 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reflectance-Oriented Probabilistic Equalization for Image Enhancement
Sep 14, 2022
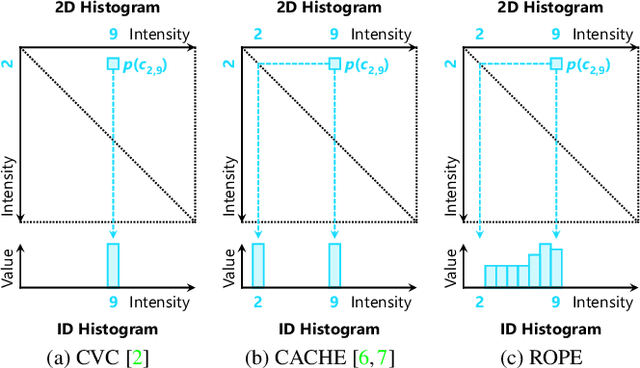
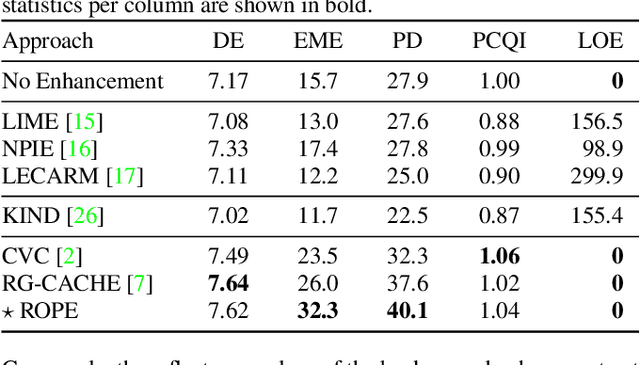
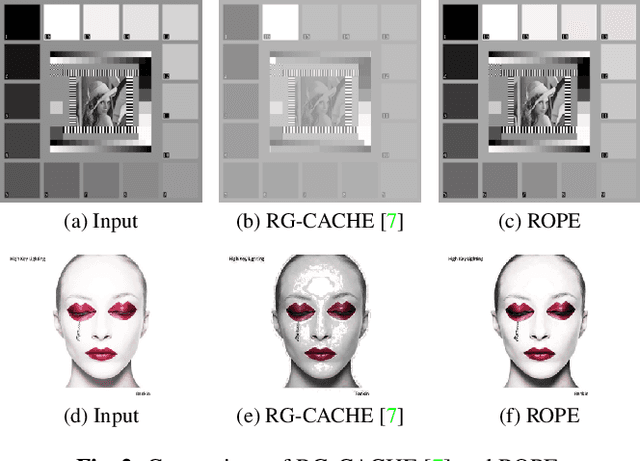
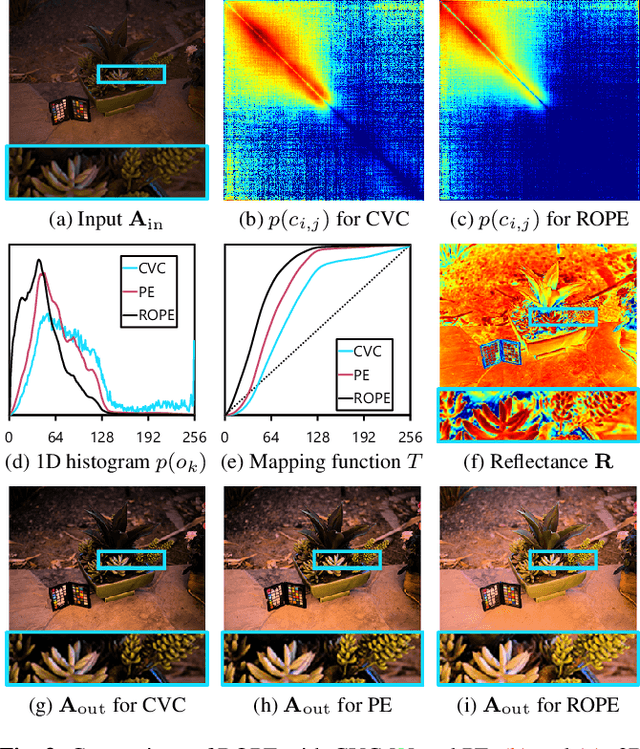
Despite recent advances in image enhancement, it remains difficult for existing approaches to adaptively improve the brightness and contrast for both low-light and normal-light images. To solve this problem, we propose a novel 2D histogram equalization approach. It assumes intensity occurrence and co-occurrence to be dependent on each other and derives the distribution of intensity occurrence (1D histogram) by marginalizing over the distribution of intensity co-occurrence (2D histogram). This scheme improves global contrast more effectively and reduces noise amplification. The 2D histogram is defined by incorporating the local pixel value differences in image reflectance into the density estimation to alleviate the adverse effects of dark lighting conditions. Over 500 images were used for evaluation, demonstrating the superiority of our approach over existing studies. It can sufficiently improve the brightness of low-light images while avoiding over-enhancement in normal-light images.
