 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explore the Power of Dropout on Few-shot Learning
Jan 26, 2023
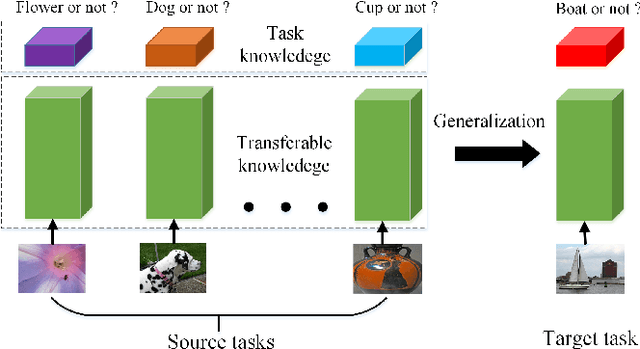
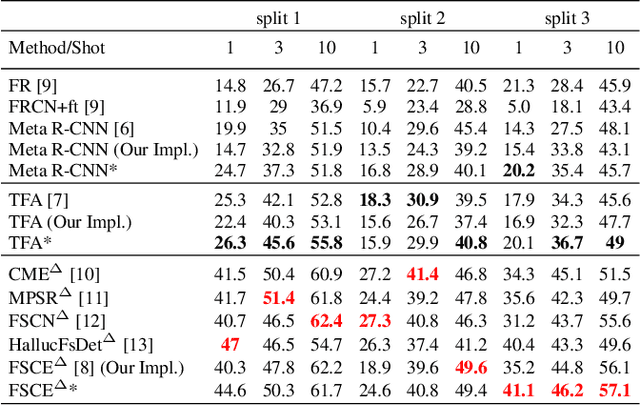
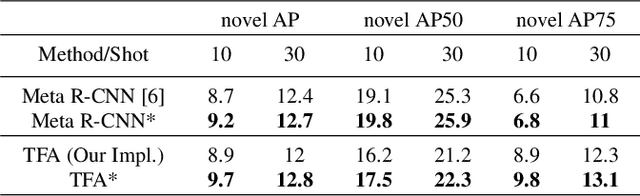

The generalization power of the pre-trained model is the key for few-shot deep learning. Dropout is a regularization technique used in traditional deep learning methods. In this paper, we explore the power of dropout on few-shot learning and provide some insights about how to use it. Extensive experiments on the few-shot object detection and few-shot image classification datasets, i.e., Pascal VOC, MS COCO, CUB, and mini-ImageNet, validate the effectiveness of our method.
Scaling Painting Style Transfer
Dec 27, 2022

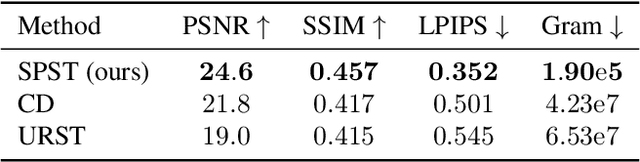
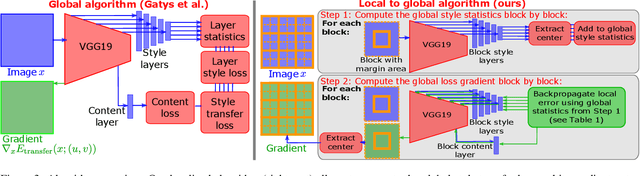
Neural style transfer is a deep learning technique that produces an unprecedentedly rich style transfer from a style image to a content image and is particularly impressive when it comes to transferring style from a painting to an image. It was originally achieved by solving an optimization problem to match the global style statistics of the style image while preserving the local geometric features of the content image. The two main drawbacks of this original approach is that it is computationally expensive and that the resolution of the output images is limited by high GPU memory requirements. Many solutions have been proposed to both accelerate neural style transfer and increase its resolution, but they all compromise the quality of the produced images. Indeed, transferring the style of a painting is a complex task involving features at different scales, from the color palette and compositional style to the fine brushstrokes and texture of the canvas. This paper provides a solution to solve the original global optimization for ultra-high resolution images, enabling multiscale style transfer at unprecedented image sizes. This is achieved by spatially localizing the computation of each forward and backward passes through the VGG network. Extensive qualitative and quantitative comparisons show that our method produces a style transfer of unmatched quality for such high resolution painting styles.
