 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deformation equivariant cross-modality image synthesis with paired non-aligned training data
Aug 26, 2022
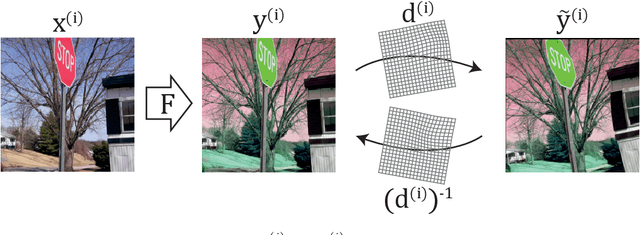
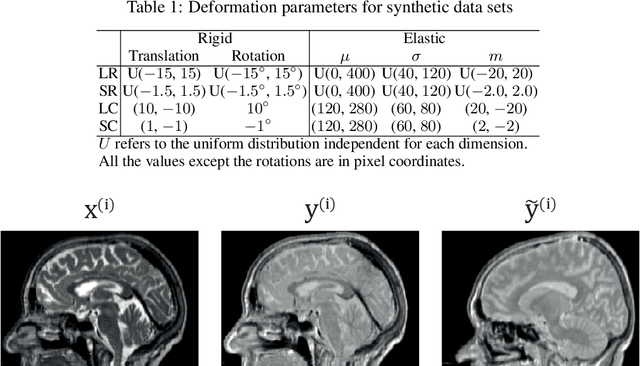
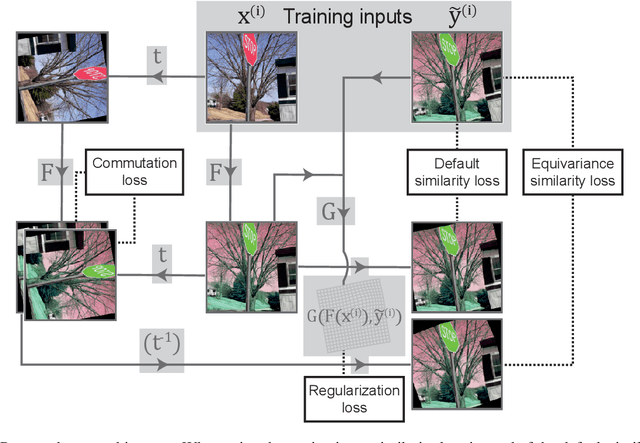
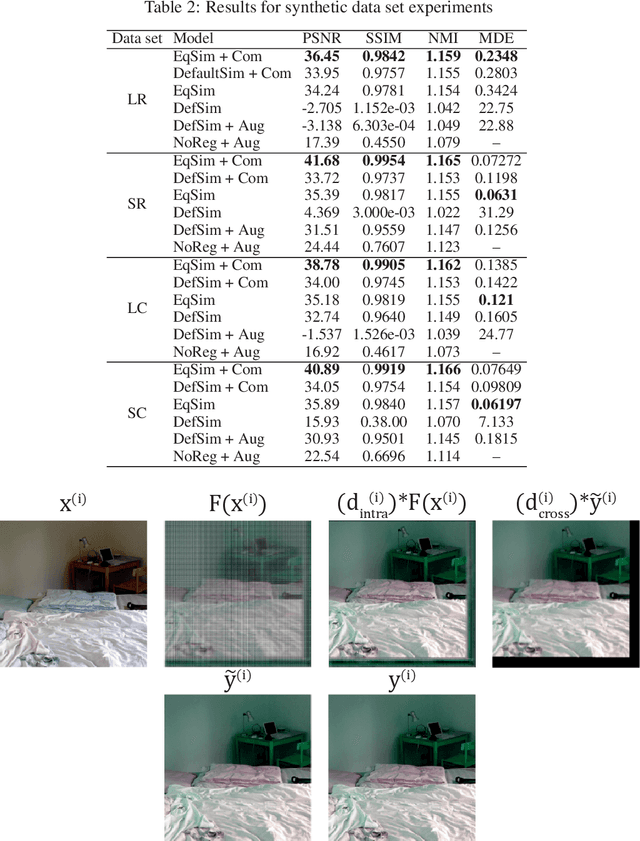
Cross-modality image synthesis is an active research topic with multiple medical clinically relevant applications. Recently, methods allowing training with paired but misaligned data have started to emerge. However, no robust and well-performing methods applicable to a wide range of real world data sets exist. In this work, we propose a generic solution to the problem of cross-modality image synthesis with paired but non-aligned data by introducing new deformation equivariance encouraging loss functions. The method consists of joint training of an image synthesis network together with separate registration networks and allows adversarial training conditioned on the input even with misaligned data. The work lowers the bar for new clinical applications by allowing effortless training of cross-modality image synthesis networks for more difficult data sets and opens up opportunities for the development of new generic learning based cross-modality registration algorithms.
