 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic Image Synthesis via Diffusion Models
Jun 30, 2022
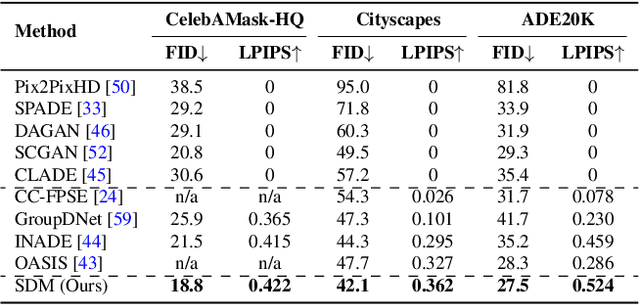
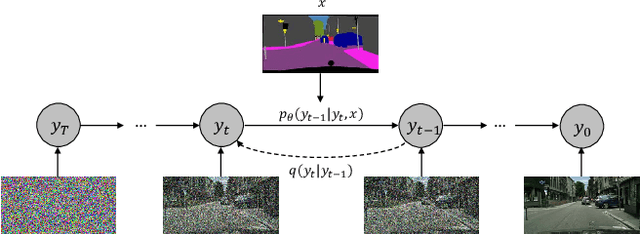
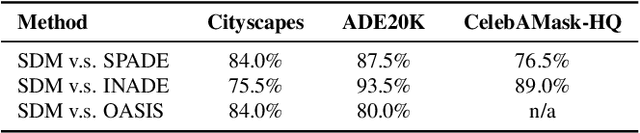
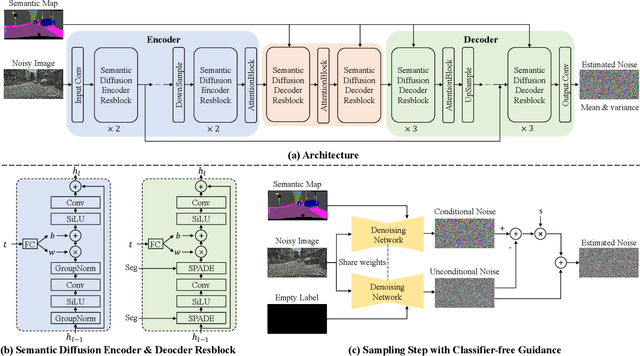
Denoising Diffusion Probabilistic Models (DDPMs) have achieved remarkable success in various image generation tasks compared with Generative Adversarial Nets (GANs). Recent work on semantic image synthesis mainly follows the \emph{de facto} GAN-based approaches, which may lead to unsatisfactory quality or diversity of generated images. In this paper, we propose a novel framework based on DDPM for semantic image synthesis. Unlike previous conditional diffusion model directly feeds the semantic layout and noisy image as input to a U-Net structure, which may not fully leverage the information in the input semantic mask, our framework processes semantic layout and noisy image differently. It feeds noisy image to the encoder of the U-Net structure while the semantic layout to the decoder by multi-layer spatially-adaptive normalization operators. To further improve the generation quality and semantic interpretability in semantic image synthesis, we introduce the classifier-free guidance sampling strategy, which acknowledge the scores of an unconditional model for sampling process. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our proposed method, achieving state-of-the-art performance in terms of fidelity~(FID) and diversity~(LPIPS).
