 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-view Kernel PCA for Time series Forecasting
Jan 24, 2023

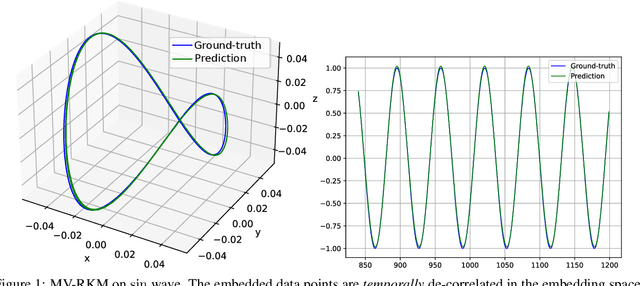
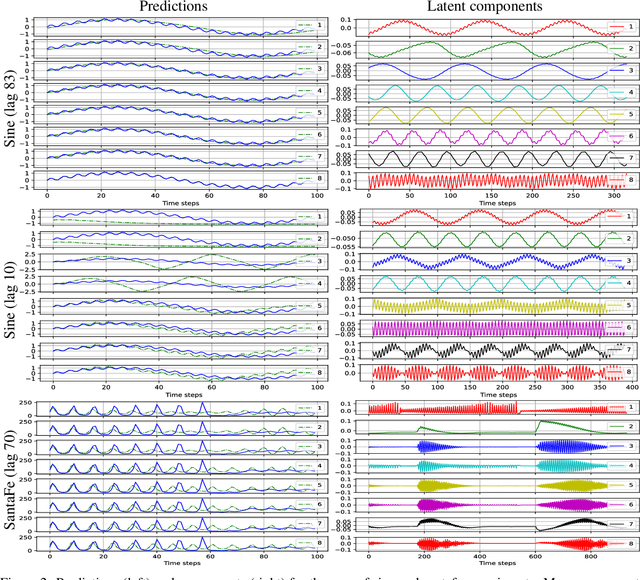
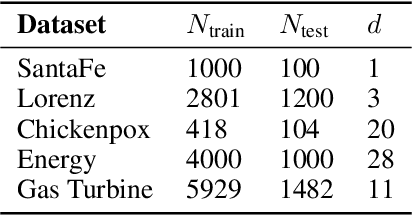
In this paper, we propose a kernel principal component analysis model for multi-variate time series forecasting, where the training and prediction schemes are derived from the multi-view formulation of Restricted Kernel Machines. The training problem is simply an eigenvalue decomposition of the summation of two kernel matrices corresponding to the views of the input and output data. When a linear kernel is used for the output view, it is shown that the forecasting equation takes the form of kernel ridge regression. When that kernel is non-linear, a pre-image problem has to be solved to forecast a point in the input space. We evaluate the model on several standard time series datasets, perform ablation studies, benchmark with closely related models and discuss its results.