Living Images: A Recursive Approach to Computing the Structural Beauty of Images or the Livingness of Space
Jan 04, 2023

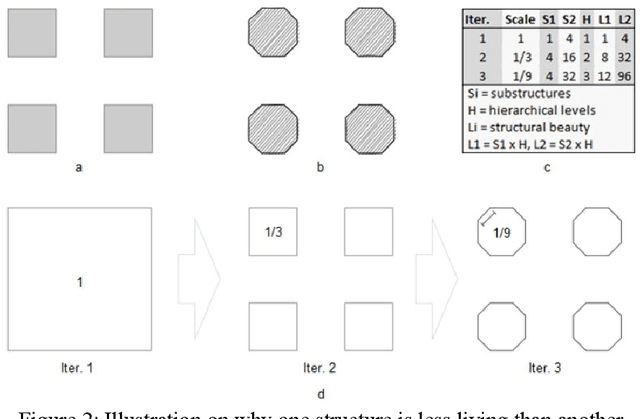
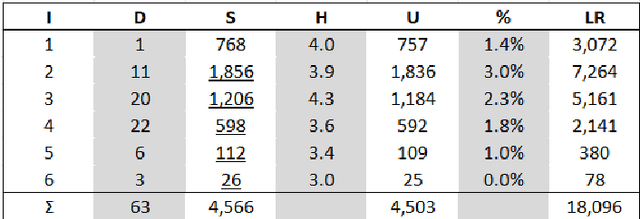
Any image is perceived subconsciously as a coherent structure (or whole) with two contrast substructures: figure and ground. The figure consists of numerous auto-generated substructures with an inherent hierarchy of far more smalls than larges. Through these substructures, the structural beauty of an image (L) can be computed by the multiplication of the number of substructures (S) and their inherent hierarchy (H). This definition implies that the more substructures, the more living or more structurally beautiful, and the higher hierarchy of the substructures, the more living or more structurally beautiful. This is the non-recursive approach to the structural beauty of images or the livingness of space. In this paper we develop a recursive approach, which derives all substructures of an image (instead of its figure) and continues the deriving process for those decomposable substructures until none of them are decomposable. All of the substructures derived at different iterations (or recursive levels) together constitute a living structure; hence the notion of living images. We applied the recursive approach to a set of images and found that (1) the number of substructures of an image is far lower (3 percent on average) than the number of pixels and the centroids of the substructures can effectively capture the skeleton or saliency of the image; (2) all the images have the recursive levels more than three, indicating that they are indeed living images; (3) no more than 2 percent of the substructures are decomposable; (4) structural beauty can be measured by the recursively defined substructures, as well as their decomposable subsets. The recursive approach is proved to be more robust than the non-recursive approach. The recursive approach and the non-recursive approach both provide a powerful means to study the livingness or vitality of space in cities and communities.