Stochastic Surprisal: An inferential measurement of Free Energy in Neural Networks
Feb 11, 2023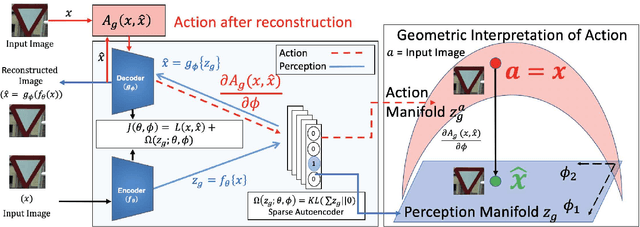
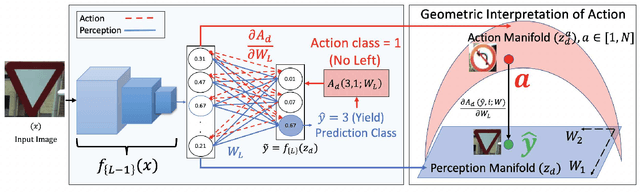
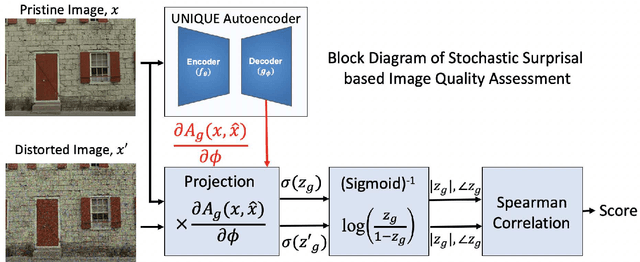
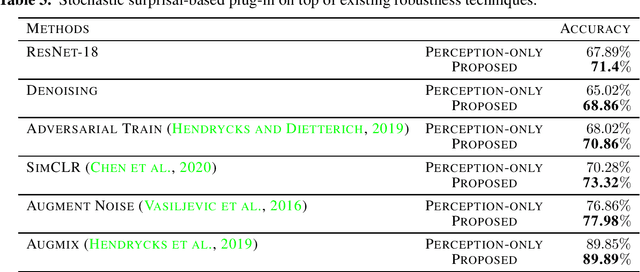
This paper conjectures and validates a framework that allows for action during inference in supervised neural networks. Supervised neural networks are constructed with the objective to maximize their performance metric in any given task. This is done by reducing free energy and its associated surprisal during training. However, the bottom-up inference nature of supervised networks is a passive process that renders them fallible to noise. In this paper, we provide a thorough background of supervised neural networks, both generative and discriminative, and discuss their functionality from the perspective of free energy principle. We then provide a framework for introducing action during inference. We introduce a new measurement called stochastic surprisal that is a function of the network, the input, and any possible action. This action can be any one of the outputs that the neural network has learnt, thereby lending stochasticity to the measurement. Stochastic surprisal is validated on two applications: Image Quality Assessment and Recognition under noisy conditions. We show that, while noise characteristics are ignored to make robust recognition, they are analyzed to estimate image quality scores. We apply stochastic surprisal on two applications, three datasets, and as a plug-in on twelve networks. In all, it provides a statistically significant increase among all measures. We conclude by discussing the implications of the proposed stochastic surprisal in other areas of cognitive psychology including expectancy-mismatch and abductive reasoning.
