 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sparse, Geometric Autoencoder Models of V1
Feb 22, 2023

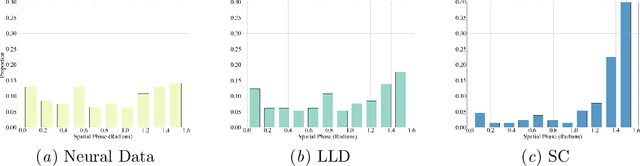
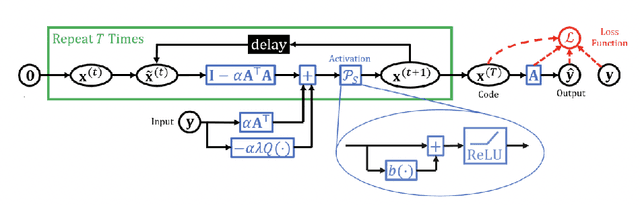
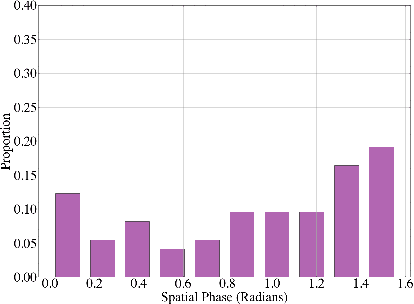
The classical sparse coding model represents visual stimuli as a linear combination of a handful of learned basis functions that are Gabor-like when trained on natural image data. However, the Gabor-like filters learned by classical sparse coding far overpredict well-tuned simple cell receptive field (SCRF) profiles. A number of subsequent models have either discarded the sparse dictionary learning framework entirely or have yet to take advantage of the surge in unrolled, neural dictionary learning architectures. A key missing theme of these updates is a stronger notion of \emph{structured sparsity}. We propose an autoencoder architecture whose latent representations are implicitly, locally organized for spectral clustering, which begets artificial neurons better matched to observed primate data. The weighted-$\ell_1$ (WL) constraint in the autoencoder objective function maintains core ideas of the sparse coding framework, yet also offers a promising path to describe the differentiation of receptive fields in terms of a discriminative hierarchy in future work.
A Validation Approach to Over-parameterized Matrix and Image Recovery
Sep 21, 2022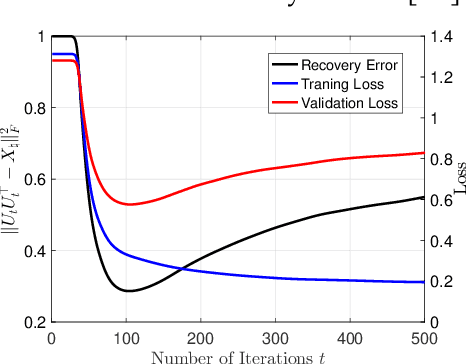
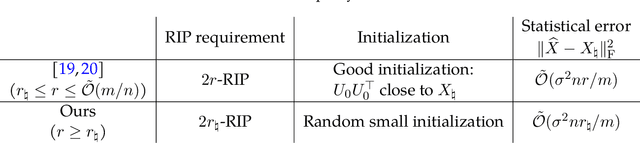
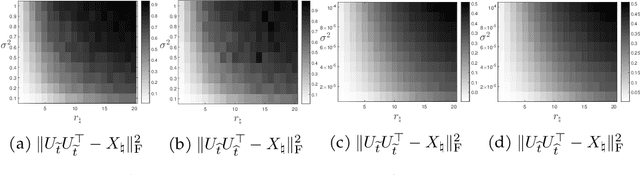
In this paper, we study the problem of recovering a low-rank matrix from a number of noisy random linear measurements. We consider the setting where the rank of the ground-truth matrix is unknown a prior and use an overspecified factored representation of the matrix variable, where the global optimal solutions overfit and do not correspond to the underlying ground-truth. We then solve the associated nonconvex problem using gradient descent with small random initialization. We show that as long as the measurement operators satisfy the restricted isometry property (RIP) with its rank parameter scaling with the rank of ground-truth matrix rather than scaling with the overspecified matrix variable, gradient descent iterations are on a particular trajectory towards the ground-truth matrix and achieve nearly information-theoretically optimal recovery when stop appropriately. We then propose an efficient early stopping strategy based on the common hold-out method and show that it detects nearly optimal estimator provably. Moreover, experiments show that the proposed validation approach can also be efficiently used for image restoration with deep image prior which over-parameterizes an image with a deep network.
