 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bridge Damage Cause Estimation Using Multiple Images Based on Visual Question Answering
Feb 18, 2023
In this paper, a bridge member damage cause estimation framework is proposed by calculating the image position using Structure from Motion (SfM) and acquiring its information via Visual Question Answering (VQA). For this, a VQA model was developed that uses bridge images for dataset creation and outputs the damage or member name and its existence based on the images and questions. In the developed model, the correct answer rate for questions requiring the member's name and the damage's name were 67.4% and 68.9%, respectively. The correct answer rate for questions requiring a yes/no answer was 99.1%. Based on the developed model, a damage cause estimation method was proposed. In the proposed method, the damage causes are narrowed down by inputting new questions to the VQA model, which are determined based on the surrounding images obtained via SfM and the results of the VQA model. Subsequently, the proposed method was then applied to an actual bridge and shown to be capable of determining damage and estimating its cause. The proposed method could be used to prevent damage causes from being overlooked, and practitioners could determine inspection focus areas, which could contribute to the improvement of maintenance techniques. In the future, it is expected to contribute to infrastructure diagnosis automation.
Exploring the Representation Manifolds of Stable Diffusion Through the Lens of Intrinsic Dimension
Feb 16, 2023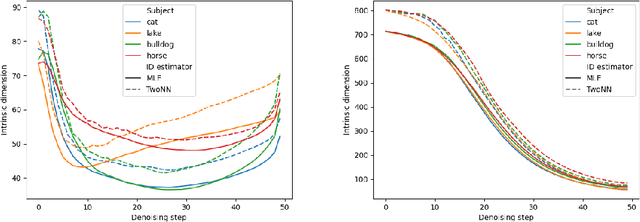
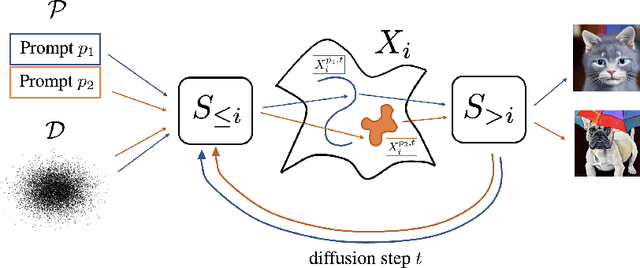
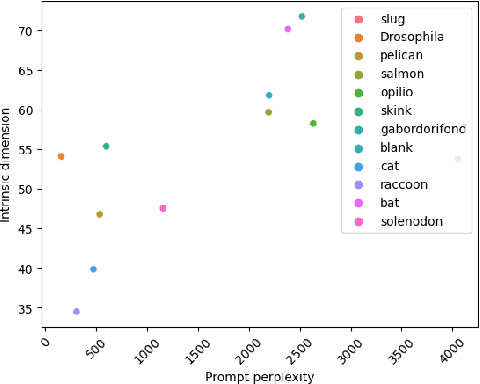
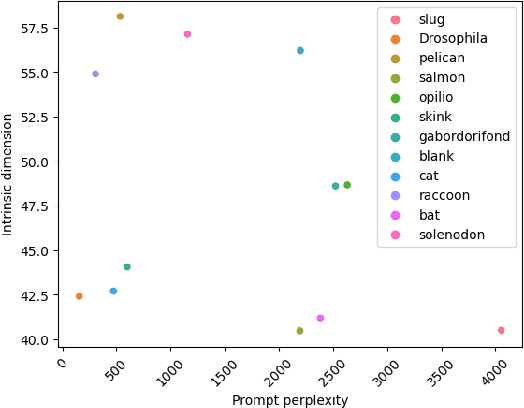
Prompting has become an important mechanism by which users can more effectively interact with many flavors of foundation model. Indeed, the last several years have shown that well-honed prompts can sometimes unlock emergent capabilities within such models. While there has been a substantial amount of empirical exploration of prompting within the community, relatively few works have studied prompting at a mathematical level. In this work we aim to take a first step towards understanding basic geometric properties induced by prompts in Stable Diffusion, focusing on the intrinsic dimension of internal representations within the model. We find that choice of prompt has a substantial impact on the intrinsic dimension of representations at both layers of the model which we explored, but that the nature of this impact depends on the layer being considered. For example, in certain bottleneck layers of the model, intrinsic dimension of representations is correlated with prompt perplexity (measured using a surrogate model), while this correlation is not apparent in the latent layers. Our evidence suggests that intrinsic dimension could be a useful tool for future studies of the impact of different prompts on text-to-image models.