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models
Oct 26, 2022
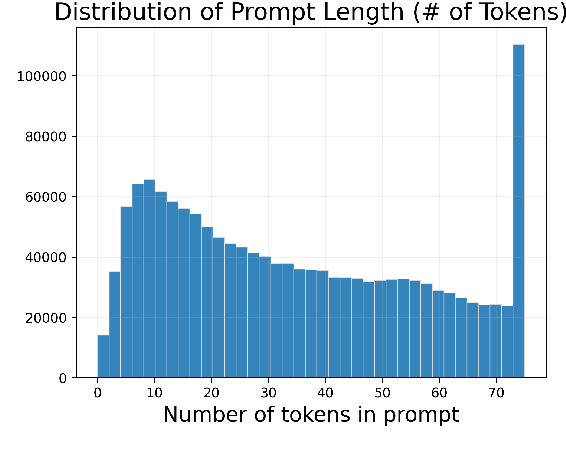
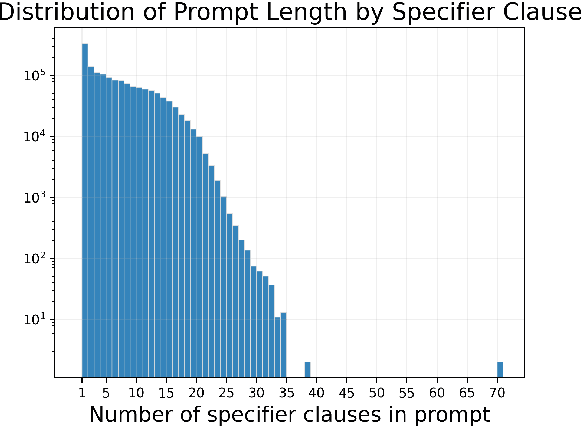
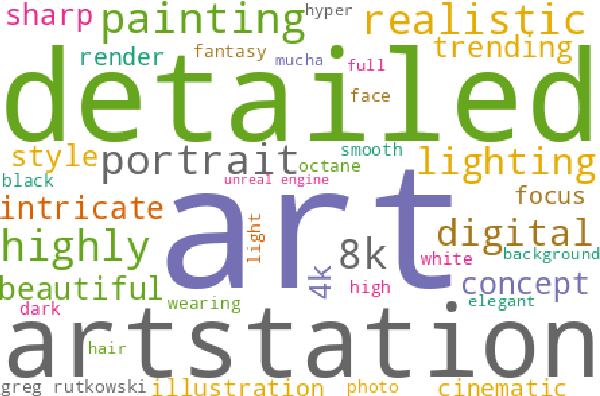
With recent advancements in diffusion models, users can generate high-quality images by writing text prompts in natural language. However, generating images with desired details requires proper prompts, and it is often unclear how a model reacts to different prompts and what the best prompts are. To help researchers tackle these critical challenges, we introduce DiffusionDB, the first large-scale text-to-image prompt dataset. DiffusionDB contains 2 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users. We analyze prompts in the dataset and discuss key properties of these prompts. The unprecedented scale and diversity of this human-actuated dataset provide exciting research opportunities in understanding the interplay between prompts and generative models, detecting deepfakes, and designing human-AI interaction tools to help users more easily use these models. DiffusionDB is publicly available at: https://poloclub.github.io/diffusiondb.
Learned Lossless Image Compression With Combined Autoregressive Models And Attention Modules
Aug 30, 2022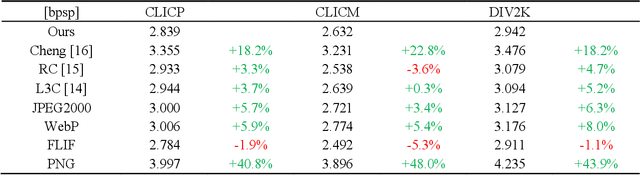
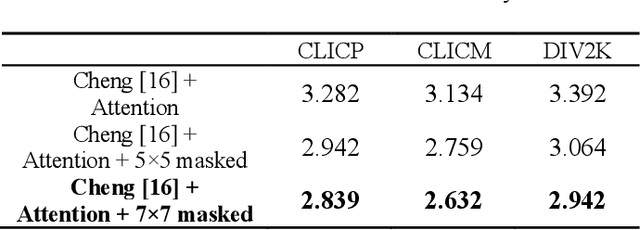

Lossless image compression is an essential research field in image compression. Recently, learning-based image compression methods achieved impressive performance compared with traditional lossless methods, such as WebP, JPEG2000, and FLIF. However, there are still many impressive lossy compression methods that can be applied to lossless compression. Therefore, in this paper, we explore the methods widely used in lossy compression and apply them to lossless compression. Inspired by the impressive performance of the Gaussian mixture model (GMM) shown in lossy compression, we generate a lossless network architecture with GMM. Besides noticing the successful achievements of attention modules and autoregressive models, we propose to utilize attention modules and add an extra autoregressive model for raw images in our network architecture to boost the performance. Experimental results show that our approach outperforms most classical lossless compression methods and existing learning-based methods.
