 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UniBind: LLM-Augmented Unified and Balanced Representation Space to Bind Them All
Mar 19, 2024
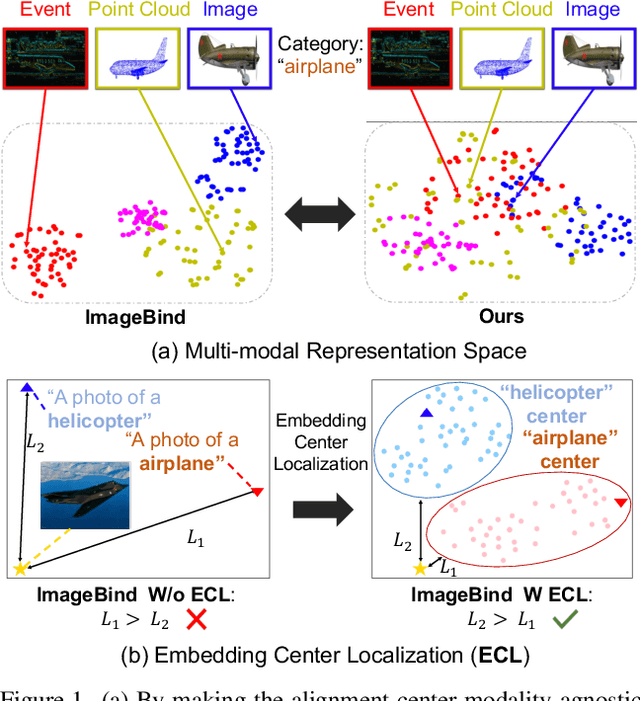
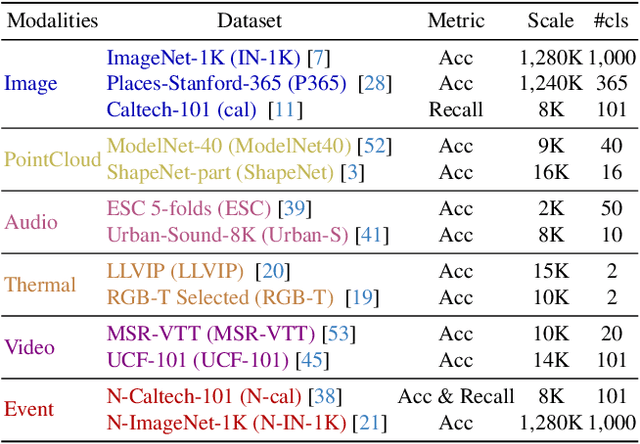
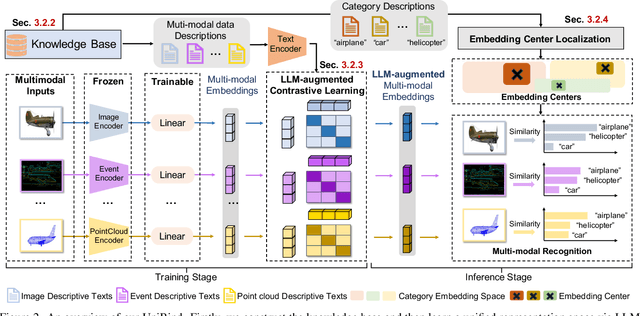
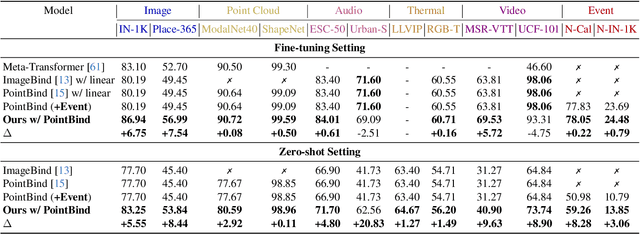
We present UniBind, a flexible and efficient approach that learns a unified representation space for seven diverse modalities -- images, text, audio, point cloud, thermal, video, and event data. Existing works, eg., ImageBind, treat the image as the central modality and build an image-centered representation space; however, the space may be sub-optimal as it leads to an unbalanced representation space among all modalities. Moreover, the category names are directly used to extract text embeddings for the downstream tasks, making it hardly possible to represent the semantics of multi-modal data. The 'out-of-the-box' insight of our UniBind is to make the alignment center modality-agnostic and further learn a unified and balanced representation space, empowered by the large language models (LLMs). UniBind is superior in its flexible application to all CLIP-style models and delivers remarkable performance boosts. To make this possible, we 1) construct a knowledge base of text embeddings with the help of LLMs and multi-modal LLMs; 2) adaptively build LLM-augmented class-wise embedding center on top of the knowledge base and encoded visual embeddings; 3) align all the embeddings to the LLM-augmented embedding center via contrastive learning to achieve a unified and balanced representation space. UniBind shows strong zero-shot recognition performance gains over prior arts by an average of 6.36%. Finally, we achieve new state-of-the-art performance, eg., a 6.75% gain on ImageNet, on the multi-modal fine-tuning setting while reducing 90% of the learnable parameters.
