 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiplane Quantitative Phase Imaging Using a Wavelength-Multiplexed Diffractive Optical Processor
Mar 16, 2024
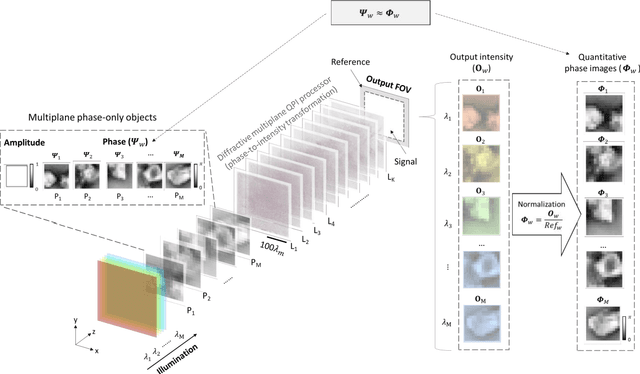
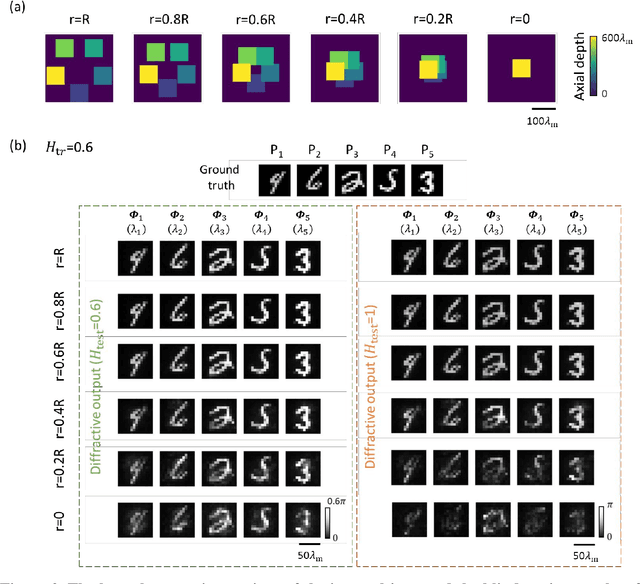
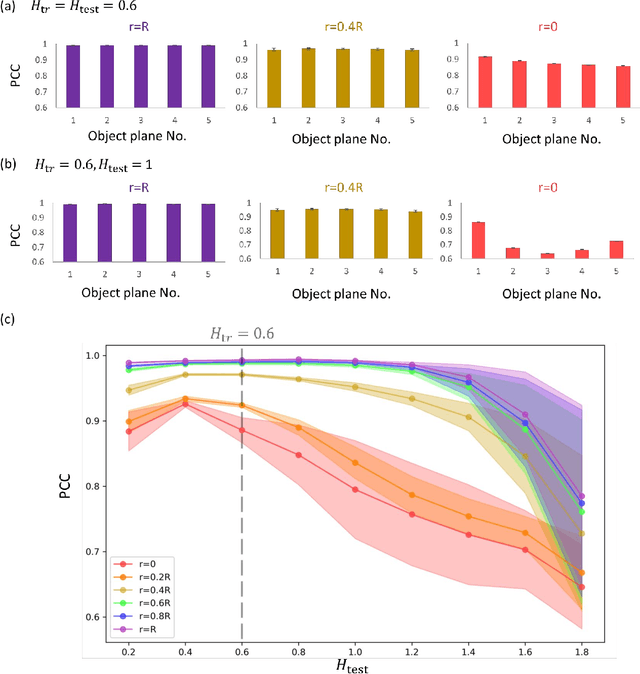
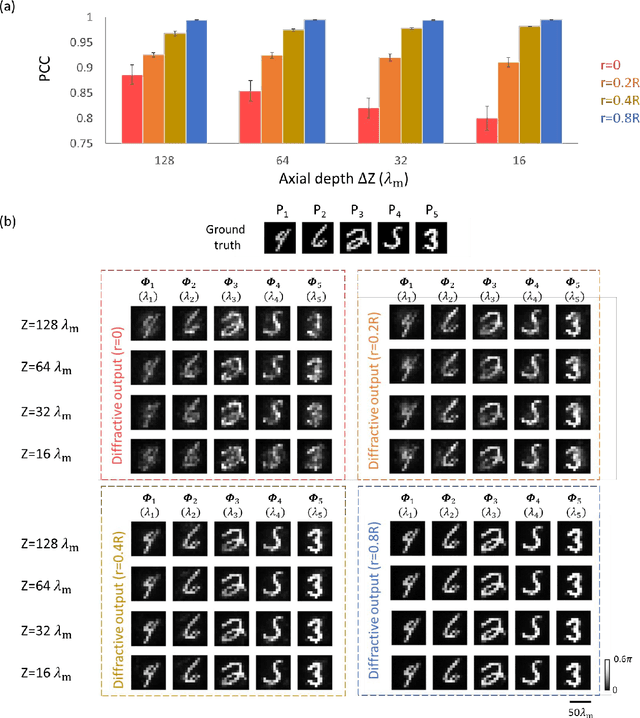
Quantitative phase imaging (QPI) is a label-free technique that provides optical path length information for transparent specimens, finding utility in biology, materials science, and engineering. Here, we present quantitative phase imaging of a 3D stack of phase-only objects using a wavelength-multiplexed diffractive optical processor. Utilizing multiple spatially engineered diffractive layers trained through deep learning, this diffractive processor can transform the phase distributions of multiple 2D objects at various axial positions into intensity patterns, each encoded at a unique wavelength channel. These wavelength-multiplexed patterns are projected onto a single field-of-view (FOV) at the output plane of the diffractive processor, enabling the capture of quantitative phase distributions of input objects located at different axial planes using an intensity-only image sensor. Based on numerical simulations, we show that our diffractive processor could simultaneously achieve all-optical quantitative phase imaging across several distinct axial planes at the input by scanning the illumination wavelength. A proof-of-concept experiment with a 3D-fabricated diffractive processor further validated our approach, showcasing successful imaging of two distinct phase objects at different axial positions by scanning the illumination wavelength in the terahertz spectrum. Diffractive network-based multiplane QPI designs can open up new avenues for compact on-chip phase imaging and sensing devices.
