 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-similarity Driven Scale-invariant Learning for Weakly Supervised Person Search
Feb 25, 2023
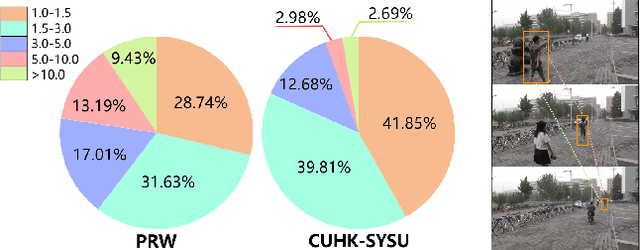
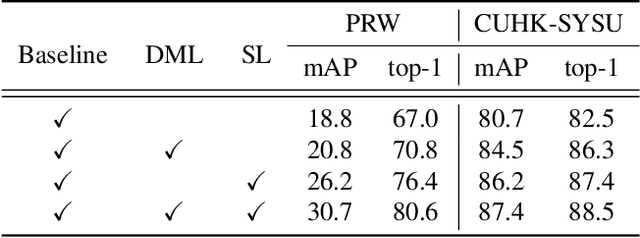
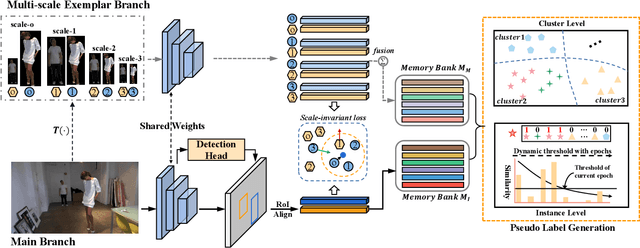
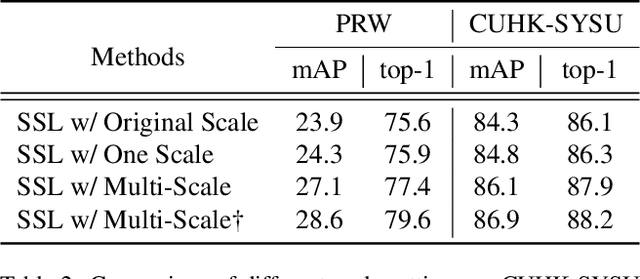
Weakly supervised person search aims to jointly detect and match persons with only bounding box annotations. Existing approaches typically focus on improving the features by exploring relations of persons. However, scale variation problem is a more severe obstacle and under-studied that a person often owns images with different scales (resolutions). On the one hand, small-scale images contain less information of a person, thus affecting the accuracy of the generated pseudo labels. On the other hand, the similarity of cross-scale images is often smaller than that of images with the same scale for a person, which will increase the difficulty of matching. In this paper, we address this problem by proposing a novel one-step framework, named Self-similarity driven Scale-invariant Learning (SSL). Scale invariance can be explored based on the self-similarity prior that it shows the same statistical properties of an image at different scales. To this end, we introduce a Multi-scale Exemplar Branch to guide the network in concentrating on the foreground and learning scale-invariant features by hard exemplars mining. To enhance the discriminative power of the features in an unsupervised manner, we introduce a dynamic multi-label prediction which progressively seeks true labels for training. It is adaptable to different types of unlabeled data and serves as a compensation for clustering based strategy. Experiments on PRW and CUHK-SYSU databases demonstrate the effectiveness of our method.
