 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the optimal measurement of conversion gain in the presence of dark noise
Jan 20, 2023

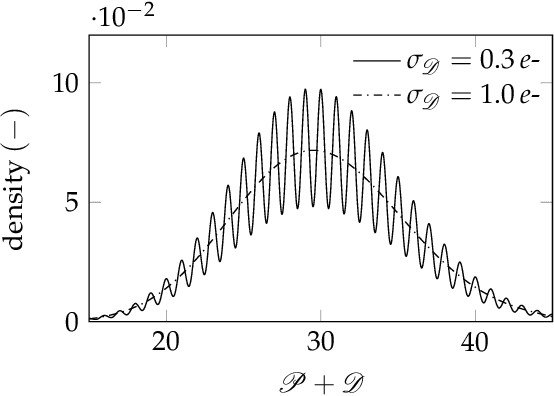
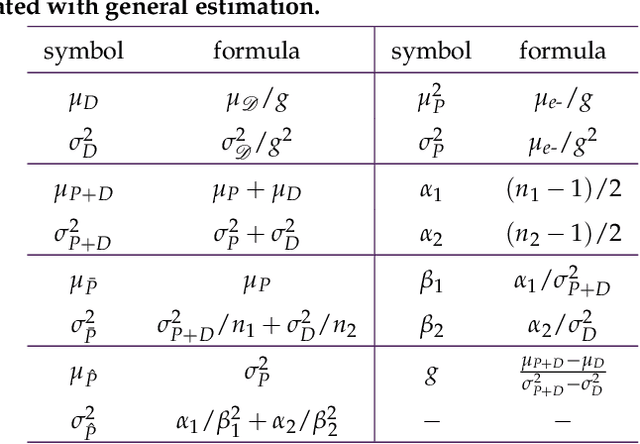
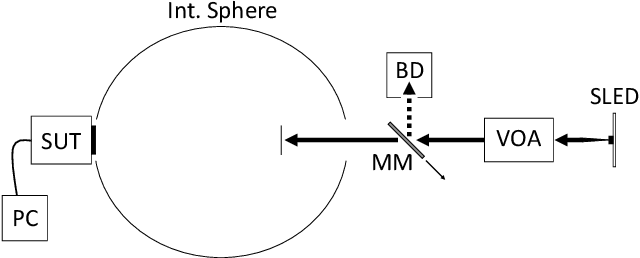
Working from a model of Gaussian pixel noise, we present and unify over twenty-five years of developments in the statistical analysis of the photon transfer conversion gain measurement. We then study a two-sample estimator of the conversion gain that accounts for the general case of non-negligible dark noise. The moments of this estimator are ill-defined (their integral representations diverge) and so we propose a method for assigning pseudomoments, which are shown to agree with actual sample moments under mild conditions. A definition of optimal sample size pairs for this two-sample estimator is proposed and used to find approximate optimal sample size pairs that allow experimenters to achieve a predetermined measurement uncertainty with as little data as possible. The conditions under which these approximations hold are also discussed. Design and control of experiment procedures are developed and used to optimally estimate a per-pixel conversion gain map of a real image sensor. Experimental results show excellent agreement with theoretical predictions and are backed up with Monte Carlo simulation. The per-pixel conversion gain estimates are then applied in a demonstration of per-pixel read noise estimation of the same image sensor. The results of this work open the door to a comprehensive pixel-level adaptation of the photon transfer method.
