 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Understanding the Distillation Process from Deep Generative Models to Tractable Probabilistic Circuits
Feb 16, 2023
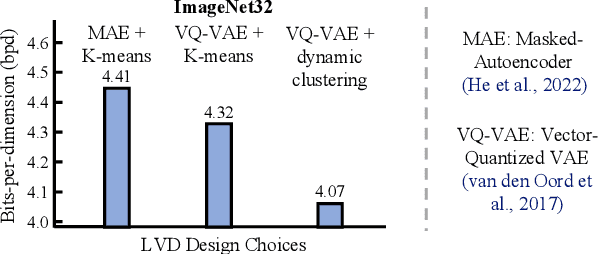
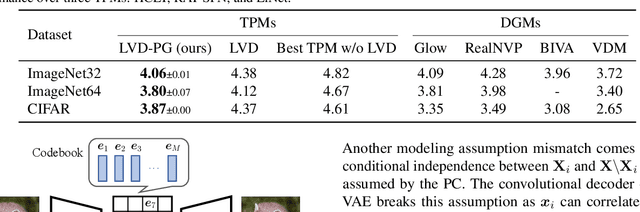
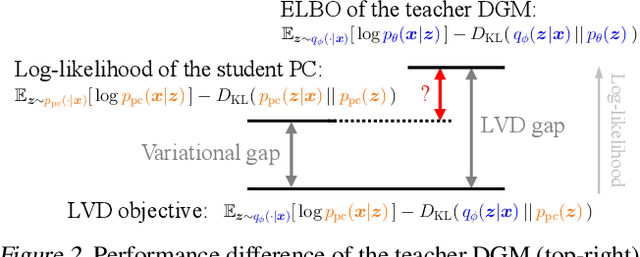
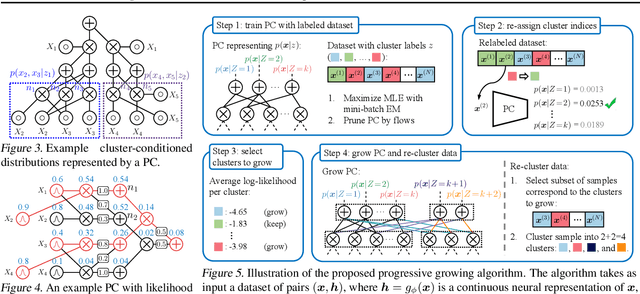
Probabilistic Circuits (PCs) are a general and unified computational framework for tractable probabilistic models that support efficient computation of various inference tasks (e.g., computing marginal probabilities). Towards enabling such reasoning capabilities in complex real-world tasks, Liu et al. (2022) propose to distill knowledge (through latent variable assignments) from less tractable but more expressive deep generative models. However, it is still unclear what factors make this distillation work well. In this paper, we theoretically and empirically discover that the performance of a PC can exceed that of its teacher model. Therefore, instead of performing distillation from the most expressive deep generative model, we study what properties the teacher model and the PC should have in order to achieve good distillation performance. This leads to a generic algorithmic improvement as well as other data-type-specific ones over the existing latent variable distillation pipeline. Empirically, we outperform SoTA TPMs by a large margin on challenging image modeling benchmarks. In particular, on ImageNet32, PCs achieve 4.06 bits-per-dimension, which is only 0.34 behind variational diffusion models (Kingma et al., 2021).
