 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatial Functa: Scaling Functa to ImageNet Classification and Generation
Feb 09, 2023
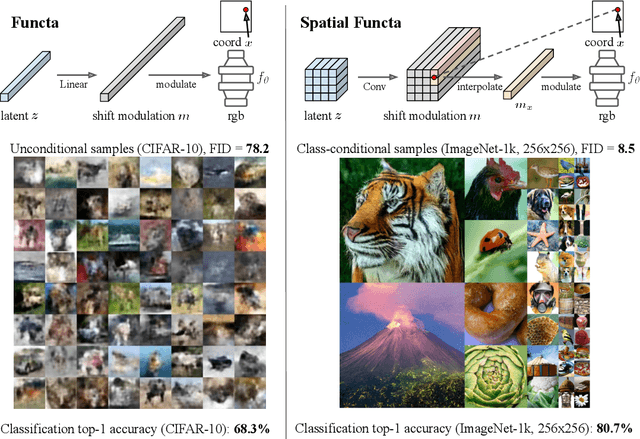
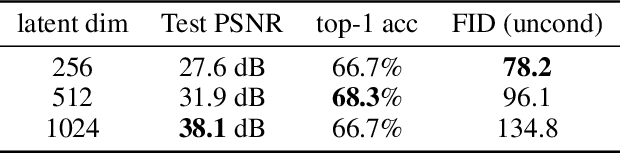


Neural fields, also known as implicit neural representations, have emerged as a powerful means to represent complex signals of various modalities. Based on this Dupont et al. (2022) introduce a framework that views neural fields as data, termed *functa*, and proposes to do deep learning directly on this dataset of neural fields. In this work, we show that the proposed framework faces limitations when scaling up to even moderately complex datasets such as CIFAR-10. We then propose *spatial functa*, which overcome these limitations by using spatially arranged latent representations of neural fields, thereby allowing us to scale up the approach to ImageNet-1k at 256x256 resolution. We demonstrate competitive performance to Vision Transformers (Steiner et al., 2022) on classification and Latent Diffusion (Rombach et al., 2022) on image generation respectively.
Stacking Ensemble Learning in Deep Domain Adaptation for Ophthalmic Image Classification
Sep 27, 2022Domain adaptation is an attractive approach given the availability of a large amount of labeled data with similar properties but different domains. It is effective in image classification tasks where obtaining sufficient label data is challenging. We propose a novel method, named SELDA, for stacking ensemble learning via extending three domain adaptation methods for effectively solving real-world problems. The major assumption is that when base domain adaptation models are combined, we can obtain a more accurate and robust model by exploiting the ability of each of the base models. We extend Maximum Mean Discrepancy (MMD), Low-rank coding, and Correlation Alignment (CORAL) to compute the adaptation loss in three base models. Also, we utilize a two-fully connected layer network as a meta-model to stack the output predictions of these three well-performing domain adaptation models to obtain high accuracy in ophthalmic image classification tasks. The experimental results using Age-Related Eye Disease Study (AREDS) benchmark ophthalmic dataset demonstrate the effectiveness of the proposed model.
