 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explore the Power of Dropout on Few-shot Learning
Jan 26, 2023
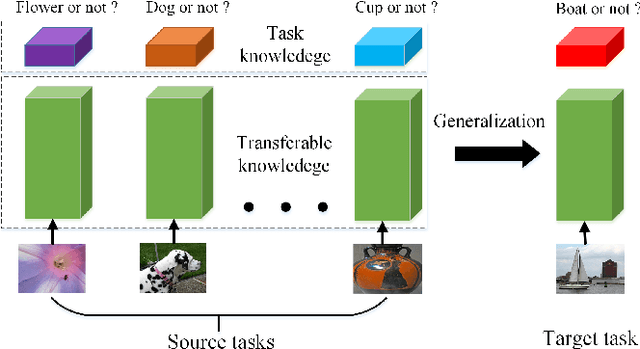
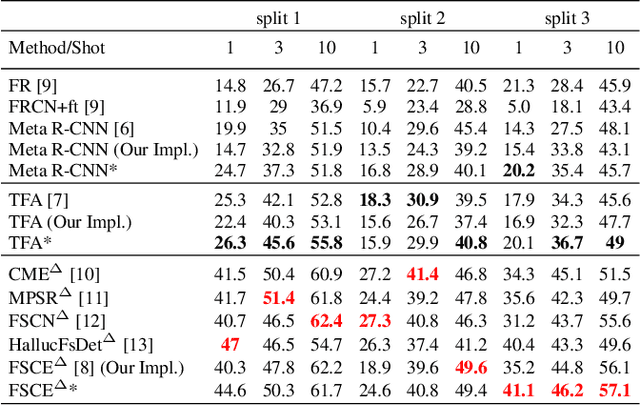
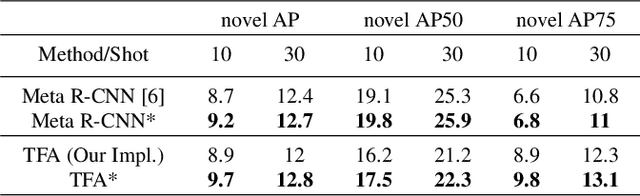

The generalization power of the pre-trained model is the key for few-shot deep learning. Dropout is a regularization technique used in traditional deep learning methods. In this paper, we explore the power of dropout on few-shot learning and provide some insights about how to use it. Extensive experiments on the few-shot object detection and few-shot image classification datasets, i.e., Pascal VOC, MS COCO, CUB, and mini-ImageNet, validate the effectiveness of our method.
The autoregressive neural network architecture of the Boltzmann distribution of pairwise interacting spins systems
Feb 16, 2023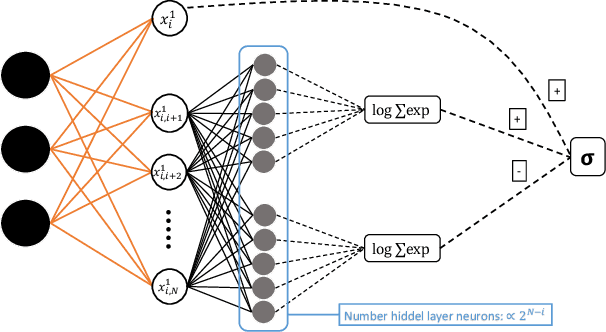
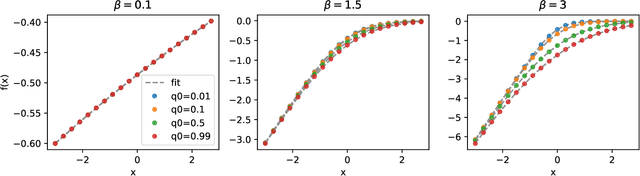
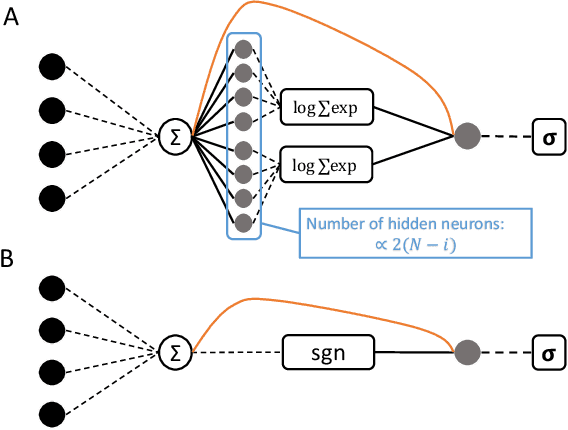
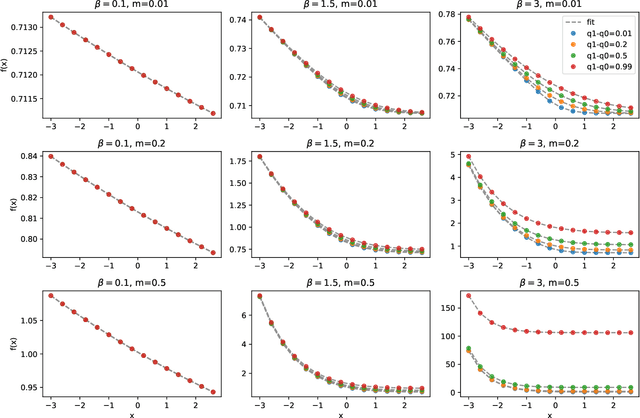
Generative Autoregressive Neural Networks (ARNN) have recently demonstrated exceptional results in image and language generation tasks, contributing to the growing popularity of generative models in both scientific and commercial applications. This work presents a physical interpretation of the ARNNs by reformulating the Boltzmann distribution of binary pairwise interacting systems into autoregressive form. The resulting ARNN architecture has weights and biases of its first layer corresponding to the Hamiltonian's couplings and external fields, featuring widely used structures like the residual connections and a recurrent architecture with clear physical meanings. However, the exponential growth, with system size, of the number of parameters of the hidden layers makes its direct application