Take Me Home: Reversing Distribution Shifts using Reinforcement Learning
Feb 20, 2023

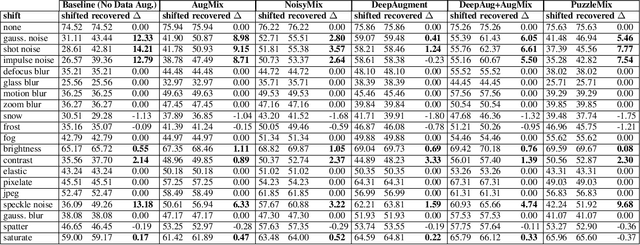
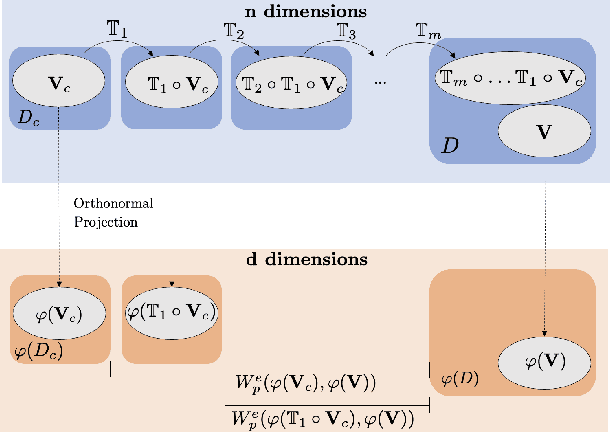
Deep neural networks have repeatedly been shown to be non-robust to the uncertainties of the real world. Even subtle adversarial attacks and naturally occurring distribution shifts wreak havoc on systems relying on deep neural networks. In response to this, current state-of-the-art techniques use data-augmentation to enrich the training distribution of the model and consequently improve robustness to natural distribution shifts. We propose an alternative approach that allows the system to recover from distribution shifts online. Specifically, our method applies a sequence of semantic-preserving transformations to bring the shifted data closer in distribution to the training set, as measured by the Wasserstein distance. We formulate the problem of sequence selection as an MDP, which we solve using reinforcement learning. To aid in our estimates of Wasserstein distance, we employ dimensionality reduction through orthonormal projection. We provide both theoretical and empirical evidence that orthonormal projection preserves characteristics of the data at the distributional level. Finally, we apply our distribution shift recovery approach to the ImageNet-C benchmark for distribution shifts, targeting shifts due to additive noise and image histogram modifications. We demonstrate an improvement in average accuracy up to 14.21% across a variety of state-of-the-art ImageNet classifiers.
An Out-of-Domain Synapse Detection Challenge for Microwasp Brain Connectomes
Feb 01, 2023

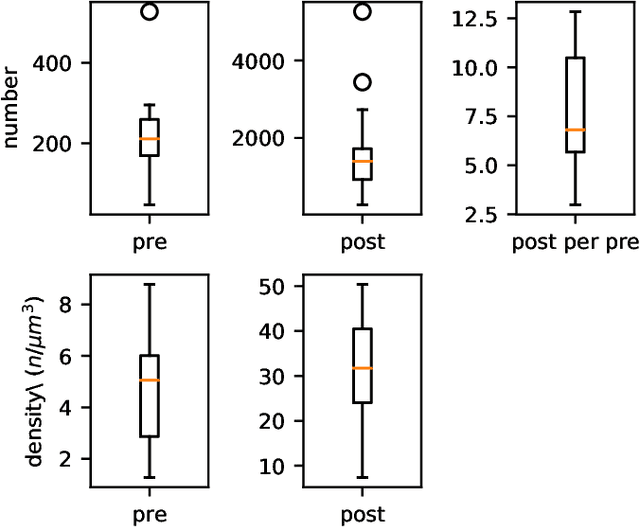

The size of image stacks in connectomics studies now reaches the terabyte and often petabyte scales with a great diversity of appearance across brain regions and samples. However, manual annotation of neural structures, e.g., synapses, is time-consuming, which leads to limited training data often smaller than 0.001\% of the test data in size. Domain adaptation and generalization approaches were proposed to address similar issues for natural images, which were less evaluated on connectomics data due to a lack of out-of-domain benchmarks.