* 16 pages, 5 figures
Real Image Restoration via Structure-preserving Complementarity Attention
Jul 28, 2022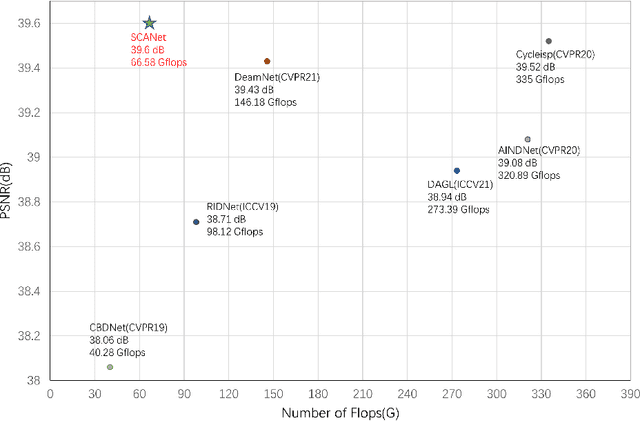
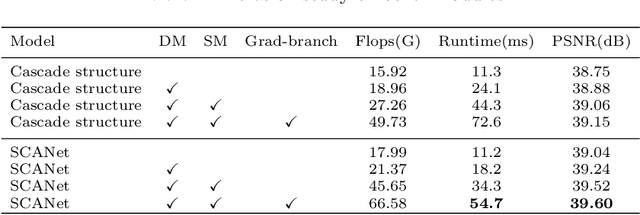
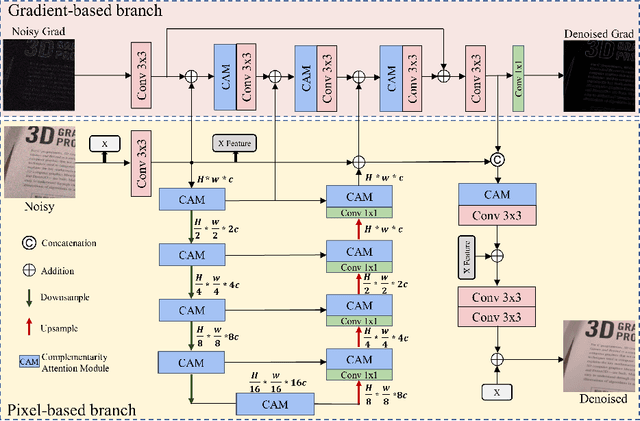

Since convolutional neural networks perform well in learning generalizable image priors from large-scale data, these models have been widely used in image denoising tasks. However, the computational complexity increases dramatically as well on complex model. In this paper, We propose a novel lightweight Complementary Attention Module, which includes a density module and a sparse module, which can cooperatively mine dense and sparse features for feature complementary learning to build an efficient lightweight architecture. Moreover, to reduce the loss of details caused by denoising, this paper constructs a gradient-based structure-preserving branch. We utilize gradient-based branches to obtain additional structural priors for denoising, and make the model pay more attention to image geometric details through gradient loss optimization.Based on the above, we propose an efficiently Unet structured network with dual branch, the visual results show that can effectively preserve the structural details of the original image, we evaluate benchmarks including SIDD and DND, where SCANet achieves state-of-the-art performance in PSNR and SSIM while significantly reducing computational cost.
Rethinking the Reference-based Distinctive Image Captioning
Jul 22, 2022
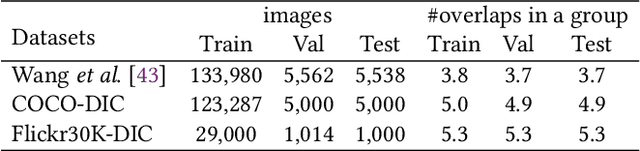
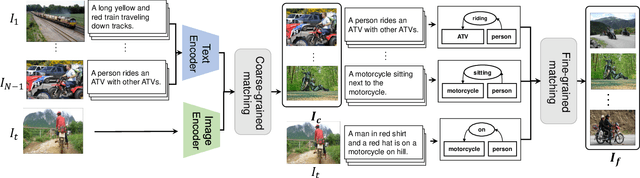
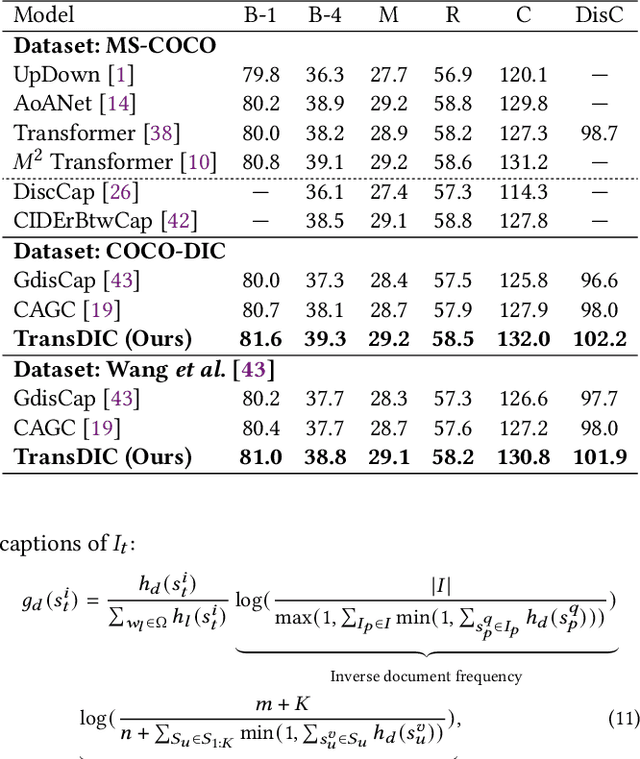
Distinctive Image Captioning (DIC) -- generating distinctive captions that describe the unique details of a target image -- has received considerable attention over the last few years. A recent DIC work proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i.e., reference-based DIC (Ref-DIC). It aims to make the generated captions can tell apart the target and reference images. Unfortunately, reference