Image-Based Dietary Assessment: A Healthy Eating Plate Estimation System
Mar 02, 2024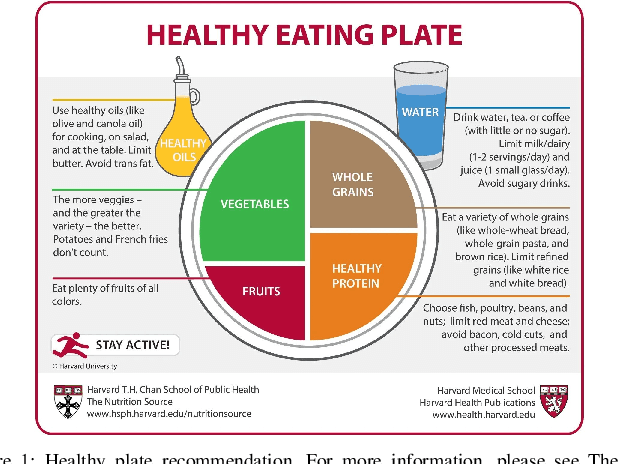
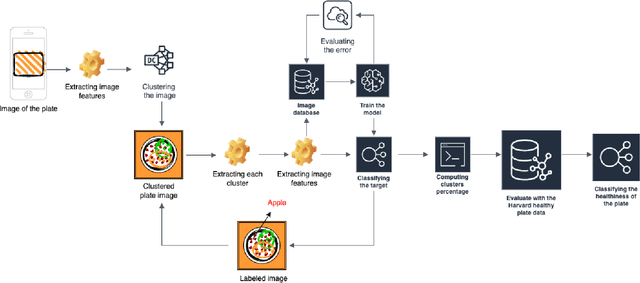

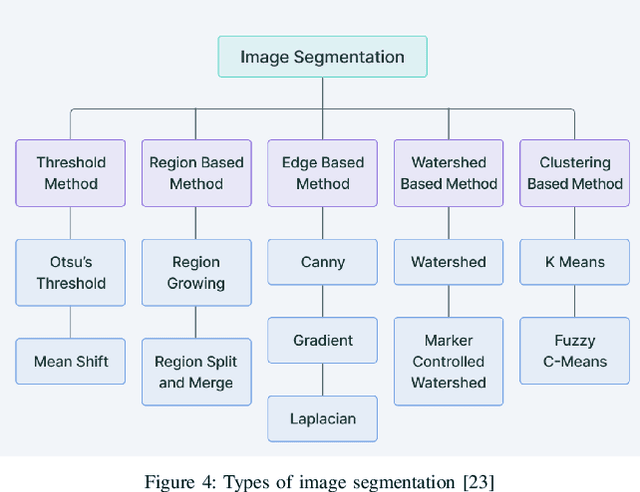
The nutritional quality of diets has significantly deteriorated over the past two to three decades, a decline often underestimated by the people. This deterioration, coupled with a hectic lifestyle, has contributed to escalating health concerns. Recognizing this issue, researchers at Harvard have advocated for a balanced nutritional plate model to promote health. Inspired by this research, our paper introduces an innovative Image-Based Dietary Assessment system aimed at evaluating the healthiness of meals through image analysis. Our system employs advanced image segmentation and classification techniques to analyze food items on a plate, assess their proportions, and calculate meal adherence to Harvard's healthy eating recommendations. This approach leverages machine learning and nutritional science to empower individuals with actionable insights for healthier eating choices. Our four-step framework involves segmenting the image, classifying the items, conducting a nutritional assessment based on the Harvard Healthy Eating Plate research, and offering tailored recommendations. The prototype system has shown promising results in promoting healthier eating habits by providing an accessible, evidence-based tool for dietary assessment.
