 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reference-Guided Texture and Structure Inference for Image Inpainting
Jul 29, 2022

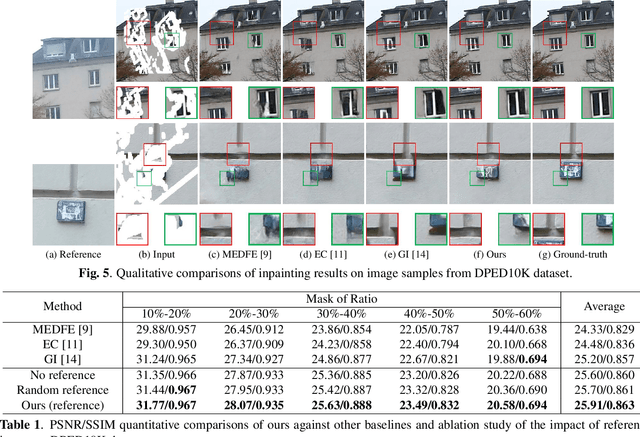

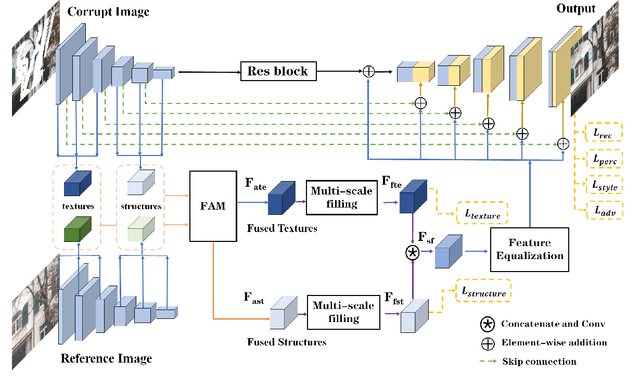
Existing learning-based image inpainting methods are still in challenge when facing complex semantic environments and diverse hole patterns. The prior information learned from the large scale training data is still insufficient for these situations. Reference images captured covering the same scenes share similar texture and structure priors with the corrupted images, which offers new prospects for the image inpainting tasks. Inspired by this, we first build a benchmark dataset containing 10K pairs of input and reference images for reference-guided inpainting. Then we adopt an encoder-decoder structure to separately infer the texture and structure features of the input image considering their pattern discrepancy of texture and structure during inpainting. A feature alignment module is further designed to refine these features of the input image with the guidance of a reference image. Both quantitative and qualitative evaluations demonstrate the superiority of our method over the state-of-the-art methods in terms of completing complex holes.
Long Horizon Temperature Scaling
Feb 07, 2023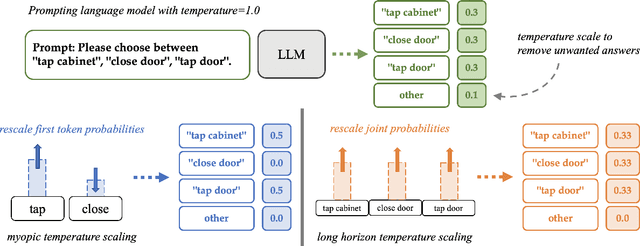
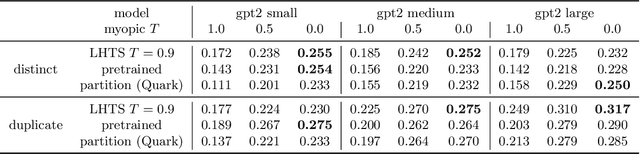

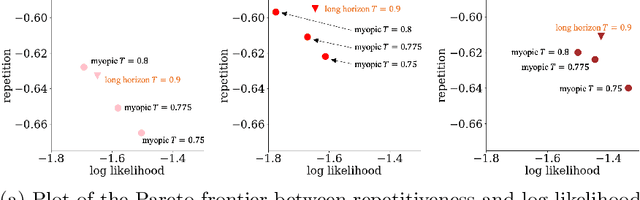
Temperature scaling is a popular technique for tuning the sharpness of a model distribution. It is used extensively for sampling likely generations and calibrating model uncertainty, and even features as a controllable parameter to many large language models in deployment. However, autoregressive models rely on myopic temperature scaling that greedily optimizes the next token. To address this, we propose Long Horizon Temperature Scaling (LHTS), a novel approach for sampling from temperature-scaled joint distributions. LHTS is compatible with all likelihood-based models, and optimizes for the long-horizon likelihood of samples. We derive a temperature-dependent LHTS objective, and show that fine-tuning a model on a range of temperatures produces a single model capable of generation with a controllable long-horizon temperature parameter. We experiment with LHTS on image diffusion models and character/language autoregressive models, demonstrating advantages over myopic temperature scaling in likelihood and sample quality, and showing improvements in accuracy on a multiple choice analogy task by $10\%$.