Learning Frequency-Specific Quantization Scaling in VVC for Standard-Compliant Task-driven Image Coding
Jan 20, 2023

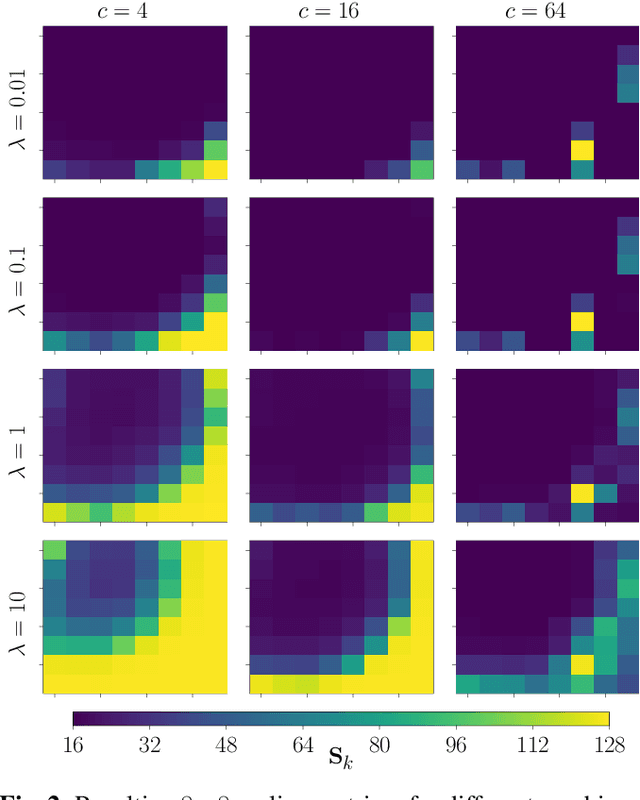
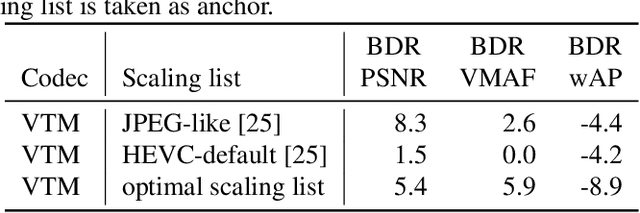
Today, visual data is often analyzed by a neural network without any human being involved, which demands for specialized codecs. For standard-compliant codec adaptations towards certain information sinks, HEVC or VVC provide the possibility of frequency-specific quantization with scaling lists. This is a well-known method for the human visual system, where scaling lists are derived from psycho-visual models. In this work, we employ scaling lists when performing VVC intra coding for neural networks as information sink. To this end, we propose a novel data-driven method to obtain optimal scaling lists for arbitrary neural networks. Experiments with Mask R-CNN as information sink reveal that coding the Cityscapes dataset with the proposed scaling lists result in peak bitrate savings of 8.9 % over VVC with constant quantization. By that, our approach also outperforms scaling lists optimized for the human visual system. The generated scaling lists can be found under https://github.com/FAU-LMS/VCM_scaling_lists.
* Originally submitted at IEEE ICIP 2022
InfoNCE Loss Provably Learns Cluster-Preserving Representations
Feb 15, 2023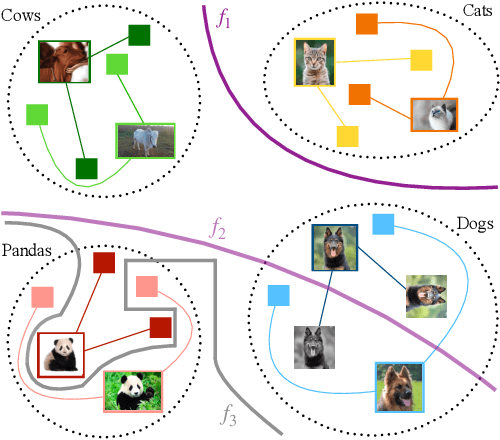
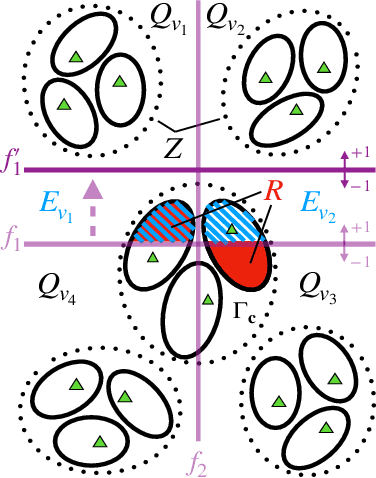
The goal of contrasting learning is to learn a representation that preserves underlying clusters by keeping samples with similar content, e.g. the ``dogness'' of a dog, close to each other in the space generated by the representation. A common and successful approach for tackling this unsupervised learning problem is minimizing the InfoNCE loss associated with the training samples, where each sample is associated with their augmentations (positive samples such as rotation, crop) and a batch of negative samples (unrelated samples). To the best of our knowledge, it was unanswered if the representation learned by minimizing the InfoNCE loss preserves the underlying data clusters, as it only promotes learning a representation that is faithful to augmentations, i.e., an image and its augmentations have the same representation. Our main result is to show that the representation learned by InfoNCE with a finite number of negative samples is also consistent with respect to clusters in the data, under the condition that the augmentation sets within clusters may be non-overlapping but are close and intertwined, relative to the complexity of the learning function class.
