 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Txt2Img-MHN: Remote Sensing Image Generation from Text Using Modern Hopfield Networks
Aug 08, 2022

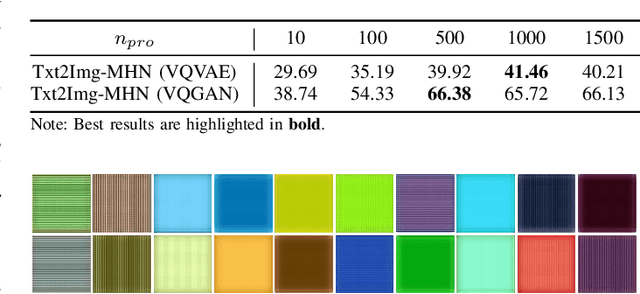
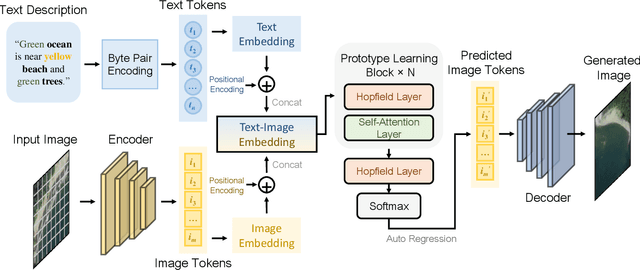
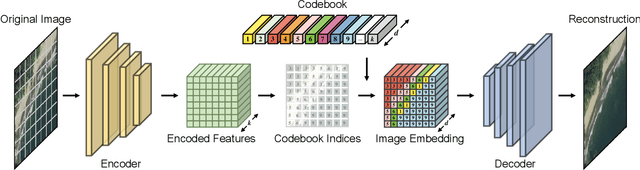
The synthesis of high-resolution remote sensing images based on text descriptions has great potential in many practical application scenarios. Although deep neural networks have achieved great success in many important remote sensing tasks, generating realistic remote sensing images from text descriptions is still very difficult. To address this challenge, we propose a novel text-to-image modern Hopfield network (Txt2Img-MHN). The main idea of Txt2Img-MHN is to conduct hierarchical prototype learning on both text and image embeddings with modern Hopfield layers. Instead of directly learning concrete but highly diverse text-image joint feature representations for different semantics, Txt2Img-MHN aims to learn the most representative prototypes from text-image embeddings, achieving a coarse-to-fine learning strategy. These learned prototypes can then be utilized to represent more complex semantics in the text-to-image generation task. To better evaluate the realism and semantic consistency of the generated images, we further conduct zero-shot classification on real remote sensing data using the classification model trained on synthesized images. Despite its simplicity, we find that the overall accuracy in the zero-shot classification may serve as a good metric to evaluate the ability to generate an image from text. Extensive experiments on the benchmark remote sensing text-image dataset demonstrate that the proposed Txt2Img-MHN can generate more realistic remote sensing images than existing methods. Code and pre-trained models are available online (https://github.com/YonghaoXu/Txt2Img-MHN).
Instance Image Retrieval by Learning Purely From Within the Dataset
Aug 12, 2022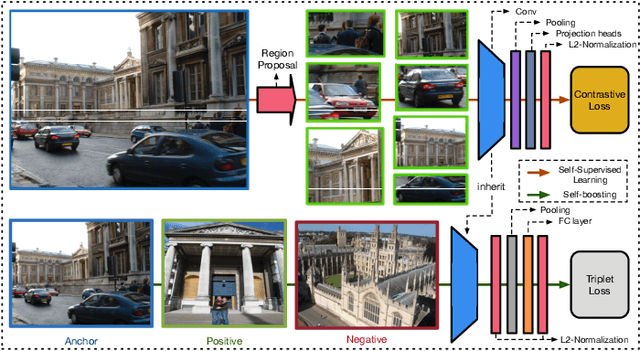
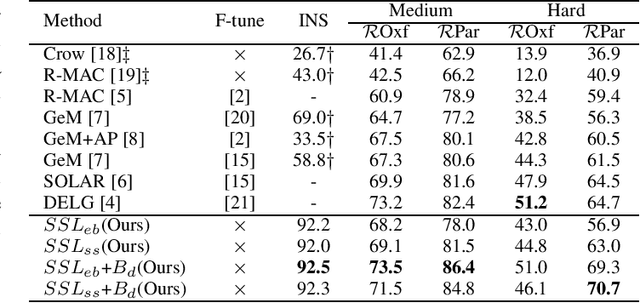

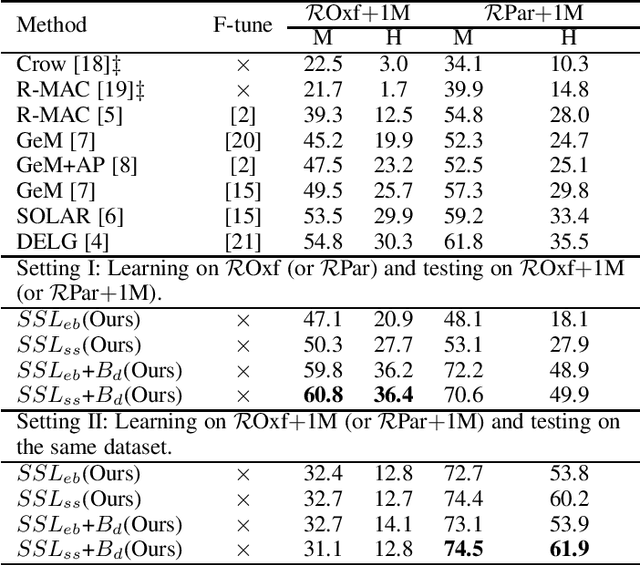
