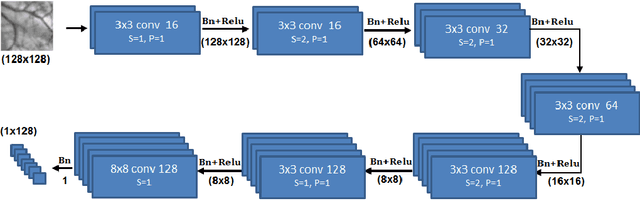
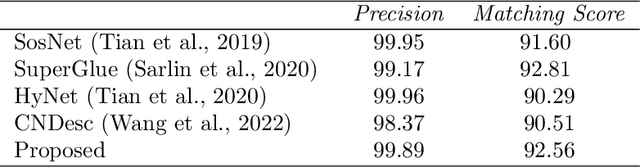
Feature matching and finding correspondences between endoscopic images is a key step in many clinical applications such as patient follow-up and generation of panoramic image from clinical sequences for fast anomalies localization. Nonetheless, due to the high texture variability present in endoscopic images, the development of robust and accurate feature matching becomes a challenging task. Recently, deep learning techniques which deliver learned features extracted via convolutional neural networks (CNNs) have gained traction in a wide range of computer vision tasks. However, they all follow a supervised learning scheme where a large amount of annotated data is required to reach good performances, which is generally not always available for medical data databases. To overcome this limitation related to labeled data scarcity, the self-supervised learning paradigm has recently shown great success in a number of applications. This paper proposes a novel self-supervised approach for endoscopic image matching based on deep learning techniques. When compared to standard hand-crafted local feature descriptors, our method outperformed them in terms of precision and recall. Furthermore, our self-supervised descriptor provides a competitive performance in comparison to a selection of state-of-the-art deep learning based supervised methods in terms of precision and matching score.
Annotation by Clicks: A Point-Supervised Contrastive Variance Method for Medical Semantic Segmentation
Dec 23, 2022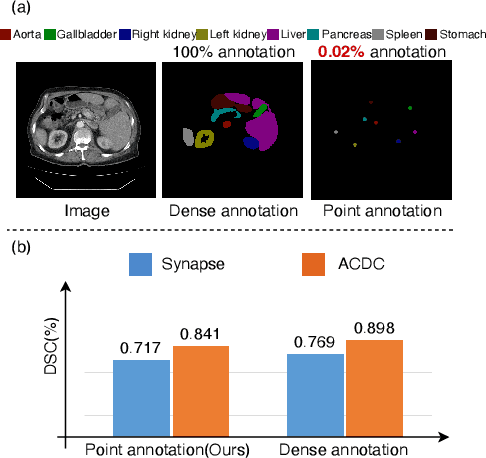

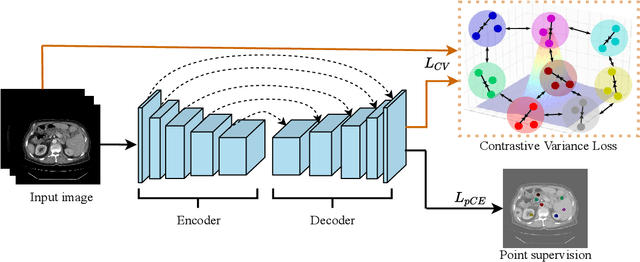
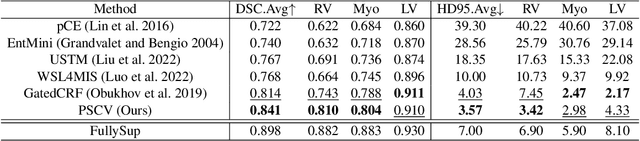
Medical image segmentation methods typically rely on numerous dense annotated images for model training, which are notoriously expensive and time-consuming to collect. To alleviate this burden, weakly supervised techniques have been exploited to train segmentation models with less expensive annotations. In this paper, we propose a novel point-supervised contrastive variance method (PSCV) for medical image semantic segmentation, which only requires one pixel-point from each organ category to be annotated. The proposed method trains the base segmentation network by using a novel contrastive variance (CV) loss to exploit the unlabeled pixels and a partial cross-entropy loss on the labeled pixels. The CV loss function is designed to exploit the statistical spatial distribution properties of organs in medical images and their variance distribution map representations to enforce discriminative predictions over the unlabeled pixels. Experimental results on two standard medical image datasets demonstrate that the proposed method outperforms the state-of-the-art weakly supervised methods on point-supervised medical image semantic segmentation tasks.
