 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
Mar 17, 2024
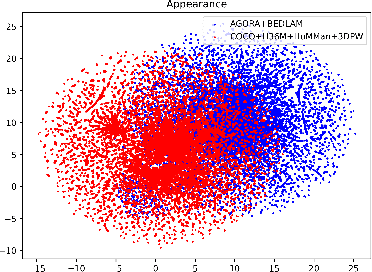
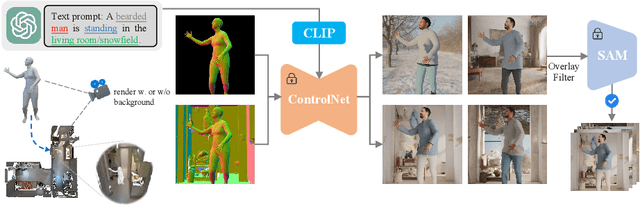
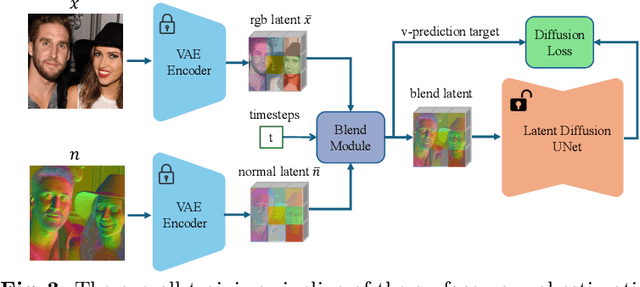
In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
Learn and Search: An Elegant Technique for Object Lookup using Contrastive Learning
Mar 12, 2024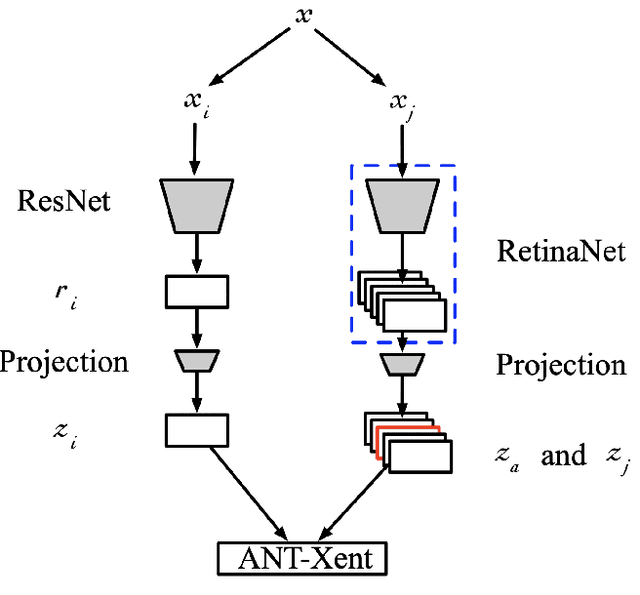


The rapid proliferation of digital content and the ever-growing need for precise object recognition and segmentation have driven the advancement of cutting-edge techniques in the field of object classification and segmentation. This paper introduces "Learn and Search", a novel approach for object lookup that leverages the power of contrastive learning to enhance the efficiency and effectiveness of retrieval systems. In this study, we present an elegant and innovative methodology that integrates deep learning principles and contrastive learning to tackle the challenges of object search. Our extensive experimentation reveals compelling results, with "Learn and Search" achieving superior Similarity Grid Accuracy, showcasing its efficacy in discerning regions of utmost similarity within an image relative to a cropped image. The seamless fusion of deep learning and contrastive learning to address the intricacies of object identification not only promises transformative applications in image recognition, recommendation systems, and content tagging but also revolutionizes content-based search and retrieval. The amalgamation of these techniques, as exemplified by "Learn and Search," represents a significant stride in the ongoing evolution of methodologies in the dynamic realm of object classification and segmentation.