images used by existing Ref-DIC works are easy to distinguish: these reference images only resemble the target image at scene-level and have few common objects, such that a Ref-DIC model can trivially generate distinctive captions even without considering the reference images. To ensure Ref-DIC models really perceive the unique objects (or attributes) in target images, we first propose two new Ref-DIC benchmarks. Specifically, we design a two-stage matching mechanism, which strictly controls the similarity between the target and reference images at object-/attribute- level (vs. scene-level). Secondly, to generate distinctive captions, we develop a strong Transformer-based Ref-DIC baseline, dubbed as TransDIC. It not only extracts visual features from the target image, but also encodes the differences between objects in the target and reference images. Finally, for more trustworthy benchmarking, we propose a new evaluation metric named DisCIDEr for Ref-DIC, which evaluates both the accuracy and distinctiveness of the generated captions. Experimental results demonstrate that our TransDIC can generate distinctive captions. Besides, it outperforms several state-of-the-art models on the two new benchmarks over different metrics.
Adapting the Hypersphere Loss Function from Anomaly Detection to Anomaly Segmentation
Jan 23, 2023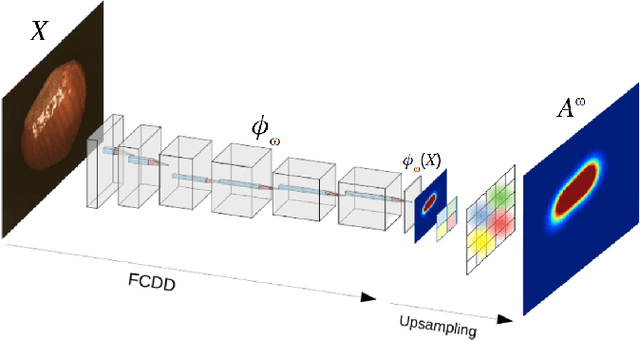


We propose an incremental improvement to Fully Convolutional Data Description (FCDD), an adaptation of the one-class classification approach from anomaly detection to image anomaly segmentation (a.k.a. anomaly localization). We analyze its original loss function and propose a substitute that better resembles its predecessor, the Hypersphere Classifier (HSC). Both are compared on the MVTec Anomaly Detection Dataset (MVTec-AD) -- training images are flawless objects/textures and the goal is to segment unseen defects -- showing that consistent improvement is achieved by better designing the pixel-wise supervision.