Chaotic Variational Auto encoder-based Adversarial Machine Learning
Feb 25, 2023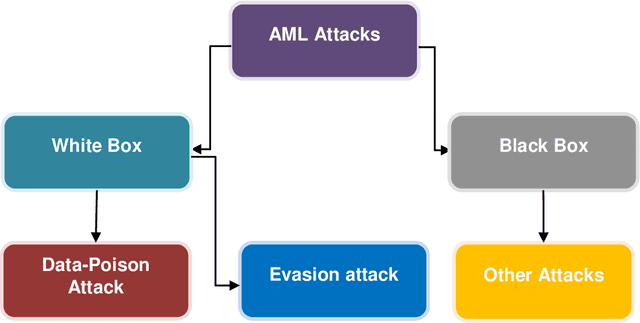
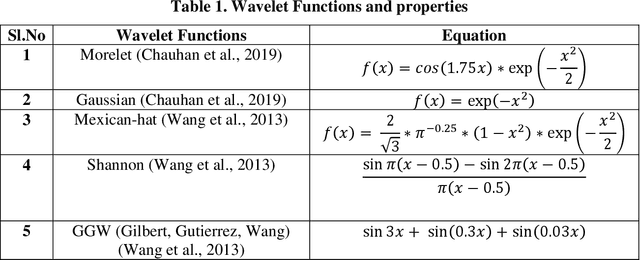
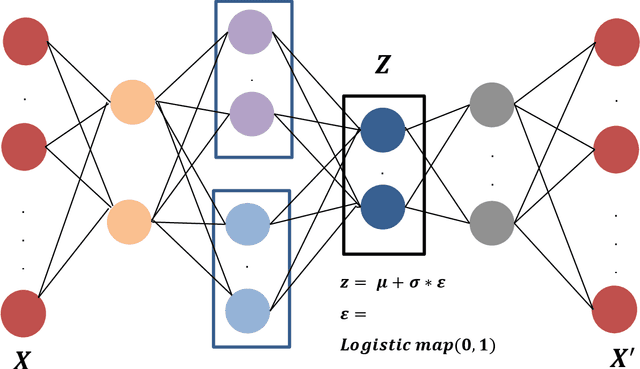
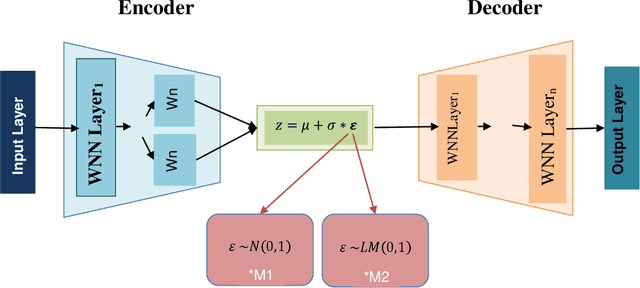
Machine Learning (ML) has become the new contrivance in almost every field. This makes them a target of fraudsters by various adversary attacks, thereby hindering the performance of ML models. Evasion and Data-Poison-based attacks are well acclaimed, especially in finance, healthcare, etc. This motivated us to propose a novel computationally less expensive attack mechanism based on the adversarial sample generation by Variational Auto Encoder (VAE). It is well known that Wavelet Neural Network (WNN) is considered computationally efficient in solving image and audio processing, speech recognition, and time-series forecasting. This paper proposed VAE-Deep-Wavelet Neural Network (VAE-Deep-WNN), where Encoder and Decoder employ WNN networks. Further, we proposed chaotic variants of both VAE with Multi-layer perceptron (MLP) and Deep-WNN and named them C-VAE-MLP and C-VAE-Deep-WNN, respectively. Here, we employed a Logistic map to generate random noise in the latent space. In this paper, we performed VAE-based adversary sample generation and applied it to various problems related to finance and cybersecurity domain-related problems such as loan default, credit card fraud, and churn modelling, etc., We performed both Evasion and Data-Poison attacks on Logistic Regression (LR) and Decision Tree (DT) models. The results indicated that VAE-Deep-WNN outperformed the rest in the majority of the datasets and models. However, its chaotic variant C-VAE-Deep-WNN performed almost similarly to VAE-Deep-WNN in the majority of the datasets.