Unsupervised Cardiac Segmentation Utilizing Synthesized Images from Anatomical Labels
Jan 15, 2023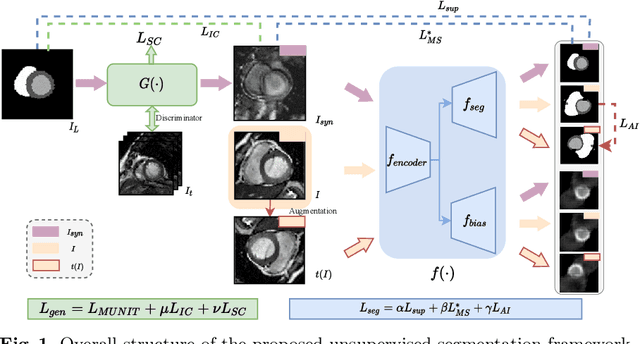
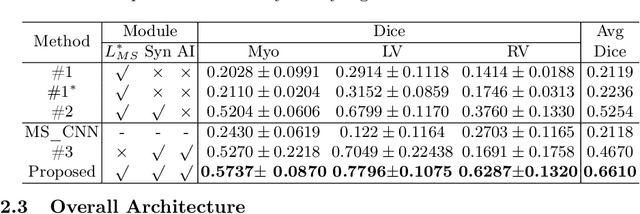


Cardiac segmentation is in great demand for clinical practice. Due to the enormous labor of manual delineation, unsupervised segmentation is desired. The ill-posed optimization problem of this task is inherently challenging, requiring well-designed constraints. In this work, we propose an unsupervised framework for multi-class segmentation with both intensity and shape constraints. Firstly, we extend a conventional non-convex energy function as an intensity constraint and implement it with U-Net. For shape constraint, synthetic images are generated from anatomical labels via image-to-image translation, as shape supervision for the segmentation network. Moreover, augmentation invariance is applied to facilitate the segmentation network to learn the latent features in terms of shape. We evaluated the proposed framework using the public datasets from MICCAI2019 MSCMR Challenge and achieved promising results on cardiac MRIs with Dice scores of 0.5737, 0.7796, and 0.6287 in Myo, LV, and RV, respectively.
Image-Specific Information Suppression and Implicit Local Alignment for Text-based Person Search
Aug 30, 2022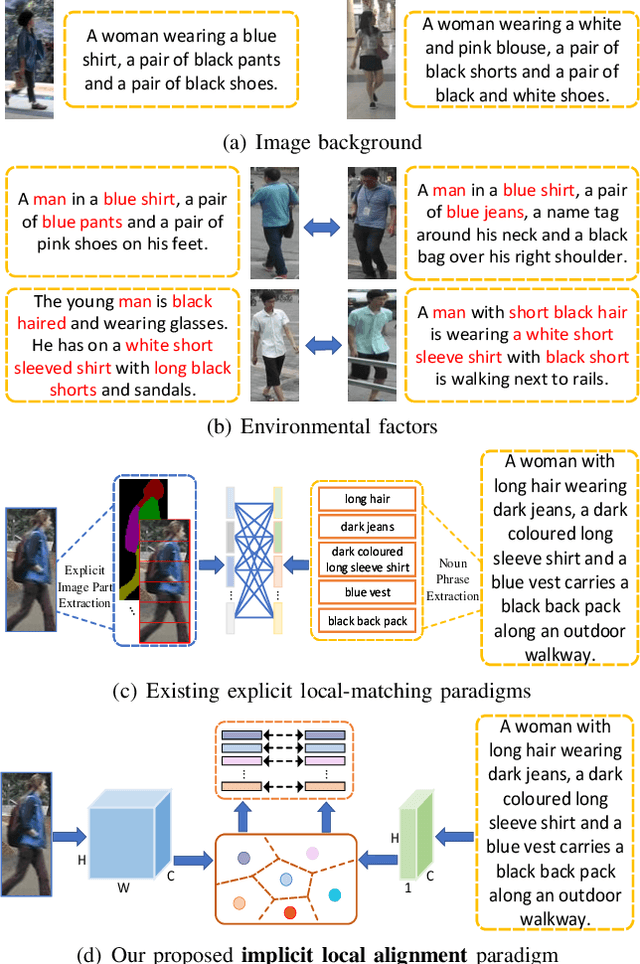
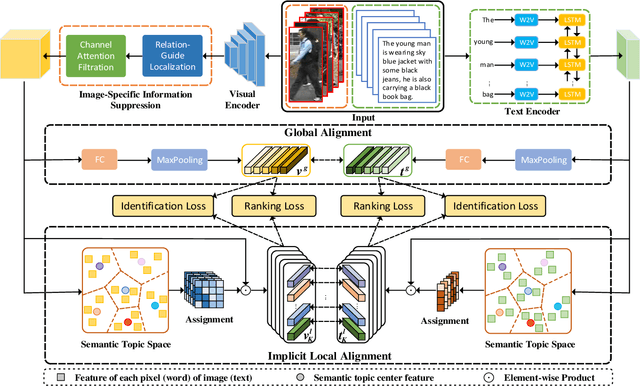
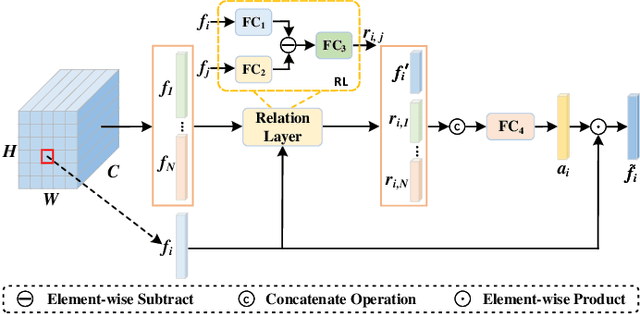
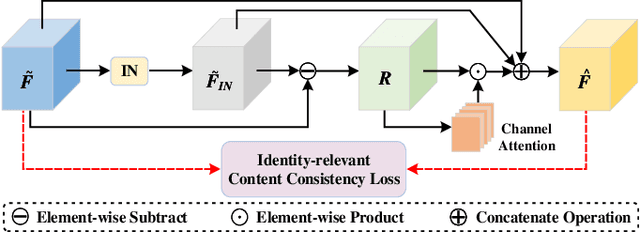
Text-based person search is a challenging task that aims to search pedestrian images with the same identity from the image gallery given a query text description. In recent years, text-based person search has made good progress, and state-of-the-art methods achieve superior performance by learning local fine-grained correspondence between images and texts. However, the existing methods explicitly extract image parts and text phrases from images and texts by hand-crafted split or external tools and then conduct complex cross-modal local matching. Moreover, the existing methods seldom consider the problem of information inequality between modalities caused by image-specific information. In this paper, we propose an efficient joint Information and Semantic Alignment Network (ISANet) for text-based person search. Specifically, we first design an image-specific information suppression module, which suppresses image background and environmental factors by relation-guide localization and channel attention filtration respectively. This design can effectively alleviate the problem of information inequality and realize the information alignment between images and texts. Secondly, we propose an implicit local alignment module to adaptively aggregate image and text features to a set of modality-shared semantic topic centers, and implicitly learn the local fine-grained correspondence between images and texts without additional supervision information and complex cross-modal interactions. Moreover, a global alignment is introduced as a supplement to the local perspective. Extensive experiments on multiple databases demonstrate the effectiveness and superiority of the proposed ISANet.