Adaptive Edge Offloading for Image Classification Under Rate Limit
Jul 31, 2022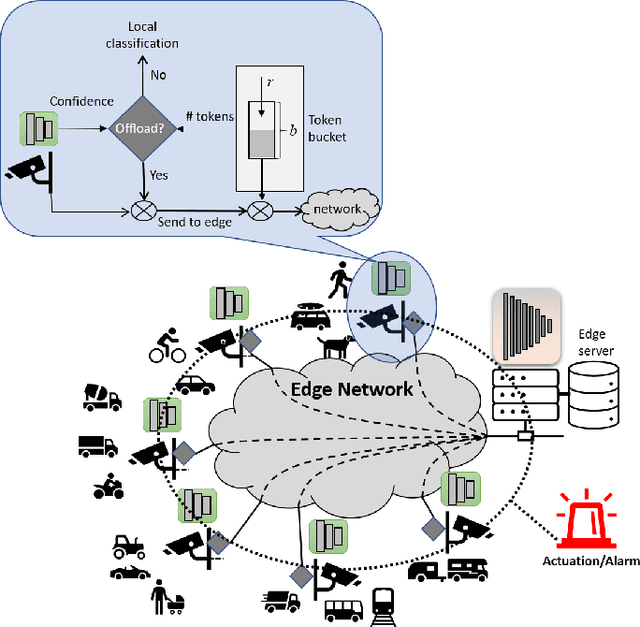
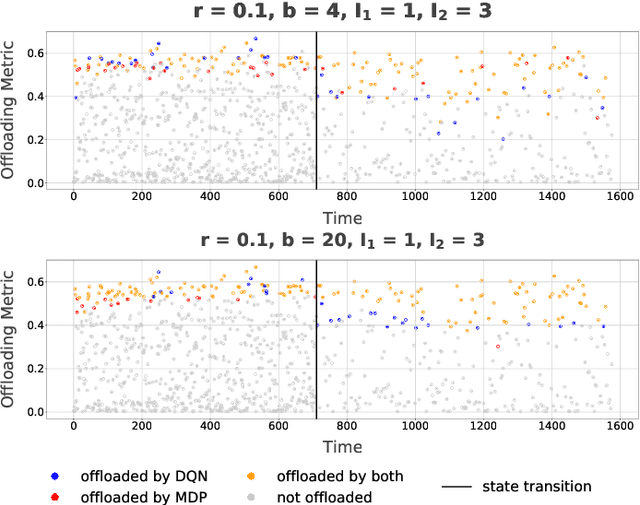
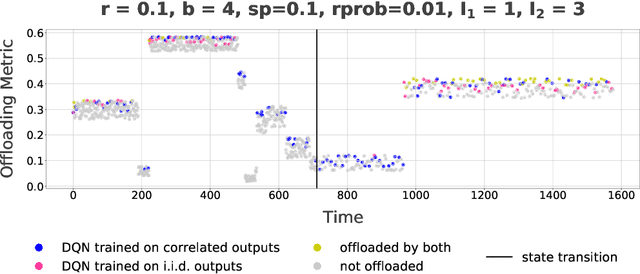
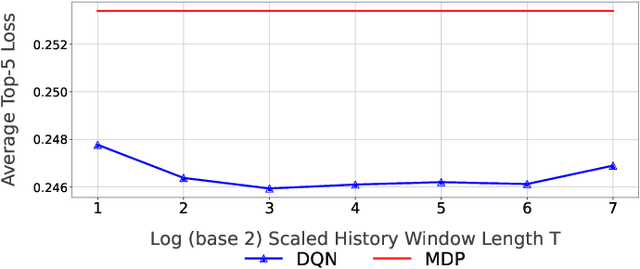
This paper considers a setting where embedded devices are used to acquire and classify images. Because of limited computing capacity, embedded devices rely on a parsimonious classification model with uneven accuracy. When local classification is deemed inaccurate, devices can decide to offload the image to an edge server with a more accurate but resource-intensive model. Resource constraints, e.g., network bandwidth, however, require regulating such transmissions to avoid congestion and high latency. The paper investigates this offloading problem when transmissions regulation is through a token bucket, a mechanism commonly used for such purposes. The goal is to devise a lightweight, online offloading policy that optimizes an application-specific metric (e.g., classification accuracy) under the constraints of the token bucket. The paper develops a policy based on a Deep Q-Network (DQN), and demonstrates both its efficacy and the feasibility of its deployment on embedded devices. Of note is the fact that the policy can handle complex input patterns, including correlation in image arrivals and classification accuracy. The evaluation is carried out by performing image classification over a local testbed using synthetic traces generated from the ImageNet image classification benchmark. Implementation of this work is available at https://github.com/qiujiaming315/edgeml-dqn.