Improving Sketch Colorization using Adversarial Segmentation Consistency
Jan 20, 2023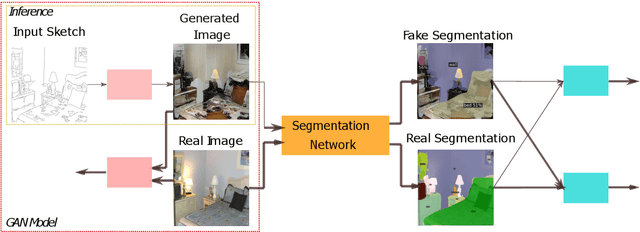
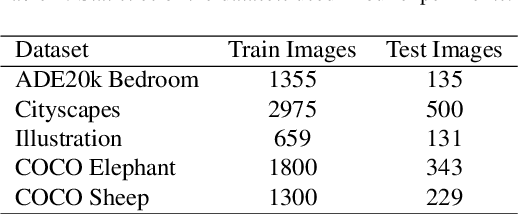

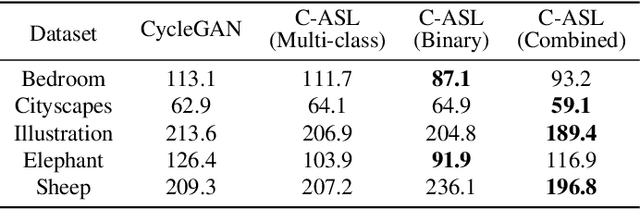
We propose a new method for producing color images from sketches. Current solutions in sketch colorization either necessitate additional user instruction or are restricted to the "paired" translation strategy. We leverage semantic image segmentation from a general-purpose panoptic segmentation network to generate an additional adversarial loss function. The proposed loss function is compatible with any GAN model. Our method is not restricted to datasets with segmentation labels and can be applied to unpaired translation tasks as well. Using qualitative, and quantitative analysis, and based on a user study, we demonstrate the efficacy of our method on four distinct image datasets. On the FID metric, our model improves the baseline by up to 35 points. Our code, pretrained models, scripts to produce newly introduced datasets and corresponding sketch images are available at https://github.com/giddyyupp/AdvSegLoss.
Deep Lossy Plus Residual Coding for Lossless and Near-lossless Image Compression
Sep 11, 2022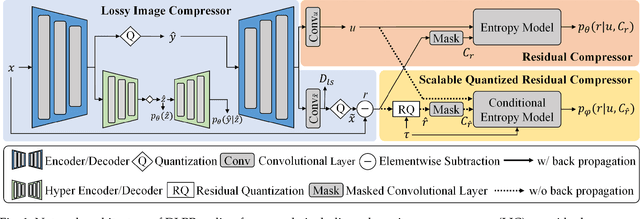
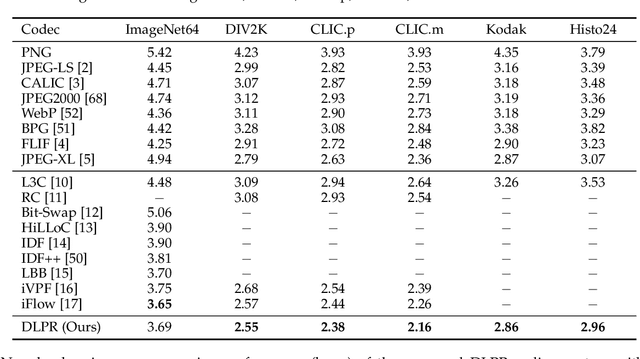
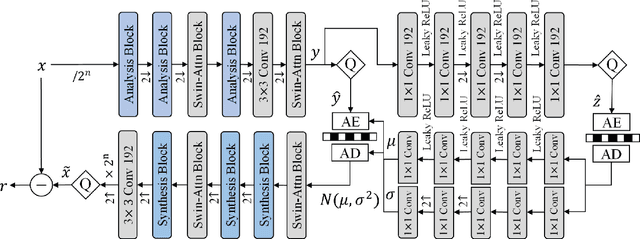
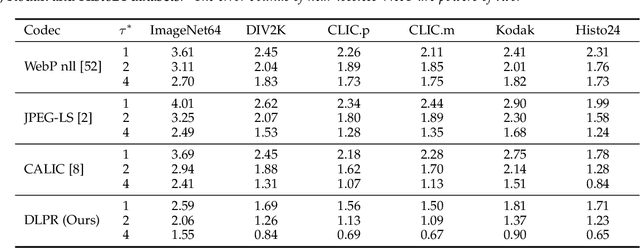
Lossless and near-lossless image compression is of paramount importance to professional users in many technical fields, such as medicine, remote sensing, precision engineering and scientific research. But despite rapidly growing research interests in learning-based image compression, no published method offers both lossless and near-lossless modes. In this paper, we propose a unified and powerful deep lossy plus residual (DLPR) coding framework for both lossless and near-lossless image compression. In the lossless mode, the DLPR coding system first performs lossy compression and then lossless coding of residuals. We solve the joint lossy and residual compression problem in the approach of VAEs, and add autoregressive