 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prompt-to-Prompt Image Editing with Cross Attention Control
Aug 02, 2022


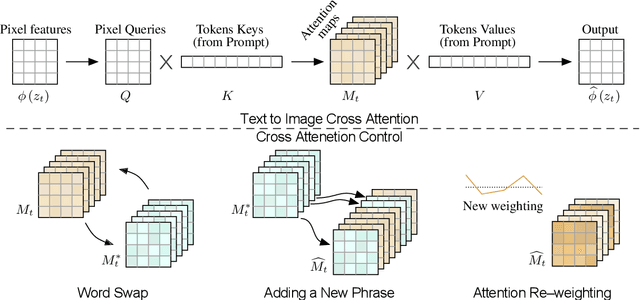
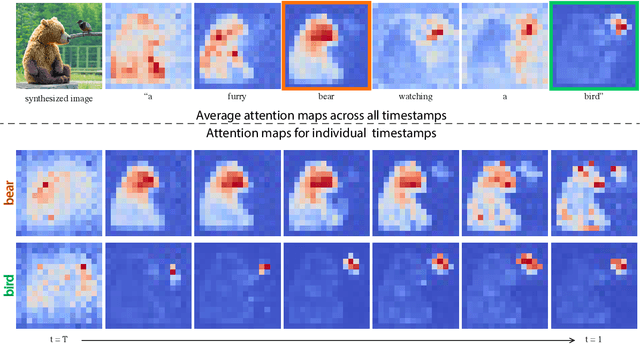
Recent large-scale text-driven synthesis models have attracted much attention thanks to their remarkable capabilities of generating highly diverse images that follow given text prompts. Such text-based synthesis methods are particularly appealing to humans who are used to verbally describe their intent. Therefore, it is only natural to extend the text-driven image synthesis to text-driven image editing. Editing is challenging for these generative models, since an innate property of an editing technique is to preserve most of the original image, while in the text-based models, even a small modification of the text prompt often leads to a completely different outcome. State-of-the-art methods mitigate this by requiring the users to provide a spatial mask to localize the edit, hence, ignoring the original structure and content within the masked region. In this paper, we pursue an intuitive prompt-to-prompt editing framework, where the edits are controlled by text only. To this end, we analyze a text-conditioned model in depth and observe that the cross-attention layers are the key to controlling the relation between the spatial layout of the image to each word in the prompt. With this observation, we present several applications which monitor the image synthesis by editing the textual prompt only. This includes localized editing by replacing a word, global editing by adding a specification, and even delicately controlling the extent to which a word is reflected in the image. We present our results over diverse images and prompts, demonstrating high-quality synthesis and fidelity to the edited prompts.
Linking data separation, visual separation, and classifier performance using pseudo-labeling by contrastive learning
Feb 06, 2023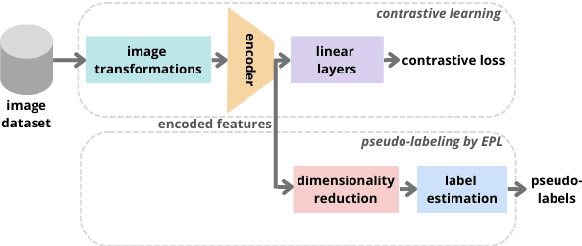


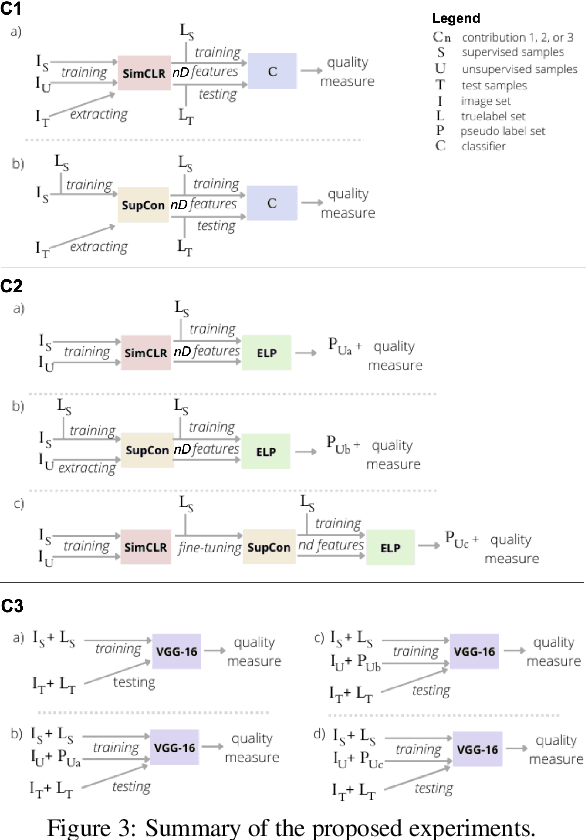
