 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep leakage from gradients
Dec 15, 2022
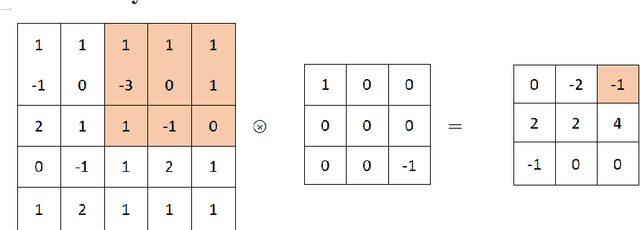
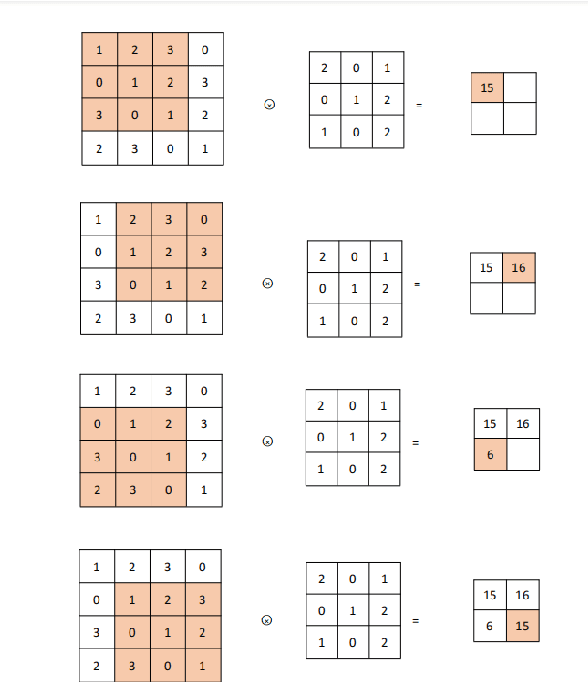

With the development of artificial intelligence technology, Federated Learning (FL) model has been widely used in many industries for its high efficiency and confidentiality. Some researchers have explored its confidentiality and designed some algorithms to attack training data sets, but these algorithms all have their own limitations. Therefore, most people still believe that local machine learning gradient information is safe and reliable. In this paper, an algorithm based on gradient features is designed to attack the federated learning model in order to attract more attention to the security of federated learning systems. In federated learning system, gradient contains little information compared with the original training data set, but this project intends to restore the original training image data through gradient information. Convolutional Neural Network (CNN) has excellent performance in image processing. Therefore, the federated learning model of this project is equipped with Convolutional Neural Network structure, and the model is trained by using image data sets. The algorithm calculates the virtual gradient by generating virtual image labels. Then the virtual gradient is matched with the real gradient to restore the original image. This attack algorithm is written in Python language, uses cat and dog classification Kaggle data sets, and gradually extends from the full connection layer to the convolution layer, thus improving the universality. At present, the average squared error between the data recovered by this algorithm and the original image information is approximately 5, and the vast majority of images can be completely restored according to the gradient information given, indicating that the gradient of federated learning system is not absolutely safe and reliable.