unfeasible. Nevertheless, its architecture's explicit formulation allows using statistical physics techniques to derive new ARNNs for specific systems. As examples, new effective ARNN architectures are derived from two well-known mean-field systems, the Curie-Weiss and Sherrington-Kirkpatrick models, showing superior performances in approximating the Boltzmann distributions of the corresponding physics model than other commonly used ARNNs architectures. The connection established between the physics of the system and the ARNN architecture provides a way to derive new neural network architectures for different interacting systems and interpret existing ones from a physical perspective.
THC: Accelerating Distributed Deep Learning Using Tensor Homomorphic Compression
Feb 16, 2023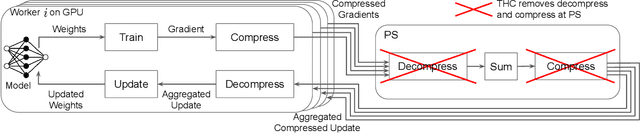
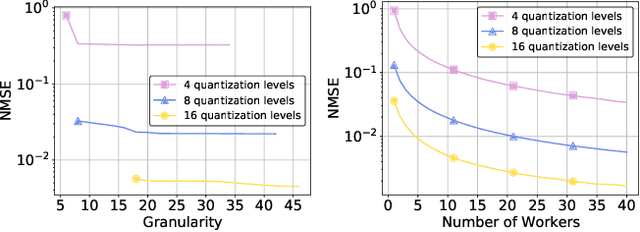
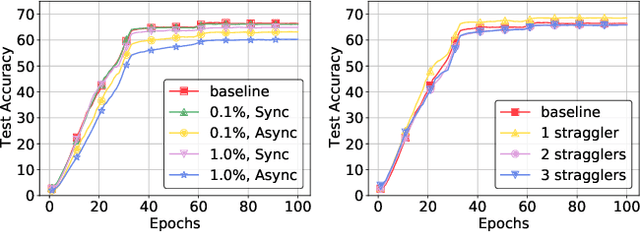
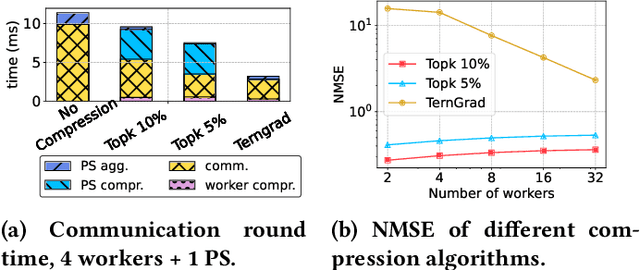
Deep neural networks (DNNs) are the de-facto standard for essential use cases, such as image classification, computer vision, and natural language processing. As DNNs and datasets get larger, they require distributed training on increasingly larger clusters. A main bottleneck is then the resulting communication overhead where workers exchange model updates (i.e., gradients) on a per-round basis. To address this bottleneck and accelerate training, a widely-deployed approach is compression. However, previous deployments often apply bi-directional compression schemes by simply using a uni-directional gradient compression scheme in each direction. This results in significant computational overheads at the parameter server and increased compression error, leading to longer training and lower accuracy. We introduce Tensor Homomorphic Compression (THC), a novel bi-directional