context modeling of the residuals to enhance lossless compression performance. In the near-lossless mode, we quantize the original residuals to satisfy a given $\ell_\infty$ error bound, and propose a scalable near-lossless compression scheme that works for variable $\ell_\infty$ bounds instead of training multiple networks. To expedite the DLPR coding, we increase the degree of algorithm parallelization by a novel design of coding context, and accelerate the entropy coding with adaptive residual interval. Experimental results demonstrate that the DLPR coding system achieves both the state-of-the-art lossless and near-lossless image compression performance with competitive coding speed.
MIDMs: Matching Interleaved Diffusion Models for Exemplar-based Image Translation
Sep 23, 2022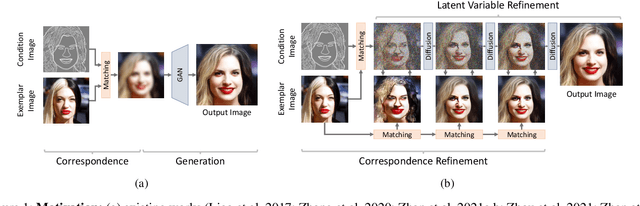
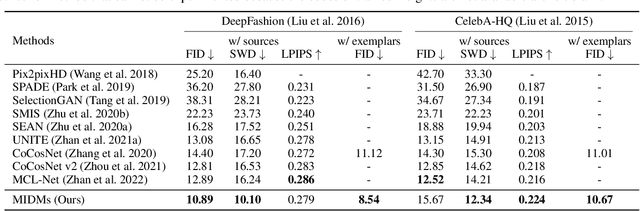
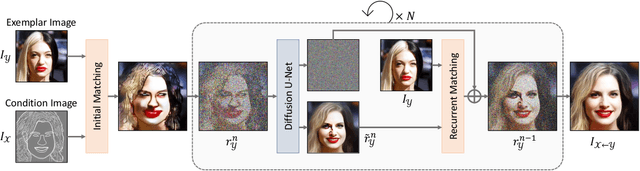
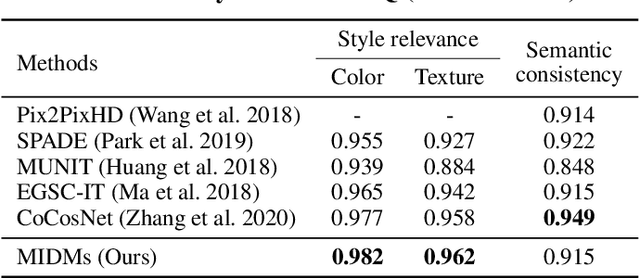
We present a novel method for exemplar-based image translation, called matching interleaved diffusion models (MIDMs). Most existing methods for this task were formulated as GAN-based matching-then-generation framework. However, in this framework, matching errors induced by the difficulty of semantic matching across cross-domain, e.g., sketch and photo, can be easily propagated to the generation step, which in turn leads to degenerated results. Motivated by the recent success of diffusion models overcoming the shortcomings of GANs, we incorporate the diffusion models to overcome these limitations. Specifically, we formulate a diffusion-based matching-and-generation framework that interleaves cross-domain matching and diffusion steps in the latent space by iteratively feeding the intermediate warp into the noising process and denoising it to generate a translated image. In addition, to improve the reliability of the diffusion process, we design a confidence-aware process using cycle-consistency to consider only confident regions during translation. Experimental results show that our MIDMs generate more plausible images than state-of-the-art methods.
