 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Txt2Img-MHN: Remote Sensing Image Generation from Text Using Modern Hopfield Networks
Aug 08, 2022

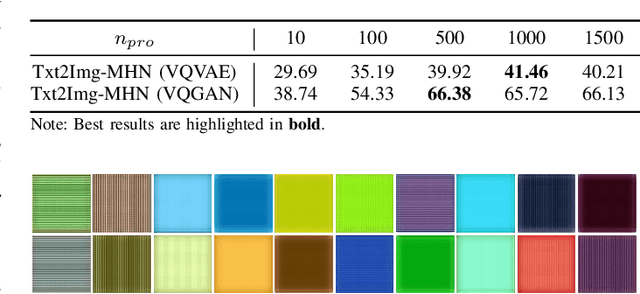
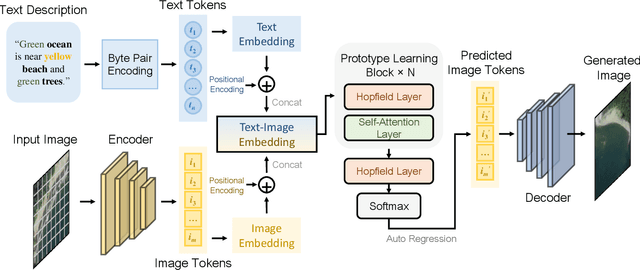
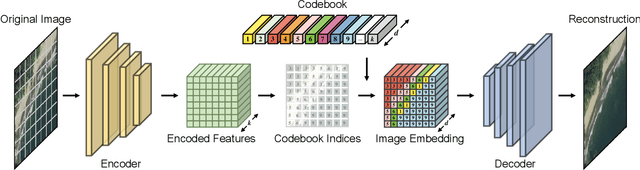
The synthesis of high-resolution remote sensing images based on text descriptions has great potential in many practical application scenarios. Although deep neural networks have achieved great success in many important remote sensing tasks, generating realistic remote sensing images from text descriptions is still very difficult. To address this challenge, we propose a novel text-to-image modern Hopfield network (Txt2Img-MHN). The main idea of Txt2Img-MHN is to conduct hierarchical prototype learning on both text and image embeddings with modern Hopfield layers. Instead of directly learning concrete but highly diverse text-image joint feature representations for different semantics, Txt2Img-MHN aims to learn the most representative prototypes from text-image embeddings, achieving a coarse-to-fine learning strategy. These learned prototypes can then be utilized to represent more complex semantics in the text-to-image generation task. To better evaluate the realism and semantic consistency of the generated images, we further conduct zero-shot classification on real remote sensing data using the classification model trained on synthesized images. Despite its simplicity, we find that the overall accuracy in the zero-shot classification may serve as a good metric to evaluate the ability to generate an image from text. Extensive experiments on the benchmark remote sensing text-image dataset demonstrate that the proposed Txt2Img-MHN can generate more realistic remote sensing images than existing methods. Code and pre-trained models are available online (https://github.com/YonghaoXu/Txt2Img-MHN).
Robust Image Protection Countering Cropping Manipulation
Jun 06, 2022



Image cropping is an inexpensive and effective operation of maliciously altering image contents. Existing cropping detection mechanisms analyze the fundamental traces of image cropping, for example, chromatic aberration and vignetting to uncover cropping attack, yet fragile to common post-processing attacks which deceive forensics by removing such cues. Besides, they ignore the fact that recovering the cropped-out contents can unveil the purpose of the behaved cropping attack. This paper presents a novel robust watermarking scheme for image Cropping Localization and Recovery (CLR-Net). We first protect the original image by introducing imperceptible perturbations. Then, typical image post-processing attacks are simulated to erode the protected image. On the recipient's side, we predict the cropping mask and recover the original image. We propose two plug-and-play networks to improve the real-world robustness of CLR-Net, namely, the Fine-Grained generative JPEG simulator (FG-JPEG) and the Siamese image pre-processing network. To the best of our knowledge, we are the first to address the combined challenge of image cropping localization and entire image recovery from a fragment. Experiments demonstrate that CLR-Net can accurately localize the cropping as well as recover the details of the cropped-out regions with both high quality and fidelity, despite of the presence of image processing attacks of varied types.
