 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Crossing Points Detection in Plain Weave for Old Paintings with Deep Learning
Feb 23, 2023



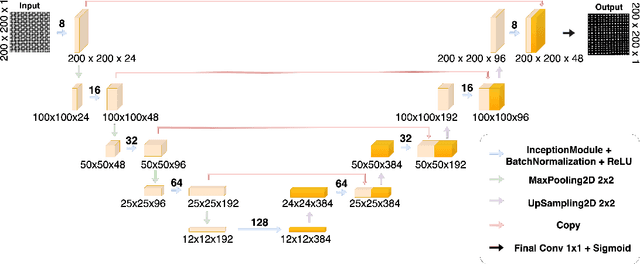
In the forensic studies of painting masterpieces, the analysis of the support is of major importance. For plain weave fabrics, the densities of vertical and horizontal threads are used as main features, while angle deviations from the vertical and horizontal axis are also of help. These features can be studied locally through the canvas. In this work, deep learning is proposed as a tool to perform these local densities and angle studies. We trained the model with samples from 36 paintings by Vel\'azquez, Rubens or Ribera, among others. The data preparation and augmentation are dealt with at a first stage of the pipeline. We then focus on the supervised segmentation of crossing points between threads. The U-Net with inception and Dice loss are presented as good choices for this task. Densities and angles are then estimated based on the segmented crossing points. We report test results of the analysis of a few canvases and a comparison with methods in the frequency domain, widely used in this problem. We concluded that this new approach succeeds in some cases where the frequency analysis tools fail, while improving the results in others. Besides, our proposal does not need the labeling of part of the to-be-processed image. As case studies, we apply this novel algorithm to the analysis of two pairs of canvases by Vel\'azquez and Murillo, to conclude that the fabrics used came from the same roll.
Hypercomplex Image-to-Image Translation
May 04, 2022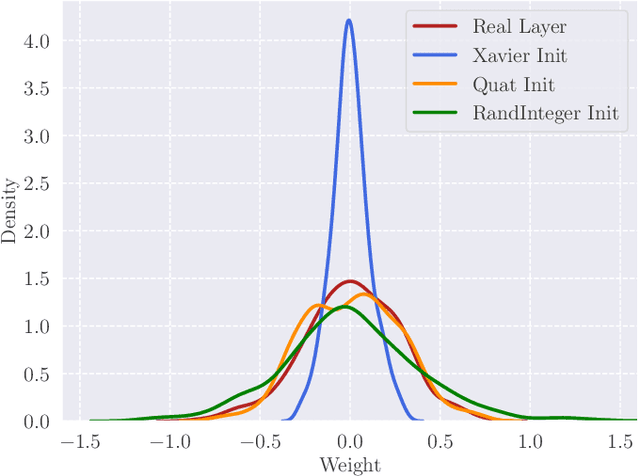
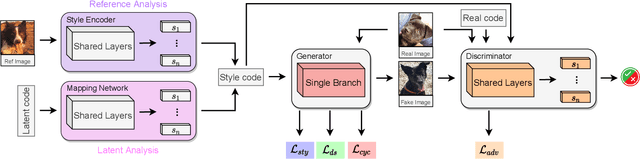


Image-to-image translation (I2I) aims at transferring the content representation from an input domain to an output one, bouncing along different target domains. Recent I2I generative models, which gain outstanding results in this task, comprise a set of diverse deep networks each with tens of million parameters. Moreover, images are usually three-dimensional being composed of RGB channels and common neural models do not take dimensions correlation into account, losing beneficial information. In this paper, we propose to leverage hypercomplex algebra properties to define lightweight I2I generative models capable of preserving pre-existing relations among image dimensions, thus exploiting additional input information. On manifold I2I benchmarks, we show how the proposed Quaternion StarGANv2 and parameterized hypercomplex StarGANv2 (PHStarGANv2) reduce parameters and storage memory amount while ensuring high domain translation performance and good image quality as measured by FID and LPIPS scores. Full code is available at: https://github.com/ispamm/HI2I.
