 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ColoristaNet for Photorealistic Video Style Transfer
Dec 21, 2022

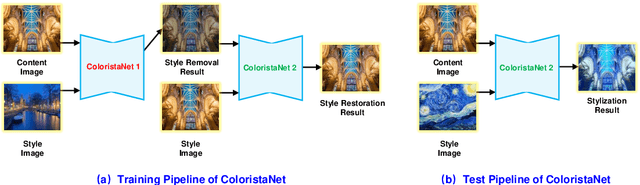
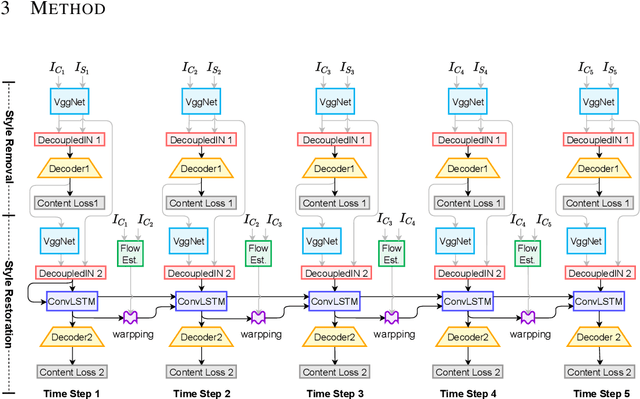
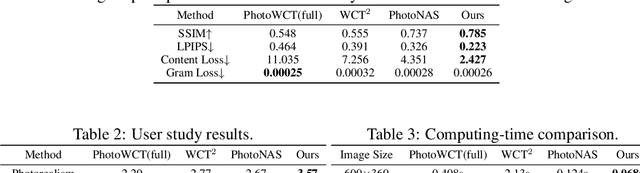
Photorealistic style transfer aims to transfer the artistic style of an image onto an input image or video while keeping photorealism. In this paper, we think it's the summary statistics matching scheme in existing algorithms that leads to unrealistic stylization. To avoid employing the popular Gram loss, we propose a self-supervised style transfer framework, which contains a style removal part and a style restoration part. The style removal network removes the original image styles, and the style restoration network recovers image styles in a supervised manner. Meanwhile, to address the problems in current feature transformation methods, we propose decoupled instance normalization to decompose feature transformation into style whitening and restylization. It works quite well in ColoristaNet and can transfer image styles efficiently while keeping photorealism. To ensure temporal coherency, we also incorporate optical flow methods and ConvLSTM to embed contextual information. Experiments demonstrates that ColoristaNet can achieve better stylization effects when compared with state-of-the-art algorithms.
ISS: Image as Stetting Stone for Text-Guided 3D Shape Generation
Sep 09, 2022

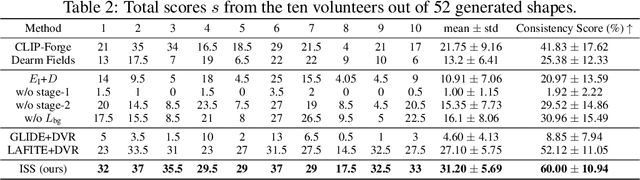

Text-guided 3D shape generation remains challenging due to the absence of large paired text-shape data, the substantial semantic gap between these two modalities, and the structural complexity of 3D shapes. This paper presents a new framework called Image as Stepping Stone (ISS) for the task by introducing 2D image as a stepping stone to connect the two modalities and to eliminate the need for paired text-shape data. Our key contribution is a two-stage feature-space-alignment approach that maps CLIP features to shapes by harnessing a pre-trained single-view reconstruction (SVR) model with multi-view supervisions: first map the CLIP image feature to the detail-rich shape space in the SVR model, then map the CLIP text feature to the shape space and optimize the mapping by encouraging CLIP consistency between the input text and the rendered images. Further, we formulate a text-guided shape stylization module to dress up the output shapes with novel textures. Beyond existing works on 3D shape generation from text, our new approach is general for creating shapes in a broad range of categories, without requiring paired text-shape data. Experimental results manifest that our approach outperforms the state-of-the-arts and our baselines in terms of fidelity and consistency with text. Further, our approach can stylize the generated shapes with both realistic and fantasy structures and textures.
