 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models
Feb 01, 2023
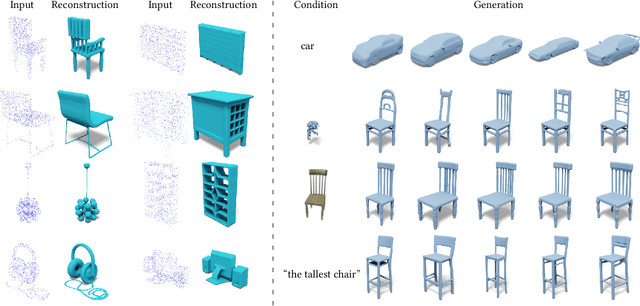
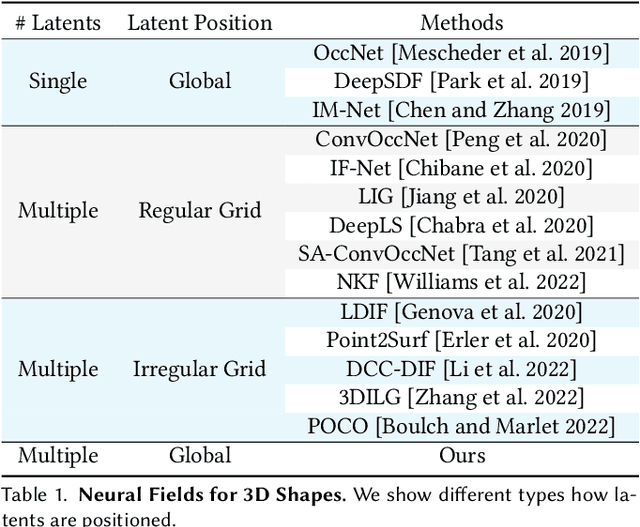
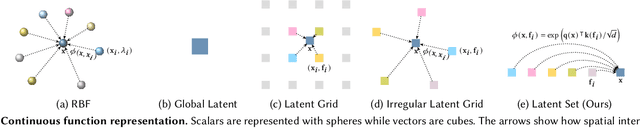
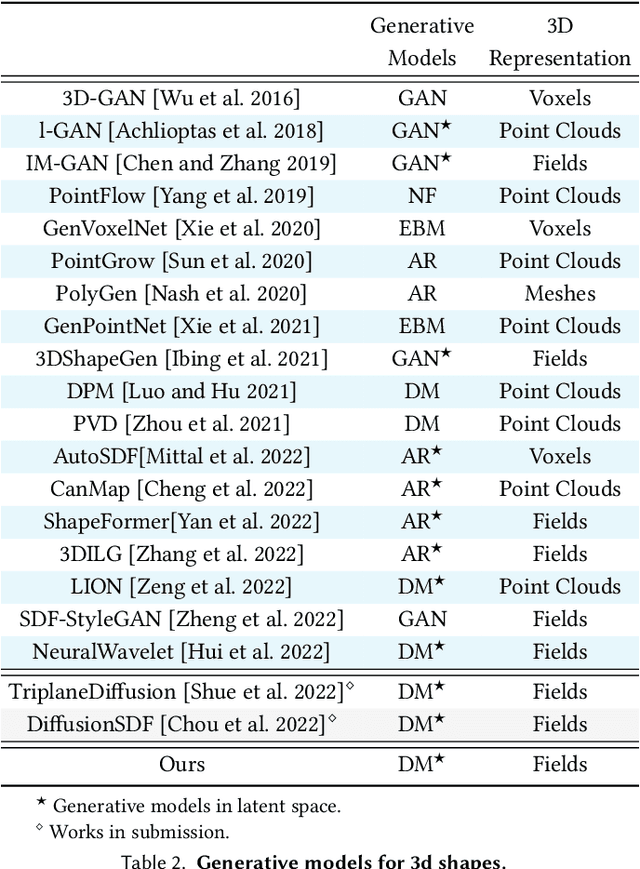
We introduce 3DShape2VecSet, a novel shape representation for neural fields designed for generative diffusion models. Our shape representation can encode 3D shapes given as surface models or point clouds, and represents them as neural fields. The concept of neural fields has previously been combined with a global latent vector, a regular grid of latent vectors, or an irregular grid of latent vectors. Our new representation encodes neural fields on top of a set of vectors. We draw from multiple concepts, such as the radial basis function representation and the cross attention and self-attention function, to design a learnable representation that is especially suitable for processing with transformers. Our results show improved performance in 3D shape encoding and 3D shape generative modeling tasks. We demonstrate a wide variety of generative applications: unconditioned generation, category-conditioned generation, text-conditioned generation, point-cloud completion, and image-conditioned generation.