Understanding the Impact of Image Quality and Distance of Objects to Object Detection Performance
Sep 17, 2022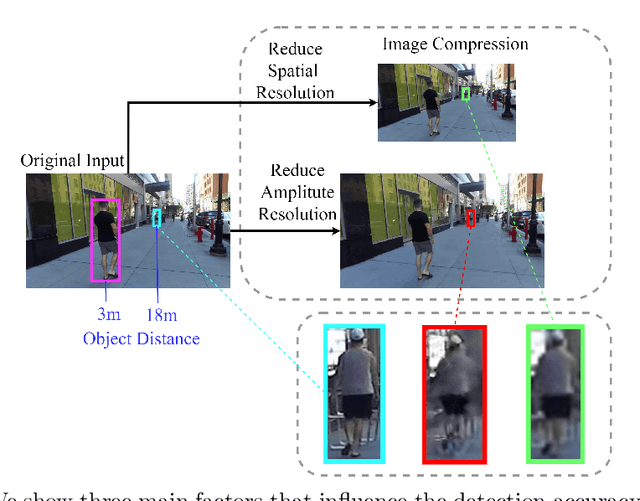
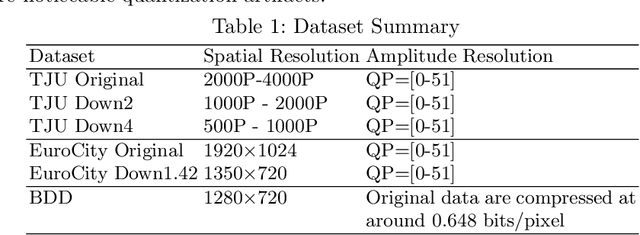
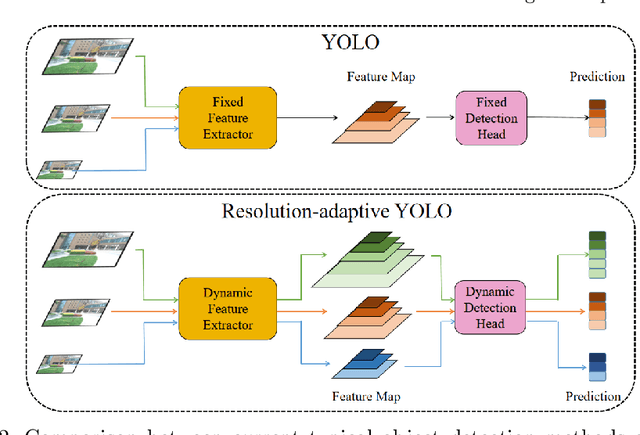

Deep learning has made great strides for object detection in images. The detection accuracy and computational cost of object detection depend on the spatial resolution of an image, which may be constrained by both the camera and storage considerations. Compression is often achieved by reducing either spatial or amplitude resolution or, at times, both, both of which have well-known effects on performance. Detection accuracy also depends on the distance of the object of interest from the camera. Our work examines the impact of spatial and amplitude resolution, as well as object distance, on object detection accuracy and computational cost. We develop a resolution-adaptive variant of YOLOv5 (RA-YOLO), which varies the number of scales in the feature pyramid and detection head based on the spatial resolution of the input image. To train and evaluate this new method, we created a dataset of images with diverse spatial and amplitude resolutions by combining images from the TJU and Eurocity datasets and generating different resolutions by applying spatial resizing and compression. We first show that RA-YOLO achieves a good trade-off between detection accuracy and inference time over a large range of spatial resolutions. We then evaluate the impact of spatial and amplitude resolutions on object detection accuracy using the proposed RA-YOLO model. We demonstrate that the optimal spatial resolution that leads to the highest detection accuracy depends on the 'tolerated' image size. We further assess the impact of the distance of an object to the camera on the detection accuracy and show that higher spatial resolution enables a greater detection range. These results provide important guidelines for choosing the image spatial resolution and compression settings predicated on available bandwidth, storage, desired inference time, and/or desired detection range, in practical applications.