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 22, 2024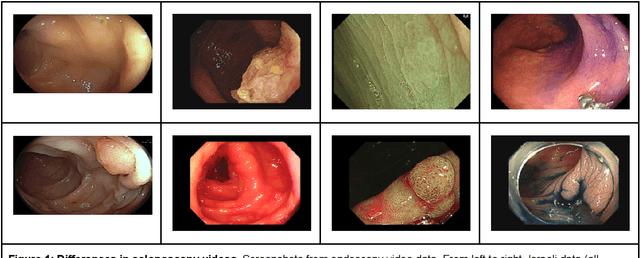
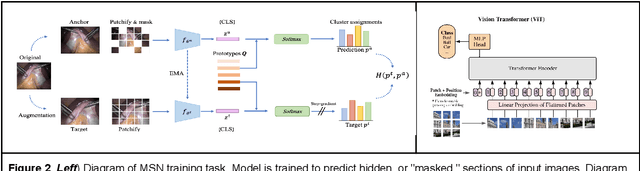
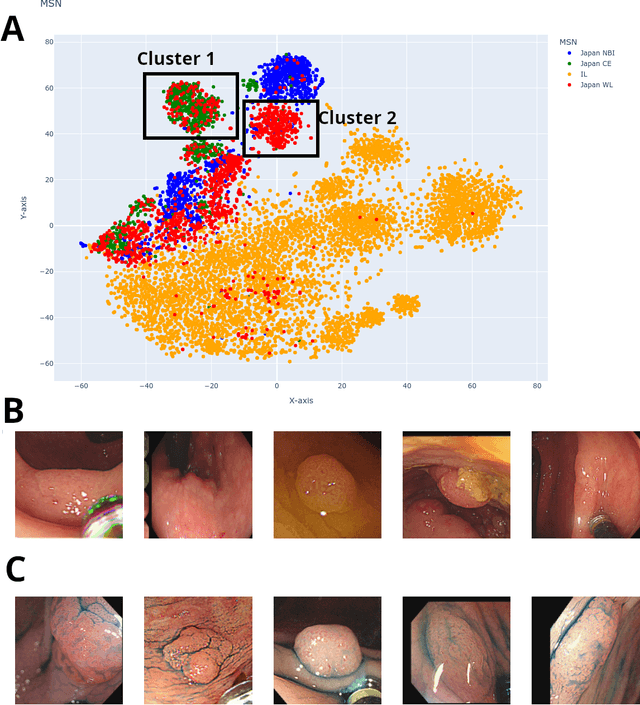
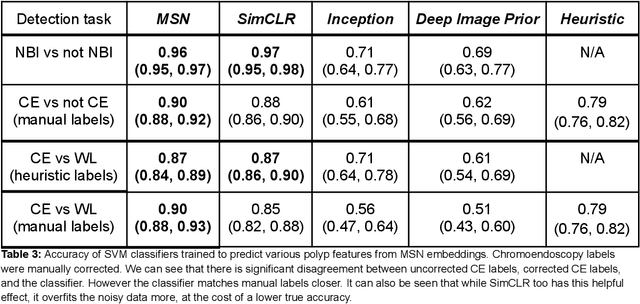
$\textbf{Background}$: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. $\textbf{Methods}$: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. $\textbf{Results}$: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). $\textbf{Conclusion}$: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
A Dual-domain Regularization Method for Ring Artifact Removal of X-ray CT
Mar 15, 2024



Ring artifacts in computed tomography images, arising from the undesirable responses of detector units, significantly degrade image quality and diagnostic reliability. To address this challenge, we propose a dual-domain regularization model to effectively remove ring artifacts, while maintaining the integrity of the original CT image. The proposed model corrects the vertical stripe artifacts on the sinogram by innovatively updating the response inconsistency compensation coefficients of detector units, which is achieved by employing the group sparse constraint and the projection-view direction sparse constraint on the stripe artifacts. Simultaneously, we apply the sparse constraint on the reconstructed image to further rectified ring artifacts in the image domain. The key advantage of the proposed method lies in considering the relationship between the response inconsistency compensation coefficients of the detector units and the projection views, which enables a more accurate correction of the response of the detector units. An alternating minimization method is designed to solve the model. Comparative experiments on real photon counting detector data demonstrate that the proposed method not only surpasses existing methods in removing ring artifacts but also excels in preserving structural details and image fidelity.