Simple Hardware-Efficient Long Convolutions for Sequence Modeling
Feb 13, 2023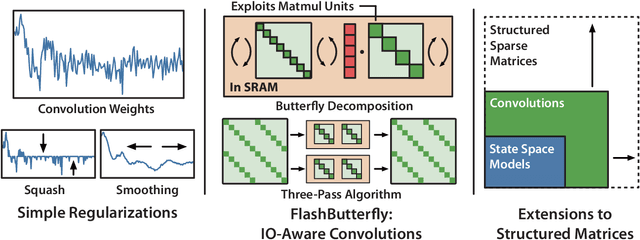

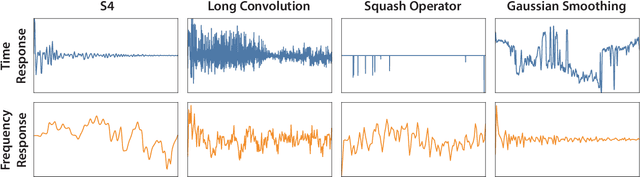

State space models (SSMs) have high performance on long sequence modeling but require sophisticated initialization techniques and specialized implementations for high quality and runtime performance. We study whether a simple alternative can match SSMs in performance and efficiency: directly learning long convolutions over the sequence. We find that a key requirement to achieving high performance is keeping the convolution kernels smooth. We find that simple interventions--such as squashing the kernel weights--result in smooth kernels and recover SSM performance on a range of tasks including the long range arena, image classification, language modeling, and brain data modeling. Next, we develop FlashButterfly, an IO-aware algorithm to improve the runtime performance of long convolutions. FlashButterfly appeals to classic Butterfly decompositions of the convolution to reduce GPU memory IO and increase FLOP utilization. FlashButterfly speeds up convolutions by 2.2$\times$, and allows us to train on Path256, a challenging task with sequence length 64K, where we set state-of-the-art by 29.1 points while training 7.2$\times$ faster than prior work. Lastly, we introduce an extension to FlashButterfly that learns the coefficients of the Butterfly decomposition, increasing expressivity without increasing runtime. Using this extension, we outperform a Transformer on WikiText103 by 0.2 PPL with 30% fewer parameters.
GenAug: Retargeting behaviors to unseen situations via Generative Augmentation
Feb 13, 2023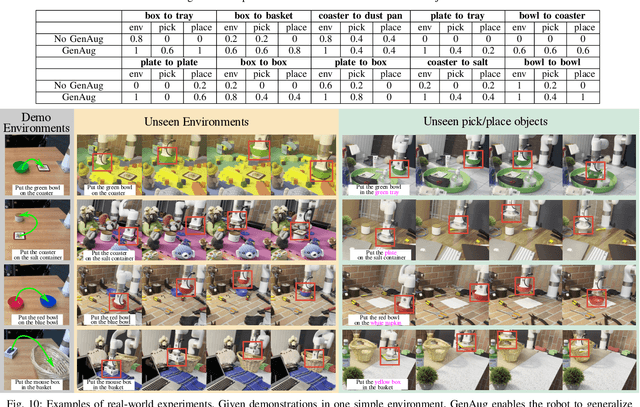
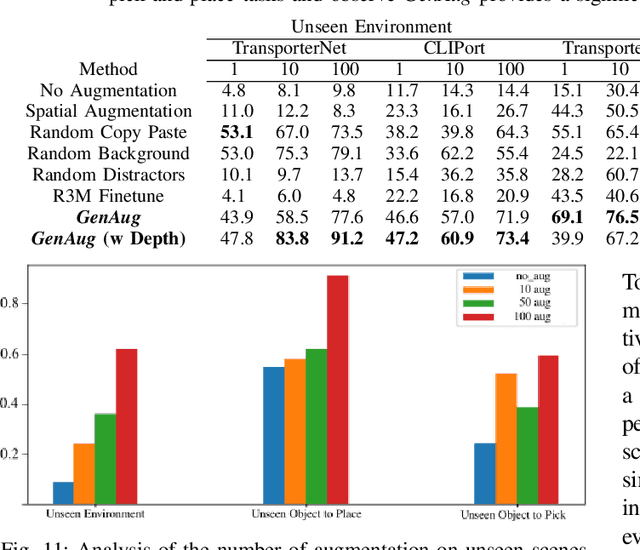


Robot learning methods have the potential for widespread generalization across tasks, environments, and objects. However, these methods require large diverse datasets that are expensive to collect in real-world robotics settings. For robot learning to generalize, we must be able to leverage sources of data or priors beyond the robot's own experience. In this work, we posit that image-text generative models, which are pre-trained on large corpora of web-scraped data, can serve as such a data source. We show that despite these generative models being trained on largely non-robotics data, they can serve as effective ways to impart priors into the process of robot learning in a way that enables widespread generalization. In particular, we show how pre-trained generative models can serve as effective tools for semantically meaningful data augmentation. By leveraging these pre-trained models for generating appropriate "semantic" data augmentations, we propose a system GenAug that is able to significantly improve policy generalization. We apply GenAug to tabletop manipulation tasks, showing the ability to re-target behavior to novel scenarios, while only requiring marginal amounts of real-world data. We demonstrate the efficacy of this system on a number of object manipulation problems in the real world, showing a 40% improvement in generalization to novel scenes and objects.
