 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extensions to Generalized Annotated Logic and an Equivalent Neural Architecture
Feb 23, 2023

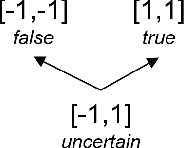
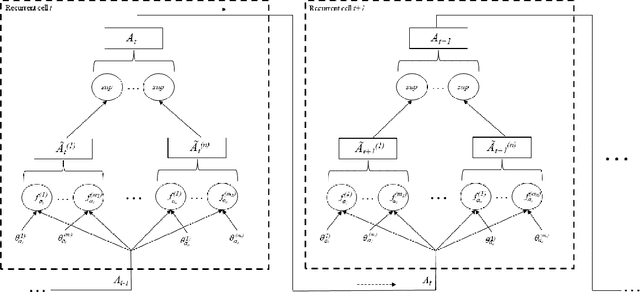
While deep neural networks have led to major advances in image recognition, language translation, data mining, and game playing, there are well-known limits to the paradigm such as lack of explainability, difficulty of incorporating prior knowledge, and modularity. Neuro symbolic hybrid systems have recently emerged as a straightforward way to extend deep neural networks by incorporating ideas from symbolic reasoning such as computational logic. In this paper, we propose a list desirable criteria for neuro symbolic systems and examine how some of the existing approaches address these criteria. We then propose an extension to generalized annotated logic that allows for the creation of an equivalent neural architecture comprising an alternate neuro symbolic hybrid. However, unlike previous approaches that rely on continuous optimization for the training process, our framework is designed as a binarized neural network that uses discrete optimization. We provide proofs of correctness and discuss several of the challenges that must be overcome to realize this framework in an implemented system.
Deep Age-Invariant Fingerprint Segmentation System
Mar 06, 2023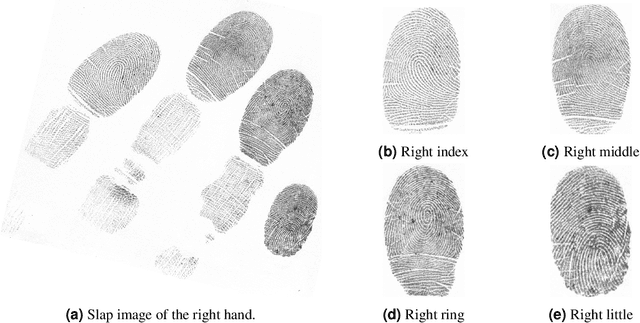

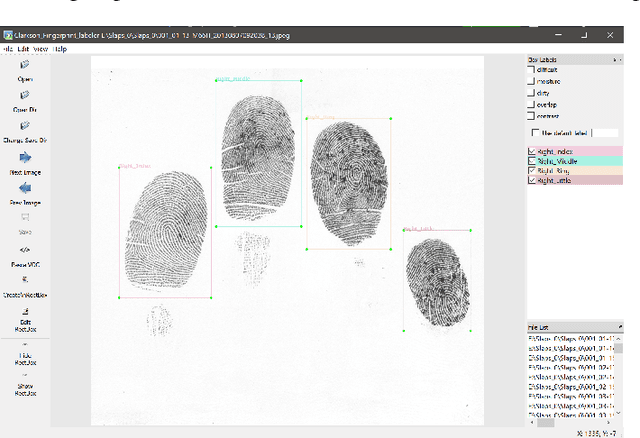

Fingerprint-based identification systems achieve higher accuracy when a slap containing multiple fingerprints of a subject is used instead of a single fingerprint. However, segmenting or auto-localizing all fingerprints in a slap image is a challenging task due to the different orientations of fingerprints, noisy backgrounds, and the smaller size of fingertip components. The presence of slap images in a real-world dataset where one or more fingerprints are rotated makes it challenging for a biometric recognition system to localize and label the fingerprints automatically. Improper fingerprint localization and finger labeling errors lead to poor matching performance. In this paper, we introduce a method to generate arbitrary angled bounding boxes using a deep learning-based algorithm that precisely localizes and labels fingerprints from both axis-aligned and over-rotated slap images. We built a fingerprint segmentation model named CRFSEG (Clarkson Rotated Fingerprint segmentation Model) by updating the previously proposed CFSEG model which was based on traditional Faster R-CNN architecture [21]. CRFSEG improves upon the Faster R-CNN algorithm with arbitrarily angled bounding boxes that allow the CRFSEG to perform better in challenging slap images. After training the CRFSEG algorithm on a new dataset containing slap images collected from both adult and children subjects, our results suggest that the CRFSEG model was invariant across different age groups and can handle over-rotated slap images successfully. In the Combined dataset containing both normal and rotated images of adult and children subjects, we achieved a matching accuracy of 97.17%, which outperformed state-of-the-art VeriFinger (94.25%) and NFSEG segmentation systems (80.58%).