AACP: Aesthetics assessment of children's paintings based on self-supervised learning
Mar 12, 2024
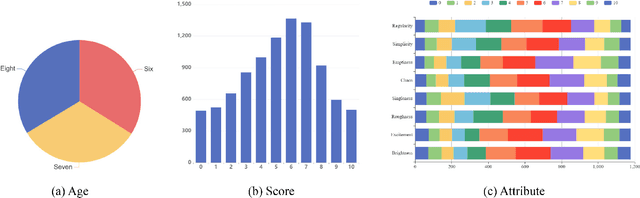
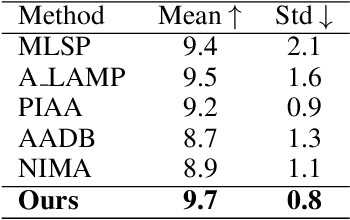
The Aesthetics Assessment of Children's Paintings (AACP) is an important branch of the image aesthetics assessment (IAA), playing a significant role in children's education. This task presents unique challenges, such as limited available data and the requirement for evaluation metrics from multiple perspectives. However, previous approaches have relied on training large datasets and subsequently providing an aesthetics score to the image, which is not applicable to AACP. To solve this problem, we construct an aesthetics assessment dataset of children's paintings and a model based on self-supervised learning. 1) We build a novel dataset composed of two parts: the first part contains more than 20k unlabeled images of children's paintings; the second part contains 1.2k images of children's paintings, and each image contains eight attributes labeled by multiple design experts. 2) We design a pipeline that includes a feature extraction module, perception modules and a disentangled evaluation module. 3) We conduct both qualitative and quantitative experiments to compare our model's performance with five other methods using the AACP dataset. Our experiments reveal that our method can accurately capture aesthetic features and achieve state-of-the-art performance.
Regularizing CNNs using Confusion Penalty Based Label Smoothing for Histopathology Images
Mar 16, 2024
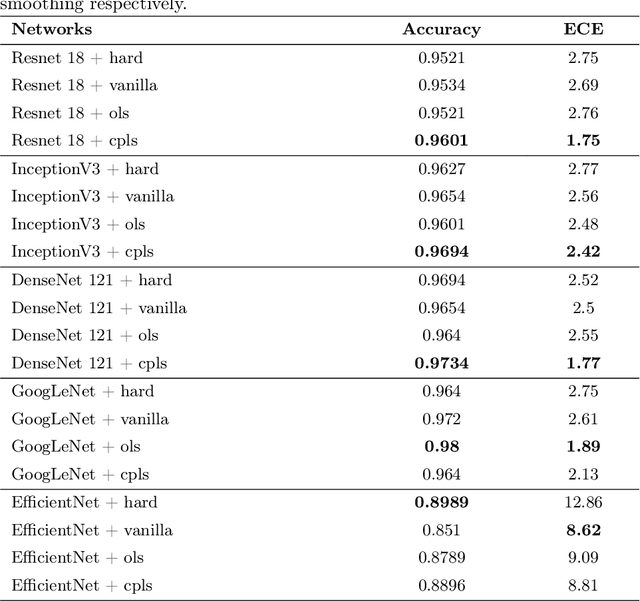
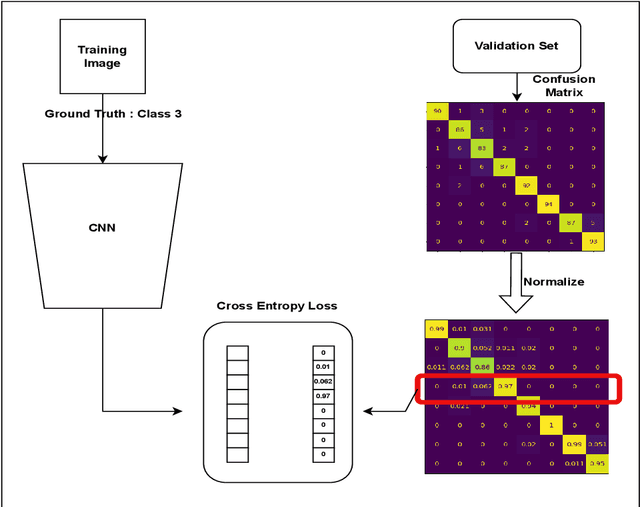
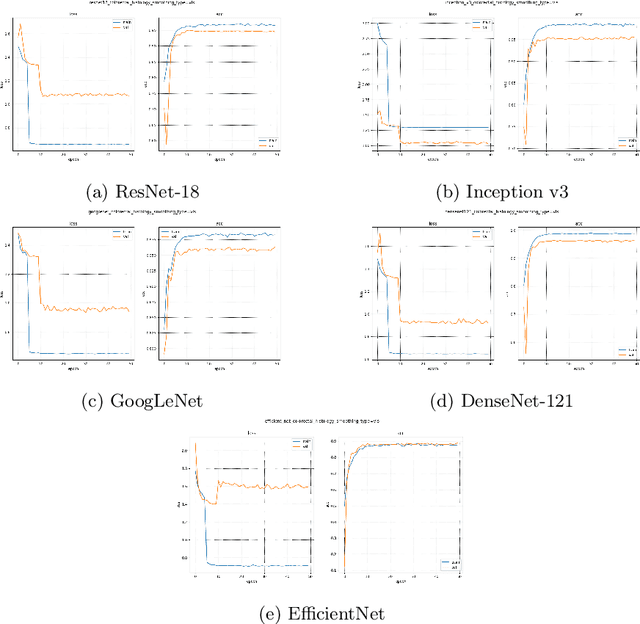