Quality feature representation is key to instance image retrieval. To attain it, existing methods usually resort to a deep model pre-trained on benchmark datasets or even fine-tune the model with a task-dependent labelled auxiliary dataset. Although achieving promising results, this approach is restricted by two issues: 1) the domain gap between benchmark datasets and the dataset of a given retrieval task; 2) the required auxiliary dataset cannot be readily obtained. In light of this situation, this work looks into a different approach which has not been well investigated for instance image retrieval previously: {can we learn feature representation \textit{specific to} a given retrieval task in order to achieve excellent retrieval?} Our finding is encouraging. By adding an object proposal generator to generate image regions for self-supervised learning, the investigated approach can successfully learn feature representation specific to a given dataset for retrieval. This representation can be made even more effective by boosting it with image similarity information mined from the dataset. As experimentally validated, such a simple ``self-supervised learning + self-boosting'' approach can well compete with the relevant state-of-the-art retrieval methods. Ablation study is conducted to show the appealing properties of this approach and its limitation on generalisation across datasets.
SlideVQA: A Dataset for Document Visual Question Answering on Multiple Images
Jan 12, 2023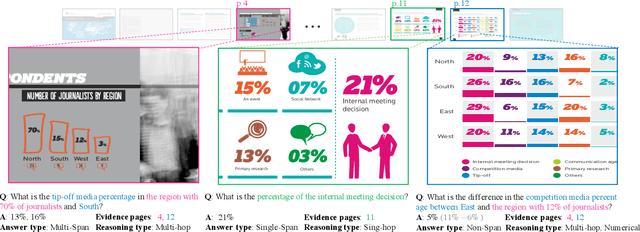

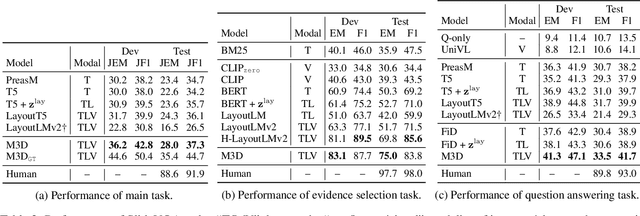
Visual question answering on document images that contain textual, visual, and layout information, called document VQA, has received much attention recently. Although many datasets have been proposed for developing document VQA systems, most of the existing datasets focus on understanding the content relationships within a single image and not across multiple images. In this study, we propose a new multi-image document VQA dataset, SlideVQA, containing 2.6k+ slide decks composed of 52k+ slide images and 14.5k questions about a slide deck. SlideVQA requires complex reasoning, including single-hop, multi-hop, and numerical reasoning, and also provides annotated arithmetic expressions of numerical answers for enhancing the ability of numerical reasoning. Moreover, we developed a new end-to-end document VQA model that treats evidence selection and question answering in a unified sequence-to-sequence format. Experiments on SlideVQA show that our model outperformed existing state-of-the-art QA models, but that it still has a large gap behind human performance. We believe that our dataset will facilitate research on document VQA.