Class-Continuous Conditional Generative Neural Radiance Field
Jan 09, 2023

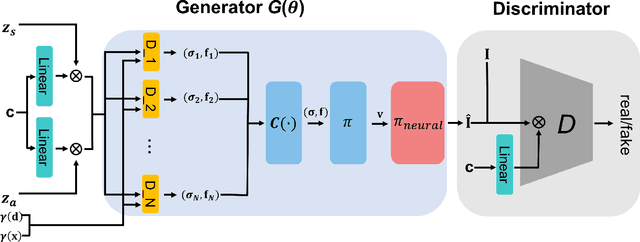
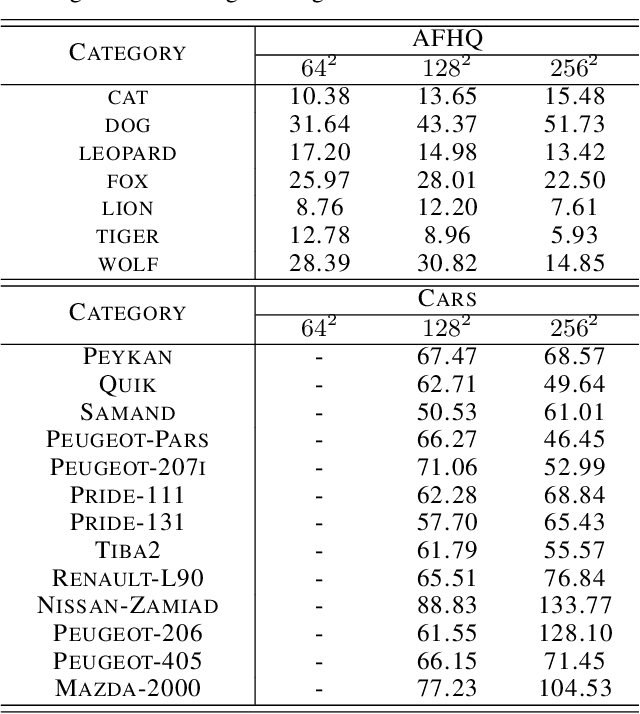
The 3D-aware image synthesis focuses on conserving spatial consistency besides generating high-resolution images with fine details. Recently, Neural Radiance Field (NeRF) has been introduced for synthesizing novel views with low computational cost and superior performance. While several works investigate a generative NeRF and show remarkable achievement, they cannot handle conditional and continuous feature manipulation in the generation procedure. In this work, we introduce a novel model, called Class-Continuous Conditional Generative NeRF ($\text{C}^{3}$G-NeRF), which can synthesize conditionally manipulated photorealistic 3D-consistent images by projecting conditional features to the generator and the discriminator. The proposed $\text{C}^{3}$G-NeRF is evaluated with three image datasets, AFHQ, CelebA, and Cars. As a result, our model shows strong 3D-consistency with fine details and smooth interpolation in conditional feature manipulation. For instance, $\text{C}^{3}$G-NeRF exhibits a Fr\'echet Inception Distance (FID) of 7.64 in 3D-aware face image synthesis with a $\text{128}^{2}$ resolution. Additionally, we provide FIDs of generated 3D-aware images of each class of the datasets as it is possible to synthesize class-conditional images with $\text{C}^{3}$G-NeRF.
Learning Customized Visual Models with Retrieval-Augmented Knowledge
Jan 17, 2023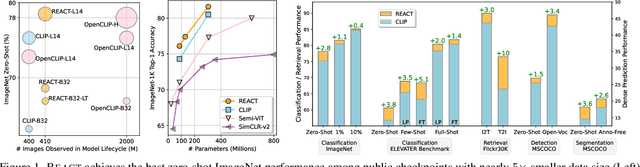
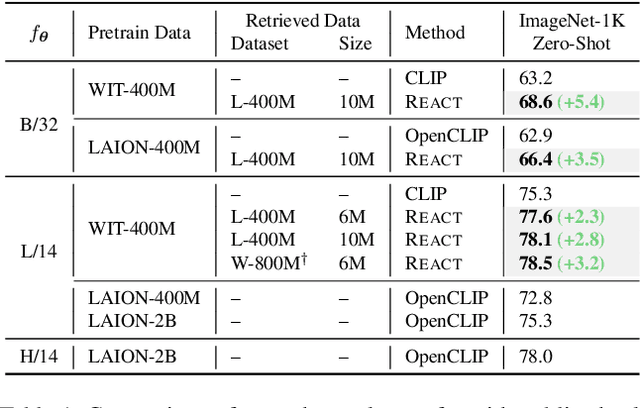
