 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
POSTER V2: A simpler and stronger facial expression recognition network
Jan 28, 2023
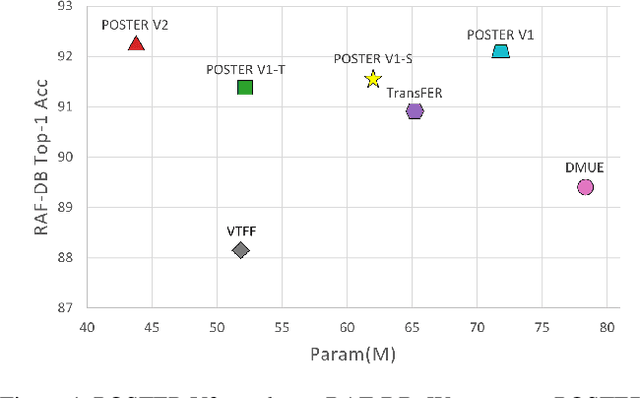

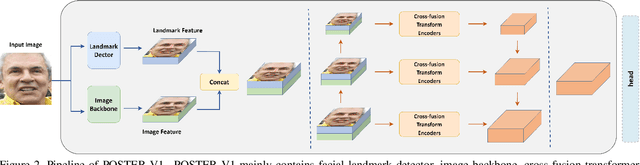
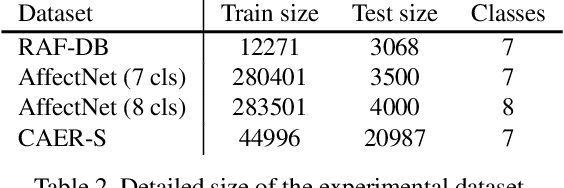
Facial expression recognition (FER) plays an important role in a variety of real-world applications such as human-computer interaction. POSTER V1 achieves the state-of-the-art (SOTA) performance in FER by effectively combining facial landmark and image features through two-stream pyramid cross-fusion design. However, the architecture of POSTER V1 is undoubtedly complex. It causes expensive computational costs. In order to relieve the computational pressure of POSTER V1, in this paper, we propose POSTER V2. It improves POSTER V1 in three directions: cross-fusion, two-stream, and multi-scale feature extraction. In cross-fusion, we use window-based cross-attention mechanism replacing vanilla cross-attention mechanism. We remove the image-to-landmark branch in the two-stream design. For multi-scale feature extraction, POSTER V2 combines images with landmark's multi-scale features to replace POSTER V1's pyramid design. Extensive experiments on several standard datasets show that our POSTER V2 achieves the SOTA FER performance with the minimum computational cost. For example, POSTER V2 reached 92.21\% on RAF-DB, 67.49\% on AffectNet (7 cls) and 63.77\% on AffectNet (8 cls), respectively, using only 8.4G floating point operations (FLOPs) and 43.7M parameters (Param). This demonstrates the effectiveness of our improvements. The code and models are available at ~\url{https://github.com/Talented-Q/POSTER_V2}.
MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining
Aug 25, 2022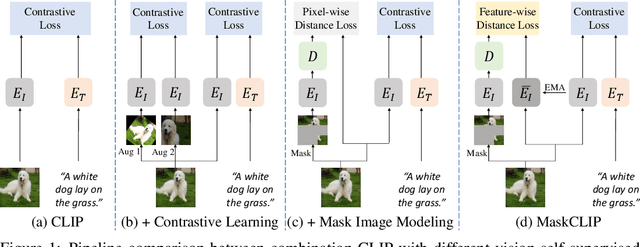
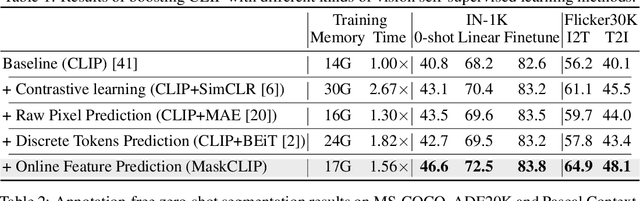
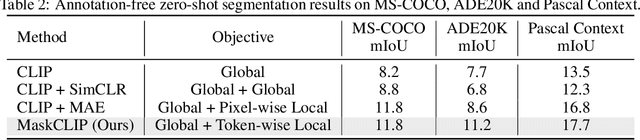
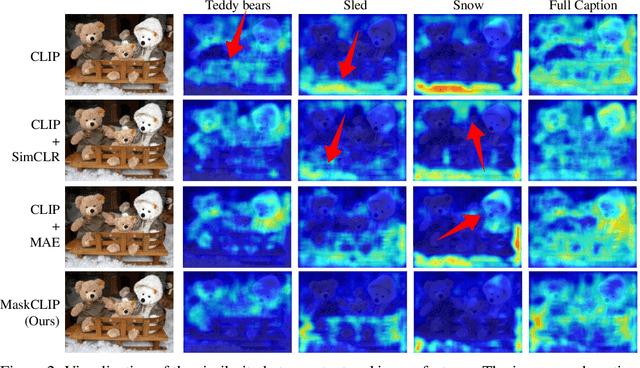
This paper presents a simple yet effective framework MaskCLIP, which incorporates a newly proposed masked self-distillation into contrastive language-image pretraining. The core idea of masked self-distillation is to distill representation from a full image to the representation predicted from a masked image. Such incorporation enjoys two vital benefits. First, masked self-distillation targets local patch representation learning, which is complementary to vision-language contrastive focusing on text-related representation.Second, masked self-distillation is also consistent with vision-language contrastive from the perspective of training objective as both utilize the visual encoder for feature aligning, and thus is able to learn local semantics getting indirect supervision from the language. We provide specially designed experiments with a comprehensive analysis to validate the two benefits. Empirically, we show that MaskCLIP, when applied to various challenging downstream tasks, achieves superior results in linear probing, finetuning as well as the zero-shot performance with the guidance of the language encoder.
3D Human Pose Lifting with Grid Convolution
Feb 17, 2023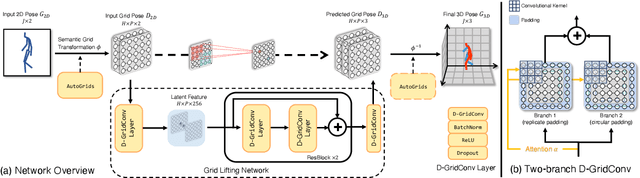
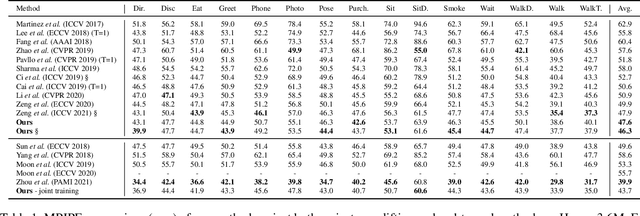
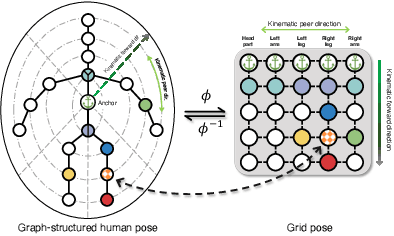
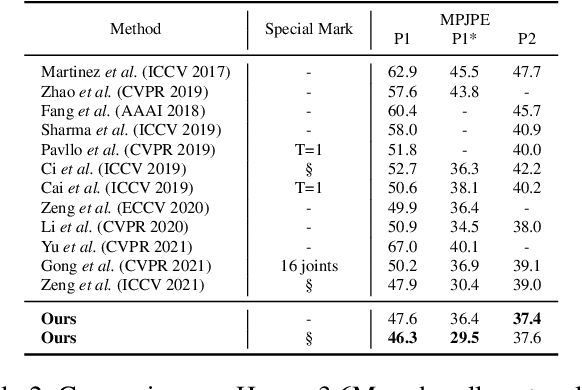
Existing lifting networks for regressing 3D human poses from 2D single-view poses are typically constructed with linear layers based on graph-structured representation learning. In sharp contrast to them, this paper presents Grid Convolution (GridConv), mimicking the wisdom of regular convolution operations in image space. GridConv is based on a novel Semantic Grid Transformation (SGT) which leverages a binary assignment matrix to map the irregular graph-structured