Efficiency 360: Efficient Vision Transformers
Feb 23, 2023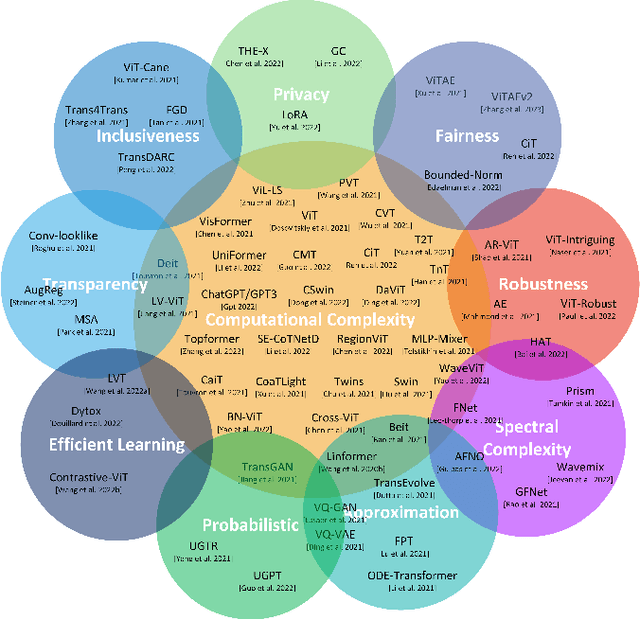
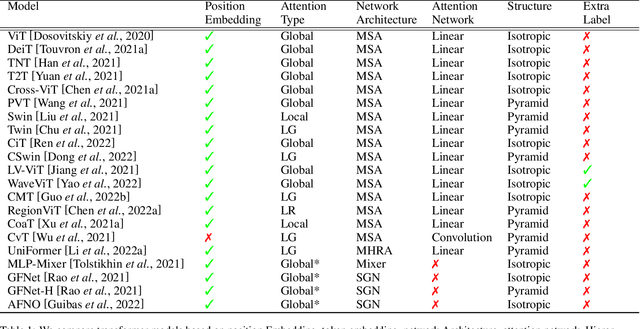
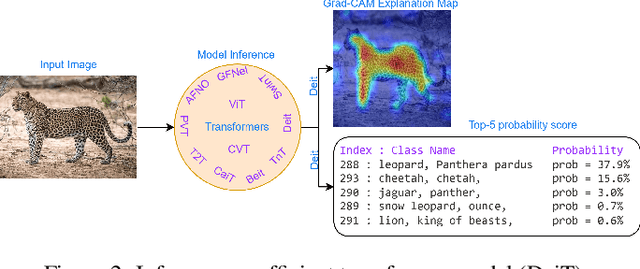
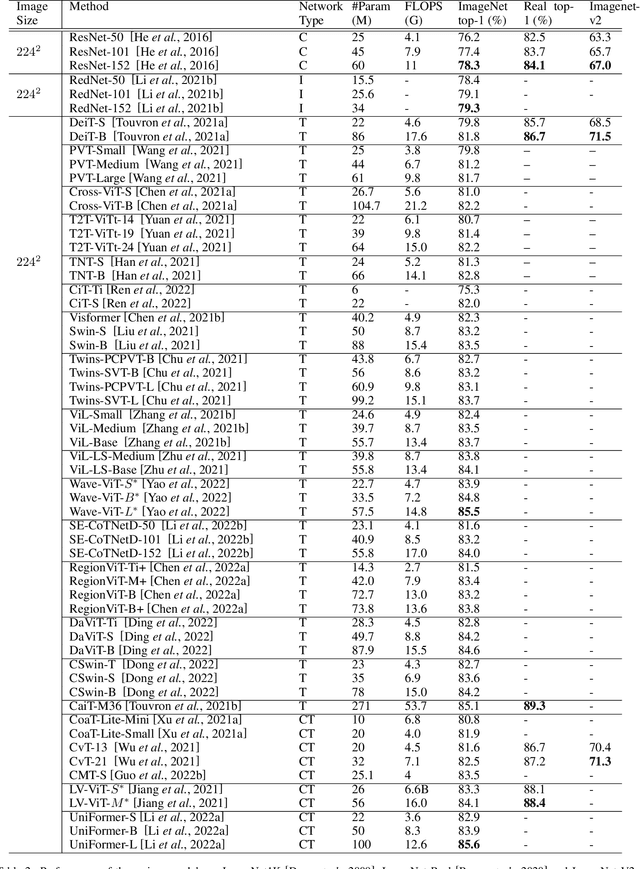
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
HL Dataset: Grounding High-Level Linguistic Concepts in Vision
Feb 23, 2023

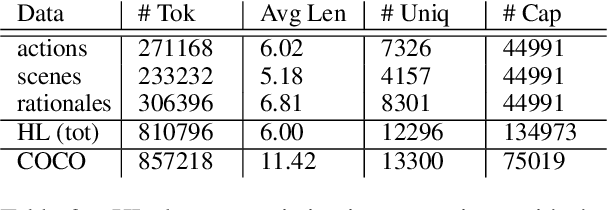
Current captioning datasets, focus on object-centric captions, describing the visible objects in the image, often ending up stating the obvious (for humans), e.g. "people eating food in a park". Although these datasets are useful to evaluate the ability of Vision & Language models to recognize the visual content, they lack in expressing trivial abstract concepts, e.g. "people having a picnic". Such concepts are licensed by human's personal experience and contribute to forming common sense assumptions. We present the High-Level Dataset; a dataset extending 14997 images of the COCO dataset with 134973 human-annotated (high-level) abstract captions collected along three axes: scenes, actions and rationales. We describe and release such dataset and we show how it can be used to assess models' multimodal grounding of abstract concepts and enrich models' visio-lingusitic representations. Moreover, we describe potential tasks enabled by this dataset involving high- and low-level concepts interactions.