Understanding Multimodal Contrastive Learning and Incorporating Unpaired Data
Feb 13, 2023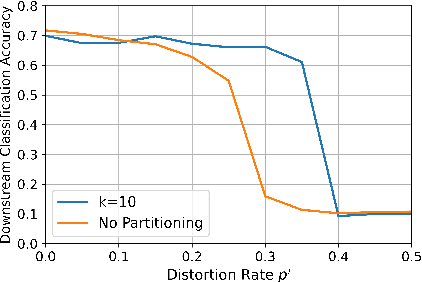
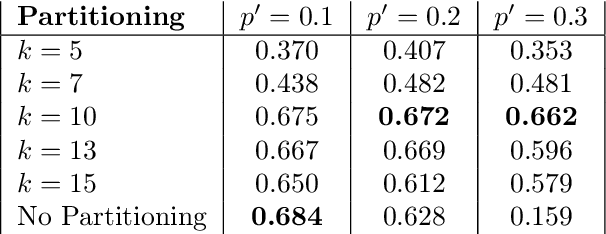
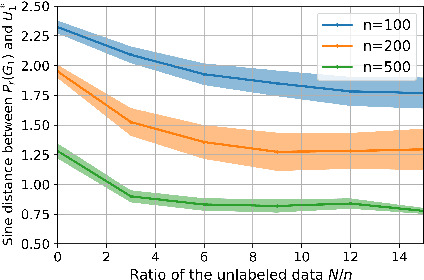
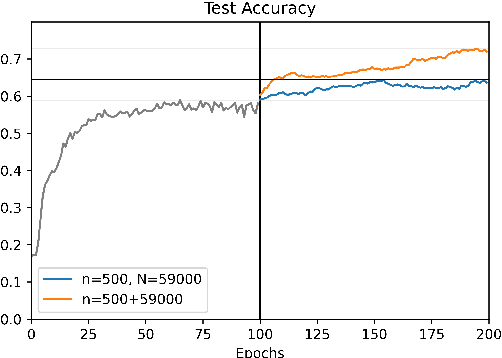
Language-supervised vision models have recently attracted great attention in computer vision. A common approach to build such models is to use contrastive learning on paired data across the two modalities, as exemplified by Contrastive Language-Image Pre-Training (CLIP). In this paper, under linear representation settings, (i) we initiate the investigation of a general class of nonlinear loss functions for multimodal contrastive learning (MMCL) including CLIP loss and show its connection to singular value decomposition (SVD). Namely, we show that each step of loss minimization by gradient descent can be seen as performing SVD on a contrastive cross-covariance matrix. Based on this insight, (ii) we analyze the performance of MMCL. We quantitatively show that the feature learning ability of MMCL can be better than that of unimodal contrastive learning applied to each modality even under the presence of wrongly matched pairs. This characterizes the robustness of MMCL to noisy data. Furthermore, when we have access to additional unpaired data, (iii) we propose a new MMCL loss that incorporates additional unpaired datasets. We show that the algorithm can detect the ground-truth pairs and improve performance by fully exploiting unpaired datasets. The performance of the proposed algorithm was verified by numerical experiments.