Deep Learning, particularly Convolutional Neural Networks (CNN), has been successful in computer vision tasks and medical image analysis. However, modern CNNs can be overconfident, making them difficult to deploy in real-world scenarios. Researchers propose regularizing techniques, such as Label Smoothing (LS), which introduces soft labels for training data, making the classifier more regularized. LS captures disagreements or lack of confidence in the training phase, making the classifier more regularized. Although LS is quite simple and effective, traditional LS techniques utilize a weighted average between target distribution and a uniform distribution across the classes, which limits the objective of LS as well as the performance. This paper introduces a novel LS technique based on the confusion penalty, which treats model confusion for each class with more importance than others. We have performed extensive experiments with well-known CNN architectures with this technique on publicly available Colorectal Histology datasets and got satisfactory results. Also, we have compared our findings with the State-of-the-art and shown our method's efficacy with Reliability diagrams and t-distributed Stochastic Neighbor Embedding (t-SNE) plots of feature space.
DPPE: Dense Pose Estimation in a Plenoxels Environment using Gradient Approximation
Mar 16, 2024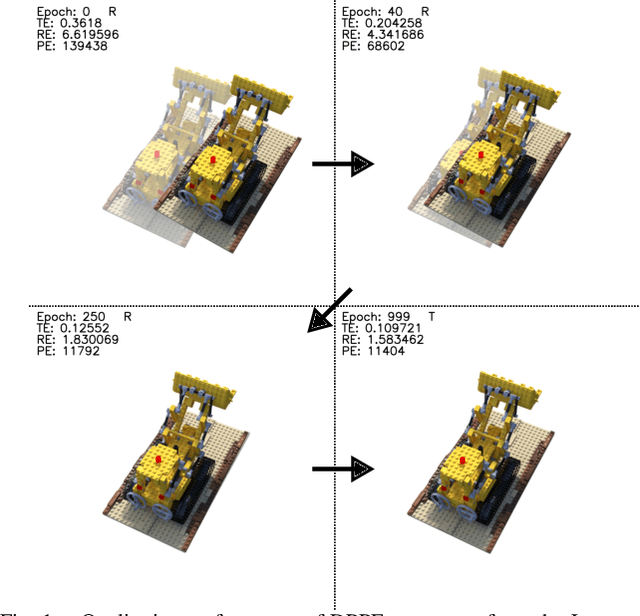
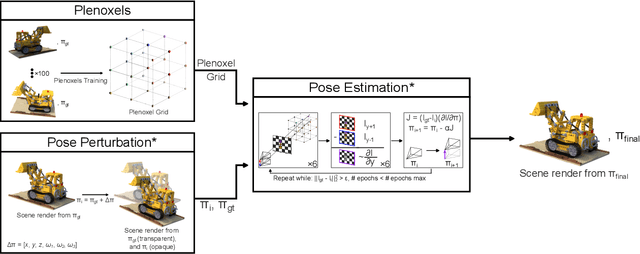
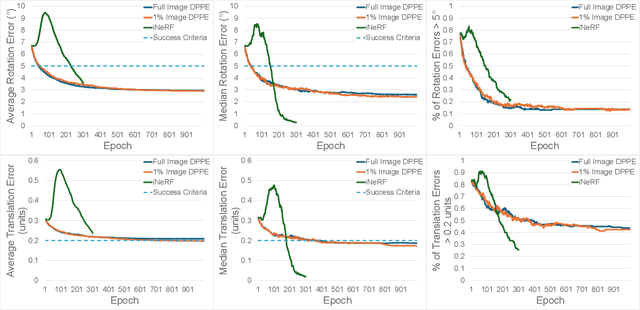

We present DPPE, a dense pose estimation algorithm that functions over a Plenoxels environment. Recent advances in neural radiance field techniques have shown that it is a powerful tool for environment representation. More recent neural rendering algorithms have significantly improved both training duration and rendering speed. Plenoxels introduced a fully-differentiable radiance field technique that uses Plenoptic