G-CEALS: Gaussian Cluster Embedding in Autoencoder Latent Space for Tabular Data Representation
Jan 05, 2023
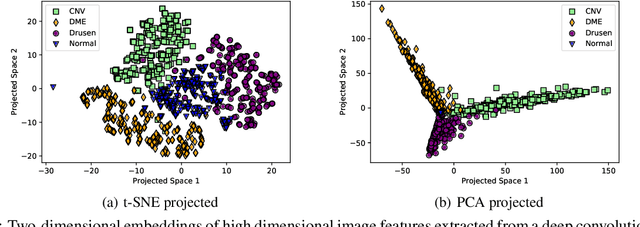
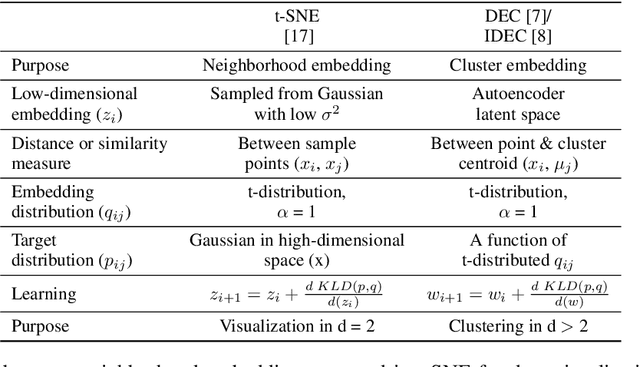
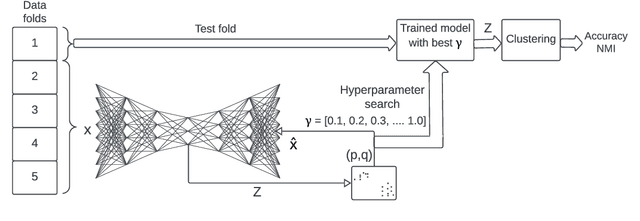
The latent space of autoencoders has been improved for clustering image data by jointly learning a t-distributed embedding with a clustering algorithm inspired by the neighborhood embedding concept proposed for data visualization. However, multivariate tabular data pose different challenges in representation learning than image data, where traditional machine learning is often superior to deep tabular data learning. In this paper, we address the challenges of learning tabular data in contrast to image data and present a novel Gaussian Cluster Embedding in Autoencoder Latent Space (G-CEALS) algorithm by replacing t-distributions with multivariate Gaussian clusters. Unlike current methods, the proposed approach independently defines the Gaussian embedding and the target cluster distribution to accommodate any clustering algorithm in representation learning. A trained G-CEALS model extracts a quality embedding for unseen test data. Based on the embedding clustering accuracy, the average rank of the proposed G-CEALS method is 1.4 (0.7), which is superior to all eight baseline clustering and cluster embedding methods on seven tabular data sets. This paper shows one of the first algorithms to jointly learn embedding and clustering to improve multivariate tabular data representation in downstream clustering.
Combining Metric Learning and Attention Heads For Accurate and Efficient Multilabel Image Classification
Sep 14, 2022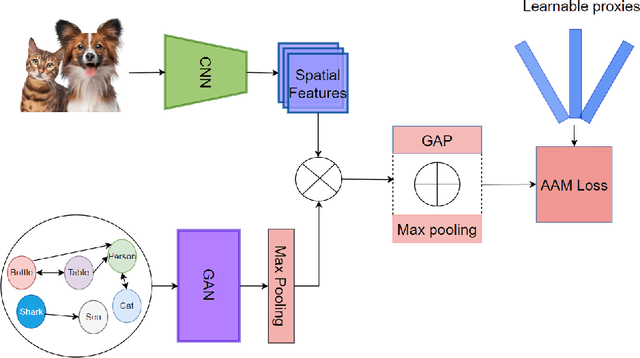
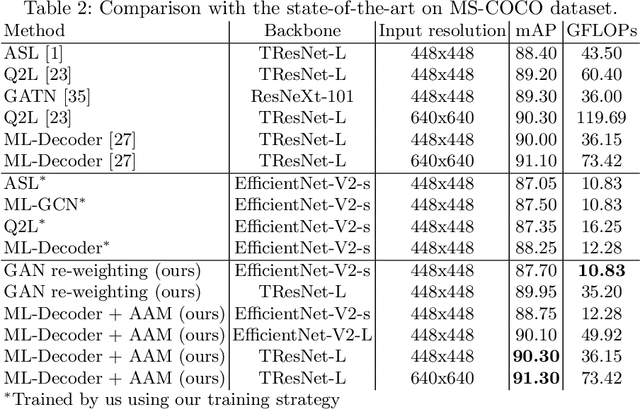
Multi-label image classification allows predicting a set of labels from a given image. Unlike multiclass classification, where only one label per image is assigned, such setup is applicable for a broader range of applications. In this work we revisit two popular approaches to multilabel classification: transformer-based heads and labels relations information graph processing branches. Although transformer-based heads are