MEW-UNet: Multi-axis representation learning in frequency domain for medical image segmentation
Oct 25, 2022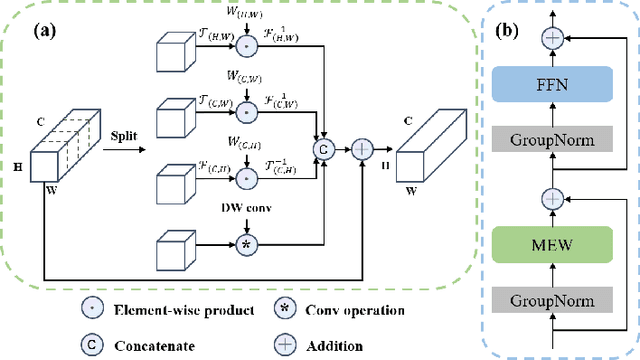
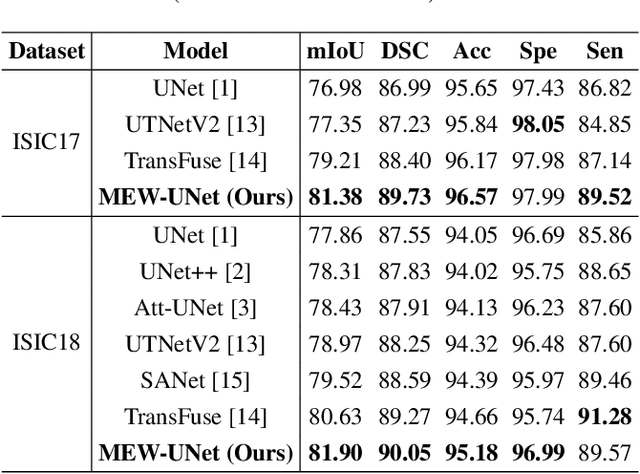
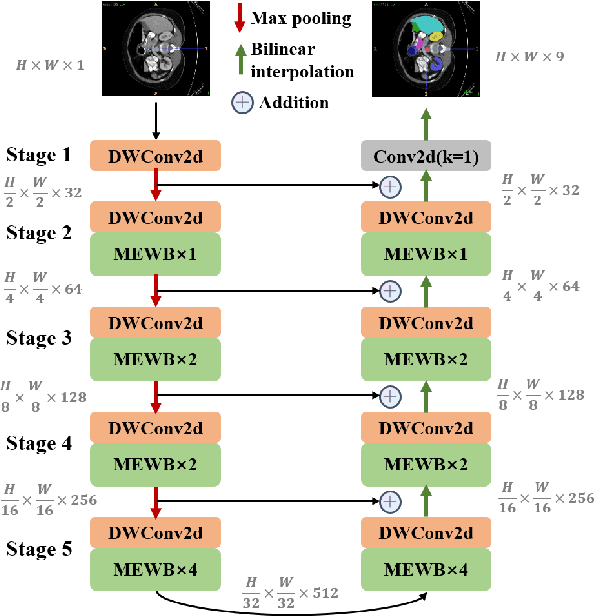
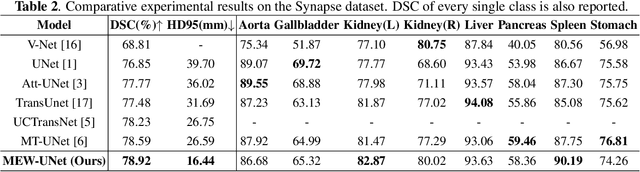
Recently, Visual Transformer (ViT) has been widely used in various fields of computer vision due to applying self-attention mechanism in the spatial domain to modeling global knowledge. Especially in medical image segmentation (MIS), many works are devoted to combining ViT and CNN, and even some works directly utilize pure ViT-based models. However, recent works improved models in the aspect of spatial domain while ignoring the importance of frequency domain information. Therefore, we propose Multi-axis External Weights UNet (MEW-UNet) for MIS based on the U-shape architecture by replacing self-attention in ViT with our Multi-axis External Weights block. Specifically, our block performs a Fourier transform on the three axes of the input feature and assigns the external weight in the frequency domain, which is generated by our Weights Generator. Then, an inverse Fourier transform is performed to change the features back to the spatial domain. We evaluate our model on four datasets and achieve state-of-the-art performances. In particular, on the Synapse dataset, our method outperforms MT-UNet by 10.15mm in terms of HD95. Code is available at https://github.com/JCruan519/MEW-UNet.