On Feasibility of Server-side Backdoor Attacks on Split Learning
Feb 19, 2023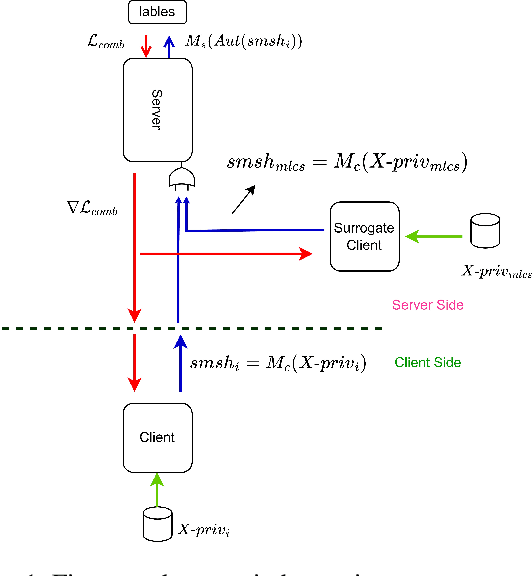
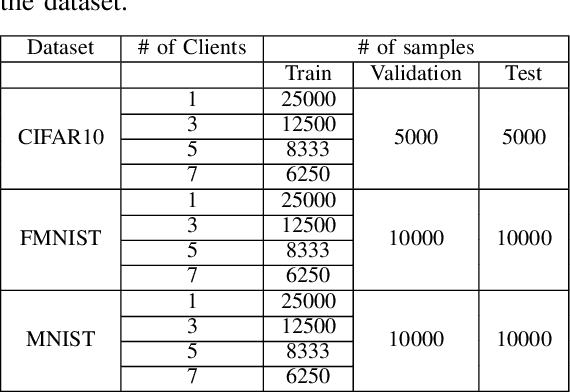
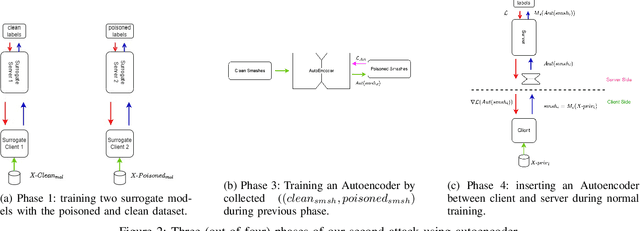
Split learning is a collaborative learning design that allows several participants (clients) to train a shared model while keeping their datasets private. Recent studies demonstrate that collaborative learning models, specifically federated learning, are vulnerable to security and privacy attacks such as model inference and backdoor attacks. Backdoor attacks are a group of poisoning attacks in which the attacker tries to control the model output by manipulating the model's training process. While there have been studies regarding inference attacks on split learning, it has not yet been tested for backdoor attacks. This paper performs a novel backdoor attack on split learning and studies its effectiveness. Despite traditional backdoor attacks done on the client side, we inject the backdoor trigger from the server side. For this purpose, we provide two attack methods: one using a surrogate client and another using an autoencoder to poison the model via incoming smashed data and its outgoing gradient toward the innocent participants. We did our experiments using three model architectures and three publicly available datasets in the image domain and ran a total of 761 experiments to evaluate our attack methods. The results show that despite using strong patterns and injection methods, split learning is highly robust and resistant to such poisoning attacks. While we get the attack success rate of 100% as our best result for the MNIST dataset, in most of the other cases, our attack shows little success when increasing the cut layer.