Weight Prediction Boosts the Convergence of AdamW
Feb 01, 2023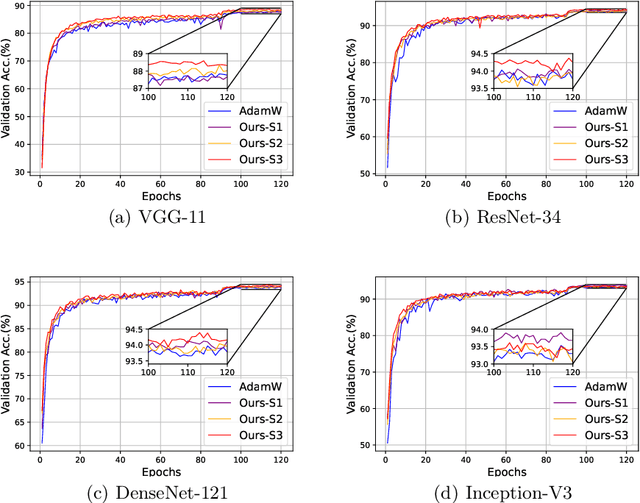
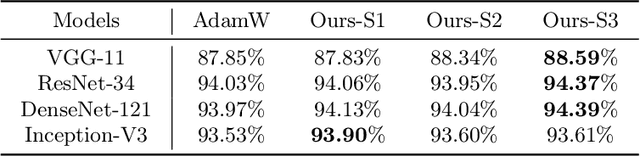
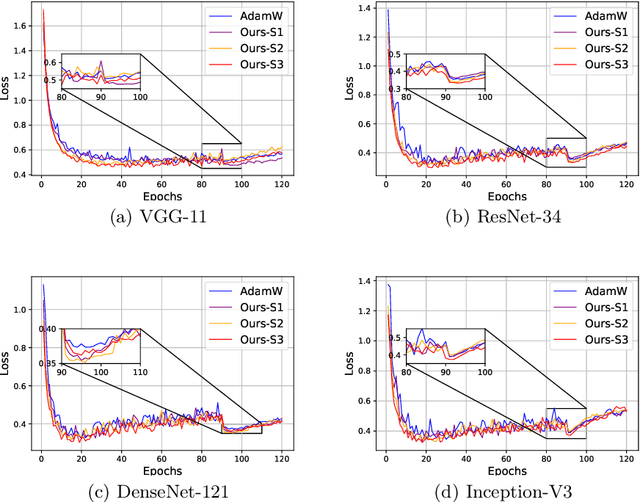
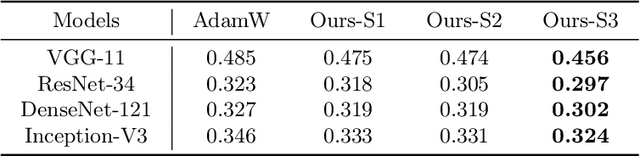
In this paper, we introduce weight prediction into the AdamW optimizer to boost its convergence when training the deep neural network (DNN) models. In particular, ahead of each mini-batch training, we predict the future weights according to the update rule of AdamW and then apply the predicted future weights to do both forward pass and backward propagation. In this way, the AdamW optimizer always utilizes the gradients w.r.t. the future weights instead of current weights to update the DNN parameters, making the AdamW optimizer achieve better convergence. Our proposal is simple and straightforward to implement but effective in boosting the convergence of DNN training. We performed extensive experimental evaluations on image classification and language modeling tasks to verify the effectiveness of our proposal. The experimental results validate that our proposal can boost the convergence of AdamW and achieve better accuracy than AdamW when training the DNN models.