Point Cloud-based Proactive Link Quality Prediction for Millimeter-wave Communications
Jan 02, 2023
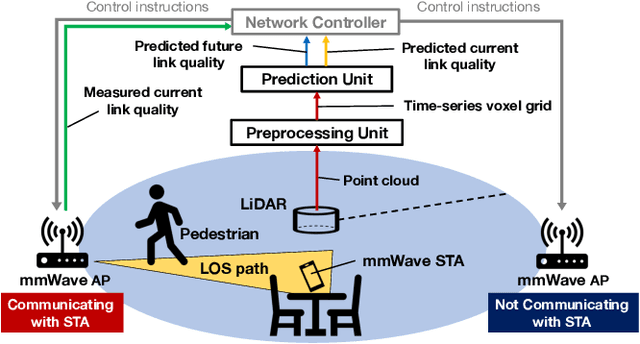
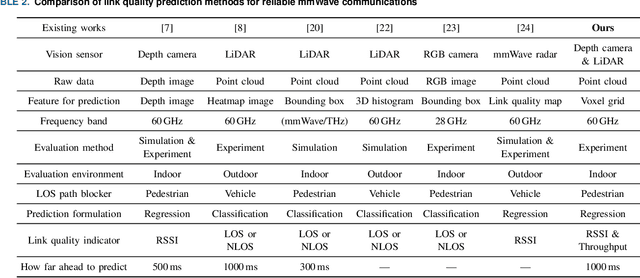
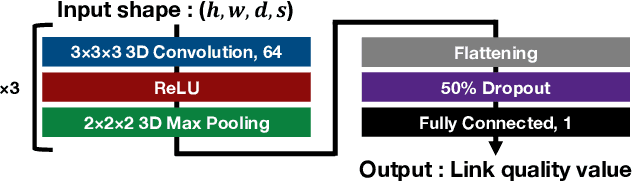
This study demonstrates the feasibility of point cloud-based proactive link quality prediction for millimeter-wave (mmWave) communications. Image-based methods to quantitatively and deterministically predict future received signal strength using machine learning from time series of depth images to mitigate the human body line-of-sight (LOS) path blockage in mmWave communications have been proposed. However, image-based methods have been limited in applicable environments because camera images may contain private information. Thus, this study demonstrates the feasibility of using point clouds obtained from light detection and ranging (LiDAR) for the mmWave link quality prediction. Point clouds represent three-dimensional (3D) spaces as a set of points and are sparser and less likely to contain sensitive information than camera images. Additionally, point clouds provide 3D position and motion information, which is necessary for understanding the radio propagation environment involving pedestrians. This study designs the mmWave link quality prediction method and conducts two experimental evaluations using different types of point clouds obtained from LiDAR and depth cameras, as well as different numerical indicators of link quality, received signal strength and throughput. Based on these experiments, our proposed method can predict future large attenuation of mmWave link quality due to LOS blockage by human bodies, therefore our point cloud-based method can be an alternative to image-based methods.
MetaNO: How to Transfer Your Knowledge on Learning Hidden Physics
Feb 03, 2023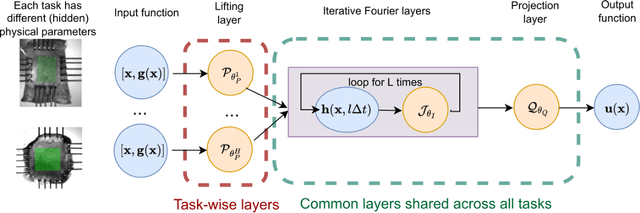
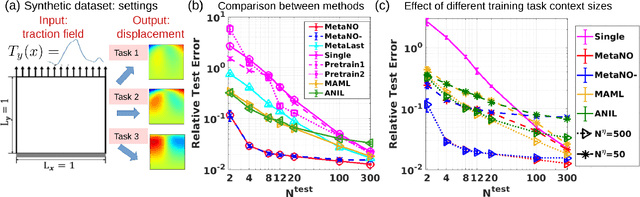
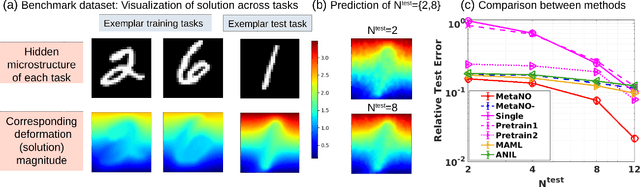
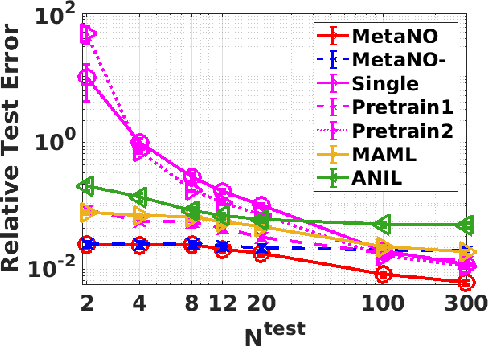