PLACE: Adaptive Layout-Semantic Fusion for Semantic Image Synthesis
Mar 04, 2024
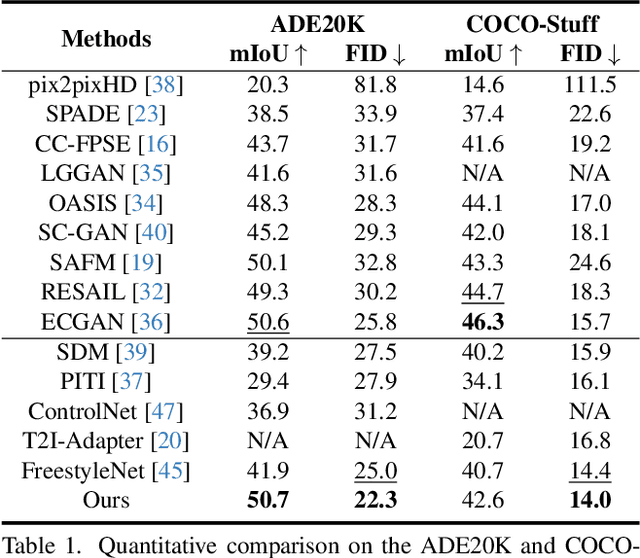
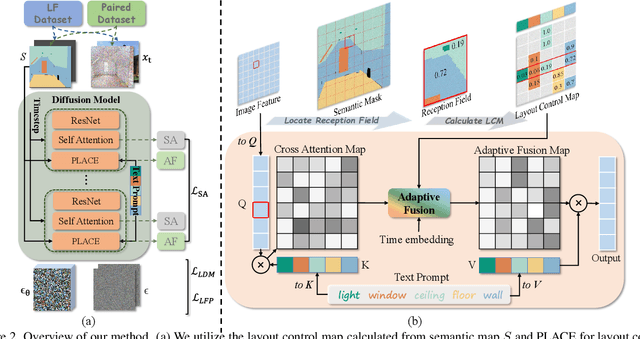
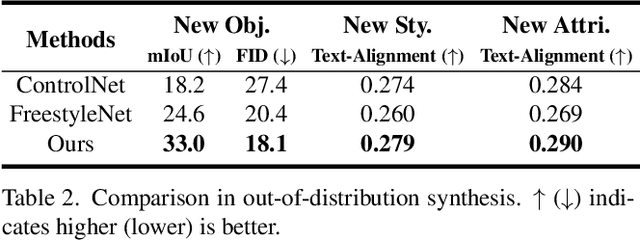
Recent advancements in large-scale pre-trained text-to-image models have led to remarkable progress in semantic image synthesis. Nevertheless, synthesizing high-quality images with consistent semantics and layout remains a challenge. In this paper, we propose the adaPtive LAyout-semantiC fusion modulE (PLACE) that harnesses pre-trained models to alleviate the aforementioned issues. Specifically, we first employ the layout control map to faithfully represent layouts in the feature space. Subsequently, we combine the layout and semantic features in a timestep-adaptive manner to synthesize images with realistic details. During fine-tuning, we propose the Semantic Alignment (SA) loss to further enhance layout alignment. Additionally, we introduce the Layout-Free Prior Preservation (LFP) loss, which leverages unlabeled data to maintain the priors of pre-trained models, thereby improving the visual quality and semantic consistency of synthesized images. Extensive experiments demonstrate that our approach performs favorably in terms of visual quality, semantic consistency, and layout alignment. The source code and model are available at https://github.com/cszy98/PLACE/tree/main.