Unsupervised Domain Adaptive Fundus Image Segmentation with Few Labeled Source Data
Oct 10, 2022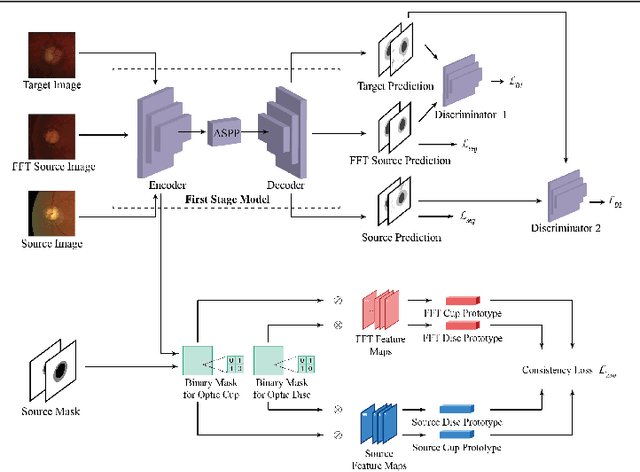
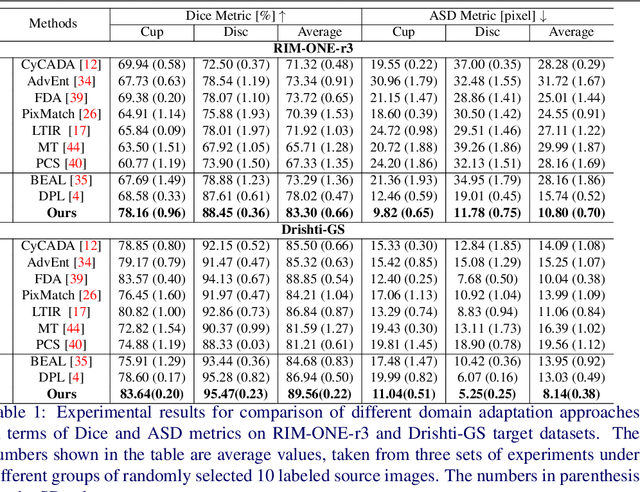
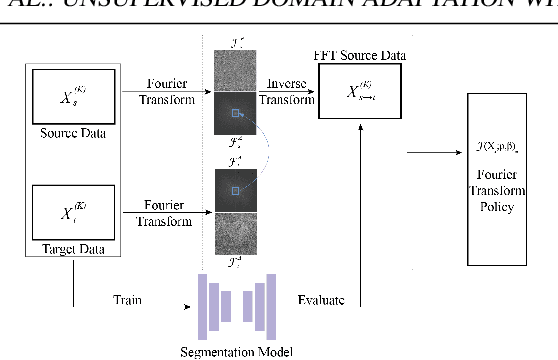
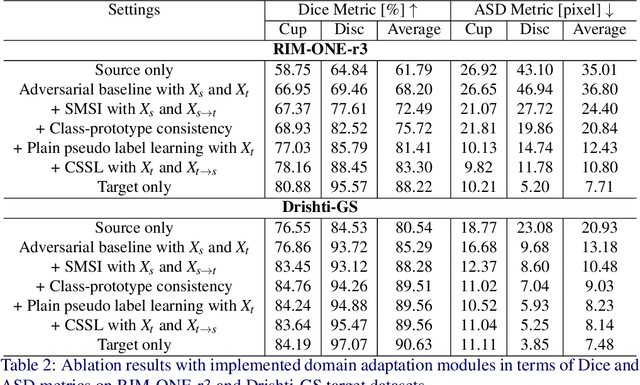
Deep learning-based segmentation methods have been widely employed for automatic glaucoma diagnosis and prognosis. In practice, fundus images obtained by different fundus cameras vary significantly in terms of illumination and intensity. Although recent unsupervised domain adaptation (UDA) methods enhance the models' generalization ability on the unlabeled target fundus datasets, they always require sufficient labeled data from the source domain, bringing auxiliary data acquisition and annotation costs. To further facilitate the data efficiency of the cross-domain segmentation methods on the fundus images, we explore UDA optic disc and cup segmentation problems using few labeled source data in this work. We first design a Searching-based Multi-style Invariant Mechanism to diversify the source data style as well as increase the data amount. Next, a prototype consistency mechanism on the foreground objects is proposed to facilitate the feature alignment for each kind of tissue under different image styles. Moreover, a cross-style self-supervised learning stage is further designed to improve the segmentation performance on the target images. Our method has outperformed several state-of-the-art UDA segmentation methods under the UDA fundus segmentation with few labeled source data.
