 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reliability-Aware Prediction via Uncertainty Learning for Person Image Retrieval
Oct 24, 2022
Current person image retrieval methods have achieved great improvements in accuracy metrics. However, they rarely describe the reliability of the prediction. In this paper, we propose an Uncertainty-Aware Learning (UAL) method to remedy this issue. UAL aims at providing reliability-aware predictions by considering data uncertainty and model uncertainty simultaneously. Data uncertainty captures the ``noise" inherent in the sample, while model uncertainty depicts the model's confidence in the sample's prediction. Specifically, in UAL, (1) we propose a sampling-free data uncertainty learning method to adaptively assign weights to different samples during training, down-weighting the low-quality ambiguous samples. (2) we leverage the Bayesian framework to model the model uncertainty by assuming the parameters of the network follow a Bernoulli distribution. (3) the data uncertainty and the model uncertainty are jointly learned in a unified network, and they serve as two fundamental criteria for the reliability assessment: if a probe is high-quality (low data uncertainty) and the model is confident in the prediction of the probe (low model uncertainty), the final ranking will be assessed as reliable. Experiments under the risk-controlled settings and the multi-query settings show the proposed reliability assessment is effective. Our method also shows superior performance on three challenging benchmarks under the vanilla single query settings.
Interpreting wealth distribution via poverty map inference using multimodal data
Feb 17, 2023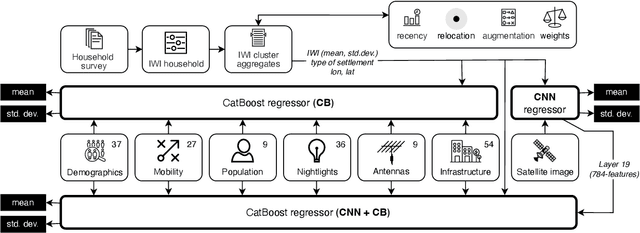
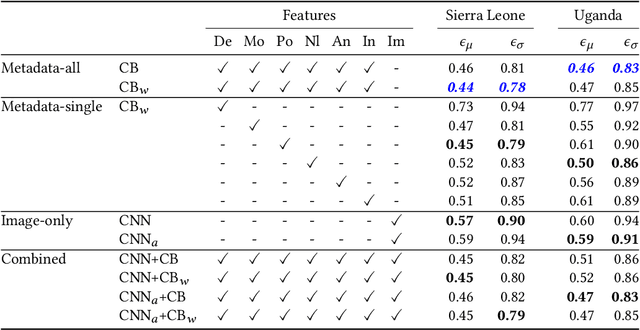
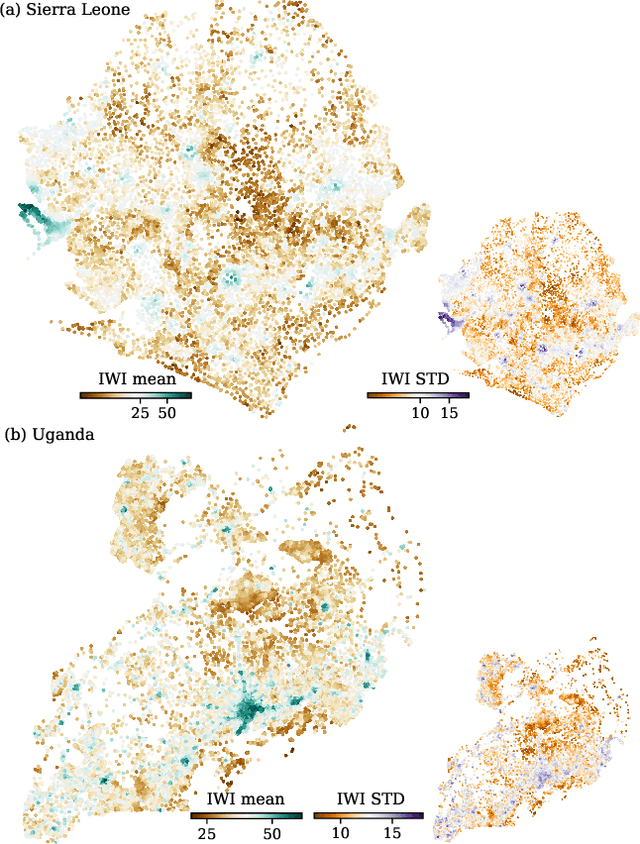
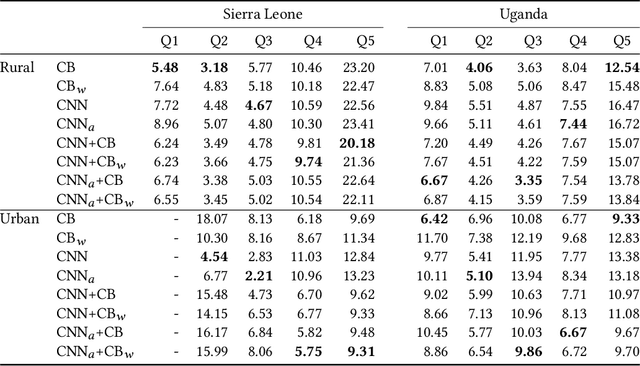
Poverty maps are essential tools for governments and NGOs to track socioeconomic changes and adequately allocate infrastructure and services in places in need. Sensor and online crowd-sourced data combined with machine learning methods have provided a recent breakthrough in poverty map inference. However, these methods do not capture local wealth fluctuations, and are not optimized to produce accountable results that guarantee accurate predictions to all sub-populations. Here, we propose a pipeline of machine learning models to infer the mean and standard deviation of wealth across multiple geographically clustered populated places, and