Gradient-based meta-learning methods have primarily been applied to classical machine learning tasks such as image classification. Recently, PDE-solving deep learning methods, such as neural operators, are starting to make an important impact on learning and predicting the response of a complex physical system directly from observational data. Since the data acquisition in this context is commonly challenging and costly, the call of utilization and transfer of existing knowledge to new and unseen physical systems is even more acute. Herein, we propose a novel meta-learning approach for neural operators, which can be seen as transferring the knowledge of solution operators between governing (unknown) PDEs with varying parameter fields. Our approach is a provably universal solution operator for multiple PDE solving tasks, with a key theoretical observation that underlying parameter fields can be captured in the first layer of neural operator models, in contrast to typical final-layer transfer in existing meta-learning methods. As applications, we demonstrate the efficacy of our proposed approach on PDE-based datasets and a real-world material modeling problem, illustrating that our method can handle complex and nonlinear physical response learning tasks while greatly improving the sampling efficiency in unseen tasks.
Privacy-Preserving Image Classification Using ConvMixer with Adaptive Permutation Matrix
Aug 04, 2022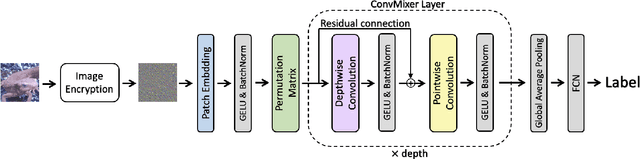

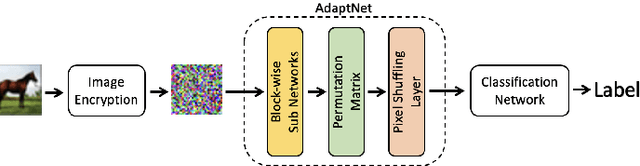
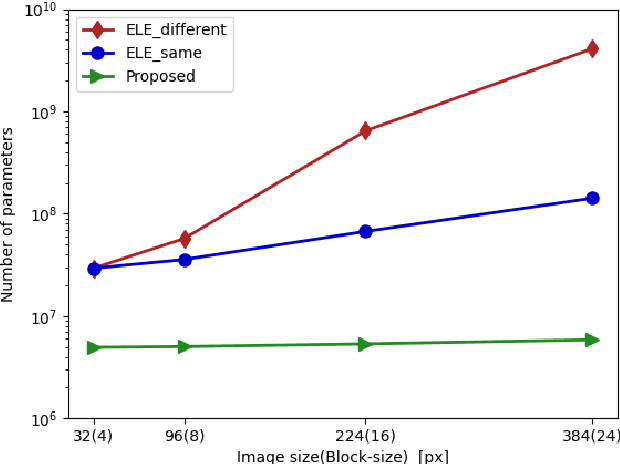
In this paper, we propose a privacy-preserving image classification method using encrypted images under the use of the ConvMixer structure. Block-wise scrambled images, which are robust enough against various attacks, have been used for privacy-preserving image classification tasks, but the combined use of a classification network and an adaptation network is needed to reduce the influence of image encryption. However, images with a large size cannot be applied to the conventional method with an adaptation network because the adaptation network has so many parameters. Accordingly, we propose a novel method, which allows us not only to apply block-wise scrambled images to ConvMixer for both training and testing without the adaptation network, but also to provide a higher classification accuracy than conventional methods.