Image sensing with multilayer, nonlinear optical neural networks
Jul 27, 2022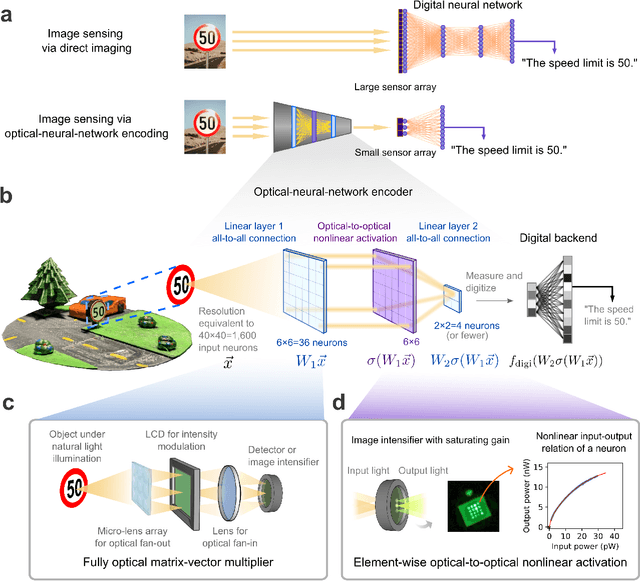
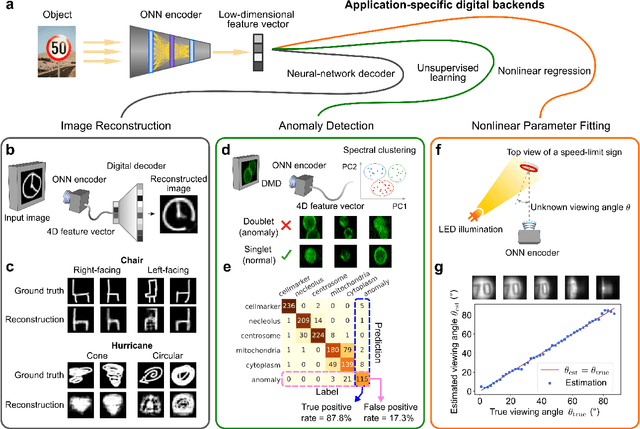
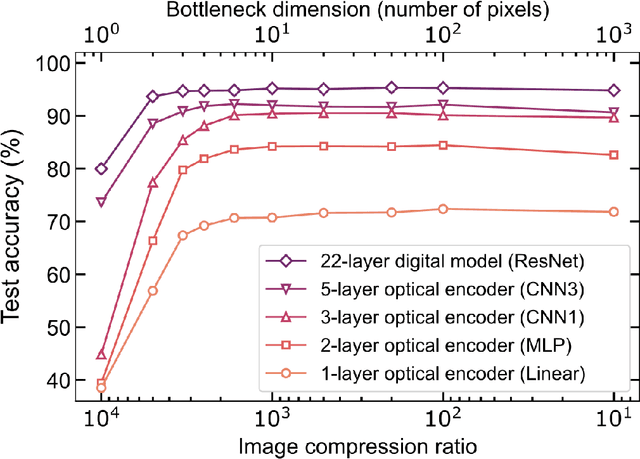

Optical imaging is commonly used for both scientific and technological applications across industry and academia. In image sensing, a measurement, such as of an object's position, is performed by computational analysis of a digitized image. An emerging image-sensing paradigm breaks this delineation between data collection and analysis by designing optical components to perform not imaging, but encoding. By optically encoding images into a compressed, low-dimensional latent space suitable for efficient post-analysis, these image sensors can operate with fewer pixels and fewer photons, allowing higher-throughput, lower-latency operation. Optical neural networks (ONNs) offer a platform for processing data in the analog, optical domain. ONN-based sensors have however been limited to linear processing, but nonlinearity is a prerequisite for depth, and multilayer NNs significantly outperform shallow NNs on many tasks. Here, we realize a multilayer ONN pre-processor for image sensing, using a commercial image intensifier as a parallel optoelectronic, optical-to-optical nonlinear activation function. We demonstrate that the nonlinear ONN pre-processor can achieve compression ratios of up to 800:1 while still enabling high accuracy across several representative computer-vision tasks, including machine-vision benchmarks, flow-cytometry image classification, and identification of objects in real scenes. In all cases we find that the ONN's nonlinearity and depth allowed it to outperform a purely linear ONN encoder. Although our experiments are specialized to ONN sensors for incoherent-light images, alternative ONN platforms should facilitate a range of ONN sensors. These ONN sensors may surpass conventional sensors by pre-processing optical information in spatial, temporal, and/or spectral dimensions, potentially with coherent and quantum qualities, all natively in the optical domain.