compression framework that enables the direct aggregation of compressed values while optimizing the bandwidth to accuracy tradeoff, thus eliminating the aforementioned overheads. Moreover, THC is compatible with in-network aggregation (INA), which allows for further acceleration. Evaluation over a testbed shows that THC improves time-to-accuracy in comparison to alternatives by up to 1.32x with a software PS and up to 1.51x using INA. Finally, we demonstrate that THC is scalable and tolerant for acceptable packet-loss rates.
NYCU-TWO at Memotion 3: Good Foundation, Good Teacher, then you have Good Meme Analysis
Feb 14, 2023
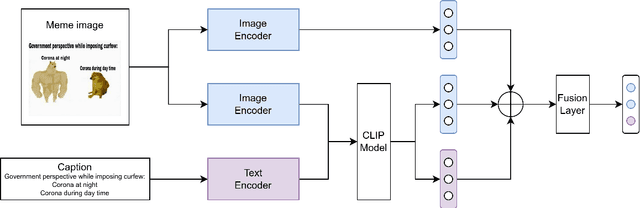

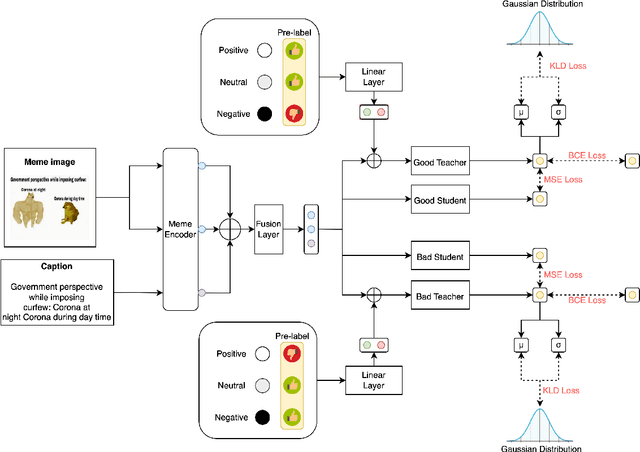
This paper presents a robust solution to the Memotion 3.0 Shared Task. The goal of this task is to classify the emotion and the corresponding intensity expressed by memes, which are usually in the form of images with short captions on social media. Understanding the multi-modal features of the given memes will be the key to solving the task. In this work, we use CLIP to extract aligned image-text features and propose a novel meme sentiment analysis framework, consisting of a Cooperative Teaching Model (CTM) for Task A and a Cascaded Emotion Classifier (CEC) for Tasks B&C. CTM is based on the idea of knowledge distillation, and can better predict the sentiment of a given meme in Task A; CEC can leverage the emotion intensity suggestion from the prediction of Task C to classify the emotion more precisely in Task B. Experiments show that we achieved the 2nd place ranking for both Task A and Task B and the 4th place ranking for Task C, with weighted F1-scores of 0.342, 0.784, and 0.535 respectively. The results show the robustness and effectiveness of our framework. Our code is released at github.
