 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leaving Reality to Imagination: Robust Classification via Generated Datasets
Feb 05, 2023
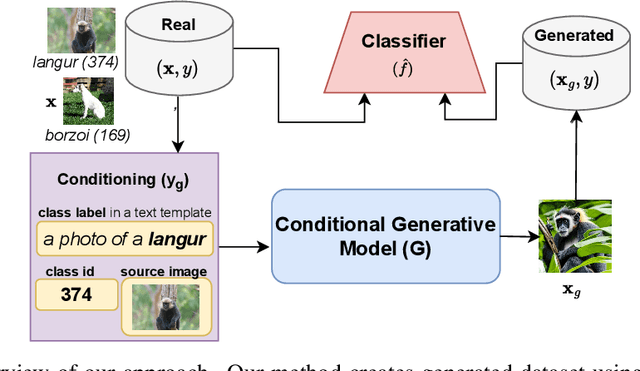

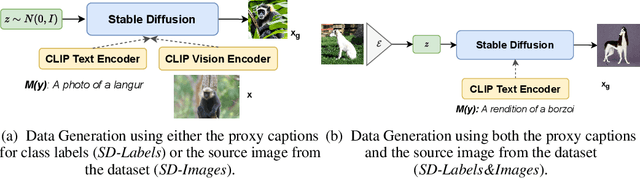

Recent research on robustness has revealed significant performance gaps between neural image classifiers trained on datasets that are similar to the test set, and those that are from a naturally shifted distribution, such as sketches, paintings, and animations of the object categories observed during training. Prior work focuses on reducing this gap by designing engineered augmentations of training data or through unsupervised pretraining of a single large model on massive in-the-wild training datasets scraped from the Internet. However, the notion of a dataset is also undergoing a paradigm shift in recent years. With drastic improvements in the quality, ease-of-use, and access to modern generative models, generated data is pervading the web. In this light, we study the question: How do these generated datasets influence the natural robustness of image classifiers? We find that Imagenet classifiers trained on real data augmented with generated data achieve higher accuracy and effective robustness than standard training and popular augmentation strategies in the presence of natural distribution shifts. We analyze various factors influencing these results, including the choice of conditioning strategies and the amount of generated data. Lastly, we introduce and analyze an evolving generated dataset, ImageNet-G-v1, to better benchmark the design, utility, and critique of standalone generated datasets for robust and trustworthy machine learning. The code and datasets are available at https://github.com/Hritikbansal/generative-robustness.
Spatial Moment Pooling Improves Neural Image Assessment
Sep 29, 2022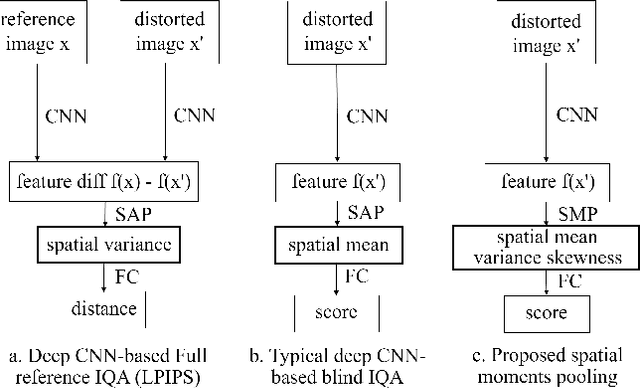
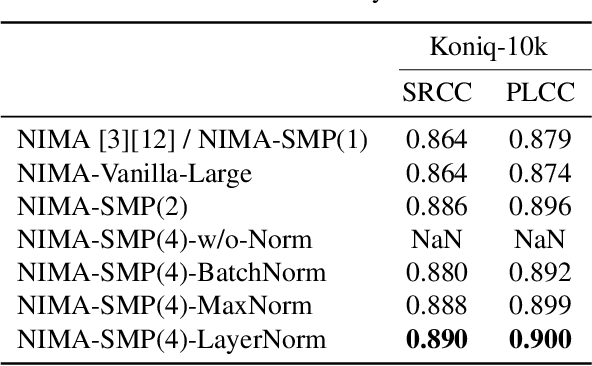
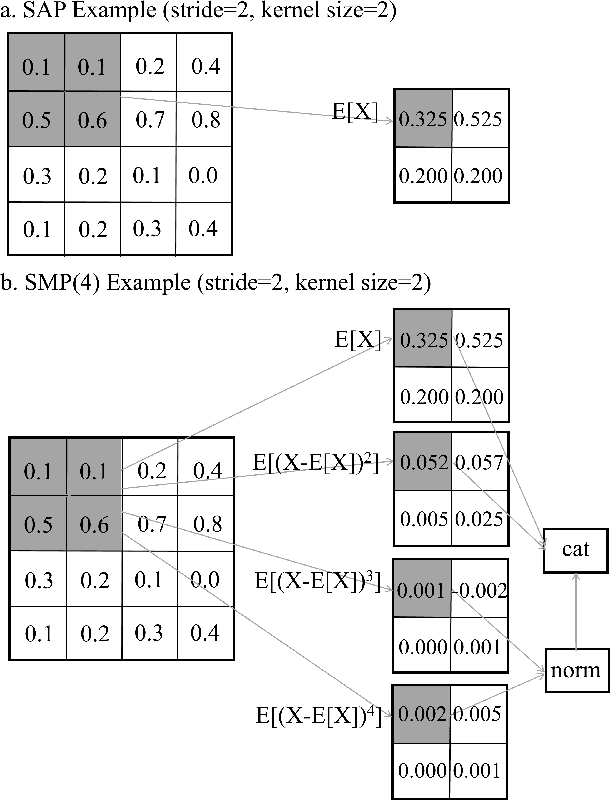
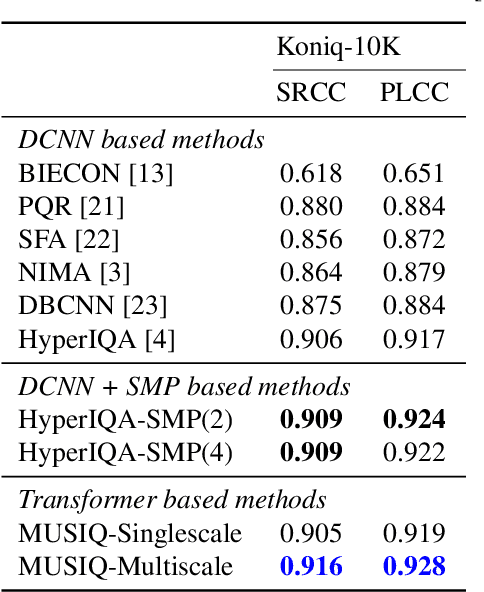