volume elements contained in voxels for rendering, offering reduced training times and better rendering accuracy, while also eliminating the neural net component. In this work, we introduce a 6-DoF monocular RGB-only pose estimation procedure for Plenoxels, which seeks to recover the ground truth camera pose after a perturbation. We employ a variation on classical template matching techniques, using stochastic gradient descent to optimize the pose by minimizing errors in re-rendering. In particular, we examine an approach that takes advantage of the rapid rendering speed of Plenoxels to numerically approximate part of the pose gradient, using a central differencing technique. We show that such methods are effective in pose estimation. Finally, we perform ablations over key components of the problem space, with a particular focus on image subsampling and Plenoxel grid resolution. Project website: https://sites.google.com/view/dppe
Anomaly Detection Based on Isolation Mechanisms: A Survey
Mar 16, 2024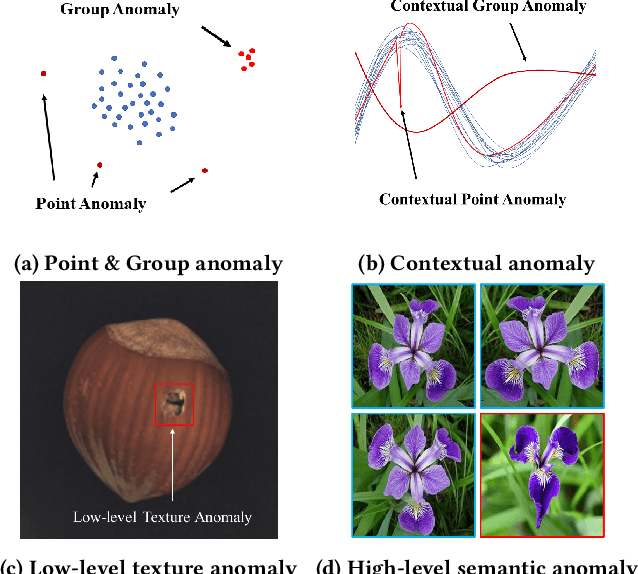
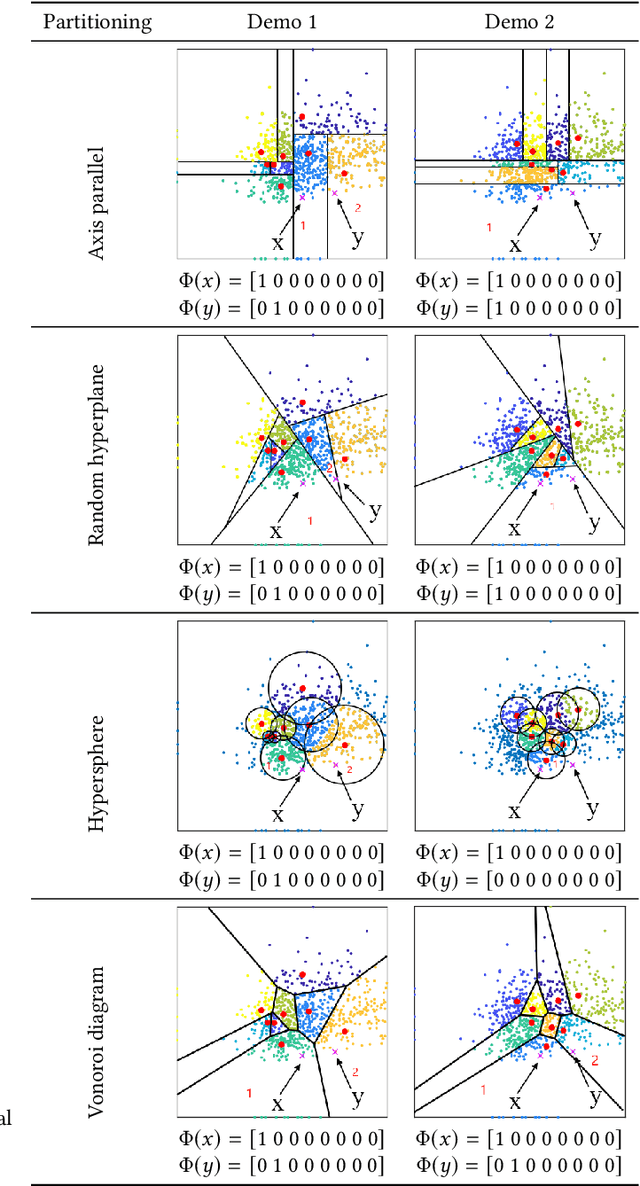
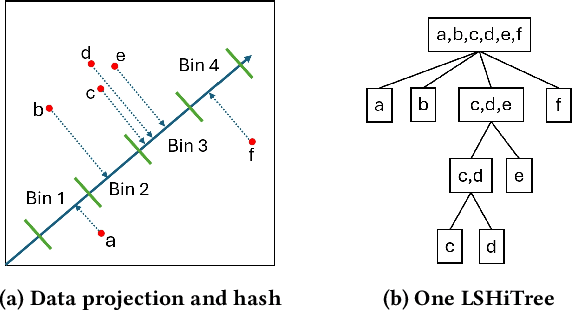

Anomaly detection is a longstanding and active research area that has many applications in domains such as finance, security, and manufacturing. However, the efficiency and performance of anomaly detection algorithms are challenged by the large-scale, high-dimensional, and heterogeneous data that are prevalent in the era of big data. Isolation-based unsupervised anomaly detection is a novel and effective approach for identifying anomalies in data. It relies on the idea that anomalies are few and different from normal instances, and thus can be easily isolated by random partitioning. Isolation-based methods have several advantages over existing