A semantic backdoor attack against Graph Convolutional Networks
Feb 28, 2023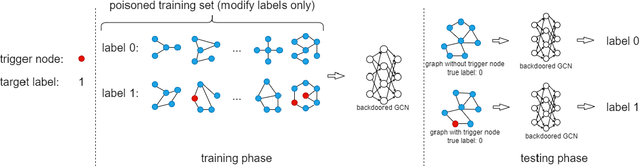
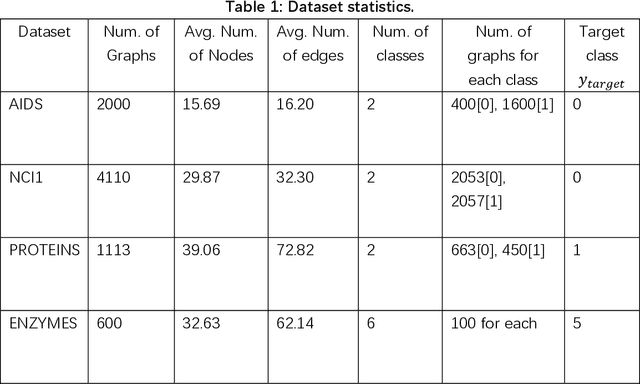
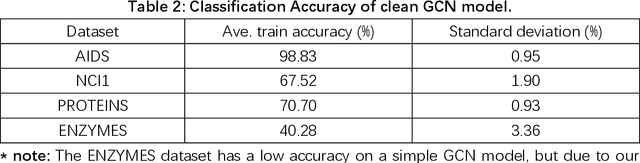
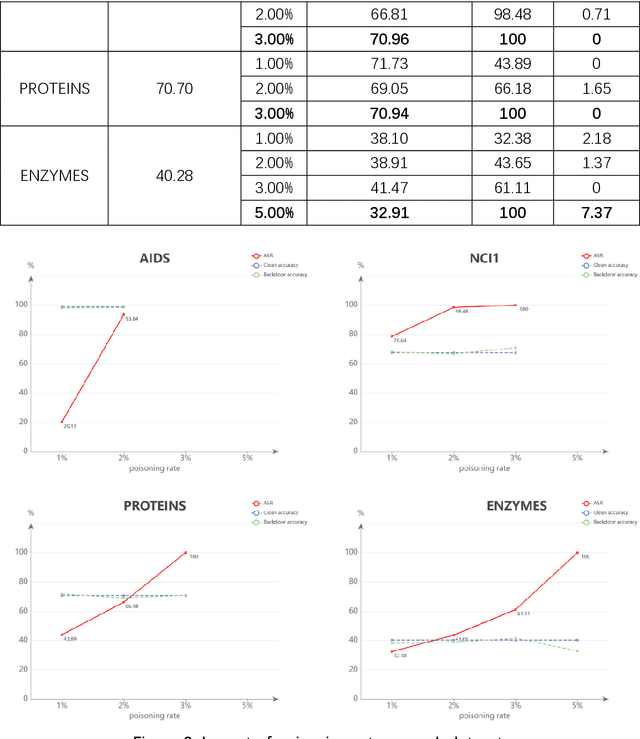
Graph Convolutional Networks (GCNs) have been very effective in addressing the issue of various graph-structured related tasks, such as node classification and graph classification. However, extensive research has shown that GCNs are vulnerable to adversarial attacks. One of the security threats facing GCNs is the backdoor attack, which hides incorrect classification rules in models and activates only when the model encounters specific inputs containing special features (e.g., fixed patterns like subgraphs, called triggers), thus outputting incorrect classification results, while the model behaves normally on benign samples. The semantic backdoor attack is a type of the backdoor attack where the trigger is a semantic part of the sample; i.e., the trigger exists naturally in the original dataset and the attacker can pick a naturally occurring feature as the backdoor trigger, which causes the model to misclassify even unmodified inputs. Meanwhile, it is difficult to detect even if the attacker modifies the input samples in the inference phase as they do not have any anomaly compared to normal samples. Thus, semantic backdoor attacks are more imperceptible than non-semantic ones. However, existed research on semantic backdoor attacks has only focused on image and text domains, which have not been well explored against GCNs. In this work, we propose a black-box Semantic Backdoor Attack (SBA) against GCNs. We assign the trigger as a certain class of nodes in the dataset and our trigger is semantic. Through evaluation on several real-world benchmark graph datasets, the experimental results demonstrate that our proposed SBA can achieve almost 100% attack success rate under the poisoning rate less than 5% while having no impact on normal predictive accuracy.
