 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 12, 2024
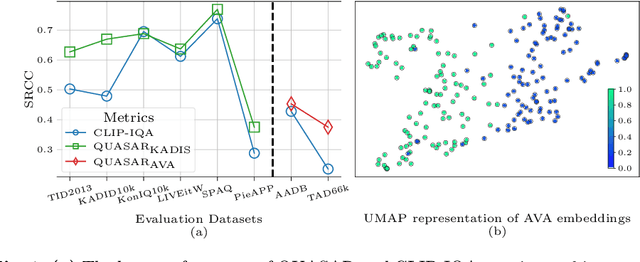
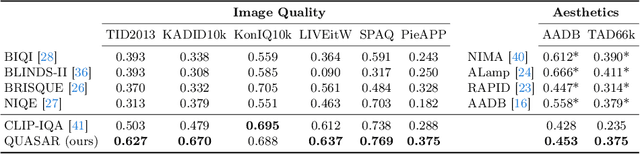
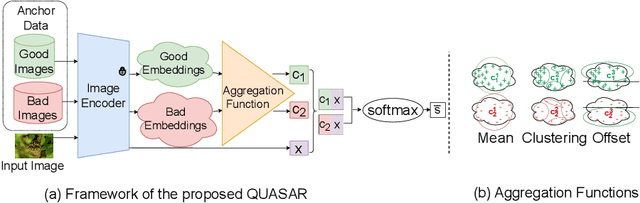

This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.
Two-stage Cytopathological Image Synthesis for Augmenting Cervical Abnormality Screening
Feb 25, 2024Automatic thin-prep cytologic test (TCT) screening can assist pathologists in finding cervical abnormality towards accurate and efficient cervical cancer diagnosis. Current automatic TCT screening systems mostly involve abnormal cervical cell detection, which generally requires large-scale and diverse training data with high-quality annotations to achieve promising performance. Pathological image synthesis is naturally raised to minimize the efforts in data collection and annotation. However, it is challenging to generate realistic large-size cytopathological images while simultaneously synthesizing visually plausible appearances for small-size abnormal cervical cells. In this paper, we propose a two-stage image synthesis framework to create synthetic data for augmenting cervical abnormality screening. In the first Global Image Generation stage, a Normal Image Generator is designed to generate cytopathological images full of normal cervical cells. In the second Local Cell Editing stage, normal cells are randomly selected from the generated images and then are converted to different types of abnormal cells using the proposed Abnormal Cell Synthesizer. Both Normal Image Generator and Abnormal Cell Synthesizer are built upon Stable Diffusion, a pre-trained foundation model for image synthesis, via parameter-efficient fine-tuning methods for customizing cytopathological image contents and extending spatial layout controllability, respectively. Our experiments demonstrate the synthetic image quality, diversity, and controllability of the proposed synthesis framework, and validate its data augmentation effectiveness in enhancing the performance of abnormal cervical cell detection.
Text2QR: Harmonizing Aesthetic Customization and Scanning Robustness for Text-Guided QR Code Generation
Mar 13, 2024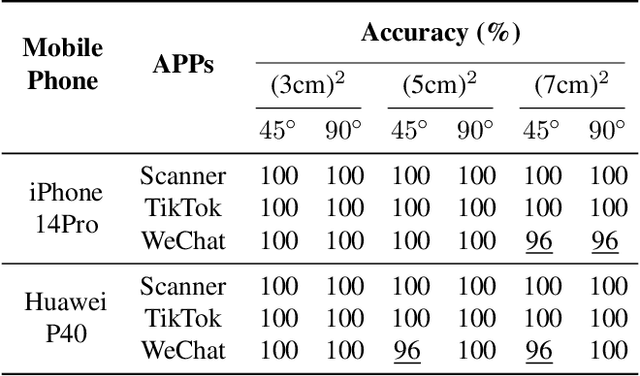


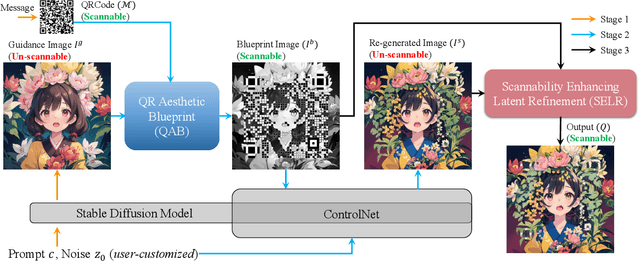