Large Scale Multi-Lingual Multi-Modal Summarization Dataset
Feb 13, 2023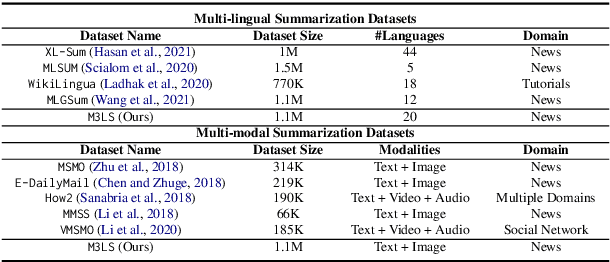

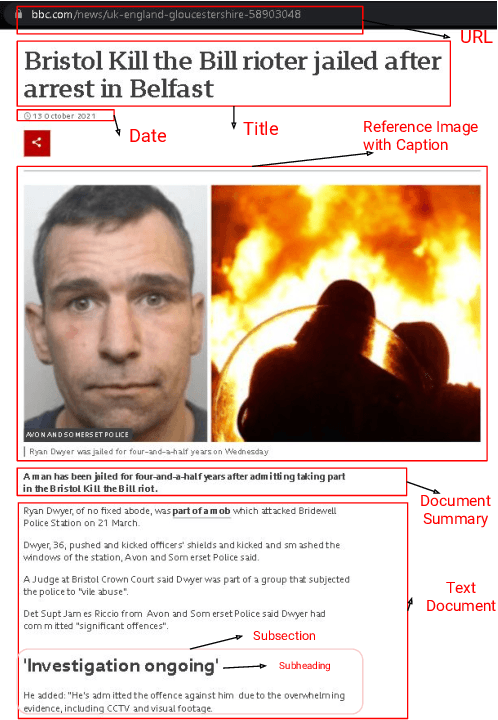
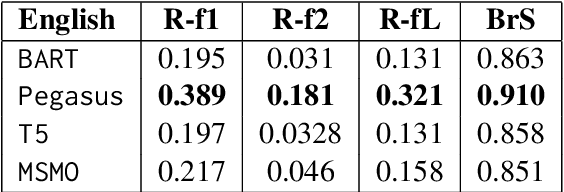
Significant developments in techniques such as encoder-decoder models have enabled us to represent information comprising multiple modalities. This information can further enhance many downstream tasks in the field of information retrieval and natural language processing; however, improvements in multi-modal techniques and their performance evaluation require large-scale multi-modal data which offers sufficient diversity. Multi-lingual modeling for a variety of tasks like multi-modal summarization, text generation, and translation leverages information derived from high-quality multi-lingual annotated data. In this work, we present the current largest multi-lingual multi-modal summarization dataset (M3LS), and it consists of over a million instances of document-image pairs along with a professionally annotated multi-modal summary for each pair. It is derived from news articles published by British Broadcasting Corporation(BBC) over a decade and spans 20 languages, targeting diversity across five language roots, it is also the largest summarization dataset for 13 languages and consists of cross-lingual summarization data for 2 languages. We formally define the multi-lingual multi-modal summarization task utilizing our dataset and report baseline scores from various state-of-the-art summarization techniques in a multi-lingual setting. We also compare it with many similar datasets to analyze the uniqueness and difficulty of M3LS.