Revisiting Hidden Representations in Transfer Learning for Medical Imaging
Feb 16, 2023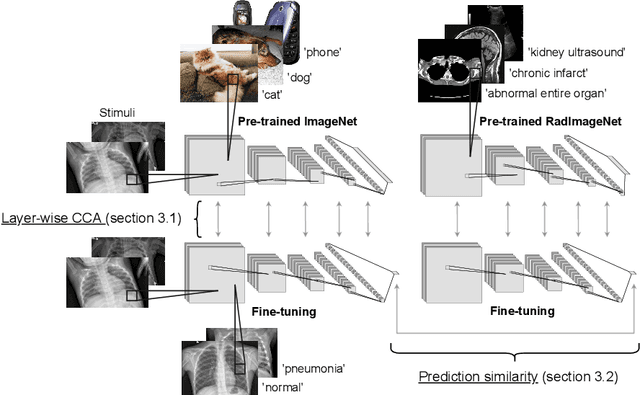
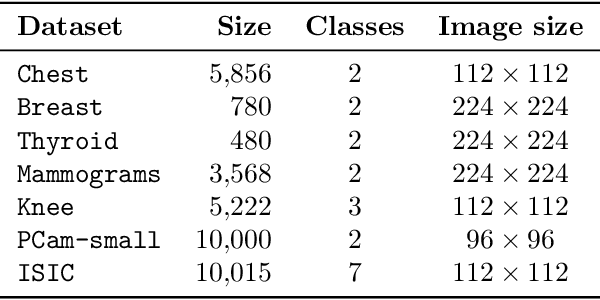

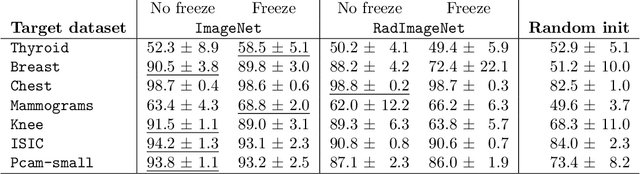
While a key component to the success of deep learning is the availability of massive amounts of training data, medical image datasets are often limited in diversity and size. Transfer learning has the potential to bridge the gap between related yet different domains. For medical applications, however, it remains unclear whether it is more beneficial to pre-train on natural or medical images. We aim to shed light on this problem by comparing initialization on ImageNet and RadImageNet on seven medical classification tasks. We investigate their learned representations with Canonical Correlation Analysis (CCA) and compare the predictions of the different models. We find that overall the models pre-trained on ImageNet outperform those trained on RadImageNet. Our results show that, contrary to intuition, ImageNet and RadImageNet converge to distinct intermediate representations, and that these representations are even more dissimilar after fine-tuning. Despite these distinct representations, the predictions of the models remain similar. Our findings challenge the notion that transfer learning is effective due to the reuse of general features in the early layers of a convolutional neural network and show that weight similarity before and after fine-tuning is negatively related to performance gains.
Vision-Based Terrain Relative Navigation on High-Altitude Balloon and Sub-Orbital Rocket
Feb 16, 2023
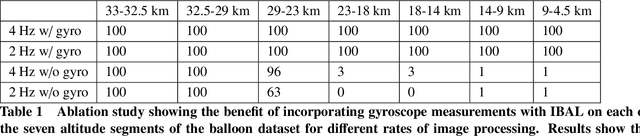


We present an experimental analysis on the use of a camera-based approach for high-altitude navigation by associating mapped landmarks from a satellite image database to camera images, and by leveraging inertial sensors between camera frames. We evaluate performance of both a sideways-tilted and downward-facing camera on data collected from a World View Enterprises high-altitude balloon with data beginning at an altitude of 33 km and descending to near ground level (4.5 km) with 1.5 hours of flight time. We demonstrate less than 290 meters of average position error over a trajectory of more than 150 kilometers. In addition to showing performance across a range of altitudes, we also demonstrate the robustness of the Terrain Relative Navigation (TRN) method to rapid rotations of the balloon, in some cases exceeding 20 degrees per second, and to camera obstructions caused by both cloud coverage and cords swaying underneath the balloon. Additionally, we evaluate performance on data collected by two cameras inside the capsule of Blue Origin's New Shepard rocket on payload flight NS-23, traveling at speeds up to 880 km/hr, and demonstrate less than 55 meters of average position error.