Explicit Image Caption Editing
Jul 20, 2022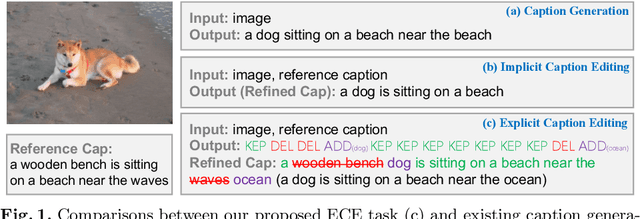
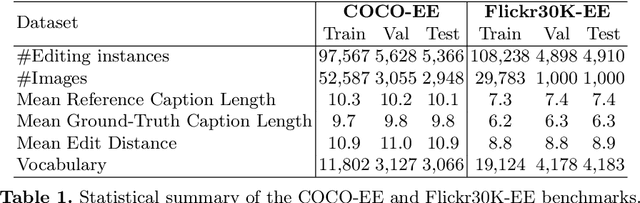

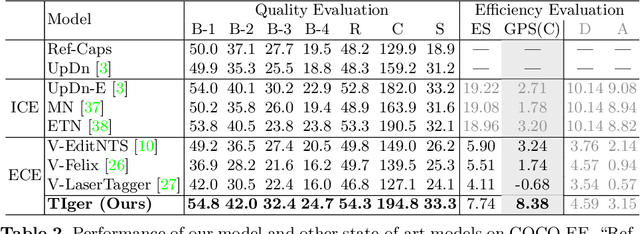
Given an image and a reference caption, the image caption editing task aims to correct the misalignment errors and generate a refined caption. However, all existing caption editing works are implicit models, ie, they directly produce the refined captions without explicit connections to the reference captions. In this paper, we introduce a new task: Explicit Caption Editing (ECE). ECE models explicitly generate a sequence of edit operations, and this edit operation sequence can translate the reference caption into a refined one. Compared to the implicit editing, ECE has multiple advantages: 1) Explainable: it can trace the whole editing path. 2) Editing Efficient: it only needs to modify a few words. 3) Human-like: it resembles the way that humans perform caption editing, and tries to keep original sentence structures. To solve this new task, we propose the first ECE model: TIger. TIger is a non-autoregressive transformer-based model, consisting of three modules: Tagger_del, Tagger_add, and Inserter. Specifically, Tagger_del decides whether each word should be preserved or not, Tagger_add decides where to add new words, and Inserter predicts the specific word for adding. To further facilitate ECE research, we propose two new ECE benchmarks by re-organizing two existing datasets, dubbed COCO-EE and Flickr30K-EE, respectively. Extensive ablations on both two benchmarks have demonstrated the effectiveness of TIger.
Supervision Complexity and its Role in Knowledge Distillation
Jan 28, 2023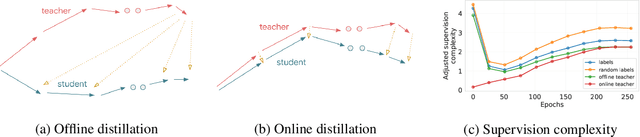


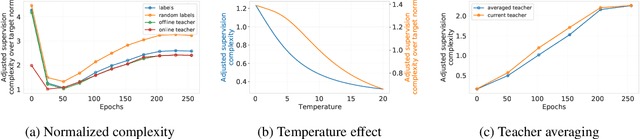
Despite the popularity and efficacy of knowledge distillation, there is limited understanding of why it helps. In order to study the generalization behavior of a distilled student, we propose a new theoretical framework that leverages supervision complexity: a measure of alignment between teacher-provided supervision and the student's neural tangent kernel. The framework highlights a delicate interplay among the teacher's accuracy, the student's margin with respect to the teacher predictions, and the complexity of the teacher predictions. Specifically, it provides a rigorous justification for the utility of various techniques that are prevalent in the context of distillation, such as early stopping and temperature scaling. Our analysis further suggests the use of online distillation, where a student receives increasingly more complex supervision from teachers in different stages of their training. We demonstrate efficacy of online distillation and validate the theoretical findings on a range of image classification benchmarks and model architectures.