illustrate their performance in Sierra Leone and Uganda. These models leverage seven independent and freely available feature sources based on satellite images, and metadata collected via online crowd-sourcing and social media. Our models show that combined metadata features are the best predictors of wealth in rural areas, outperforming image-based models, which are the best for predicting the highest wealth quintiles. Our results recover the local mean and variation of wealth, and correctly capture the positive yet non-monotonous correlation between them. We further demonstrate the capabilities and limitations of model transfer across countries and the effects of data recency and other biases. Our methodology provides open tools to build towards more transparent and interpretable models to help governments and NGOs to make informed decisions based on data availability, urbanization level, and poverty thresholds.
Apple scab detection in orchards using deep learning on colour and multispectral images
Feb 17, 2023


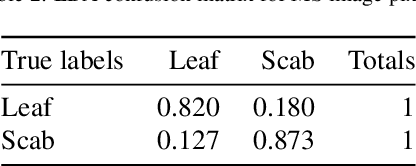
Apple scab is a fungal disease caused by Venturia inaequalis. Disease is of particular concern for growers, as it causes significant damage to fruit and leaves, leading to loss of fruit and yield. This article examines the ability of deep learning and hyperspectral imaging to accurately identify an apple symptom infection in apple trees. In total, 168 image scenes were collected using conventional RGB and Visible to Near-infrared (VIS-NIR) spectral imaging (8 channels) in infected orchards. Spectral data were preprocessed with an Artificial Neural Network (ANN) trained in segmentation to detect scab pixels based on spectral information. Linear Discriminant Analysis (LDA) was used to find the most discriminating channels in spectral data based on the healthy leaf and scab infested leaf spectra. Five combinations of false-colour images were created from the spectral data and the segmentation net results. The images were trained and evaluated with a modified version of the YOLOv5 network. Despite the promising results of deep learning using RGB images (P=0.8, mAP@50=0.73), the detection of apple scab in apple trees using multispectral imaging proved to be a difficult task. The high-light environment of the open field made it difficult to collect a balanced spectrum from the multispectral camera, since the infrared channel and the visible channels needed to be constantly balanced so that they did not overexpose in the images.