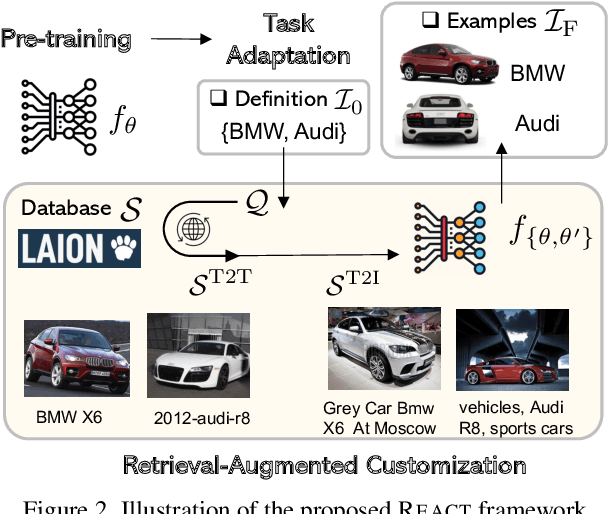
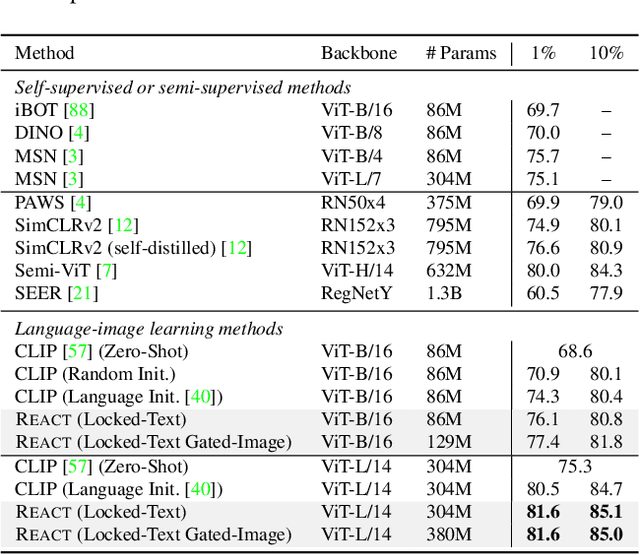
Image-text contrastive learning models such as CLIP have demonstrated strong task transfer ability. The high generality and usability of these visual models is achieved via a web-scale data collection process to ensure broad concept coverage, followed by expensive pre-training to feed all the knowledge into model weights. Alternatively, we propose REACT, REtrieval-Augmented CusTomization, a framework to acquire the relevant web knowledge to build customized visual models for target domains. We retrieve the most relevant image-text pairs (~3% of CLIP pre-training data) from the web-scale database as external knowledge, and propose to customize the model by only training new modualized blocks while freezing all the original weights. The effectiveness of REACT is demonstrated via extensive experiments on classification, retrieval, detection and segmentation tasks, including zero, few, and full-shot settings. Particularly, on the zero-shot classification task, compared with CLIP, it achieves up to 5.4% improvement on ImageNet and 3.7% on the ELEVATER benchmark (20 datasets).
Unsupervised ensemble-based phenotyping helps enhance the discoverability of genes related to heart morphology
Jan 07, 2023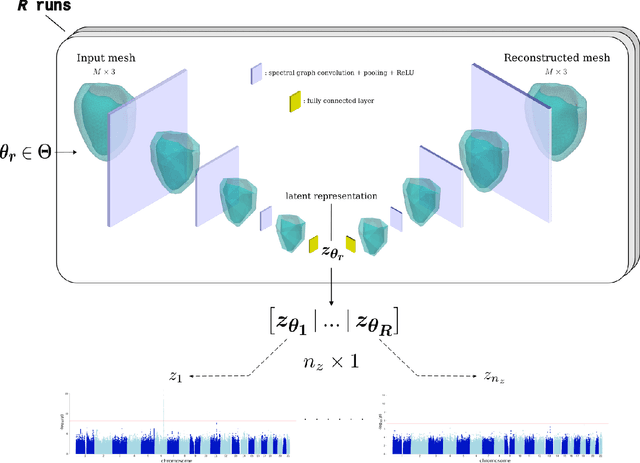
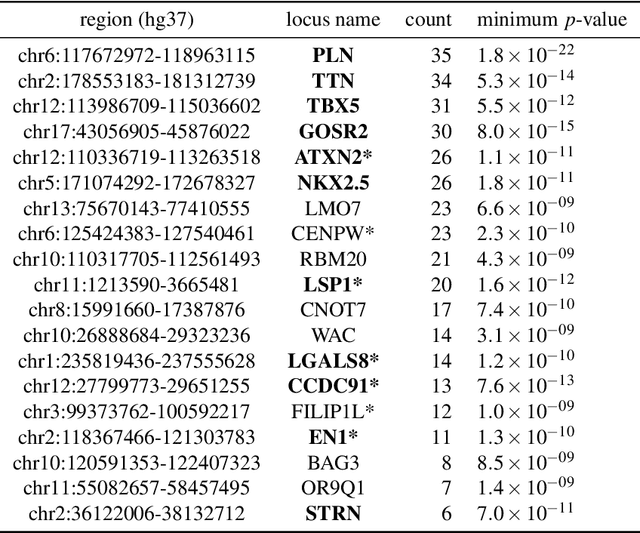
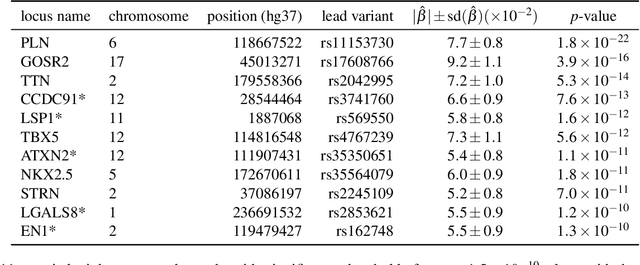
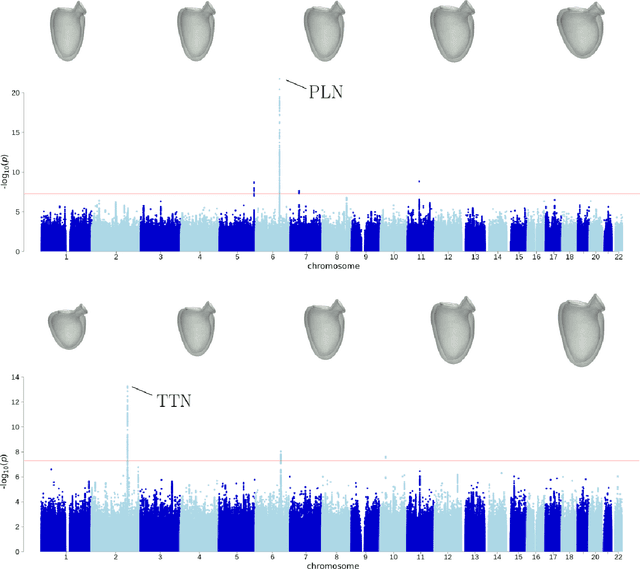
Recent genome-wide association studies (GWAS) have been successful in identifying associations between genetic variants and simple cardiac parameters derived from cardiac magnetic resonance (CMR) images. However, the emergence of big databases including genetic data linked to CMR, facilitates investigation of more nuanced patterns of shape variability. Here, we propose a new framework for gene discovery entitled Unsupervised