* Published in 2023 AIAA SciTech
Visible-Infrared Person Re-Identification via Patch-Mixed Cross-Modality Learning
Feb 16, 2023
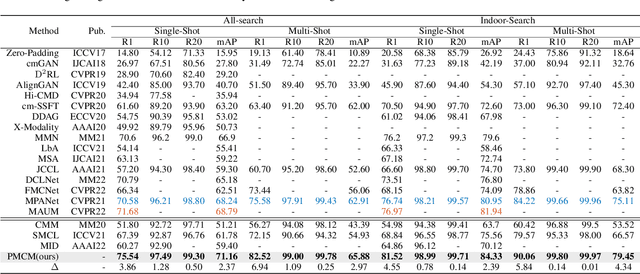
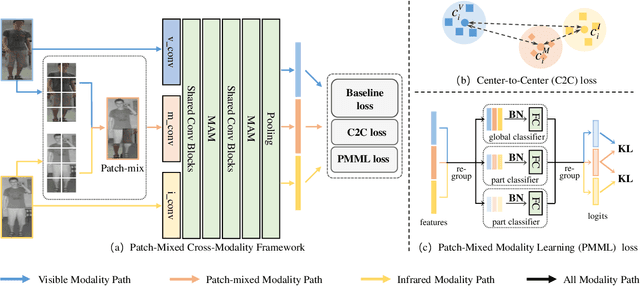
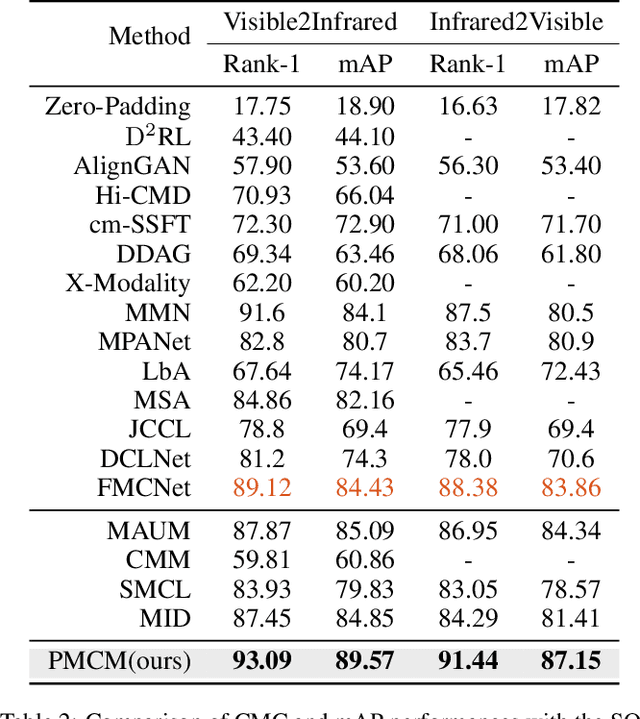
Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same pedestrian from different modalities, where the challenges lie in the significant modality discrepancy. To alleviate the modality gap, recent methods generate intermediate images by GANs, grayscaling, or mixup strategies. However, these methods could ntroduce extra noise, and the semantic correspondence between the two modalities is not well learned. In this paper, we propose a Patch-Mixed Cross-Modality framework (PMCM), where two images of the same person from two modalities are split into patches and stitched into a new one for model learning. In this way, the modellearns to recognize a person through patches of different styles, and the modality semantic correspondence is directly embodied. With the flexible image generation strategy, the patch-mixed images freely adjust the ratio of different modality patches, which could further alleviate the modality imbalance problem. In addition, the relationship between identity centers among modalities is explored to further reduce the modality variance, and the global-to-part constraint is introduced to regularize representation learning of part features. On two VI-ReID datasets, we report new state-of-the-art performance with the proposed method.