MILAN: Masked Image Pretraining on Language Assisted Representation
Aug 15, 2022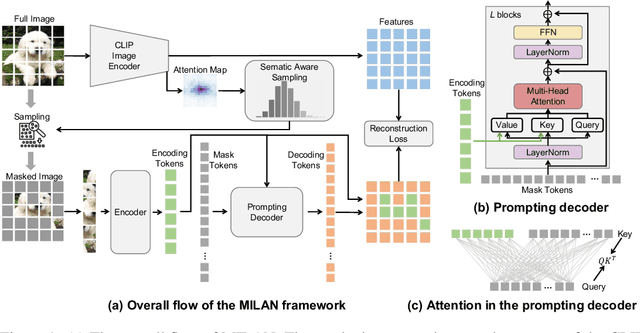
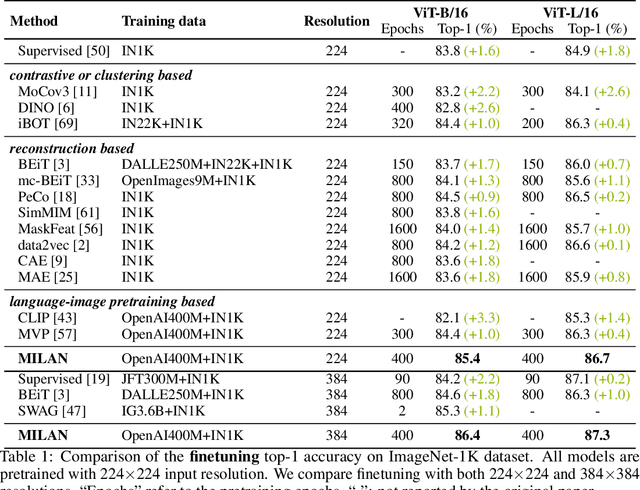

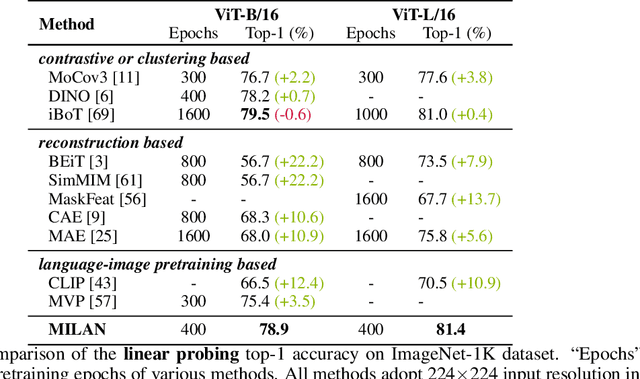
Self-attention based transformer models have been dominating many computer vision tasks in the past few years. Their superb model qualities heavily depend on the excessively large labeled image datasets. In order to reduce the reliance on large labeled datasets, reconstruction based masked autoencoders are gaining popularity, which learn high quality transferable representations from unlabeled images. For the same purpose, recent weakly supervised image pretraining methods explore language supervision from text captions accompanying the images. In this work, we propose masked image pretraining on language assisted representation, dubbed as MILAN. Instead of predicting raw pixels or low level features, our pretraining objective is to reconstruct the image features with substantial semantic signals that are obtained using caption supervision. Moreover, to accommodate our reconstruction target, we propose a more efficient prompting decoder architecture and a semantic aware mask sampling mechanism, which further advance the transfer performance of the pretrained model. Experimental results demonstrate that MILAN delivers higher accuracy than the previous works. When the masked autoencoder is pretrained and finetuned on ImageNet-1K dataset with an input resolution of 224x224, MILAN achieves a top-1 accuracy of 85.4% on ViTB/16, surpassing previous state-of-the-arts by 1%. In the downstream semantic segmentation task, MILAN achieves 52.7 mIoU using ViT-B/16 backbone on ADE20K dataset, outperforming previous masked pretraining results by 4 points.