Phenotype Ensembles (UPE). UPE builds a redundant yet highly expressive representation by pooling a set of phenotypes learned in an unsupervised manner, using deep learning models trained with different hyperparameters. These phenotypes are then analyzed via (GWAS), retaining only highly confident and stable associations across the ensemble. We apply our approach to the UK Biobank database to extract left-ventricular (LV) geometric features from image-derived three-dimensional meshes. We demonstrate that our approach greatly improves the discoverability of genes influencing LV shape, identifying 11 loci with study-wide significance and 8 with suggestive significance. We argue that our approach would enable more extensive discovery of gene associations with image-derived phenotypes for other organs or image modalities.
Spiking Synaptic Penalty: Appropriate Penalty Term for Energy-Efficient Spiking Neural Networks
Feb 03, 2023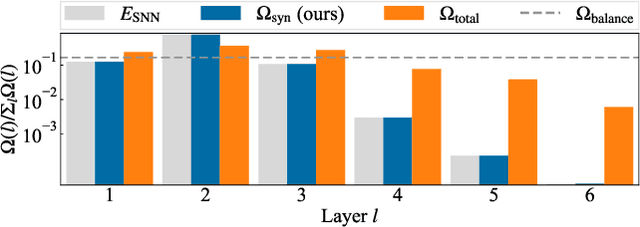

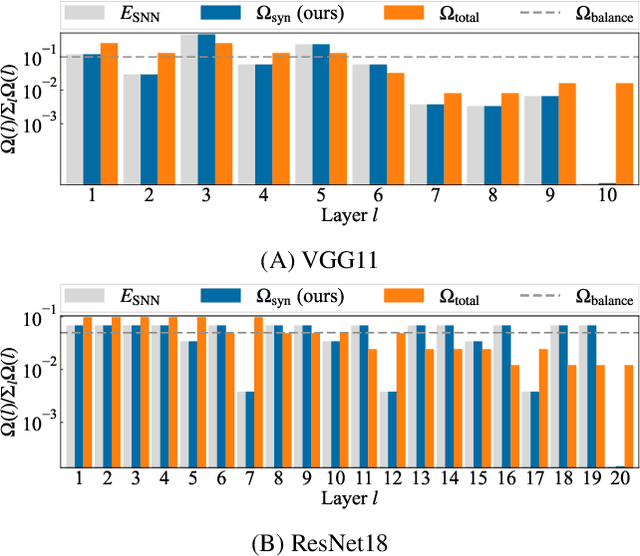
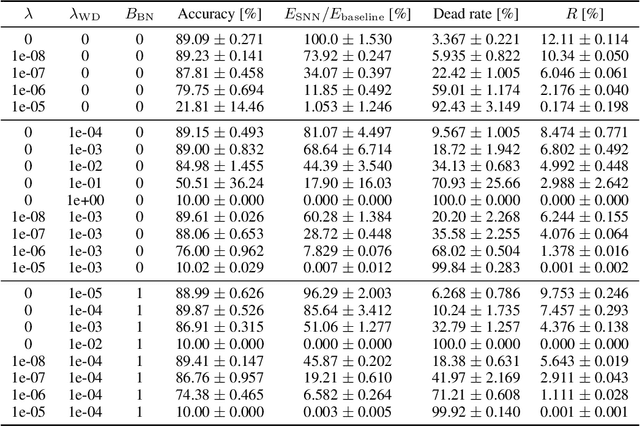
Spiking neural networks (SNNs) are energy-efficient neural networks because of their spiking nature. However, as the spike firing rate of SNNs increases, the energy consumption does as well, and thus, the advantage of SNNs diminishes. Here, we tackle this problem by introducing a novel penalty term for the spiking activity into the objective function in the training phase. Our method is designed so as to optimize the energy consumption metric directly without modifying the network architecture. Therefore, the proposed method can reduce the energy consumption more than other methods while maintaining the accuracy. We conducted experiments for image classification tasks, and the results indicate the effectiveness of the proposed method, which mitigates the dilemma of the energy--accuracy trade-off.
