 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Endoscopic Image Key-Points Matching
Aug 24, 2022
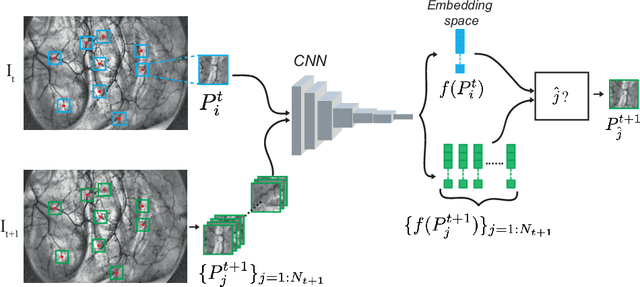
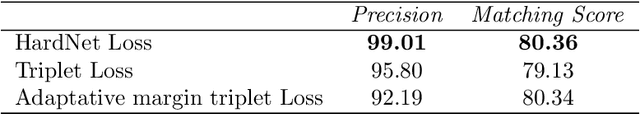
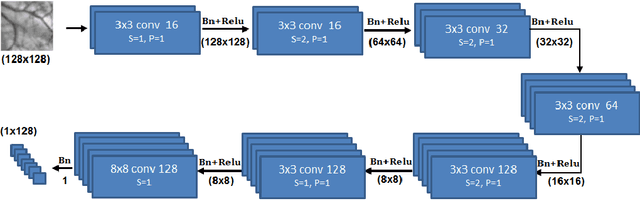
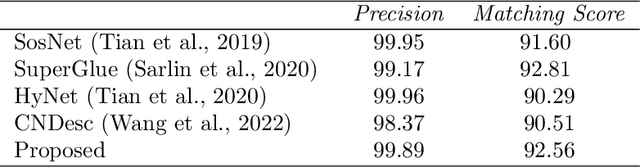
Feature matching and finding correspondences between endoscopic images is a key step in many clinical applications such as patient follow-up and generation of panoramic image from clinical sequences for fast anomalies localization. Nonetheless, due to the high texture variability present in endoscopic images, the development of robust and accurate feature matching becomes a challenging task. Recently, deep learning techniques which deliver learned features extracted via convolutional neural networks (CNNs) have gained traction in a wide range of computer vision tasks. However, they all follow a supervised learning scheme where a large amount of annotated data is required to reach good performances, which is generally not always available for medical data databases. To overcome this limitation related to labeled data scarcity, the self-supervised learning paradigm has recently shown great success in a number of applications. This paper proposes a novel self-supervised approach for endoscopic image matching based on deep learning techniques. When compared to standard hand-crafted local feature descriptors, our method outperformed them in terms of precision and recall. Furthermore, our self-supervised descriptor provides a competitive performance in comparison to a selection of state-of-the-art deep learning based supervised methods in terms of precision and matching score.
Foundation Models for Natural Language Processing -- Pre-trained Language Models Integrating Media
Feb 16, 2023This open access book provides a comprehensive overview of the state of the art in research and applications of Foundation Models and is intended for readers familiar with basic Natural Language Processing (NLP) concepts. Over the recent years, a revolutionary new paradigm has been developed for training models for NLP. These models are first pre-trained on large collections of text documents to acquire general syntactic knowledge and semantic information. Then, they are fine-tuned for specific tasks, which they can often solve with superhuman accuracy. When the models are large enough, they can be instructed by prompts to solve new tasks without any fine-tuning. Moreover, they can be applied to a wide range of different media and problem domains, ranging from image and video processing to robot control learning. Because they provide a blueprint for solving many tasks in artificial intelligence, they have been called Foundation Models. After a brief introduction to basic NLP models the main pre-trained language models BERT, GPT and sequence-to-sequence transformer are described, as well as the concepts of self-attention and context-sensitive embedding. Then, different approaches to improving these models are discussed, such as expanding the pre-training criteria, increasing the length of input texts, or including extra knowledge. An overview of the best-performing models for about twenty application areas is then presented, e.g., question answering, translation, story generation, dialog systems, generating images from text, etc. For each application area, the strengths and weaknesses of current models are discussed, and an outlook on further developments is given. In addition, links are provided to freely available program code. A concluding chapter summarizes the economic opportunities, mitigation of risks, and potential developments of AI.