Lacking supervised data is an issue while training deep neural networks (DNNs), mainly when considering medical and biological data where supervision is expensive. Recently, Embedded Pseudo-Labeling (EPL) addressed this problem by using a non-linear projection (t-SNE) from a feature space of the DNN to a 2D space, followed by semi-supervised label propagation using a connectivity-based method (OPFSemi). We argue that the performance of the final classifier depends on the data separation present in the latent space and visual separation present in the projection. We address this by first proposing to use contrastive learning to produce the latent space for EPL by two methods (SimCLR and SupCon) and by their combination, and secondly by showing, via an extensive set of experiments, the aforementioned correlations between data separation, visual separation, and classifier performance. We demonstrate our results by the classification of five real-world challenging image datasets of human intestinal parasites with only 1% supervised samples.
Fine-Grained Action Detection with RGB and Pose Information using Two Stream Convolutional Networks
Feb 06, 2023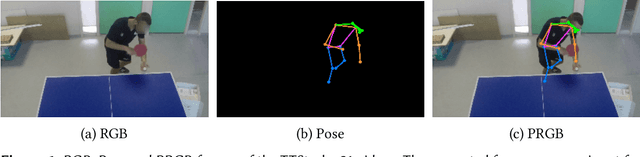
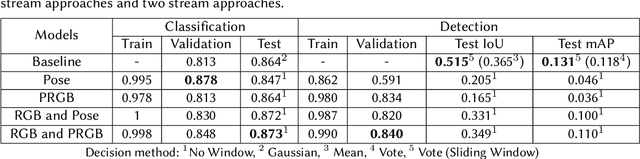
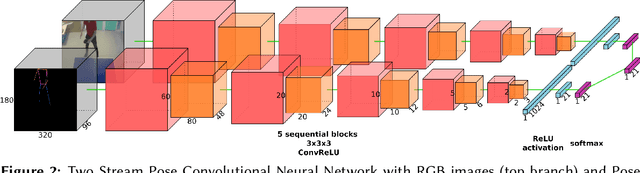
As participants of the MediaEval 2022 Sport Task, we propose a two-stream network approach for the classification and detection of table tennis strokes. Each stream is a succession of 3D Convolutional Neural Network (CNN) blocks using attention mechanisms. Each stream processes different 4D inputs. Our method utilizes raw RGB data and pose information computed from MMPose toolbox. The pose information is treated as an image by applying the pose either on a black background or on the original RGB frame it has been computed from. Best performance is obtained by feeding raw RGB data to one stream, Pose + RGB (PRGB) information to the other stream and applying late fusion on the features. The approaches were evaluated on the provided TTStroke-21 data sets. We can report an improvement in stroke classification, reaching 87.3% of accuracy, while the detection does not outperform the baseline but still reaches an IoU of 0.349 and mAP of 0.110.