Dual-mode adaptive-SVD ghost imaging
Feb 14, 2023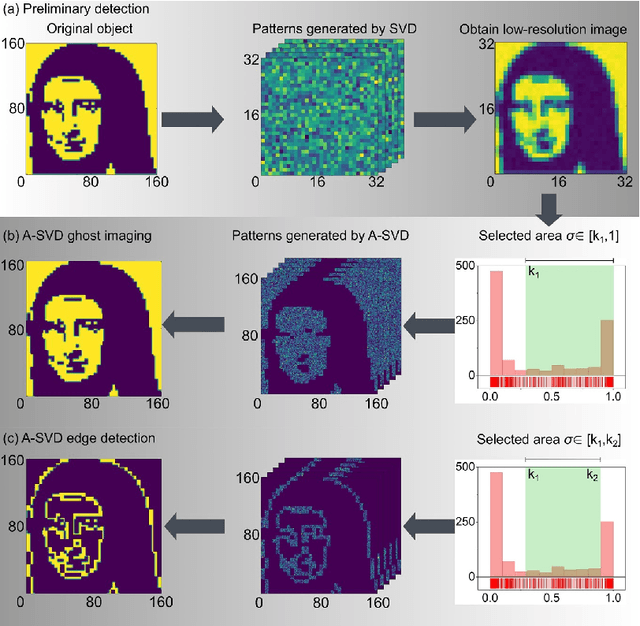
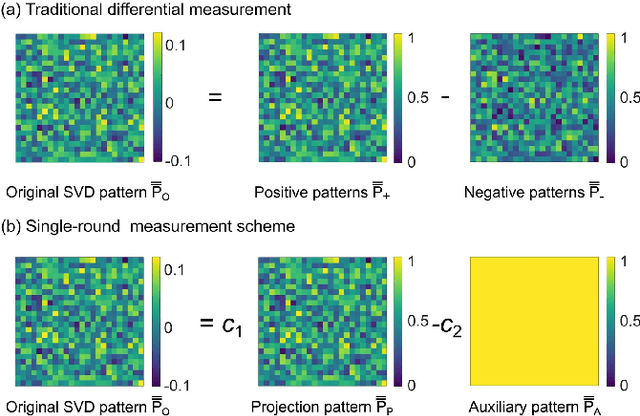
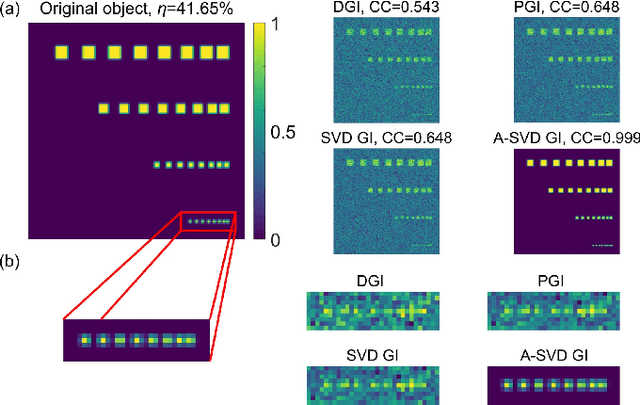
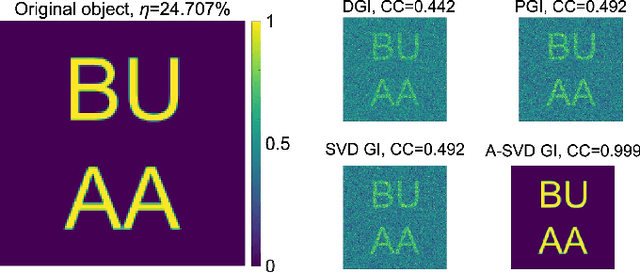
In this paper, we present a dual-mode adaptive singular value decomposition ghost imaging (A-SVD GI), which can be easily switched between the modes of imaging and edge detection. It can adaptively localize the foreground pixels via a threshold selection method. Then only the foreground region is illuminated by the singular value decomposition (SVD) - based patterns, consequently retrieving high-quality images with fewer sampling ratios. By changing the selecting range of foreground pixels, the A-SVD GI can be switched to the mode of edge detection to directly reveal the edge of objects, without needing the original image. We investigate the performance of these two modes through both numerical simulations and experiments. We also develop a single-round scheme to halve measurement numbers in experiments, instead of separately illuminating positive and negative patterns in traditional methods. The binarized SVD patterns, generated by the spatial dithering method, are modulated by a digital micromirror device (DMD) to speed up the data acquisition. This dual-mode A-SVD GI can be applied in various applications, such as remote sensing or target recognition, and could be further extended for multi-modality functional imaging/detection.