A Deep Learning-based in silico Framework for Optimization on Retinal Prosthetic Stimulation
Feb 07, 2023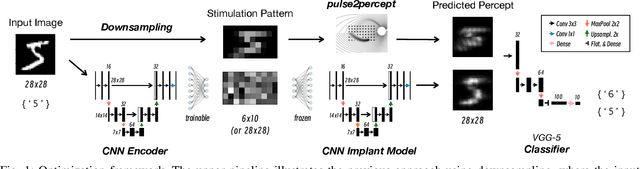

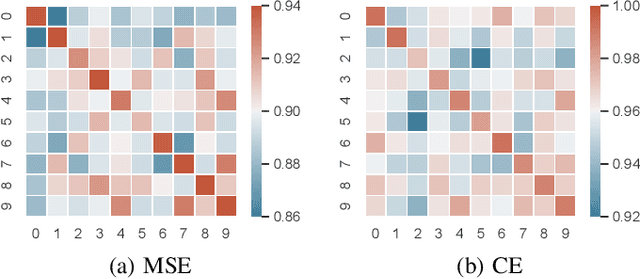
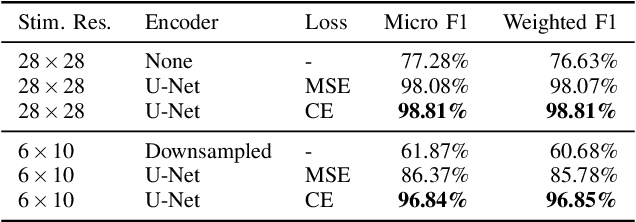
We propose a neural network-based framework to optimize the perceptions simulated by the in silico retinal implant model pulse2percept. The overall pipeline consists of a trainable encoder, a pre-trained retinal implant model and a pre-trained evaluator. The encoder is a U-Net, which takes the original image and outputs the stimulus. The pre-trained retinal implant model is also a U-Net, which is trained to mimic the biomimetic perceptual model implemented in pulse2percept. The evaluator is a shallow VGG classifier, which is trained with original images. Based on 10,000 test images from the MNIST dataset, we show that the convolutional neural network-based encoder performs significantly better than the trivial downsampling approach, yielding a boost in the weighted F1-Score by 36.17% in the pre-trained classifier with 6x10 electrodes. With this fully neural network-based encoder, the quality of the downstream perceptions can be fine-tuned using gradient descent in an end-to-end fashion.