Swin MAE: Masked Autoencoders for Small Datasets
Jan 05, 2023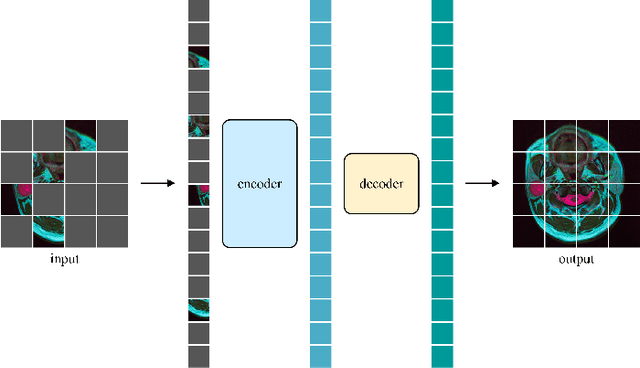
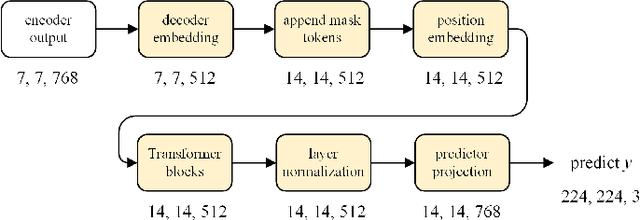
The development of deep learning models in medical image analysis is majorly limited by the lack of large-sized and well-annotated datasets. Unsupervised learning does not require labels and is more suitable for solving medical image analysis problems. However, most of the current unsupervised learning methods need to be applied to large datasets. To make unsupervised learning applicable to small datasets, we proposed Swin MAE, which is a masked autoencoder with Swin Transformer as its backbone. Even on a dataset of only a few thousand medical images and without using any pre-trained models, Swin MAE is still able to learn useful semantic features purely from images. It can equal or even slightly outperform the supervised model obtained by Swin Transformer trained on ImageNet in terms of the transfer learning results of downstream tasks. The code is publicly available at https://github.com/Zian-Xu/Swin-MAE.
Learning Multimodal Data Augmentation in Feature Space
Dec 29, 2022

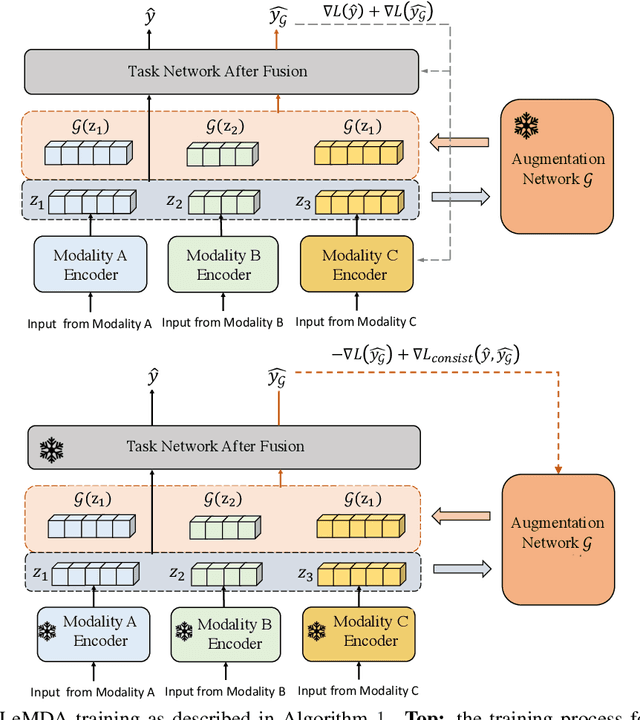