Meta-Learned Kernel For Blind Super-Resolution Kernel Estimation
Dec 15, 2022
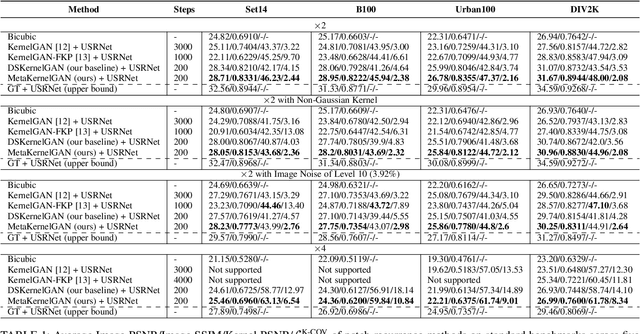
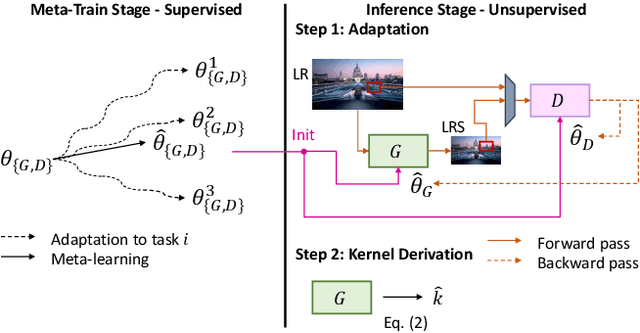
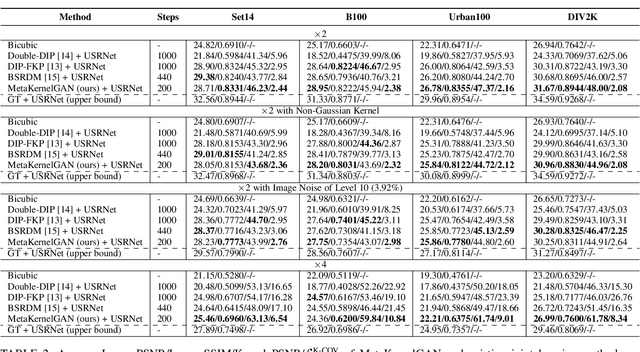
Recent image degradation estimation methods have enabled single-image super-resolution (SR) approaches to better upsample real-world images. Among these methods, explicit kernel estimation approaches have demonstrated unprecedented performance at handling unknown degradations. Nonetheless, a number of limitations constrain their efficacy when used by downstream SR models. Specifically, this family of methods yields i) excessive inference time due to long per-image adaptation times and ii) inferior image fidelity due to kernel mismatch. In this work, we introduce a learning-to-learn approach that meta-learns from the information contained in a distribution of images, thereby enabling significantly faster adaptation to new images with substantially improved performance in both kernel estimation and image fidelity. Specifically, we meta-train a kernel-generating GAN, named MetaKernelGAN, on a range of tasks, such that when a new image is presented, the generator starts from an informed kernel estimate and the discriminator starts with a strong capability to distinguish between patch distributions. Compared with state-of-the-art methods, our experiments show that MetaKernelGAN better estimates the magnitude and covariance of the kernel, leading to state-of-the-art blind SR results within a similar computational regime when combined with a non-blind SR model. Through supervised learning of an unsupervised learner, our method maintains the generalizability of the unsupervised learner, improves the optimization stability of kernel estimation, and hence image adaptation, and leads to a faster inference with a speedup between 14.24 to 102.1x over existing methods.