Exploiting Partial Common Information Microstructure for Multi-Modal Brain Tumor Segmentation
Feb 06, 2023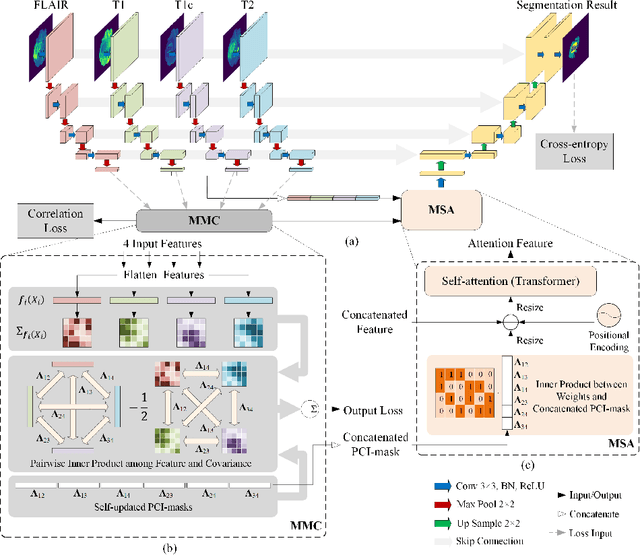


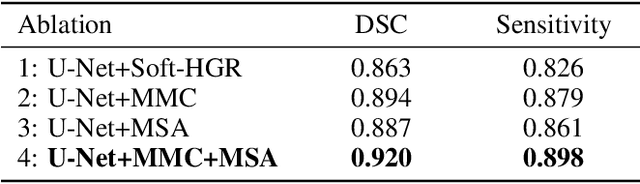
Learning with multiple modalities is crucial for automated brain tumor segmentation from magnetic resonance imaging data. Explicitly optimizing the common information shared among all modalities (e.g., by maximizing the total correlation) has been shown to achieve better feature representations and thus enhance the segmentation performance. However, existing approaches are oblivious to partial common information shared by subsets of the modalities. In this paper, we show that identifying such partial common information can significantly boost the discriminative power of image segmentation models. In particular, we introduce a novel concept of partial common information mask (PCI-mask) to provide a fine-grained characterization of what partial common information is shared by which subsets of the modalities. By solving a masked correlation maximization and simultaneously learning an optimal PCI-mask, we identify the latent microstructure of partial common information and leverage it in a self-attention module to selectively weight different feature representations in multi-modal data. We implement our proposed framework on the standard U-Net. Our experimental results on the Multi-modal Brain Tumor Segmentation Challenge (BraTS) datasets consistently outperform those of state-of-the-art segmentation baselines, with validation Dice similarity coefficients of 0.920, 0.897, 0.837 for the whole tumor, tumor core, and enhancing tumor on BraTS-2020.
Multi-Modality Image Inpainting using Generative Adversarial Networks
Jun 22, 2022



Deep learning techniques, especially Generative Adversarial Networks (GANs) have significantly improved image inpainting and image-to-image translation tasks over the past few years. To the best of our knowledge, the problem of combining the image inpainting task with the multi-modality image-to-image translation remains intact. In this paper, we propose a model to address this problem. The model will be evaluated on combined night-to-day image translation and inpainting, along with promising qualitative and quantitative results.