A Lightweight Reconstruction Network for Surface Defect Inspection
Dec 25, 2022

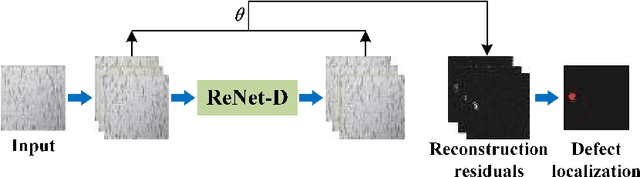

Currently, most deep learning methods cannot solve the problem of scarcity of industrial product defect samples and significant differences in characteristics. This paper proposes an unsupervised defect detection algorithm based on a reconstruction network, which is realized using only a large number of easily obtained defect-free sample data. The network includes two parts: image reconstruction and surface defect area detection. The reconstruction network is designed through a fully convolutional autoencoder with a lightweight structure. Only a small number of normal samples are used for training so that the reconstruction network can be A defect-free reconstructed image is generated. A function combining structural loss and $\mathit{L}1$ loss is proposed as the loss function of the reconstruction network to solve the problem of poor detection of irregular texture surface defects. Further, the residual of the reconstructed image and the image to be tested is used as the possible region of the defect, and conventional image operations can realize the location of the fault. The unsupervised defect detection algorithm of the proposed reconstruction network is used on multiple defect image sample sets. Compared with other similar algorithms, the results show that the unsupervised defect detection algorithm of the reconstructed network has strong robustness and accuracy.