Real Image Restoration via Structure-preserving Complementarity Attention
Jul 28, 2022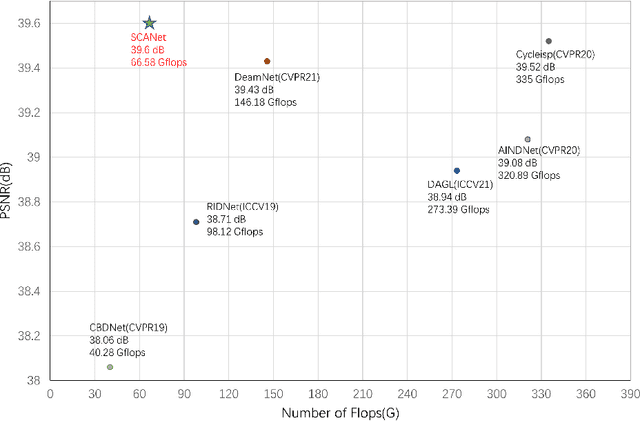
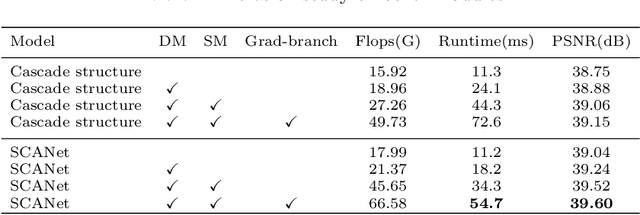
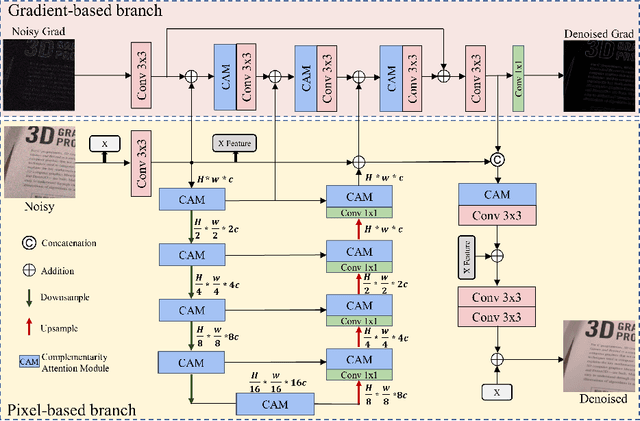

Since convolutional neural networks perform well in learning generalizable image priors from large-scale data, these models have been widely used in image denoising tasks. However, the computational complexity increases dramatically as well on complex model. In this paper, We propose a novel lightweight Complementary Attention Module, which includes a density module and a sparse module, which can cooperatively mine dense and sparse features for feature complementary learning to build an efficient lightweight architecture. Moreover, to reduce the loss of details caused by denoising, this paper constructs a gradient-based structure-preserving branch. We utilize gradient-based branches to obtain additional structural priors for denoising, and make the model pay more attention to image geometric details through gradient loss optimization.Based on the above, we propose an efficiently Unet structured network with dual branch, the visual results show that can effectively preserve the structural details of the original image, we evaluate benchmarks including SIDD and DND, where SCANet achieves state-of-the-art performance in PSNR and SSIM while significantly reducing computational cost.