ERA-Solver: Error-Robust Adams Solver for Fast Sampling of Diffusion Probabilistic Models
Feb 06, 2023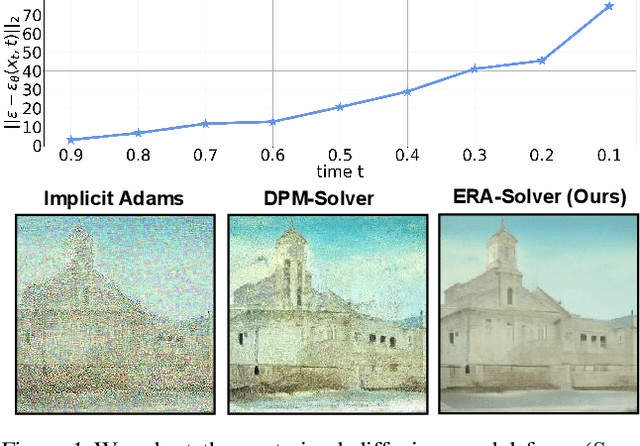

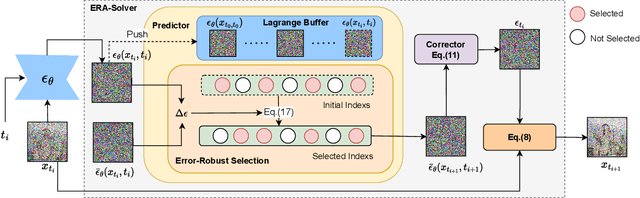
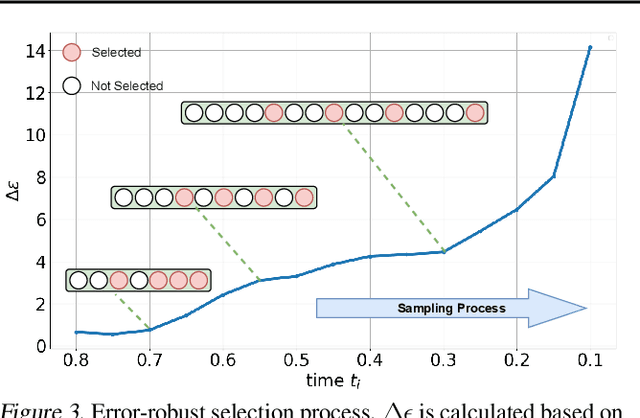
Though denoising diffusion probabilistic models (DDPMs) have achieved remarkable generation results, the low sampling efficiency of DDPMs still limits further applications. Since DDPMs can be formulated as diffusion ordinary differential equations (ODEs), various fast sampling methods can be derived from solving diffusion ODEs. However, we notice that previous sampling methods with fixed analytical form are not robust with the error in the noise estimated from pretrained diffusion models. In this work, we construct an error-robust Adams solver (ERA-Solver), which utilizes the implicit Adams numerical method that consists of a predictor and a corrector. Different from the traditional predictor based on explicit Adams methods, we leverage a Lagrange interpolation function as the predictor, which is further enhanced with an error-robust strategy to adaptively select the Lagrange bases with lower error in the estimated noise. Experiments on Cifar10, LSUN-Church, and LSUN-Bedroom datasets demonstrate that our proposed ERA-Solver achieves 5.14, 9.42, and 9.69 Fenchel Inception Distance (FID) for image generation, with only 10 network evaluations.
Multipath agents for modular multitask ML systems