See Your Heart: Psychological states Interpretation through Visual Creations
Feb 11, 2023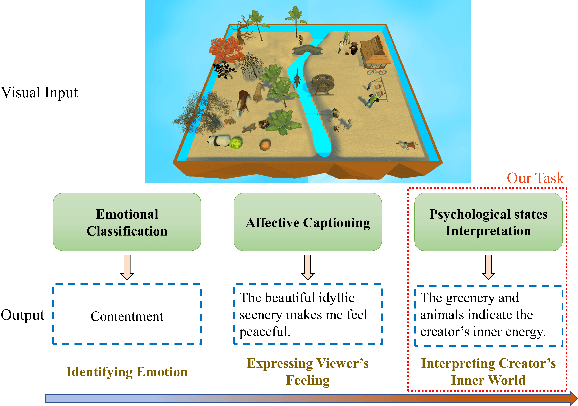

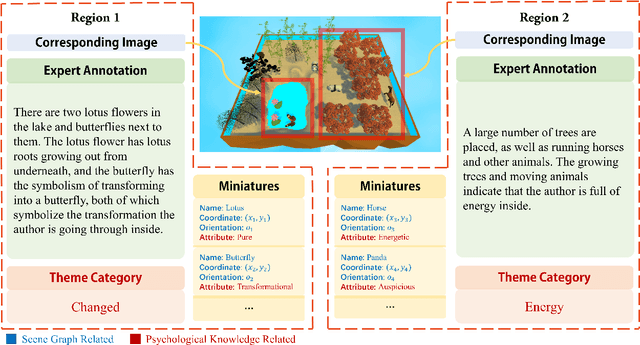
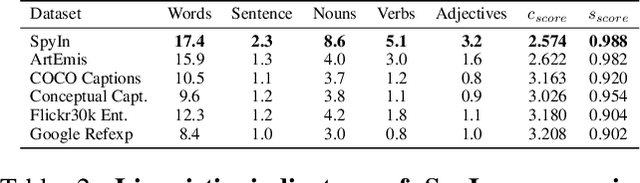
In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.
Towards Semantic Communications: Deep Learning-Based Image Semantic Coding
Aug 08, 2022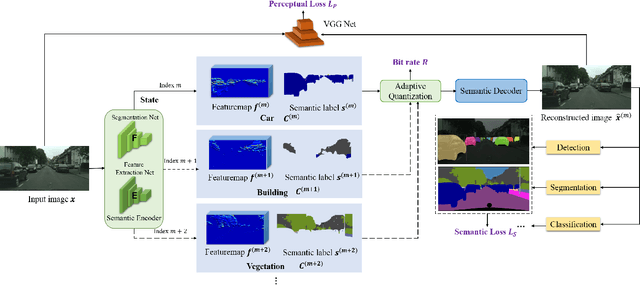

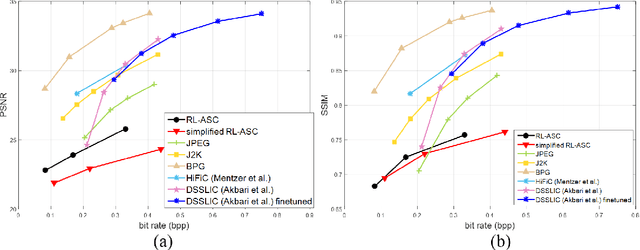
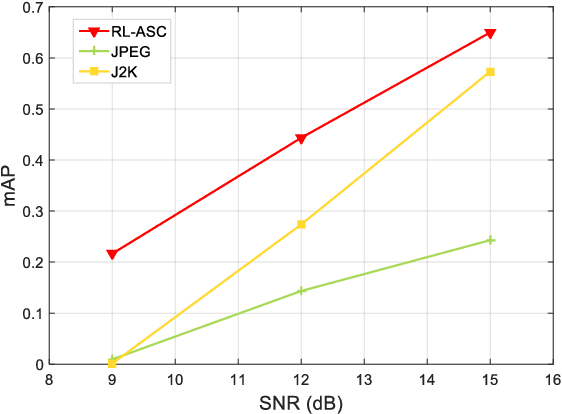
Semantic communications has received growing interest since it can remarkably reduce the amount of data to be transmitted without missing critical information. Most existing works explore the semantic encoding and transmission for text and apply techniques in Natural Language Processing (NLP) to interpret the meaning of the text. In this paper, we conceive the semantic communications for image data that is much more richer in semantics and bandwidth sensitive. We propose an reinforcement learning based adaptive semantic coding (RL-ASC) approach that encodes images beyond pixel level. Firstly, we define the semantic concept of image data that includes the category, spatial arrangement, and visual feature as the representation unit, and propose a convolutional semantic encoder to extract semantic concepts. Secondly, we propose the image reconstruction criterion that evolves from the traditional pixel similarity to semantic similarity and perceptual performance. Thirdly, we design a novel RL-based semantic bit allocation model, whose reward is the increase in rate-semantic-perceptual performance after encoding a certain semantic concept with adaptive quantization level. Thus, the task-related information is preserved and reconstructed properly while less important data is discarded. Finally, we propose the Generative Adversarial Nets (GANs) based semantic decoder that fuses both locally and globally features via an attention module. Experimental results demonstrate that the proposed RL-ASC is noise robust and could reconstruct visually pleasant and semantic consistent image, and saves times of bit cost compared to standard codecs and other deep learning-based image codecs.