LoRA-Composer: Leveraging Low-Rank Adaptation for Multi-Concept Customization in Training-Free Diffusion Models
Mar 18, 2024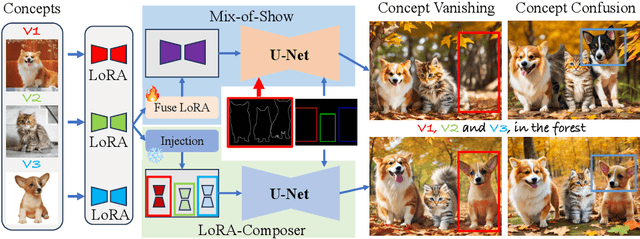
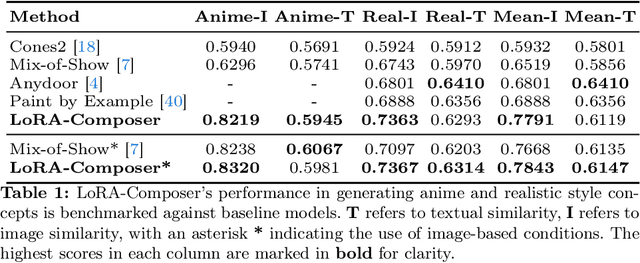
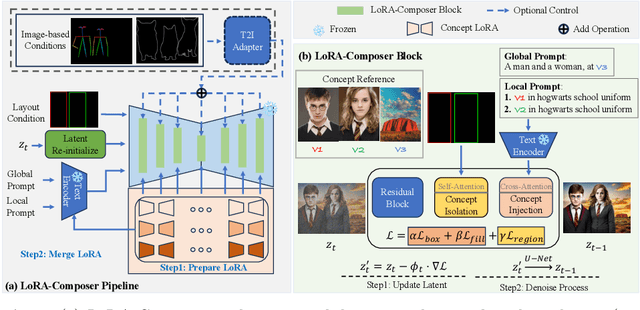
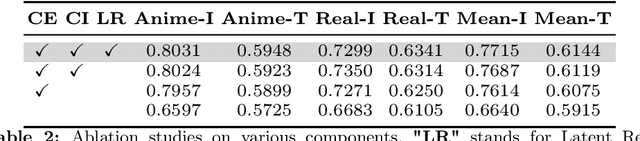
Customization generation techniques have significantly advanced the synthesis of specific concepts across varied contexts. Multi-concept customization emerges as the challenging task within this domain. Existing approaches often rely on training a Low-Rank Adaptations (LoRA) fusion matrix of multiple LoRA to merge various concepts into a single image. However, we identify this straightforward method faces two major challenges: 1) concept confusion, which occurs when the model cannot preserve distinct individual characteristics, and 2) concept vanishing, where the model fails to generate the intended subjects. To address these issues, we introduce LoRA-Composer, a training-free framework designed for seamlessly integrating multiple LoRAs, thereby enhancing the harmony among different concepts within generated images. LoRA-Composer addresses concept vanishing through Concept Injection Constraints, enhancing concept visibility via an expanded cross-attention mechanism. To combat concept confusion, Concept Isolation Constraints are introduced, refining the self-attention computation. Furthermore, Latent Re-initialization is proposed to effectively stimulate concept-specific latent within designated regions. Our extensive testing showcases a notable enhancement in LoRA-Composer's performance compared to standard baselines, especially when eliminating the image-based conditions like canny edge or pose estimations. Code is released at https://github.com/Young98CN/LoRA\_Composer.
Modality-Agnostic fMRI Decoding of Vision and Language
Mar 18, 2024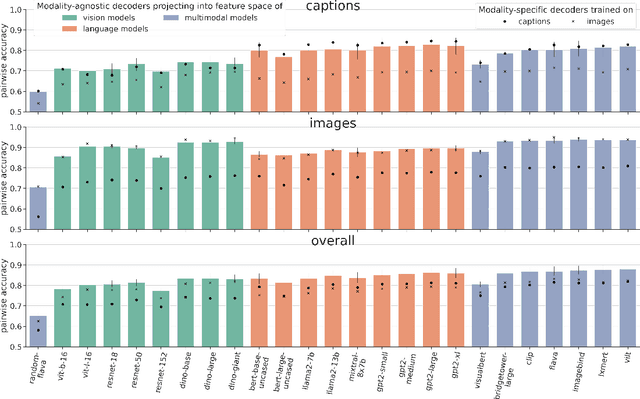
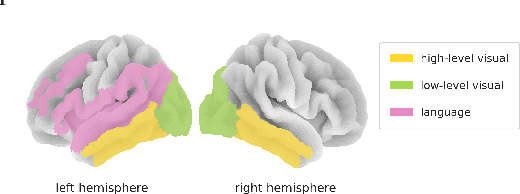
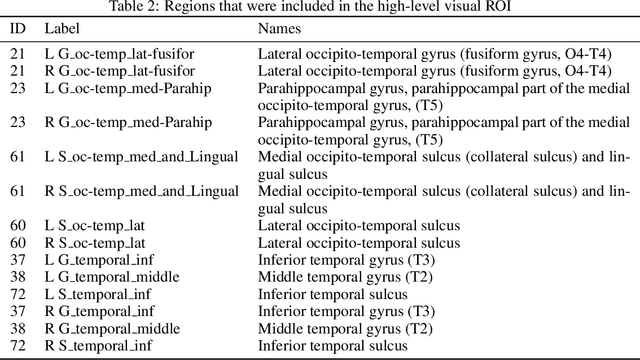