methods, such as low computational complexity, low memory usage, high scalability, robustness to noise and irrelevant features, and no need for prior knowledge or heavy parameter tuning. In this survey, we review the state-of-the-art isolation-based anomaly detection methods, including their data partitioning strategies, anomaly score functions, and algorithmic details. We also discuss some extensions and applications of isolation-based methods in different scenarios, such as detecting anomalies in streaming data, time series, trajectory, and image datasets. Finally, we identify some open challenges and future directions for isolation-based anomaly detection research.
N2F2: Hierarchical Scene Understanding with Nested Neural Feature Fields
Mar 16, 2024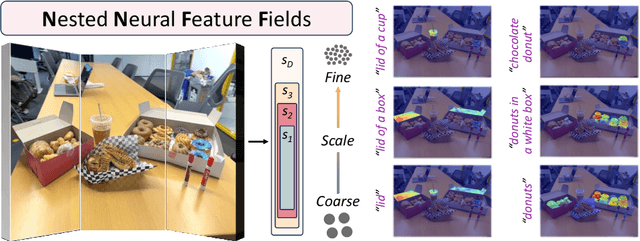
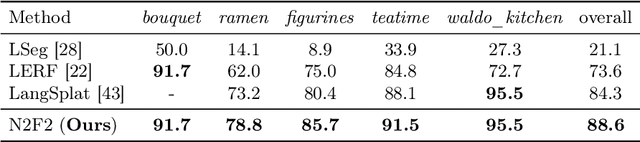
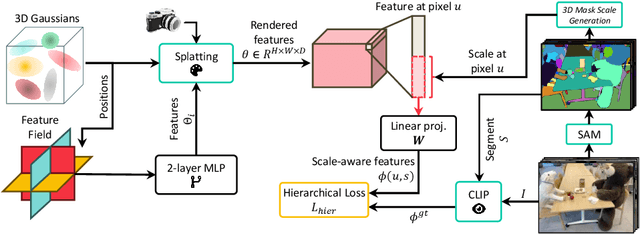
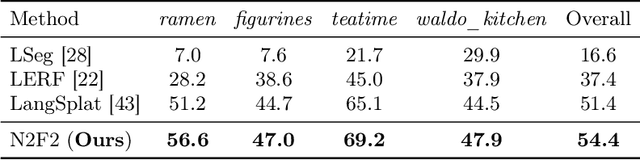
Understanding complex scenes at multiple levels of abstraction remains a formidable challenge in computer vision. To address this, we introduce Nested Neural Feature Fields (N2F2), a novel approach that employs hierarchical supervision to learn a single feature field, wherein different dimensions within the same high-dimensional feature encode scene properties at varying granularities. Our method allows for a flexible definition of hierarchies, tailored to either the physical dimensions or semantics or both, thereby enabling a comprehensive and nuanced understanding of scenes. We leverage a 2D class-agnostic segmentation model to provide semantically meaningful pixel groupings at arbitrary scales in the image space, and query the CLIP vision-encoder to obtain language-aligned embeddings for each of these segments. Our proposed hierarchical supervision method