Fast Fourier Convolution Based Remote Sensor Image Object Detection for Earth Observation
Sep 01, 2022
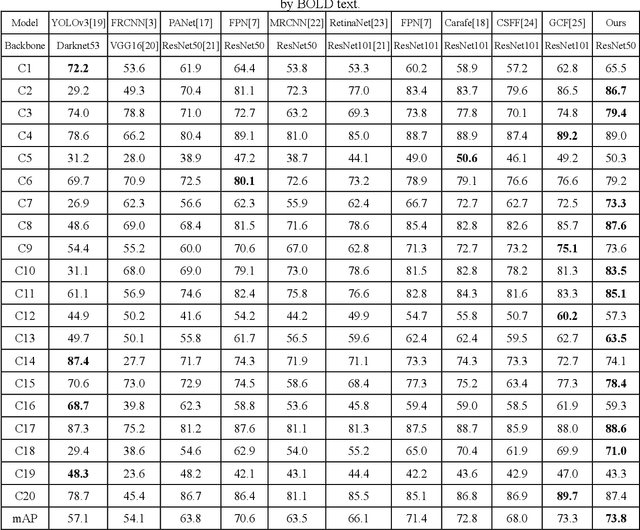
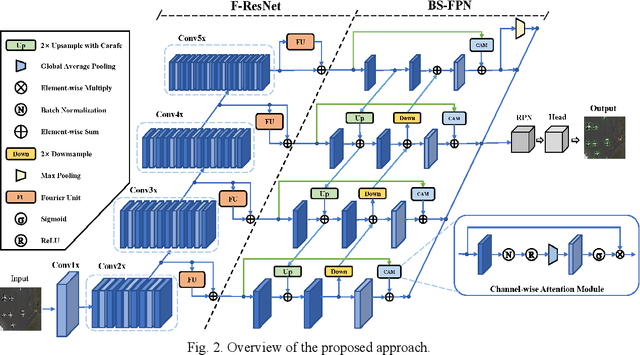

Remote sensor image object detection is an important technology for Earth observation, and is used in various tasks such as forest fire monitoring and ocean monitoring. Image object detection technology, despite the significant developments, is struggling to handle remote sensor images and small-scale objects, due to the limited pixels of small objects. Numerous existing studies have demonstrated that an effective way to promote small object detection is to introduce the spatial context. Meanwhile, recent researches for image classification have shown that spectral convolution operations can perceive long-term spatial dependence more efficiently in the frequency domain than spatial domain. Inspired by this observation, we propose a Frequency-aware Feature Pyramid Framework (FFPF) for remote sensing object detection, which consists of a novel Frequency-aware ResNet (F-ResNet) and a Bilateral Spectral-aware Feature Pyramid Network (BS-FPN). Specifically, the F-ResNet is proposed to perceive the spectral context information by plugging the frequency domain convolution into each stage of the backbone, extracting richer features of small objects. To the best of our knowledge, this is the first work to introduce frequency-domain convolution into remote sensing object detection task. In addition, the BSFPN is designed to use a bilateral sampling strategy and skipping connection to better model the association of object features at different scales, towards unleashing the potential of the spectral context information from F-ResNet. Extensive experiments are conducted for object detection in the optical remote sensing image dataset (DIOR and DOTA). The experimental results demonstrate the excellent performance of our method. It achieves an average accuracy (mAP) without any tricks.