A$^2$-UAV: Application-Aware Content and Network Optimization of Edge-Assisted UAV Systems
Jan 16, 2023
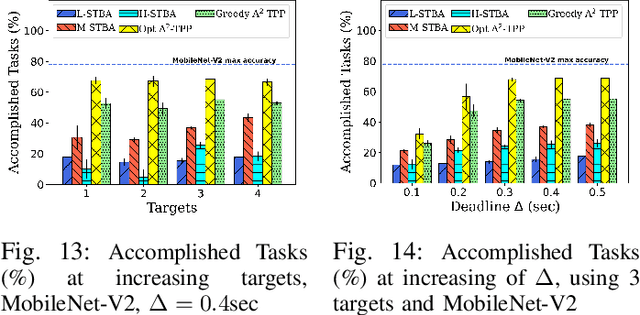
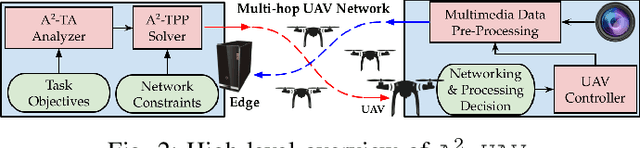
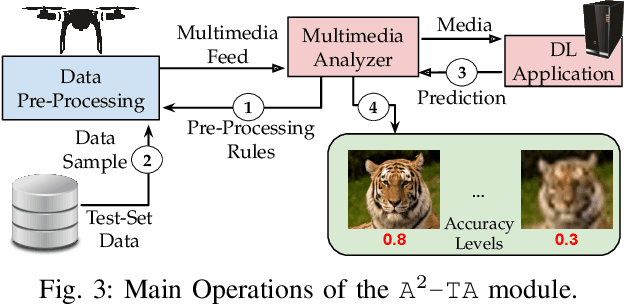
To perform advanced surveillance, Unmanned Aerial Vehicles (UAVs) require the execution of edge-assisted computer vision (CV) tasks. In multi-hop UAV networks, the successful transmission of these tasks to the edge is severely challenged due to severe bandwidth constraints. For this reason, we propose a novel A$^2$-UAV framework to optimize the number of correctly executed tasks at the edge. In stark contrast with existing art, we take an application-aware approach and formulate a novel pplication-Aware Task Planning Problem (A$^2$-TPP) that takes into account (i) the relationship between deep neural network (DNN) accuracy and image compression for the classes of interest based on the available dataset, (ii) the target positions, (iii) the current energy/position of the UAVs to optimize routing, data pre-processing and target assignment for each UAV. We demonstrate A$^2$-TPP is NP-Hard and propose a polynomial-time algorithm to solve it efficiently. We extensively evaluate A$^2$-UAV through real-world experiments with a testbed composed by four DJI Mavic Air 2 UAVs. We consider state-of-the-art image classification tasks with four different DNN models (i.e., DenseNet, ResNet152, ResNet50 and MobileNet-V2) and object detection tasks using YoloV4 trained on the ImageNet dataset. Results show that A$^2$-UAV attains on average around 38% more accomplished tasks than the state-of-the-art, with 400% more accomplished tasks when the number of targets increases significantly. To allow full reproducibility, we pledge to share datasets and code with the research community.