Feb 06, 2023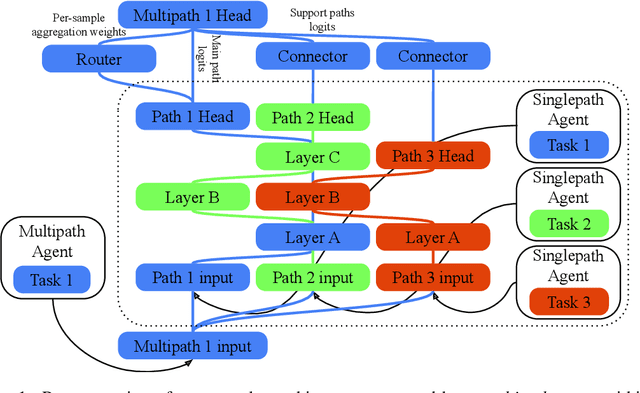
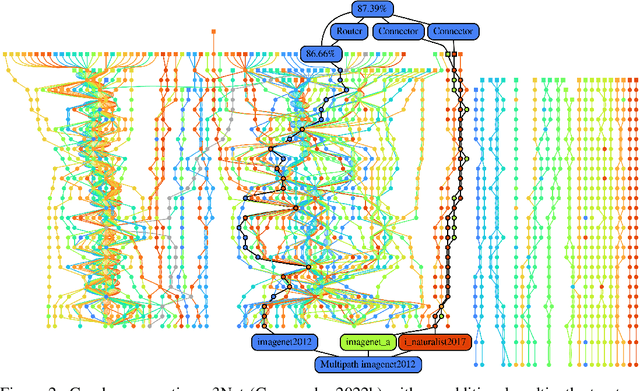
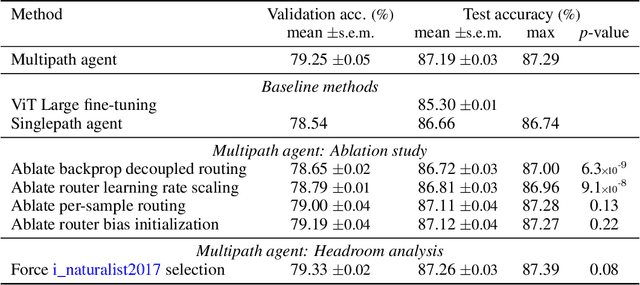
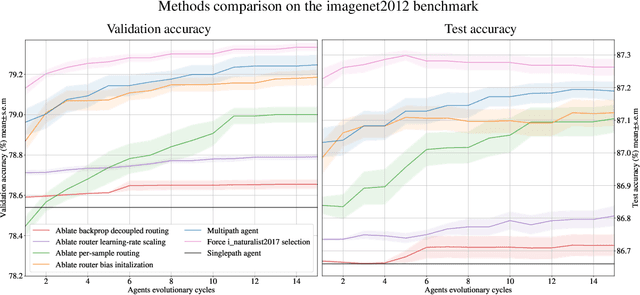
A standard ML model is commonly generated by a single method that specifies aspects such as architecture, initialization, training data and hyperparameters configuration. The presented work introduces a novel methodology allowing to define multiple methods as distinct agents. Agents can collaborate and compete to generate and improve ML models for a given tasks. The proposed methodology is demonstrated with the generation and extension of a dynamic modular multitask ML system solving more than one hundred image classification tasks. Diverse agents can compete to produce the best performing model for a task by reusing the modules introduced to the system by competing agents. The presented work focuses on the study of agents capable of: 1) reusing the modules generated by concurrent agents, 2) activating in parallel multiple modules in a frozen state by connecting them with trainable modules, 3) condition the activation mixture on each data sample by using a trainable router module. We demonstrate that this simple per-sample parallel routing method can boost the quality of the combined solutions by training a fraction of the activated parameters.
Cluster-aware Contrastive Learning for Unsupervised Out-of-distribution Detection