Efficient subtyping of ovarian cancer histopathology whole slide images using active sampling in multiple instance learning
Feb 17, 2023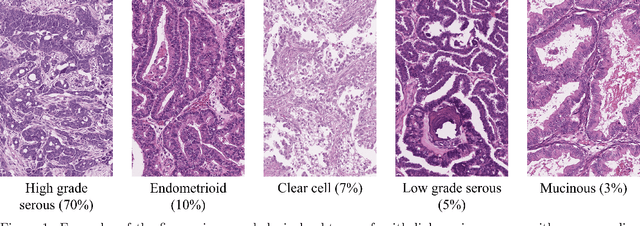

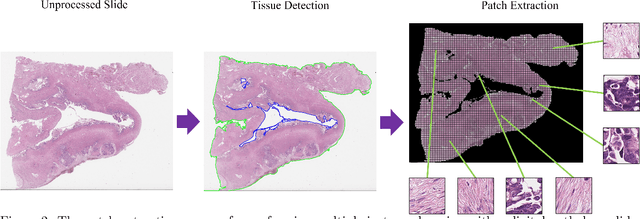
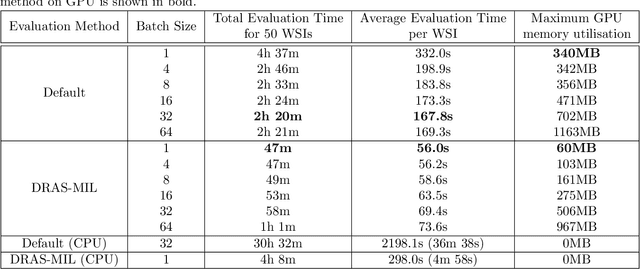
Weakly-supervised classification of histopathology slides is a computationally intensive task, with a typical whole slide image (WSI) containing billions of pixels to process. We propose Discriminative Region Active Sampling for Multiple Instance Learning (DRAS-MIL), a computationally efficient slide classification method using attention scores to focus sampling on highly discriminative regions. We apply this to the diagnosis of ovarian cancer histological subtypes, which is an essential part of the patient care pathway as different subtypes have different genetic and molecular profiles, treatment options, and patient outcomes. We use a dataset of 714 WSIs acquired from 147 epithelial ovarian cancer patients at Leeds Teaching Hospitals NHS Trust to distinguish the most common subtype, high-grade serous carcinoma, from the other four subtypes (low-grade serous, endometrioid, clear cell, and mucinous carcinomas) combined. We demonstrate that DRAS-MIL can achieve similar classification performance to exhaustive slide analysis, with a 3-fold cross-validated AUC of 0.8679 compared to 0.8781 with standard attention-based MIL classification. Our approach uses at most 18% as much memory as the standard approach, while taking 33% of the time when evaluating on a GPU and only 14% on a CPU alone. Reducing prediction time and memory requirements may benefit clinical deployment and the democratisation of AI, reducing the extent to which computational hardware limits end-user adoption.
Differentiable Outlier Detection Enable Robust Deep Multimodal Analysis
Feb 11, 2023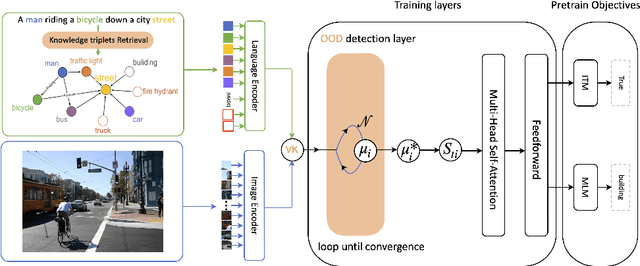
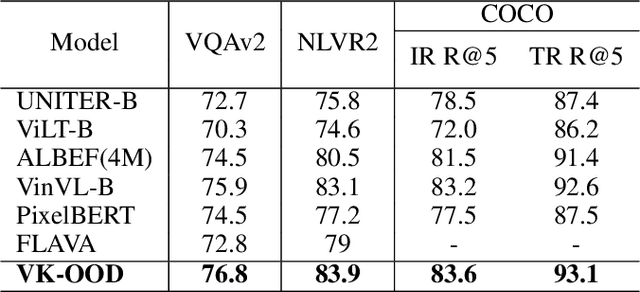

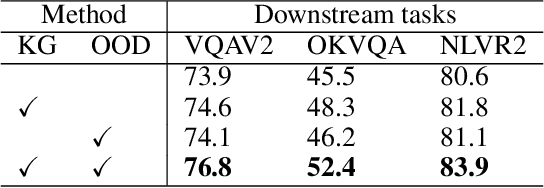
Often, deep network models are purely inductive during training and while performing inference on unseen data. Thus, when such models are used for predictions, it is well known that they often fail to capture the semantic information and implicit dependencies that exist among objects (or concepts) on a population level. Moreover, it is still unclear how domain or prior modal knowledge can be specified in a backpropagation friendly manner, especially in large-scale and noisy settings. In this work, we propose an end-to-end vision and language model incorporating explicit knowledge graphs. We also introduce an interactive out-of-distribution (OOD) layer using implicit network operator. The layer is used to filter noise that is brought by external knowledge base. In practice, we apply our model on several vision and language downstream tasks including visual question answering, visual reasoning, and image-text retrieval on different datasets. Our experiments show that it is possible to design models that perform similarly to state-of-art results but with significantly fewer samples and training time.