Advancing Radiograph Representation Learning with Masked Record Modeling
Feb 15, 2023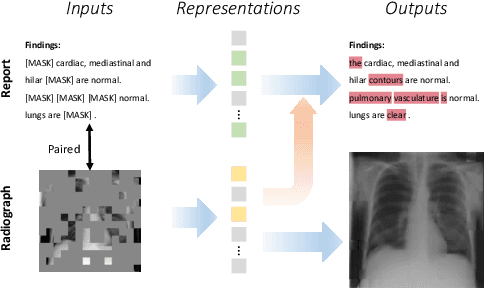
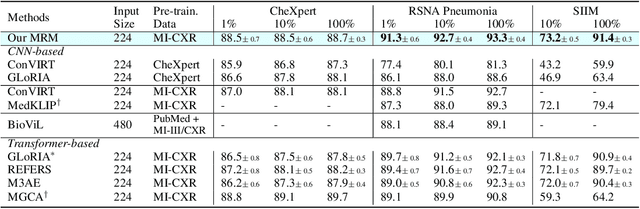
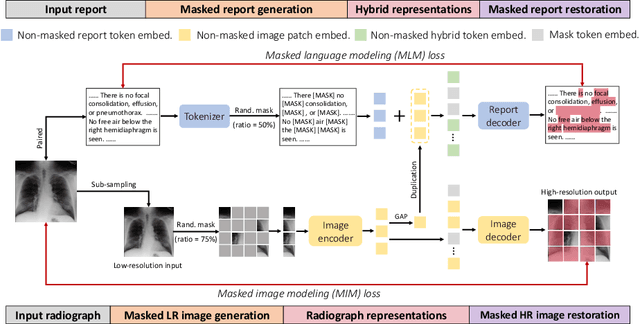
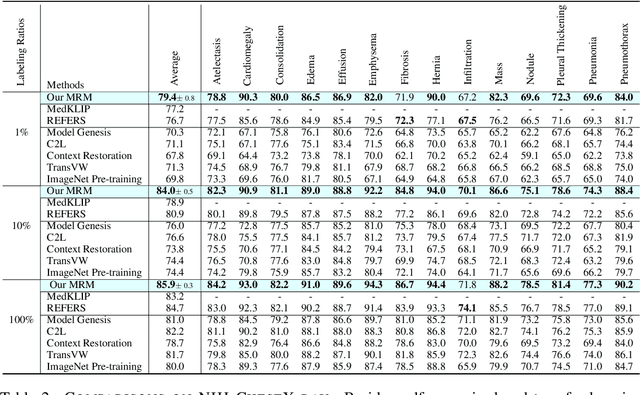
Modern studies in radiograph representation learning rely on either self-supervision to encode invariant semantics or associated radiology reports to incorporate medical expertise, while the complementarity between them is barely noticed. To explore this, we formulate the self- and report-completion as two complementary objectives and present a unified framework based on masked record modeling (MRM). In practice, MRM reconstructs masked image patches and masked report tokens following a multi-task scheme to learn knowledge-enhanced semantic representations. With MRM pre-training, we obtain pre-trained models that can be well transferred to various radiography tasks. Specifically, we find that MRM offers superior performance in label-efficient fine-tuning. For instance, MRM achieves 88.5% mean AUC on CheXpert using 1% labeled data, outperforming previous R$^2$L methods with 100% labels. On NIH ChestX-ray, MRM outperforms the best performing counterpart by about 3% under small labeling ratios. Besides, MRM surpasses self- and report-supervised pre-training in identifying the pneumonia type and the pneumothorax area, sometimes by large margins.