Learning Gradients of Convex Functions with Monotone Gradient Networks
Jan 25, 2023
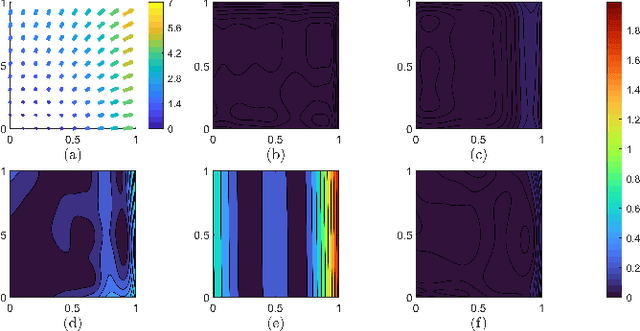
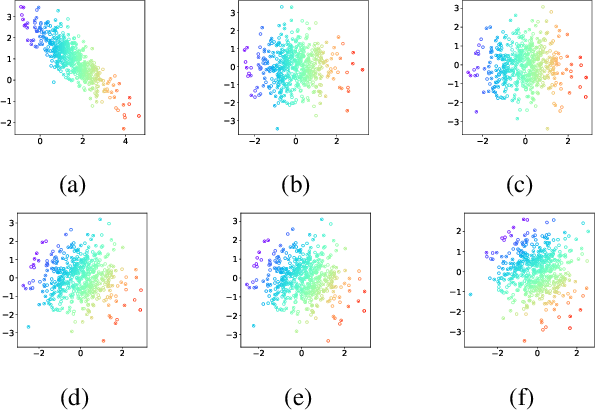
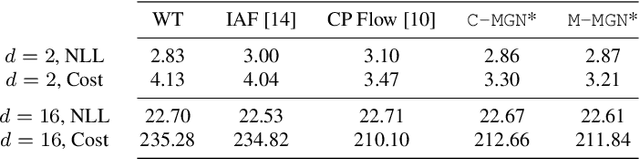
While much effort has been devoted to deriving and studying effective convex formulations of signal processing problems, the gradients of convex functions also have critical applications ranging from gradient-based optimization to optimal transport. Recent works have explored data-driven methods for learning convex objectives, but learning their monotone gradients is seldom studied. In this work, we propose Cascaded and Modular Monotone Gradient Networks (C-MGN and M-MGN respectively), two monotone gradient neural network architectures for directly learning the gradients of convex functions. We show that our networks are simpler to train, learn monotone gradient fields more accurately, and use significantly fewer parameters than state of the art methods. We further demonstrate their ability to learn optimal transport mappings to augment driving image data.
Human-centric Image Cropping with Partition-aware and Content-preserving Features
Jul 21, 2022

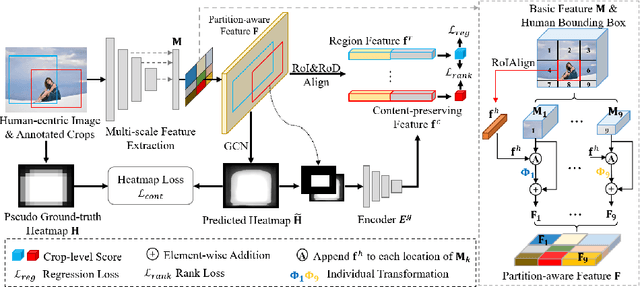
Image cropping aims to find visually appealing crops in an image, which is an important yet challenging task. In this paper, we consider a specific and practical application: human-centric image cropping, which focuses on the depiction of a person. To this end, we propose a human-centric image cropping method with two novel feature designs for the candidate crop: partition-aware feature and content-preserving feature. For partition-aware feature, we divide the whole image into nine partitions based on the human bounding box and treat different partitions in a candidate crop differently conditioned on the human information. For content-preserving feature, we predict a heatmap indicating the important content to be included in a good crop, and extract the geometric relation between the heatmap and a candidate crop. Extensive experiments demonstrate that our method can perform favorably against state-of-the-art image cropping methods on human-centric image cropping task. Code is available at https://github.com/bcmi/Human-Centric-Image-Cropping.