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Aug 21, 2022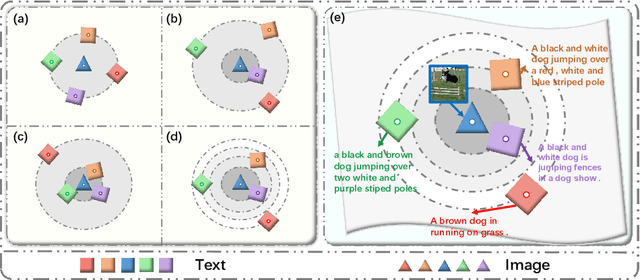
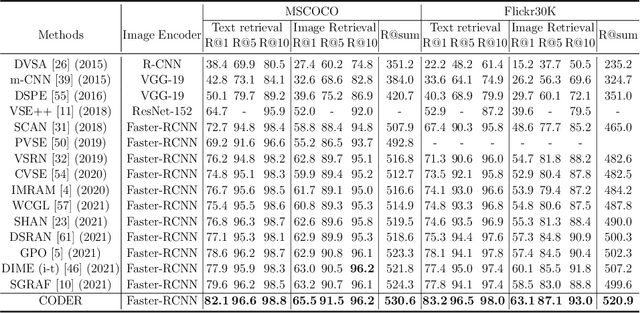
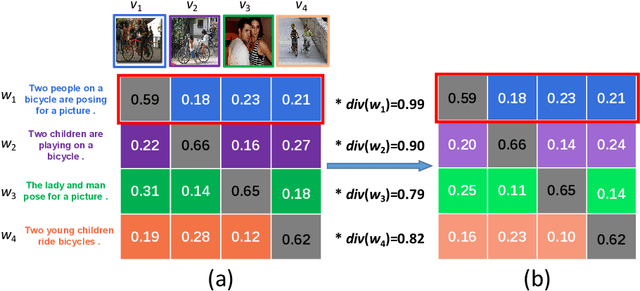
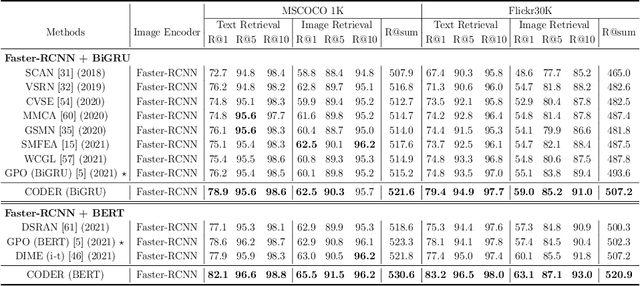
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models
Oct 26, 2022
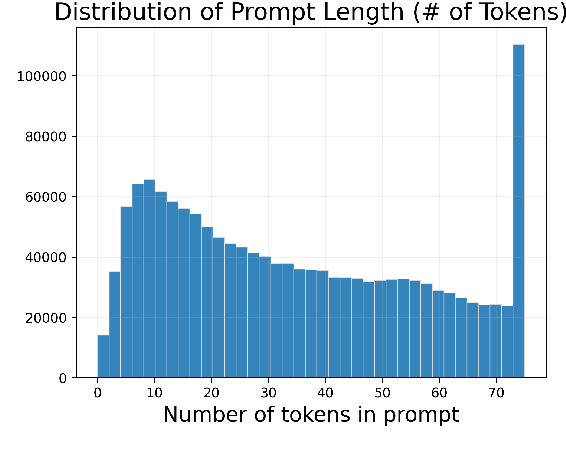
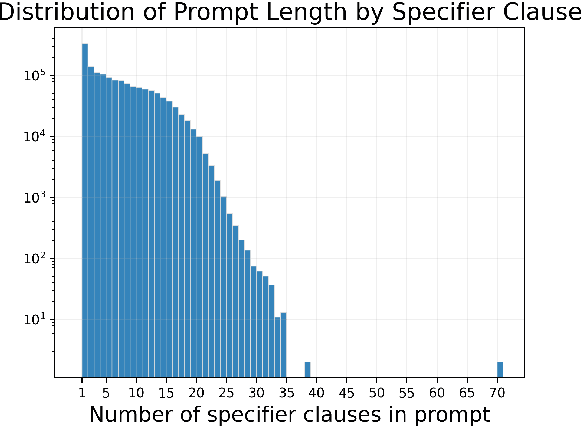
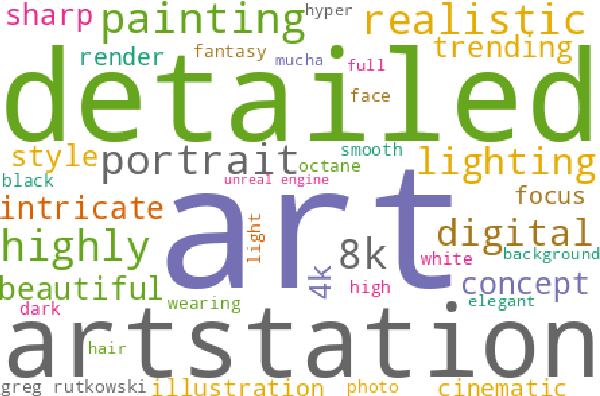
With recent advancements in diffusion models, users can generate high-quality images by writing text prompts in natural language. However, generating images with desired details requires proper prompts, and it is often unclear how a model reacts to different prompts and what the best prompts are. To help researchers tackle these critical challenges, we introduce DiffusionDB, the first large-scale text-to-image prompt dataset. DiffusionDB contains 