In the digital era, QR codes serve as a linchpin connecting virtual and physical realms. Their pervasive integration across various applications highlights the demand for aesthetically pleasing codes without compromised scannability. However, prevailing methods grapple with the intrinsic challenge of balancing customization and scannability. Notably, stable-diffusion models have ushered in an epoch of high-quality, customizable content generation. This paper introduces Text2QR, a pioneering approach leveraging these advancements to address a fundamental challenge: concurrently achieving user-defined aesthetics and scanning robustness. To ensure stable generation of aesthetic QR codes, we introduce the QR Aesthetic Blueprint (QAB) module, generating a blueprint image exerting control over the entire generation process. Subsequently, the Scannability Enhancing Latent Refinement (SELR) process refines the output iteratively in the latent space, enhancing scanning robustness. This approach harnesses the potent generation capabilities of stable-diffusion models, navigating the trade-off between image aesthetics and QR code scannability. Our experiments demonstrate the seamless fusion of visual appeal with the practical utility of aesthetic QR codes, markedly outperforming prior methods. Codes are available at \url{https://github.com/mulns/Text2QR}
Dynamic Graph Representation with Knowledge-aware Attention for Histopathology Whole Slide Image Analysis
Mar 12, 2024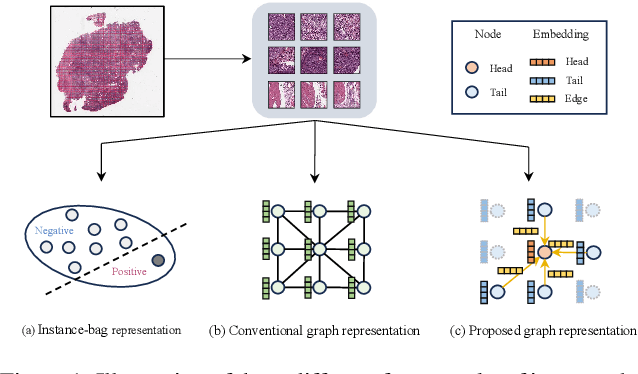
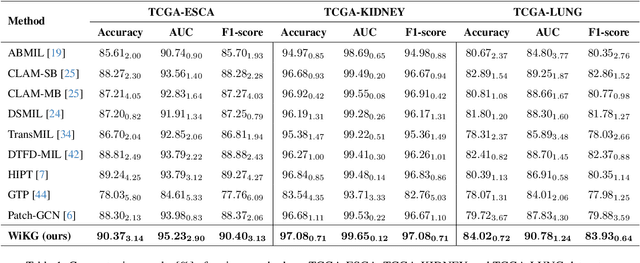
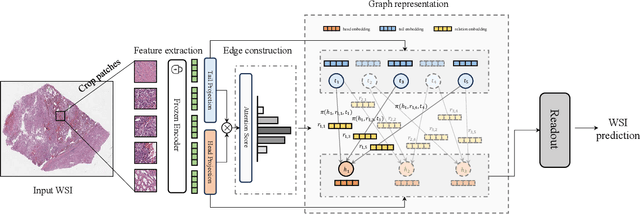
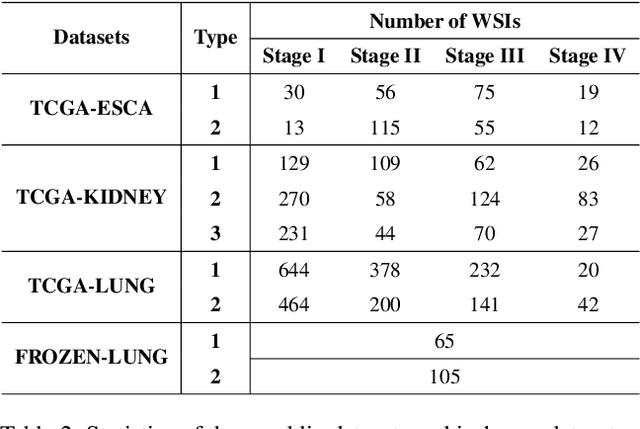
Histopathological whole slide images (WSIs) classification has become a foundation task in medical microscopic imaging processing. Prevailing approaches involve learning WSIs as instance-bag representations, emphasizing significant instances but struggling to capture the interactions between instances. Additionally, conventional graph representation methods utilize explicit spatial positions to construct topological structures but restrict the flexible interaction capabilities between instances at arbitrary locations, particularly when spatially distant. In response, we propose a novel dynamic graph representation algorithm that conceptualizes WSIs as a form of the knowledge graph structure. Specifically, we dynamically construct neighbors and directed edge embeddings based on the head and tail relationships between instances. Then, we devise a knowledge-aware attention mechanism that can update the head node features by learning the joint attention score of each neighbor and edge. Finally, we obtain a graph-level embedding through the global pooling process of the updated head, serving as an implicit representation for the WSI classification. Our end-to-end graph representation learning approach has outperformed the state-of-the-art WSI analysis methods on three TCGA benchmark datasets and in-house test sets. Our code is available at https://github.com/WonderLandxD/WiKG.