A Unified Algebraic Perspective on Lipschitz Neural Networks
Mar 06, 2023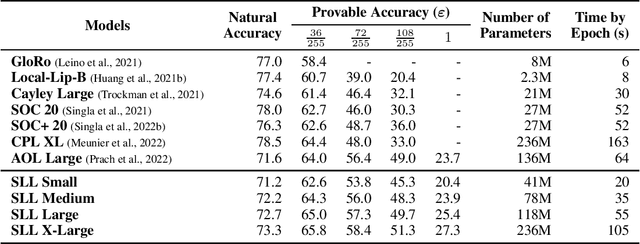
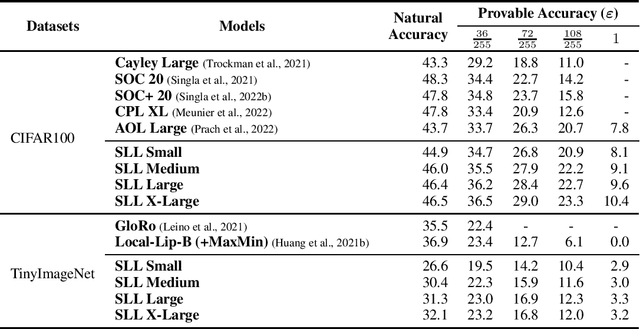
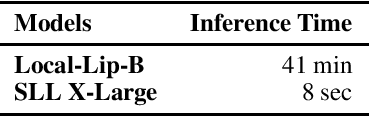
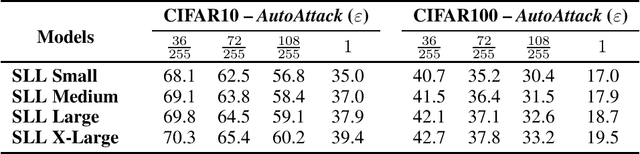
Important research efforts have focused on the design and training of neural networks with a controlled Lipschitz constant. The goal is to increase and sometimes guarantee the robustness against adversarial attacks. Recent promising techniques draw inspirations from different backgrounds to design 1-Lipschitz neural networks, just to name a few: convex potential layers derive from the discretization of continuous dynamical systems, Almost-Orthogonal-Layer proposes a tailored method for matrix rescaling. However, it is today important to consider the recent and promising contributions in the field under a common theoretical lens to better design new and improved layers. This paper introduces a novel algebraic perspective unifying various types of 1-Lipschitz neural networks, including the ones previously mentioned, along with methods based on orthogonality and spectral methods. Interestingly, we show that many existing techniques can be derived and generalized via finding analytical solutions of a common semidefinite programming (SDP) condition. We also prove that AOL biases the scaled weight to the ones which are close to the set of orthogonal matrices in a certain mathematical manner. Moreover, our algebraic condition, combined with the Gershgorin circle theorem, readily leads to new and diverse parameterizations for 1-Lipschitz network layers. Our approach, called SDP-based Lipschitz Layers (SLL), allows us to design non-trivial yet efficient generalization of convex potential layers. Finally, the comprehensive set of experiments on image classification shows that SLLs outperform previous approaches on certified robust accuracy. Code is available at https://github.com/araujoalexandre/Lipschitz-SLL-Networks.