2 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users. We analyze prompts in the dataset and discuss key properties of these prompts. The unprecedented scale and diversity of this human-actuated dataset provide exciting research opportunities in understanding the interplay between prompts and generative models, detecting deepfakes, and designing human-AI interaction tools to help users more easily use these models. DiffusionDB is publicly available at: https://poloclub.github.io/diffusiondb.
Deformation equivariant cross-modality image synthesis with paired non-aligned training data
Aug 26, 2022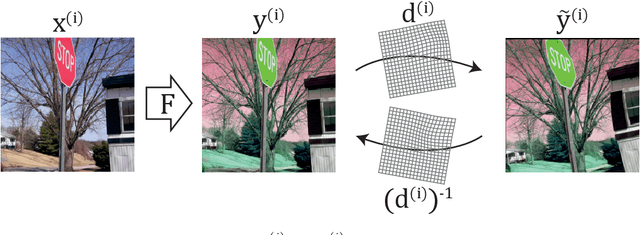
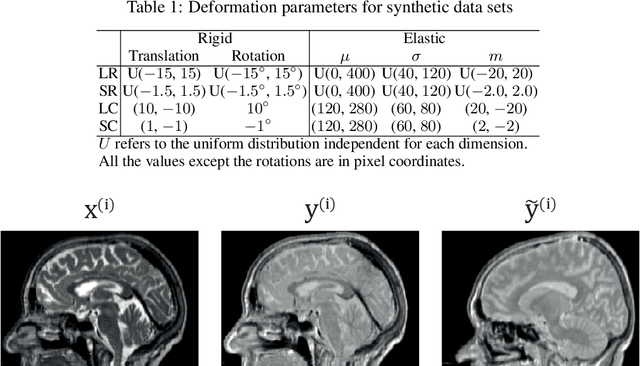
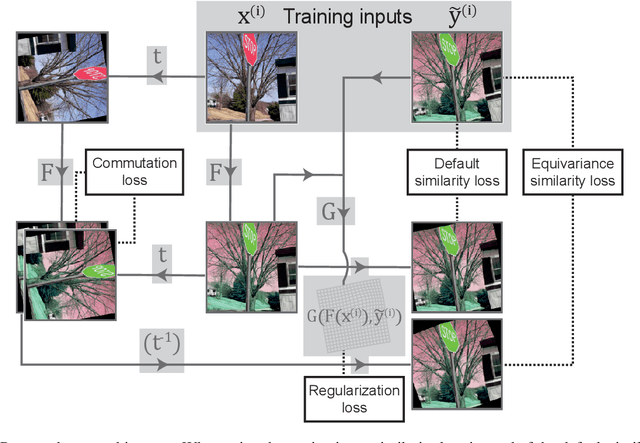
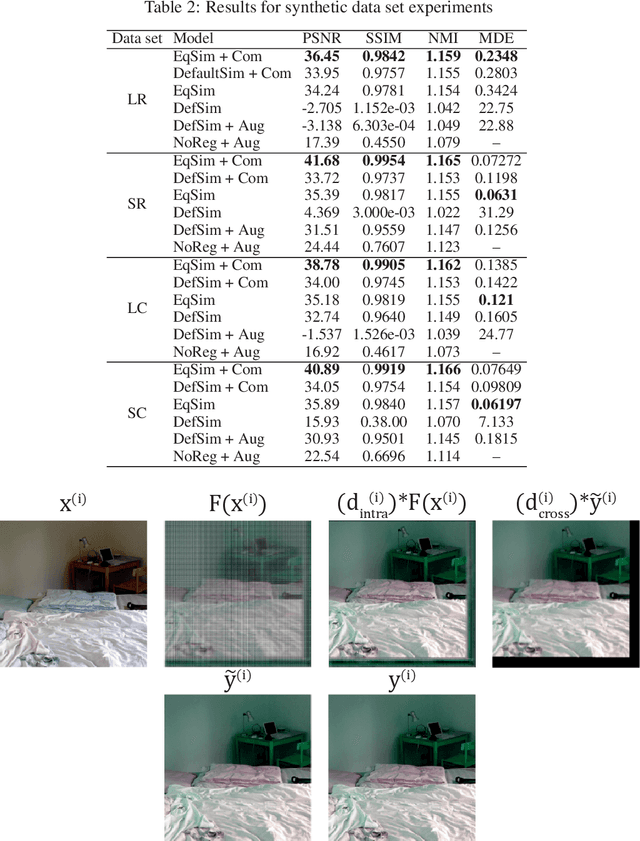
Cross-modality image synthesis is an active research topic with multiple medical clinically relevant applications. Recently, methods allowing training with paired but misaligned data have started to emerge. However, no robust and well-performing methods applicable to a wide range of real world data sets exist. In this work, we propose a generic solution to the problem of cross-modality image synthesis with paired but non-aligned data by introducing new deformation equivariance encouraging loss functions. The method consists of joint training of an image synthesis network together with separate registration networks and allows adversarial training conditioned on the input even with misaligned data. The work lowers the bar for new clinical applications by allowing effortless training of cross-modality image synthesis networks for more difficult data sets and opens up opportunities for the development of new generic learning based cross-modality registration algorithms.