Diffusion Models For Stronger Face Morphing Attacks
Jan 10, 2023
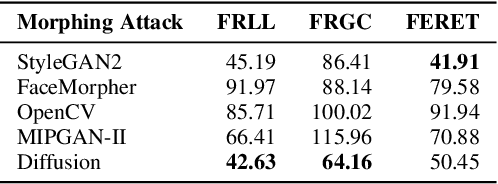
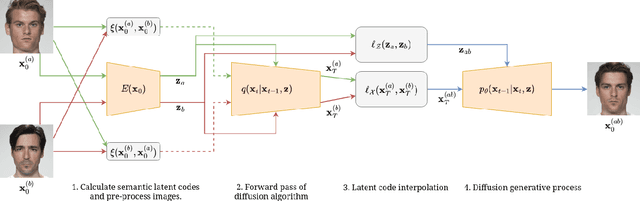
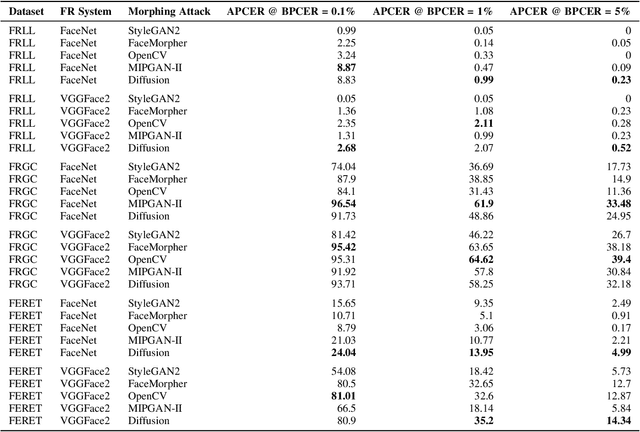
Face morphing attacks seek to deceive a Face Recognition (FR) system by presenting a morphed image consisting of the biometric qualities from two different identities with the aim of triggering a false acceptance with one of the two identities, thereby presenting a significant threat to biometric systems. The success of a morphing attack is dependent on the ability of the morphed image to represent the biometric characteristics of both identities that were used to create the image. We present a novel morphing attack that uses a Diffusion-based architecture to improve the visual fidelity of the image and improve the ability of the morphing attack to represent characteristics from both identities. We demonstrate the high fidelity of the proposed attack by evaluating its visual fidelity via the Frechet Inception Distance. Extensive experiments are conducted to measure the vulnerability of FR systems to the proposed attack. The proposed attack is compared to two state-of-the-art GAN-based morphing attacks along with two Landmark-based attacks. The ability of a morphing attack detector to detect the proposed attack is measured and compared against the other attacks. Additionally, a novel metric to measure the relative strength between morphing attacks is introduced and evaluated.
Geometry-Complete Diffusion for 3D Molecule Generation
Feb 15, 2023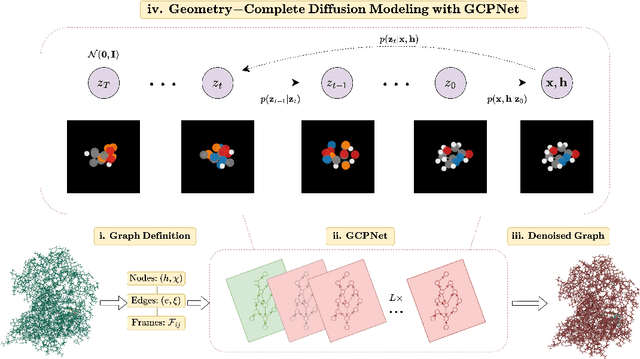
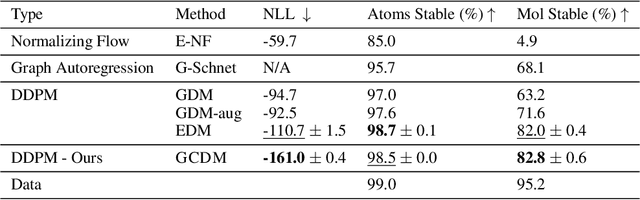
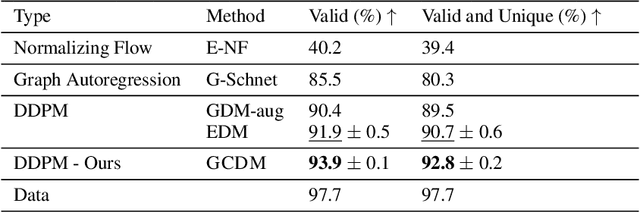
Denoising diffusion probabilistic models (DDPMs) have recently taken the field of generative modeling by storm, pioneering new state-of-the-art results in disciplines such as computer vision and computational biology for diverse tasks ranging from text-guided image generation to structure-guided protein design. Along this latter line of research, methods such as those of Hoogeboom et al. 2022 have been proposed for unconditionally generating 3D molecules using equivariant graph neural networks (GNNs) within a DDPM framework. Toward this end, we propose GCDM, a geometry-complete diffusion model that achieves new state-of-the-art results for 3D molecule diffusion generation by leveraging the representation learning strengths offered by GNNs that perform geometry-complete message-passing. Our results with GCDM also offer preliminary insights into how physical inductive biases impact the generative dynamics of molecular DDPMs. The source code, data, and instructions to train new models or reproduce our results are freely available at https://github.com/BioinfoMachineLearning/bio-diffusion.