EMV-LIO: An Efficient Multiple Vision aided LiDAR-Inertial Odometry
Feb 15, 2023
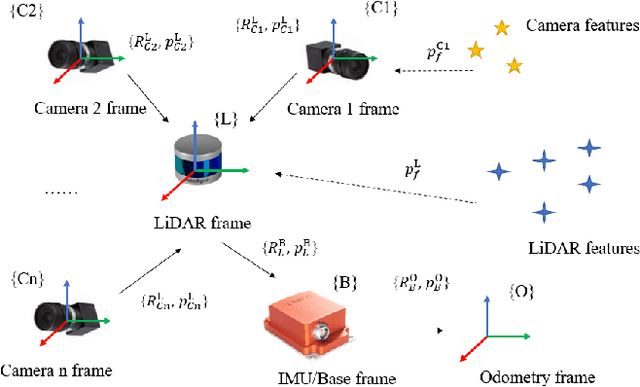
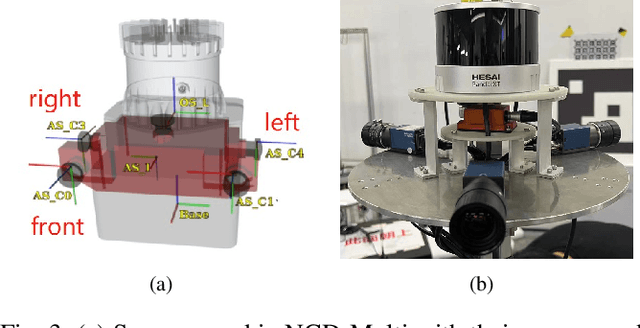

To deal with the degeneration caused by the incomplete constraints of single sensor, multi-sensor fusion strategies especially in LiDAR-vision-inertial fusion area have attracted much interest from both the industry and the research community in recent years. Considering that a monocular camera is vulnerable to the influence of ambient light from a certain direction and fails, which makes the system degrade into a LiDAR-inertial system, multiple cameras are introduced to expand the visual observation so as to improve the accuracy and robustness of the system. Besides, removing LiDAR's noise via range image, setting condition for nearest neighbor search, and replacing kd-Tree with ikd-Tree are also introduced to enhance the efficiency. Based on the above, we propose an Efficient Multiple vision aided LiDAR-inertial odometry system (EMV-LIO), and evaluate its performance on both open datasets and our custom datasets. Experiments show that the algorithm is helpful to improve the accuracy, robustness and efficiency of the whole system compared with LVI-SAM. Our implementation will be available upon acceptance.
Enhancing Biogenic Emission Maps Using Deep Learning
Feb 15, 2023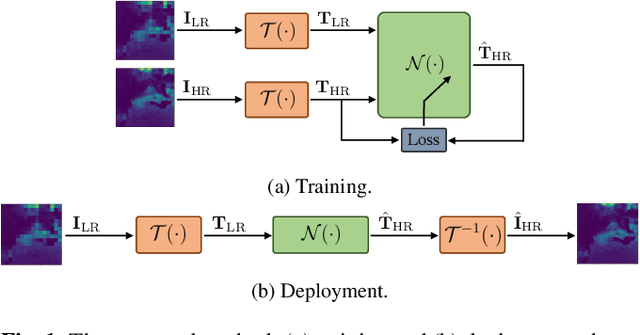
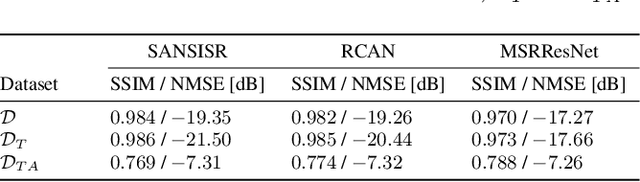
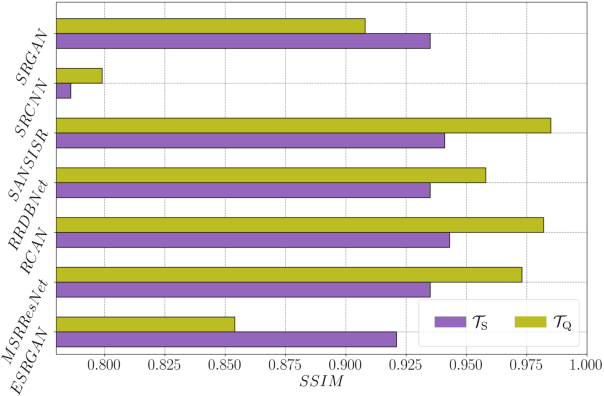
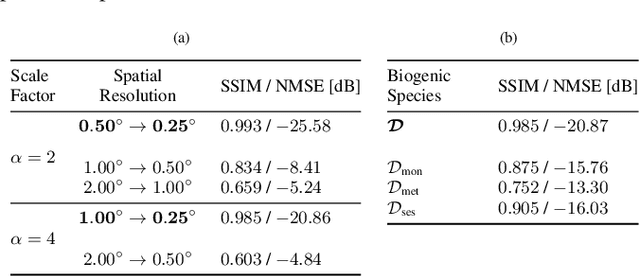
Biogenic Volatile Organic Compounds (BVOCs) play a critical role in biosphere-atmosphere interactions, being a key factor in the physical and chemical properties of the atmosphere and climate. Acquiring large and fine-grained BVOC emission maps is expensive and time-consuming, so most of the available BVOC data are obtained on a loose and sparse sampling grid or on small regions. However, high-resolution BVOC data are desirable in many applications, such as air quality, atmospheric chemistry, and