MimCo: Masked Image Modeling Pre-training with Contrastive Teacher
Sep 07, 2022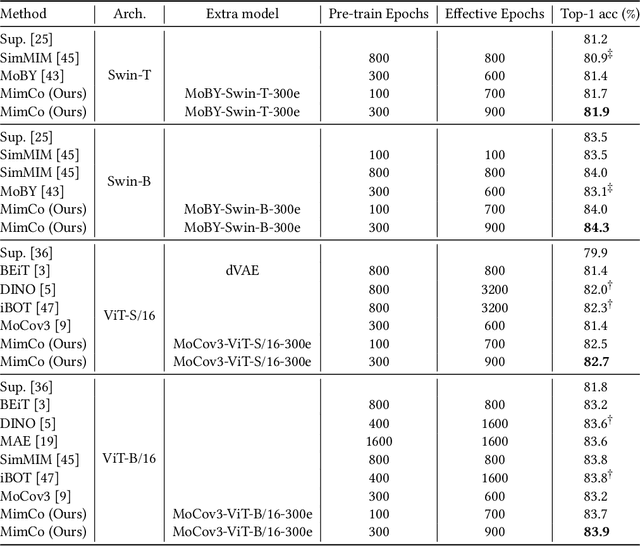
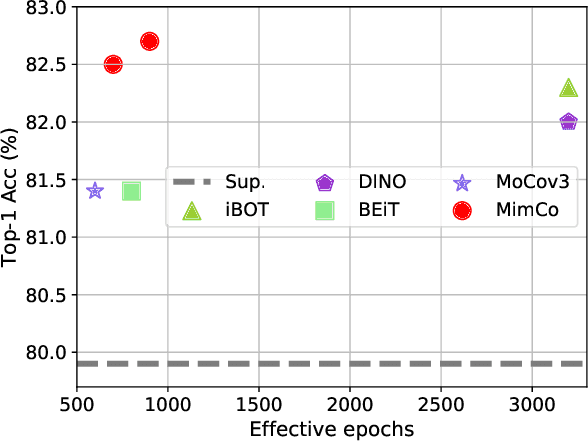
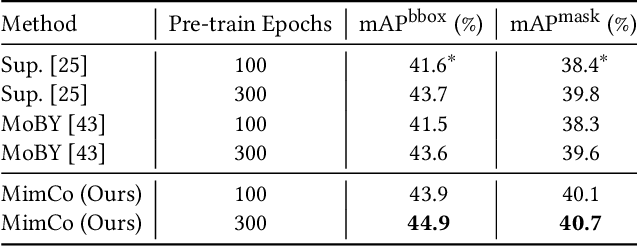
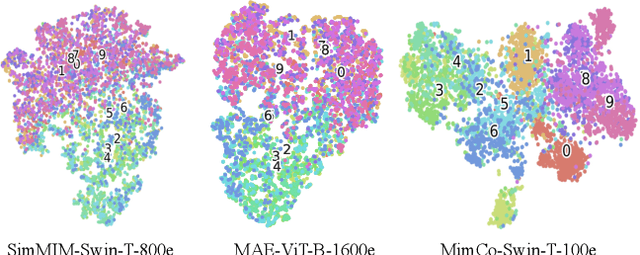
Recent masked image modeling (MIM) has received much attention in self-supervised learning (SSL), which requires the target model to recover the masked part of the input image. Although MIM-based pre-training methods achieve new state-of-the-art performance when transferred to many downstream tasks, the visualizations show that the learned representations are less separable, especially compared to those based on contrastive learning pre-training. This inspires us to think whether the linear separability of MIM pre-trained representation can be further improved, thereby improving the pre-training performance. Since MIM and contrastive learning tend to utilize different data augmentations and training strategies, combining these two pretext tasks is not trivial. In this work, we propose a novel and flexible pre-training framework, named MimCo, which combines MIM and contrastive learning through two-stage pre-training. Specifically, MimCo takes a pre-trained