In recent years, there has been widespread attention drawn to convolutional neural network (CNN) based blind image quality assessment (IQA). A large number of works start by extracting deep features from CNN. Then, those features are processed through spatial average pooling (SAP) and fully connected layers to predict quality. Inspired by full reference IQA and texture features, in this paper, we extend SAP ($1^{st}$ moment) into spatial moment pooling (SMP) by incorporating higher order moments (such as variance, skewness). Moreover, we provide learning friendly normalization to circumvent numerical issue when computing gradients of higher moments. Experimental results suggest that simply upgrading SAP to SMP significantly enhances CNN-based blind IQA methods and achieves state of the art performance.
Deep Dependency Networks for Multi-Label Classification
Feb 01, 2023
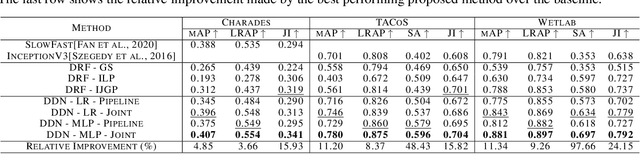
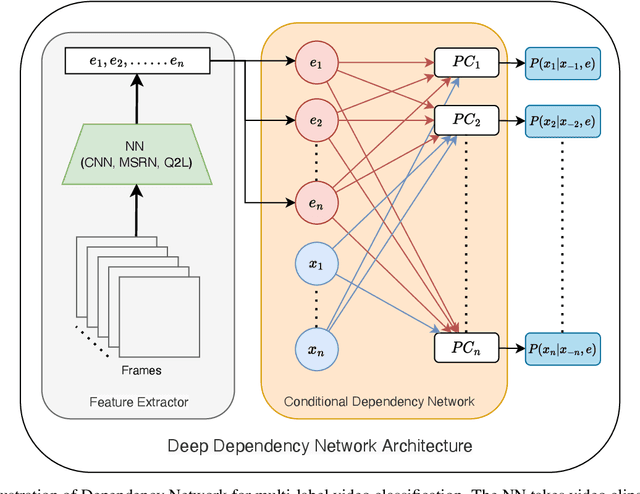
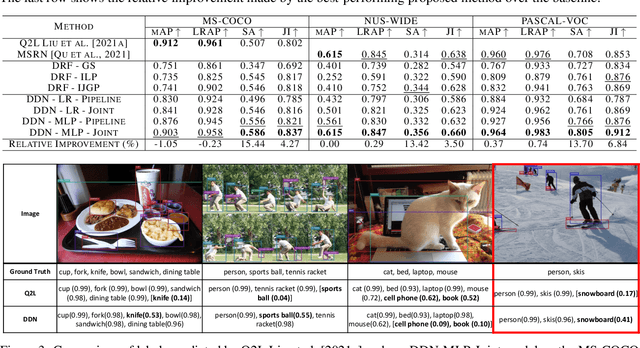
We propose a simple approach which combines the strengths of probabilistic graphical models and deep learning architectures for solving the multi-label classification task, focusing specifically on image and video data. First, we show that the performance of previous approaches that combine Markov Random Fields with neural networks can be modestly improved by leveraging more powerful methods such as iterative join graph propagation, integer linear programming, and $\ell_1$ regularization-based structure learning. Then we propose a new modeling framework called deep dependency networks, which augments a dependency network, a model that is easy to train and learns more accurate dependencies but is limited to Gibbs sampling for inference, to the output layer of a neural network. We show that despite its simplicity, jointly learning this new architecture yields significant improvements in performance over the baseline neural network. In particular, our experimental evaluation on three video activity classification datasets: Charades, Textually Annotated Cooking Scenes (TACoS), and Wetlab, and three multi-label image classification datasets: MS-COCO, PASCAL VOC, and NUS-WIDE show that deep dependency networks are almost always superior to pure neural architectures that do not use dependency networks.