Detecting Clouds in Multispectral Satellite Images Using Quantum-Kernel Support Vector Machines
Feb 16, 2023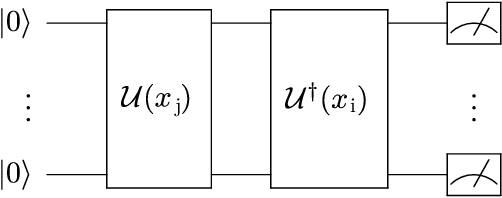

Support vector machines (SVMs) are a well-established classifier effectively deployed in an array of classification tasks. In this work, we consider extending classical SVMs with quantum kernels and applying them to satellite data analysis. The design and implementation of SVMs with quantum kernels (hybrid SVMs) are presented. Here, the pixels are mapped to the Hilbert space using a family of parameterized quantum feature maps (related to quantum kernels). The parameters are optimized to maximize the kernel target alignment. The quantum kernels have been selected such that they enabled analysis of numerous relevant properties while being able to simulate them with classical computers on a real-life large-scale dataset. Specifically, we approach the problem of cloud detection in the multispectral satellite imagery, which is one of the pivotal steps in both on-the-ground and on-board satellite image analysis processing chains. The experiments performed over the benchmark Landsat-8 multispectral dataset revealed that the simulated hybrid SVM successfully classifies satellite images with accuracy comparable to the classical SVM with the RBF kernel for large datasets. Interestingly, for large datasets, the high accuracy was also observed for the simple quantum kernels, lacking quantum entanglement.
Deep Learning for Medical Image Segmentation: Tricks, Challenges and Future Directions
Sep 21, 2022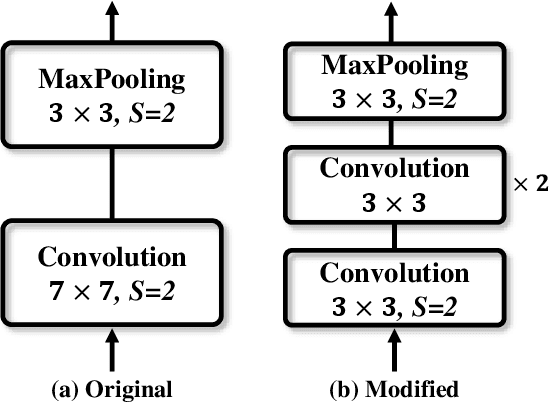
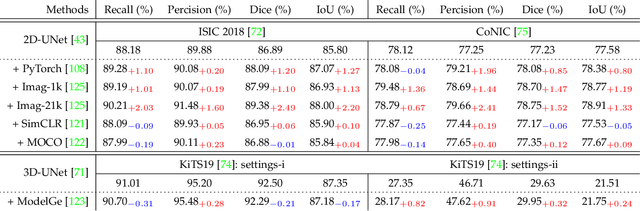
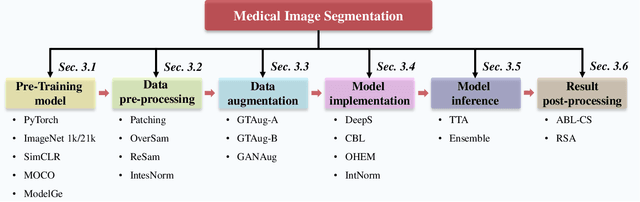
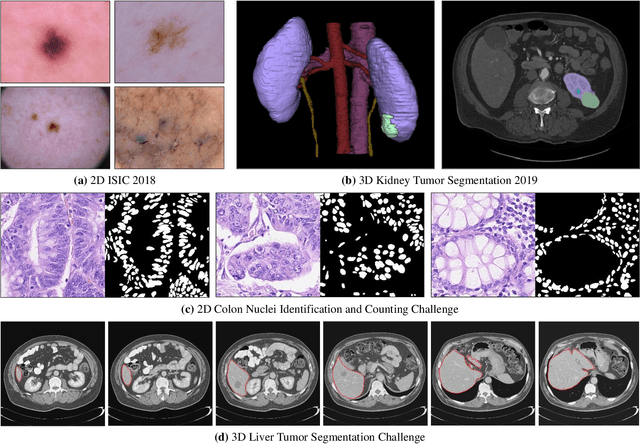
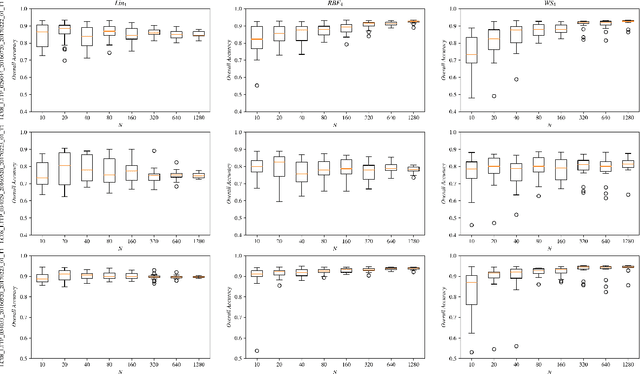
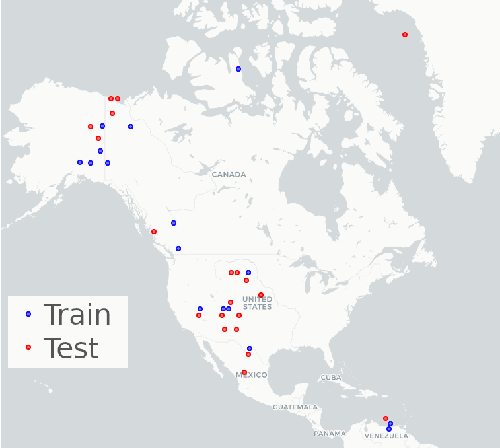
Over the past few years, the rapid development of deep learning technologies for computer vision has greatly promoted the performance of medical image segmentation (MedISeg). However, the recent MedISeg publications usually focus on presentations of the major contributions (e.g., network architectures, training strategies, and loss functions) while unwittingly ignoring some marginal implementation details (also known as "tricks"), leading to a potential problem of the unfair experimental result comparisons. In this paper, we collect a series of MedISeg tricks for different model implementation phases (i.e., pre-training