Seeing a Rose in Five Thousand Ways
Dec 09, 2022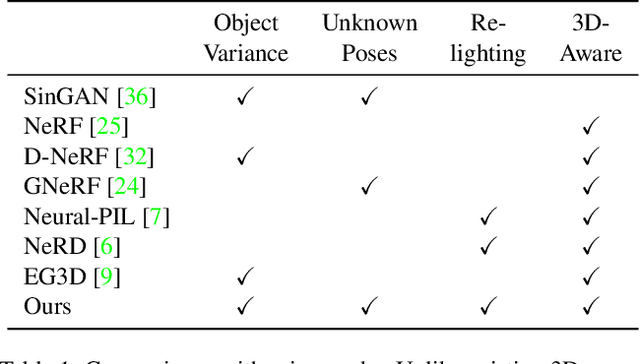
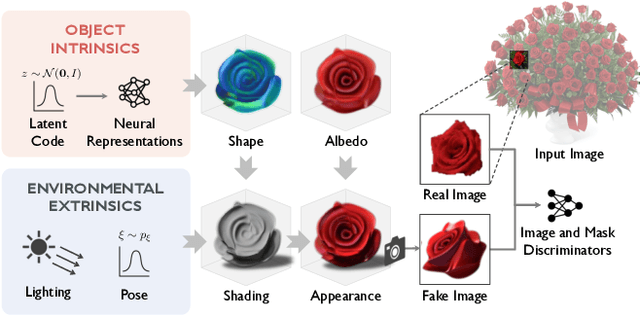

What is a rose, visually? A rose comprises its intrinsics, including the distribution of geometry, texture, and material specific to its object category. With knowledge of these intrinsic properties, we may render roses of different sizes and shapes, in different poses, and under different lighting conditions. In this work, we build a generative model that learns to capture such object intrinsics from a single image, such as a photo of a bouquet. Such an image includes multiple instances of an object type. These instances all share the same intrinsics, but appear different due to a combination of variance within these intrinsics and differences in extrinsic factors, such as pose and illumination. Experiments show that our model successfully learns object intrinsics (distribution of geometry, texture, and material) for a wide range of objects, each from a single Internet image. Our method achieves superior results on multiple downstream tasks, including intrinsic image decomposition, shape and image generation, view synthesis, and relighting.
CADA-GAN: Context-Aware GAN with Data Augmentation
Jan 21, 2023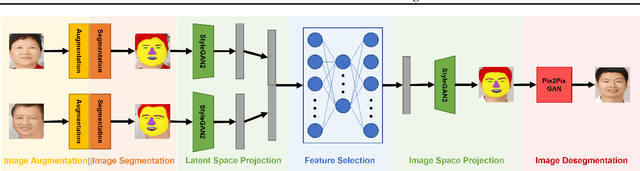


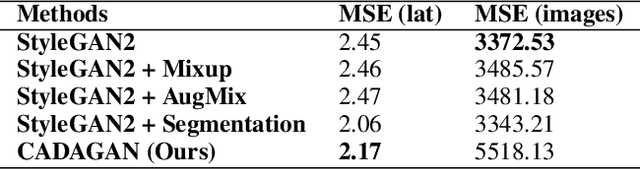
Current child face generators are restricted by the limited size of the available datasets. In addition, feature selection can prove to be a significant challenge, especially due to the large amount of features that need to be trained for. To manage these problems, we proposed CADA-GAN, a \textbf{C}ontext-\textbf{A}ware GAN that allows optimal feature extraction, with added robustness from additional \textbf{D}ata \textbf{A}ugmentation. CADA-GAN is adapted from the popular StyleGAN2-Ada model, with attention on augmentation and segmentation of the parent images. The model has the lowest \textit{Mean Squared Error Loss} (MSEloss) on latent feature representations and the generated child image is robust compared with the one that generated from baseline models.
MOMA:Distill from Self-Supervised Teachers
Feb 04, 2023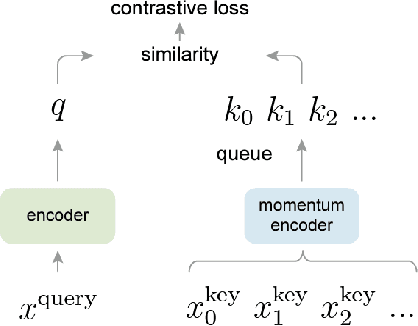
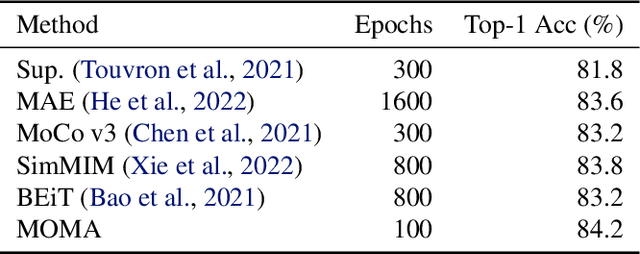
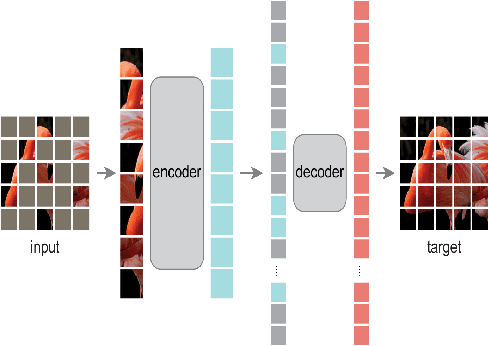

Contrastive Learning and Masked Image Modelling have demonstrated exceptional performance on self-supervised representation learning, where Momentum Contrast (i.e., MoCo) and Masked AutoEncoder (i.e., MAE) are the state-of-the-art, respectively. In this work, we propose MOMA to distill from pre-trained MoCo and MAE in a self-supervised manner to collaborate the knowledge from both paradigms. We introduce three