Multi-Plane Neural Radiance Fields for Novel View Synthesis
Mar 03, 2023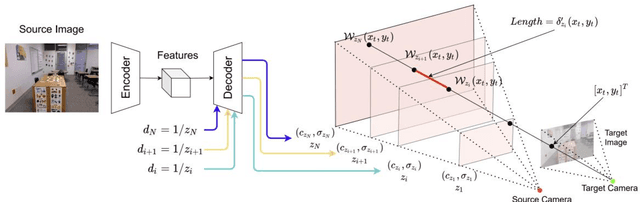
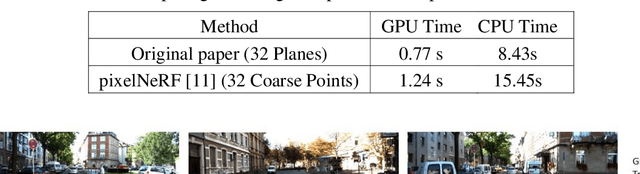
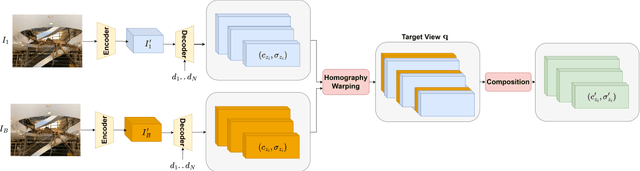
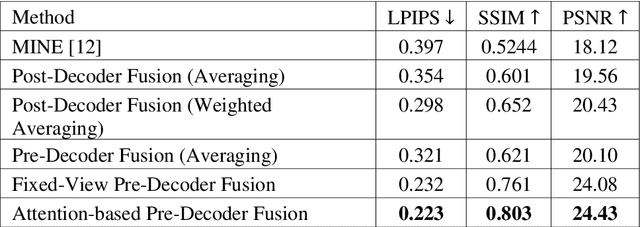
Novel view synthesis is a long-standing problem that revolves around rendering frames of scenes from novel camera viewpoints. Volumetric approaches provide a solution for modeling occlusions through the explicit 3D representation of the camera frustum. Multi-plane Images (MPI) are volumetric methods that represent the scene using front-parallel planes at distinct depths but suffer from depth discretization leading to a 2.D scene representation. Another line of approach relies on implicit 3D scene representations. Neural Radiance Fields (NeRF) utilize neural networks for encapsulating the continuous 3D scene structure within the network weights achieving photorealistic synthesis results, however, methods are constrained to per-scene optimization settings which are inefficient in practice. Multi-plane Neural Radiance Fields (MINE) open the door for combining implicit and explicit scene representations. It enables continuous 3D scene representations, especially in the depth dimension, while utilizing the input image features to avoid per-scene optimization. The main drawback of the current literature work in this domain is being constrained to single-view input, limiting the synthesis ability to narrow viewpoint ranges. In this work, we thoroughly examine the performance, generalization, and efficiency of single-view multi-plane neural radiance fields. In addition, we propose a new multiplane NeRF architecture that accepts multiple views to improve the synthesis results and expand the viewing range. Features from the input source frames are effectively fused through a proposed attention-aware fusion module to highlight important information from different viewpoints. Experiments show the effectiveness of attention-based fusion and the promising outcomes of our proposed method when compared to multi-view NeRF and MPI techniques.