Region-aware Knowledge Distillation for Efficient Image-to-Image Translation
May 25, 2022
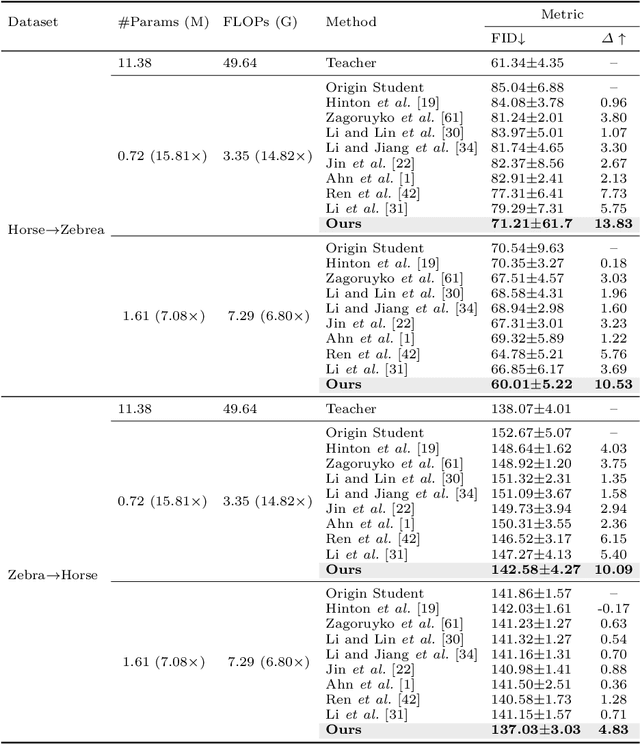
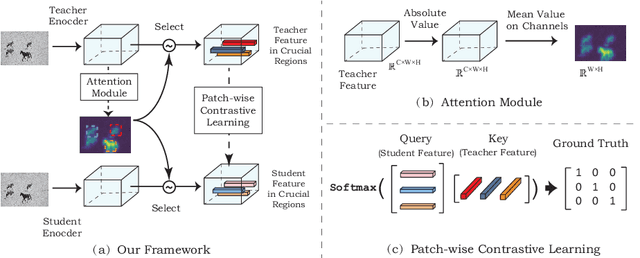
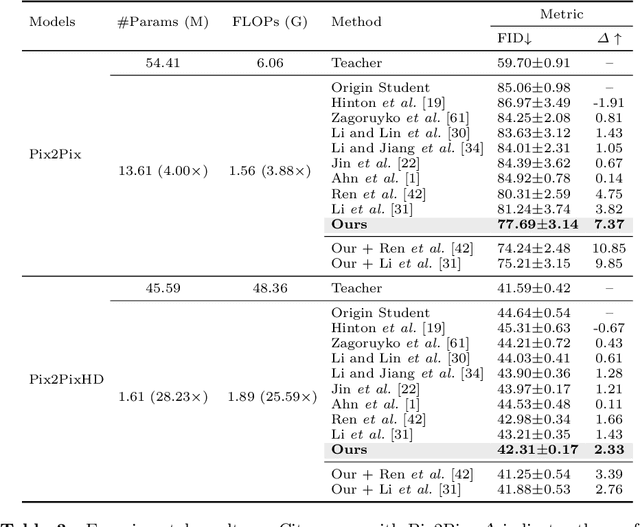
Recent progress in image-to-image translation has witnessed the success of generative adversarial networks (GANs). However, GANs usually contain a huge number of parameters, which lead to intolerant memory and computation consumption and limit their deployment on edge devices. To address this issue, knowledge distillation is proposed to transfer the knowledge from a cumbersome teacher model to an efficient student model. However, most previous knowledge distillation methods are designed for image classification and lead to limited performance in image-to-image translation. In this paper, we propose Region-aware Knowledge Distillation ReKo to compress image-to-image translation models. Firstly, ReKo adaptively finds the crucial regions in the images with an attention module. Then, patch-wise contrastive learning is adopted to maximize the mutual information between students and teachers in these crucial regions. Experiments with eight comparison methods on nine datasets demonstrate the substantial effectiveness of ReKo on both paired and unpaired image-to-image translation. For instance, our 7.08X compressed and 6.80X accelerated CycleGAN student outperforms its teacher by 1.33 and 1.04 FID scores on Horse to Zebra and Zebra to Horse, respectively. Codes will be released on GitHub.