Expanding Language-Image Pretrained Models for General Video Recognition
Aug 04, 2022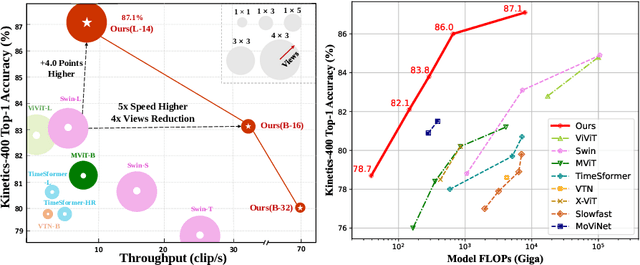
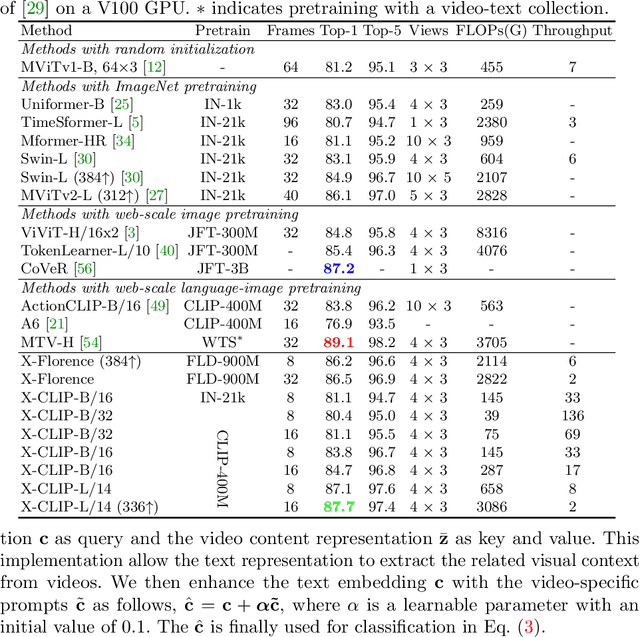
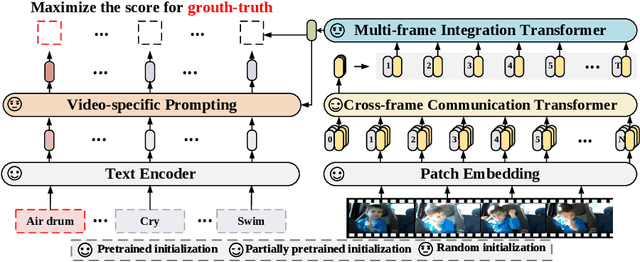
Contrastive language-image pretraining has shown great success in learning visual-textual joint representation from web-scale data, demonstrating remarkable "zero-shot" generalization ability for various image tasks. However, how to effectively expand such new language-image pretraining methods to video domains is still an open problem. In this work, we present a simple yet effective approach that adapts the pretrained language-image models to video recognition directly, instead of pretraining a new model from scratch. More concretely, to capture the long-range dependencies of frames along the temporal dimension, we propose a cross-frame attention mechanism that explicitly exchanges information across frames. Such module is lightweight and can be plugged into pretrained language-image models seamlessly. Moreover, we propose a video-specific prompting scheme, which leverages video content information for generating discriminative textual prompts. Extensive experiments demonstrate that our approach is effective and can be generalized to different video recognition scenarios. In particular, under fully-supervised settings, our approach achieves a top-1 accuracy of 87.1% on Kinectics-400, while using 12 times fewer FLOPs compared with Swin-L and ViViT-H. In zero-shot experiments, our approach surpasses the current state-of-the-art methods by +7.6% and +14.9% in terms of top-1 accuracy under two popular protocols. In few-shot scenarios, our approach outperforms previous best methods by +32.1% and +23.1% when the labeled data is extremely limited. Code and models are available at https://aka.ms/X-CLIP