model, data pre-processing, data augmentation, model implementation, model inference, and result post-processing), and experimentally explore the effectiveness of these tricks on the consistent baseline models. Compared to paper-driven surveys that only blandly focus on the advantages and limitation analyses of segmentation models, our work provides a large number of solid experiments and is more technically operable. With the extensive experimental results on both the representative 2D and 3D medical image datasets, we explicitly clarify the effect of these tricks. Moreover, based on the surveyed tricks, we also open-sourced a strong MedISeg repository, where each of its components has the advantage of plug-and-play. We believe that this milestone work not only completes a comprehensive and complementary survey of the state-of-the-art MedISeg approaches, but also offers a practical guide for addressing the future medical image processing challenges including but not limited to small dataset learning, class imbalance learning, multi-modality learning, and domain adaptation. The code has been released at: https://github.com/hust-linyi/MedISeg
MILAN: Masked Image Pretraining on Language Assisted Representation
Aug 15, 2022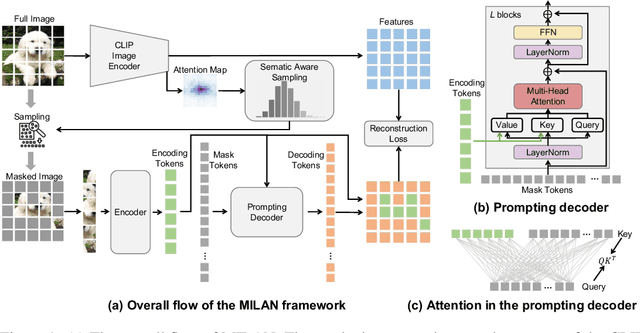
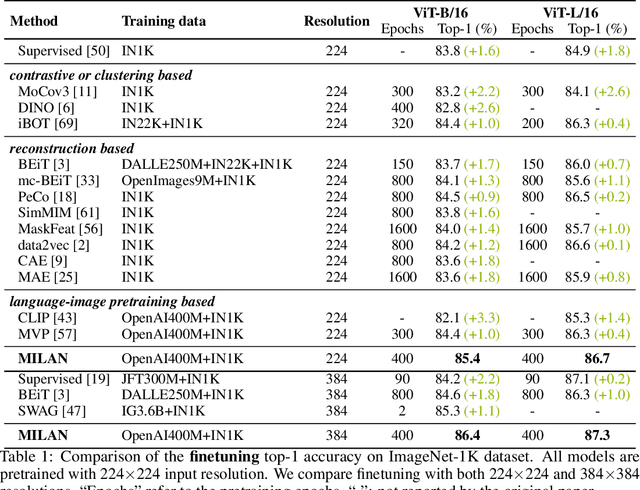

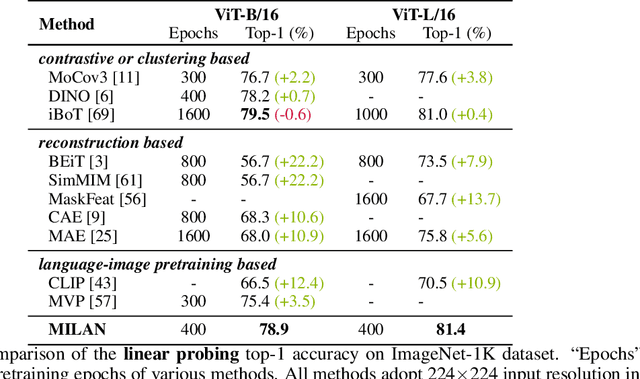
Self-attention based transformer models have been dominating many computer vision tasks in the past few years. Their superb model qualities heavily depend on the excessively large labeled image datasets. In order to reduce the reliance on large labeled datasets, reconstruction based masked autoencoders are gaining popularity, which learn high quality transferable representations from unlabeled images. For the same purpose, recent weakly supervised image pretraining methods explore language supervision from text captions accompanying the images. In this work, we propose masked image pretraining on language assisted representation, dubbed as MILAN. Instead of predicting raw pixels or low level features, our pretraining objective is to reconstruct the image features with substantial semantic signals that are obtained using caption supervision. Moreover, to accommodate our reconstruction target, we propose a more efficient prompting decoder architecture and a semantic aware mask sampling mechanism, which further advance the transfer performance of