A Survey on Evolutionary Computation for Computer Vision and Image Analysis: Past, Present, and Future Trends
Sep 14, 2022
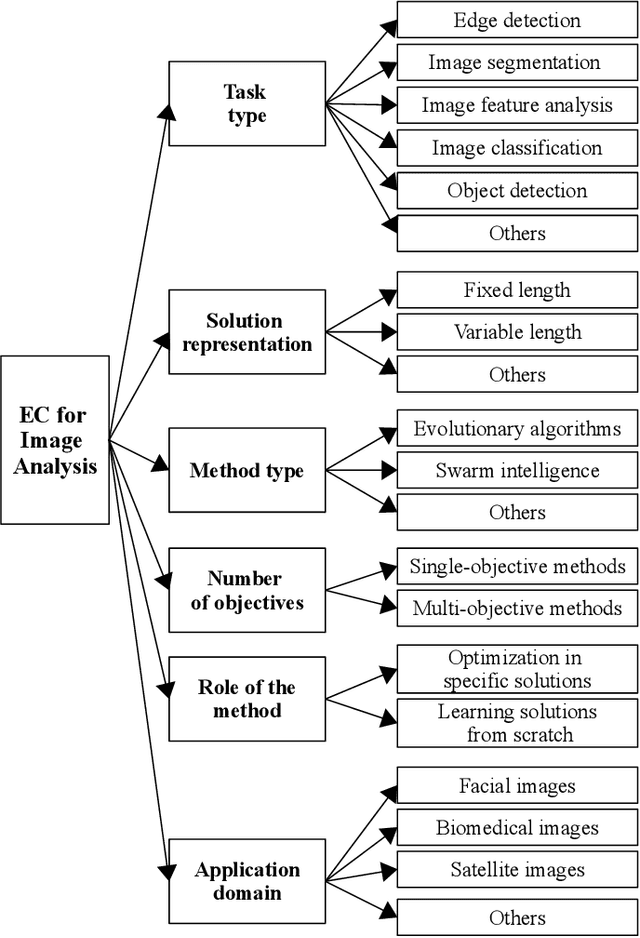
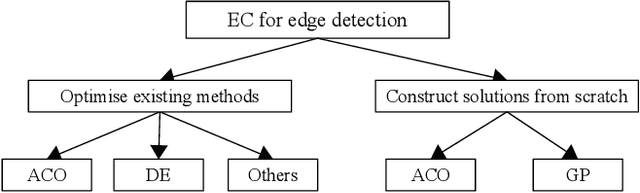

Computer vision (CV) is a big and important field in artificial intelligence covering a wide range of applications. Image analysis is a major task in CV aiming to extract, analyse and understand the visual content of images. However, image-related tasks are very challenging due to many factors, e.g., high variations across images, high dimensionality, domain expertise requirement, and image distortions. Evolutionary computation (EC) approaches have been widely used for image analysis with significant achievement. However, there is no comprehensive survey of existing EC approaches to image analysis. To fill this gap, this paper provides a comprehensive survey covering all essential EC approaches to important image analysis tasks including edge detection, image segmentation, image feature analysis, image classification, object detection, and others. This survey aims to provide a better understanding of evolutionary computer vision (ECV) by discussing the contributions of different approaches and exploring how and why EC is used for CV and image analysis. The applications, challenges, issues, and trends associated to this research field are also discussed and summarised to provide further guidelines and opportunities for future research.