Feb 06, 2023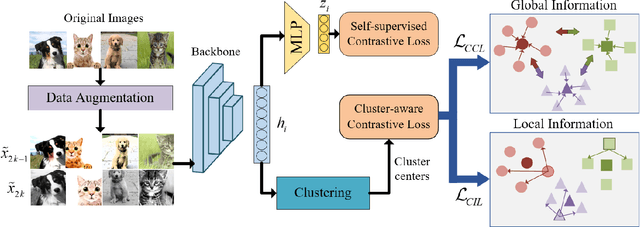
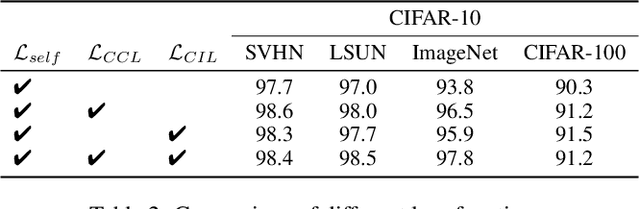
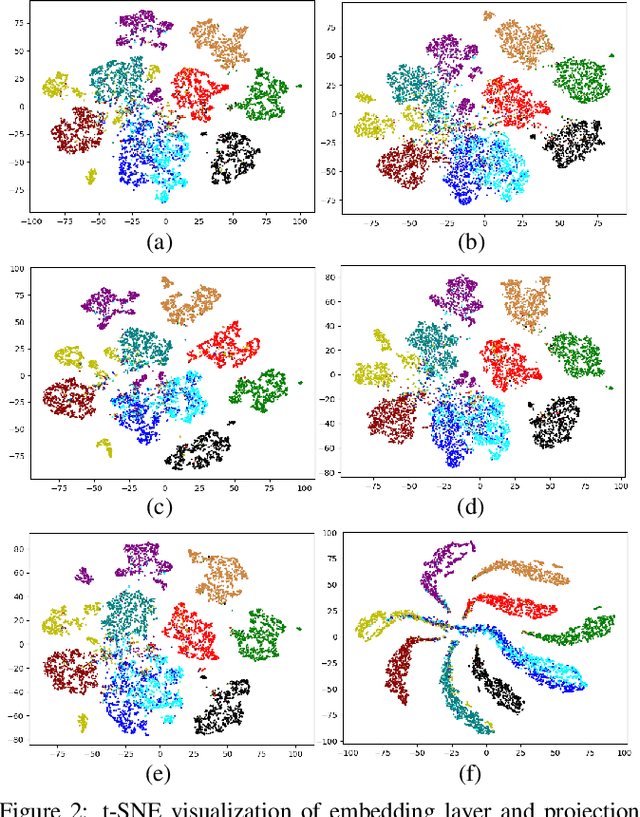
Unsupervised out-of-distribution (OOD) Detection aims to separate the samples falling outside the distribution of training data without label information. Among numerous branches, contrastive learning has shown its excellent capability of learning discriminative representation in OOD detection. However, for its limited vision, merely focusing on instance-level relationship between augmented samples, it lacks attention to the relationship between samples with same semantics. Based on the classic contrastive learning, we propose Cluster-aware Contrastive Learning (CCL) framework for unsupervised OOD detection, which considers both instance-level and semantic-level information. Specifically, we study a cooperation strategy of clustering and contrastive learning to effectively extract the latent semantics and design a cluster-aware contrastive loss function to enhance OOD discriminative ability. The loss function can simultaneously pay attention to the global and local relationships by treating both the cluster centers and the samples belonging to the same cluster as positive samples. We conducted sufficient experiments to verify the effectiveness of our framework and the model achieves significant improvement on various image benchmarks.
Accelerated Dynamic Magnetic Resonance Imaging from Spatial-Subspace Reconstructions (SPARS)