Human-centric Image Cropping with Partition-aware and Content-preserving Features
Jul 21, 2022

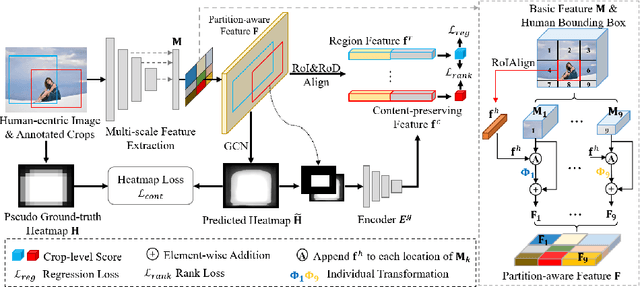
Image cropping aims to find visually appealing crops in an image, which is an important yet challenging task. In this paper, we consider a specific and practical application: human-centric image cropping, which focuses on the depiction of a person. To this end, we propose a human-centric image cropping method with two novel feature designs for the candidate crop: partition-aware feature and content-preserving feature. For partition-aware feature, we divide the whole image into nine partitions based on the human bounding box and treat different partitions in a candidate crop differently conditioned on the human information. For content-preserving feature, we predict a heatmap indicating the important content to be included in a good crop, and extract the geometric relation between the heatmap and a candidate crop. Extensive experiments demonstrate that our method can perform favorably against state-of-the-art image cropping methods on human-centric image cropping task. Code is available at https://github.com/bcmi/Human-Centric-Image-Cropping.
Q-Diffusion: Quantizing Diffusion Models
Feb 08, 2023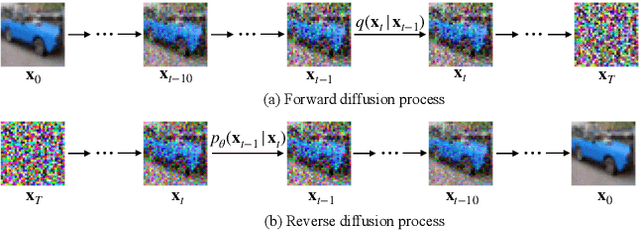

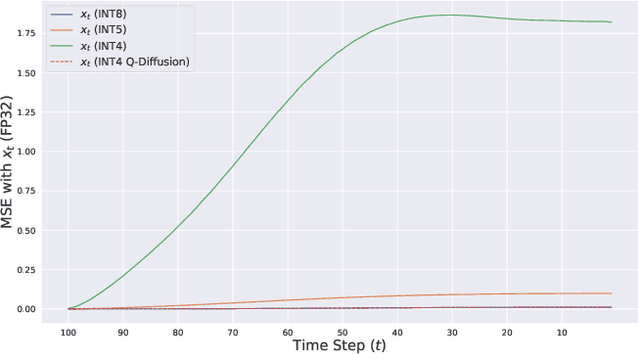
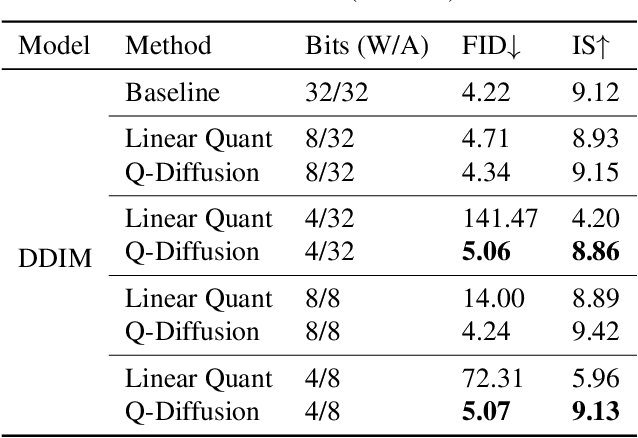
Diffusion models have recently achieved great success in synthesizing diverse and high-fidelity images. However, sampling speed and memory constraints remain a major barrier to the practical adoption of diffusion models as the generation process for these models can be slow due to the need for iterative noise estimation using complex neural networks. We propose a solution to this problem by compressing the noise estimation network to accelerate the generation process using post-training quantization (PTQ). While existing PTQ approaches have not been able to effectively deal with the changing output distributions of noise estimation networks in diffusion models over multiple time steps, we are able to formulate a PTQ method that is specifically designed to handle the unique multi-timestep structure of diffusion models with a data calibration scheme using data sampled from different time steps. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a FID change of at most 1.88. Our approach can also be applied to text-guided image generation, and for the first time we can run stable diffusion in 4-bit weights without losing much perceptual quality, as shown in Figure 5 and Figure 9.