Pix2Map: Cross-modal Retrieval for Inferring Street Maps from Images
Jan 10, 2023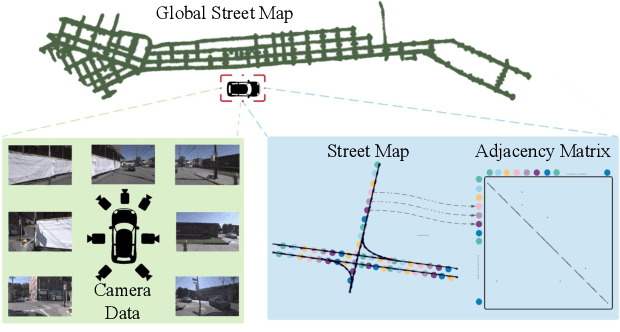
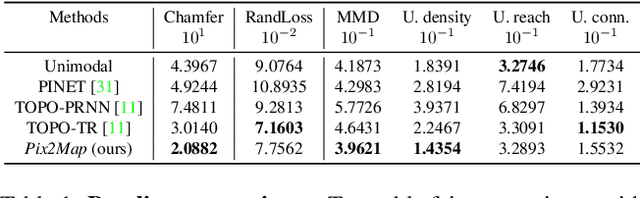
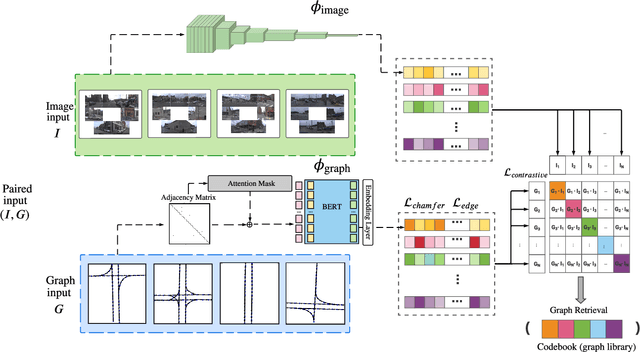
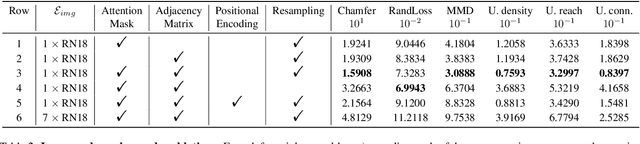
Self-driving vehicles rely on urban street maps for autonomous navigation. In this paper, we introduce Pix2Map, a method for inferring urban street map topology directly from ego-view images, as needed to continually update and expand existing maps. This is a challenging task, as we need to infer a complex urban road topology directly from raw image data. The main insight of this paper is that this problem can be posed as cross-modal retrieval by learning a joint, cross-modal embedding space for images and existing maps, represented as discrete graphs that encode the topological layout of the visual surroundings. We conduct our experimental evaluation using the Argoverse dataset and show that it is indeed possible to accurately retrieve street maps corresponding to both seen and unseen roads solely from image data. Moreover, we show that our retrieved maps can be used to update or expand existing maps and even show proof-of-concept results for visual localization and image retrieval from spatial graphs.
Dataset Distillation with Convexified Implicit Gradients
Feb 13, 2023
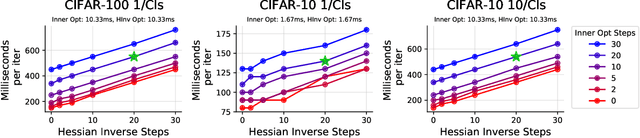
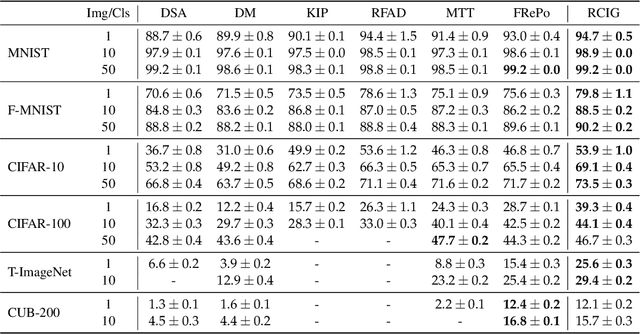

We propose a new dataset distillation algorithm using reparameterization and convexification of implicit gradients (RCIG), that substantially improves the state-of-the-art. To this end, we first formulate dataset distillation as a bi-level optimization problem. Then, we show how implicit gradients can be effectively used to compute meta-gradient updates. We further equip the algorithm with a convexified approximation that corresponds to learning on top of a frozen finite-width neural tangent kernel. Finally, we improve bias in implicit gradients by parameterizing the neural network to enable analytical computation of final-layer parameters given the body parameters. RCIG establishes the new state-of-the-art on a diverse series of dataset distillation tasks. Notably, with one image per class, on resized ImageNet, RCIG sees on average a 108% improvement over the previous state-of-the-art distillation algorithm. Similarly, we observed a 66% gain over SOTA on Tiny-ImageNet and 37% on CIFAR-100.