different mechanisms of knowledge transfer in the propsoed MOMA framework. : (1) Distill pre-trained MoCo to MAE. (2) Distill pre-trained MAE to MoCo (3) Distill pre-trained MoCo and MAE to a random initialized student. During the distillation, the teacher and the student are fed with original inputs and masked inputs, respectively. The learning is enabled by aligning the normalized representations from the teacher and the projected representations from the student. This simple design leads to efficient computation with extremely high mask ratio and dramatically reduced training epochs, and does not require extra considerations on the distillation target. The experiments show MOMA delivers compact student models with comparable performance to existing state-of-the-art methods, combining the power of both self-supervised learning paradigms. It presents competitive results against different benchmarks in computer vision. We hope our method provides an insight on transferring and adapting the knowledge from large-scale pre-trained models in a computationally efficient way.
Rethinking Soft Label in Label Distribution Learning Perspective
Jan 31, 2023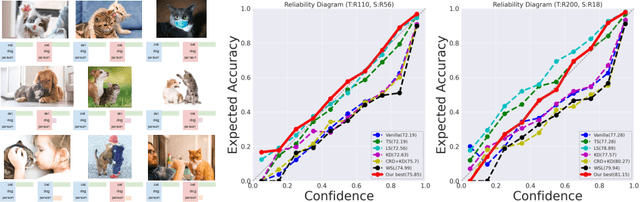
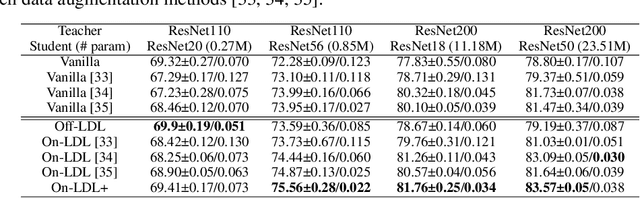
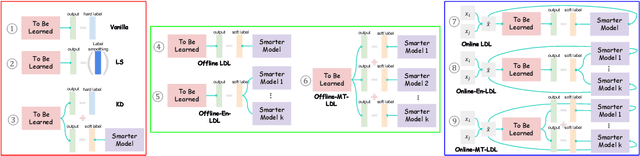
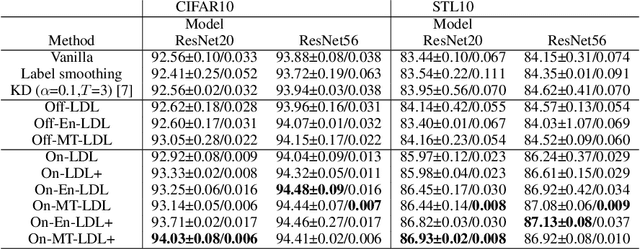
The primary goal of training in early convolutional neural networks (CNN) is the higher generalization performance of the model. However, as the expected calibration error (ECE), which quantifies the explanatory power of model inference, was recently introduced, research on training models that can be explained is in progress. We hypothesized that a gap in supervision criteria during training and inference leads to overconfidence, and investigated that performing label distribution learning (LDL) would enhance the model calibration in CNN training. To verify this assumption, we used a simple LDL setting with recent data augmentation techniques. Based on a series of experiments, the following results are obtained: 1) State-of-the-art KD methods significantly impede model calibration. 2) Training using LDL with recent data augmentation can have excellent effects on model calibration and even in generalization performance. 3) Online LDL brings additional improvements in model calibration and accuracy with long training, especially in large-size models. Using the proposed approach, we simultaneously achieved a lower ECE and higher generalization performance for the image classification datasets CIFAR10, 100, STL10, and ImageNet. We performed several visualizations and analyses and witnessed several interesting behaviors in CNN training with the LDL.