Q-Diffusion: Quantizing Diffusion Models
Feb 08, 2023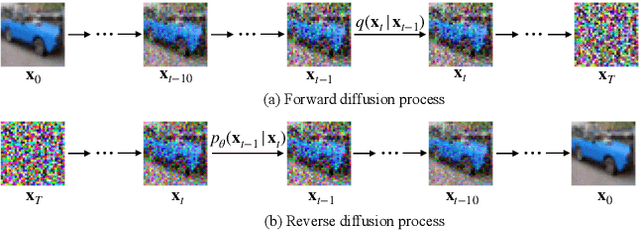

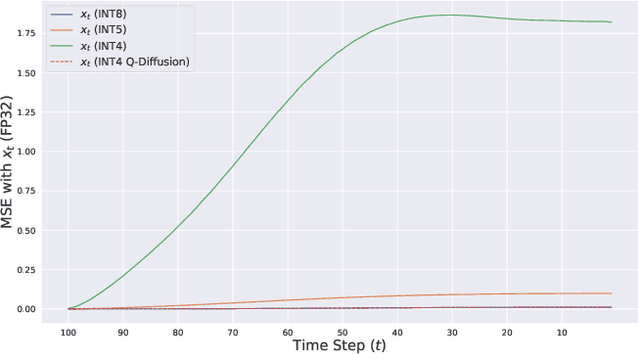
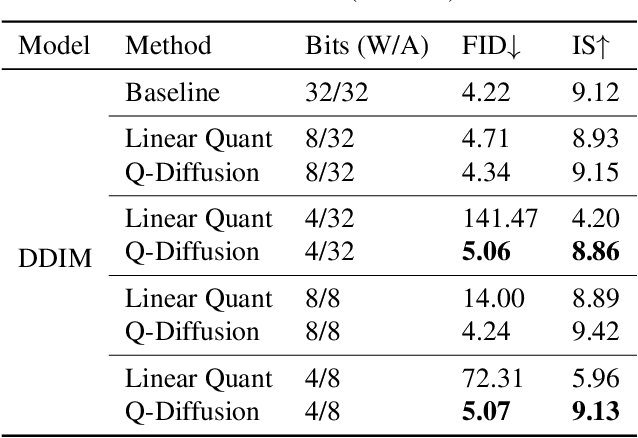
Diffusion models have recently achieved great success in synthesizing diverse and high-fidelity images. However, sampling speed and memory constraints remain a major barrier to the practical adoption of diffusion models as the generation process for these models can be slow due to the need for iterative noise estimation using complex neural networks. We propose a solution to this problem by compressing the noise estimation network to accelerate the generation process using post-training quantization (PTQ). While existing PTQ approaches have not been able to effectively deal with the changing output distributions of noise estimation networks in diffusion models over multiple time steps, we are able to formulate a PTQ method that is specifically designed to handle the unique multi-timestep structure of diffusion models with a data calibration scheme using data sampled from different time steps. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a FID change of at most 1.88. Our approach can also be applied to text-guided image generation, and for the first time we can run stable diffusion in 4-bit weights without losing much perceptual quality, as shown in Figure 5 and Figure 9.