then assigns different nested dimensions of the feature field to distill the CLIP embeddings using deferred volumetric rendering at varying physical scales, creating a coarse-to-fine representation. Extensive experiments show that our approach outperforms the state-of-the-art feature field distillation methods on tasks such as open-vocabulary 3D segmentation and localization, demonstrating the effectiveness of the learned nested feature field.
Semantic Residual Prompts for Continual Learning
Mar 14, 2024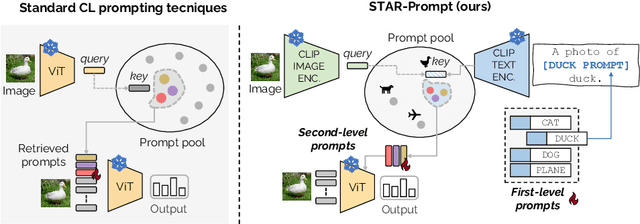
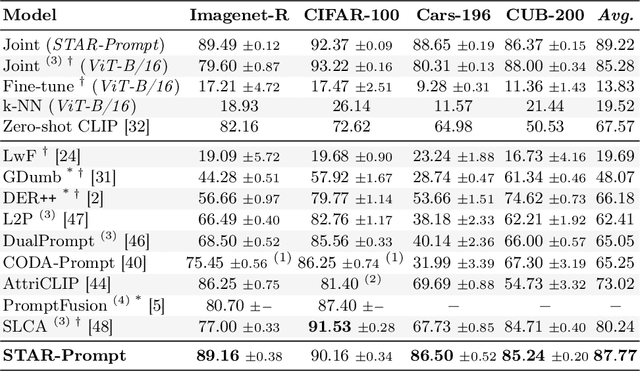
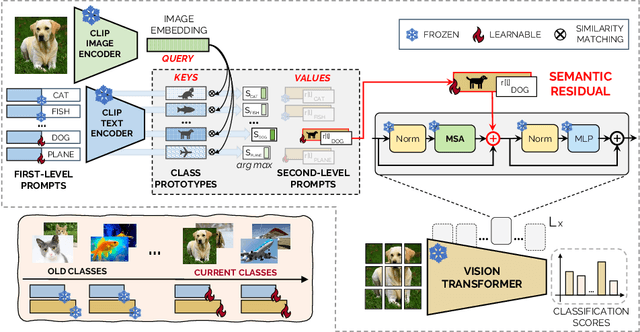
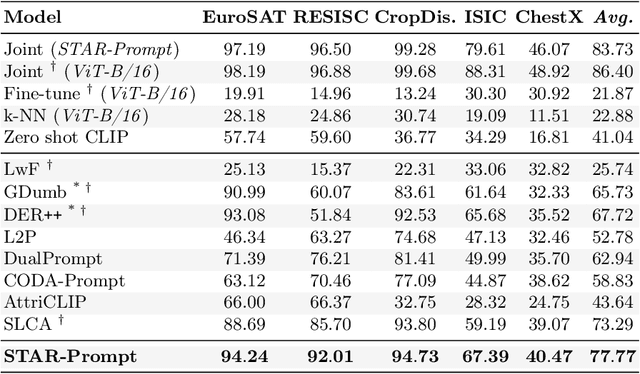
Prompt-tuning methods for Continual Learning (CL) freeze a large pre-trained model and focus training on a few parameter vectors termed prompts. Most of these methods organize these vectors in a pool of key-value pairs, and use the input image as query to retrieve the prompts (values). However, as keys are learned while tasks progress, the prompting selection strategy is itself subject to catastrophic forgetting, an issue often overlooked by existing approaches. For instance, prompts introduced to accommodate new tasks might end up interfering with previously learned prompts. To make the selection strategy more stable, we ask a foundational model (CLIP) to select our prompt within a two-level adaptation mechanism. Specifically, the first level leverages standard textual prompts for the CLIP textual encoder, leading to stable class prototypes. The second level, instead, uses these prototypes along with the query image as keys to index a second pool. The retrieved prompts serve to adapt a pre-trained ViT, granting plasticity. In doing so, we also propose a novel residual mechanism to transfer CLIP semantics