Standardized CycleGAN training for unsupervised stain adaptation in invasive carcinoma classification for breast histopathology
Jan 30, 2023
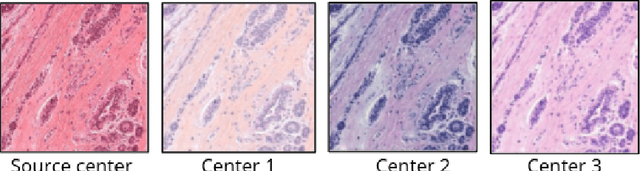
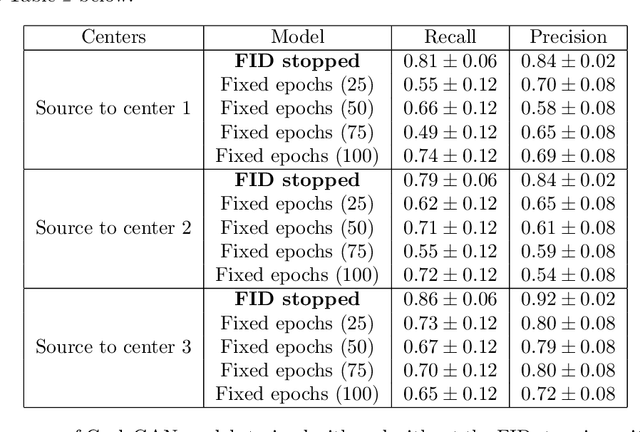
Generalization is one of the main challenges of computational pathology. Slide preparation heterogeneity and the diversity of scanners lead to poor model performance when used on data from medical centers not seen during training. In order to achieve stain invariance in breast invasive carcinoma patch classification, we implement a stain translation strategy using cycleGANs for unsupervised image-to-image translation. We compare three cycleGAN-based approaches to a baseline classification model obtained without any stain invariance strategy. Two of the proposed approaches use cycleGAN's translations at inference or training in order to build stain-specific classification models. The last method uses them for stain data augmentation during training. This constrains the classification model to learn stain-invariant features. Baseline metrics are set by training and testing the baseline classification model on a reference stain. We assessed performances using three medical centers with H&E and H&E&S staining. Every approach tested in this study improves baseline metrics without needing labels on target stains. The stain augmentation-based approach produced the best results on every stain. Each method's pros and cons are studied and discussed in this paper. However, training highly performing cycleGANs models in itself represents a challenge. In this work, we introduce a systematical method for optimizing cycleGAN training by setting a novel stopping criterion. This method has the benefit of not requiring any visual inspection of cycleGAN results and proves superiority to methods using a predefined number of training epochs. In addition, we also study the minimal amount of data required for cycleGAN training.