3M3D: Multi-view, Multi-path, Multi-representation for 3D Object Detection
Feb 16, 2023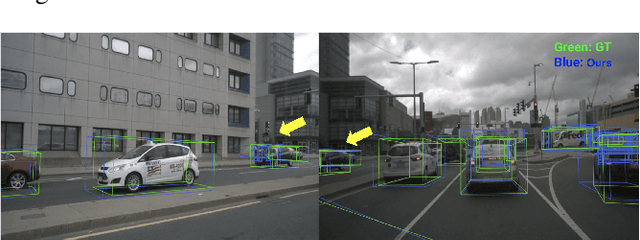
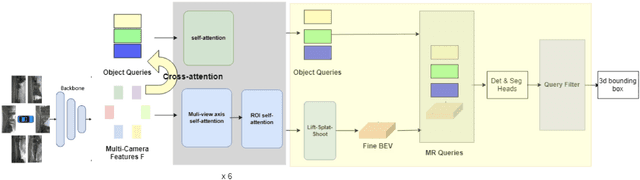

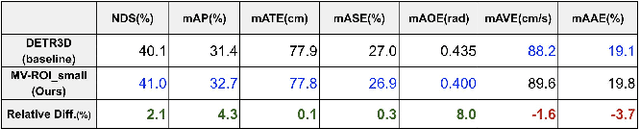
3D visual perception tasks based on multi-camera images are essential for autonomous driving systems. Latest work in this field performs 3D object detection by leveraging multi-view images as an input and iteratively enhancing object queries (object proposals) by cross-attending multi-view features. However, individual backbone features are not updated with multi-view features and it stays as a mere collection of the output of the single-image backbone network. Therefore we propose 3M3D: A Multi-view, Multi-path, Multi-representation for 3D Object Detection where we update both multi-view features and query features to enhance the representation of the scene in both fine panoramic view and coarse global view. Firstly, we update multi-view features by multi-view axis self-attention. It will incorporate panoramic information in the multi-view features and enhance understanding of the global scene. Secondly, we update multi-view features by self-attention of the ROI (Region of Interest) windows which encodes local finer details in the features. It will help exchange the information not only along the multi-view axis but also along the other spatial dimension. Lastly, we leverage the fact of multi-representation of queries in different domains to further boost the performance. Here we use sparse floating queries along with dense BEV (Bird's Eye View) queries, which are later post-processed to filter duplicate detections. Moreover, we show performance improvements on nuScenes benchmark dataset on top of our baselines.
A Unified View of Long-Sequence Models towards Modeling Million-Scale Dependencies
Feb 16, 2023

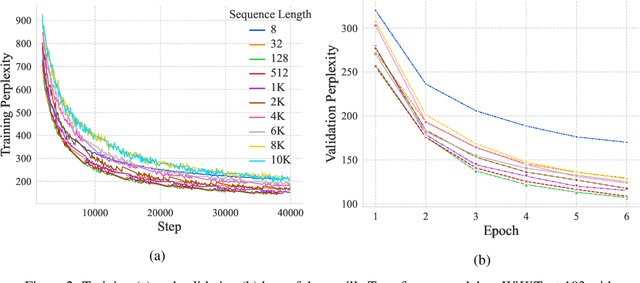
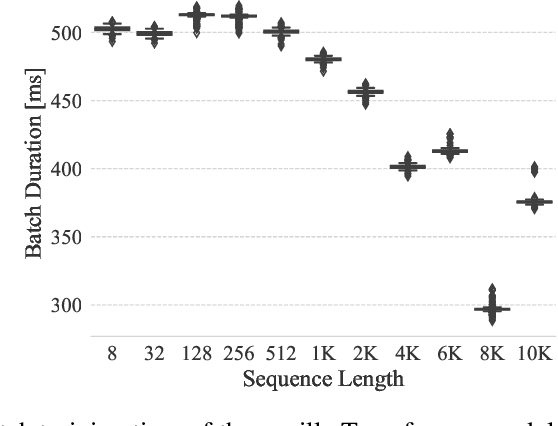
Ever since their conception, Transformers have taken over traditional sequence models in many tasks, such as NLP, image classification, and video/audio processing, for their fast training and superior performance. Much of the merit is attributable to positional encoding and multi-head attention. However, Transformers fall short in learning long-range dependencies mainly due to the quadratic complexity scaled with context length, in terms of both time and space. Consequently, over the past five years, a myriad of methods has been proposed to make Transformers more efficient. In this work, we first take a step back, study and compare existing solutions to long-sequence modeling in terms of their pure mathematical formulation. Specifically, we summarize them using a unified template, given their shared nature of token mixing. Through benchmarks, we then demonstrate that long context length does yield better performance, albeit application-dependent, and traditional Transformer models fall short in taking advantage of long-range dependencies. Next, inspired by emerging sparse models of huge capacity, we propose a machine learning system for handling million-scale dependencies. As a proof of concept, we evaluate the performance of one essential component of this system, namely, the distributed multi-head attention. We show that our algorithm can scale up attention computation by almost $40\times$ using four GeForce RTX 4090 GPUs, compared to vanilla multi-head attention mechanism. We believe this study is an instrumental step towards modeling million-scale dependencies.