MixSKD: Self-Knowledge Distillation from Mixup for Image Recognition
Aug 11, 2022
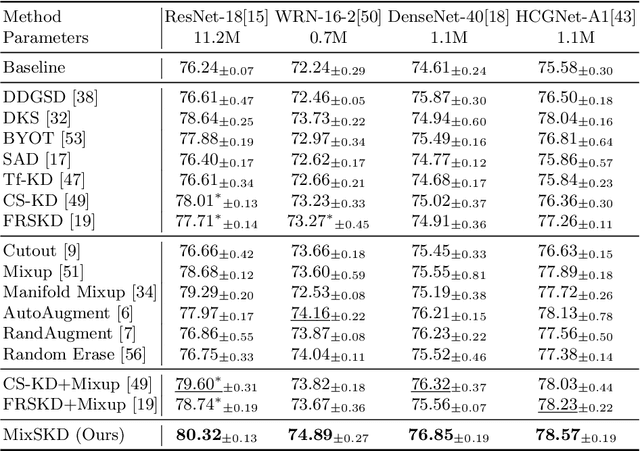
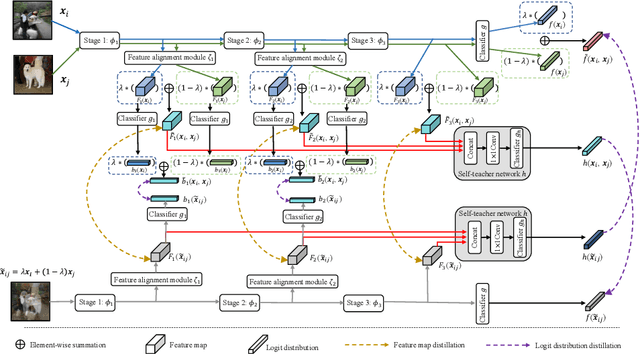
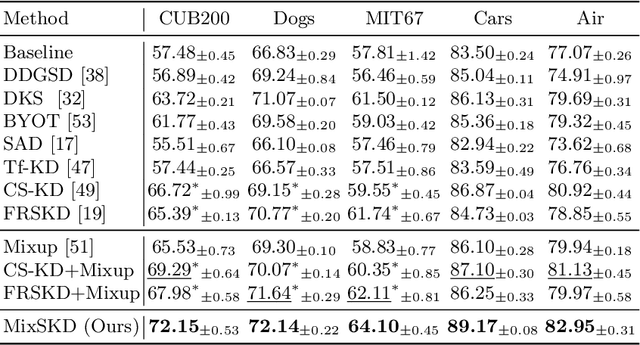
Unlike the conventional Knowledge Distillation (KD), Self-KD allows a network to learn knowledge from itself without any guidance from extra networks. This paper proposes to perform Self-KD from image Mixture (MixSKD), which integrates these two techniques into a unified framework. MixSKD mutually distills feature maps and probability distributions between the random pair of original images and their mixup images in a meaningful way. Therefore, it guides the network to learn cross-image knowledge by modelling supervisory signals from mixup images. Moreover, we construct a self-teacher network by aggregating multi-stage feature maps for providing soft labels to supervise the backbone classifier, further improving the efficacy of self-boosting. Experiments on image classification and transfer learning to object detection and semantic segmentation demonstrate that MixSKD outperforms other state-of-the-art Self-KD and data augmentation methods. The code is available at https://github.com/winycg/Self-KD-Lib.
Rethinking the Reference-based Distinctive Image Captioning
Jul 22, 2022
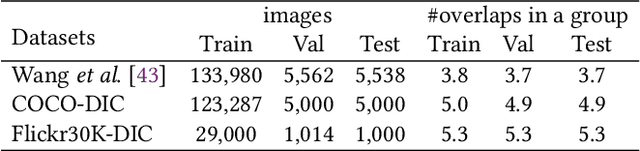
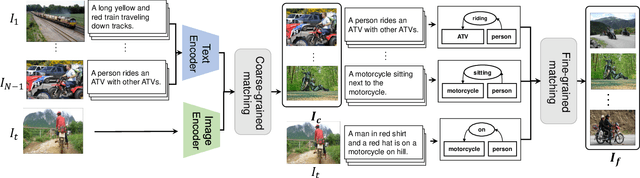
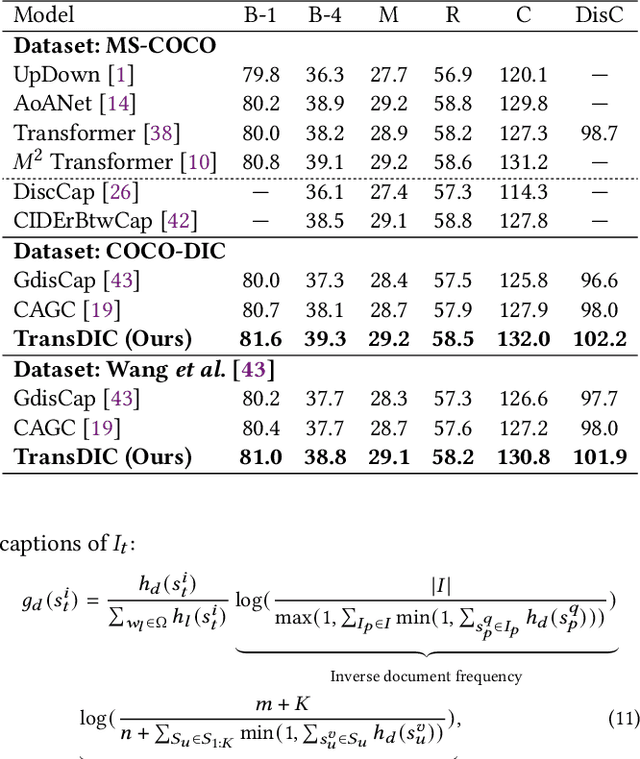
Distinctive Image Captioning (DIC) -- generating distinctive captions that describe the unique details of a target image -- has received considerable attention over the last few years. A recent DIC work proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i.e., reference-based DIC (Ref-DIC). It aims to make the generated captions can tell apart the target and reference images. Unfortunately, reference images used by existing Ref-DIC works are easy to distinguish: these reference images only resemble the target image at scene-level and have few common objects, such that a Ref-DIC model can trivially generate distinctive captions even without considering the reference images. To ensure Ref-DIC models really perceive the unique objects (or attributes) in target images, we first propose two new Ref-DIC