Information-Theoretic Diffusion
Feb 07, 2023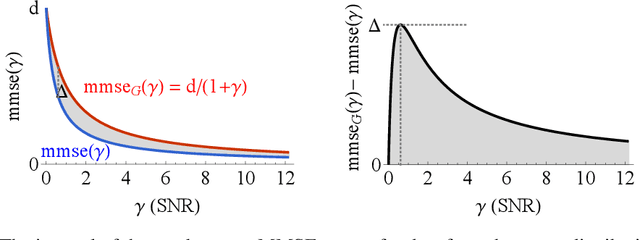
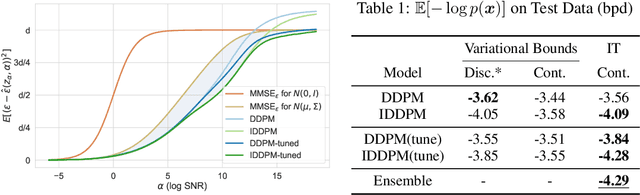
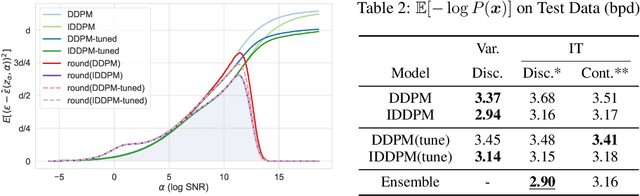
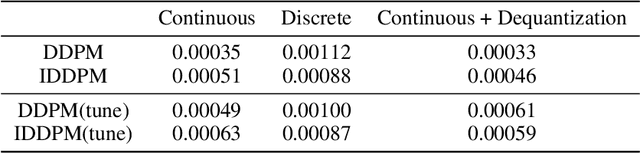
Denoising diffusion models have spurred significant gains in density modeling and image generation, precipitating an industrial revolution in text-guided AI art generation. We introduce a new mathematical foundation for diffusion models inspired by classic results in information theory that connect Information with Minimum Mean Square Error regression, the so-called I-MMSE relations. We generalize the I-MMSE relations to exactly relate the data distribution to an optimal denoising regression problem, leading to an elegant refinement of existing diffusion bounds. This new insight leads to several improvements for probability distribution estimation, including theoretical justification for diffusion model ensembling. Remarkably, our framework shows how continuous and discrete probabilities can be learned with the same regression objective, avoiding domain-specific generative models used in variational methods. Code to reproduce experiments is provided at http://github.com/kxh001/ITdiffusion and simplified demonstration code is at http://github.com/gregversteeg/InfoDiffusionSimple.