SF(DA)$^2$: Source-free Domain Adaptation Through the Lens of Data Augmentation
Mar 16, 2024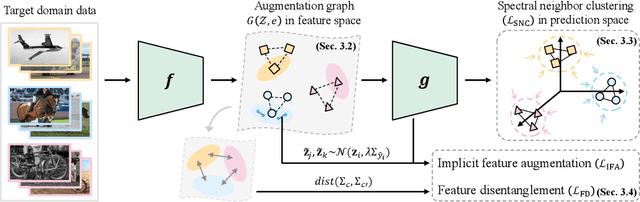
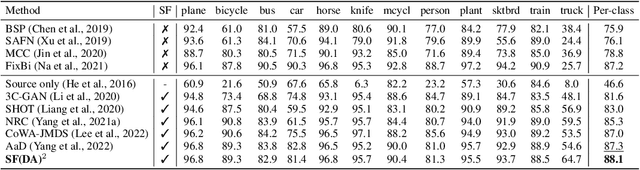
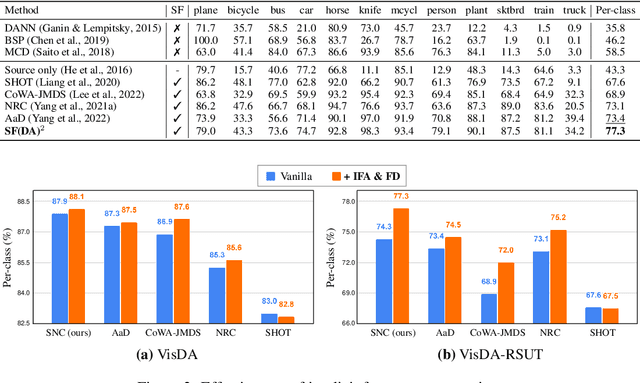
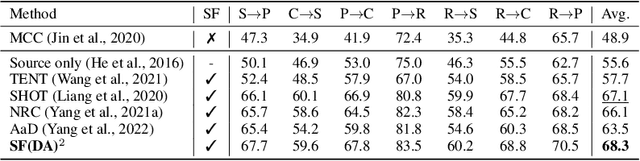
In the face of the deep learning model's vulnerability to domain shift, source-free domain adaptation (SFDA) methods have been proposed to adapt models to new, unseen target domains without requiring access to source domain data. Although the potential benefits of applying data augmentation to SFDA are attractive, several challenges arise such as the dependence on prior knowledge of class-preserving transformations and the increase in memory and computational requirements. In this paper, we propose Source-free Domain Adaptation Through the Lens of Data Augmentation (SF(DA)$^2$), a novel approach that leverages the benefits of data augmentation without suffering from these challenges. We construct an augmentation graph in the feature space of the pretrained model using the neighbor relationships between target features and propose spectral neighborhood clustering to identify partitions in the prediction space. Furthermore, we propose implicit feature augmentation and feature disentanglement as regularization loss functions that effectively utilize class semantic information within the feature space. These regularizers simulate the inclusion of an unlimited number of augmented target features into the augmentation graph while minimizing computational and memory demands. Our method shows superior adaptation performance in SFDA scenarios, including 2D image and 3D point cloud datasets and a highly imbalanced dataset.