* Journal of Mathematical Imaging and Vision(JMIV)
WIRE: Wavelet Implicit Neural Representations
Jan 05, 2023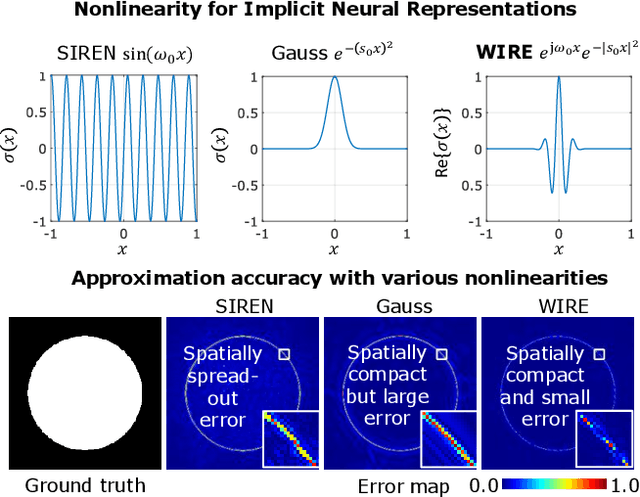
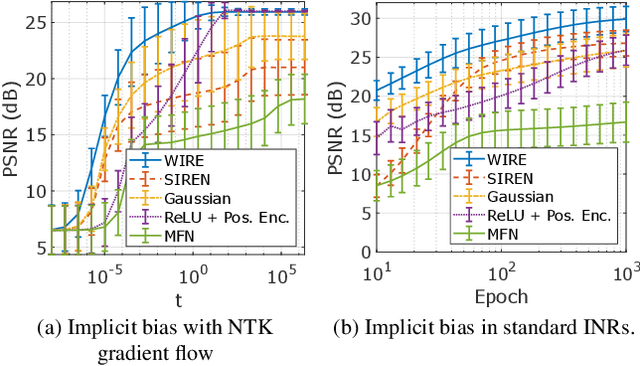
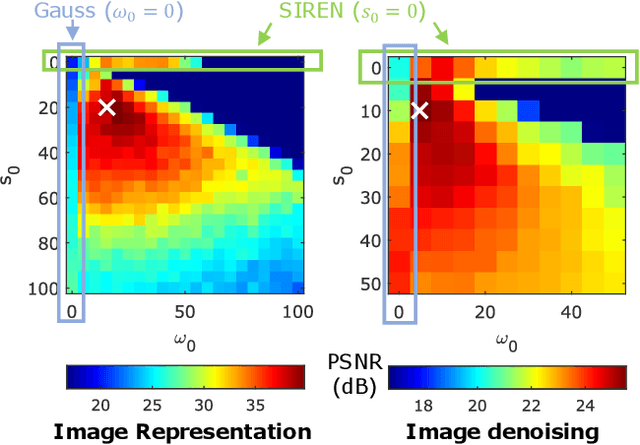
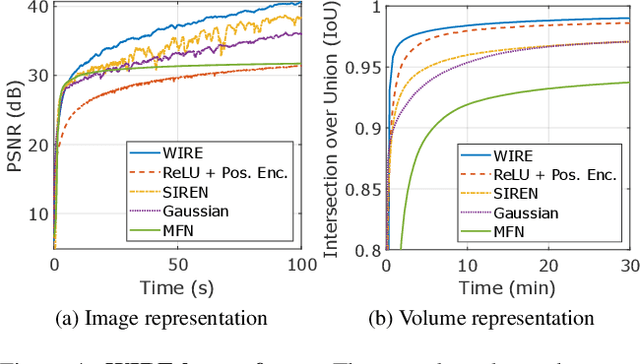
Implicit neural representations (INRs) have recently advanced numerous vision-related areas. INR performance depends strongly on the choice of the nonlinear activation function employed in its multilayer perceptron (MLP) network. A wide range of nonlinearities have been explored, but, unfortunately, current INRs designed to have high accuracy also suffer from poor robustness (to signal noise, parameter variation, etc.). Inspired by harmonic analysis, we develop a new, highly accurate and robust INR that does not exhibit this tradeoff. Wavelet Implicit neural REpresentation (WIRE) uses a continuous complex Gabor wavelet activation function that is well-known to be optimally concentrated in space-frequency and to have excellent biases for representing images. A wide range of experiments (image denoising, image inpainting, super-resolution, computed tomography reconstruction, image overfitting, and novel view synthesis with neural radiance fields) demonstrate that WIRE defines the new state of the art in INR accuracy, training time, and robustness.