Better Diffusion Models Further Improve Adversarial Training
Feb 09, 2023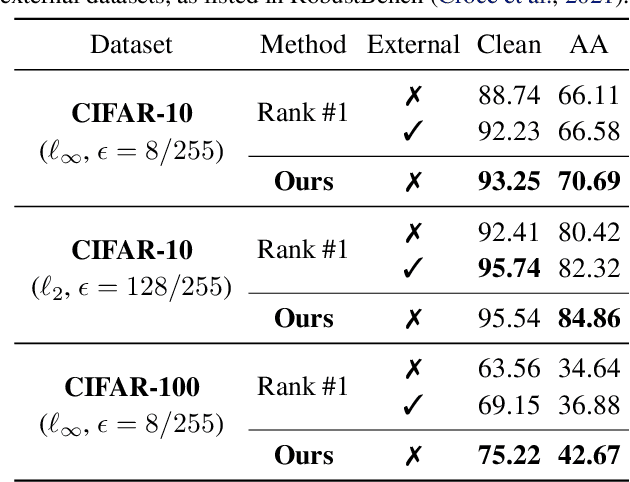
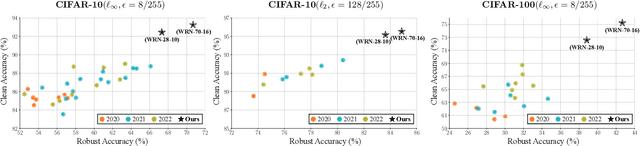
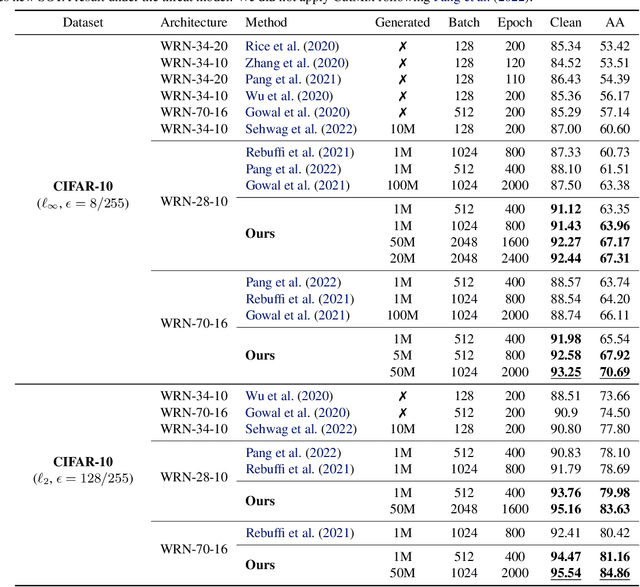
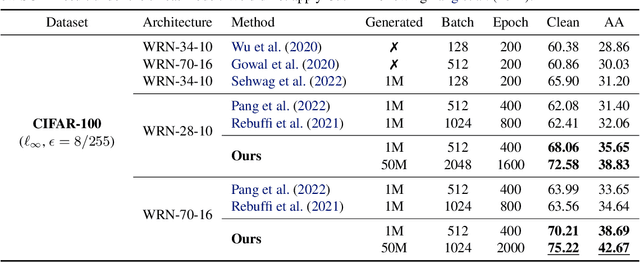
It has been recognized that the data generated by the denoising diffusion probabilistic model (DDPM) improves adversarial training. After two years of rapid development in diffusion models, a question naturally arises: can better diffusion models further improve adversarial training? This paper gives an affirmative answer by employing the most recent diffusion model which has higher efficiency ($\sim 20$ sampling steps) and image quality (lower FID score) compared with DDPM. Our adversarially trained models achieve state-of-the-art performance on RobustBench using only generated data (no external datasets). Under the $\ell_\infty$-norm threat model with $\epsilon=8/255$, our models achieve $70.69\%$ and $42.67\%$ robust accuracy on CIFAR-10 and CIFAR-100, respectively, i.e. improving upon previous state-of-the-art models by $+4.58\%$ and $+8.03\%$. Under the $\ell_2$-norm threat model with $\epsilon=128/255$, our models achieve $84.86\%$ on CIFAR-10 ($+4.44\%$). These results also beat previous works that use external data. Our code is available at https://github.com/wzekai99/DM-Improves-AT.
Reversible Vision Transformers
Feb 09, 2023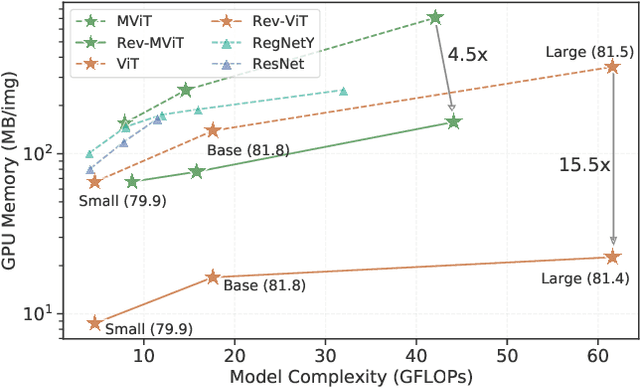
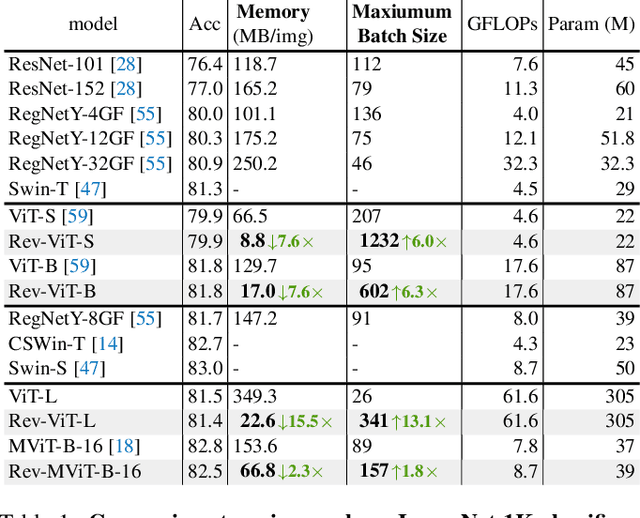
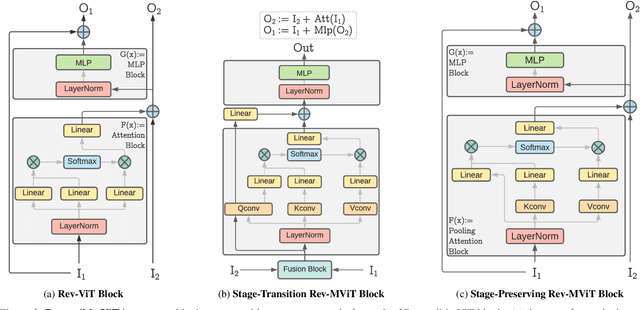
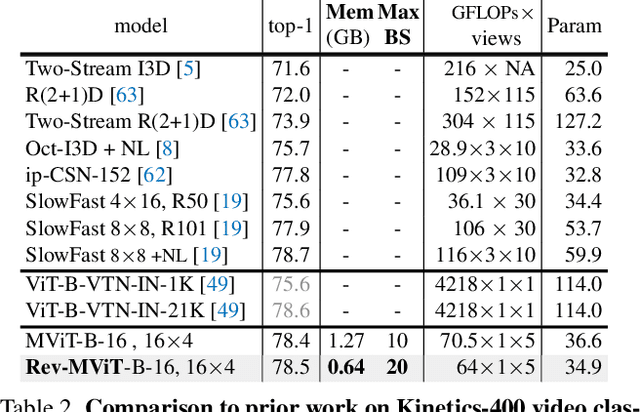