Beyond web-scraping: Crowd-sourcing a geographically diverse image dataset
Jan 05, 2023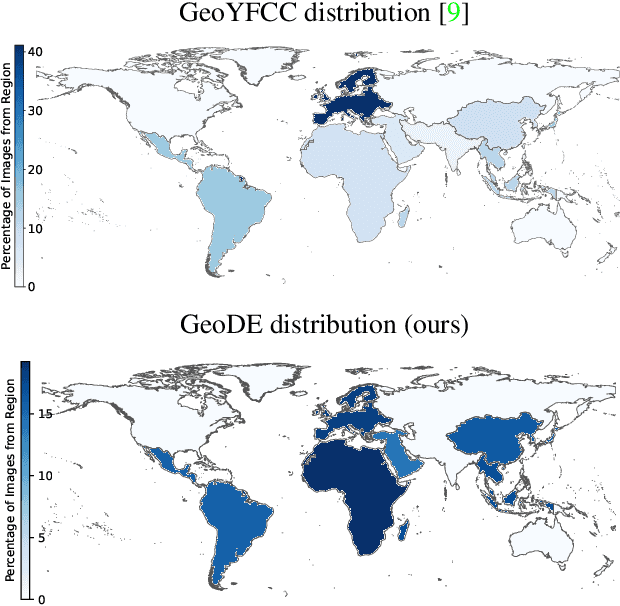
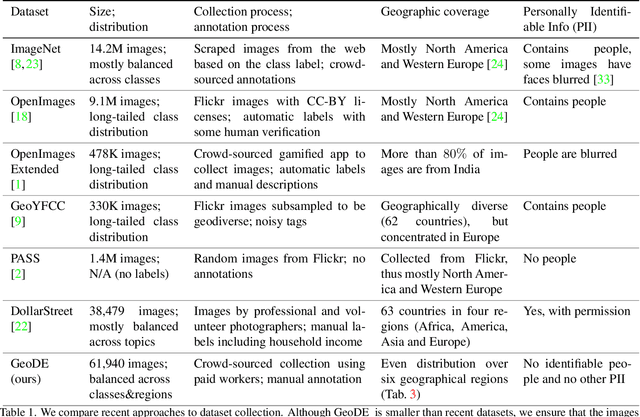


Current dataset collection methods typically scrape large amounts of data from the web. While this technique is extremely scalable, data collected in this way tends to reinforce stereotypical biases, can contain personally identifiable information, and typically originates from Europe and North America. In this work, we rethink the dataset collection paradigm and introduce GeoDE, a geographically diverse dataset with 61,940 images from 40 classes and 6 world regions, and no personally identifiable information, collected through crowd-sourcing. We analyse GeoDE to understand differences in images collected in this manner compared to web-scraping. Despite the smaller size of this dataset, we demonstrate its use as both an evaluation and training dataset, highlight shortcomings in current models, as well as show improved performances when even small amounts of GeoDE (1000 - 2000 images per region) are added to a training dataset. We release the full dataset and code at https://geodiverse-data-collection.cs.princeton.edu/