SurgT challenge: Benchmark of Soft-Tissue Trackers for Robotic Surgery
Feb 28, 2023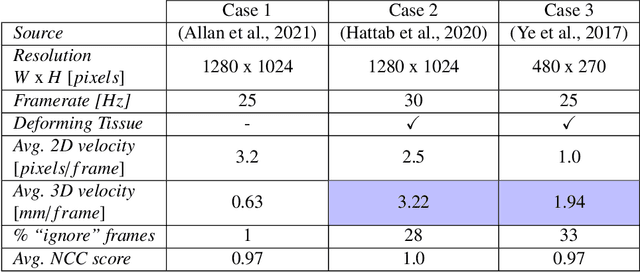
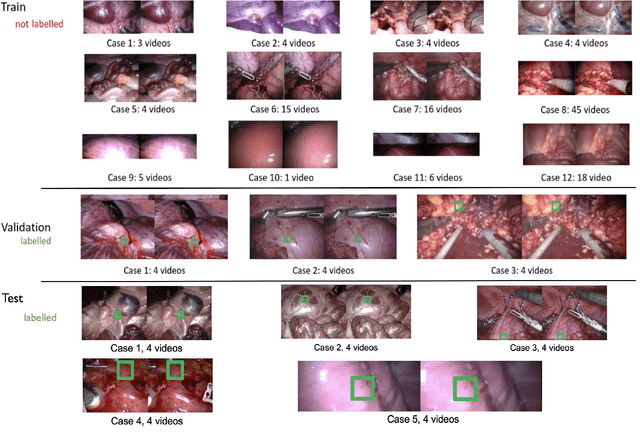
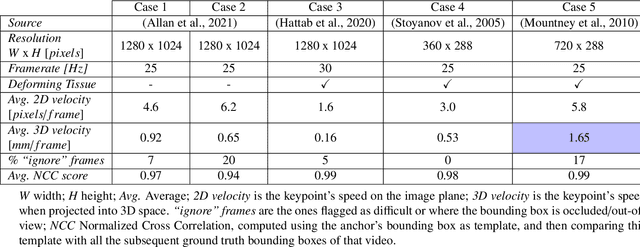
This paper introduces the "SurgT: Surgical Tracking" challenge which was organised in conjunction with the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2022). There were two purposes for the creation of this challenge: (1) the establishment of the first standardised benchmark for the research community to assess soft-tissue trackers; and (2) to encourage the development of unsupervised deep learning methods, given the lack of annotated data in surgery. A dataset of 157 stereo endoscopic videos from 20 clinical cases, along with stereo camera calibration parameters, have been provided. The participants were tasked with the development of algorithms to track a bounding box on stereo endoscopic videos. At the end of the challenge, the developed methods were assessed on a previously hidden test subset. This assessment uses benchmarking metrics that were purposely developed for this challenge and are now available online. The teams were ranked according to their Expected Average Overlap (EAO) score, which is a weighted average of the Intersection over Union (IoU) scores. The performance evaluation study verifies the efficacy of unsupervised deep learning algorithms in tracking soft-tissue. The best-performing method achieved an EAO score of 0.583 in the test subset. The dataset and benchmarking tool created for this challenge have been made publicly available. This challenge is expected to contribute to the development of autonomous robotic surgery and other digital surgical technologies.