the pretrained model. Experimental results demonstrate that MILAN delivers higher accuracy than the previous works. When the masked autoencoder is pretrained and finetuned on ImageNet-1K dataset with an input resolution of 224x224, MILAN achieves a top-1 accuracy of 85.4% on ViTB/16, surpassing previous state-of-the-arts by 1%. In the downstream semantic segmentation task, MILAN achieves 52.7 mIoU using ViT-B/16 backbone on ADE20K dataset, outperforming previous masked pretraining results by 4 points.
A framework for benchmarking class-out-of-distribution detection and its application to ImageNet
Feb 23, 2023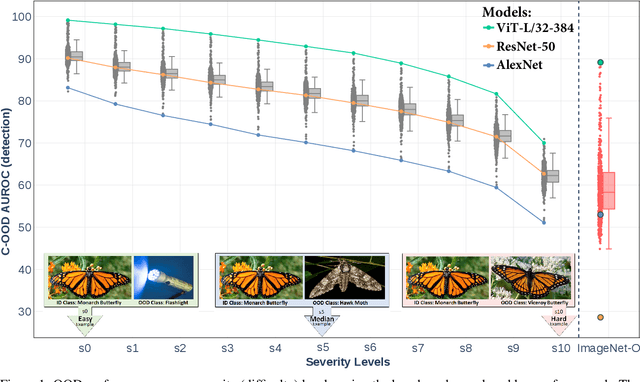



When deployed for risk-sensitive tasks, deep neural networks must be able to detect instances with labels from outside the distribution for which they were trained. In this paper we present a novel framework to benchmark the ability of image classifiers to detect class-out-of-distribution instances (i.e., instances whose true labels do not appear in the training distribution) at various levels of detection difficulty. We apply this technique to ImageNet, and benchmark 525 pretrained, publicly available, ImageNet-1k classifiers. The code for generating a benchmark for any ImageNet-1k classifier, along with the benchmarks prepared for the above-mentioned 525 models is available at https://github.com/mdabbah/COOD_benchmarking. The usefulness of the proposed framework and its advantage over alternative existing benchmarks is demonstrated by analyzing the results obtained for these models, which reveals numerous novel observations including: (1) knowledge distillation consistently improves class-out-of-distribution (C-OOD) detection performance; (2) a subset of ViTs performs better C-OOD detection than any other model; (3) the language--vision CLIP model achieves good zero-shot detection performance, with its best instance outperforming 96% of all other models evaluated; (4) accuracy and in-distribution ranking are positively correlated to C-OOD detection; and (5) we compare various confidence functions for C-OOD detection. Our companion paper, also published in ICLR 2023 (What Can We Learn From The Selective Prediction And Uncertainty Estimation Performance Of 523 Imagenet Classifiers), examines the uncertainty estimation performance (ranking, calibration, and selective prediction performance) of these classifiers in an in-distribution setting.