Self-Supervised 2D/3D Registration for X-Ray to CT Image Fusion
Oct 14, 2022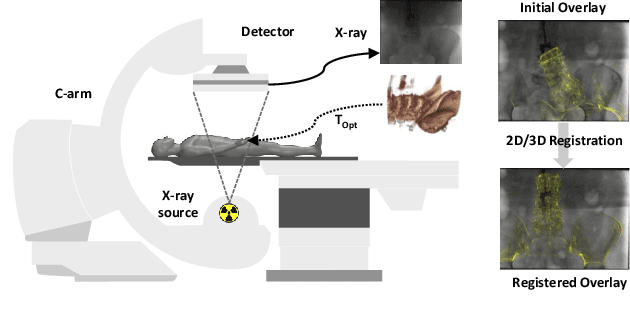

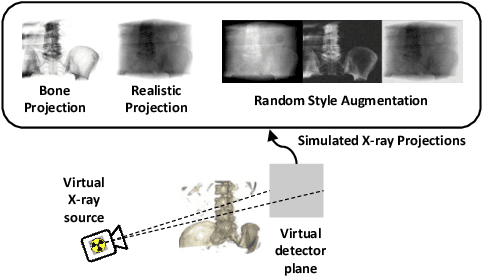

Deep Learning-based 2D/3D registration enables fast, robust, and accurate X-ray to CT image fusion when large annotated paired datasets are available for training. However, the need for paired CT volume and X-ray images with ground truth registration limits the applicability in interventional scenarios. An alternative is to use simulated X-ray projections from CT volumes, thus removing the need for paired annotated datasets. Deep Neural Networks trained exclusively on simulated X-ray projections can perform significantly worse on real X-ray images due to the domain gap. We propose a self-supervised 2D/3D registration framework combining simulated training with unsupervised feature and pixel space domain adaptation to overcome the domain gap and eliminate the need for paired annotated datasets. Our framework achieves a registration accuracy of 1.83$\pm$1.16 mm with a high success ratio of 90.1% on real X-ray images showing a 23.9% increase in success ratio compared to reference annotation-free algorithms.
Pixelated Reconstruction of Foreground Density and Background Surface Brightness in Gravitational Lensing Systems using Recurrent Inference Machines
Jan 10, 2023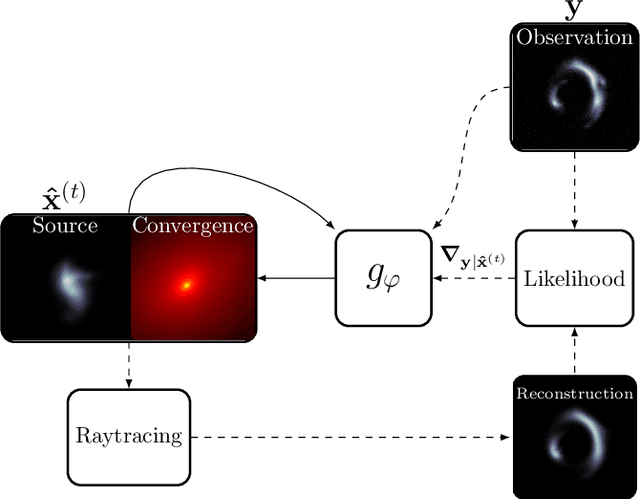

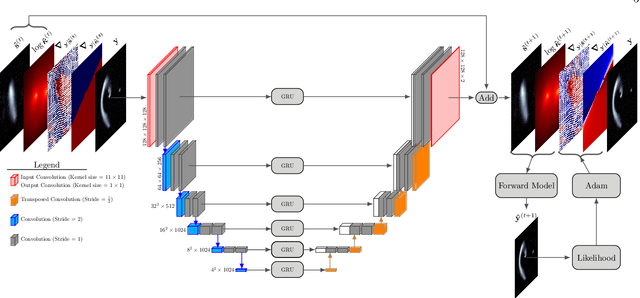
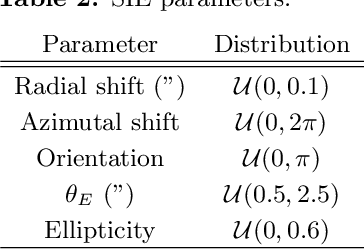
Modeling strong gravitational lenses in order to quantify the distortions in the images of background sources and to reconstruct the mass density in the foreground lenses has been a difficult computational challenge. As the quality of gravitational lens images increases, the task of fully exploiting the information they contain becomes computationally and algorithmically more difficult. In this work, we use a neural network based on the Recurrent Inference Machine (RIM) to simultaneously reconstruct an undistorted image of the background source and the lens mass density distribution as pixelated maps. The method iteratively reconstructs the model parameters (the image of the source and a pixelated density map) by learning the process of optimizing the likelihood given the data using the physical model (a ray-tracing simulation), regularized by a prior implicitly learned by the neural network through its training data. When compared to more traditional parametric models, the proposed method is significantly more expressive and can reconstruct complex mass distributions, which we demonstrate by using realistic lensing galaxies taken from the IllustrisTNG cosmological hydrodynamic simulation.