Previous studies have shown that it is possible to map brain activation data of subjects viewing images onto the feature representation space of not only vision models (modality-specific decoding) but also language models (cross-modal decoding). In this work, we introduce and use a new large-scale fMRI dataset (~8,500 trials per subject) of people watching both images and text descriptions of such images. This novel dataset enables the development of modality-agnostic decoders: a single decoder that can predict which stimulus a subject is seeing, irrespective of the modality (image or text) in which the stimulus is presented. We train and evaluate such decoders to map brain signals onto stimulus representations from a large range of publicly available vision, language and multimodal (vision+language) models. Our findings reveal that (1) modality-agnostic decoders perform as well as (and sometimes even better than) modality-specific decoders (2) modality-agnostic decoders mapping brain data onto representations from unimodal models perform as well as decoders relying on multimodal representations (3) while language and low-level visual (occipital) brain regions are best at decoding text and image stimuli, respectively, high-level visual (temporal) regions perform well on both stimulus types.
Learning User Embeddings from Human Gaze for Personalised Saliency Prediction
Mar 20, 2024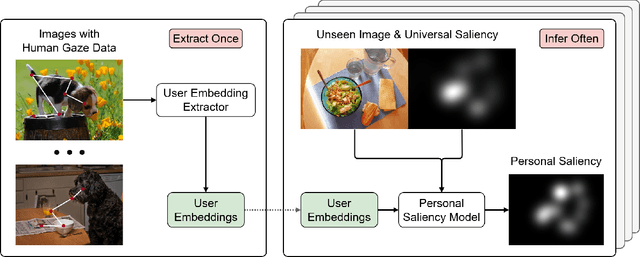
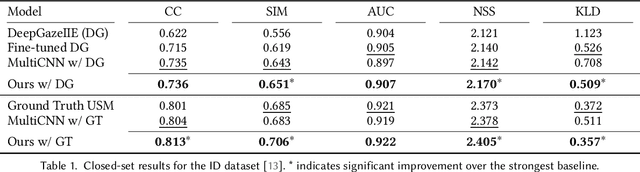
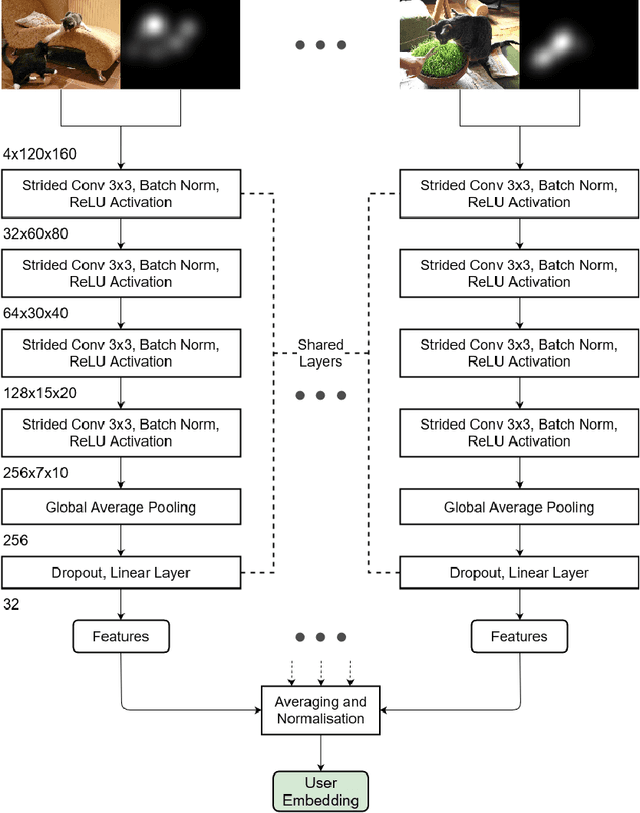
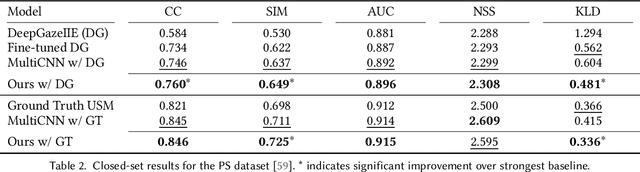
Reusable embeddings of user behaviour have shown significant performance improvements for the personalised saliency prediction task. However, prior works require explicit user characteristics and preferences as input, which are often difficult to obtain. We present a novel method to extract user embeddings from pairs of natural images and corresponding saliency maps generated from a small amount of user-specific eye