contrastive learning model as the teacher model and is pre-trained with two types of learning targets: patch-level and image-level reconstruction losses. Extensive transfer experiments on downstream tasks demonstrate the superior performance of our MimCo pre-training framework. Taking ViT-S as an example, when using the pre-trained MoCov3-ViT-S as the teacher model, MimCo only needs 100 epochs of pre-training to achieve 82.53% top-1 finetuning accuracy on Imagenet-1K, which outperforms the state-of-the-art self-supervised learning counterparts.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023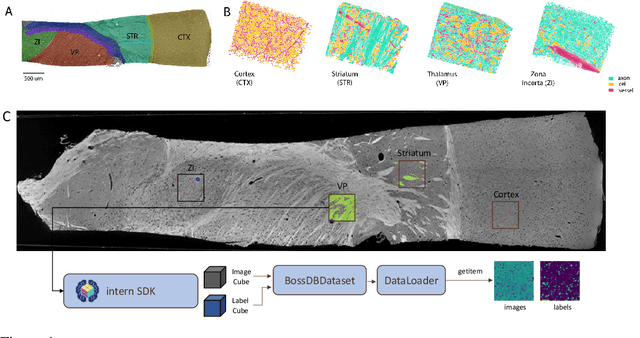
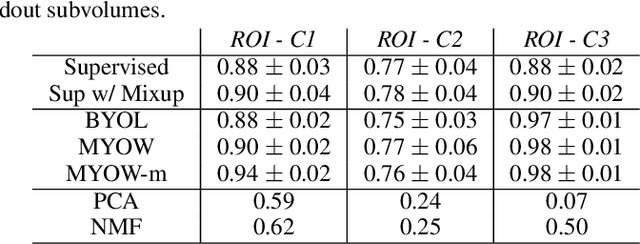

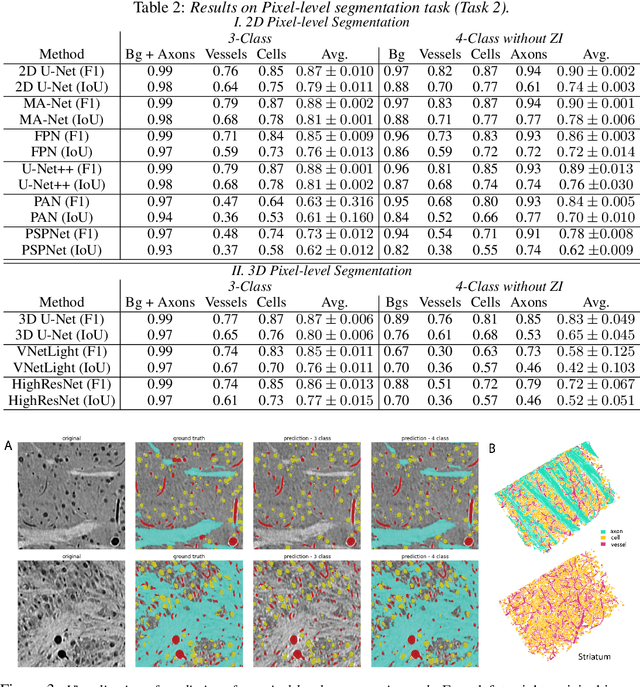
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
Auto-regressive Image Synthesis with Integrated Quantization
Jul 21, 2022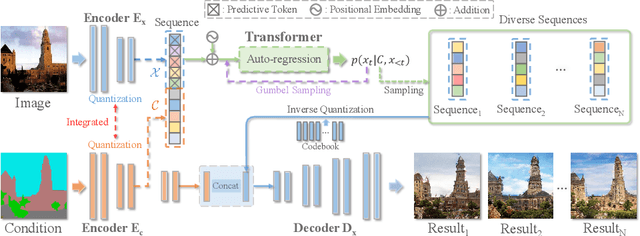
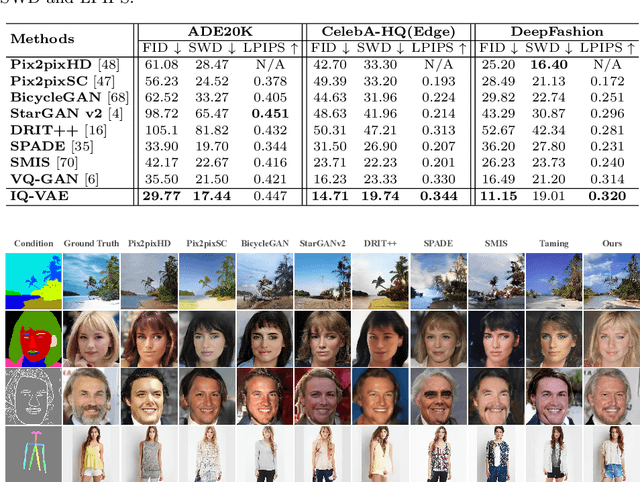
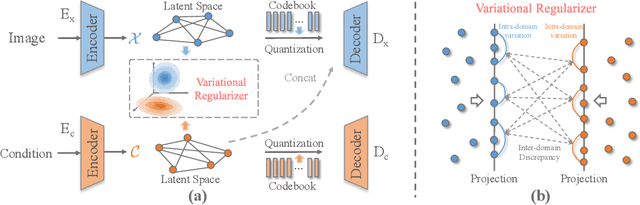
Deep generative models have achieved conspicuous progress in realistic image synthesis with multifarious conditional inputs, while generating diverse yet high-fidelity images remains a grand challenge in conditional image generation. This paper presents a versatile framework for conditional image generation which incorporates the inductive bias of CNNs and powerful sequence modeling of auto-regression that naturally leads to diverse image generation. Instead of independently quantizing the features of multiple domains as in prior research, we design an integrated quantization scheme with a variational regularizer that mingles the feature discretization in multiple domains, and markedly boosts the auto-regressive modeling performance. Notably, the variational regularizer enables to regularize feature distributions in incomparable latent spaces by penalizing the intra-domain variations of distributions. In addition, we design a Gumbel sampling strategy that allows to incorporate distribution uncertainty into the auto-regressive training procedure. The Gumbel sampling substantially mitigates the exposure bias that often incurs misalignment between the training and inference stages and severely impairs the inference performance. Extensive experiments over multiple conditional image generation tasks show that our method achieves superior diverse image generation performance qualitatively and quantitatively as compared with the state-of-the-art.