Multimodal Federated Learning via Contrastive Representation Ensemble
Feb 17, 2023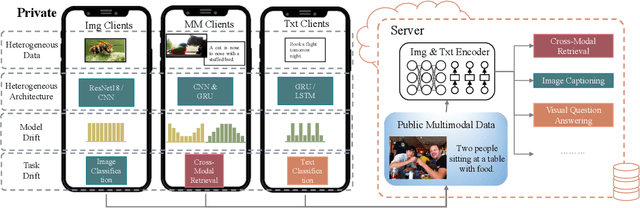
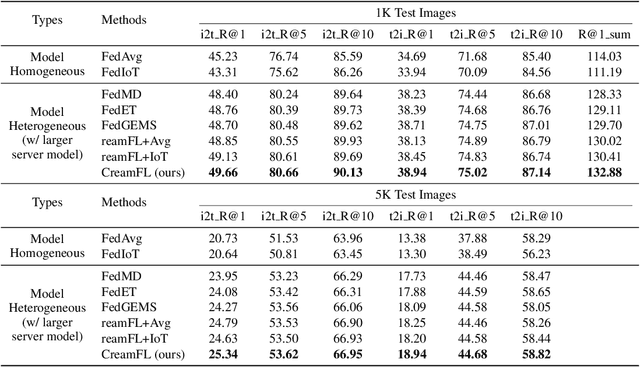
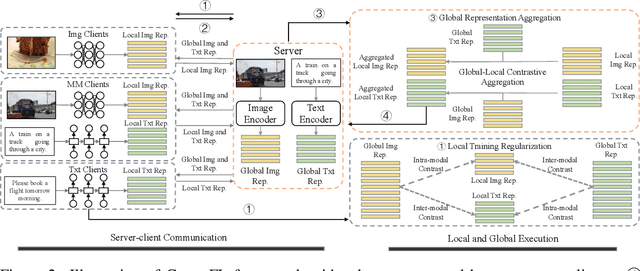
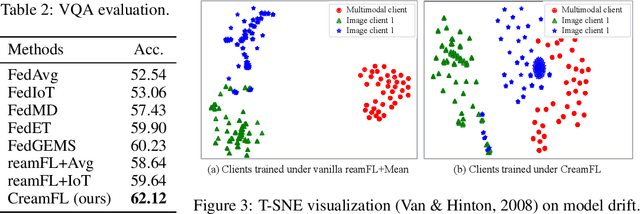
With the increasing amount of multimedia data on modern mobile systems and IoT infrastructures, harnessing these rich multimodal data without breaching user privacy becomes a critical issue. Federated learning (FL) serves as a privacy-conscious alternative to centralized machine learning. However, existing FL methods extended to multimodal data all rely on model aggregation on single modality level, which restrains the server and clients to have identical model architecture for each modality. This limits the global model in terms of both model complexity and data capacity, not to mention task diversity. In this work, we propose Contrastive Representation Ensemble and Aggregation for Multimodal FL (CreamFL), a multimodal federated learning framework that enables training larger server models from clients with heterogeneous model architectures and data modalities, while only communicating knowledge on public dataset. To achieve better multimodal representation fusion, we design a global-local cross-modal ensemble strategy to aggregate client representations. To mitigate local model drift caused by two unprecedented heterogeneous factors stemming from multimodal discrepancy (modality gap and task gap), we further propose two inter-modal and intra-modal contrasts to regularize local training, which complements information of the absent modality for uni-modal clients and regularizes local clients to head towards global consensus. Thorough evaluations and ablation studies on image-text retrieval and visual question answering tasks showcase the superiority of CreamFL over state-of-the-art FL methods and its practical value.