Multimodal Federated Learning via Contrastive Representation Ensemble
Feb 17, 2023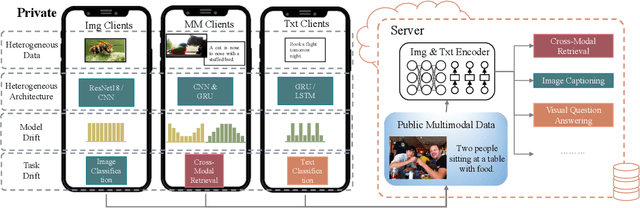
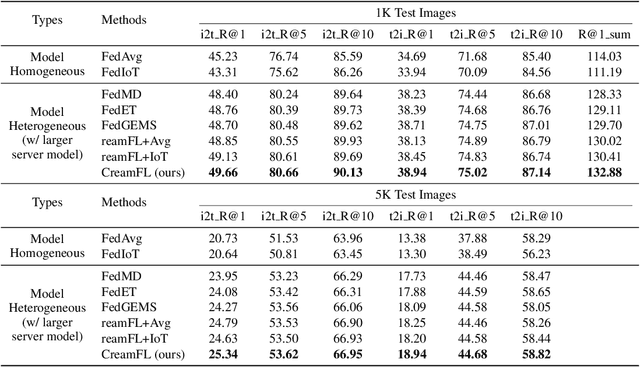
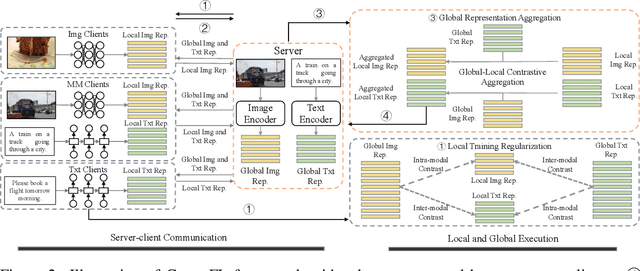
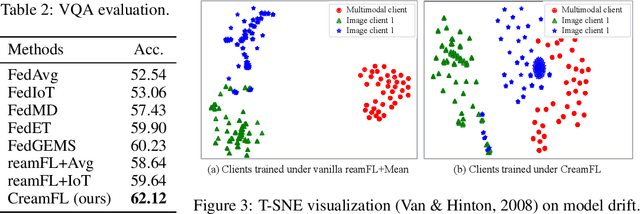
With the increasing amount of multimedia data on modern mobile systems and IoT infrastructures, harnessing these rich multimodal data without breaching user privacy becomes a critical issue. Federated learning (FL) serves as a privacy-conscious alternative to centralized machine learning. However, existing FL methods extended to multimodal data all rely on model aggregation on single modality level, which restrains the server and clients to have identical model architecture for each modality. This limits the global model in terms of both model complexity and data capacity, not to mention task diversity. In this work, we propose Contrastive Representation Ensemble and Aggregation for Multimodal FL (CreamFL), a multimodal federated learning framework that enables training larger server models from clients with heterogeneous model architectures and data modalities, while only communicating knowledge on public dataset. To achieve better multimodal representation fusion, we design a global-local cross-modal ensemble strategy to aggregate client representations. To mitigate local model drift caused by two unprecedented heterogeneous factors stemming from multimodal discrepancy (modality gap and task gap), we further propose two inter-modal and intra-modal contrasts to regularize local training, which complements information of the absent modality for uni-modal clients and regularizes local clients to head towards global consensus. Thorough evaluations and ablation studies on image-text retrieval and visual question answering tasks showcase the superiority of CreamFL over state-of-the-art FL methods and its practical value.