Preconditioned Score-based Generative Models
Feb 13, 2023
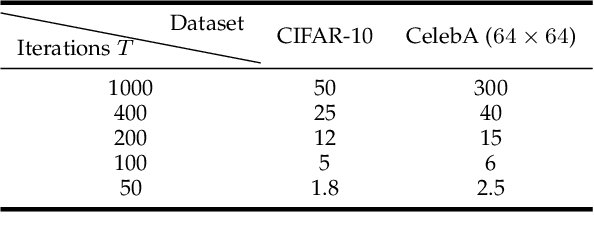
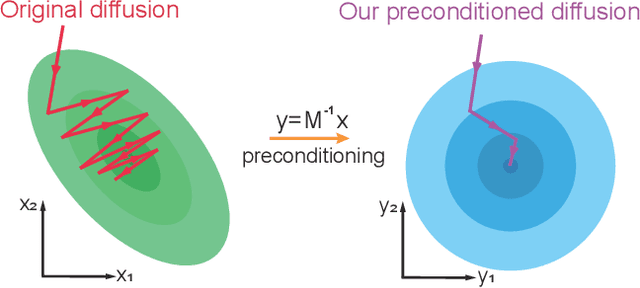

Score-based generative models (SGMs) have recently emerged as a promising class of generative models. However, a fundamental limitation is that their sampling process is slow due to a need for many (\eg, $2000$) iterations of sequential computations. An intuitive acceleration method is to reduce the sampling iterations which however causes severe performance degradation. We assault this problem to the ill-conditioned issues of the Langevin dynamics and reverse diffusion in the sampling process. Under this insight, we propose a model-agnostic {\bf\em preconditioned diffusion sampling} (PDS) method that leverages matrix preconditioning to alleviate the aforementioned problem. PDS alters the sampling process of a vanilla SGM at marginal extra computation cost, and without model retraining. Theoretically, we prove that PDS preserves the output distribution of the SGM, no risk of inducing systematical bias to the original sampling process. We further theoretically reveal a relation between the parameter of PDS and the sampling iterations,easing the parameter estimation under varying sampling iterations. Extensive experiments on various image datasets with a variety of resolutions and diversity validate that our PDS consistently accelerates off-the-shelf SGMs whilst maintaining the synthesis quality. In particular, PDS can accelerate by up to $29\times$ on more challenging high resolution (1024$\times$1024) image generation. Compared with the latest generative models (\eg, CLD-SGM, DDIM, and Analytic-DDIM), PDS can achieve the best sampling quality on CIFAR-10 at a FID score of 1.99. Our code is made publicly available to foster any further research https://github.com/fudan-zvg/PDS.
Has the Virtualization of the Face Changed Facial Perception? A Study of the Impact of Augmented Reality on Facial Perception
Mar 01, 2023
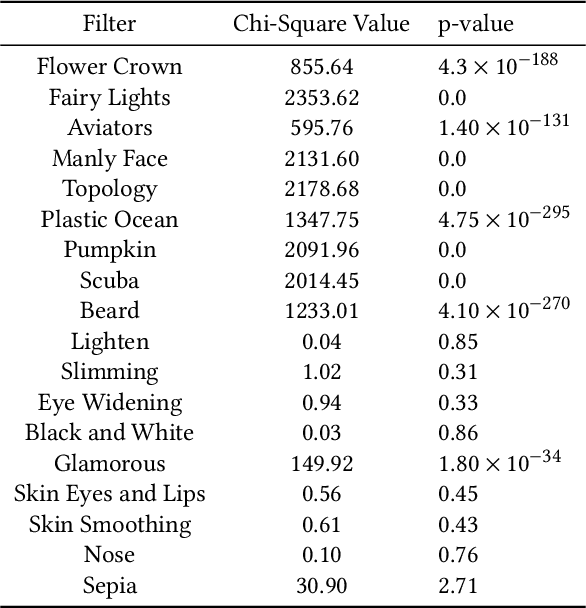

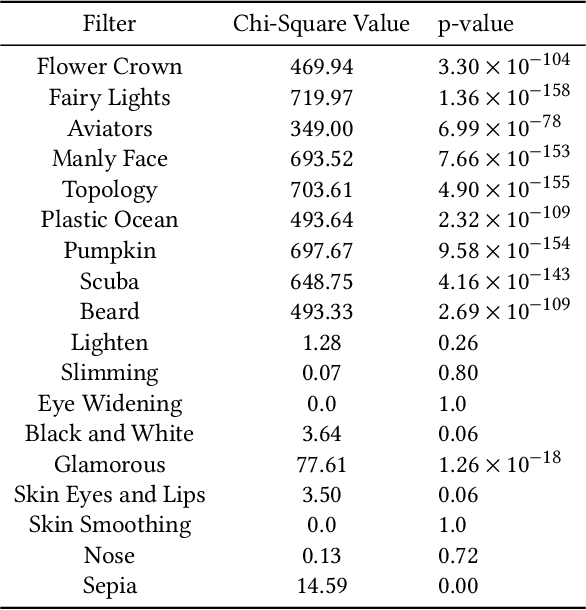
Augmented reality and other photo editing filters are popular methods used to modify images, especially images of faces, posted online. Considering the important role of human facial perception in social communication, how does exposure to an increasing number of modified faces online affect human facial perception? In this paper we present the results of six surveys designed to measure familiarity with different styles of facial filters, perceived strangeness of faces edited with different facial filters, and ability