TetCNN: Convolutional Neural Networks on Tetrahedral Meshes
Feb 08, 2023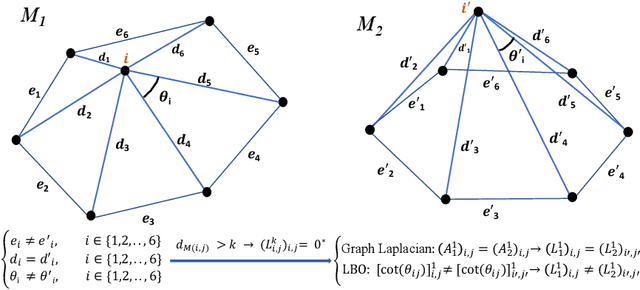
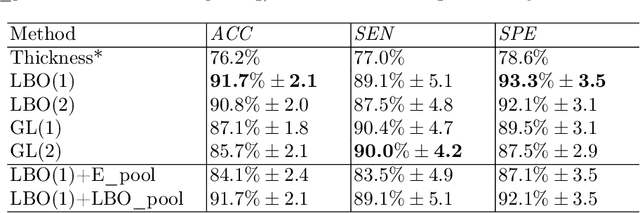
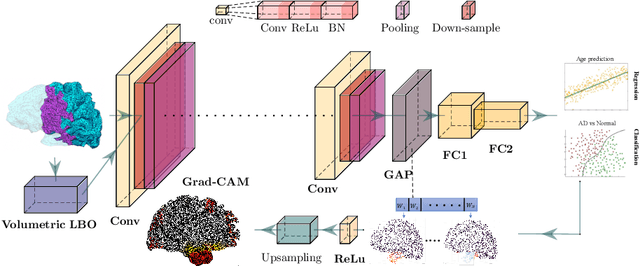
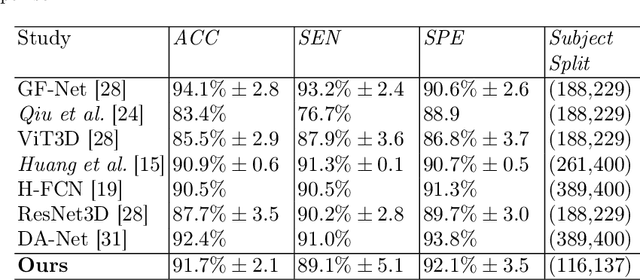
Convolutional neural networks (CNN) have been broadly studied on images, videos, graphs, and triangular meshes. However, it has seldom been studied on tetrahedral meshes. Given the merits of using volumetric meshes in applications like brain image analysis, we introduce a novel interpretable graph CNN framework for the tetrahedral mesh structure. Inspired by ChebyNet, our model exploits the volumetric Laplace-Beltrami Operator (LBO) to define filters over commonly used graph Laplacian which lacks the Riemannian metric information of 3D manifolds. For pooling adaptation, we introduce new objective functions for localized minimum cuts in the Graclus algorithm based on the LBO. We employ a piece-wise constant approximation scheme that uses the clustering assignment matrix to estimate the LBO on sampled meshes after each pooling. Finally, adapting the Gradient-weighted Class Activation Mapping algorithm for tetrahedral meshes, we use the obtained heatmaps to visualize discovered regions-of-interest as biomarkers. We demonstrate the effectiveness of our model on cortical tetrahedral meshes from patients with Alzheimer's disease, as there is scientific evidence showing the correlation of cortical thickness to neurodegenerative disease progression. Our results show the superiority of our LBO-based convolution layer and adapted pooling over the conventionally used unitary cortical thickness, graph Laplacian, and point cloud representation.
Spatiotemporal Deformation Perception for Fisheye Video Rectification
Feb 08, 2023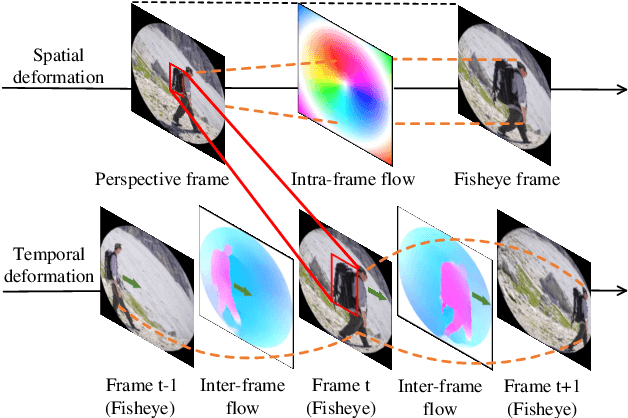
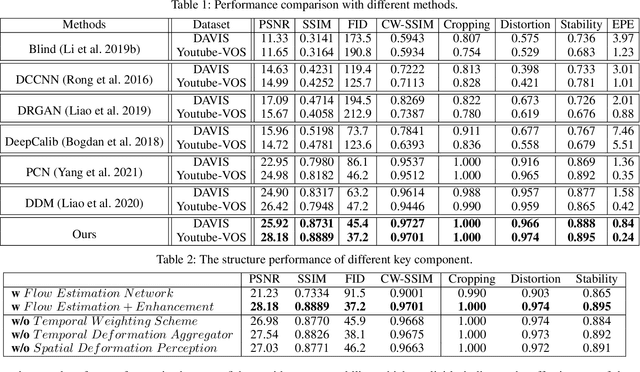
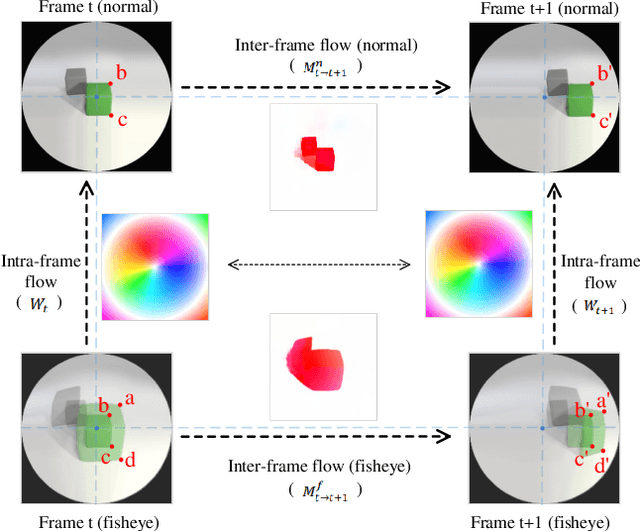
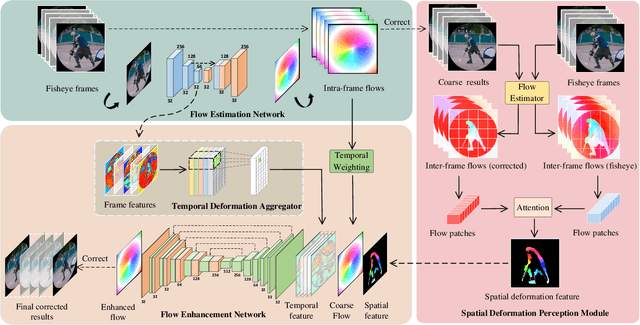