Segment Any Object Model (SAOM): Real-to-Simulation Fine-Tuning Strategy for Multi-Class Multi-Instance Segmentation
Mar 16, 2024

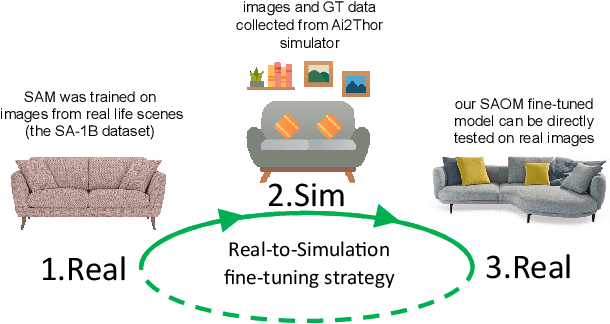
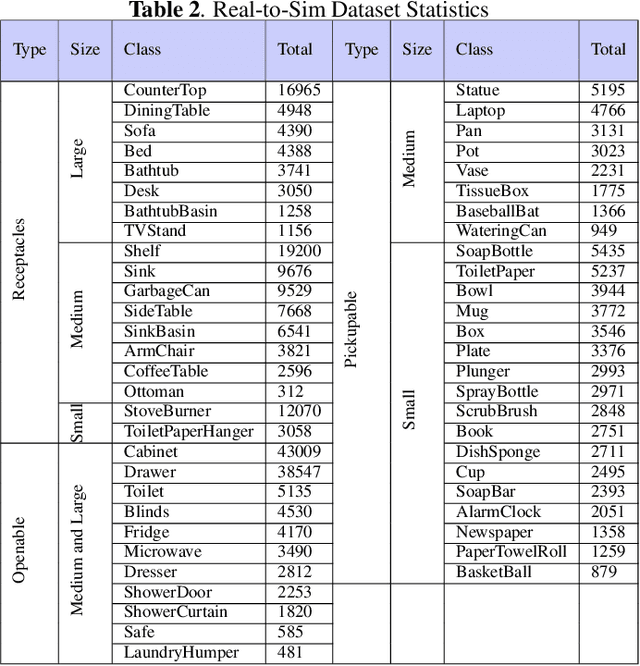
Multi-class multi-instance segmentation is the task of identifying masks for multiple object classes and multiple instances of the same class within an image. The foundational Segment Anything Model (SAM) is designed for promptable multi-class multi-instance segmentation but tends to output part or sub-part masks in the "everything" mode for various real-world applications. Whole object segmentation masks play a crucial role for indoor scene understanding, especially in robotics applications. We propose a new domain invariant Real-to-Simulation (Real-Sim) fine-tuning strategy for SAM. We use object images and ground truth data collected from Ai2Thor simulator during fine-tuning (real-to-sim). To allow our Segment Any Object Model (SAOM) to work in the "everything" mode, we propose the novel nearest neighbour assignment method, updating point embeddings for each ground-truth mask. SAOM is evaluated on our own dataset collected from Ai2Thor simulator. SAOM significantly improves on SAM, with a 28% increase in mIoU and a 25% increase in mAcc for 54 frequently-seen indoor object classes. Moreover, our Real-to-Simulation fine-tuning strategy demonstrates promising generalization performance in real environments without being trained on the real-world data (sim-to-real). The dataset and the code will be released after publication.