human pose onto a regular weave-like grid pose representation joint by joint, enabling layer-wise feature learning with GridConv operations. We provide two ways to implement SGT, including handcrafted and learnable designs. Surprisingly, both designs turn out to achieve promising results and the learnable one is better, demonstrating the great potential of this new lifting representation learning formulation. To improve the ability of GridConv to encode contextual cues, we introduce an attention module over the convolutional kernel, making grid convolution operations input-dependent, spatial-aware and grid-specific. We show that our fully convolutional grid lifting network outperforms state-of-the-art methods with noticeable margins under (1) conventional evaluation on Human3.6M and (2) cross-evaluation on MPI-INF-3DHP. Code is available at https://github.com/OSVAI/GridConv
A deep convolutional neural network for salt-and-pepper noise removal using selective convolutional blocks
Feb 10, 2023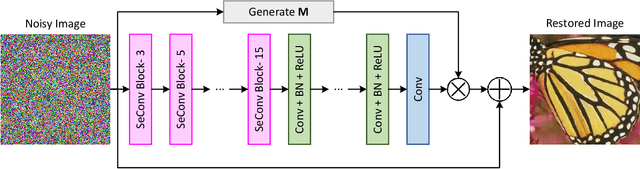
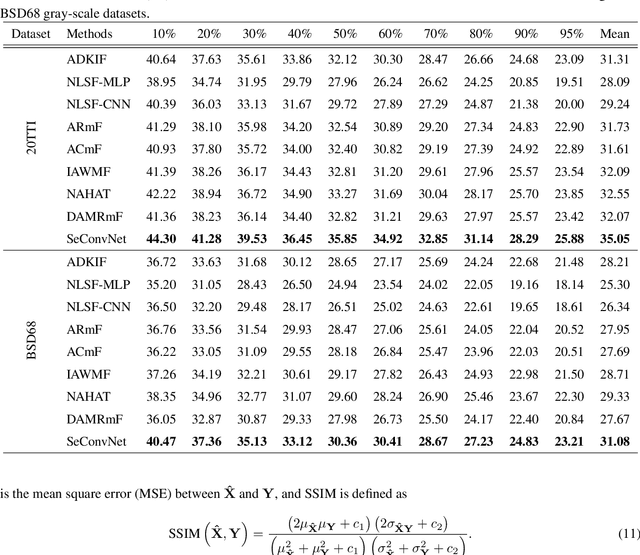

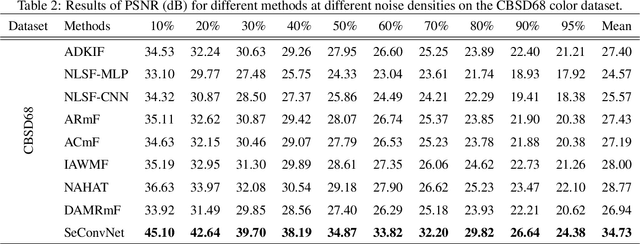
In recent years, there has been an unprecedented upsurge in applying deep learning approaches, specifically convolutional neural networks (CNNs), to solve image denoising problems, owing to their superior performance. However, CNNs mostly rely on Gaussian noise, and there is a conspicuous lack of exploiting CNNs for salt-and-pepper (SAP) noise reduction. In this paper, we proposed a deep CNN model, namely SeConvNet, to suppress SAP noise in gray-scale and color images. To meet this objective, we introduce a new selective convolutional (SeConv) block. SeConvNet is compared to state-of-the-art SAP denoising methods using extensive experiments on various common datasets. The results illustrate that the proposed SeConvNet model effectively restores images corrupted by SAP noise and surpasses all its counterparts at both quantitative criteria and visual effects, especially at high and very high noise densities.