Uncertainty Inspired Underwater Image Enhancement
Jul 20, 2022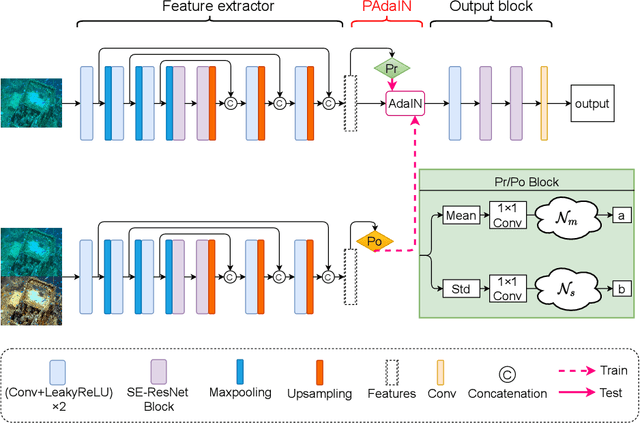
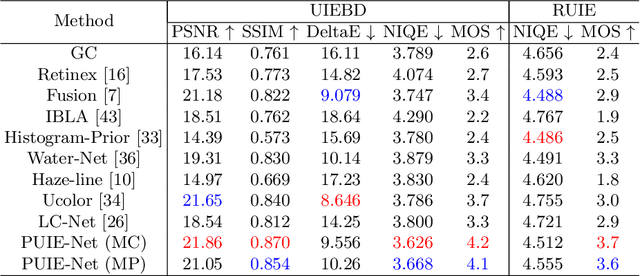


A main challenge faced in the deep learning-based Underwater Image Enhancement (UIE) is that the ground truth high-quality image is unavailable. Most of the existing methods first generate approximate reference maps and then train an enhancement network with certainty. This kind of method fails to handle the ambiguity of the reference map. In this paper, we resolve UIE into distribution estimation and consensus process. We present a novel probabilistic network to learn the enhancement distribution of degraded underwater images. Specifically, we combine conditional variational autoencoder with adaptive instance normalization to construct the enhancement distribution. After that, we adopt a consensus process to predict a deterministic result based on a set of samples from the distribution. By learning the enhancement distribution, our method can cope with the bias introduced in the reference map labeling to some extent. Additionally, the consensus process is useful to capture a robust and stable result. We examined the proposed method on two widely used real-world underwater image enhancement datasets. Experimental results demonstrate that our approach enables sampling possible enhancement predictions. Meanwhile, the consensus estimate yields competitive performance compared with state-of-the-art UIE methods. Code available at https://github.com/zhenqifu/PUIE-Net.