considered to achieve better results than graph-based branches, we argue that with the proper training strategy graph-based methods can demonstrate just a small accuracy drop, while spending less computational resources on inference. In our training strategy, instead of Asymmetric Loss (ASL), which is the de-facto standard for multilabel classification, we introduce its modification acting in the angle space. It implicitly learns a proxy feature vector on the unit hypersphere for each class, providing a better discrimination ability, than binary cross entropy loss does on unnormalized features. With the proposed loss and training strategy, we obtain SOTA results among single modality methods on widespread multilabel classification benchmarks such as MS-COCO, PASCAL-VOC, NUS-Wide and Visual Genome 500. Source code of our method is available as a part of the OpenVINO Training Extensions https://github.com/openvinotoolkit/deep-object-reid/tree/multilabel
MixSKD: Self-Knowledge Distillation from Mixup for Image Recognition
Aug 11, 2022
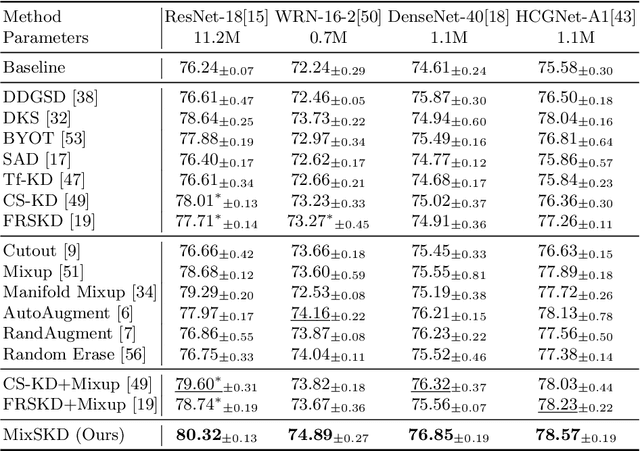
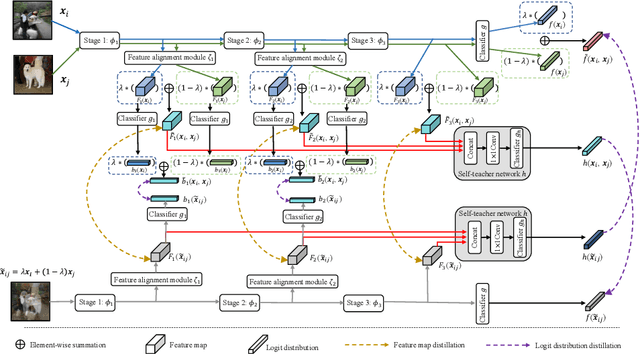
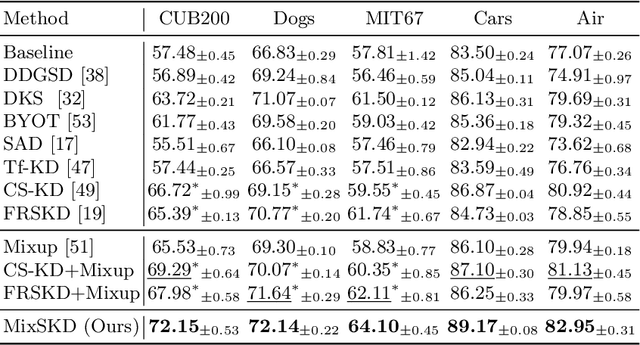
Unlike the conventional Knowledge Distillation (KD), Self-KD allows a network to learn knowledge from itself without any guidance from extra networks. This paper proposes to perform Self-KD from image Mixture (MixSKD), which integrates these two techniques into a unified framework. MixSKD mutually distills feature maps and probability distributions between the random pair of original images and their mixup images in a meaningful way. Therefore, it guides the network to learn cross-image knowledge by modelling supervisory signals from mixup images. Moreover, we construct a self-teacher network by aggregating multi-stage feature maps for providing soft labels to supervise the backbone classifier, further improving the efficacy of self-boosting. Experiments on image classification and transfer learning to object detection and semantic segmentation demonstrate that MixSKD outperforms other state-of-the-art Self-KD and data augmentation methods. The code is available at https://github.com/winycg/Self-KD-Lib.