* Conditionally accepted by IEEE Transactions on Evolutionary Computation
Noise2SR: Learning to Denoise from Super-Resolved Single Noisy Fluorescence Image
Sep 14, 2022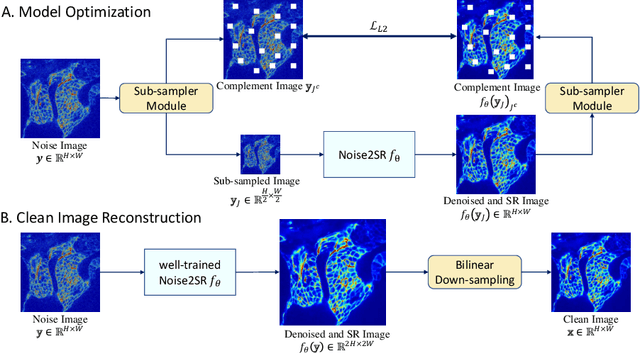
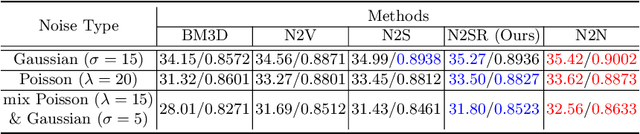

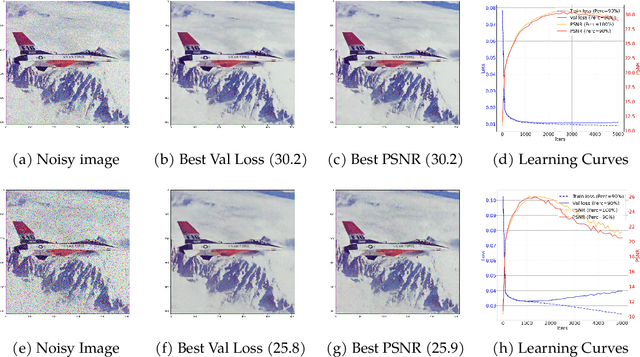
Fluorescence microscopy is a key driver to promote discoveries of biomedical research. However, with the limitation of microscope hardware and characteristics of the observed samples, the fluorescence microscopy images are susceptible to noise. Recently, a few self-supervised deep learning (DL) denoising methods have been proposed. However, the training efficiency and denoising performance of existing methods are relatively low in real scene noise removal. To address this issue, this paper proposed self-supervised image denoising method Noise2SR (N2SR) to train a simple and effective image denoising model based on single noisy observation. Our Noise2SR denoising model is designed for training with paired noisy images of different dimensions. Benefiting from this training strategy, Noise2SR is more efficiently self-supervised and able to restore more image details from a single noisy observation. Experimental results of simulated noise and real microscopy noise removal show that Noise2SR outperforms two blind-spot based self-supervised deep learning image denoising methods. We envision that Noise2SR has the potential to improve more other kind of scientific imaging quality.
* 12 pages, 6 figures
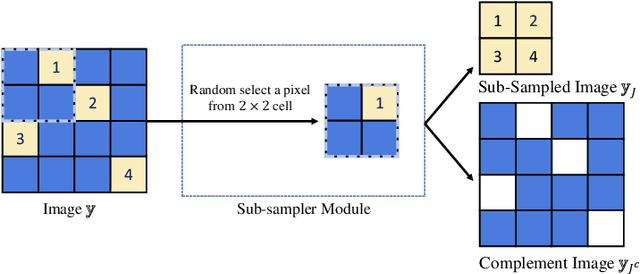
Generic-to-Specific Distillation of Masked Autoencoders