Smartphone region-wise image indoor localization using deep learning for indoor tourist attraction
Mar 12, 2024
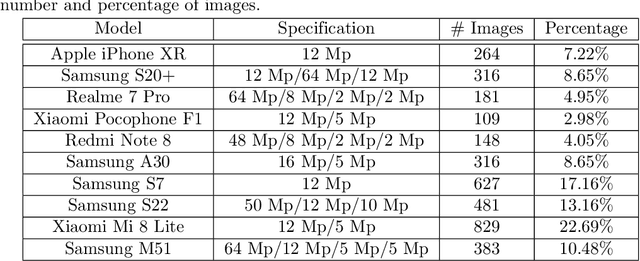
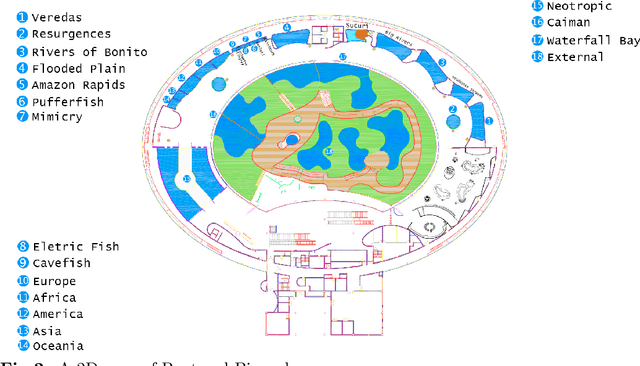
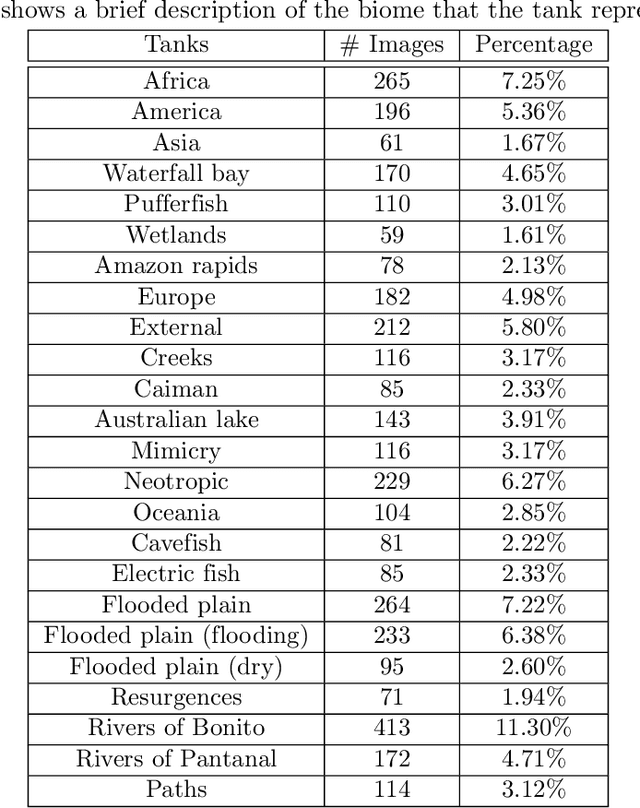
Smart indoor tourist attractions, such as smart museums and aquariums, usually require a significant investment in indoor localization devices. The smartphone Global Positional Systems use is unsuitable for scenarios where dense materials such as concrete and metal block weaken the GPS signals, which is the most common scenario in an indoor tourist attraction. Deep learning makes it possible to perform region-wise indoor localization using smartphone images. This approach does not require any investment in infrastructure, reducing the cost and time to turn museums and aquariums into smart museums or smart aquariums. This paper proposes using deep learning algorithms to classify locations using smartphone camera images for indoor tourism attractions. We evaluate our proposal in a real-world scenario in Brazil. We extensively collect images from ten different smartphones to classify biome-themed fish tanks inside the Pantanal Biopark, creating a new dataset of 3654 images. We tested seven state-of-the-art neural networks, three being transformer-based, achieving precision around 90% on average and recall and f-score around 89% on average. The results indicate good feasibility of the proposal in a most indoor tourist attractions.
Stochastic Conditional Diffusion Models for Semantic Image Synthesis
Feb 26, 2024Semantic image synthesis (SIS) is a task to generate realistic images corresponding to semantic maps (labels). It can be applied to diverse real-world practices such as photo editing or content creation. However, in real-world applications, SIS often encounters noisy user inputs. To address this, we propose Stochastic Conditional Diffusion Model (SCDM), which is a robust conditional diffusion model that features novel forward and generation processes tailored for SIS with noisy labels. It enhances robustness by stochastically perturbing the semantic label maps through Label Diffusion, which diffuses the labels with discrete diffusion. Through the diffusion of labels, the noisy and clean semantic maps become similar as the timestep increases, eventually becoming identical at $t=T$. This facilitates the generation of an image close to a clean image, enabling robust generation. Furthermore, we propose a class-wise noise schedule to differentially diffuse the labels depending on the class. We demonstrate that the proposed method generates high-quality samples through extensive experiments and analyses on benchmark datasets, including a novel experimental setup simulating human errors during real-world applications.
Auxiliary CycleGAN-guidance for Task-Aware Domain Translation from Duplex to Monoplex IHC Images
Mar 12, 2024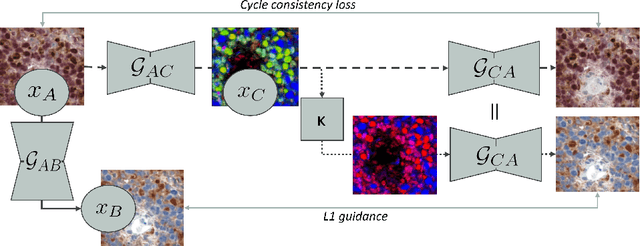

Generative models enable the translation from a source image domain where readily trained models are available to a target domain unseen during training. While Cycle Generative Adversarial Networks (GANs) are well established, the associated cycle consistency constrain relies on that an invertible mapping exists between the two domains. This is, however, not the case for the translation between images stained with chromogenic monoplex and duplex immunohistochemistry (IHC) assays. Focusing on the translation from the latter to the first, we propose - through the introduction of a novel training design, an alternative constrain leveraging a set of immunofluorescence (IF) images as an auxiliary unpaired image domain. Quantitative and qualitative results on a downstream segmentation task show the benefit of the proposed method in comparison to baseline approaches.