Generative Deformable Radiance Fields for Disentangled Image Synthesis of Topology-Varying Objects
Sep 09, 2022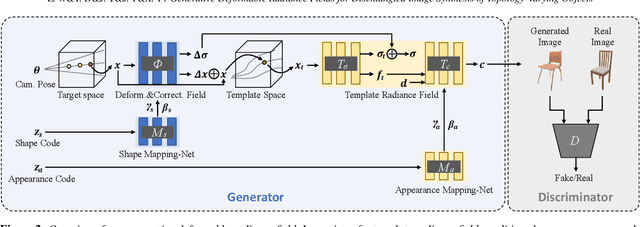
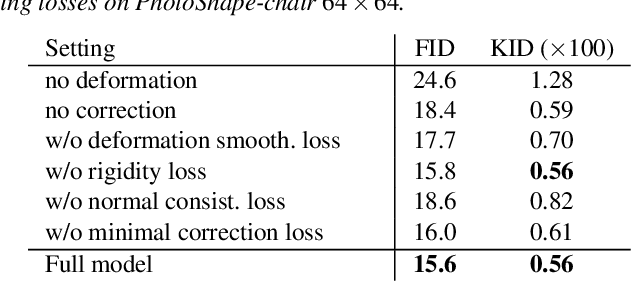
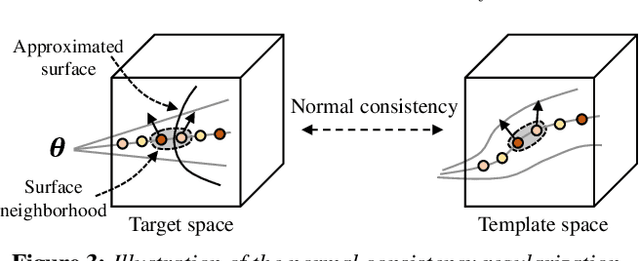
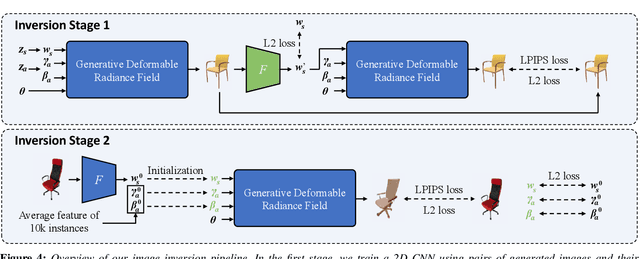
3D-aware generative models have demonstrated their superb performance to generate 3D neural radiance fields (NeRF) from a collection of monocular 2D images even for topology-varying object categories. However, these methods still lack the capability to separately control the shape and appearance of the objects in the generated radiance fields. In this paper, we propose a generative model for synthesizing radiance fields of topology-varying objects with disentangled shape and appearance variations. Our method generates deformable radiance fields, which builds the dense correspondence between the density fields of the objects and encodes their appearances in a shared template field. Our disentanglement is achieved in an unsupervised manner without introducing extra labels to previous 3D-aware GAN training. We also develop an effective image inversion scheme for reconstructing the radiance field of an object in a real monocular image and manipulating its shape and appearance. Experiments show that our method can successfully learn the generative model from unstructured monocular images and well disentangle the shape and appearance for objects (e.g., chairs) with large topological variance. The model trained on synthetic data can faithfully reconstruct the real object in a given single image and achieve high-quality texture and shape editing results.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
Feb 18, 2023
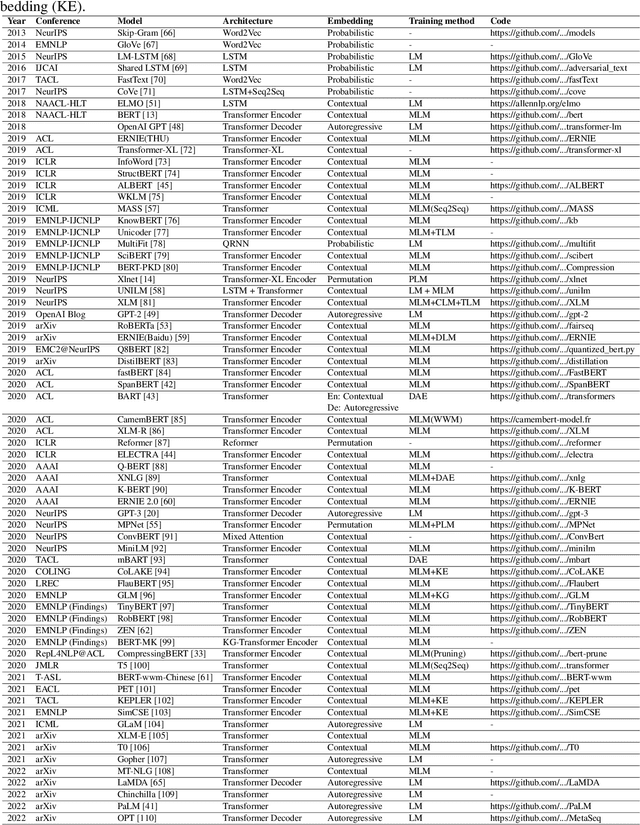
The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications. The idea of pretraining behind PFMs plays an important role in the application of large models. Different from previous methods that apply convolution and recurrent modules for feature extractions, the generative pre-training (GPT) method applies Transformer as the feature extractor and is trained on large datasets with an autoregressive paradigm. Similarly, the BERT apples transformers to train on large datasets as a contextual language model. Recently, the ChatGPT shows promising success on large language models, which applies an autoregressive language model with zero shot or few show