Although the distortion correction of fisheye images has been extensively studied, the correction of fisheye videos is still an elusive challenge. For different frames of the fisheye video, the existing image correction methods ignore the correlation of sequences, resulting in temporal jitter in the corrected video. To solve this problem, we propose a temporal weighting scheme to get a plausible global optical flow, which mitigates the jitter effect by progressively reducing the weight of frames. Subsequently, we observe that the inter-frame optical flow of the video is facilitated to perceive the local spatial deformation of the fisheye video. Therefore, we derive the spatial deformation through the flows of fisheye and distorted-free videos, thereby enhancing the local accuracy of the predicted result. However, the independent correction for each frame disrupts the temporal correlation. Due to the property of fisheye video, a distorted moving object may be able to find its distorted-free pattern at another moment. To this end, a temporal deformation aggregator is designed to reconstruct the deformation correlation between frames and provide a reliable global feature. Our method achieves an end-to-end correction and demonstrates superiority in correction quality and stability compared with the SOTA correction methods.
Robustness to Spurious Correlations Improves Semantic Out-of-Distribution Detection
Feb 08, 2023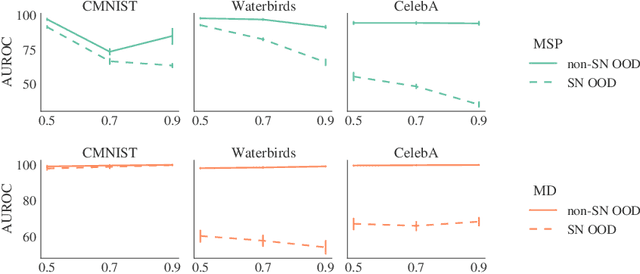
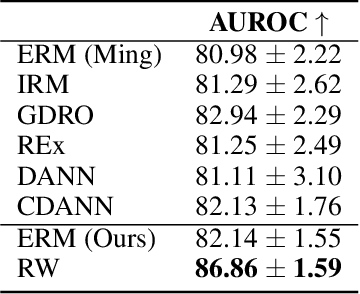
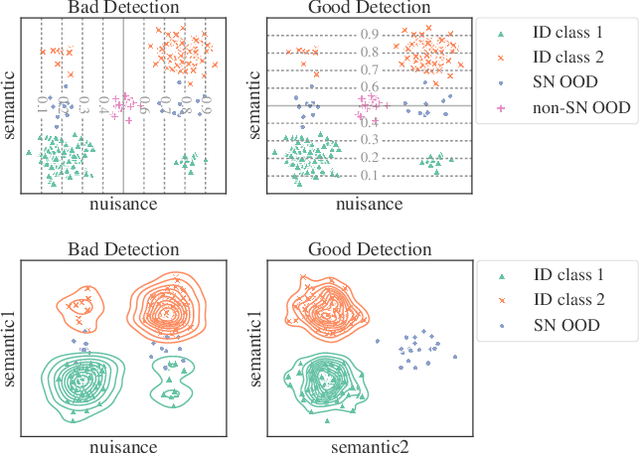
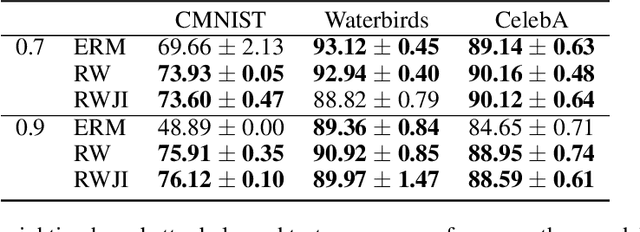
Methods which utilize the outputs or feature representations of predictive models have emerged as promising approaches for out-of-distribution (OOD) detection of image inputs. However, these methods struggle to detect OOD inputs that share nuisance values (e.g. background) with in-distribution inputs. The detection of shared-nuisance out-of-distribution (SN-OOD) inputs is particularly relevant in real-world applications, as anomalies and in-distribution inputs tend to be captured in the same settings during deployment. In this work, we provide a possible explanation for SN-OOD detection failures and propose nuisance-aware OOD detection to address them. Nuisance-aware OOD detection substitutes a classifier trained via empirical risk minimization and cross-entropy loss with one that 1. is trained under a distribution where the nuisance-label