Stain-Adaptive Self-Supervised Learning for Histopathology Image Analysis
Aug 08, 2022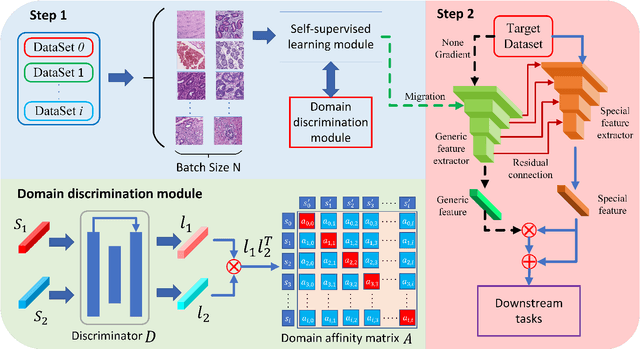
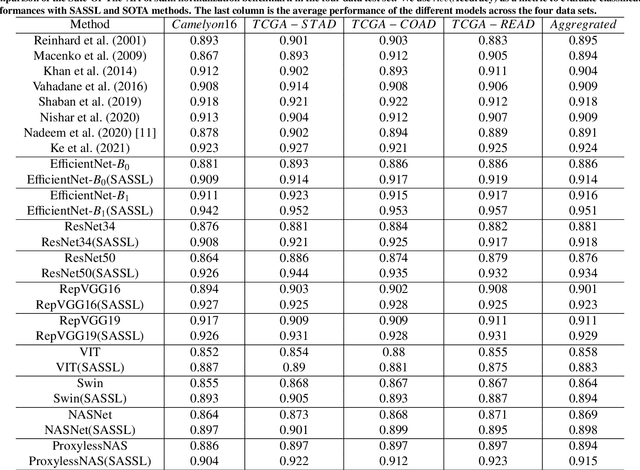
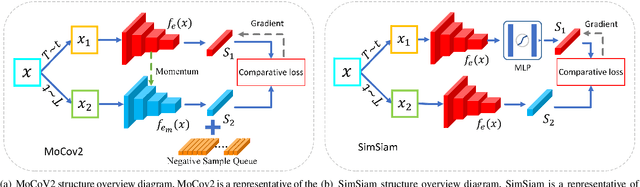
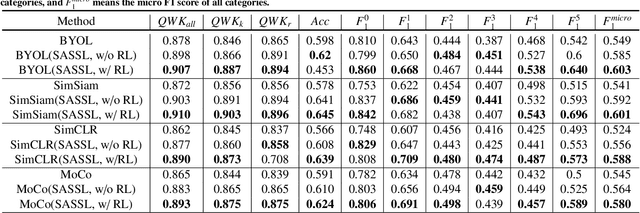
It is commonly recognized that color variations caused by differences in stains is a critical issue for histopathology image analysis. Existing methods adopt color matching, stain separation, stain transfer or the combination of them to alleviate the stain variation problem. In this paper, we propose a novel Stain-Adaptive Self-Supervised Learning(SASSL) method for histopathology image analysis. Our SASSL integrates a domain-adversarial training module into the SSL framework to learn distinctive features that are robust to both various transformations and stain variations. The proposed SASSL is regarded as a general method for domain-invariant feature extraction which can be flexibly combined with arbitrary downstream histopathology image analysis modules (e.g. nuclei/tissue segmentation) by fine-tuning the features for specific downstream tasks. We conducted experiments on publicly available pathological image analysis datasets including the PANDA, BreastPathQ, and CAMELYON16 datasets, achieving the state-of-the-art performance. Experimental results demonstrate that the proposed method can robustly improve the feature extraction ability of the model, and achieve stable performance improvement in downstream tasks.