Improved Training of Mixture-of-Experts Language GANs
Feb 23, 2023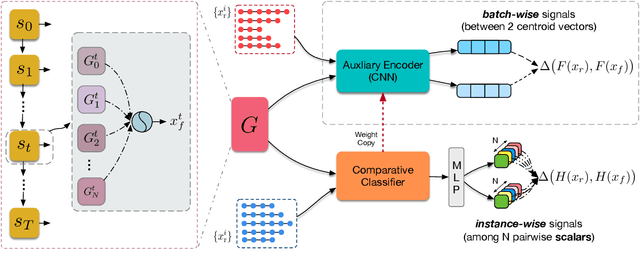
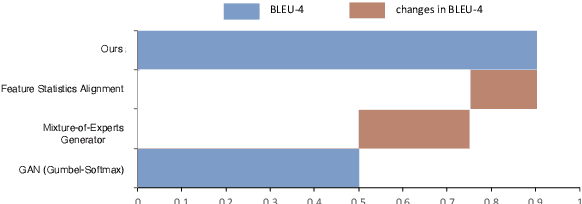

Despite the dramatic success in image generation, Generative Adversarial Networks (GANs) still face great challenges in synthesizing sequences of discrete elements, in particular human language. The difficulty in generator training arises from the limited representation capacity and uninformative learning signals obtained from the discriminator. In this work, we (1) first empirically show that the mixture-of-experts approach is able to enhance the representation capacity of the generator for language GANs and (2) harness the Feature Statistics Alignment (FSA) paradigm to render fine-grained learning signals to advance the generator training. Specifically, FSA forces the mean statistics of the distribution of fake data to approach that of real samples as close as possible in the finite-dimensional feature space. Empirical study on synthetic and real benchmarks shows the superior performance in quantitative evaluation and demonstrates the effectiveness of our approach to adversarial text generation.