From Canteen Food to Daily Meals: Generalizing Food Recognition to More Practical Scenarios
Mar 12, 2024


The precise recognition of food categories plays a pivotal role for intelligent health management, attracting significant research attention in recent years. Prominent benchmarks, such as Food-101 and VIREO Food-172, provide abundant food image resources that catalyze the prosperity of research in this field. Nevertheless, these datasets are well-curated from canteen scenarios and thus deviate from food appearances in daily life. This discrepancy poses great challenges in effectively transferring classifiers trained on these canteen datasets to broader daily-life scenarios encountered by humans. Toward this end, we present two new benchmarks, namely DailyFood-172 and DailyFood-16, specifically designed to curate food images from everyday meals. These two datasets are used to evaluate the transferability of approaches from the well-curated food image domain to the everyday-life food image domain. In addition, we also propose a simple yet effective baseline method named Multi-Cluster Reference Learning (MCRL) to tackle the aforementioned domain gap. MCRL is motivated by the observation that food images in daily-life scenarios exhibit greater intra-class appearance variance compared with those in well-curated benchmarks. Notably, MCRL can be seamlessly coupled with existing approaches, yielding non-trivial performance enhancements. We hope our new benchmarks can inspire the community to explore the transferability of food recognition models trained on well-curated datasets toward practical real-life applications.
IMPRINT: Generative Object Compositing by Learning Identity-Preserving Representation
Mar 15, 2024
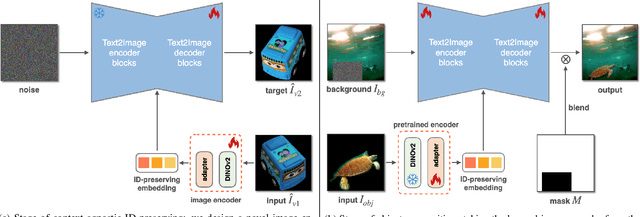
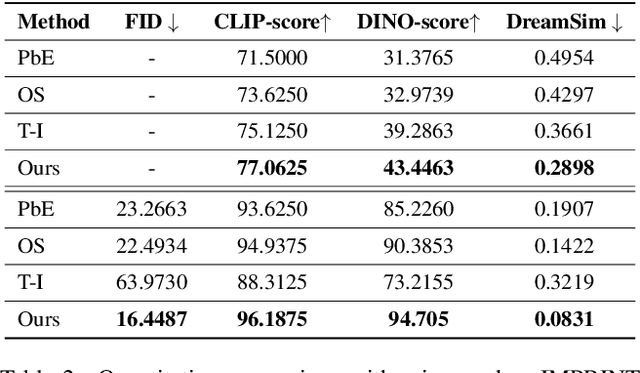
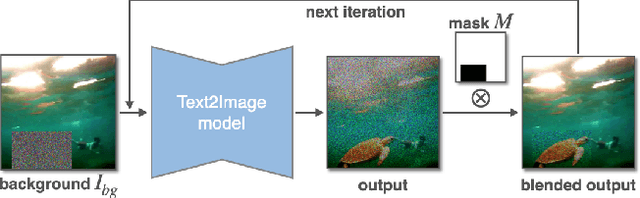
Generative object compositing emerges as a promising new avenue for compositional image editing. However, the requirement of object identity preservation poses a significant challenge, limiting practical usage of most existing methods. In response, this paper introduces IMPRINT, a novel diffusion-based generative model trained with a two-stage learning framework that decouples learning of identity preservation from that of compositing. The first stage is targeted for context-agnostic, identity-preserving pretraining of the object encoder, enabling the encoder to learn an embedding that is both view-invariant and conducive to enhanced detail preservation. The subsequent stage leverages this representation to learn seamless harmonization of the object composited to the background. In addition, IMPRINT incorporates a shape-guidance mechanism offering user-directed control over the compositing process. Extensive experiments demonstrate that IMPRINT significantly outperforms existing methods and various baselines on identity preservation and composition quality.