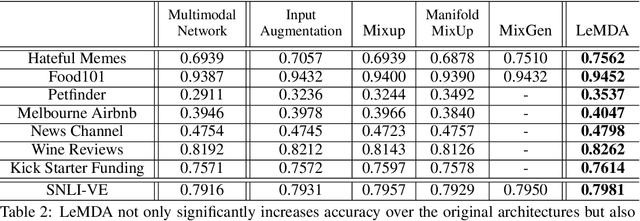
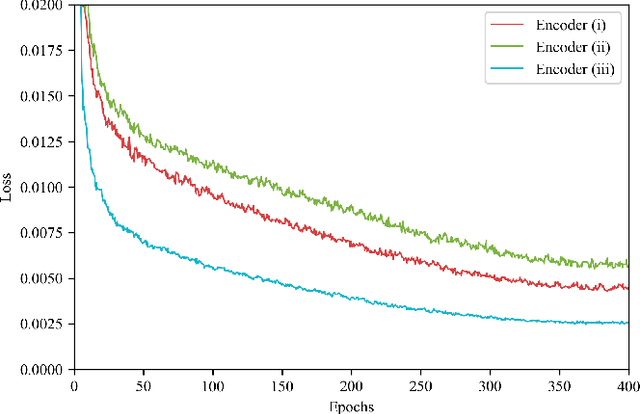
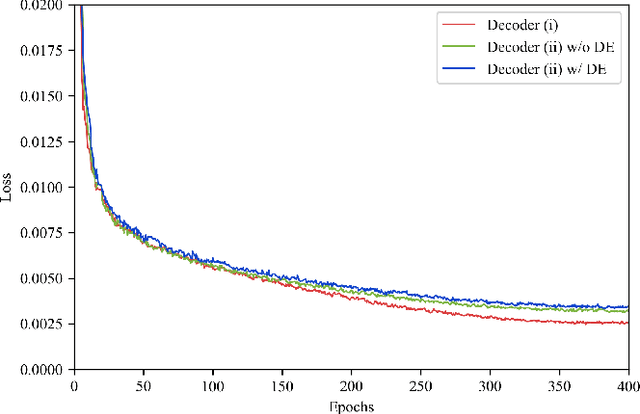
The ability to jointly learn from multiple modalities, such as text, audio, and visual data, is a defining feature of intelligent systems. While there have been promising advances in designing neural networks to harness multimodal data, the enormous success of data augmentation currently remains limited to single-modality tasks like image classification. Indeed, it is particularly difficult to augment each modality while preserving the overall semantic structure of the data; for example, a caption may no longer be a good description of an image after standard augmentations have been applied, such as translation. Moreover, it is challenging to specify reasonable transformations that are not tailored to a particular modality. In this paper, we introduce LeMDA, Learning Multimodal Data Augmentation, an easy-to-use method that automatically learns to jointly augment multimodal data in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that LeMDA can (1) profoundly improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data.