Tab2vox: CNN-Based Multivariate Multilevel Demand Forecasting Framework by Tabular-To-Voxel Image Conversion
Sep 21, 2022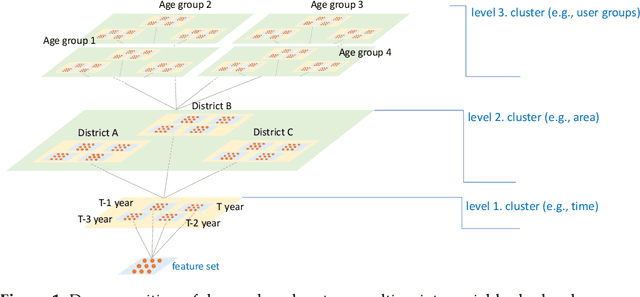
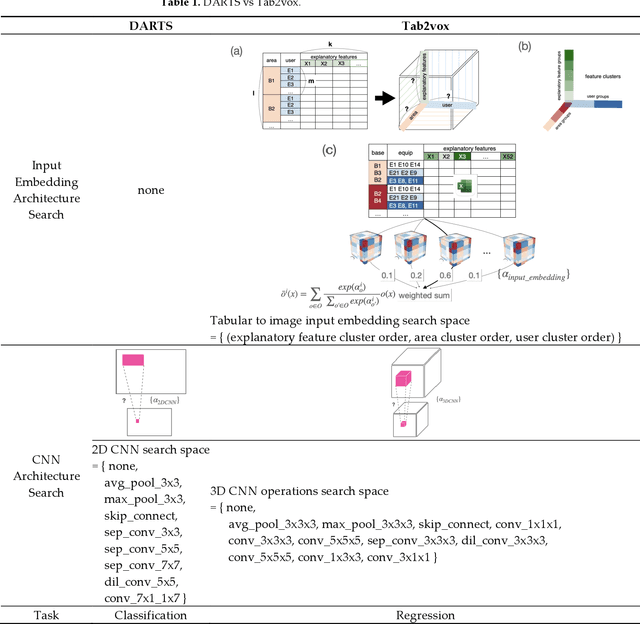
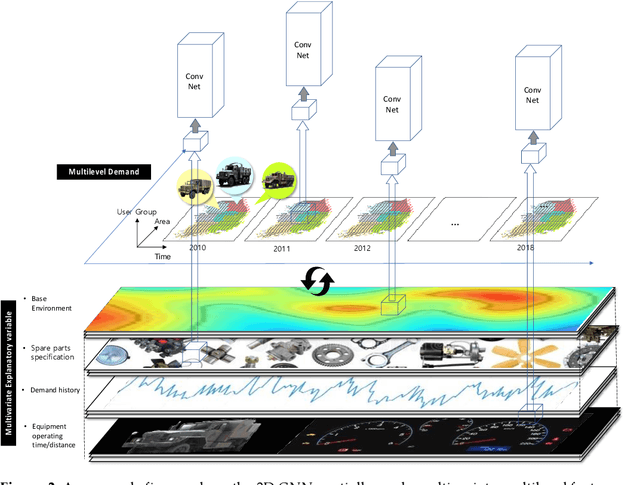
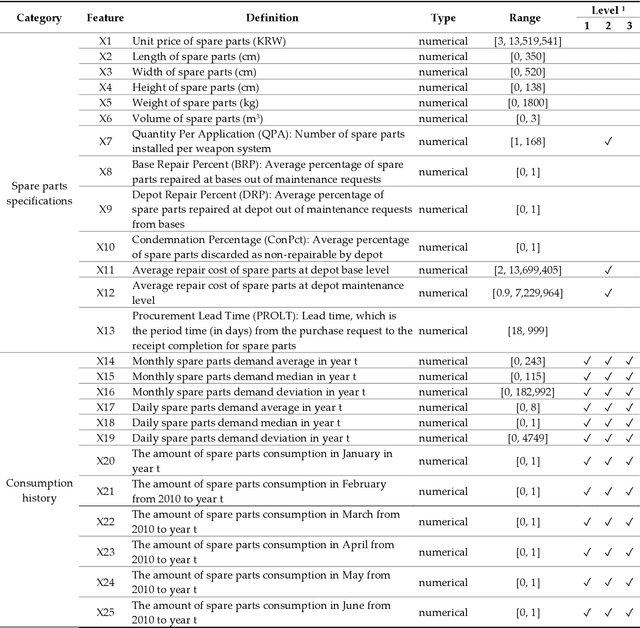
Since demand is influenced by a wide variety of causes, it is necessary to decompose the explana-tory variables into different levels, extract their relationships effectively, and reflect them in the forecast. In particular, this contextual information can be very useful in demand forecasting with large demand volatility or intermittent demand patterns. Convolutional neural networks (CNNs) have been successfully used in many fields where important information in data is represented by images. CNNs are powerful because they accept samples as images and use adjacent voxel sets to integrate multi-dimensional important information and learn important features. On the other hand, although the demand-forecasting model has been improved, the input data is still limited in its tabular form and is not suitable for CNN modeling. In this study, we propose a Tab2vox neural architecture search (NAS) model as a method to convert a high-dimensional tabular sam-ple into a well-formed 3D voxel image and use it in a 3D CNN network. For each image repre-sentation, the 3D CNN forecasting model proposed from the Tab2vox framework showed supe-rior performance, compared to the existing time series and machine learning techniques using tabular data, and the latest image transformation studies.