Feb 28, 2023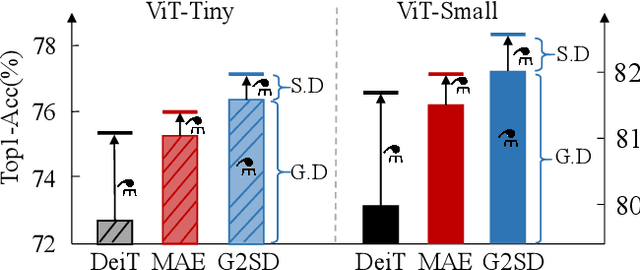
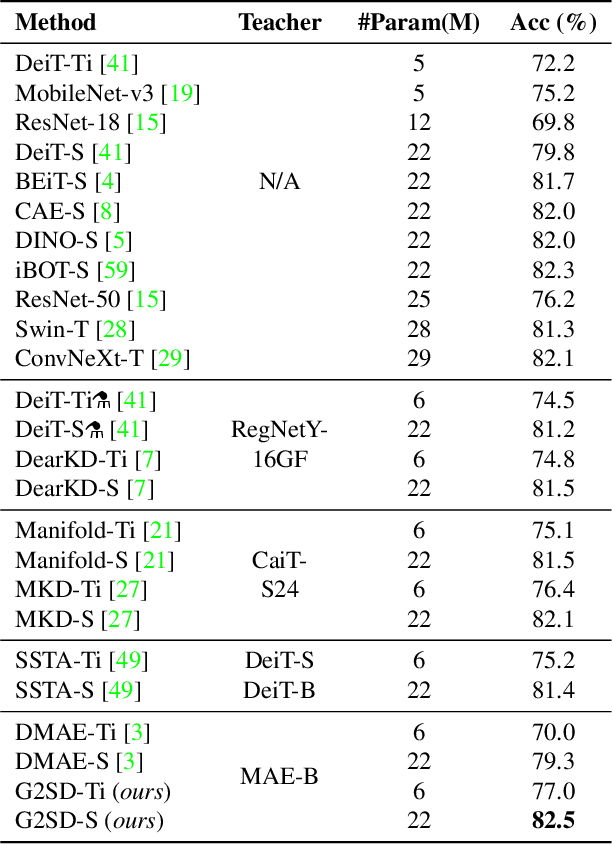
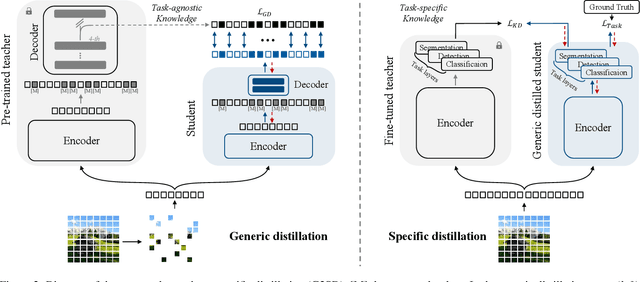
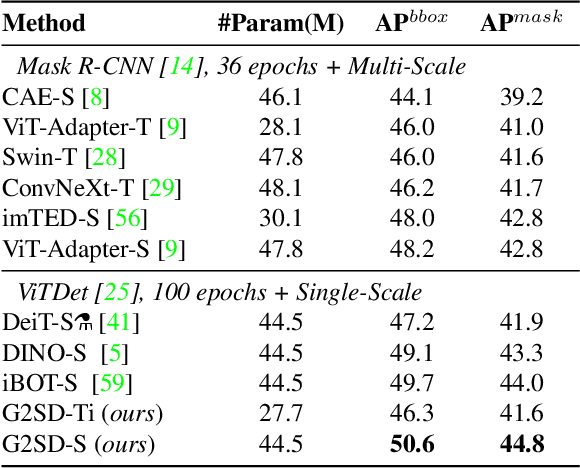
Large vision Transformers (ViTs) driven by self-supervised pre-training mechanisms achieved unprecedented progress. Lightweight ViT models limited by the model capacity, however, benefit little from those pre-training mechanisms. Knowledge distillation defines a paradigm to transfer representations from large (teacher) models to small (student) ones. However, the conventional single-stage distillation easily gets stuck on task-specific transfer, failing to retain the task-agnostic knowledge crucial for model generalization. In this study, we propose generic-to-specific distillation (G2SD), to tap the potential of small ViT models under the supervision of large models pre-trained by masked autoencoders. In generic distillation, decoder of the small model is encouraged to align feature predictions with hidden representations of the large model, so that task-agnostic knowledge can be transferred. In specific distillation, predictions of the small model are constrained to be consistent with those of the large model, to transfer task-specific features which guarantee task performance. With G2SD, the vanilla ViT-Small model respectively achieves 98.7%, 98.1% and 99.3% the performance of its teacher (ViT-Base) for image classification, object detection, and semantic segmentation, setting a solid baseline for two-stage vision distillation. Code will be available at https://github.com/pengzhiliang/G2SD.