Learning Frequency-Specific Quantization Scaling in VVC for Standard-Compliant Task-driven Image Coding
Jan 20, 2023

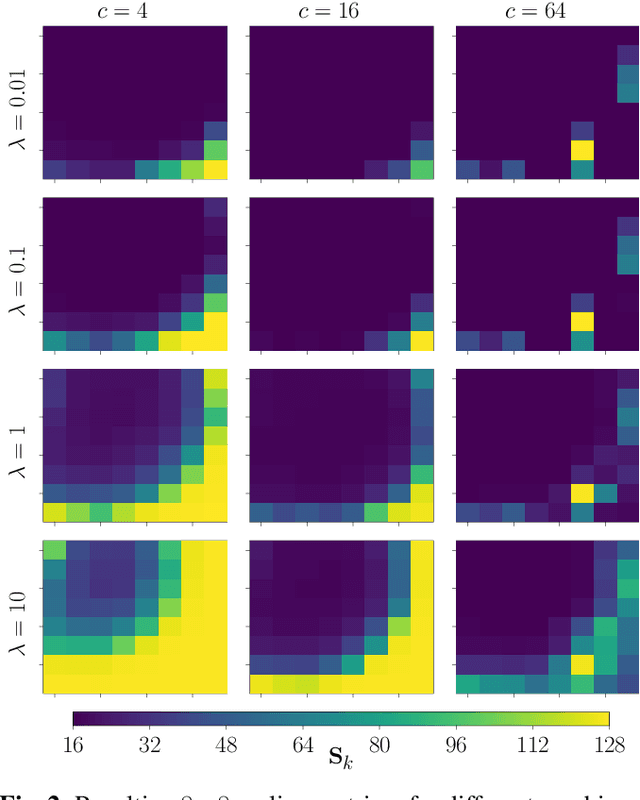
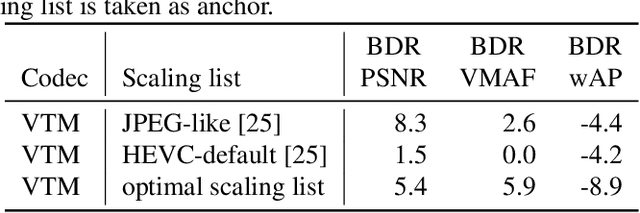
Today, visual data is often analyzed by a neural network without any human being involved, which demands for specialized codecs. For standard-compliant codec adaptations towards certain information sinks, HEVC or VVC provide the possibility of frequency-specific quantization with scaling lists. This is a well-known method for the human visual system, where scaling lists are derived from psycho-visual models. In this work, we employ scaling lists when performing VVC intra coding for neural networks as information sink. To this end, we propose a novel data-driven method to obtain optimal scaling lists for arbitrary neural networks. Experiments with Mask R-CNN as information sink reveal that coding the Cityscapes dataset with the proposed scaling lists result in peak bitrate savings of 8.9 % over VVC with constant quantization. By that, our approach also outperforms scaling lists optimized for the human visual system. The generated scaling lists can be found under https://github.com/FAU-LMS/VCM_scaling_lists.