benchmarks. Specifically, we design a two-stage matching mechanism, which strictly controls the similarity between the target and reference images at object-/attribute- level (vs. scene-level). Secondly, to generate distinctive captions, we develop a strong Transformer-based Ref-DIC baseline, dubbed as TransDIC. It not only extracts visual features from the target image, but also encodes the differences between objects in the target and reference images. Finally, for more trustworthy benchmarking, we propose a new evaluation metric named DisCIDEr for Ref-DIC, which evaluates both the accuracy and distinctiveness of the generated captions. Experimental results demonstrate that our TransDIC can generate distinctive captions. Besides, it outperforms several state-of-the-art models on the two new benchmarks over different metrics.
Differentiable Rendering for Pose Estimation in Proximity Operations
Dec 24, 2022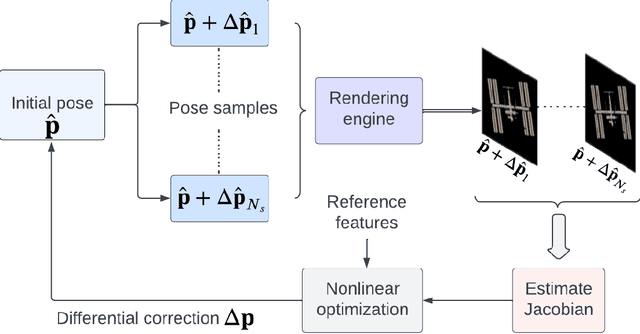
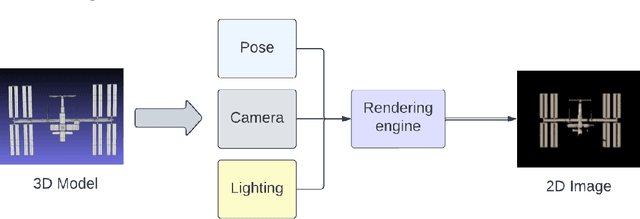
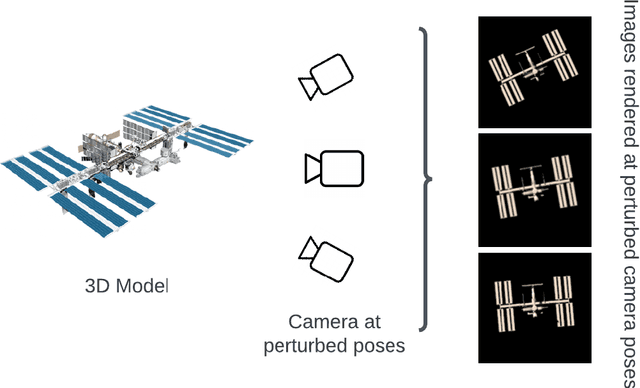
Differentiable rendering aims to compute the derivative of the image rendering function with respect to the rendering parameters. This paper presents a novel algorithm for 6-DoF pose estimation through gradient-based optimization using a differentiable rendering pipeline. We emphasize two key contributions: (1) instead of solving the conventional 2D to 3D correspondence problem and computing reprojection errors, images (rendered using the 3D model) are compared only in the 2D feature space via sparse 2D feature correspondences. (2) Instead of an analytical image formation model, we compute an approximate local gradient of the rendering process through online learning. The learning data consists of image features extracted from multi-viewpoint renders at small perturbations in the pose neighborhood. The gradients are propagated through the rendering pipeline for the 6-DoF pose estimation using nonlinear least squares. This gradient-based optimization regresses directly upon the pose parameters by aligning the 3D model to reproduce a reference image shape. Using representative experiments, we demonstrate the application of our approach to pose estimation in proximity operations.