to discern whether images are filtered or not. Our results indicate that faces filtered with photo editing filters that change the image color tones, modify facial structure, or add facial beautification tend to be perceived similarly to unmodified faces; however, faces filtered with augmented reality filters (\textit{i.e.,} filters that overlay digital objects) are perceived differently from unmodified faces. We also found that responses differed based on different survey question phrasings, indicating that the shift in facial perception due to the prevalence of filtered images is noisy to detect. A better understanding of shifts in facial perception caused by facial filters will help us build online spaces more responsibly and could inform the training of more accurate and equitable facial recognition models, especially those trained with human psychophysical annotations.
Uncertainty-Aware Unsupervised Image Deblurring with Deep Priors Guided by Domain Knowledge
Oct 09, 2022
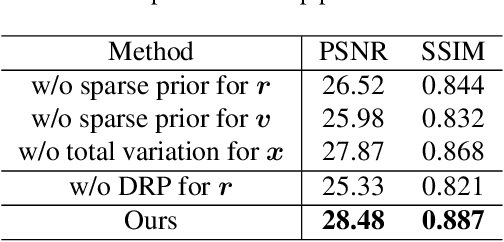

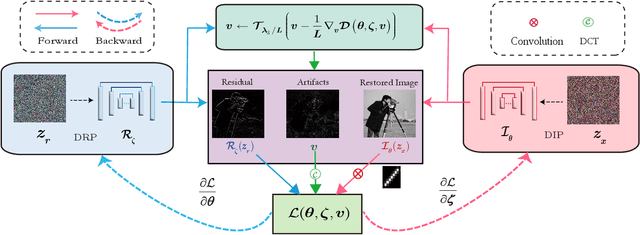
Non-blind deblurring methods achieve decent performance under the accurate blur kernel assumption. Since the kernel error is inevitable in practice, ringing artifacts are often introduced by non-blind deblurring. Recently, semi-blind deblurring methods can handle kernel uncertainty by introducing the prior of the kernel (or induced) error. However, how to design a suitable prior for the kernel (or induced) error remains challenging. Hand-crafted prior, incorporating domain knowledge, generally performs well but may lead to poor performance when kernel (or induced) error is complex. Data-driven prior, which excessively depends on the diversity and abundance of training data, is vulnerable to out-of-distribution blurs and images. To address this challenge, we suggest a data-free deep prior for the kernel induced error (termed as residual) expressed by a customized untrained deep neural network, which allows us to flexibly adapt to different blurs and images in real scenarios. By organically integrating the respective strengths of deep priors and hand-crafted priors, we propose an unsupervised semi-blind deblurring model which recovers the latent image from the blurry image and inaccurate blur kernel. To tackle the formulated model, an efficient alternating minimization algorithm is developed. Extensive experiments demonstrate the superiority of the proposed method to both data-driven prior and hand-crafted prior based methods in terms of the image quality and the robustness to the kernel error.