relationship is broken and 2. yields representations that are independent of the nuisance under this distribution, both marginally and conditioned on the label. We can train a classifier to achieve these objectives using Nuisance-Randomized Distillation (NuRD), an algorithm developed for OOD generalization under spurious correlations. Output- and feature-based nuisance-aware OOD detection perform substantially better than their original counterparts, succeeding even when detection based on domain generalization algorithms fails to improve performance.
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 08, 2023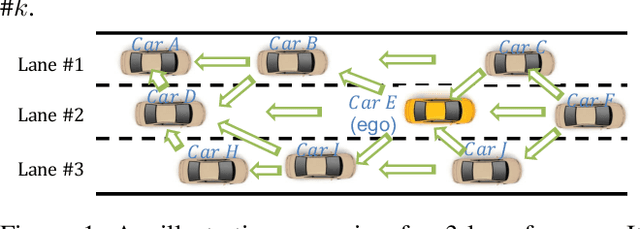

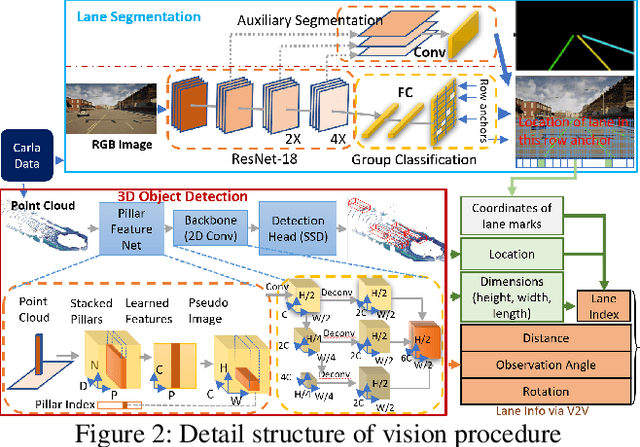
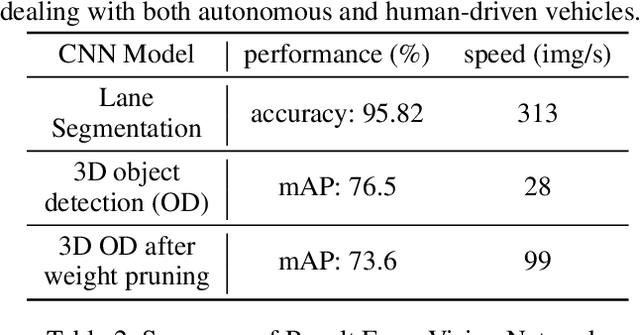
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
CoMAE: Single Model Hybrid Pre-training on Small-Scale RGB-D Datasets
Feb 13, 2023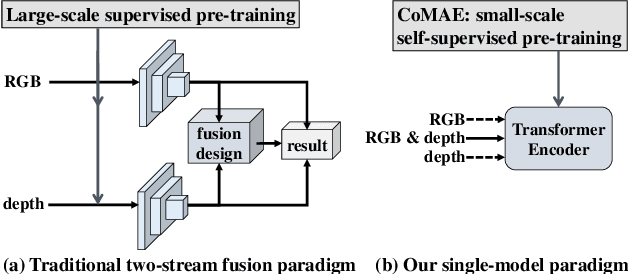

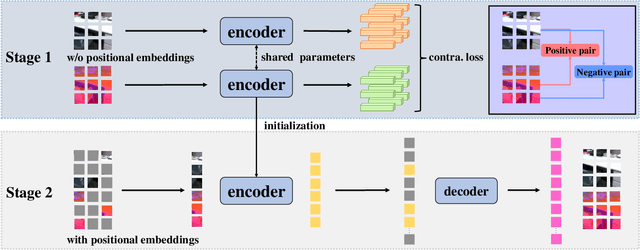

Current RGB-D scene recognition approaches often train two standalone backbones for RGB and depth modalities with the same Places or ImageNet pre-training. However, the pre-trained depth network is still biased by RGB-based models which may result in a suboptimal solution. In this paper, we present a single-model self-supervised hybrid pre-training framework for RGB and depth modalities, termed as CoMAE. Our CoMAE presents a curriculum learning strategy to unify the two popular self-supervised representation learning algorithms: contrastive learning and masked image modeling. Specifically, we first build a patch-level alignment task to pre-train a single encoder shared by two modalities via cross-modal contrastive learning. Then, the pre-trained contrastive encoder is passed to a multi-modal masked autoencoder to capture the finer context features from a generative perspective. In addition, our single-model design without requirement of fusion module is very flexible and robust to generalize to unimodal scenario in both training and testing phases. Extensive experiments on SUN RGB-D and NYUDv2 datasets demonstrate the effectiveness of our CoMAE for RGB and depth representation learning. In addition, our experiment