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 15, 2023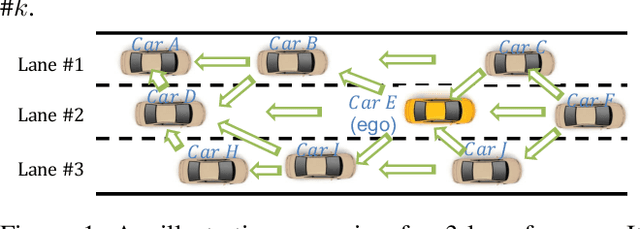

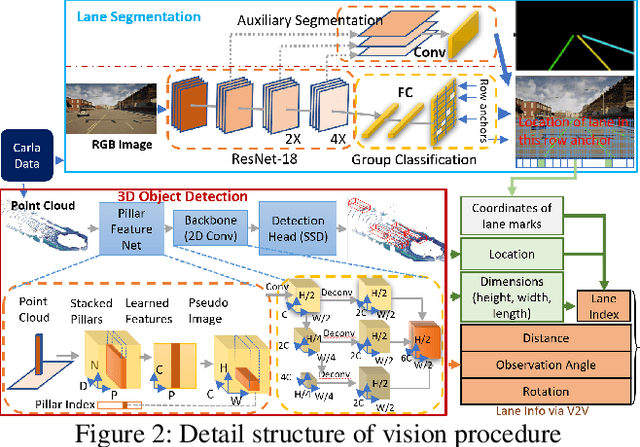
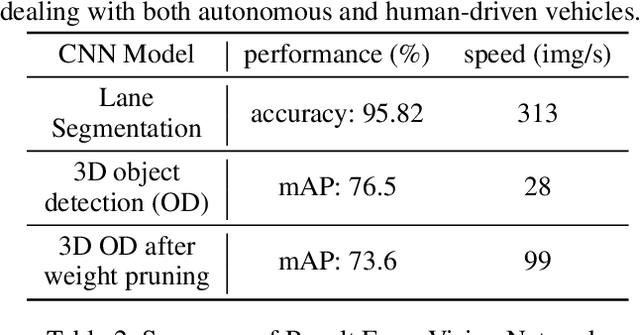
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
Topological Neural Discrete Representation Learning à la Kohonen
Feb 15, 2023
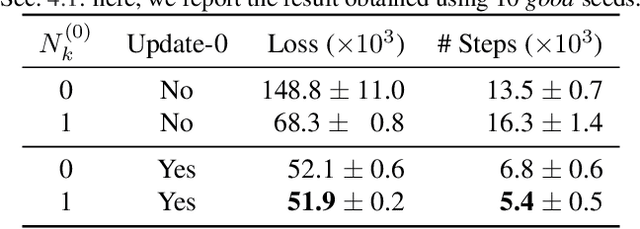
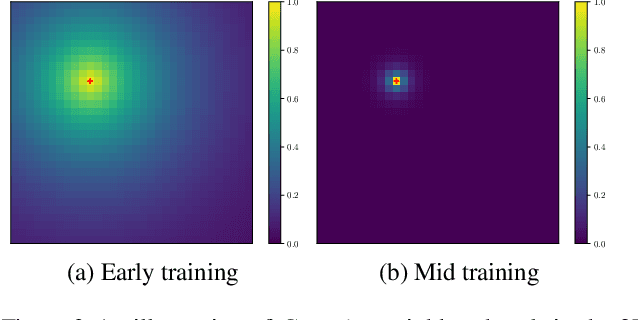

Unsupervised learning of discrete representations from continuous ones in neural networks (NNs) is the cornerstone of several applications today. Vector Quantisation (VQ) has become a popular method to achieve such representations, in particular in the context of generative models such as Variational Auto-Encoders (VAEs). For example, the exponential moving average-based VQ (EMA-VQ) algorithm is often used. Here we study an alternative VQ algorithm based on the learning rule of Kohonen Self-Organising Maps (KSOMs; 1982) of which EMA-VQ is a special case. In fact, KSOM is a classic VQ algorithm which is known to offer two potential benefits over the latter: empirically, KSOM is known to perform faster VQ, and discrete representations learned by KSOM form a topological structure on the grid whose nodes are the discrete symbols, resulting in an artificial version of the topographic map in the brain. We revisit these properties by using KSOM in VQ-VAEs for image processing. In particular, our experiments show that, while the speed-up compared to well-configured EMA-VQ is only observable at the beginning of training, KSOM is generally much more robust than EMA-VQ, e.g., w.r.t. the choice of initialisation schemes. Our code is public.