Street-View Image Generation from a Bird's-Eye View Layout
Jan 16, 2023
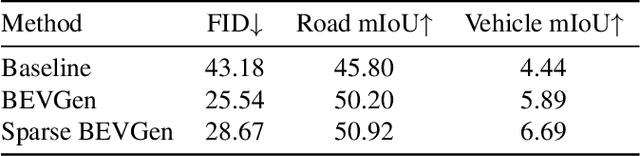
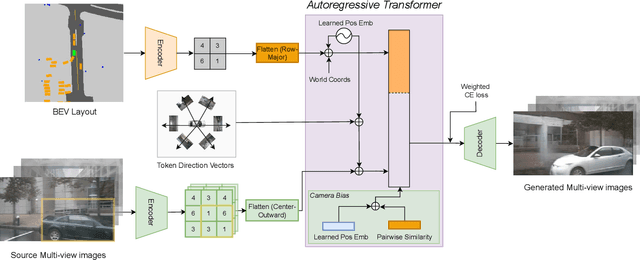

Bird's-Eye View (BEV) Perception has received increasing attention in recent years as it provides a concise and unified spatial representation across views and benefits a diverse set of downstream driving applications. While the focus has been placed on discriminative tasks such as BEV segmentation, the dual generative task of creating street-view images from a BEV layout has rarely been explored. The ability to generate realistic street-view images that align with a given HD map and traffic layout is critical for visualizing complex traffic scenarios and developing robust perception models for autonomous driving. In this paper, we propose BEVGen, a conditional generative model that synthesizes a set of realistic and spatially consistent surrounding images that match the BEV layout of a traffic scenario. BEVGen incorporates a novel cross-view transformation and spatial attention design which learn the relationship between cameras and map views to ensure their consistency. Our model can accurately render road and lane lines, as well as generate traffic scenes under different weather conditions and times of day. The code will be made publicly available.
ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training
Sep 30, 2022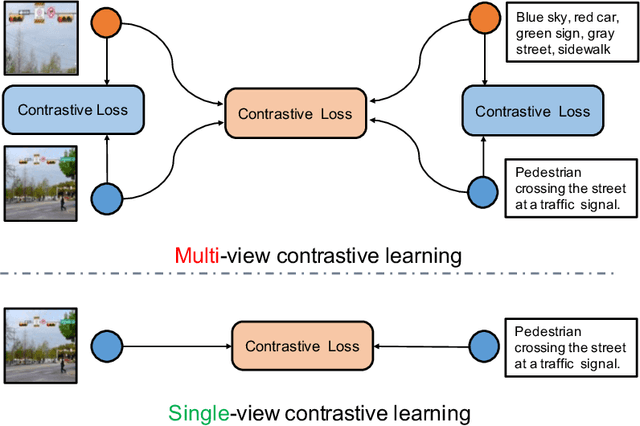
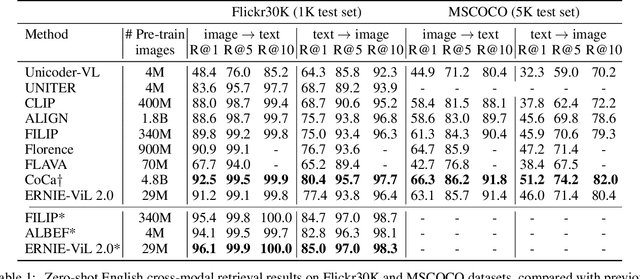
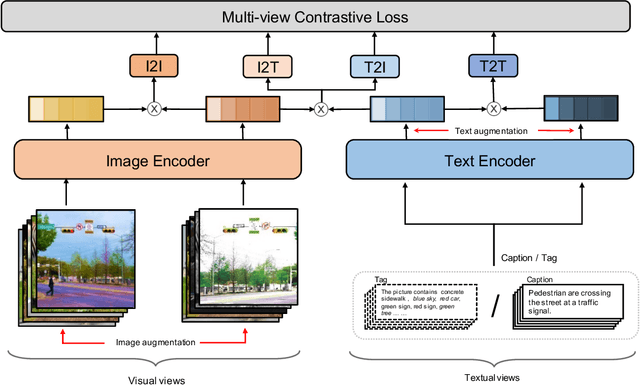
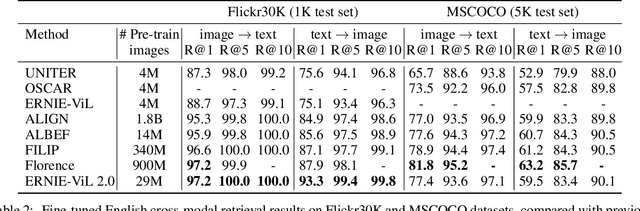
Recent Vision-Language Pre-trained (VLP) models based on dual encoder have attracted extensive attention from academia and industry due to their superior performance on various cross-modal tasks and high computational efficiency. They attempt to learn cross-modal representation using contrastive learning on image-text pairs, however, the built inter-modal correlations only rely on a single view for each modality. Actually, an image or a text contains various potential views, just as humans could capture a real-world scene via diverse descriptions or