The Biased Artist: Exploiting Cultural Biases via Homoglyphs in Text-Guided Image Generation Models
Sep 19, 2022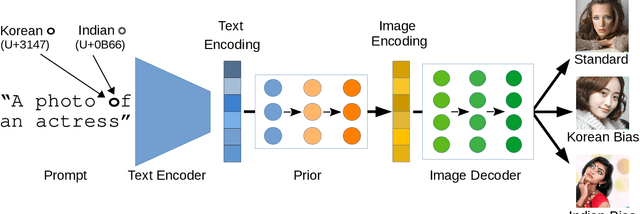



Text-guided image generation models, such as DALL-E 2 and Stable Diffusion, have recently received much attention from academia and the general public. Provided with textual descriptions, these models are capable of generating high-quality images depicting various concepts and styles. However, such models are trained on large amounts of public data and implicitly learn relationships from their training data that are not immediately apparent. We demonstrate that common multimodal models implicitly learned cultural biases that can be triggered and injected into the generated images by simply replacing single characters in the textual description with visually similar non-Latin characters. These so-called homoglyph replacements enable malicious users or service providers to induce biases into the generated images and even render the whole generation process useless. We practically illustrate such attacks on DALL-E 2 and Stable Diffusion as text-guided image generation models and further show that CLIP also behaves similarly. Our results further indicate that text encoders trained on multilingual data provide a way to mitigate the effects of homoglyph replacements.
CLIPood: Generalizing CLIP to Out-of-Distributions
Feb 02, 2023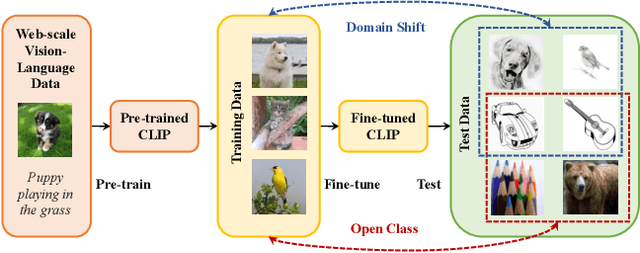
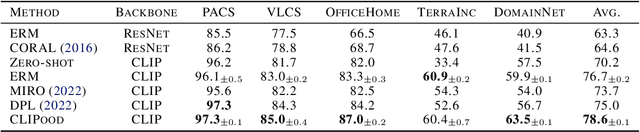
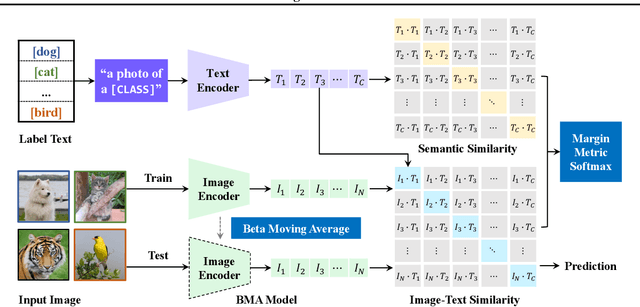

Out-of-distribution (OOD) generalization, where the model needs to handle distribution shifts from training, is a major challenge of machine learning. Recently, contrastive language-image pre-training (CLIP) models have shown impressive zero-shot ability, revealing a promising path toward OOD generalization. However, to boost upon zero-shot performance, further adaptation of CLIP on downstream tasks is indispensable but undesirably degrades OOD generalization ability. In this paper, we aim at generalizing CLIP to out-of-distribution test data on downstream tasks. Beyond the two canonical OOD situations, domain shift and open class, we tackle a more general but difficult in-the-wild setting where both OOD situations may occur on the unseen test data. We propose CLIPood, a simple fine-tuning method that can adapt CLIP models to all OOD situations. To exploit semantic relations between classes from the text modality, CLIPood introduces a new training objective, margin metric softmax (MMS), with class adaptive margins for fine-tuning. Moreover, to incorporate both the pre-trained zero-shot model and the fine-tuned task-adaptive model, CLIPood proposes a new Beta moving average (BMA) to maintain a temporal ensemble according to Beta distribution. Experiments on diverse datasets with different OOD scenarios show that CLIPood consistently outperforms existing generalization techniques.