to the ViT layers. Through extensive analysis on established CL benchmarks, we show that our method significantly outperforms both state-of-the-art CL approaches and the zero-shot CLIP test. Notably, our findings hold true even for datasets with a substantial domain gap w.r.t. the pre-training knowledge of the backbone model, as showcased by experiments on satellite imagery and medical datasets.
Diffusion Posterior Proximal Sampling for Image Restoration
Feb 25, 2024Diffusion models have demonstrated remarkable efficacy in generating high-quality samples. Existing diffusion-based image restoration algorithms exploit pre-trained diffusion models to leverage data priors, yet they still preserve elements inherited from the unconditional generation paradigm. These strategies initiate the denoising process with pure white noise and incorporate random noise at each generative step, leading to over-smoothed results. In this paper, we introduce a refined paradigm for diffusion-based image restoration. Specifically, we opt for a sample consistent with the measurement identity at each generative step, exploiting the sampling selection as an avenue for output stability and enhancement. Besides, we start the restoration process with an initialization combined with the measurement signal, providing supplementary information to better align the generative process. Extensive experimental results and analyses validate the effectiveness of our proposed approach across diverse image restoration tasks.
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 12, 2024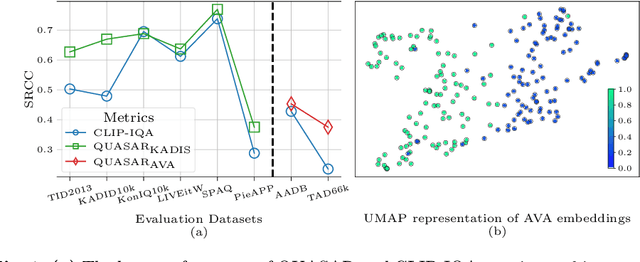
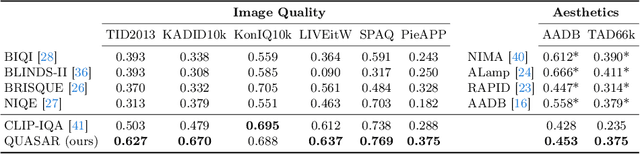
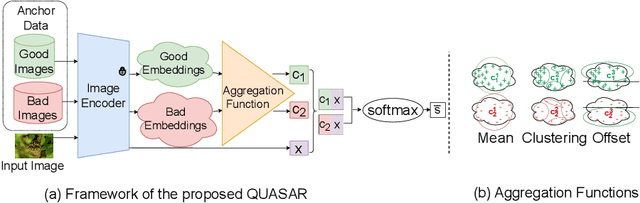

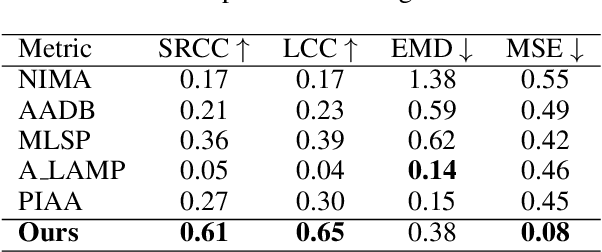
This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.