photos. In this paper, we propose ERNIE-ViL 2.0, a Multi-View Contrastive learning framework to build intra-modal and inter-modal correlations between diverse views simultaneously, aiming at learning a more robust cross-modal representation. Specifically, we construct multiple views within each modality to learn the intra-modal correlation for enhancing the single-modal representation. Besides the inherent visual/textual views, we construct sequences of object tags as a special textual view to narrow the cross-modal semantic gap on noisy image-text pairs. Pre-trained with 29M publicly available datasets, ERNIE-ViL 2.0 achieves competitive results on English cross-modal retrieval. Additionally, to generalize our method to Chinese cross-modal tasks, we train ERNIE-ViL 2.0 through scaling up the pre-training datasets to 1.5B Chinese image-text pairs, resulting in significant improvements compared to previous SOTA results on Chinese cross-modal retrieval. We release our pre-trained models in https://github.com/PaddlePaddle/ERNIE.
DGP-Net: Dense Graph Prototype Network for Few-Shot SAR Target Recognition
Feb 19, 2023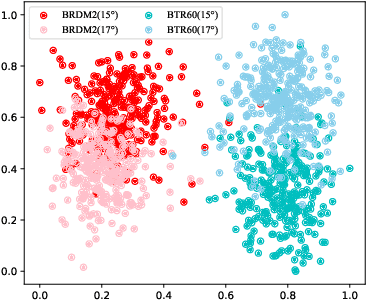
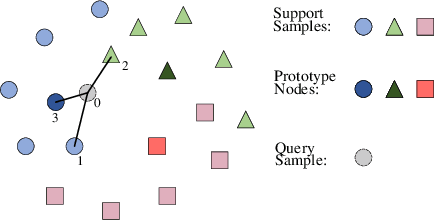
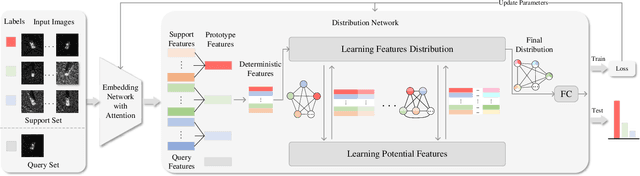
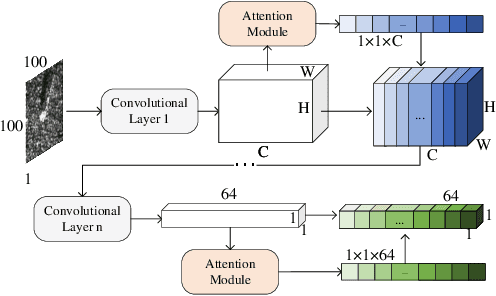
The inevitable feature deviation of synthetic aperture radar (SAR) image due to the special imaging principle (depression angle variation) leads to poor recognition accuracy, especially in few-shot learning (FSL). To deal with this problem, we propose a dense graph prototype network (DGP-Net) to eliminate the feature deviation by learning potential features, and classify by learning feature distribution. The role of the prototype in this model is to solve the problem of large distance between congeneric samples taken due to the contingency of single sampling in FSL, and enhance the robustness of the model. Experimental results on the MSTAR dataset show that the DGP-Net has good classification results for SAR images with different depression angles and the recognition accuracy of it is higher than typical FSL methods.