A Synthetic Hyperspectral Array Video Database with Applications to Cross-Spectral Reconstruction and Hyperspectral Video Coding
Jan 19, 2023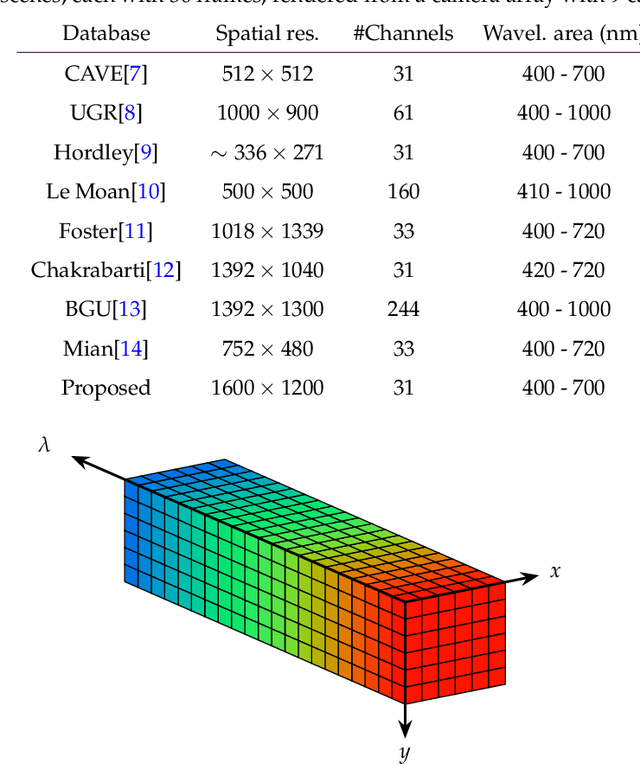

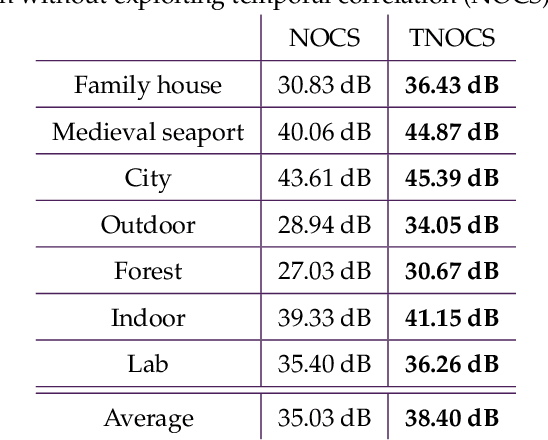
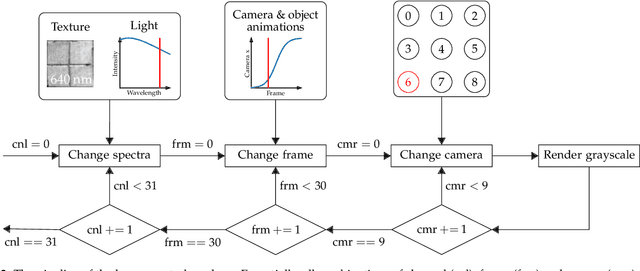
In this paper, a synthetic hyperspectral video database is introduced. Since it is impossible to record ground truth hyperspectral videos, this database offers the possibility to leverage the evaluation of algorithms in diverse applications. For all scenes, depth maps are provided as well to yield the position of a pixel in all spatial dimensions as well as the reflectance in spectral dimension. Two novel algorithms for two different applications are proposed to prove the diversity of applications that can be addressed by this novel database. First, a cross-spectral image reconstruction algorithm is extended to exploit the temporal correlation between two consecutive frames. The evaluation using this hyperspectral database shows an increase in PSNR of up to 5.6 dB dependent on the scene. Second, a hyperspectral video coder is introduced which extends an existing hyperspectral image coder by exploiting temporal correlation. The evaluation shows rate savings of up to 10% depending on the scene. The novel hyperspectral video database and source code is available at https:// github.com/ FAU-LMS/ HyViD for use by the research community.
Multiview Compressive Coding for 3D Reconstruction
Jan 19, 2023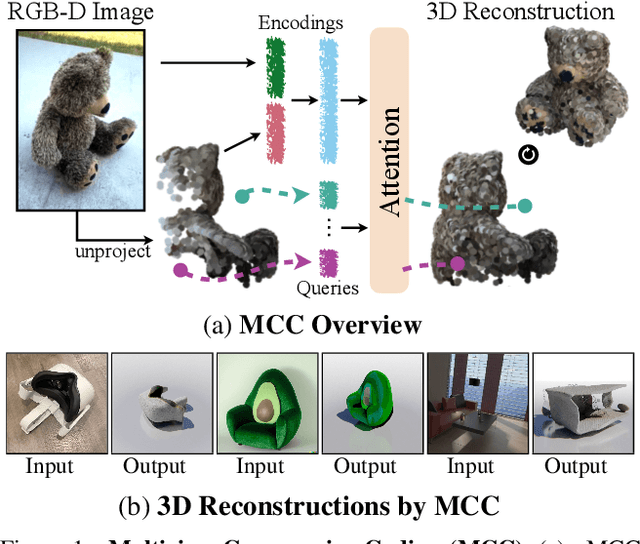
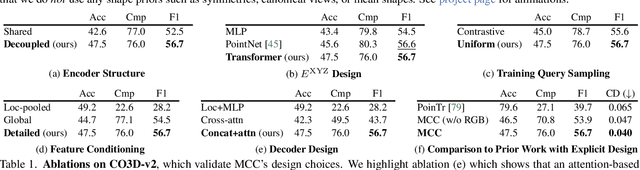
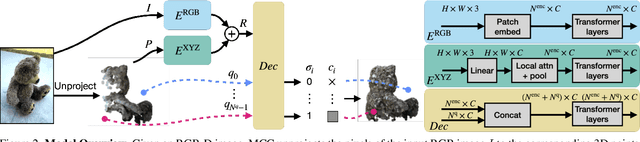
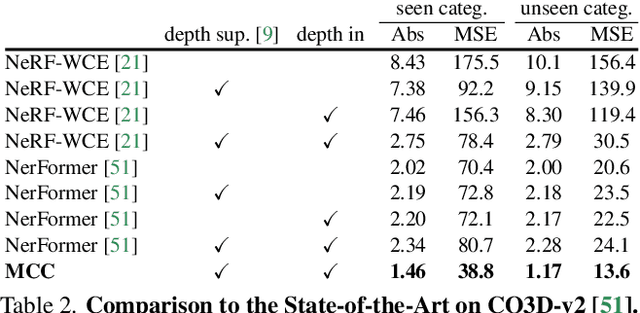
A central goal of visual recognition is to understand objects and scenes from a single image. 2D recognition has witnessed tremendous progress thanks to large-scale learning and general-purpose representations. Comparatively, 3D poses new challenges stemming from occlusions not depicted in the image. Prior works try to overcome these by inferring from multiple views or rely on scarce CAD models and category-specific priors which hinder scaling to novel settings. In this work, we explore single-view 3D reconstruction by learning generalizable representations inspired by advances in self-supervised learning. We introduce