We present Reversible Vision Transformers, a memory efficient architecture design for visual recognition. By decoupling the GPU memory requirement from the depth of the model, Reversible Vision Transformers enable scaling up architectures with efficient memory usage. We adapt two popular models, namely Vision Transformer and Multiscale Vision Transformers, to reversible variants and benchmark extensively across both model sizes and tasks of image classification, object detection and video classification. Reversible Vision Transformers achieve a reduced memory footprint of up to 15.5x at roughly identical model complexity, parameters and accuracy, demonstrating the promise of reversible vision transformers as an efficient backbone for hardware resource limited training regimes. Finally, we find that the additional computational burden of recomputing activations is more than overcome for deeper models, where throughput can increase up to 2.3x over their non-reversible counterparts. Full code and trained models are available at https://github.com/facebookresearch/slowfast. A simpler, easy to understand and modify version is also available at https://github.com/karttikeya/minREV
A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions
Feb 09, 2023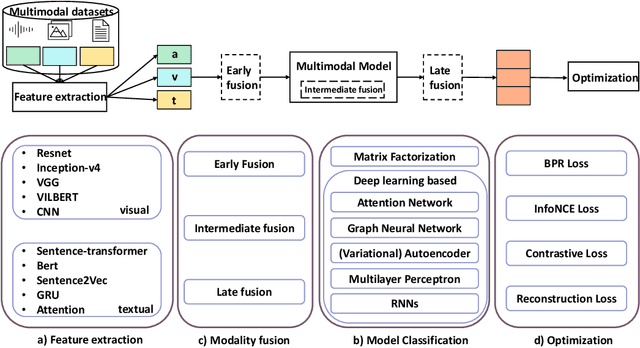
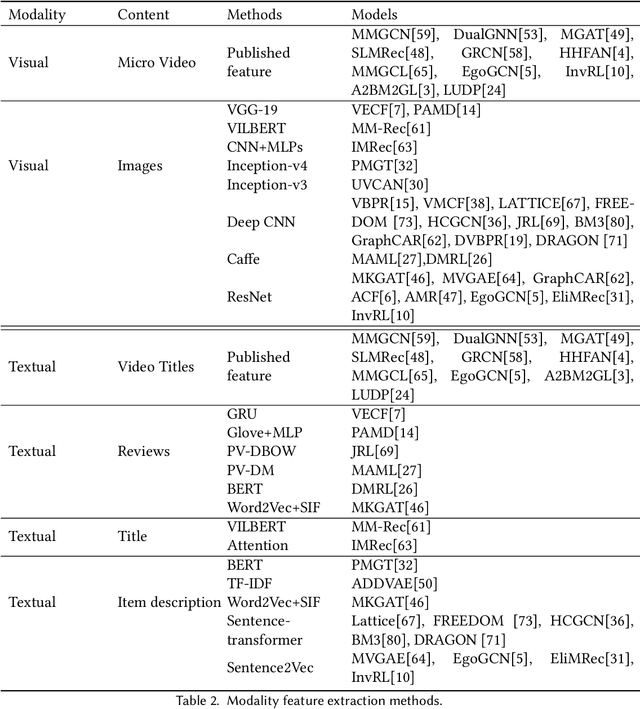
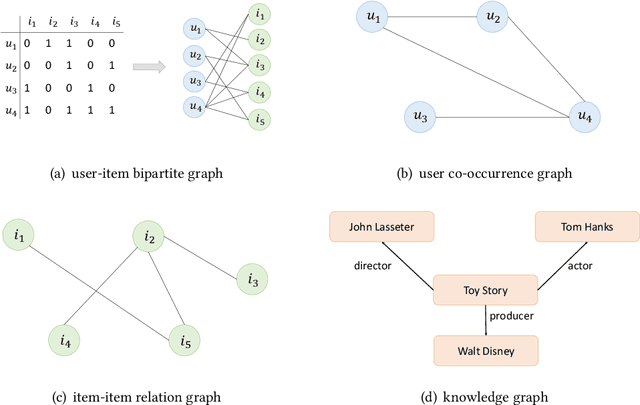
Recommendation systems have become popular and effective tools to help users discover their interesting items by modeling the user preference and item property based on implicit interactions (e.g., purchasing and clicking). Humans perceive the world by processing the modality signals (e.g., audio, text and image), which inspired researchers to build a recommender system that can understand and interpret data from different modalities. Those models could capture the hidden relations between different modalities and possibly recover the complementary