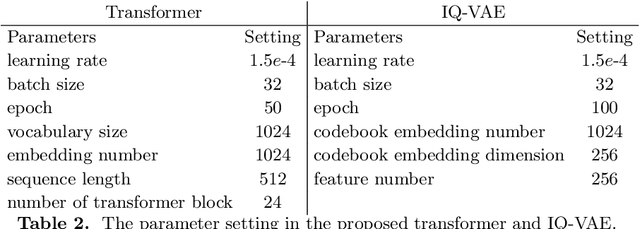
End-to-end joint optimization of metasurface and image processing for compact snapshot hyperspectral imaging
Oct 14, 2022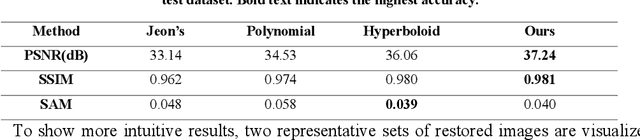
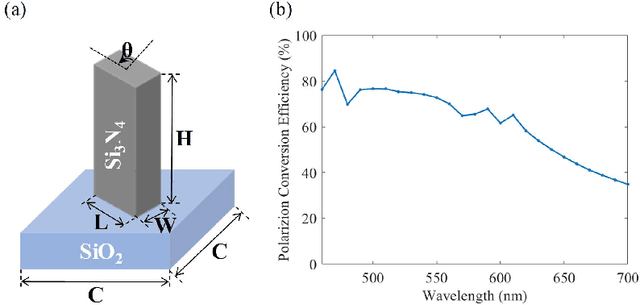
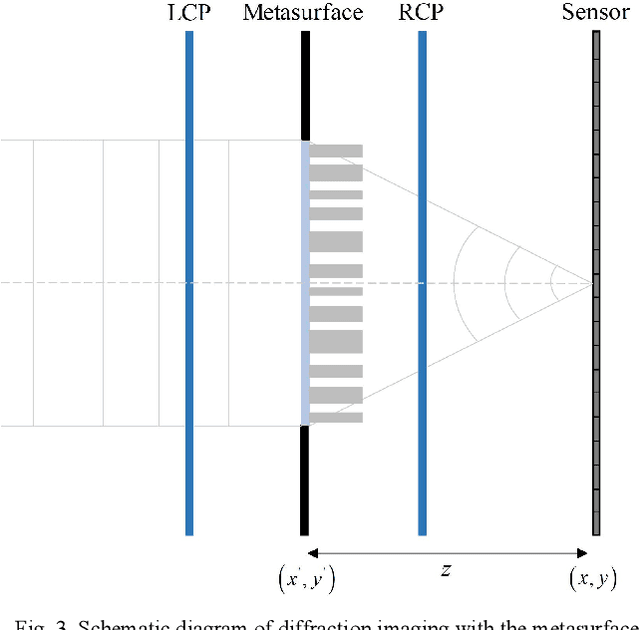
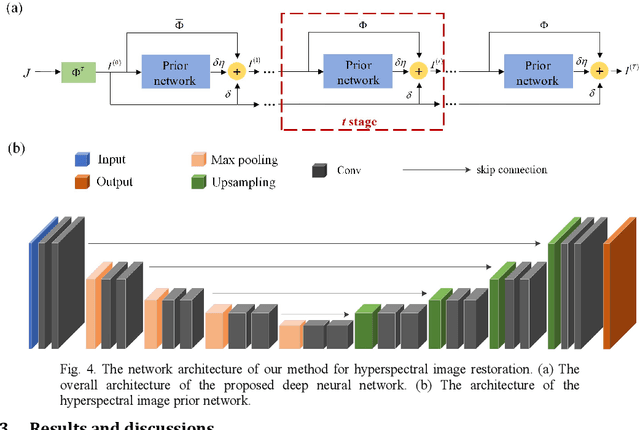
Traditional snapshot hyperspectral imaging systems generally require multiple refractive-optics-based elements to modulate light, resulting in bulky framework. In pursuit of a more compact form factor, a metasurface-based snapshot hyperspectral imaging system, which achieves joint optimization of metasurface and image processing, is proposed in this paper. The unprecedented light manipulation capabilities of metasurfaces are used in conjunction with neural networks to encode and decode light fields for better hyperspectral imaging. Specifically, the extremely strong dispersion of metasurfaces is exploited to distinguish spectral information, and a neural network based on spectral priors is applied for hyperspectral image reconstruction. By constructing a fully differentiable model of metasurface-based hyperspectral imaging, the front-end metasurface phase distribution and the back-end recovery network parameters can be jointly optimized. This method achieves high-quality hyperspectral reconstruction results numerically, outperforming separation optimization methods. The proposed system holds great potential for miniaturization and portability of hyperspectral imaging systems.