climate monitoring. In this work, we propose to investigate the possibility of enhancing BVOC acquisitions, taking a step forward in explaining the relationships between plants and these compounds. We do so by comparing the performances of several state-of-the-art neural networks proposed for Single-Image Super-Resolution (SISR), showing how to adapt them to correctly handle emission data through preprocessing. Moreover, we also consider realistic scenarios, considering both temporal and geographical constraints. Finally, we present possible future developments in terms of Super-Resolution (SR) generalization, considering the scale-invariance property and super-resolving emissions from unseen compounds.
Zero-Shot Anomaly Detection without Foundation Models
Feb 15, 2023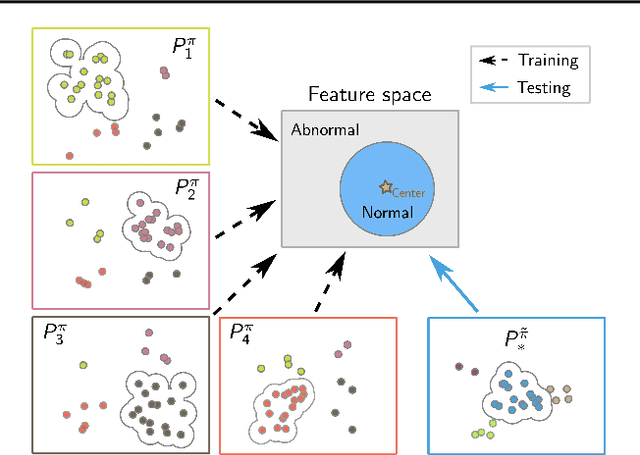
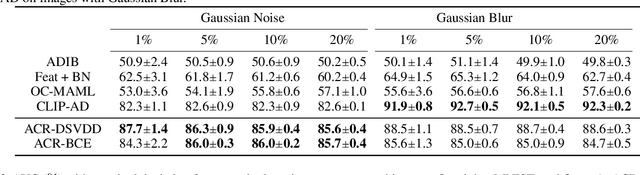
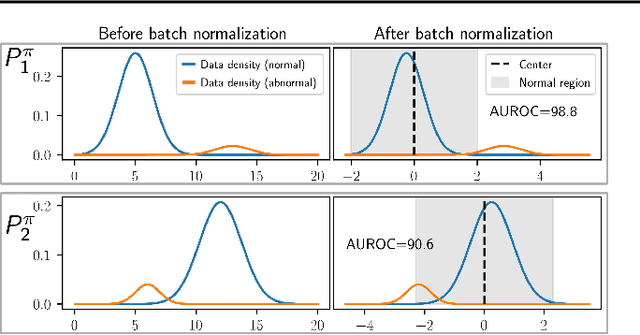
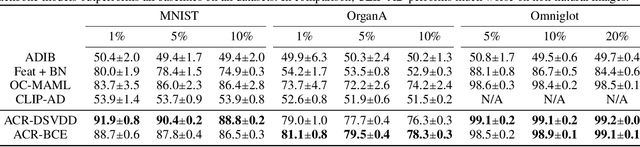
Anomaly detection (AD) tries to identify data instances that deviate from the norm in a given data set. Since data distributions are subject to distribution shifts, our concept of ``normality" may also drift, raising the need for zero-shot adaptation approaches for anomaly detection. However, the fact that current zero-shot AD methods rely on foundation models that are restricted in their domain (natural language and natural images), are costly, and oftentimes proprietary, asks for alternative approaches. In this paper, we propose a simple and highly effective zero-shot AD approach compatible with a variety of established AD methods. Our solution relies on training an off-the-shelf anomaly detector (such as a deep SVDD) on a set of inter-related data distributions in combination with batch normalization. This simple recipe--batch normalization plus meta-training--is a highly effective and versatile tool. Our results demonstrate the first zero-shot anomaly detection results for tabular data and SOTA zero-shot AD results for image data from specialized domains.