Improved Online Conformal Prediction via Strongly Adaptive Online Learning
Feb 15, 2023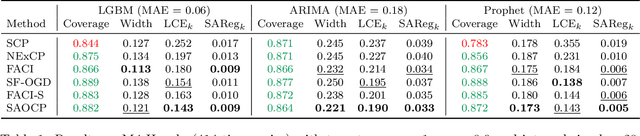
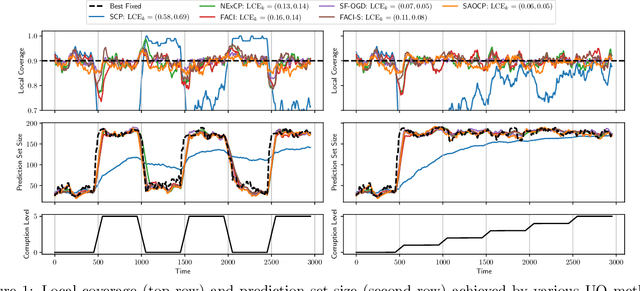

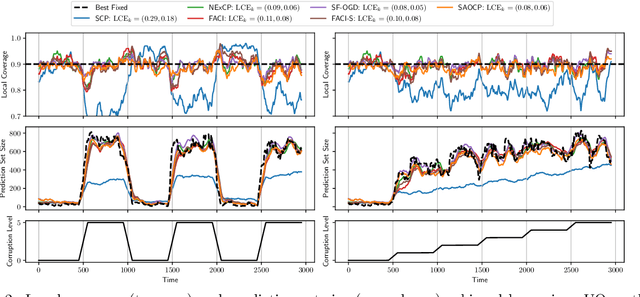
We study the problem of uncertainty quantification via prediction sets, in an online setting where the data distribution may vary arbitrarily over time. Recent work develops online conformal prediction techniques that leverage regret minimization algorithms from the online learning literature to learn prediction sets with approximately valid coverage and small regret. However, standard regret minimization could be insufficient for handling changing environments, where performance guarantees may be desired not only over the full time horizon but also in all (sub-)intervals of time. We develop new online conformal prediction methods that minimize the strongly adaptive regret, which measures the worst-case regret over all intervals of a fixed length. We prove that our methods achieve near-optimal strongly adaptive regret for all interval lengths simultaneously, and approximately valid coverage. Experiments show that our methods consistently obtain better coverage and smaller prediction sets than existing methods on real-world tasks, such as time series forecasting and image classification under distribution shift.
Unsupervised Hashing via Similarity Distribution Calibration
Feb 15, 2023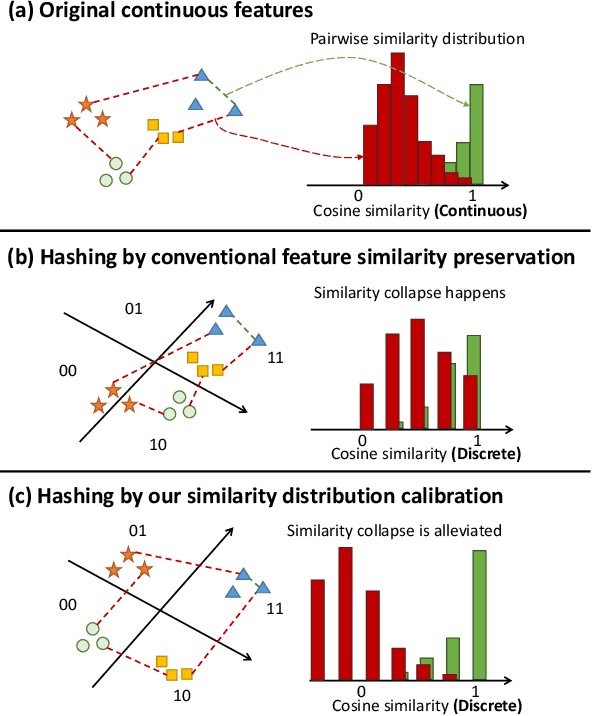
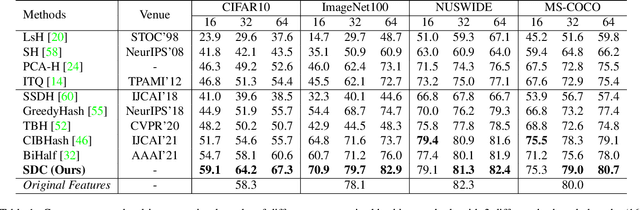
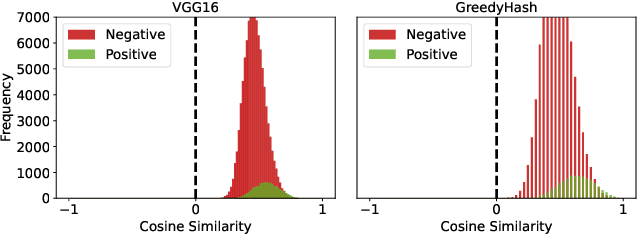

Existing unsupervised hashing methods typically adopt a feature similarity preservation paradigm. As a result, they overlook the intrinsic similarity capacity discrepancy between the continuous feature and discrete hash code spaces. Specifically, since the feature similarity distribution is intrinsically biased (e.g., moderately positive similarity scores on negative pairs), the hash code similarities of positive and negative pairs often become inseparable (i.e., the similarity collapse problem). To solve this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. Instead of matching individual pairwise similarity scores, SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity capacity/range, to alleviate the similarity collapse problem. Extensive experiments show that our SDC outperforms the state-of-the-art alternatives on both coarse category-level and instance-level image retrieval tasks, often by a large margin. Code is available at https://github.com/kamwoh/sdc.