SWAG: Splatting in the Wild images with Appearance-conditioned Gaussians
Mar 15, 2024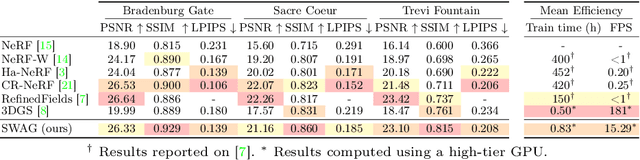
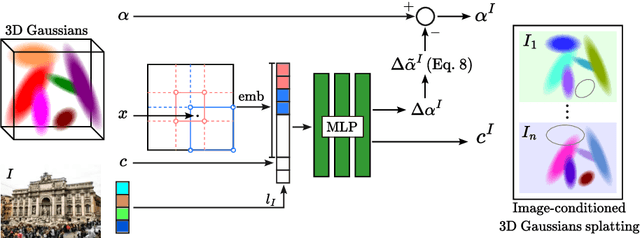
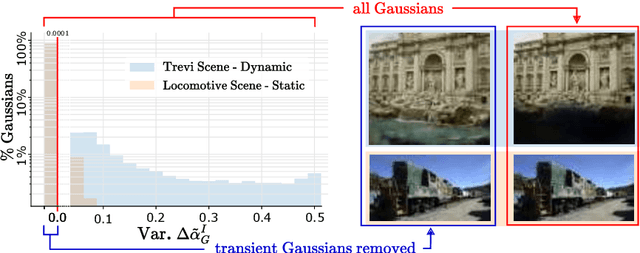
Implicit neural representation methods have shown impressive advancements in learning 3D scenes from unstructured in-the-wild photo collections but are still limited by the large computational cost of volumetric rendering. More recently, 3D Gaussian Splatting emerged as a much faster alternative with superior rendering quality and training efficiency, especially for small-scale and object-centric scenarios. Nevertheless, this technique suffers from poor performance on unstructured in-the-wild data. To tackle this, we extend over 3D Gaussian Splatting to handle unstructured image collections. We achieve this by modeling appearance to seize photometric variations in the rendered images. Additionally, we introduce a new mechanism to train transient Gaussians to handle the presence of scene occluders in an unsupervised manner. Experiments on diverse photo collection scenes and multi-pass acquisition of outdoor landmarks show the effectiveness of our method over prior works achieving state-of-the-art results with improved efficiency.
PNeSM: Arbitrary 3D Scene Stylization via Prompt-Based Neural Style Mapping
Mar 13, 2024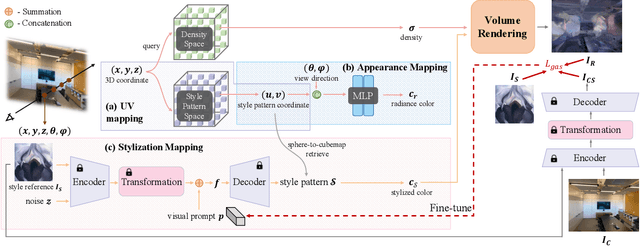

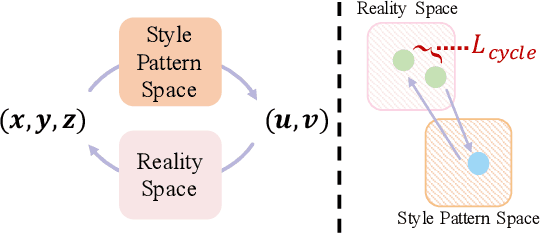

3D scene stylization refers to transform the appearance of a 3D scene to match a given style image, ensuring that images rendered from different viewpoints exhibit the same style as the given style image, while maintaining the 3D consistency of the stylized scene. Several existing methods have obtained impressive results in stylizing 3D scenes. However, the models proposed by these methods need to be re-trained when applied to a new scene. In other words, their models are coupled with a specific scene and cannot adapt to arbitrary other scenes. To address this issue, we propose a novel 3D scene stylization framework to transfer an arbitrary style to an arbitrary scene, without any style-related or scene-related re-training. Concretely, we first map the appearance of the 3D scene into a 2D style pattern space, which realizes complete disentanglement of the geometry and appearance of the 3D scene and makes our model be generalized to arbitrary 3D scenes. Then we stylize the appearance of the 3D scene in the 2D style pattern space via a prompt-based 2D stylization algorithm. Experimental results demonstrate that our proposed framework is superior to SOTA methods in both visual quality and generalization.