MINOTAUR: Multi-task Video Grounding From Multimodal Queries
Feb 16, 2023
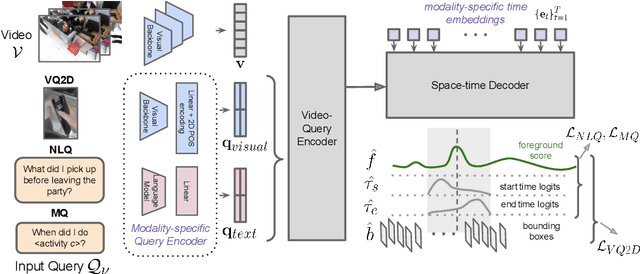
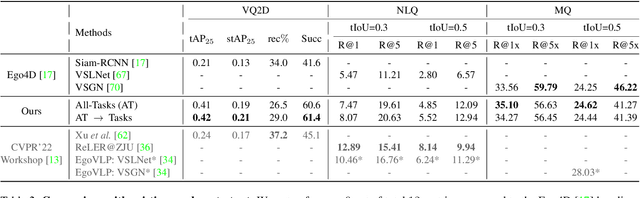
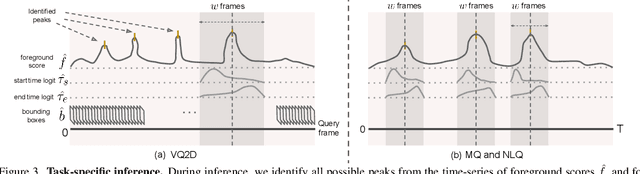
Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.
Unsupervised Representation Learning from Pre-trained Diffusion Probabilistic Models
Jan 01, 2023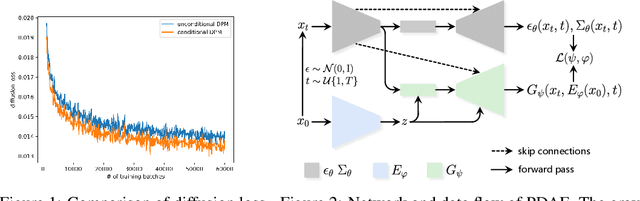
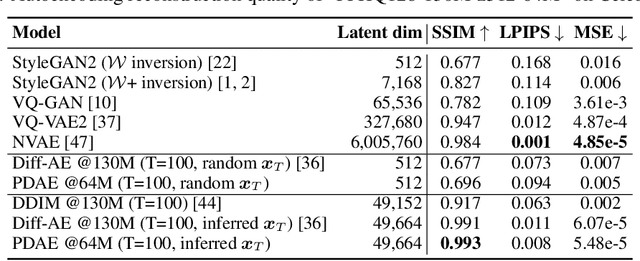


Diffusion Probabilistic Models (DPMs) have shown a powerful capacity of generating high-quality image samples. Recently, diffusion autoencoders (Diff-AE) have been proposed to explore DPMs for representation learning via autoencoding. Their key idea is to jointly train an encoder for discovering meaningful representations from images and a conditional DPM as the decoder for reconstructing images. Considering that training DPMs from scratch will take a long time and there have existed numerous pre-trained DPMs, we propose \textbf{P}re-trained \textbf{D}PM \textbf{A}uto\textbf{E}ncoding (\textbf{PDAE}), a general method to adapt existing pre-trained DPMs to the decoders for image reconstruction, with better training efficiency and performance than Diff-AE. Specifically, we find that the reason that pre-trained DPMs fail to reconstruct an image from its latent variables is due to the information loss of forward process, which causes a gap between their predicted posterior mean and the true one. From this perspective, the classifier-guided sampling method can be explained as computing an extra mean shift to fill the gap, reconstructing the lost class information in samples. These imply that the gap corresponds to the lost information of the image, and we can reconstruct the image by filling the gap. Drawing inspiration from this, we employ a trainable model to predict a mean shift according to encoded representation and train it to fill as much gap as possible, in this way, the encoder is forced to learn as much information as possible from images to help the filling. By reusing a part of network of pre-trained DPMs and redesigning the weighting scheme of diffusion loss, PDAE can learn meaningful representations from images efficiently. Extensive experiments demonstrate the effectiveness, efficiency and flexibility of PDAE.