* Published in ICLR 2023. arXiv admin note: text overlap with arXiv:2206.02152
Learning to Collocate Visual-Linguistic Neural Modules for Image Captioning
Oct 04, 2022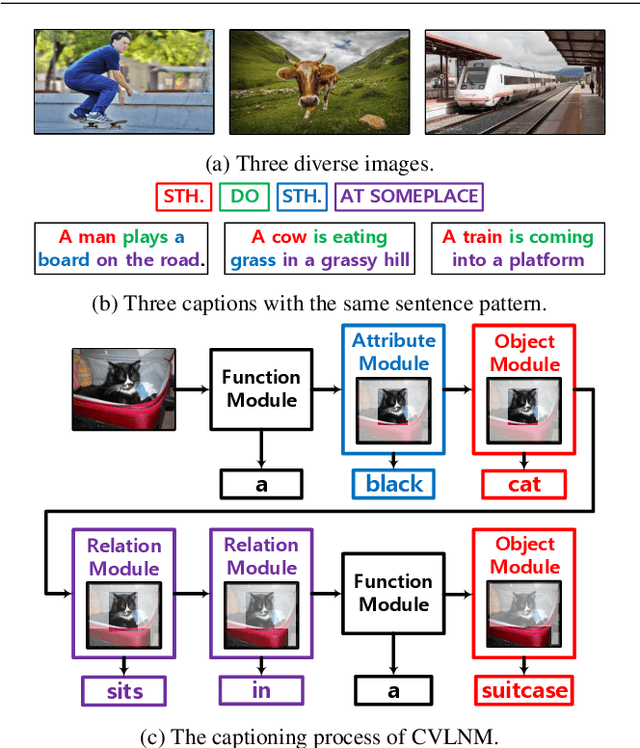


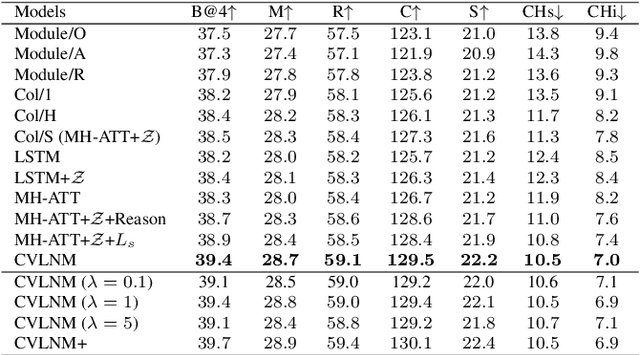
Humans tend to decompose a sentence into different parts like \textsc{sth do sth at someplace} and then fill each part with certain content. Inspired by this, we follow the \textit{principle of modular design} to propose a novel image captioner: learning to Collocate Visual-Linguistic Neural Modules (CVLNM). Unlike the \re{widely used} neural module networks in VQA, where the language (\ie, question) is fully observable, \re{the task of collocating visual-linguistic modules is more challenging.} This is because the language is only partially observable, for which we need to dynamically collocate the modules during the process of image captioning. To sum up, we make the following technical contributions to design and train our CVLNM: 1) \textit{distinguishable module design} -- \re{four modules in the encoder} including one linguistic module for function words and three visual modules for different content words (\ie, noun, adjective, and verb) and another linguistic one in the decoder for commonsense reasoning, 2) a self-attention based \textit{module controller} for robustifying the visual reasoning, 3) a part-of-speech based \textit{syntax loss} imposed on the module controller for further regularizing the training of our CVLNM. Extensive experiments on the MS-COCO dataset show that our CVLNM is more effective, \eg, achieving a new state-of-the-art 129.5 CIDEr-D, and more robust, \eg, being less likely to overfit to dataset bias and suffering less when fewer training samples are available. Codes are available at \url{https://github.com/GCYZSL/CVLMN}