Masked Generative Story Transformer with Character Guidance and Caption Augmentation
Mar 13, 2024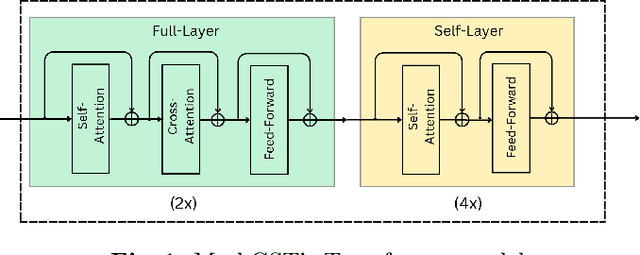
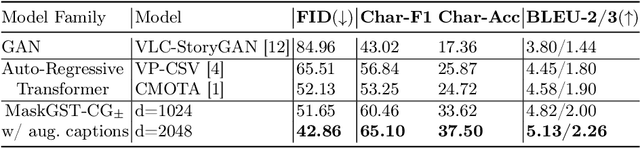

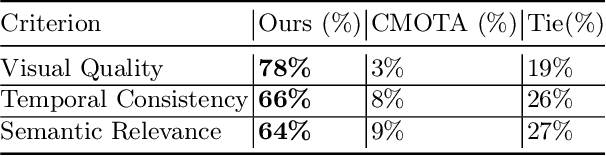
Story Visualization (SV) is a challenging generative vision task, that requires both visual quality and consistency between different frames in generated image sequences. Previous approaches either employ some kind of memory mechanism to maintain context throughout an auto-regressive generation of the image sequence, or model the generation of the characters and their background separately, to improve the rendering of characters. On the contrary, we embrace a completely parallel transformer-based approach, exclusively relying on Cross-Attention with past and future captions to achieve consistency. Additionally, we propose a Character Guidance technique to focus on the generation of characters in an implicit manner, by forming a combination of text-conditional and character-conditional logits in the logit space. We also employ a caption-augmentation technique, carried out by a Large Language Model (LLM), to enhance the robustness of our approach. The combination of these methods culminates into state-of-the-art (SOTA) results over various metrics in the most prominent SV benchmark (Pororo-SV), attained with constraint resources while achieving superior computational complexity compared to previous arts. The validity of our quantitative results is supported by a human survey.
Block and Detail: Scaffolding Sketch-to-Image Generation
Feb 28, 2024We introduce a novel sketch-to-image tool that aligns with the iterative refinement process of artists. Our tool lets users sketch blocking strokes to coarsely represent the placement and form of objects and detail strokes to refine their shape and silhouettes. We develop a two-pass algorithm for generating high-fidelity images from such sketches at any point in the iterative process. In the first pass we use a ControlNet to generate an image that strictly follows all the strokes (blocking and detail) and in the second pass we add variation by renoising regions surrounding blocking strokes. We also present a dataset generation scheme that, when used to train a ControlNet architecture, allows regions that do not contain strokes to be interpreted as not-yet-specified regions rather than empty space. We show that this partial-sketch-aware ControlNet can generate coherent elements from partial sketches that only contain a small number of strokes. The high-fidelity images produced by our approach serve as scaffolds that can help the user adjust the shape and proportions of objects or add additional elements to the composition. We demonstrate the effectiveness of our approach with a variety of examples and evaluative comparisons.
Subobject-level Image Tokenization
Feb 22, 2024Transformer-based vision models typically tokenize images into fixed-size square patches as input units, which lacks the adaptability to image content and overlooks the inherent pixel grouping structure. Inspired by the subword tokenization widely adopted in language models, we propose an image tokenizer at a subobject level, where the subobjects are represented by semantically meaningful image segments obtained by segmentation models (e.g., segment anything models). To implement a learning system based on subobject tokenization, we first introduced a Sequence-to-sequence AutoEncoder (SeqAE) to compress subobject segments of varying sizes and shapes into compact embedding vectors, then fed the subobject embeddings into a large language model for vision language learning. Empirical results demonstrated that our subobject-level tokenization significantly facilitates efficient learning of translating images into object and attribute descriptions compared to the traditional patch-level tokenization. Codes and models will be open-sourced at https://github.com/ChenDelong1999/subobjects.