ISS: Image as Stepping Stone for Text-Guided 3D Shape Generation
Sep 22, 2022

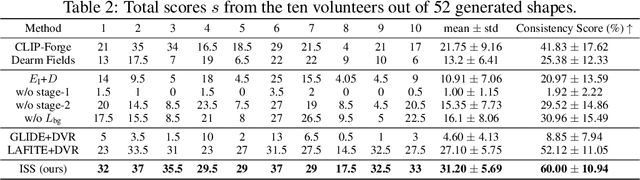

Text-guided 3D shape generation remains challenging due to the absence of large paired text-shape data, the substantial semantic gap between these two modalities, and the structural complexity of 3D shapes. This paper presents a new framework called Image as Stepping Stone (ISS) for the task by introducing 2D image as a stepping stone to connect the two modalities and to eliminate the need for paired text-shape data. Our key contribution is a two-stage feature-space-alignment approach that maps CLIP features to shapes by harnessing a pre-trained single-view reconstruction (SVR) model with multi-view supervisions: first map the CLIP image feature to the detail-rich shape space in the SVR model, then map the CLIP text feature to the shape space and optimize the mapping by encouraging CLIP consistency between the input text and the rendered images. Further, we formulate a text-guided shape stylization module to dress up the output shapes with novel textures. Beyond existing works on 3D shape generation from text, our new approach is general for creating shapes in a broad range of categories, without requiring paired text-shape data. Experimental results manifest that our approach outperforms the state-of-the-arts and our baselines in terms of fidelity and consistency with text. Further, our approach can stylize the generated shapes with both realistic and fantasy structures and textures.
Image Amodal Completion: A Survey
Jul 05, 2022
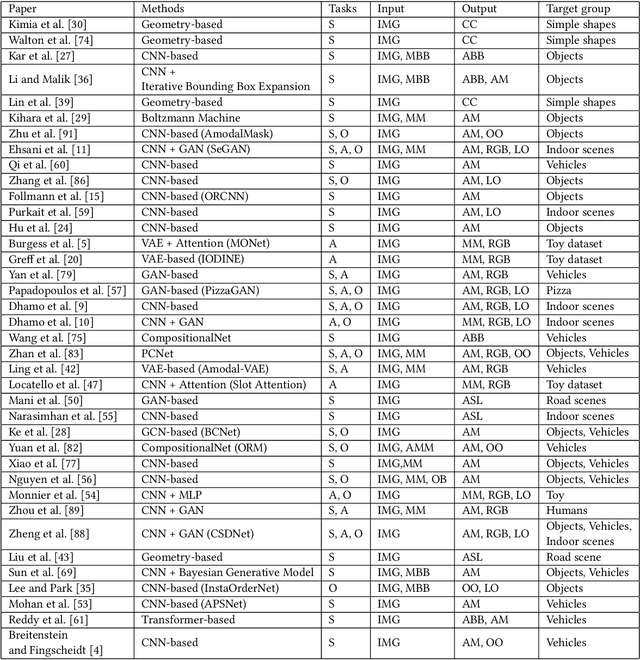
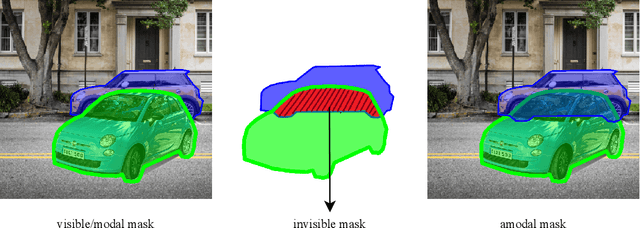
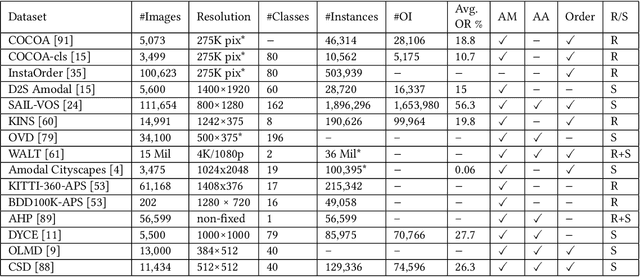