Semantic Image Synthesis via Diffusion Models
Jun 30, 2022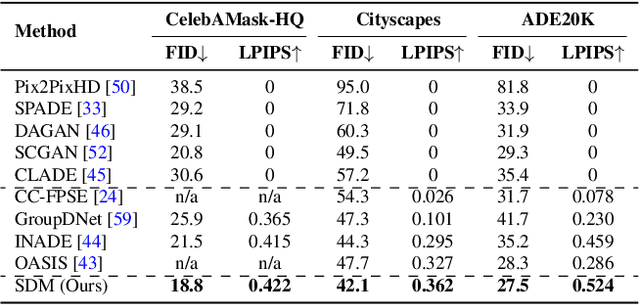
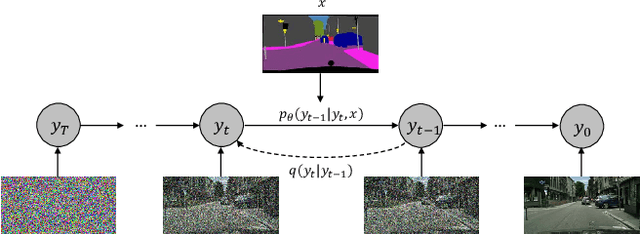
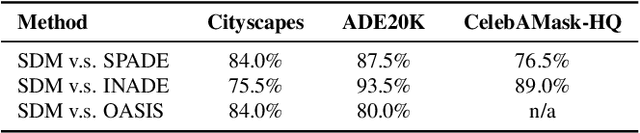
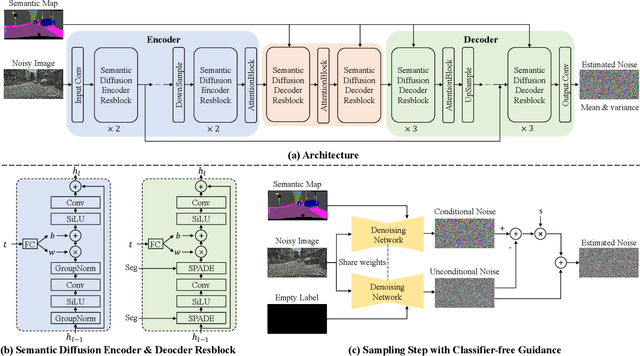
Denoising Diffusion Probabilistic Models (DDPMs) have achieved remarkable success in various image generation tasks compared with Generative Adversarial Nets (GANs). Recent work on semantic image synthesis mainly follows the \emph{de facto} GAN-based approaches, which may lead to unsatisfactory quality or diversity of generated images. In this paper, we propose a novel framework based on DDPM for semantic image synthesis. Unlike previous conditional diffusion model directly feeds the semantic layout and noisy image as input to a U-Net structure, which may not fully leverage the information in the input semantic mask, our framework processes semantic layout and noisy image differently. It feeds noisy image to the encoder of the U-Net structure while the semantic layout to the decoder by multi-layer spatially-adaptive normalization operators. To further improve the generation quality and semantic interpretability in semantic image synthesis, we introduce the classifier-free guidance sampling strategy, which acknowledge the scores of an unconditional model for sampling process. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our proposed method, achieving state-of-the-art performance in terms of fidelity~(FID) and diversity~(LPIPS).
Deep Learning Computer Vision Algorithms for Real-time UAVs On-board Camera Image Processing
Nov 02, 2022



This paper describes how advanced deep learning based computer vision algorithms are applied to enable real-time on-board sensor processing for small UAVs. Four use cases are considered: target detection, classification and localization, road segmentation for autonomous navigation in GNSS-denied zones, human body segmentation, and human action recognition. All algorithms have been developed using state-of-the-art image processing methods based on deep neural networks. Acquisition campaigns have been carried out to collect custom datasets reflecting typical operational scenarios, where the peculiar point of view of a multi-rotor UAV is replicated. Algorithms architectures and trained models performances are reported, showing high levels of both accuracy and inference speed. Output examples and on-field videos are presented, demonstrating models operation when deployed on a GPU-powered commercial embedded device (NVIDIA Jetson Xavier) mounted on board of a custom quad-rotor, paving the way to enabling high level autonomy.