High Dynamic Range Image Quality Assessment Based on Frequency Disparity
Sep 06, 2022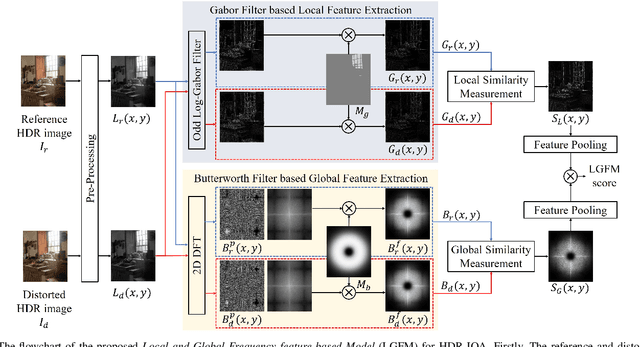
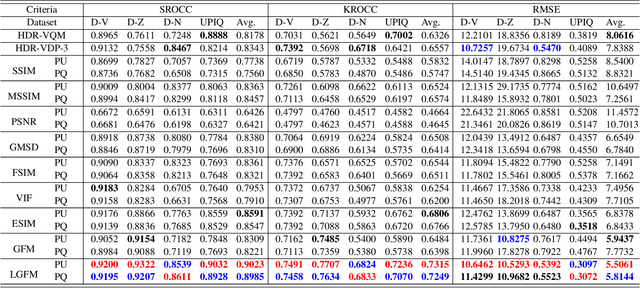
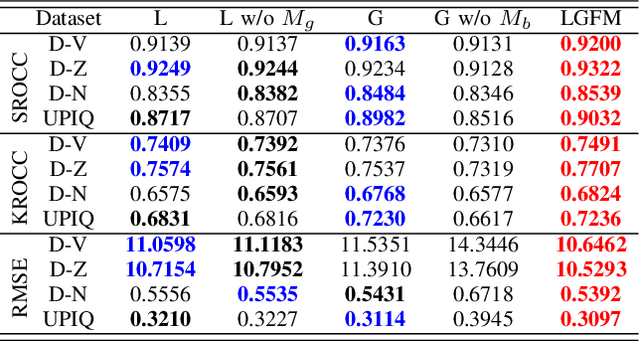
In this paper, a novel and effective image quality assessment (IQA) algorithm based on frequency disparity for high dynamic range (HDR) images is proposed, termed as local-global frequency feature-based model (LGFM). Motivated by the assumption that the human visual system is highly adapted for extracting structural information and partial frequencies when perceiving the visual scene, the Gabor and the Butterworth filters are applied to the luminance of the HDR image to extract local and global frequency features, respectively. The similarity measurement and feature pooling are sequentially performed on the frequency features to obtain the predicted quality score. The experiments evaluated on four widely used benchmarks demonstrate that the proposed LGFM can provide a higher consistency with the subjective perception compared with the state-of-the-art HDR IQA methods. Our code is available at: \url{https://github.com/eezkni/LGFM}.
High-Resolution Cloud Removal with Multi-Modal and Multi-Resolution Data Fusion: A New Baseline and Benchmark
Jan 09, 2023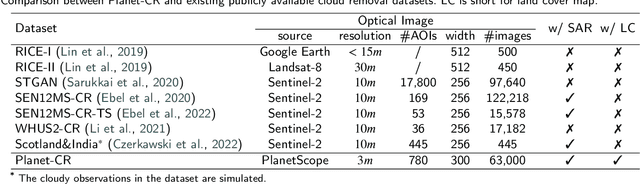
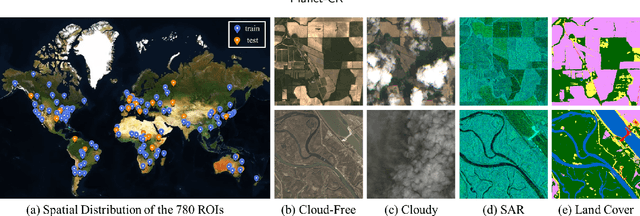
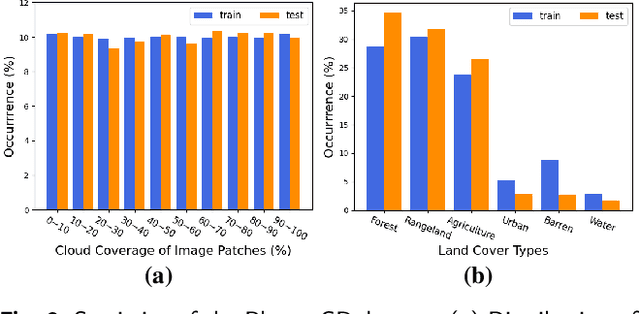
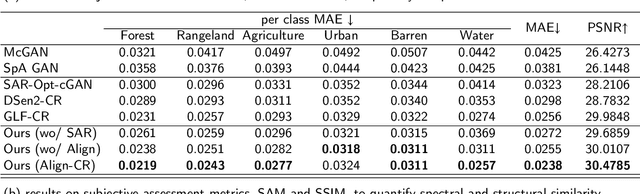
In this paper, we introduce Planet-CR, a benchmark dataset for high-resolution cloud removal with multi-modal and multi-resolution data fusion. Planet-CR is the first public dataset for cloud removal to feature globally sampled high resolution optical observations, in combination with paired radar measurements as well as pixel-level land cover annotations. It provides solid basis for exhaustive evaluation in terms of generating visually pleasing textures and semantically meaningful