results reveal that CoMAE is a data-efficient representation learner. Although we only use the small-scale and unlabeled training set for pre-training, our CoMAE pre-trained models are still competitive to the state-of-the-art methods with extra large-scale and supervised RGB dataset pre-training. Code will be released at https://github.com/MCG-NJU/CoMAE.
[Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT
Feb 13, 2023![Figure 1 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table2-1.png&w=640&q=75)
Minerals are indispensable for a functioning modern society. Yet, their supply is limited causing a need for optimizing their exploration and extraction both from ores and recyclable materials. Typically, these processes must be meticulously adapted to the precise properties of the processed particles, requiring an extensive characterization of their shapes, appearances as well as the overall material composition. Current approaches perform this analysis based on bulk segmentation and characterization of particles, and rely on rudimentary postprocessing techniques to separate touching particles. However, due to their inability to reliably perform this separation as well as the need to retrain or reconfigure most methods for each new image, these approaches leave untapped potential to be leveraged. Here, we propose an instance segmentation method that is able to extract individual particles from large micro CT images taken from mineral samples embedded in an epoxy matrix. Our approach is based on the powerful nnU-Net framework, introduces a particle size normalization, makes use of a border-core representation to enable instance segmentation and is trained with a large dataset containing particles of numerous different materials and minerals. We demonstrate that our approach can be applied out-of-the box to a large variety of particle types, including materials and appearances that have not been part of the training set. Thus, no further manual annotations and retraining are required when applying the method to new mineral samples, enabling substantially higher scalability of experiments than existing methods. Our code and dataset are made publicly available.