AIGCs Confuse AI Too: Investigating and Explaining Synthetic Image-induced Hallucinations in Large Vision-Language Models
Mar 13, 2024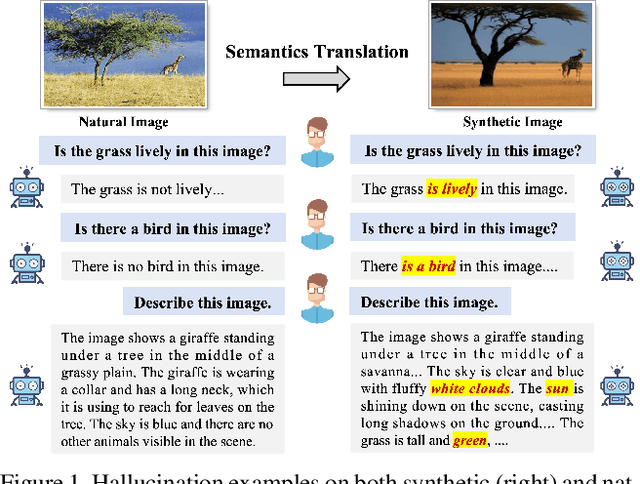
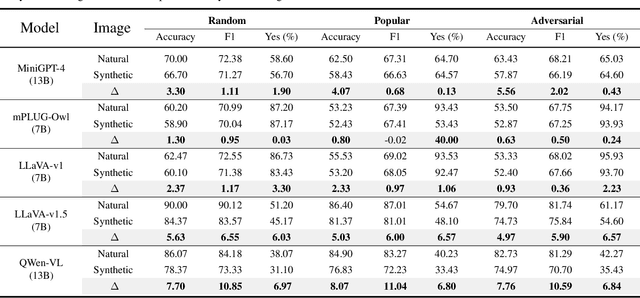

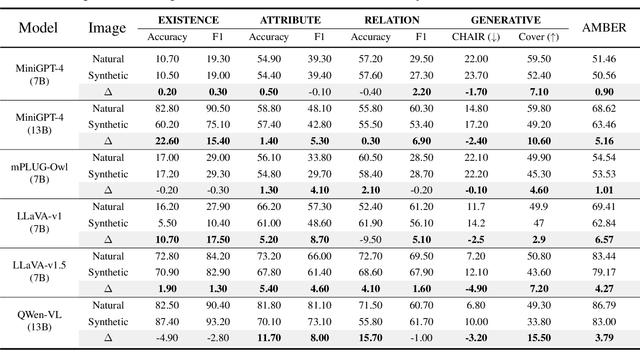
The evolution of Artificial Intelligence Generated Contents (AIGCs) is advancing towards higher quality. The growing interactions with AIGCs present a new challenge to the data-driven AI community: While AI-generated contents have played a crucial role in a wide range of AI models, the potential hidden risks they introduce have not been thoroughly examined. Beyond human-oriented forgery detection, AI-generated content poses potential issues for AI models originally designed to process natural data. In this study, we underscore the exacerbated hallucination phenomena in Large Vision-Language Models (LVLMs) caused by AI-synthetic images. Remarkably, our findings shed light on a consistent AIGC \textbf{hallucination bias}: the object hallucinations induced by synthetic images are characterized by a greater quantity and a more uniform position distribution, even these synthetic images do not manifest unrealistic or additional relevant visual features compared to natural images. Moreover, our investigations on Q-former and Linear projector reveal that synthetic images may present token deviations after visual projection, thereby amplifying the hallucination bias.