structures. With this dataset, we consider the problem of cloud removal in high resolution optical remote sensing imagery by integrating multi-modal and multi-resolution information. Existing multi-modal data fusion based methods, which assume the image pairs are aligned pixel-to-pixel, are hence not appropriate for this problem. To this end, we design a new baseline named Align-CR to perform the low-resolution SAR image guided high-resolution optical image cloud removal. It implicitly aligns the multi-modal and multi-resolution data during the reconstruction process to promote the cloud removal performance. The experimental results demonstrate that the proposed Align-CR method gives the best performance in both visual recovery quality and semantic recovery quality. The project is available at https://github.com/zhu-xlab/Planet-CR, and hope this will inspire future research.
Feature Likelihood Score: Evaluating Generalization of Generative Models Using Samples
Feb 09, 2023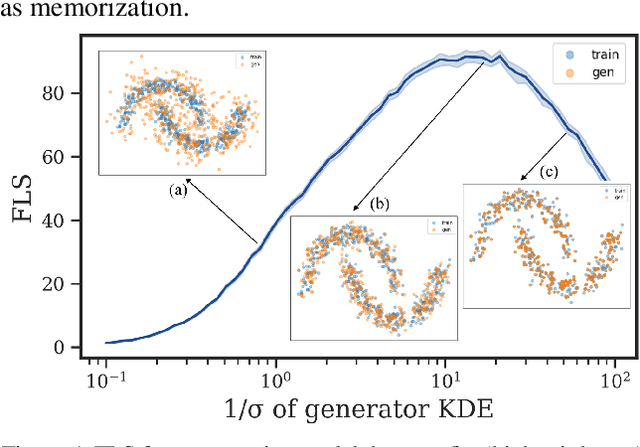
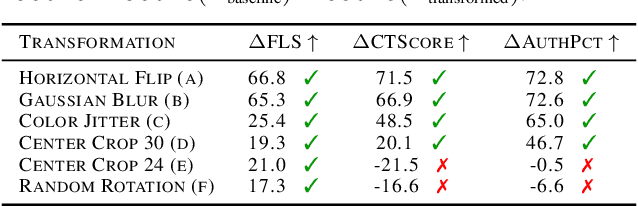
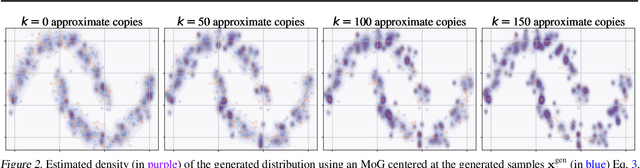
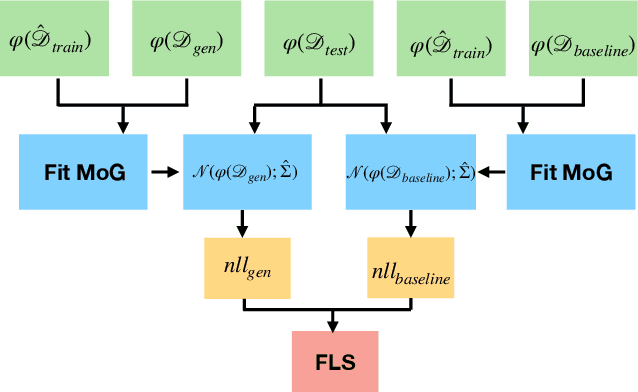
Deep generative models have demonstrated the ability to generate complex, high-dimensional, and photo-realistic data. However, a unified framework for evaluating different generative modeling families remains a challenge. Indeed, likelihood-based metrics do not apply in many cases while pure sample-based metrics such as FID fail to capture known failure modes such as overfitting on training data. In this work, we introduce the Feature Likelihood Score (FLS), a parametric sample-based score that uses density estimation to quantitatively measure the quality/diversity of generated samples while taking into account overfitting. We empirically demonstrate the ability of FLS to identify specific overfitting problem cases, even when previously proposed metrics