Long Horizon Temperature Scaling
Feb 07, 2023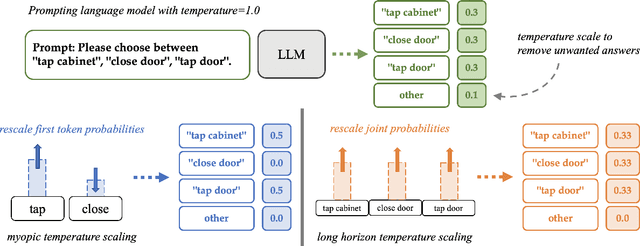
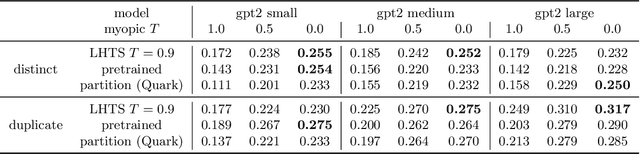

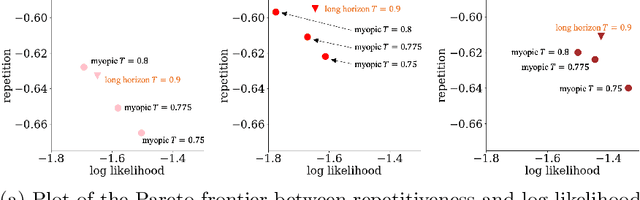
Temperature scaling is a popular technique for tuning the sharpness of a model distribution. It is used extensively for sampling likely generations and calibrating model uncertainty, and even features as a controllable parameter to many large language models in deployment. However, autoregressive models rely on myopic temperature scaling that greedily optimizes the next token. To address this, we propose Long Horizon Temperature Scaling (LHTS), a novel approach for sampling from temperature-scaled joint distributions. LHTS is compatible with all likelihood-based models, and optimizes for the long-horizon likelihood of samples. We derive a temperature-dependent LHTS objective, and show that fine-tuning a model on a range of temperatures produces a single model capable of generation with a controllable long-horizon temperature parameter. We experiment with LHTS on image diffusion models and character/language autoregressive models, demonstrating advantages over myopic temperature scaling in likelihood and sample quality, and showing improvements in accuracy on a multiple choice analogy task by $10\%$.
A Deep Learning-based in silico Framework for Optimization on Retinal Prosthetic Stimulation
Feb 07, 2023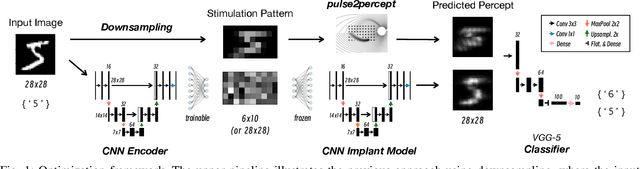

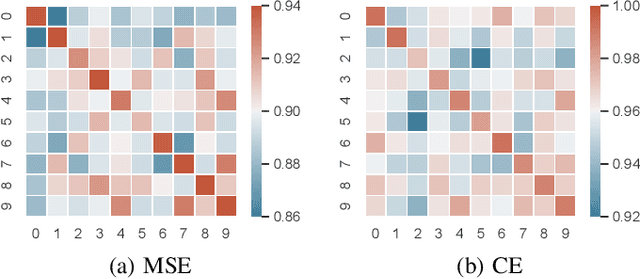
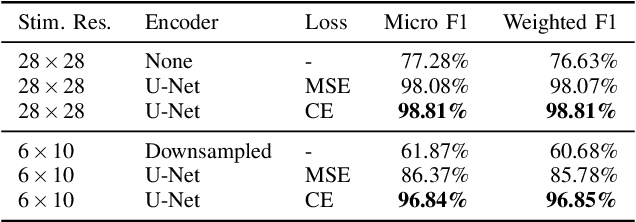
We propose a neural network-based framework to optimize the perceptions simulated by the in silico retinal implant model pulse2percept. The overall pipeline consists of a trainable encoder, a pre-trained retinal implant model and a pre-trained evaluator. The encoder is a U-Net, which takes the original image and outputs the stimulus. The pre-trained retinal implant model is also a U-Net, which is trained to mimic the biomimetic perceptual model implemented in pulse2percept. The evaluator is a shallow VGG classifier, which is trained with original images. Based on 10,000 test images from the MNIST dataset, we show that the convolutional neural network-based encoder performs significantly better than the trivial downsampling approach, yielding a boost in the weighted F1-Score by 36.17% in the pre-trained classifier with 6x10 electrodes. With this fully neural network-based encoder, the quality of the downstream perceptions can be fine-tuned using gradient descent in an end-to-end fashion.