Finding Things in the Unknown: Semantic Object-Centric Exploration with an MAV
Feb 28, 2023
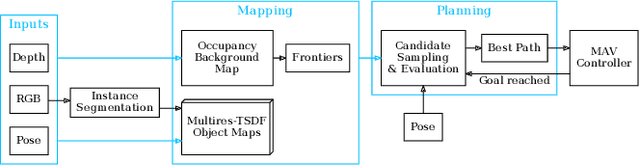
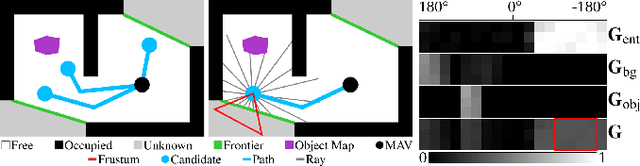

Exploration of unknown space with an autonomous mobile robot is a well-studied problem. In this work we broaden the scope of exploration, moving beyond the pure geometric goal of uncovering as much free space as possible. We believe that for many practical applications, exploration should be contextualised with semantic and object-level understanding of the environment for task-specific exploration. Here, we study the task of both finding specific objects in unknown space as well as reconstructing them to a target level of detail. We therefore extend our environment reconstruction to not only consist of a background map, but also object-level and semantically fused submaps. Importantly, we adapt our previous objective function of uncovering as much free space as possible in as little time as possible with two additional elements: first, we require a maximum observation distance of background surfaces to ensure target objects are not missed by image-based detectors because they are too small to be detected. Second, we require an even smaller maximum distance to the found objects in order to reconstruct them with the desired accuracy. We further created a Micro Aerial Vehicle (MAV) semantic exploration simulator based on Habitat in order to quantitatively demonstrate how our framework can be used to efficiently find specific objects as part of exploration. Finally, we showcase this capability can be deployed in real-world scenes involving our drone equipped with an Intel RealSense D455 RGB-D camera.
Random Padding Data Augmentation
Feb 17, 2023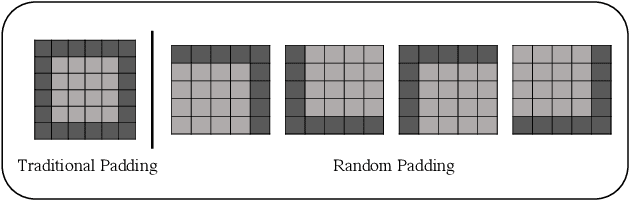
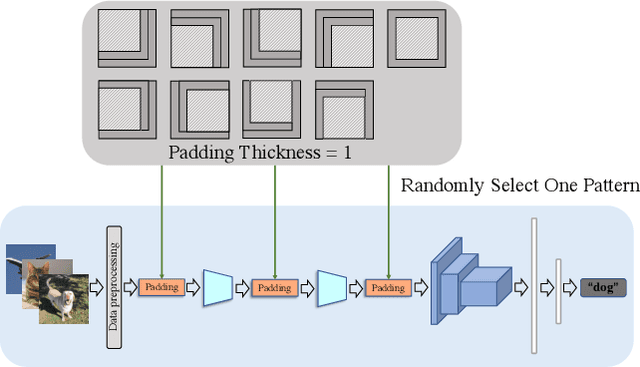
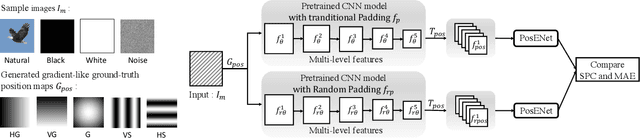
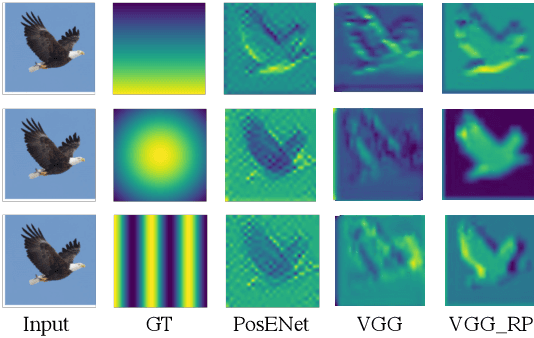
The convolutional neural network (CNN) learns the same object in different positions in images, which can improve the recognition accuracy of the model. An implication of this is that CNN may know where the object is. The usefulness of the features' spatial information in CNNs has not been well investigated. In this paper, we found that the model's learning of features' position information hindered the learning of the features' relationship. Therefore, we introduced Random Padding, a new type of padding method for training CNNs that impairs the architecture's capacity to learn position information by adding zero-padding randomly to half of the border of feature maps. Random Padding is parameter-free, simple to construct, and compatible with the majority of CNN-based recognition models. This technique is also complementary to data augmentations such as random cropping, rotation, flipping and erasing, and consistently improves the performance of image classification over strong baselines.