Towards Surgical Context Inference and Translation to Gestures
Feb 28, 2023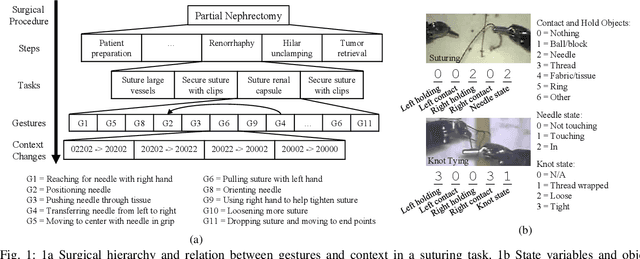
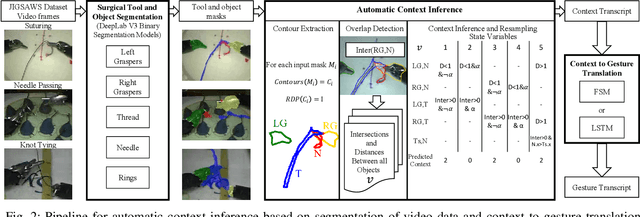
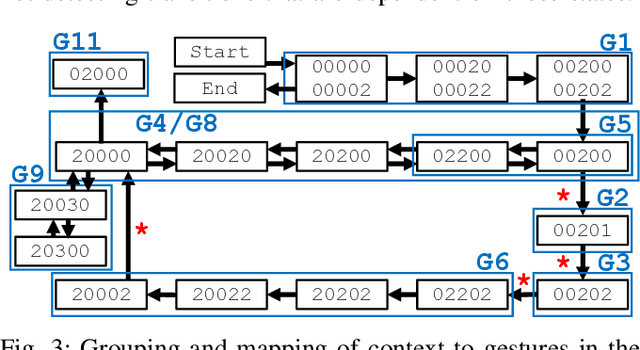
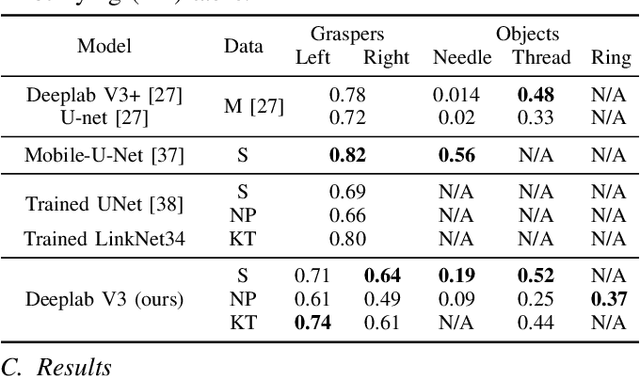
Manual labeling of gestures in robot-assisted surgery is labor intensive, prone to errors, and requires expertise or training. We propose a method for automated and explainable generation of gesture transcripts that leverages the abundance of data for image segmentation to train a surgical scene segmentation model that provides surgical tool and object masks. Surgical context is detected using segmentation masks by examining the distances and intersections between the tools and objects. Next, context labels are translated into gesture transcripts using knowledge-based Finite State Machine (FSM) and data-driven Long Short Term Memory (LSTM) models. We evaluate the performance of each stage of our method by comparing the results with the ground truth segmentation masks, the consensus context labels, and the gesture labels in the JIGSAWS dataset. Our results show that our segmentation models achieve state-of-the-art performance in recognizing needle and thread in Suturing and we can automatically detect important surgical states with high agreement with crowd-sourced labels (e.g., contact between graspers and objects in Suturing). We also find that the FSM models are more robust to poor segmentation and labeling performance than LSTMs. Our proposed method can significantly shorten the gesture labeling process (~2.8 times).
Design of an Adaptive Lightweight LiDAR to Decouple Robot-Camera Geometry
Feb 28, 2023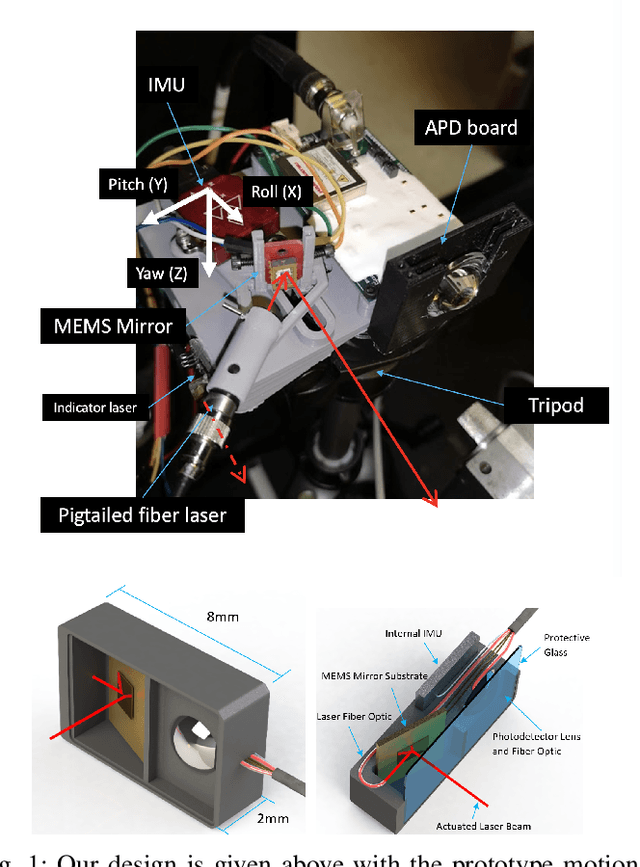
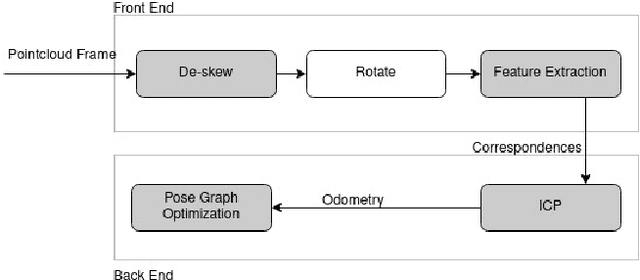
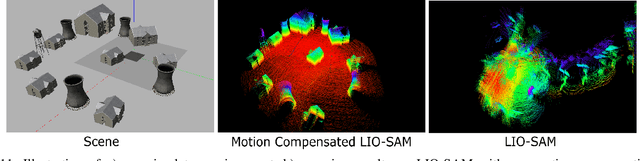
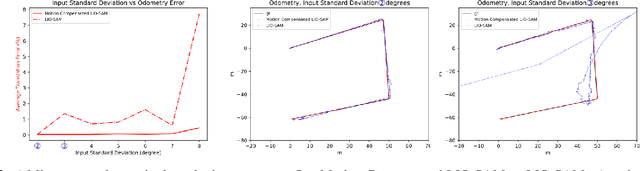
A fundamental challenge in robot perception is the coupling of the sensor pose and robot pose. This has led to research in active vision where robot pose is changed to reorient the sensor to areas of interest for perception. Further, egomotion such as jitter, and external effects such as wind and others affect perception requiring additional effort in software such as image stabilization. This effect is particularly pronounced in micro-air vehicles and micro-robots who typically are lighter and subject to larger jitter but do not have the computational capability to perform stabilization in real-time. We present a novel microelectromechanical (MEMS) mirror LiDAR system to change the field of view of the LiDAR independent of the robot motion. Our design has the potential for use on small, low-power systems where the expensive components of the LiDAR can be placed external to the small robot. We show the utility of our approach in simulation and on prototype hardware mounted on a UAV. We believe that this LiDAR and its compact movable scanning design provide mechanisms to decouple robot and sensor geometry allowing us to simplify robot perception. We also demonstrate examples of motion compensation using IMU and external odometry feedback in hardware.
Memory-aided Contrastive Consensus Learning for Co-salient Object Detection
Feb 28, 2023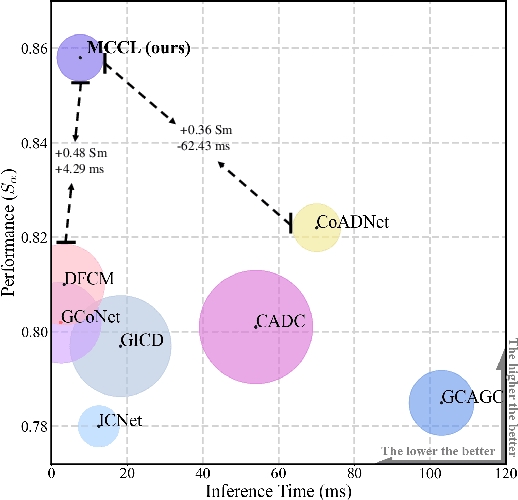
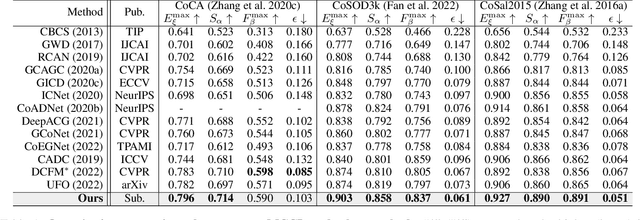
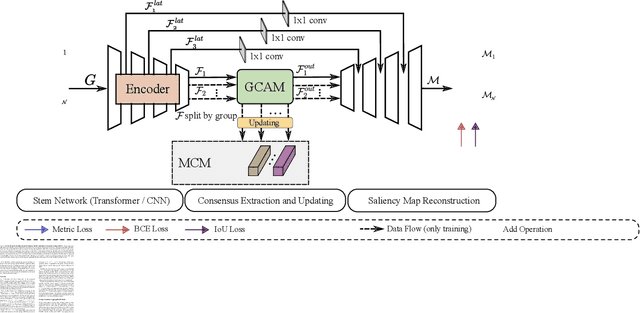

Co-Salient Object Detection (CoSOD) aims at detecting common salient objects within a group of relevant source images. Most of the latest works employ the attention mechanism for finding common objects. To achieve accurate CoSOD results with high-quality maps and high efficiency, we propose a novel Memory-aided Contrastive Consensus Learning (MCCL) framework, which is capable of effectively detecting co-salient objects in real time (~110 fps). To learn better group consensus, we propose the Group Consensus Aggregation Module (GCAM) to abstract the common features of each image group; meanwhile, to make the consensus representation more discriminative, we introduce the Memory-based Contrastive Module (MCM), which saves and updates the consensus of images from different groups in a queue of memories. Finally, to improve the quality and integrity of the predicted maps, we develop an Adversarial Integrity Learning (AIL) strategy to make the segmented regions more likely composed of complete objects with less surrounding noise. Extensive experiments on all the latest CoSOD benchmarks demonstrate that our lite MCCL outperforms 13 cutting-edge models, achieving the new state of the art (~5.9% and ~6.2% improvement in S-measure on CoSOD3k and CoSal2015, respectively). Our source codes, saliency maps, and online demos are publicly available at https://github.com/ZhengPeng7/MCCL.
Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
Feb 24, 2023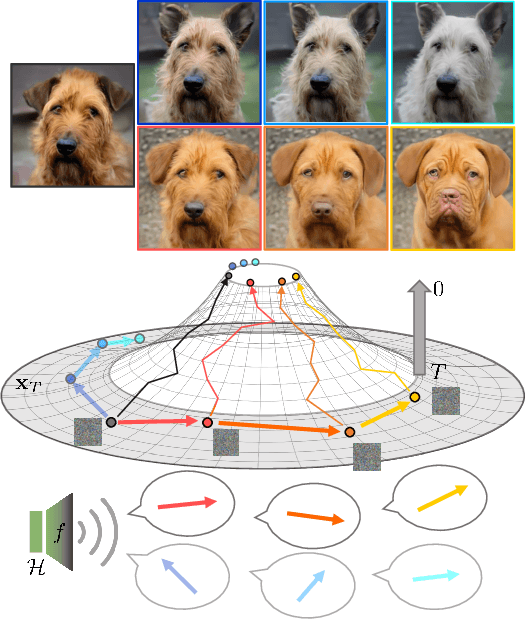
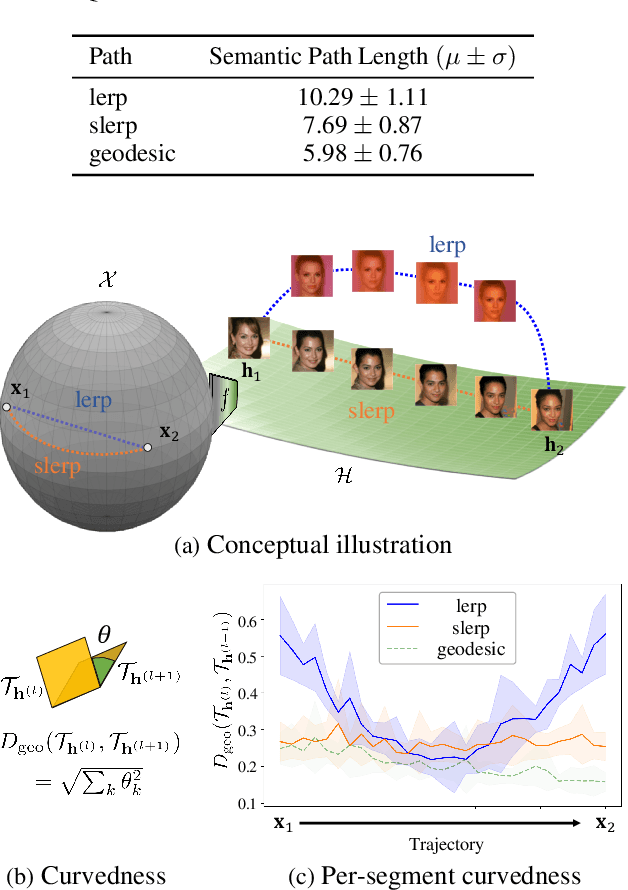


Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. While image editing with GANs builds upon latent space, DMs rely on editing the conditions such as text prompts. We present an unsupervised method to discover interpretable editing directions for the latent variables $\mathbf{x}_t \in \mathcal{X}$ of DMs. Our method adopts Riemannian geometry between $\mathcal{X}$ and the intermediate feature maps $\mathcal{H}$ of the U-Nets to provide a deep understanding over the geometrical structure of $\mathcal{X}$. The discovered semantic latent directions mostly yield disentangled attribute changes, and they are globally consistent across different samples. Furthermore, editing in earlier timesteps edits coarse attributes, while ones in later timesteps focus on high-frequency details. We define the curvedness of a line segment between samples to show that $\mathcal{X}$ is a curved manifold. Experiments on different baselines and datasets demonstrate the effectiveness of our method even on Stable Diffusion. Our source code will be publicly available for the future researchers.
HST: Hierarchical Swin Transformer for Compressed Image Super-resolution
Aug 21, 2022

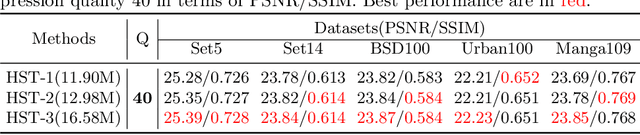
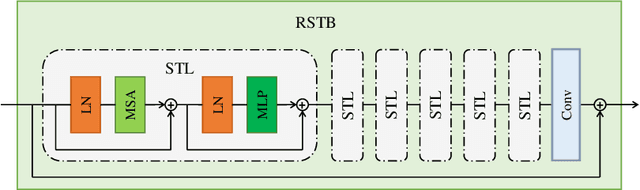
Compressed Image Super-resolution has achieved great attention in recent years, where images are degraded with compression artifacts and low-resolution artifacts. Since the complex hybrid distortions, it is hard to restore the distorted image with the simple cooperation of super-resolution and compression artifacts removing. In this paper, we take a step forward to propose the Hierarchical Swin Transformer (HST) network to restore the low-resolution compressed image, which jointly captures the hierarchical feature representations and enhances each-scale representation with Swin transformer, respectively. Moreover, we find that the pretraining with Super-resolution (SR) task is vital in compressed image super-resolution. To explore the effects of different SR pretraining, we take the commonly-used SR tasks (e.g., bicubic and different real super-resolution simulations) as our pretraining tasks, and reveal that SR plays an irreplaceable role in the compressed image super-resolution. With the cooperation of HST and pre-training, our HST achieves the fifth place in AIM 2022 challenge on the low-quality compressed image super-resolution track, with the PSNR of 23.51dB. Extensive experiments and ablation studies have validated the effectiveness of our proposed methods.