fail. We further perform an extensive experimental evaluation on various image datasets and model classes. Our results indicate that FLS matches intuitions of previous metrics, such as FID, while providing a more holistic evaluation of generative models that highlights models whose generalization abilities are under or overappreciated. Code for computing FLS is provided at https://github.com/marcojira/fls
SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation
Feb 09, 2023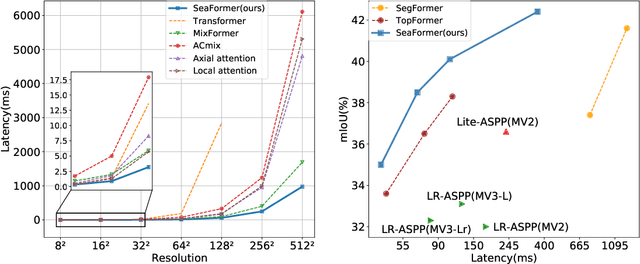
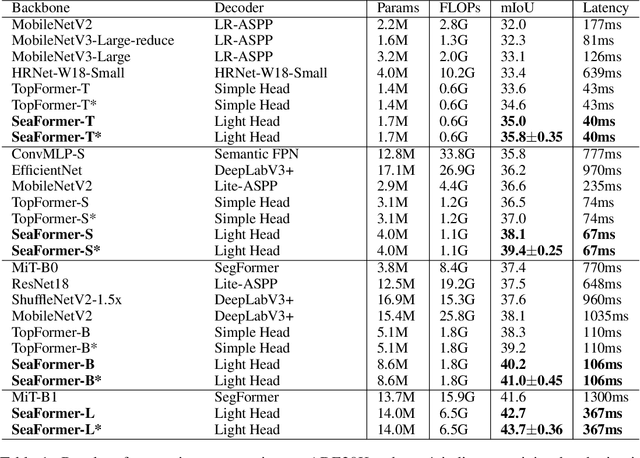
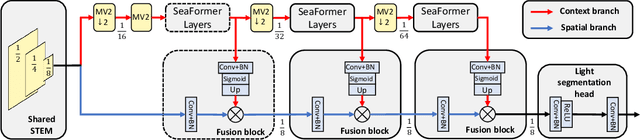
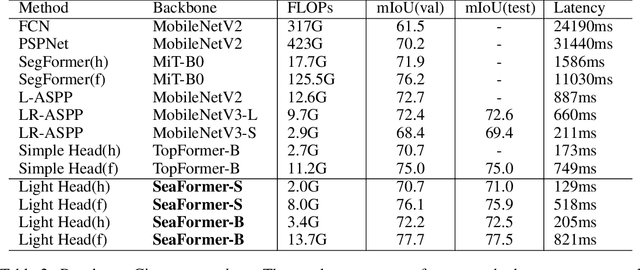
Since the introduction of Vision Transformers, the landscape of many computer vision tasks (e.g., semantic segmentation), which has been overwhelmingly dominated by CNNs, recently has significantly revolutionized. However, the computational cost and memory requirement render these methods unsuitable on the mobile device, especially for the high-resolution per-pixel semantic segmentation task. In this paper, we introduce a new method squeeze-enhanced Axial TransFormer (SeaFormer) for mobile semantic segmentation. Specifically, we design a generic attention block characterized by the formulation of squeeze Axial and detail enhancement. It can be further used to create a family of backbone architectures with superior cost-effectiveness. Coupled with a light segmentation head, we achieve the best trade-off between segmentation accuracy and latency on the ARM-based mobile devices on the ADE20K and Cityscapes datasets. Critically, we beat both the mobile-friendly rivals and Transformer-based counterparts with better performance and lower latency without bells and whistles. Beyond semantic segmentation, we further apply the proposed SeaFormer architecture to image classification problem, demonstrating the potentials of serving as a versatile mobile-friendly backbone.