An Image Processing approach to identify solar plages observed at 393.37 nm by Kodaikanal Solar Observatory
Oct 03, 2022



Solar Plages are bright chromospheric features observed in Ca II K photographic observations of the sun. These are regions of high magnetic field concentration thus tracer of magnetic activity of the Sun and are one of the most important features to study long term variability of the Sun as Ca II K spectroheliograms are recorded for more than a century. . However, detection of the plages from century-long databases is a non-trivial task and need significant human resources for doing it manually. Hence, in this study we propose an image processing algorithm which can identify solar plages from Ca II K photographic observations. The proposed study has been implemented on archival data from Kodaikanal Solar Observatory. To ensure that the algorithm works, irrespective of noise level, brightness and other image properties, we randomly draw a samples of images from data archive to test our algorithm.
IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Feb 12, 2023
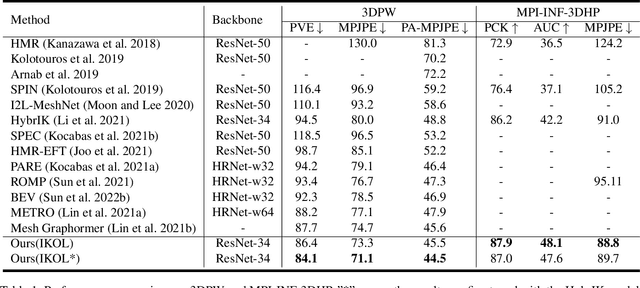
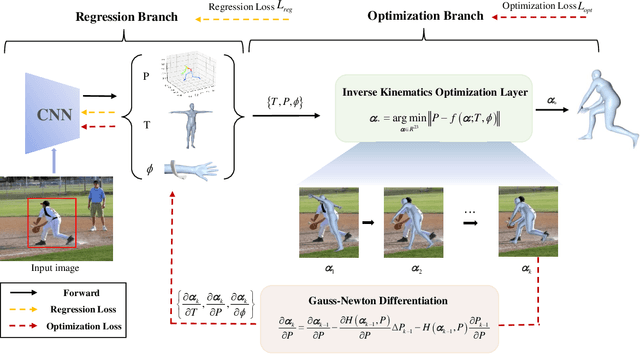
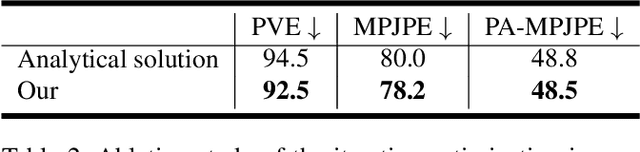
This paper presents an inverse kinematic optimization layer (IKOL) for 3D human pose and shape estimation that leverages the strength of both optimization- and regression-based methods within an end-to-end framework. IKOL involves a nonconvex optimization that establishes an implicit mapping from an image's 3D keypoints and body shapes to the relative body-part rotations. The 3D keypoints and the body shapes are the inputs and the relative body-part rotations are the solutions. However, this procedure is implicit and hard to make differentiable. So, to overcome this issue, we designed a Gauss-Newton differentiation (GN-Diff) procedure to differentiate IKOL. GN-Diff iteratively linearizes the nonconvex objective function to obtain Gauss-Newton directions with closed form solutions. Then, an automatic differentiation procedure is directly applied to generate a Jacobian matrix for end-to-end training. Notably, the GN-Diff procedure works fast because it does not rely on a time-consuming implicit differentiation procedure. The twist rotation and shape parameters are learned from the neural networks and, as a result, IKOL has a much lower computational overhead than most existing optimization-based methods. Additionally, compared to existing regression-based methods, IKOL provides a more accurate mesh-image correspondence. This is because it iteratively reduces the distance between the keypoints and also enhances the reliability of the pose structures. Extensive experiments demonstrate the superiority of our proposed framework over a wide range of 3D human pose and shape estimation methods.