TetCNN: Convolutional Neural Networks on Tetrahedral Meshes
Feb 08, 2023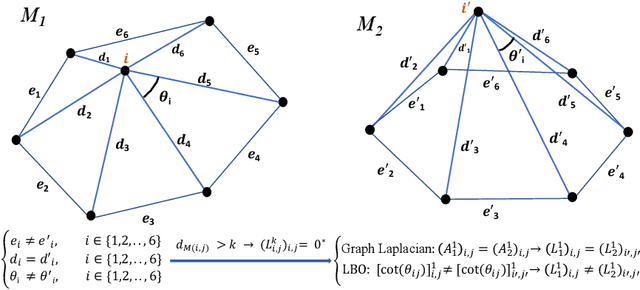
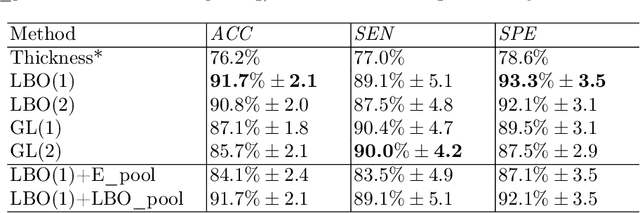
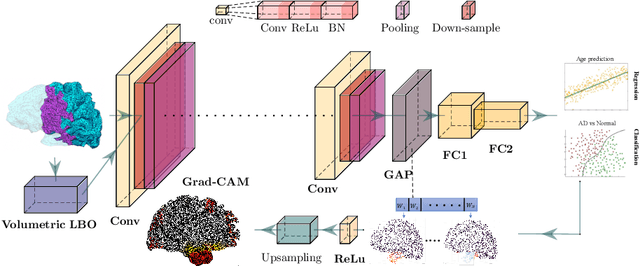
Convolutional neural networks (CNN) have been broadly studied on images, videos, graphs, and triangular meshes. However, it has seldom been studied on tetrahedral meshes. Given the merits of using volumetric meshes in applications like brain image analysis, we introduce a novel interpretable graph CNN framework for the tetrahedral mesh structure. Inspired by ChebyNet, our model exploits the volumetric Laplace-Beltrami Operator (LBO) to define filters over commonly used graph Laplacian which lacks the Riemannian metric information of 3D manifolds. For pooling adaptation, we introduce new objective functions for localized minimum cuts in the Graclus algorithm based on the LBO. We employ a piece-wise constant approximation scheme that uses the clustering assignment matrix to estimate the LBO on sampled meshes after each pooling. Finally, adapting the Gradient-weighted Class Activation Mapping algorithm for tetrahedral meshes, we use the obtained heatmaps to visualize discovered regions-of-interest as biomarkers. We demonstrate the effectiveness of our model on cortical tetrahedral meshes from patients with Alzheimer's disease, as there is scientific evidence showing the correlation of cortical thickness to neurodegenerative disease progression. Our results show the superiority of our LBO-based convolution layer and adapted pooling over the conventionally used unitary cortical thickness, graph Laplacian, and point cloud representation.
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 08, 2023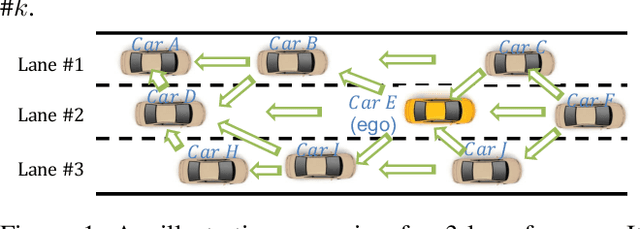