a simple framework that operates on 3D points of single objects or whole scenes coupled with category-agnostic large-scale training from diverse RGB-D videos. Our model, Multiview Compressive Coding (MCC), learns to compress the input appearance and geometry to predict the 3D structure by querying a 3D-aware decoder. MCC's generality and efficiency allow it to learn from large-scale and diverse data sources with strong generalization to novel objects imagined by DALL$\cdot$E 2 or captured in-the-wild with an iPhone.
RecRecNet: Rectangling Rectified Wide-Angle Images by Thin-Plate Spline Model and DoF-based Curriculum Learning
Jan 04, 2023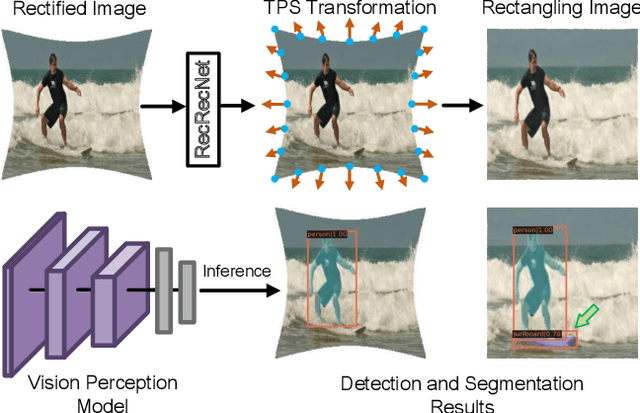
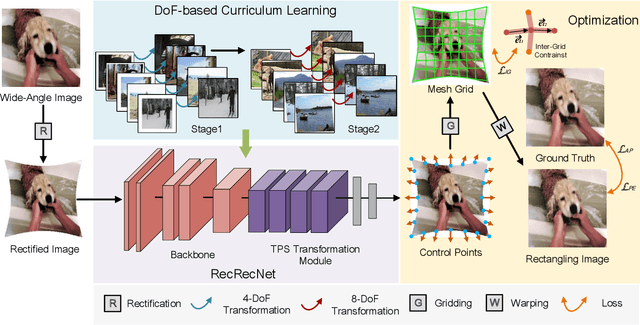


The wide-angle lens shows appealing applications in VR technologies, but it introduces severe radial distortion into its captured image. To recover the realistic scene, previous works devote to rectifying the content of the wide-angle image. However, such a rectification solution inevitably distorts the image boundary, which potentially changes related geometric distributions and misleads the current vision perception models. In this work, we explore constructing a win-win representation on both content and boundary by contributing a new learning model, i.e., Rectangling Rectification Network (RecRecNet). In particular, we propose a thin-plate spline (TPS) module to formulate the non-linear and non-rigid transformation for rectangling images. By learning the control points on the rectified image, our model can flexibly warp the source structure to the target domain and achieves an end-to-end unsupervised deformation. To relieve the complexity of structure approximation, we then inspire our RecRecNet to learn the gradual deformation rules with a DoF (Degree of Freedom)-based curriculum learning. By increasing the DoF in each curriculum stage, namely, from similarity transformation (4-DoF) to homography transformation (8-DoF), the network is capable of investigating more detailed deformations, offering fast convergence on the final rectangling task. Experiments show the superiority of our solution over the compared methods on both quantitative and qualitative evaluations. The code and dataset will be made available.