SceneScape: Text-Driven Consistent Scene Generation
Feb 02, 2023
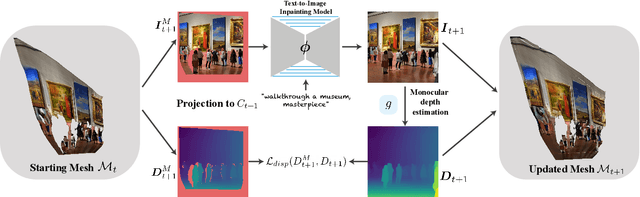
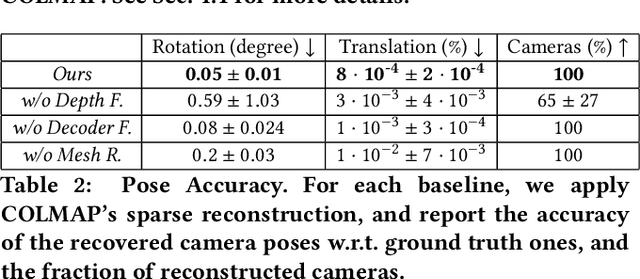

We propose a method for text-driven perpetual view generation -- synthesizing long videos of arbitrary scenes solely from an input text describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To achieve 3D consistency, i.e., generating videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene; the depth maps are used to construct a unified mesh representation of the scene, which is updated throughout the generation and is used for rendering. In contrast to previous works, which are applicable only for limited domains (e.g., landscapes), our framework generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles. Project page: https://scenescape.github.io/
Domain Generalization Emerges from Dreaming
Feb 02, 2023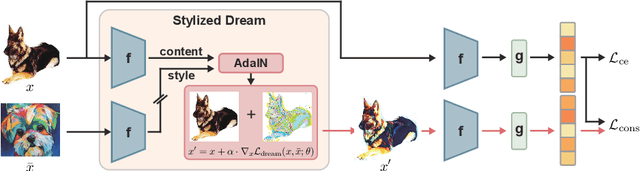
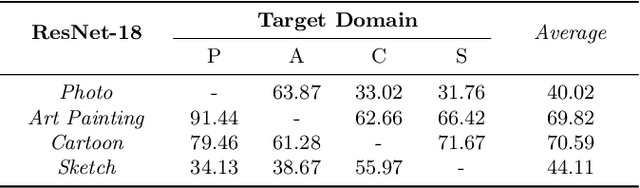

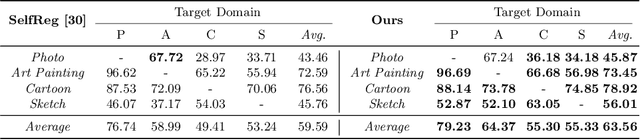
Recent studies have proven that DNNs, unlike human vision, tend to exploit texture information rather than shape. Such texture bias is one of the factors for the poor generalization performance of DNNs. We observe that the texture bias negatively affects not only in-domain generalization but also out-of-distribution generalization, i.e., Domain Generalization. Motivated by the observation, we propose a new framework to reduce the texture bias of a model by a novel optimization-based data augmentation, dubbed Stylized Dream. Our framework utilizes adaptive instance normalization (AdaIN) to augment the style of an original image yet preserve the content. We then adopt a regularization loss to predict consistent outputs between Stylized Dream and original images, which encourages the model to learn shape-based representations. Extensive experiments show that the proposed method achieves state-of-the-art performance in out-of-distribution settings on public benchmark datasets: PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet.