 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Oversampling for Imbalanced Data via Majority-Guided VAE
Feb 14, 2023
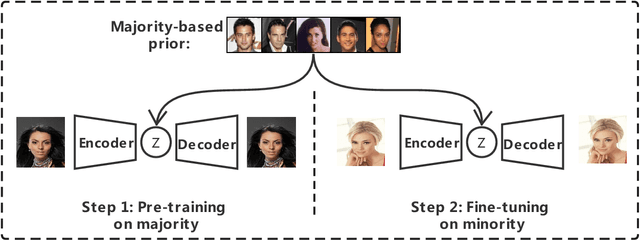
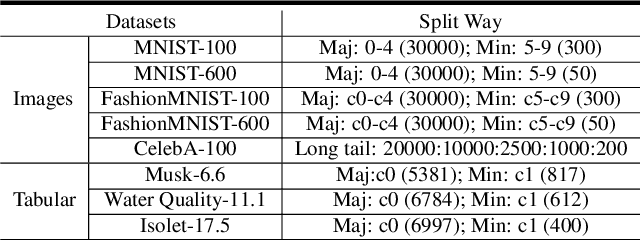

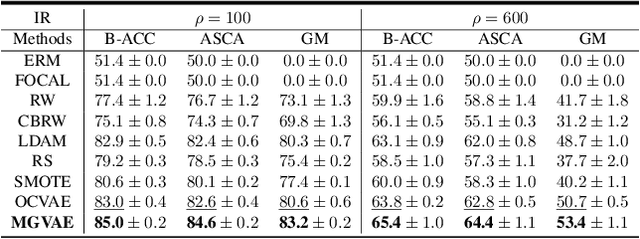
Learning with imbalanced data is a challenging problem in deep learning. Over-sampling is a widely used technique to re-balance the sampling distribution of training data. However, most existing over-sampling methods only use intra-class information of minority classes to augment the data but ignore the inter-class relationships with the majority ones, which is prone to overfitting, especially when the imbalance ratio is large. To address this issue, we propose a novel over-sampling model, called Majority-Guided VAE~(MGVAE), which generates new minority samples under the guidance of a majority-based prior. In this way, the newly generated minority samples can inherit the diversity and richness of the majority ones, thus mitigating overfitting in downstream tasks. Furthermore, to prevent model collapse under limited data, we first pre-train MGVAE on sufficient majority samples and then fine-tune based on minority samples with Elastic Weight Consolidation(EWC) regularization. Experimental results on benchmark image datasets and real-world tabular data show that MGVAE achieves competitive improvements over other over-sampling methods in downstream classification tasks, demonstrating the effectiveness of our method.
Bilateral-Fuser: A Novel Multi-cue Fusion Architecture with Anatomical-aware Tokens for Fovea Localization
Feb 14, 2023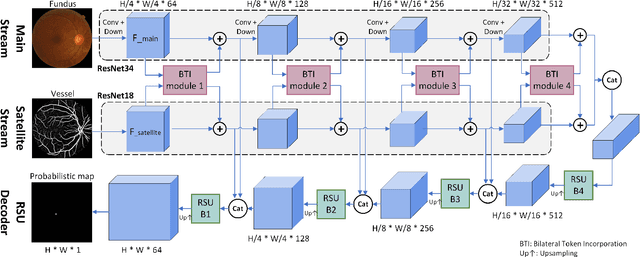
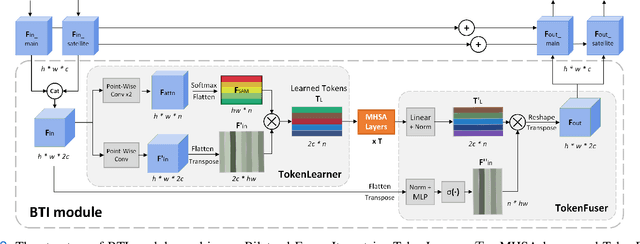
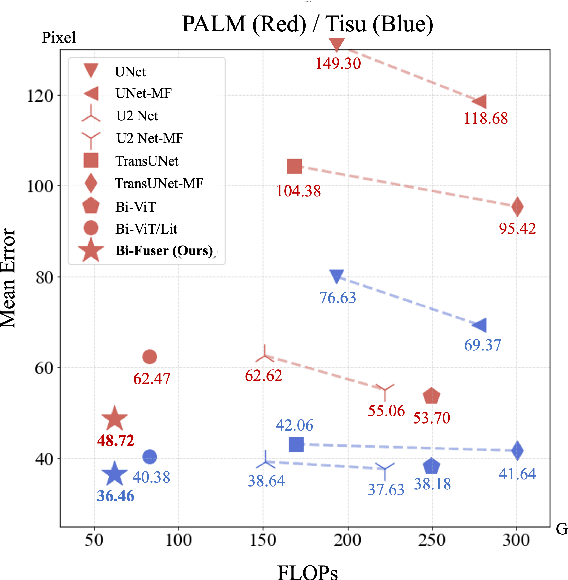
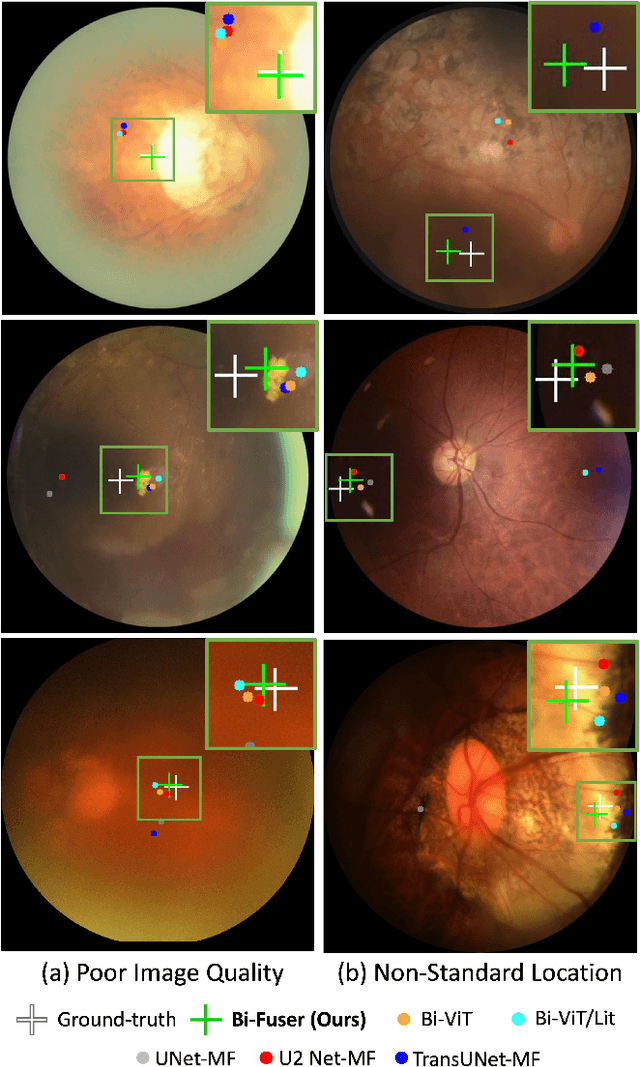
Accurate localization of fovea is one of the primary steps in analyzing retinal diseases since it helps prevent irreversible vision loss. Although current deep learning-based methods achieve better performance than traditional methods, there still remain challenges such as utilizing anatomical landmarks insufficiently, sensitivity to diseased retinal images and various image conditions. In this paper, we propose a novel transformer-based architecture (Bilateral-Fuser) for multi-cue fusion. This architecture explicitly incorporates long-range connections and global features using retina and vessel distributions for robust fovea localization. We introduce a spatial attention mechanism in the dual-stream encoder for extracting and fusing self-learned anatomical information. This design focuses more on features distributed along blood vessels and significantly decreases computational costs by reducing token numbers. Our comprehensive experiments show that the proposed architecture achieves state-of-the-art performance on two public and one large-scale private datasets. We also present that the Bilateral-Fuser is more robust on both normal and diseased retina images and has better generalization capacity in cross-dataset experiments.
Visibility-Aware Pixelwise View Selection for Multi-View Stereo Matching
Feb 14, 2023The performance of PatchMatch-based multi-view stereo algorithms depends heavily on the source views selected for computing matching costs. Instead of modeling the visibility of different views, most existing approaches handle occlusions in an ad-hoc manner. To address this issue, we propose a novel visibility-guided pixelwise view selection scheme in this paper. It progressively refines the set of source views to be used for each pixel in the reference view based on visibility information provided by already validated solutions. In addition, the Artificial Multi-Bee Colony (AMBC) algorithm is employed to search for optimal solutions for different pixels in parallel. Inter-colony communication is performed both within the same image and among different images. Fitness rewards are added to validated and propagated solutions, effectively enforcing the smoothness of neighboring pixels and allowing better handling of textureless areas. Experimental results on the DTU dataset show our method achieves state-of-the-art performance among non-learning-based methods and retrieves more details in occluded and low-textured regions.
Echocardiographic Image Quality Assessment Using Deep Neural Networks
Sep 02, 2022Echocardiography image quality assessment is not a trivial issue in transthoracic examination. As the in vivo examination of heart structures gained prominence in cardiac diagnosis, it has been affirmed that accurate diagnosis of the left ventricle functions is hugely dependent on the quality of echo images. Up till now, visual assessment of echo images is highly subjective and requires specific definition under clinical pathologies. While poor-quality images impair quantifications and diagnosis, the inherent variations in echocardiographic image quality standards indicates the complexity faced among different observers and provides apparent evidence for incoherent assessment under clinical trials, especially with less experienced cardiologists. In this research, our aim was to analyse and define specific quality attributes mostly discussed by experts and present a fully trained convolutional neural network model for assessing such quality features objectively.
Exploring the Representation Manifolds of Stable Diffusion Through the Lens of Intrinsic Dimension
Feb 16, 2023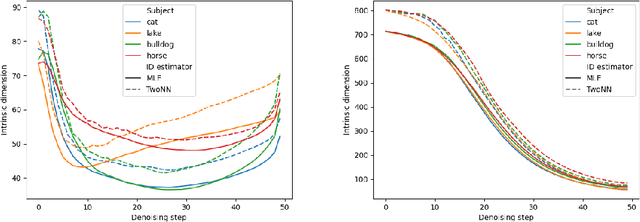
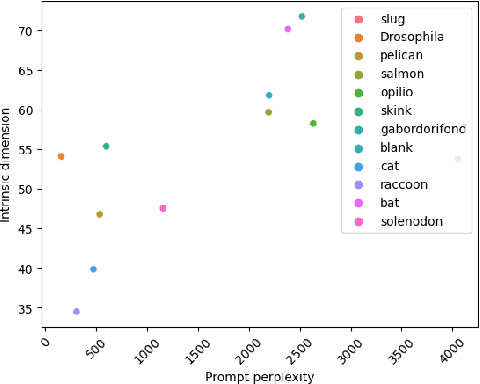
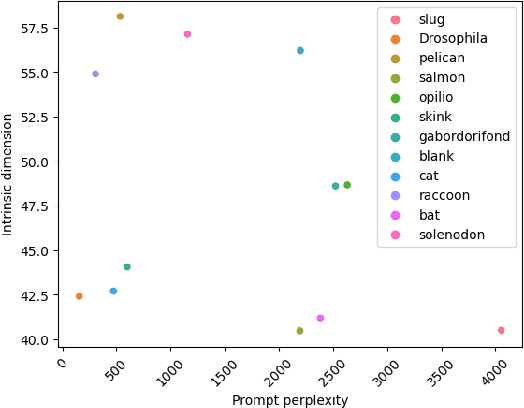
Prompting has become an important mechanism by which users can more effectively interact with many flavors of foundation model. Indeed, the last several years have shown that well-honed prompts can sometimes unlock emergent capabilities within such models. While there has been a substantial amount of empirical exploration of prompting within the community, relatively few works have studied prompting at a mathematical level. In this work we aim to take a first step towards understanding basic geometric properties induced by prompts in Stable Diffusion, focusing on the intrinsic dimension of internal representations within the model. We find that choice of prompt has a substantial impact on the intrinsic dimension of representations at both layers of the model which we explored, but that the nature of this impact depends on the layer being considered. For example, in certain bottleneck layers of the model, intrinsic dimension of representations is correlated with prompt perplexity (measured using a surrogate model), while this correlation is not apparent in the latent layers. Our evidence suggests that intrinsic dimension could be a useful tool for future studies of the impact of different prompts on text-to-image models.
Visible-Infrared Person Re-Identification via Patch-Mixed Cross-Modality Learning
Feb 16, 2023
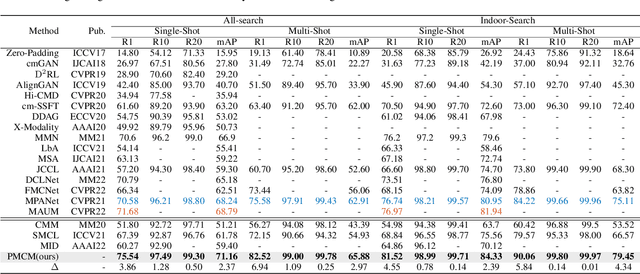
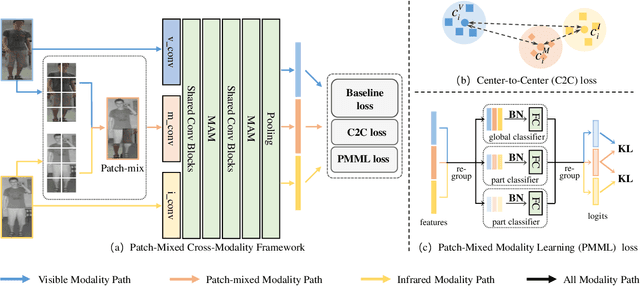
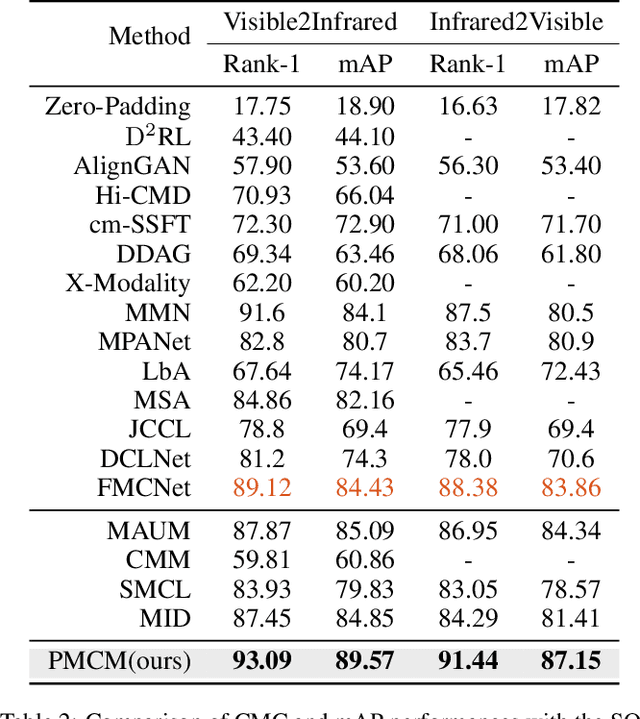
Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same pedestrian from different modalities, where the challenges lie in the significant modality discrepancy. To alleviate the modality gap, recent methods generate intermediate images by GANs, grayscaling, or mixup strategies. However, these methods could ntroduce extra noise, and the semantic correspondence between the two modalities is not well learned. In this paper, we propose a Patch-Mixed Cross-Modality framework (PMCM), where two images of the same person from two modalities are split into patches and stitched into a new one for model learning. In this way, the modellearns to recognize a person through patches of different styles, and the modality semantic correspondence is directly embodied. With the flexible image generation strategy, the patch-mixed images freely adjust the ratio of different modality patches, which could further alleviate the modality imbalance problem. In addition, the relationship between identity centers among modalities is explored to further reduce the modality variance, and the global-to-part constraint is introduced to regularize representation learning of part features. On two VI-ReID datasets, we report new state-of-the-art performance with the proposed method.
Revisiting Hidden Representations in Transfer Learning for Medical Imaging
Feb 16, 2023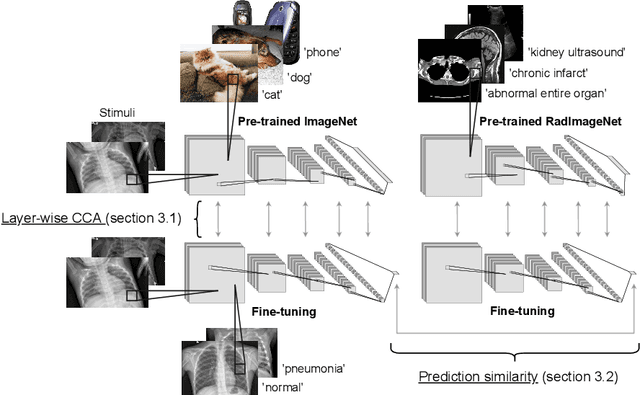
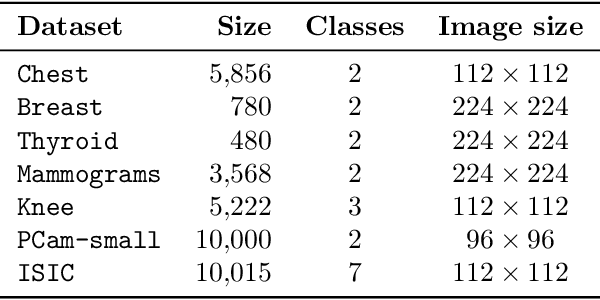

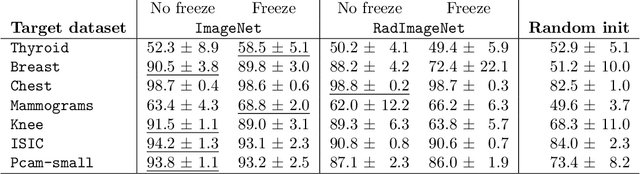
While a key component to the success of deep learning is the availability of massive amounts of training data, medical image datasets are often limited in diversity and size. Transfer learning has the potential to bridge the gap between related yet different domains. For medical applications, however, it remains unclear whether it is more beneficial to pre-train on natural or medical images. We aim to shed light on this problem by comparing initialization on ImageNet and RadImageNet on seven medical classification tasks. We investigate their learned representations with Canonical Correlation Analysis (CCA) and compare the predictions of the different models. We find that overall the models pre-trained on ImageNet outperform those trained on RadImageNet. Our results show that, contrary to intuition, ImageNet and RadImageNet converge to distinct intermediate representations, and that these representations are even more dissimilar after fine-tuning. Despite these distinct representations, the predictions of the models remain similar. Our findings challenge the notion that transfer learning is effective due to the reuse of general features in the early layers of a convolutional neural network and show that weight similarity before and after fine-tuning is negatively related to performance gains.
Detecting Clouds in Multispectral Satellite Images Using Quantum-Kernel Support Vector Machines
Feb 16, 2023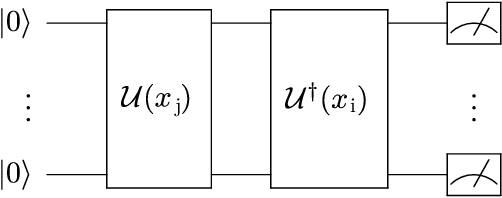
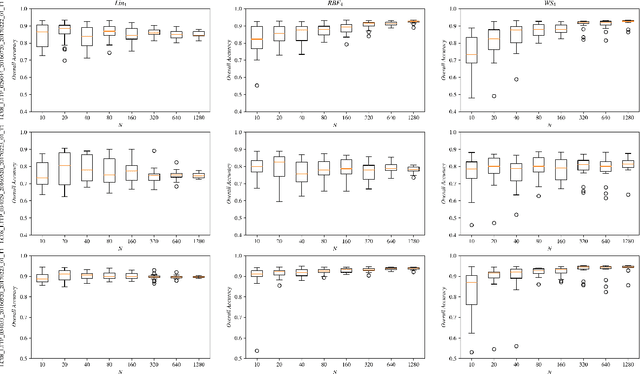

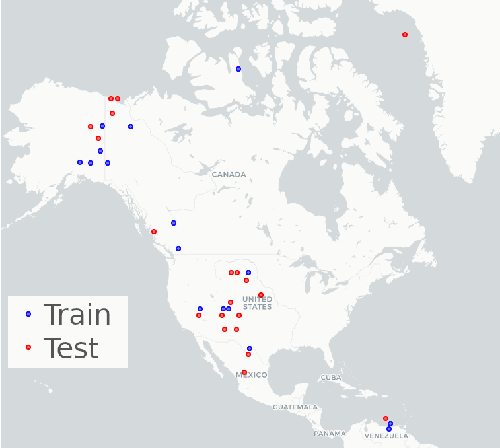
Support vector machines (SVMs) are a well-established classifier effectively deployed in an array of classification tasks. In this work, we consider extending classical SVMs with quantum kernels and applying them to satellite data analysis. The design and implementation of SVMs with quantum kernels (hybrid SVMs) are presented. Here, the pixels are mapped to the Hilbert space using a family of parameterized quantum feature maps (related to quantum kernels). The parameters are optimized to maximize the kernel target alignment. The quantum kernels have been selected such that they enabled analysis of numerous relevant properties while being able to simulate them with classical computers on a real-life large-scale dataset. Specifically, we approach the problem of cloud detection in the multispectral satellite imagery, which is one of the pivotal steps in both on-the-ground and on-board satellite image analysis processing chains. The experiments performed over the benchmark Landsat-8 multispectral dataset revealed that the simulated hybrid SVM successfully classifies satellite images with accuracy comparable to the classical SVM with the RBF kernel for large datasets. Interestingly, for large datasets, the high accuracy was also observed for the simple quantum kernels, lacking quantum entanglement.
Vision-Based Terrain Relative Navigation on High-Altitude Balloon and Sub-Orbital Rocket
Feb 16, 2023
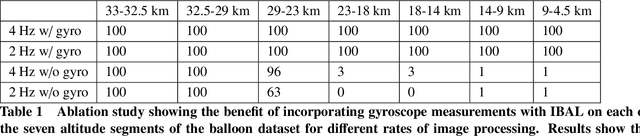


We present an experimental analysis on the use of a camera-based approach for high-altitude navigation by associating mapped landmarks from a satellite image database to camera images, and by leveraging inertial sensors between camera frames. We evaluate performance of both a sideways-tilted and downward-facing camera on data collected from a World View Enterprises high-altitude balloon with data beginning at an altitude of 33 km and descending to near ground level (4.5 km) with 1.5 hours of flight time. We demonstrate less than 290 meters of average position error over a trajectory of more than 150 kilometers. In addition to showing performance across a range of altitudes, we also demonstrate the robustness of the Terrain Relative Navigation (TRN) method to rapid rotations of the balloon, in some cases exceeding 20 degrees per second, and to camera obstructions caused by both cloud coverage and cords swaying underneath the balloon. Additionally, we evaluate performance on data collected by two cameras inside the capsule of Blue Origin's New Shepard rocket on payload flight NS-23, traveling at speeds up to 880 km/hr, and demonstrate less than 55 meters of average position error.
* Published in 2023 AIAA SciTech
Estimating Appearance Models for Image Segmentation via Tensor Factorization
Aug 16, 2022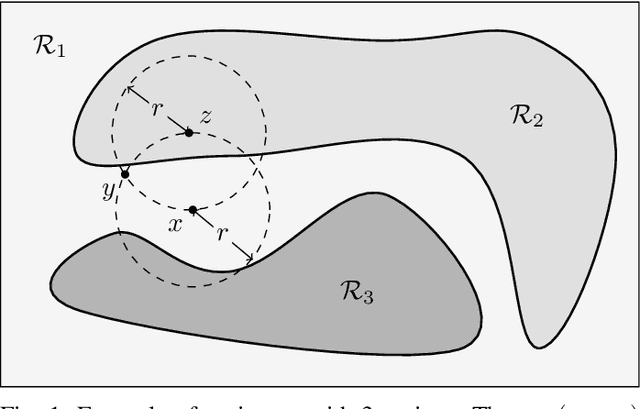
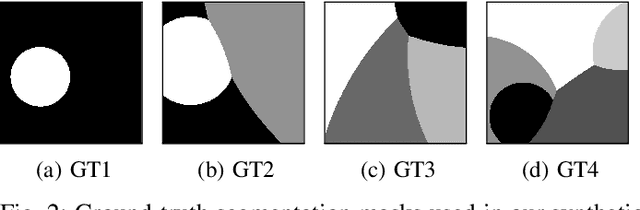

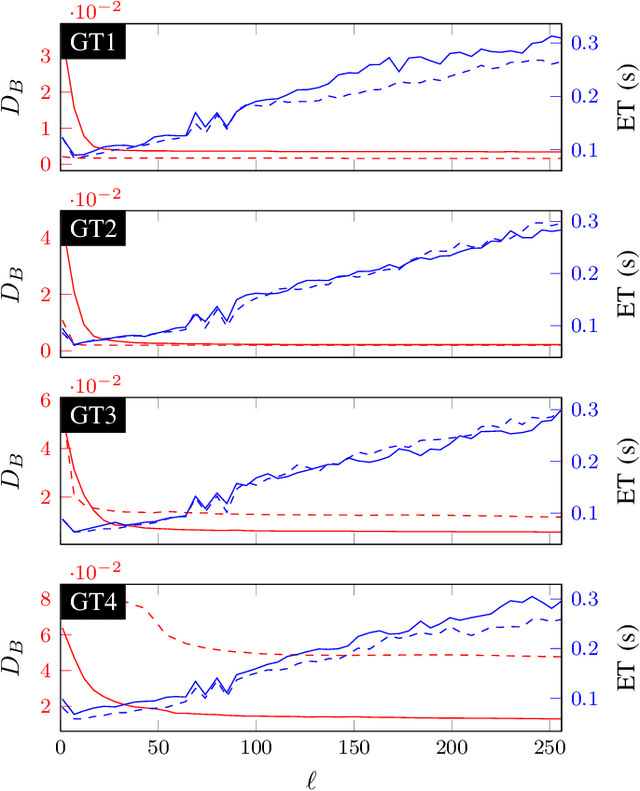
Image Segmentation is one of the core tasks in Computer Vision and solving it often depends on modeling the image appearance data via the color distributions of each it its constituent regions. Whereas many segmentation algorithms handle the appearance models dependence using alternation or implicit methods, we propose here a new approach to directly estimate them from the image without prior information on the underlying segmentation. Our method uses local high order color statistics from the image as an input to tensor factorization-based estimator for latent variable models. This approach is able to estimate models in multiregion images and automatically output the regions proportions without prior user interaction, overcoming the drawbacks from a prior attempt to this problem. We also demonstrate the performance of our proposed method in many challenging synthetic and real imaging scenarios and show that it leads to an efficient segmentation algorithm.