information which can not be captured by a uni-modal approach and implicit interactions. The goal of this survey is to provide a comprehensive review of the recent research efforts on the multimodal recommendation. Specifically, it shows a clear pipeline with commonly used techniques in each step and classifies the models by the methods used. Additionally, a code framework has been designed that helps researchers new in this area to understand the principles and techniques, and easily runs the SOTA models. Our framework is located at: https://github.com/enoche/MMRec
In-N-Out: Face Video Inversion and Editing with Volumetric Decomposition
Feb 09, 2023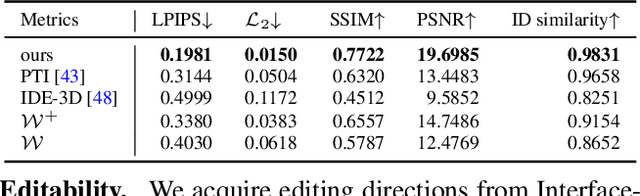

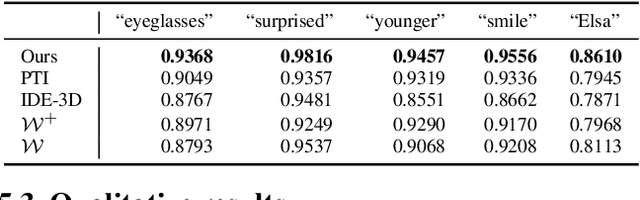
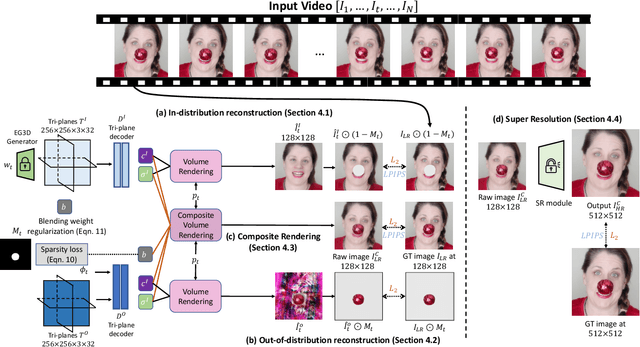
3D-aware GANs offer new capabilities for creative content editing, such as view synthesis, while preserving the editing capability of their 2D counterparts. Using GAN inversion, these methods can reconstruct an image or a video by optimizing/predicting a latent code and achieve semantic editing by manipulating the latent code. However, a model pre-trained on a face dataset (e.g., FFHQ) often has difficulty handling faces with out-of-distribution (OOD) objects, (e.g., heavy make-up or occlusions). We address this issue by explicitly modeling OOD objects in face videos. Our core idea is to represent the face in a video using two neural radiance fields, one for in-distribution and the other for out-of-distribution data, and compose them together for reconstruction. Such explicit decomposition alleviates the inherent trade-off between reconstruction fidelity and editability. We evaluate our method's reconstruction accuracy and editability on challenging real videos and showcase favorable results against other baselines.