PathM3: A Multimodal Multi-Task Multiple Instance Learning Framework for Whole Slide Image Classification and Captioning
Mar 13, 2024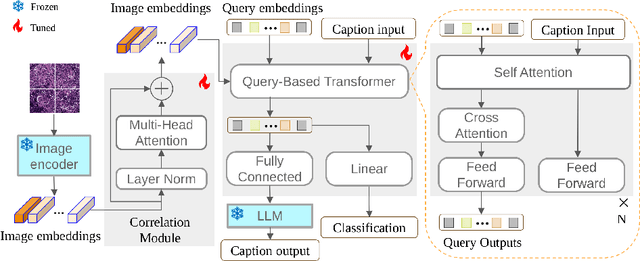
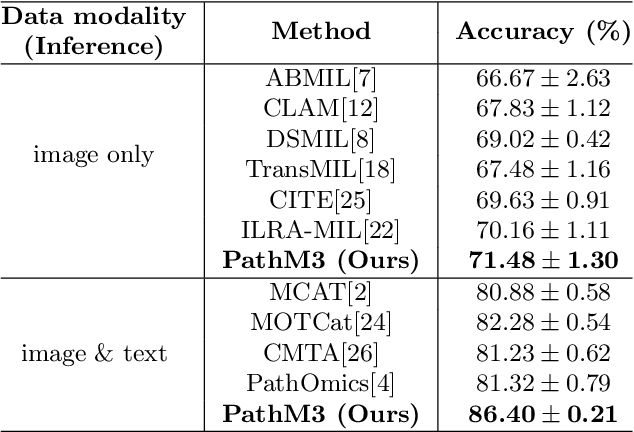

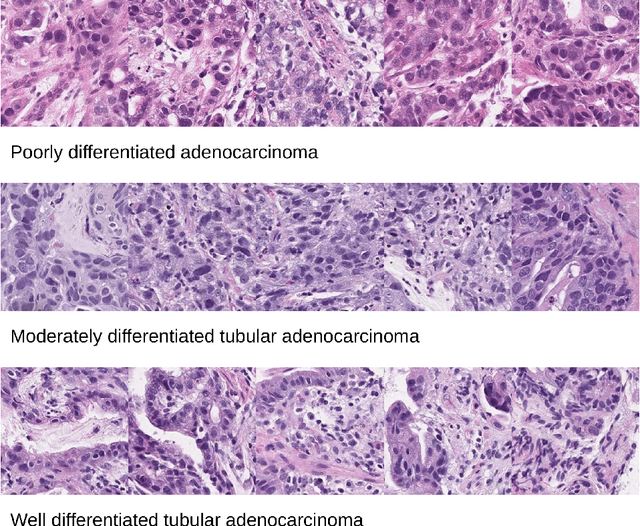
In the field of computational histopathology, both whole slide images (WSIs) and diagnostic captions provide valuable insights for making diagnostic decisions. However, aligning WSIs with diagnostic captions presents a significant challenge. This difficulty arises from two main factors: 1) Gigapixel WSIs are unsuitable for direct input into deep learning models, and the redundancy and correlation among the patches demand more attention; and 2) Authentic WSI diagnostic captions are extremely limited, making it difficult to train an effective model. To overcome these obstacles, we present PathM3, a multimodal, multi-task, multiple instance learning (MIL) framework for WSI classification and captioning. PathM3 adapts a query-based transformer to effectively align WSIs with diagnostic captions. Given that histopathology visual patterns are redundantly distributed across WSIs, we aggregate each patch feature with MIL method that considers the correlations among instances. Furthermore, our PathM3 overcomes data scarcity in WSI-level captions by leveraging limited WSI diagnostic caption data in the manner of multi-task joint learning. Extensive experiments with improved classification accuracy and caption generation demonstrate the effectiveness of our method on both WSI classification and captioning task.
RSAM-Seg: A SAM-based Approach with Prior Knowledge Integration for Remote Sensing Image Semantic Segmentation
Feb 29, 2024The development of high-resolution remote sensing satellites has provided great convenience for research work related to remote sensing. Segmentation and extraction of specific targets are essential tasks when facing the vast and complex remote sensing images. Recently, the introduction of Segment Anything Model (SAM) provides a universal pre-training model for image segmentation tasks. While the direct application of SAM to remote sensing image segmentation tasks does not yield satisfactory results, we propose RSAM-Seg, which stands for Remote Sensing SAM with Semantic Segmentation, as a tailored modification of SAM for the remote sensing field and eliminates the need for manual intervention to provide prompts. Adapter-Scale, a set of supplementary scaling modules, are proposed in the multi-head attention blocks of the encoder part of SAM. Furthermore, Adapter-Feature are inserted between the Vision Transformer (ViT) blocks. These modules aim to incorporate high-frequency image information and image embedding features to generate image-informed prompts. Experiments are conducted on four distinct remote sensing scenarios, encompassing cloud detection, field monitoring, building detection and road mapping tasks . The experimental results not only showcase the improvement over the original SAM and U-Net across cloud, buildings, fields and roads scenarios, but also highlight the capacity of RSAM-Seg to discern absent areas within the ground truth of certain datasets, affirming its potential as an auxiliary annotation method. In addition, the performance in few-shot scenarios is commendable, underscores its potential in dealing with limited datasets.