Multi-organ segmentation: a progressive exploration of learning paradigms under scarce annotation
Feb 09, 2023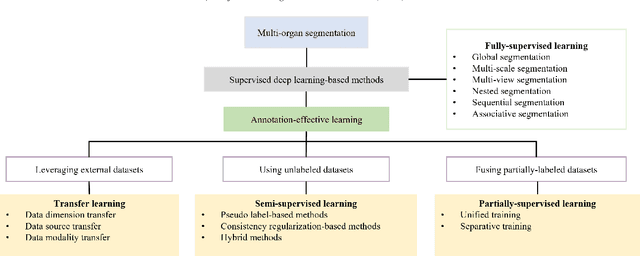
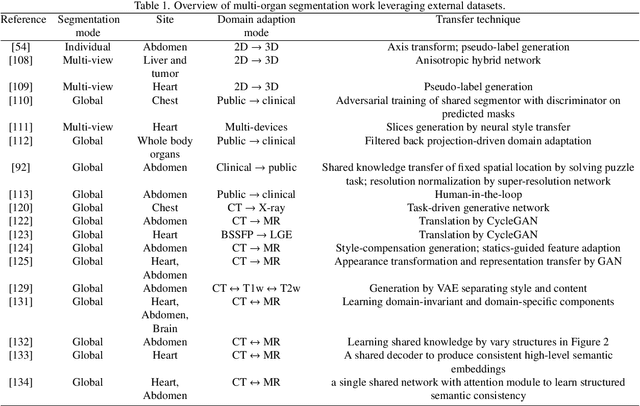
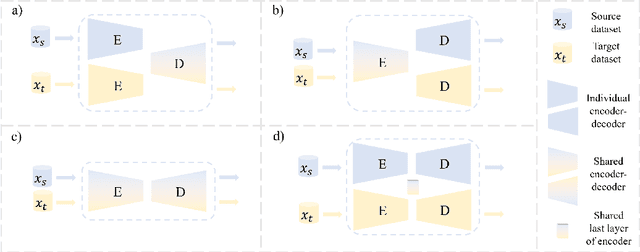

Precise delineation of multiple organs or abnormal regions in the human body from medical images plays an essential role in computer-aided diagnosis, surgical simulation, image-guided interventions, and especially in radiotherapy treatment planning. Thus, it is of great significance to explore automatic segmentation approaches, among which deep learning-based approaches have evolved rapidly and witnessed remarkable progress in multi-organ segmentation. However, obtaining an appropriately sized and fine-grained annotated dataset of multiple organs is extremely hard and expensive. Such scarce annotation limits the development of high-performance multi-organ segmentation models but promotes many annotation-efficient learning paradigms. Among these, studies on transfer learning leveraging external datasets, semi-supervised learning using unannotated datasets and partially-supervised learning integrating partially-labeled datasets have led the dominant way to break such dilemma in multi-organ segmentation. We first review the traditional fully supervised method, then present a comprehensive and systematic elaboration of the 3 abovementioned learning paradigms in the context of multi-organ segmentation from both technical and methodological perspectives, and finally summarize their challenges and future trends.