Deformation equivariant cross-modality image synthesis with paired non-aligned training data
Aug 26, 2022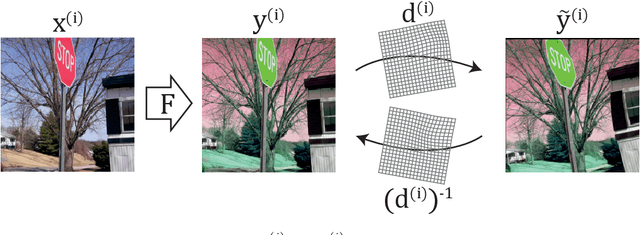
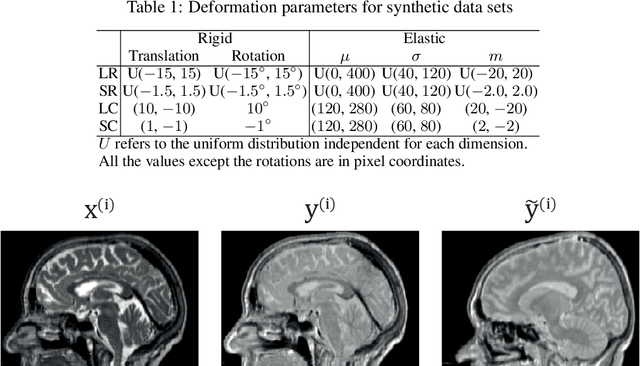
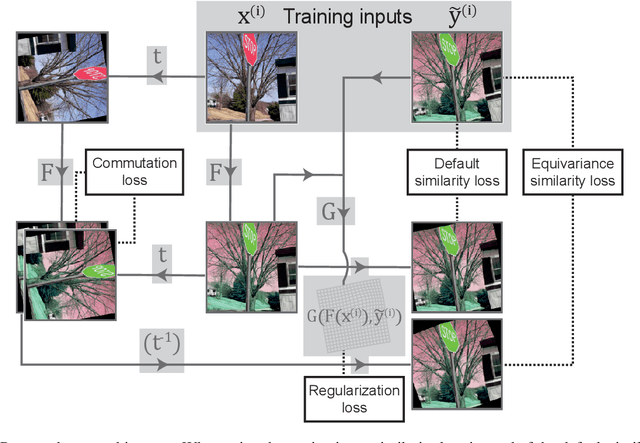
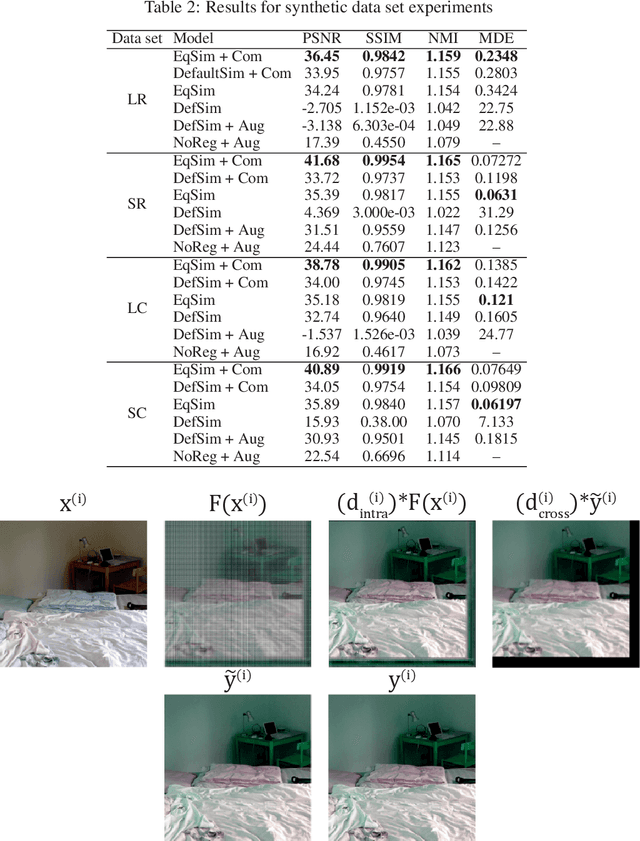
Cross-modality image synthesis is an active research topic with multiple medical clinically relevant applications. Recently, methods allowing training with paired but misaligned data have started to emerge. However, no robust and well-performing methods applicable to a wide range of real world data sets exist. In this work, we propose a generic solution to the problem of cross-modality image synthesis with paired but non-aligned data by introducing new deformation equivariance encouraging loss functions. The method consists of joint training of an image synthesis network together with separate registration networks and allows adversarial training conditioned on the input even with misaligned data. The work lowers the bar for new clinical applications by allowing effortless training of cross-modality image synthesis networks for more difficult data sets and opens up opportunities for the development of new generic learning based cross-modality registration algorithms.