LAPTNet-FPN: Multi-scale LiDAR-aided Projective Transform Network for Real Time Semantic Grid Prediction
Feb 10, 2023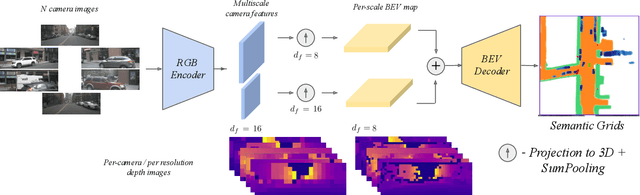

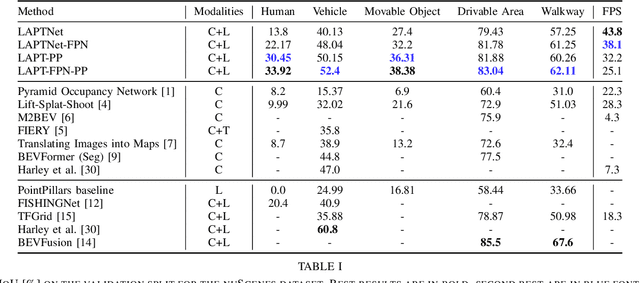
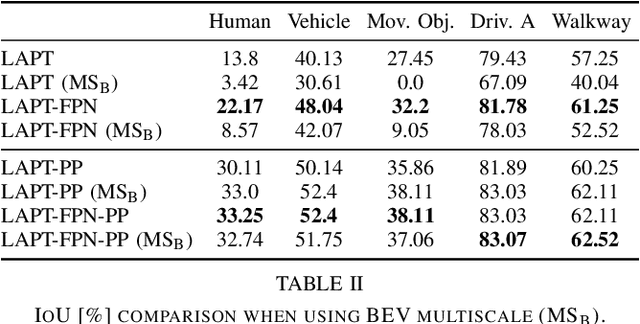
Semantic grids can be useful representations of the scene around an autonomous system. By having information about the layout of the space around itself, a robot can leverage this type of representation for crucial tasks such as navigation or tracking. By fusing information from multiple sensors, robustness can be increased and the computational load for the task can be lowered, achieving real time performance. Our multi-scale LiDAR-Aided Perspective Transform network uses information available in point clouds to guide the projection of image features to a top-view representation, resulting in a relative improvement in the state of the art for semantic grid generation for human (+8.67%) and movable object (+49.07%) classes in the nuScenes dataset, as well as achieving results close to the state of the art for the vehicle, drivable area and walkway classes, while performing inference at 25 FPS.
Image Based Food Energy Estimation With Depth Domain Adaptation
Aug 25, 2022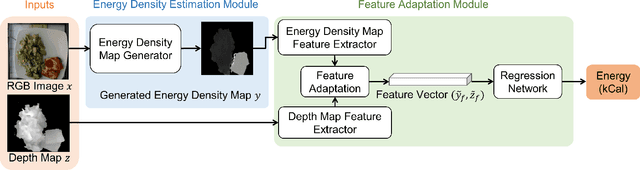

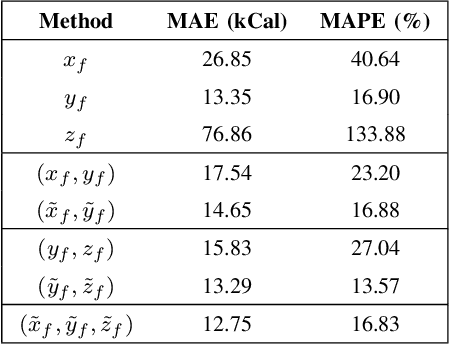
Assessment of dietary intake has primarily relied on self-report instruments, which are prone to measurement errors. Dietary assessment methods have increasingly incorporated technological advances particularly mobile, image based approaches to address some of these limitations and further automation. Mobile, image-based methods can reduce user burden and bias by automatically estimating dietary intake from eating occasion images that are captured by mobile devices. In this paper, we propose an "Energy Density Map" which is a pixel-to-pixel mapping from the RGB image to the energy density of the food. We then incorporate the "Energy Density Map" with an associated depth map that is captured by a depth sensor to estimate the food energy. The proposed method is evaluated on the Nutrition5k dataset. Experimental results show improved results compared to baseline methods with an average error of 13.29 kCal and an average percentage error of 13.57% between the ground-truth and the estimated energy of the food.