Efficiency 360: Efficient Vision Transformers
Feb 17, 2023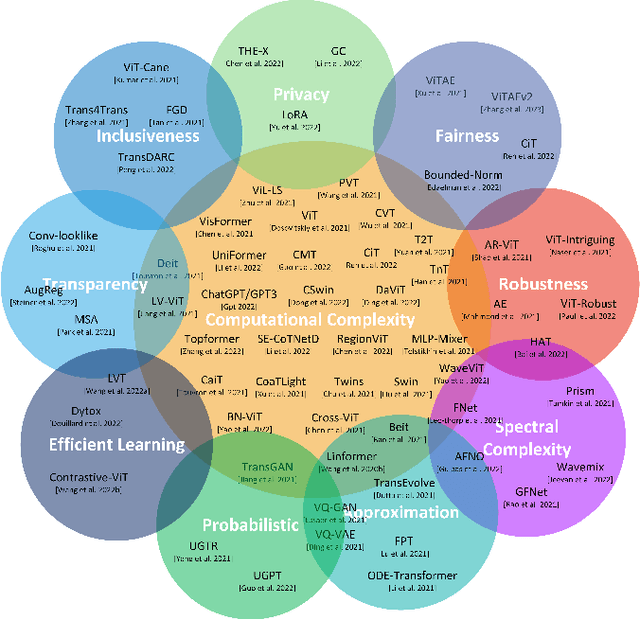
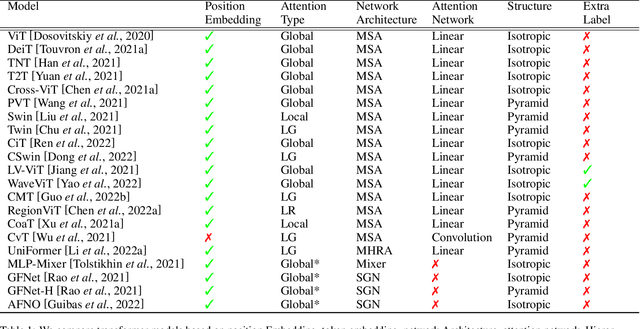
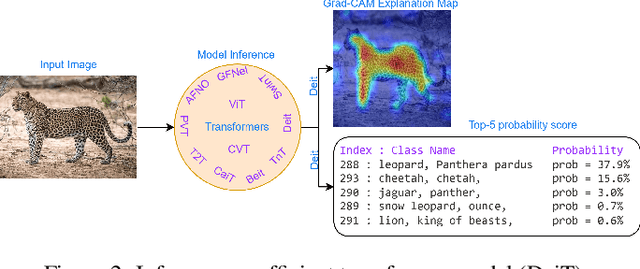
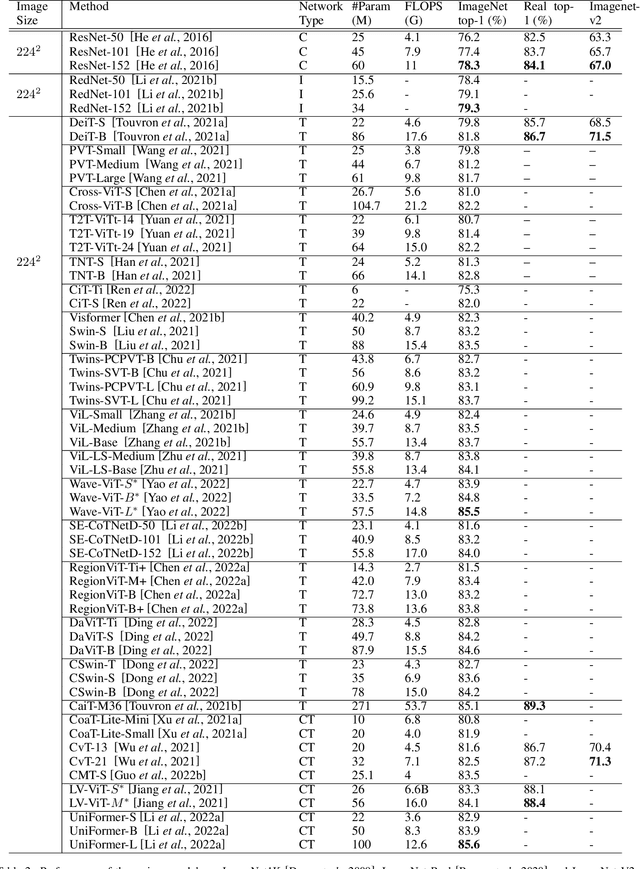
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
Contour-based Interactive Segmentation
Feb 13, 2023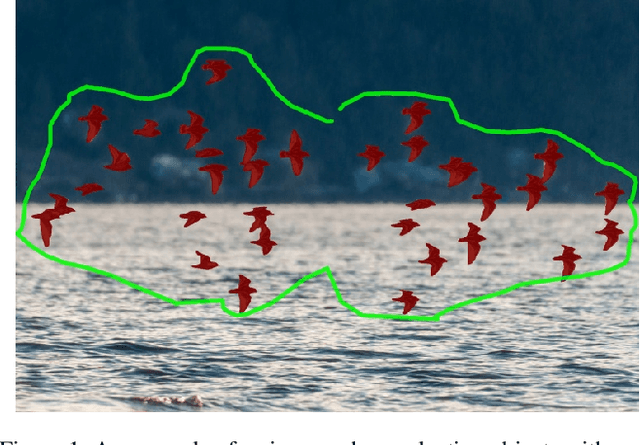
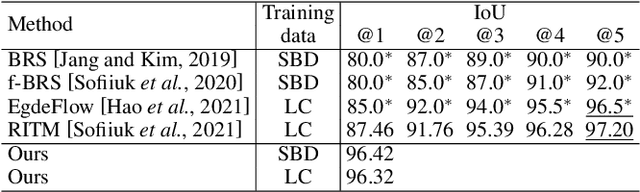
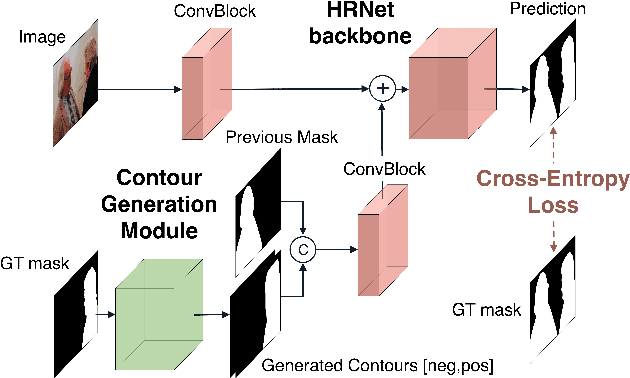
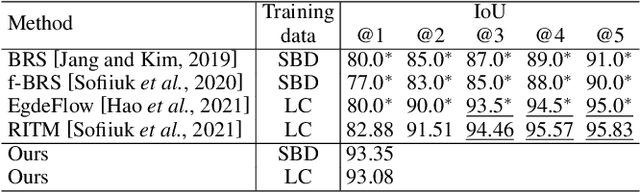
Recent advances in interactive segmentation (IS) allow speeding up and simplifying image editing and labeling greatly. The majority of modern IS approaches accept user input in the form of clicks. However, using clicks may require too many user interactions, especially when selecting small objects, minor parts of an object, or a group of objects of the same type. In this paper, we consider such a natural form of user interaction as a loose contour, and introduce a contour-based IS method. We evaluate the proposed method on the standard segmentation benchmarks, our novel UserContours dataset, and its subset UserContours-G containing difficult segmentation cases. Through experiments, we demonstrate that a single contour provides the same accuracy as multiple clicks, thus reducing the required amount of user interactions.