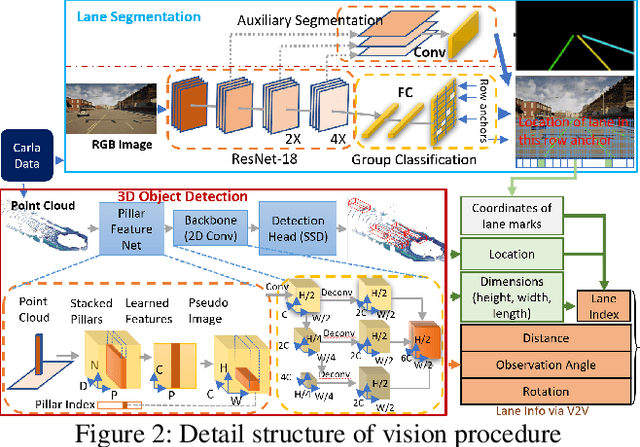
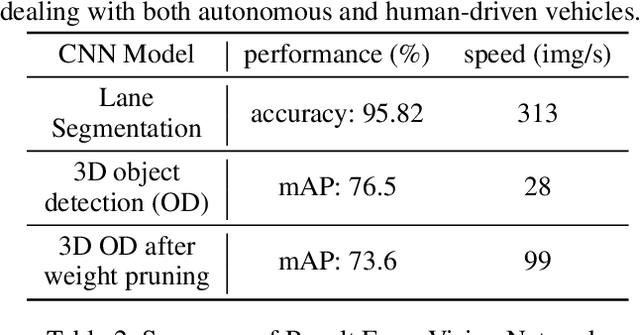
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
Spatiotemporal Deformation Perception for Fisheye Video Rectification
Feb 08, 2023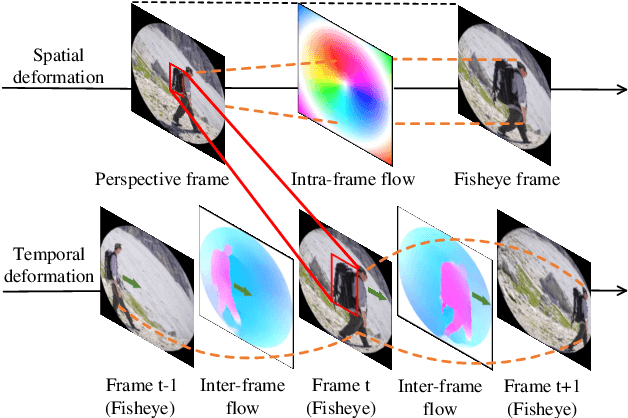
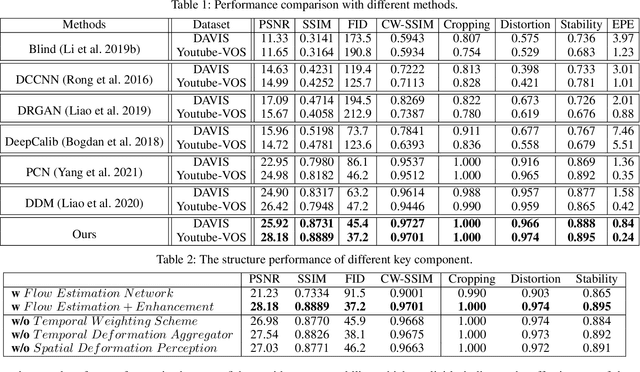
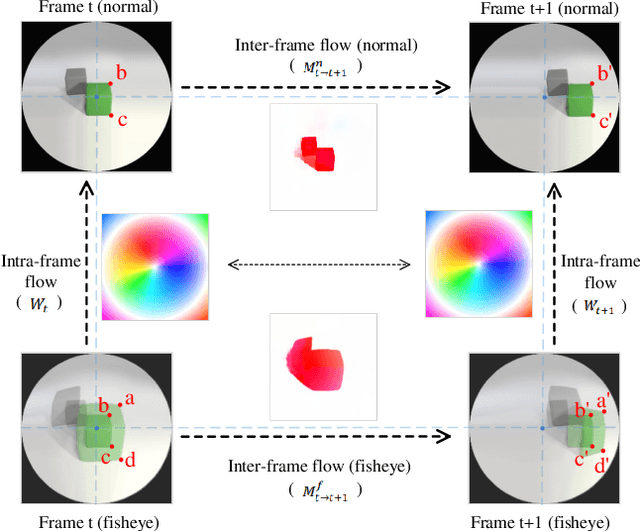
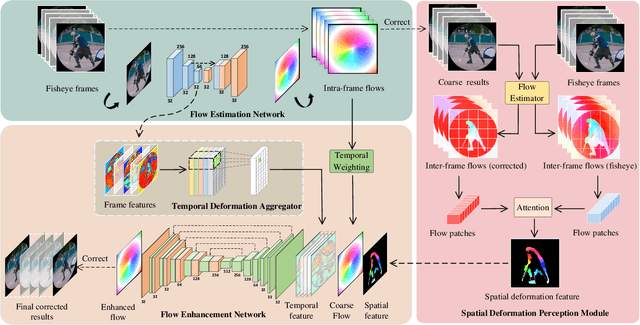
Although the distortion correction of fisheye images has been extensively studied, the correction of fisheye videos is still an elusive challenge. For different frames of the fisheye video, the existing image correction methods ignore the correlation of sequences, resulting in temporal jitter in the corrected video. To solve this problem, we propose a temporal weighting scheme to get a plausible global optical flow, which mitigates the jitter effect by progressively reducing the weight of frames. Subsequently, we observe that the inter-frame optical flow of the video is facilitated to perceive the local spatial deformation of the fisheye video. Therefore, we derive the spatial deformation through the flows of fisheye and distorted-free videos, thereby enhancing the local accuracy of the predicted result. However, the independent correction for each frame disrupts the temporal correlation. Due to the property of fisheye video, a distorted moving object may be able to find its distorted-free pattern at another moment. To this end, a temporal deformation aggregator is designed to reconstruct the deformation correlation between frames and provide a reliable global feature. Our method achieves an end-to-end correction and demonstrates superiority in correction quality and stability compared with the SOTA correction methods.