OccluMix: Towards De-Occlusion Virtual Try-on by Semantically-Guided Mixup
Jan 03, 2023

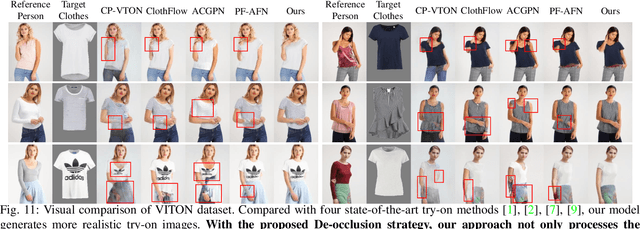

Image Virtual try-on aims at replacing the cloth on a personal image with a garment image (in-shop clothes), which has attracted increasing attention from the multimedia and computer vision communities. Prior methods successfully preserve the character of clothing images, however, occlusion remains a pernicious effect for realistic virtual try-on. In this work, we first present a comprehensive analysis of the occlusions and categorize them into two aspects: i) Inherent-Occlusion: the ghost of the former cloth still exists in the try-on image; ii) Acquired-Occlusion: the target cloth warps to the unreasonable body part. Based on the in-depth analysis, we find that the occlusions can be simulated by a novel semantically-guided mixup module, which can generate semantic-specific occluded images that work together with the try-on images to facilitate training a de-occlusion try-on (DOC-VTON) framework. Specifically, DOC-VTON first conducts a sharpened semantic parsing on the try-on person. Aided by semantics guidance and pose prior, various complexities of texture are selectively blending with human parts in a copy-and-paste manner. Then, the Generative Module (GM) is utilized to take charge of synthesizing the final try-on image and learning to de-occlusion jointly. In comparison to the state-of-the-art methods, DOC-VTON achieves better perceptual quality by reducing occlusion effects.
An Energy-Efficient Reconfigurable Autoencoder Implementation on FPGA
Jan 17, 2023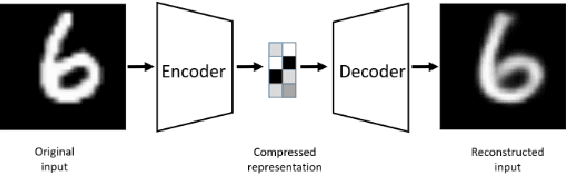


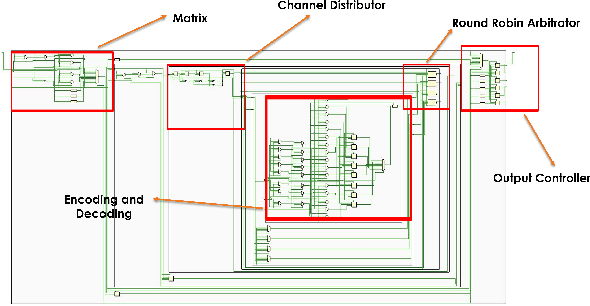
Autoencoders are unsupervised neural networks that are used to process and compress input data and then reconstruct the data back to the original data size. This allows autoencoders to be used for different processing applications such as data compression, image classification, image noise reduction, and image coloring. Hardware-wise, re-configurable architectures like Field Programmable Gate Arrays (FPGAs) have been used for accelerating computations from several domains because of their unique combination of flexibility, performance, and power efficiency. In this paper, we look at the different autoencoders available and use the convolutional autoencoder in both FPGA and GPU-based implementations to process noisy static MNIST images. We compare the different results achieved with the FPGA and GPU-based implementations and then discuss the pros and cons of each implementation. The evaluation of the proposed design achieved 80%accuracy and our experimental results show that the proposed accelerator achieves a throughput of 21.12 Giga-Operations Per Second (GOP/s) with a 5.93 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency and design flexibility. We also discuss future work that can be done with the use of our proposed accelerator.