Multi-scale Feature Alignment for Continual Learning of Unlabeled Domains
Feb 02, 2023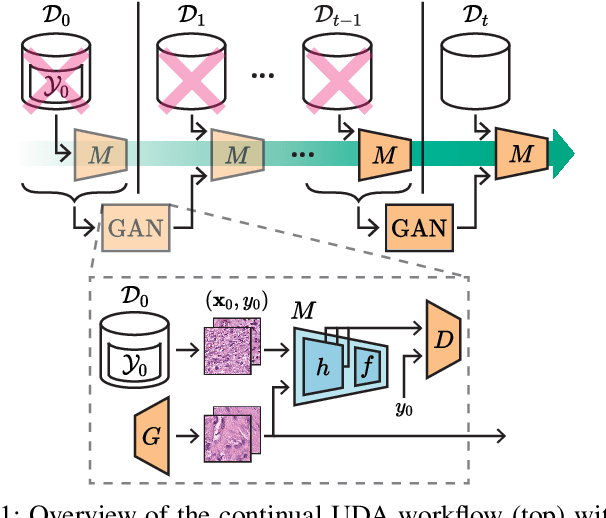
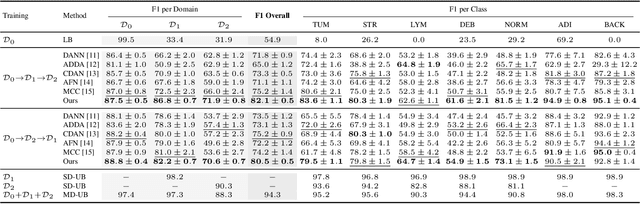
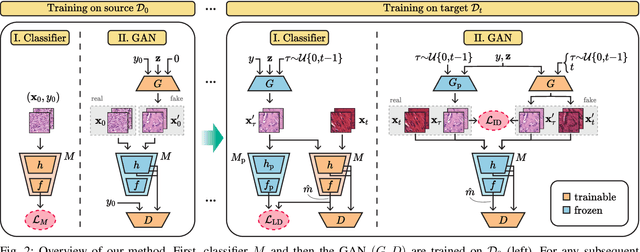

Methods for unsupervised domain adaptation (UDA) help to improve the performance of deep neural networks on unseen domains without any labeled data. Especially in medical disciplines such as histopathology, this is crucial since large datasets with detailed annotations are scarce. While the majority of existing UDA methods focus on the adaptation from a labeled source to a single unlabeled target domain, many real-world applications with a long life cycle involve more than one target domain. Thus, the ability to sequentially adapt to multiple target domains becomes essential. In settings where the data from previously seen domains cannot be stored, e.g., due to data protection regulations, the above becomes a challenging continual learning problem. To this end, we propose to use generative feature-driven image replay in conjunction with a dual-purpose discriminator that not only enables the generation of images with realistic features for replay, but also promotes feature alignment during domain adaptation. We evaluate our approach extensively on a sequence of three histopathological datasets for tissue-type classification, achieving state-of-the-art results. We present detailed ablation experiments studying our proposed method components and demonstrate a possible use-case of our continual UDA method for an unsupervised patch-based segmentation task given high-resolution tissue images.