tracking data. At the core of our method is a Siamese convolutional neural encoder that learns the user embeddings by contrasting the image and personal saliency map pairs of different users. Evaluations on two public saliency datasets show that the generated embeddings have high discriminative power, are effective at refining universal saliency maps to the individual users, and generalise well across users and images. Finally, based on our model's ability to encode individual user characteristics, our work points towards other applications that can benefit from reusable embeddings of gaze behaviour.
Retina Vision Transformer (RetinaViT): Introducing Scaled Patches into Vision Transformers
Mar 20, 2024
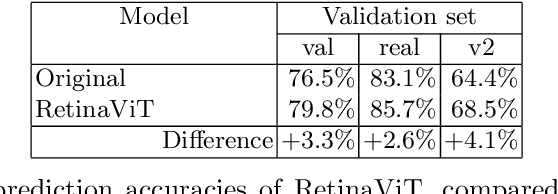
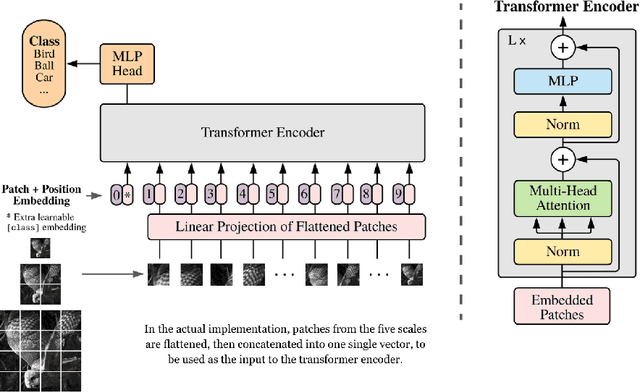
Humans see low and high spatial frequency components at the same time, and combine the information from both to form a visual scene. Drawing on this neuroscientific inspiration, we propose an altered Vision Transformer architecture where patches from scaled down versions of the input image are added to the input of the first Transformer Encoder layer. We name this model Retina Vision Transformer (RetinaViT) due to its inspiration from the human visual system. Our experiments show that when trained on the ImageNet-1K dataset with a moderate configuration, RetinaViT achieves a 3.3% performance improvement over the original ViT. We hypothesize that this improvement can be attributed to the inclusion of low spatial frequency components in the input, which improves the ability to capture structural features, and to select and forward important features to deeper layers. RetinaViT thereby opens doors to further investigations into vertical pathways and attention patterns.
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Mar 16, 2024
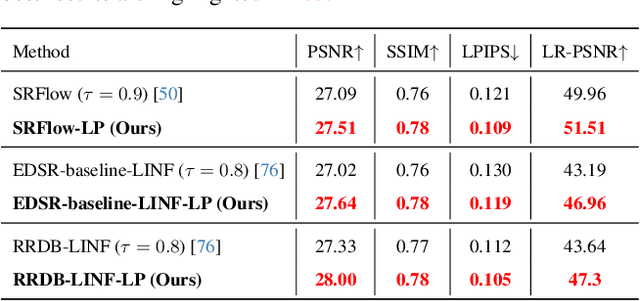

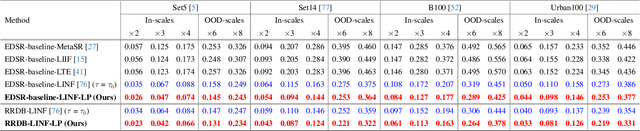
Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/FlowSR-LP