3D Human Pose Lifting with Grid Convolution
Feb 17, 2023
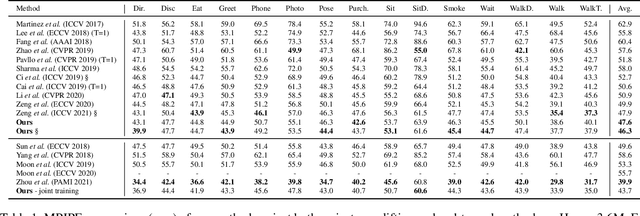
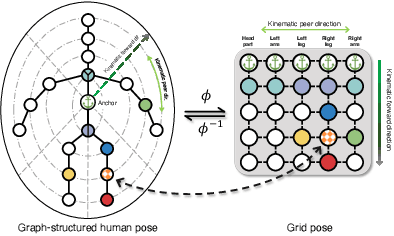
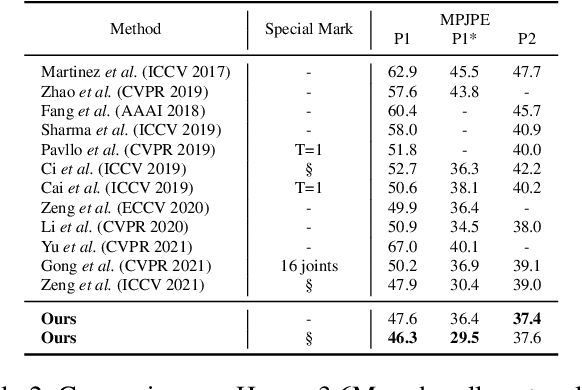
Existing lifting networks for regressing 3D human poses from 2D single-view poses are typically constructed with linear layers based on graph-structured representation learning. In sharp contrast to them, this paper presents Grid Convolution (GridConv), mimicking the wisdom of regular convolution operations in image space. GridConv is based on a novel Semantic Grid Transformation (SGT) which leverages a binary assignment matrix to map the irregular graph-structured human pose onto a regular weave-like grid pose representation joint by joint, enabling layer-wise feature learning with GridConv operations. We provide two ways to implement SGT, including handcrafted and learnable designs. Surprisingly, both designs turn out to achieve promising results and the learnable one is better, demonstrating the great potential of this new lifting representation learning formulation. To improve the ability of GridConv to encode contextual cues, we introduce an attention module over the convolutional kernel, making grid convolution operations input-dependent, spatial-aware and grid-specific. We show that our fully convolutional grid lifting network outperforms state-of-the-art methods with noticeable margins under (1) conventional evaluation on Human3.6M and (2) cross-evaluation on MPI-INF-3DHP. Code is available at https://github.com/OSVAI/GridConv
Pretraining is All You Need for Image-to-Image Translation
May 25, 2022



We propose to use pretraining to boost general image-to-image translation. Prior image-to-image translation methods usually need dedicated architectural design and train individual translation models from scratch, struggling for high-quality generation of complex scenes, especially when paired training data are not abundant. In this paper, we regard each image-to-image translation problem as a downstream task and introduce a simple and generic framework that adapts a pretrained diffusion model to accommodate various kinds of image-to-image translation. We also propose adversarial training to enhance the texture synthesis in the diffusion model training, in conjunction with normalized guidance sampling to improve the generation quality. We present extensive empirical comparison across various tasks on challenging benchmarks such as ADE20K, COCO-Stuff, and DIODE, showing the proposed pretraining-based image-to-image translation (PITI) is capable of synthesizing images of unprecedented realism and faithfulness.