An Efficient and Robust Method for Chest X-Ray Rib Suppression that Improves Pulmonary Abnormality Diagnosis
Feb 19, 2023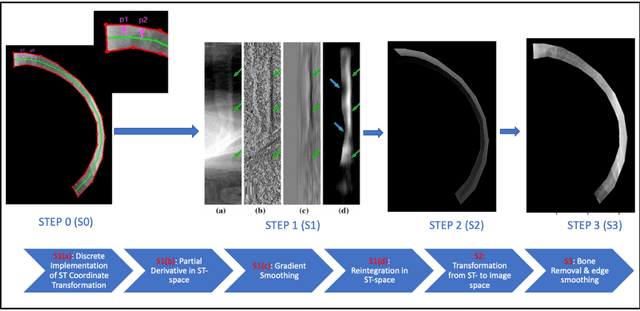
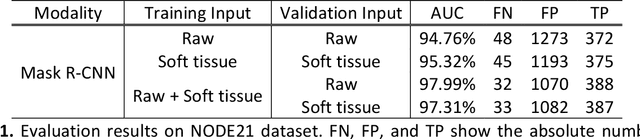

Suppression of thoracic bone shadows on chest X-rays (CXRs) has been indicated to improve the diagnosis of pulmonary disease. Previous approaches can be categorized as unsupervised physical and supervised deep learning models. Nevertheless, with physical models able to preserve morphological details but at the cost of extremely long processing time, existing DL methods face challenges of gathering sufficient/qualitative ground truth (GT) for robust training, thus leading to failure in maintaining clinically acceptable false positive rates. We hereby propose a generalizable yet efficient workflow of two stages: (1) training pairs generation with GT bone shadows eliminated in by a physical model in spatially transformed gradient fields. (2) fully supervised image denoising network training on stage-one datasets for fast rib removal on incoming CXRs. For step two, we designed a densely connected network called SADXNet, combined with peak signal to noise ratio and multi-scale structure similarity index measure objective minimization to suppress bony structures. The SADXNet organizes spatial filters in U shape (e.g., X=7; filters = 16, 64, 256, 512, 256, 64, 16) and preserves the feature map dimension throughout the network flow. Visually, SADXNet can suppress the rib edge and that near the lung wall/vertebra without jeopardizing the vessel/abnormality conspicuity. Quantitively, it achieves RMSE of ~0 during testing with one prediction taking <1s. Downstream tasks including lung nodule detection as well as common lung disease classification and localization are used to evaluate our proposed rib suppression mechanism. We observed 3.23% and 6.62% area under the curve (AUC) increase as well as 203 and 385 absolute false positive decrease for lung nodule detection and common lung disease localization, separately.