Existing computer vision systems can compete with humans in understanding the visible parts of objects, but still fall far short of humans when it comes to depicting the invisible parts of partially occluded objects. Image amodal completion aims to equip computers with human-like amodal completion functions to understand an intact object despite it being partially occluded. The main purpose of this survey is to provide an intuitive understanding of the research hotspots, key technologies and future trends in the field of image amodal completion. Firstly, we present a comprehensive review of the latest literature in this emerging field, exploring three key tasks in image amodal completion, including amodal shape completion, amodal appearance completion, and order perception. Then we examine popular datasets related to image amodal completion along with their common data collection methods and evaluation metrics. Finally, we discuss real-world applications and future research directions for image amodal completion, facilitating the reader's understanding of the challenges of existing technologies and upcoming research trends.
Face Attribute Editing with Disentangled Latent Vectors
Jan 11, 2023
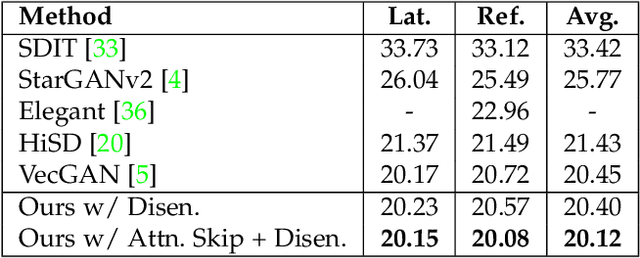
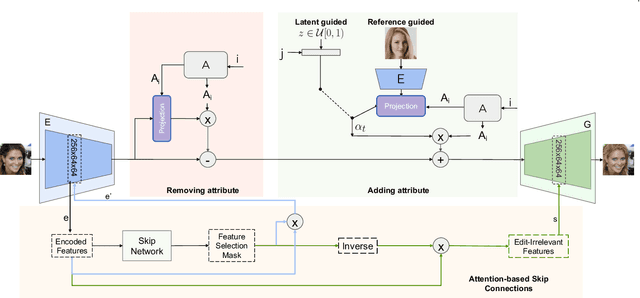
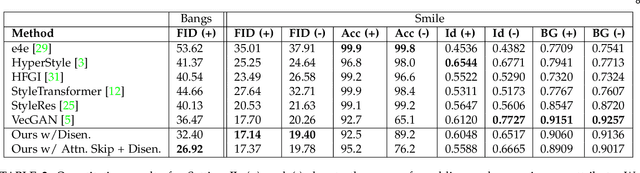
We propose an image-to-image translation framework for facial attribute editing with disentangled interpretable latent directions. Facial attribute editing task faces the challenges of targeted attribute editing with controllable strength and disentanglement in the representations of attributes to preserve the other attributes during edits. For this goal, inspired by the latent space factorization works of fixed pretrained GANs, we design the attribute editing by latent space factorization, and for each attribute, we learn a linear direction that is orthogonal to the others. We train these directions with orthogonality constraints and disentanglement losses. To project images to semantically organized latent spaces, we set an encoder-decoder architecture with attention-based skip connections. We extensively compare with previous image translation algorithms and editing with pretrained GAN works. Our extensive experiments show that our method significantly improves over the state-of-the-arts. Project page: https://yusufdalva.github.io/vecgan