A Review of Predictive and Contrastive Self-supervised Learning for Medical Images
Feb 10, 2023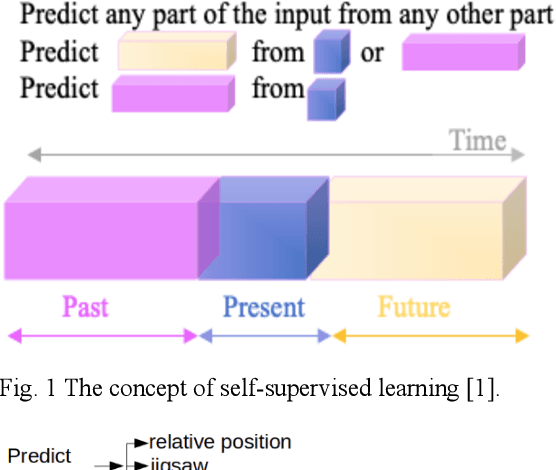
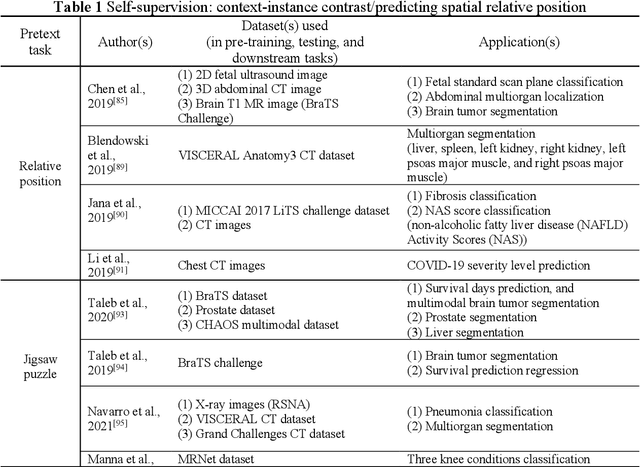
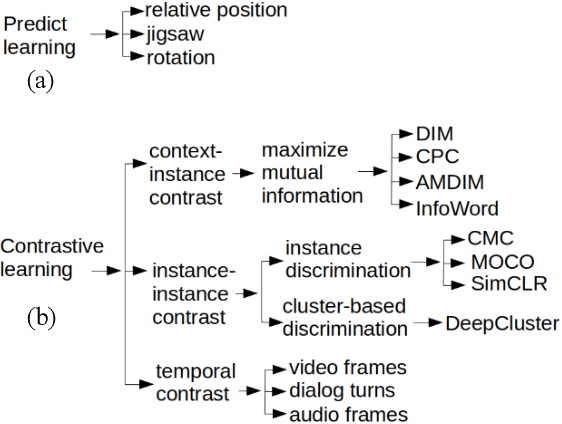
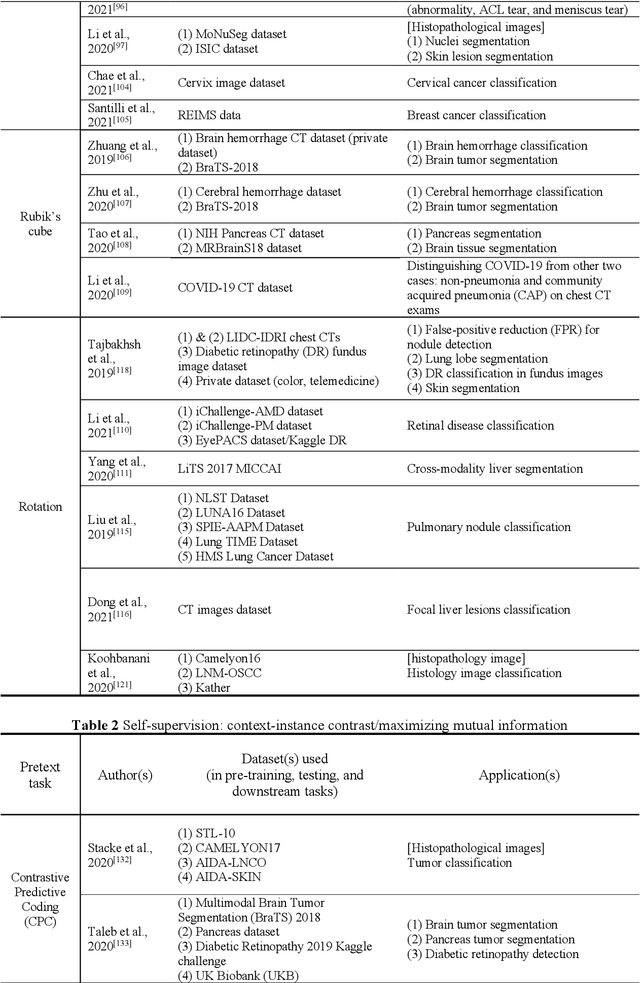
Over the last decade, supervised deep learning on manually annotated big data has been progressing significantly on computer vision tasks. But the application of deep learning in medical image analysis was limited by the scarcity of high-quality annotated medical imaging data. An emerging solution is self-supervised learning (SSL), among which contrastive SSL is the most successful approach to rivalling or outperforming supervised learning. This review investigates several state-of-the-art contrastive SSL algorithms originally on natural images as well as their adaptations for medical images, and concludes by discussing recent advances, current limitations, and future directions in applying contrastive SSL in the medical domain.