* Originally submitted at IEEE ICIP 2022
Spatial Functa: Scaling Functa to ImageNet Classification and Generation
Feb 09, 2023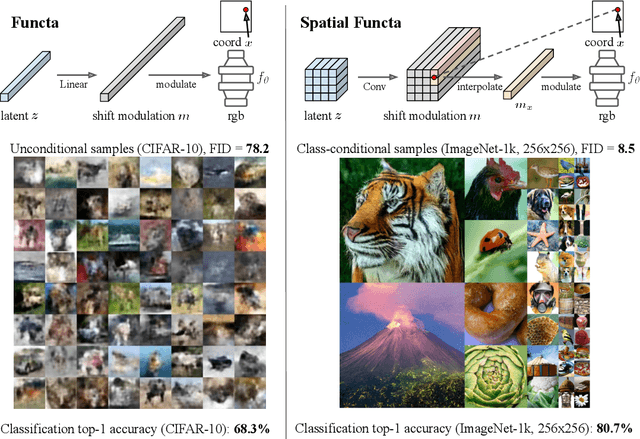
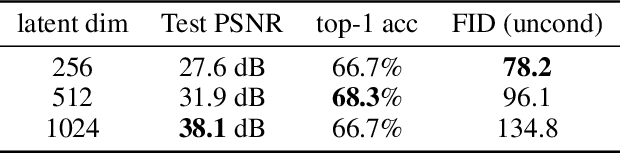


Neural fields, also known as implicit neural representations, have emerged as a powerful means to represent complex signals of various modalities. Based on this Dupont et al. (2022) introduce a framework that views neural fields as data, termed *functa*, and proposes to do deep learning directly on this dataset of neural fields. In this work, we show that the proposed framework faces limitations when scaling up to even moderately complex datasets such as CIFAR-10. We then propose *spatial functa*, which overcome these limitations by using spatially arranged latent representations of neural fields, thereby allowing us to scale up the approach to ImageNet-1k at 256x256 resolution. We demonstrate competitive performance to Vision Transformers (Steiner et al., 2022) on classification and Latent Diffusion (Rombach et al., 2022) on image generation respectively.
Controllable Image Enhancement
Jun 16, 2022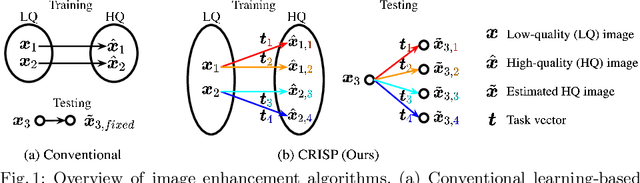
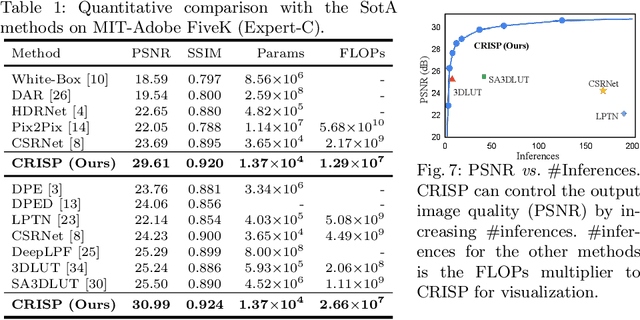
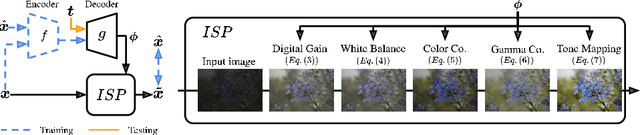

Editing flat-looking images into stunning photographs requires skill and time. Automated image enhancement algorithms have attracted increased interest by generating high-quality images without user interaction. However, the quality assessment of a photograph is subjective. Even in tone and color adjustments, a single photograph of auto-enhancement is challenging to fit user preferences which are subtle and even changeable. To address this problem, we present a semiautomatic image enhancement algorithm that can generate high-quality images with multiple styles by controlling a few parameters. We first disentangle photo retouching skills from high-quality images and build an efficient enhancement system for each skill. Specifically, an encoder-decoder framework encodes the retouching skills into latent codes and decodes them into the parameters of image signal processing (ISP) functions. The ISP functions are computationally efficient and consist of only 19 parameters. Despite our approach requiring multiple inferences to obtain the desired result, experimental results present that the proposed method achieves state-of-the-art performances on the benchmark dataset for image quality and model efficiency.