Robustness to Spurious Correlations Improves Semantic Out-of-Distribution Detection
Feb 08, 2023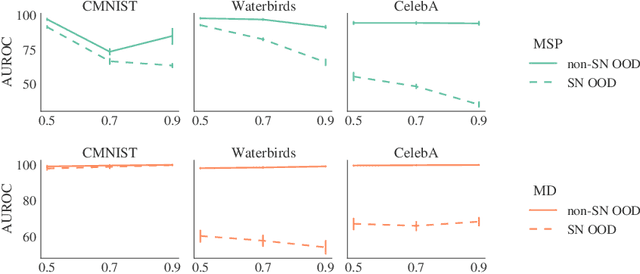
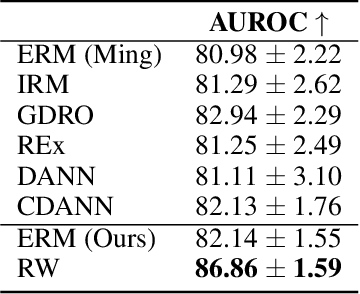
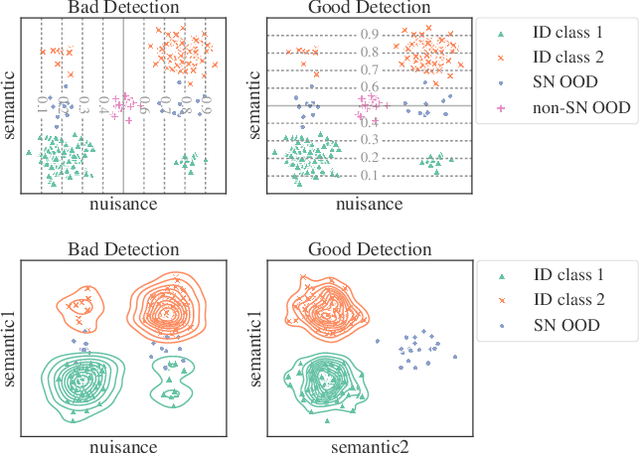
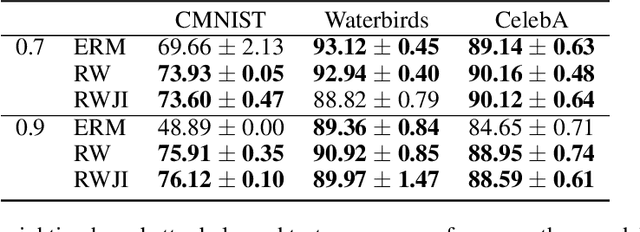
Methods which utilize the outputs or feature representations of predictive models have emerged as promising approaches for out-of-distribution (OOD) detection of image inputs. However, these methods struggle to detect OOD inputs that share nuisance values (e.g. background) with in-distribution inputs. The detection of shared-nuisance out-of-distribution (SN-OOD) inputs is particularly relevant in real-world applications, as anomalies and in-distribution inputs tend to be captured in the same settings during deployment. In this work, we provide a possible explanation for SN-OOD detection failures and propose nuisance-aware OOD detection to address them. Nuisance-aware OOD detection substitutes a classifier trained via empirical risk minimization and cross-entropy loss with one that 1. is trained under a distribution where the nuisance-label relationship is broken and 2. yields representations that are independent of the nuisance under this distribution, both marginally and conditioned on the label. We can train a classifier to achieve these objectives using Nuisance-Randomized Distillation (NuRD), an algorithm developed for OOD generalization under spurious correlations. Output- and feature-based nuisance-aware OOD detection perform substantially better than their original counterparts, succeeding even when detection based on domain generalization algorithms fails to improve performance.