Deep Uncalibrated Photometric Stereo via Inter-Intra Image Feature Fusion
Aug 06, 2022
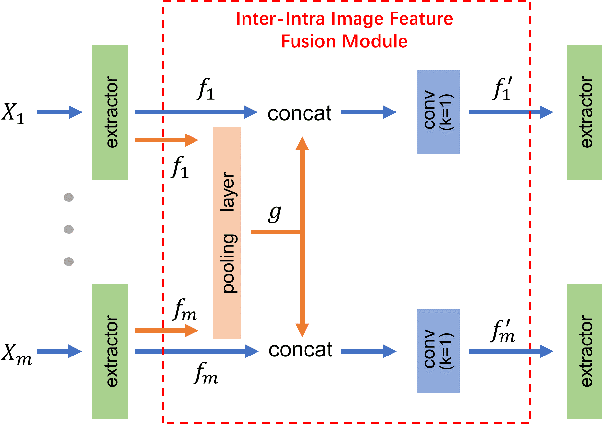
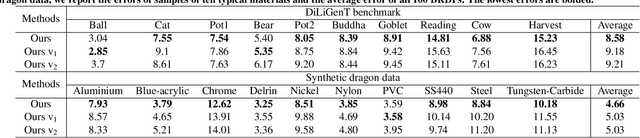
Uncalibrated photometric stereo is proposed to estimate the detailed surface normal from images under varying and unknown lightings. Recently, deep learning brings powerful data priors to this underdetermined problem. This paper presents a new method for deep uncalibrated photometric stereo, which efficiently utilizes the inter-image representation to guide the normal estimation. Previous methods use optimization-based neural inverse rendering or a single size-independent pooling layer to deal with multiple inputs, which are inefficient for utilizing information among input images. Given multi-images under different lighting, we consider the intra-image and inter-image variations highly correlated. Motivated by the correlated variations, we designed an inter-intra image feature fusion module to introduce the inter-image representation into the per-image feature extraction. The extra representation is used to guide the per-image feature extraction and eliminate the ambiguity in normal estimation. We demonstrate the effect of our design on a wide range of samples, especially on dark materials. Our method produces significantly better results than the state-of-the-art methods on both synthetic and real data.
Explaining Deep Convolutional Neural Networks for Image Classification by Evolving Local Interpretable Model-agnostic Explanations
Nov 28, 2022



Deep convolutional neural networks have proven their effectiveness, and have been acknowledged as the most dominant method for image classification. However, a severe drawback of deep convolutional neural networks is poor explainability. Unfortunately, in many real-world applications, users need to understand the rationale behind the predictions of deep convolutional neural networks when determining whether they should trust the predictions or not. To resolve this issue, a novel genetic algorithm-based method is proposed for the first time to automatically evolve local explanations that can assist users to assess the rationality of the predictions. Furthermore, the proposed method is model-agnostic, i.e., it can be utilised to explain any deep convolutional neural network models. In the experiments, ResNet is used as an example model to be explained, and the ImageNet dataset is selected as the benchmark dataset. DenseNet and MobileNet are further explained to demonstrate the model-agnostic characteristic of the proposed method. The evolved local explanations on four images, randomly selected from ImageNet, are presented, which show that the evolved local explanations are straightforward to be recognised by humans. Moreover, the evolved explanations can explain the predictions of deep convolutional neural networks on all four images very well by successfully capturing meaningful interpretable features of the sample images. Further analysis based on the 30 runs of the experiments exhibits that the evolved local explanations can also improve the probabilities/confidences of the deep convolutional neural network models in making the predictions. The proposed method can obtain local explanations within one minute, which is more than ten times faster than LIME (the state-of-the-art method).