Aligning Bag of Regions for Open-Vocabulary Object Detection
Feb 27, 2023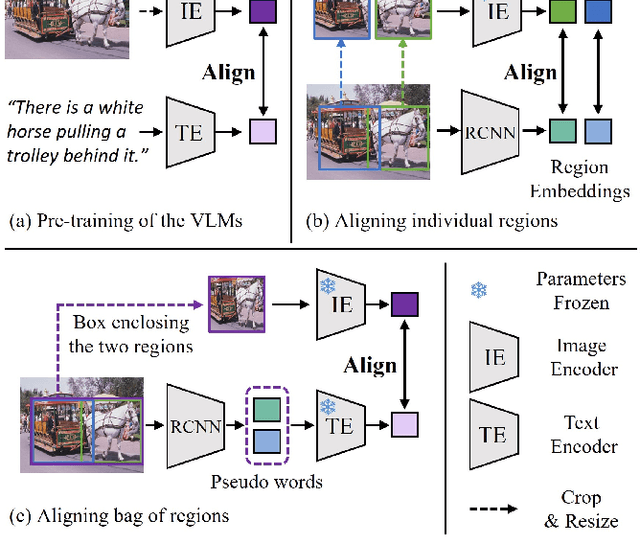

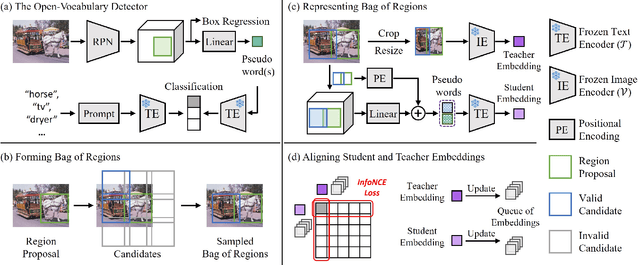
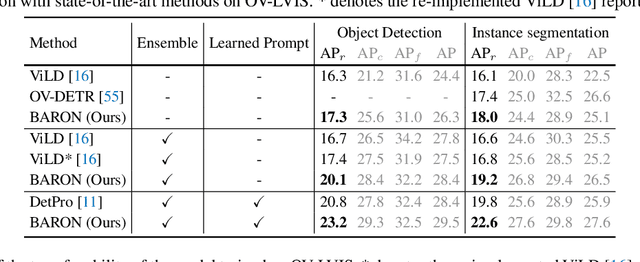
Pre-trained vision-language models (VLMs) learn to align vision and language representations on large-scale datasets, where each image-text pair usually contains a bag of semantic concepts. However, existing open-vocabulary object detectors only align region embeddings individually with the corresponding features extracted from the VLMs. Such a design leaves the compositional structure of semantic concepts in a scene under-exploited, although the structure may be implicitly learned by the VLMs. In this work, we propose to align the embedding of bag of regions beyond individual regions. The proposed method groups contextually interrelated regions as a bag. The embeddings of regions in a bag are treated as embeddings of words in a sentence, and they are sent to the text encoder of a VLM to obtain the bag-of-regions embedding, which is learned to be aligned to the corresponding features extracted by a frozen VLM. Applied to the commonly used Faster R-CNN, our approach surpasses the previous best results by 4.6 box AP50 and 2.8 mask AP on novel categories of open-vocabulary COCO and LVIS benchmarks, respectively. Code and models are available at https://github.com/wusize/ovdet.