Effective End-to-End Vision Language Pretraining with Semantic Visual Loss
Jan 18, 2023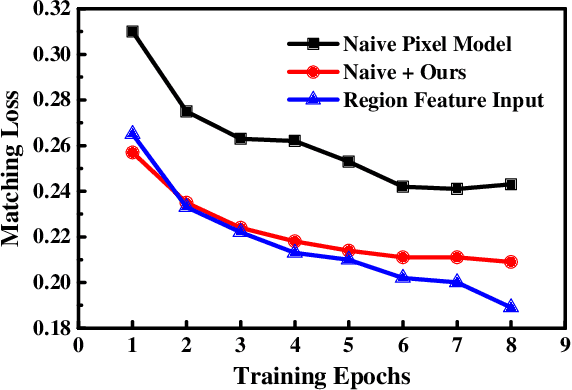
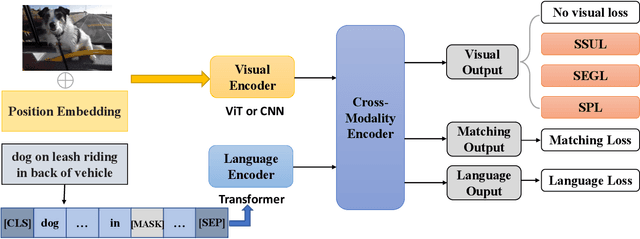
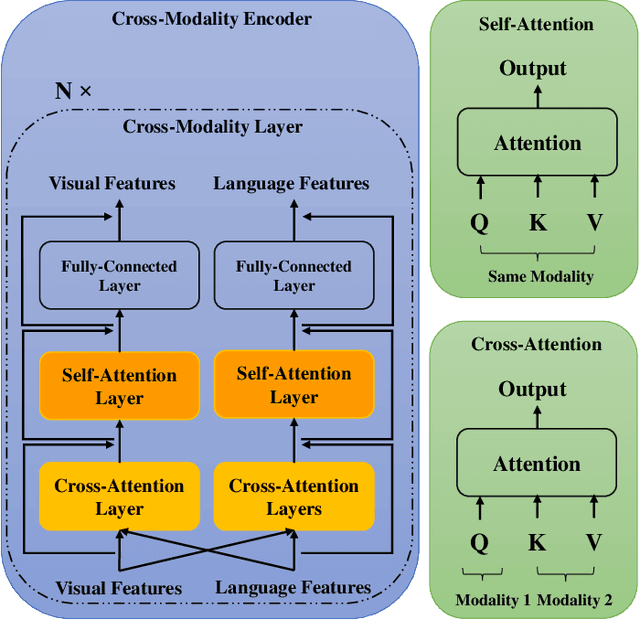
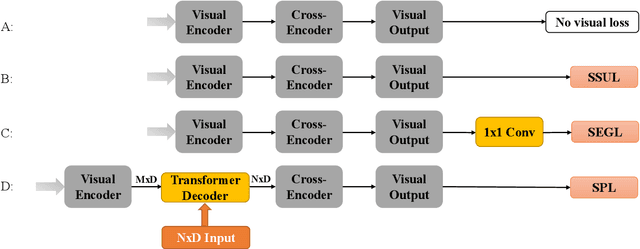
Current vision language pretraining models are dominated by methods using region visual features extracted from object detectors. Given their good performance, the extract-then-process pipeline significantly restricts the inference speed and therefore limits their real-world use cases. However, training vision language models from raw image pixels is difficult, as the raw image pixels give much less prior knowledge than region features. In this paper, we systematically study how to leverage auxiliary visual pretraining tasks to help training end-to-end vision language models. We introduce three types of visual losses that enable much faster convergence and better finetuning accuracy. Compared with region feature models, our end-to-end models could achieve similar or better performance on downstream tasks and run more than 10 times faster during inference. Compared with other end-to-end models, our proposed method could achieve similar or better performance when pretrained for only 10% of the pretraining GPU hours.