Computational Pathology for Brain Disorders
Jan 13, 2023
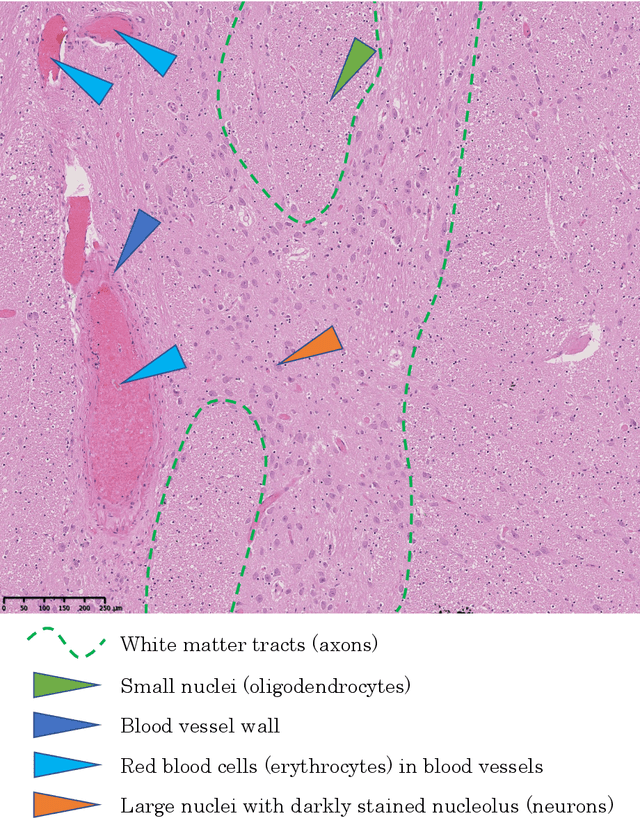
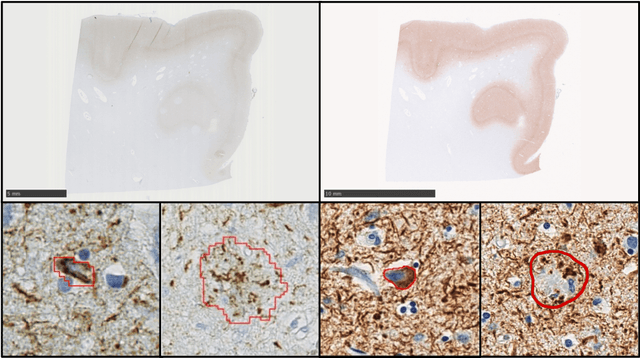
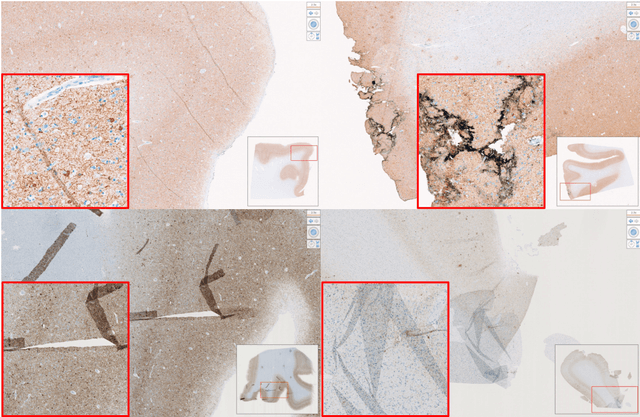
Non-invasive brain imaging techniques allow understanding the behavior and macro changes in the brain to determine the progress of a disease. However, computational pathology provides a deeper understanding of brain disorders at cellular level, able to consolidate a diagnosis and make the bridge between the medical image and the omics analysis. In traditional histopathology, histology slides are visually inspected, under the microscope, by trained pathologists. This process is time-consuming and labor-intensive; therefore, the emergence of Computational Pathology has triggered great hope to ease this tedious task and make it more robust. This chapter focuses on understanding the state-of-the-art machine learning techniques used to analyze whole slide images within the context of brain disorders. We present a selective set of remarkable machine learning algorithms providing discriminative approaches and quality results on brain disorders. These methodologies are applied to different tasks, such as monitoring mechanisms contributing to disease progression and patient survival rates, analyzing morphological phenotypes for classification and quantitative assessment of disease, improving clinical care, diagnosing tumor specimens, and intraoperative interpretation. Thanks to the recent progress in machine learning algorithms for high-content image processing, computational pathology marks the rise of a new generation of medical discoveries and clinical protocols, including in brain disorders.