GAN-Based Object Removal in High-Resolution Satellite Images
Jan 24, 2023

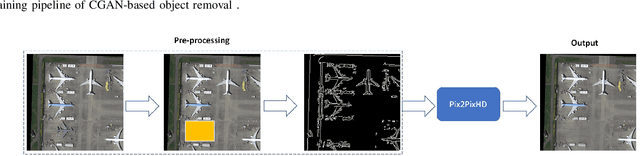

Satellite images often contain a significant level of sensitive data compared to ground-view images. That is why satellite images are more likely to be intentionally manipulated to hide specific objects and structures. GAN-based approaches have been employed to create forged images with two major problems: (i) adding a new object to the scene to hide a specific object or region may create unrealistic merging with surrounding areas; and (ii) using masks on color feature images has proven to be unsuccessful in GAN-based object removal. In this paper, we tackle the problem of object removal in high-resolution satellite images given a limited number of training data. Furthermore, we take advantage of conditional GANs (CGANs) to collect perhaps the first GAN-based forged satellite image data set. All forged instances were manipulated via CGANs trained by Canny Feature Images for object removal. As part of our experiments, we demonstrate that distinguishing the collected forged images from authentic (original) images is highly challenging for fake image detector models.
A General Visual Representation Guided Framework with Global Affinity for Weakly Supervised Salient Object Detection
Feb 21, 2023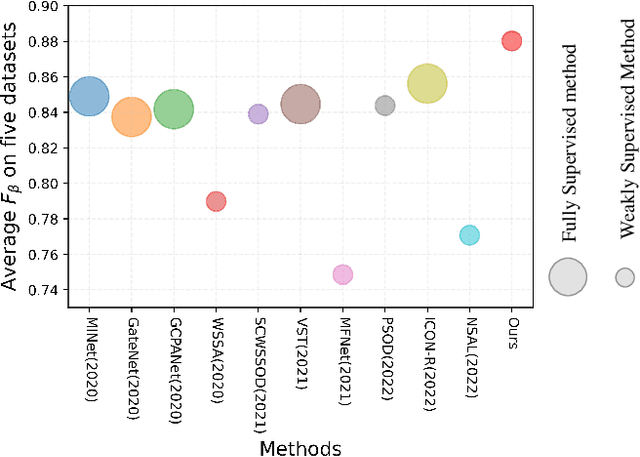
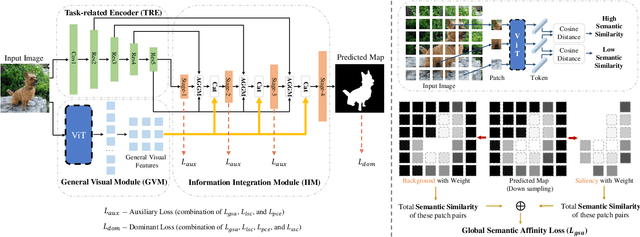
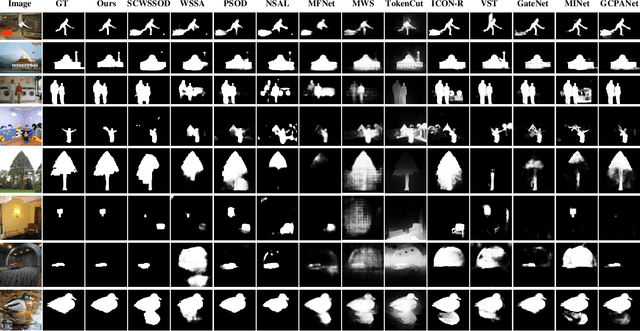

Fully supervised salient object detection (SOD) methods have made considerable progress in performance, yet these models rely heavily on expensive pixel-wise labels. Recently, to achieve a trade-off between labeling burden and performance, scribble-based SOD methods have attracted increasing attention. Previous models directly implement the SOD task only based on small-scale SOD training data. Due to the limited information provided by the weakly scribble tags and such small-scale training data, it is extremely difficult for them to understand the image and further achieve a superior SOD task. In this paper, we propose a simple yet effective framework guided by general visual representations that simulate the general cognition of humans for scribble-based SOD. It consists of a task-related encoder, a general visual module, and an information integration module to combine efficiently the general visual representations learned from large-scale unlabeled datasets with task-related features to perform the SOD task based on understanding the contextual connections of images. Meanwhile, we propose a novel global semantic affinity loss to guide the model to perceive the global structure of the salient objects. Experimental results on five public benchmark datasets demonstrate that our method that only utilizes scribble annotations without introducing any extra label outperforms the state-of-the-art weakly supervised SOD methods and is comparable or even superior to the state-of-the-art fully supervised models.