Feb 06, 2023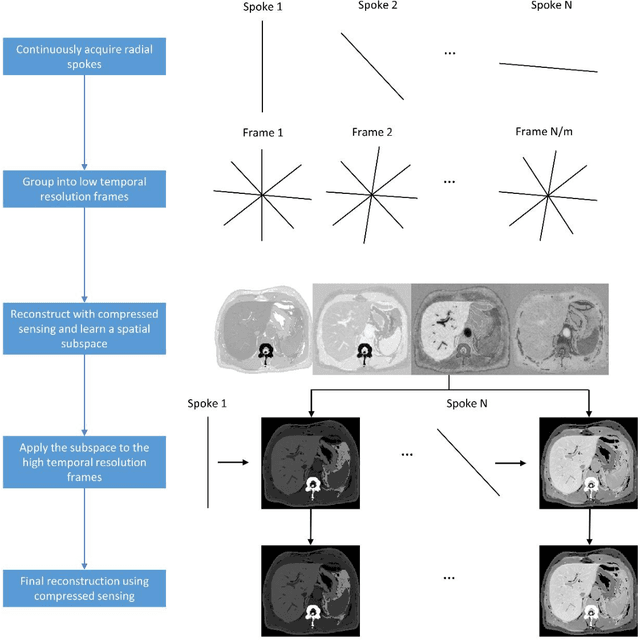
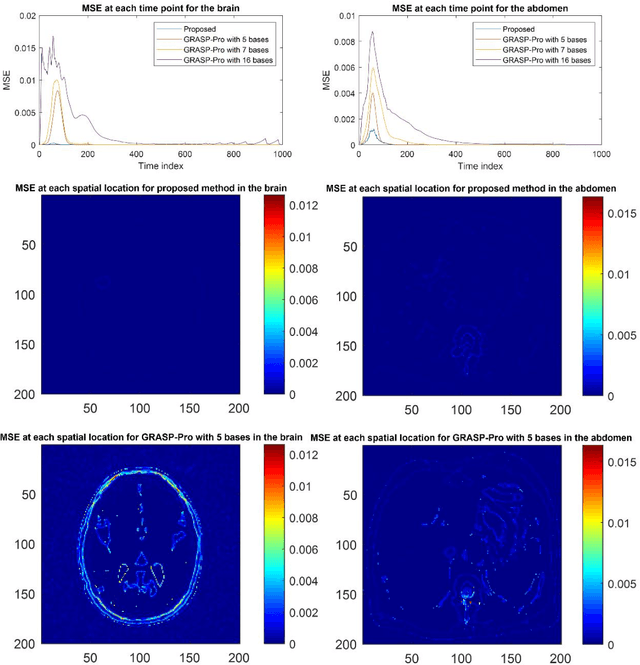
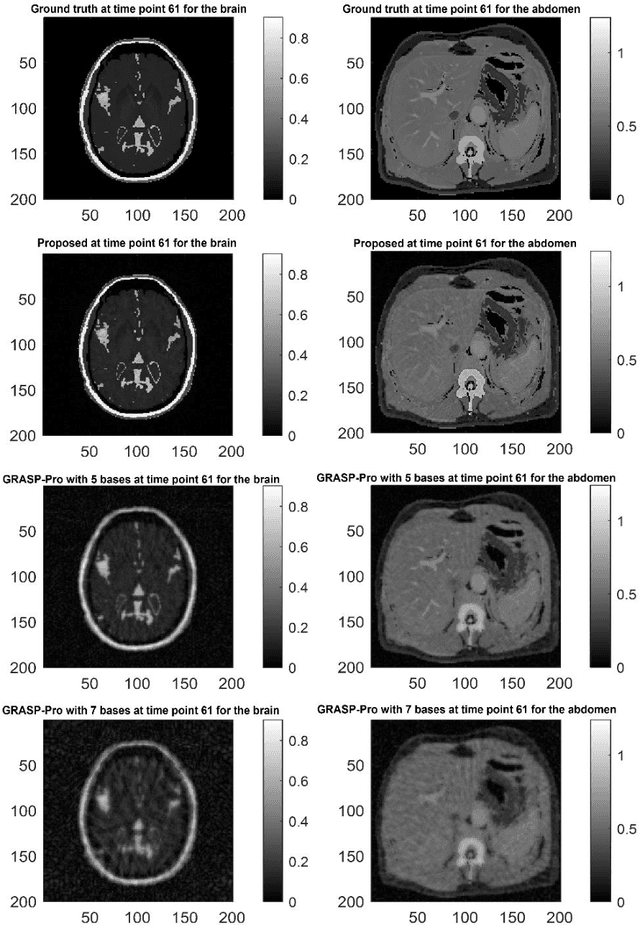
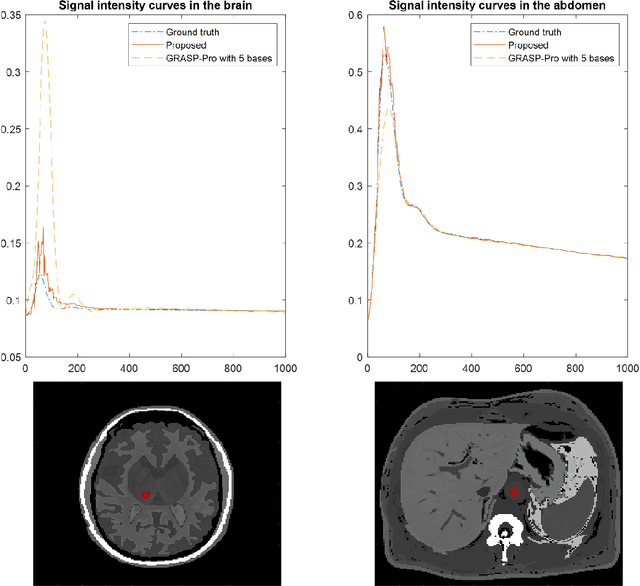
Dynamic contrast-enhanced (DCE) magnetic resonance imaging (MRI) ideally requires a high spatial and high temporal resolution, but hardware limitations prevent acquisitions from simultaneously achieving both. Existing image reconstruction techniques can artificially create spatial resolution at a given temporal resolution by estimating data that is not acquired, but, ultimately, spatial details are sacrificed at very high acceleration rates. The purpose of this paper is to introduce the concept of spatial subspace reconstructions (SPARS) and demonstrate its ability to reconstruct high spatial resolution dynamic images from as few as one acquired radial spoke per dynamic frame. Briefly, a low-temporal-high-spatial resolution organization of the acquired raw data is used to estimate a spatial subspace in which the high-temporal-high-spatial ground truth data resides. This subspace is then used to estimate entire images from single k-space spokes. In both simulated and human in-vivo data, the proposed SPARS reconstruction method outperformed standard GRASP and GRASP-Pro reconstruction, providing a shorter reconstruction time and yielding higher accuracy from both a spatial and temporal perspective.