CyberLoc: Towards Accurate Long-term Visual Localization
Jan 06, 2023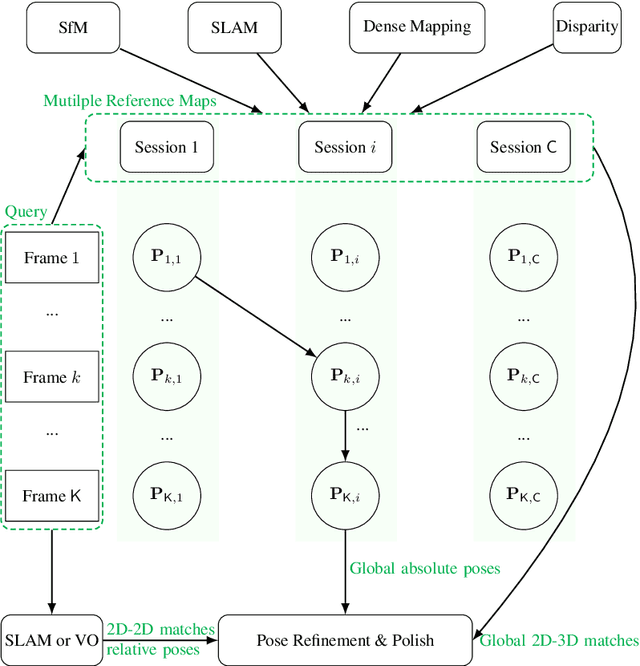


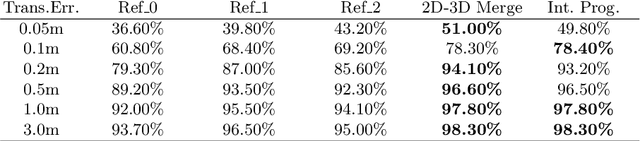
This technical report introduces CyberLoc, an image-based visual localization pipeline for robust and accurate long-term pose estimation under challenging conditions. The proposed method comprises four modules connected in a sequence. First, a mapping module is applied to build accurate 3D maps of the scene, one map for each reference sequence if there exist multiple reference sequences under different conditions. Second, a single-image-based localization pipeline (retrieval--matching--PnP) is performed to estimate 6-DoF camera poses for each query image, one for each 3D map. Third, a consensus set maximization module is proposed to filter out outlier 6-DoF camera poses, and outputs one 6-DoF camera pose for a query. Finally, a robust pose refinement module is proposed to optimize 6-DoF query poses, taking candidate global 6-DoF camera poses and their corresponding global 2D-3D matches, sparse 2D-2D feature matches between consecutive query images and SLAM poses of the query sequence as input. Experiments on the 4seasons dataset show that our method achieves high accuracy and robustness. In particular, our approach wins the localization challenge of ECCV 2022 workshop on Map-based Localization for Autonomous Driving (MLAD-ECCV2022).
Learning-Based Radiomic Prediction of Type 2 Diabetes Mellitus Using Image-Derived Phenotypes
Sep 20, 2022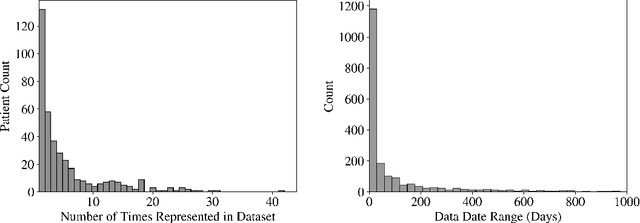

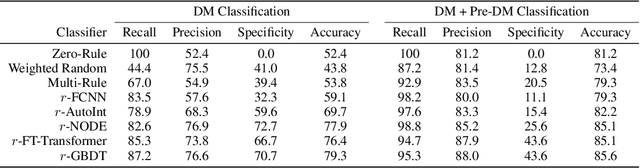
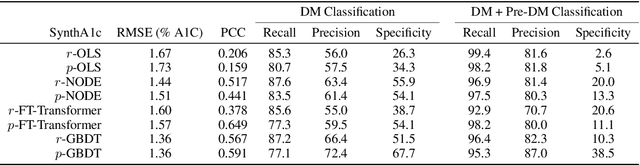
Early diagnosis of Type 2 Diabetes Mellitus (T2DM) is crucial to enable timely therapeutic interventions and lifestyle modifications. As medical imaging data become more widely available for many patient populations, we sought to investigate whether image-derived phenotypic data could be leveraged in tabular learning classifier models to predict T2DM incidence without the use of invasive blood lab measurements. We show that both neural network and decision tree models that use image-derived phenotypes can predict patient T2DM status with recall scores as high as 87.6%. We also propose the novel use of these same architectures as 'SynthA1c encoders' that are able to output interpretable values mimicking blood hemoglobin A1C empirical lab measurements. Finally, we demonstrate that T2DM risk prediction model sensitivity to small perturbations in input vector components can be used to predict performance on covariates sampled from previously unseen patient populations.