prompting. With the extraordinary success of PFMs, AI has made waves in a variety of fields over the past few years. Considerable methods, datasets, and evaluation metrics have been proposed in the literature, the need is raising for an updated survey. This study provides a comprehensive review of recent research advancements, current and future challenges, and opportunities for PFMs in text, image, graph, as well as other data modalities. We first review the basic components and existing pretraining in natural language processing, computer vision, and graph learning. We then discuss other advanced PFMs for other data modalities and unified PFMs considering the data quality and quantity. Besides, we discuss relevant research about the fundamentals of the PFM, including model efficiency and compression, security, and privacy. Finally, we lay out key implications, future research directions, challenges, and open problems.
A General Framework for Partial to Full Image Registration
Jul 13, 2022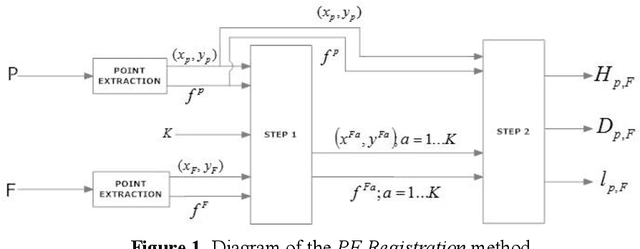
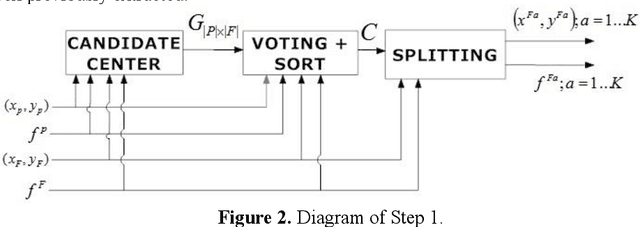
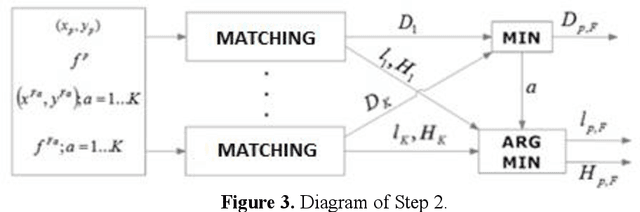

Image registration is a research field in which images must be compared and aligned independently of the point of view or camera characteristics. In some applications (such as forensic biometrics, satellite photography or outdoor scene identification) classical image registration systems fail due to one of the images compared represents a tiny piece of the other image. For instance, in forensics palmprint recognition, it is usual to find only a small piece of the palmprint, but in the database, the whole palmprint has been enrolled. The main reason of the poor behaviour of classical image registration methods is the gap between the amounts of salient points of both images, which is related to the number of points to be considered as outliers. Usually, the difficulty of finding a good match increases when the image that represents the tiny part of the scene has been drastically rotated. Again, in the case of palmprint forensics, it is difficult to decide a priori the orientation of the found tiny palmprint image. We present a rotation invariant registration method that explicitly considers that the image to be matched is a small piece of a larger image. We have experimentally validated our method in two different scenarios; palmprint identification and outdoor image registration.