Hierarchical and Progressive Image Matting
Oct 13, 2022
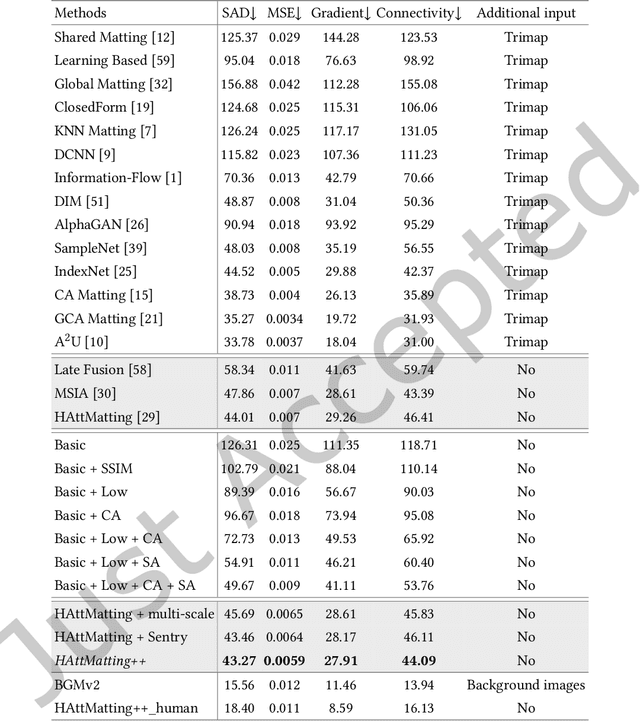
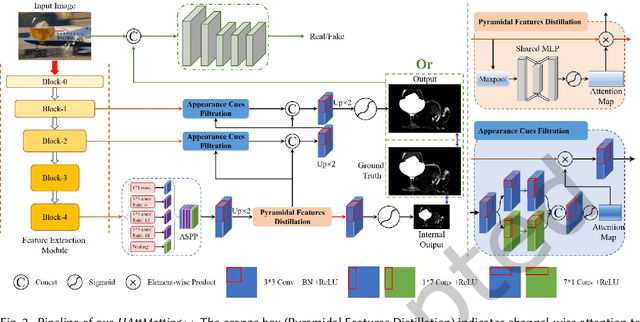
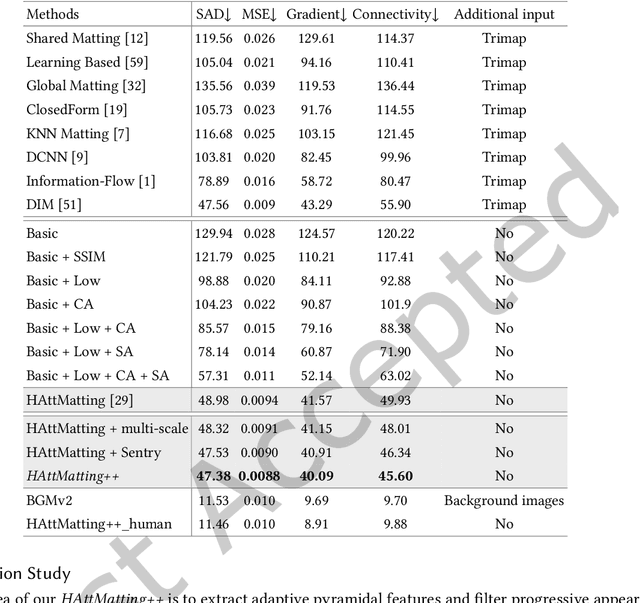
Most matting researches resort to advanced semantics to achieve high-quality alpha mattes, and direct low-level features combination is usually explored to complement alpha details. However, we argue that appearance-agnostic integration can only provide biased foreground details and alpha mattes require different-level feature aggregation for better pixel-wise opacity perception. In this paper, we propose an end-to-end Hierarchical and Progressive Attention Matting Network (HAttMatting++), which can better predict the opacity of the foreground from single RGB images without additional input. Specifically, we utilize channel-wise attention to distill pyramidal features and employ spatial attention at different levels to filter appearance cues. This progressive attention mechanism can estimate alpha mattes from adaptive semantics and semantics-indicated boundaries. We also introduce a hybrid loss function fusing Structural SIMilarity (SSIM), Mean Square Error (MSE), Adversarial loss, and sentry supervision to guide the network to further improve the overall foreground structure. Besides, we construct a large-scale and challenging image matting dataset comprised of 59, 600 training images and 1000 test images (a total of 646 distinct foreground alpha mattes), which can further improve the robustness of our hierarchical and progressive aggregation model. Extensive experiments demonstrate that the proposed HAttMatting++ can capture sophisticated foreground structures and achieve state-of-the-art performance with single RGB images as input.
ShiftDDPMs: Exploring Conditional Diffusion Models by Shifting Diffusion Trajectories
Feb 05, 2023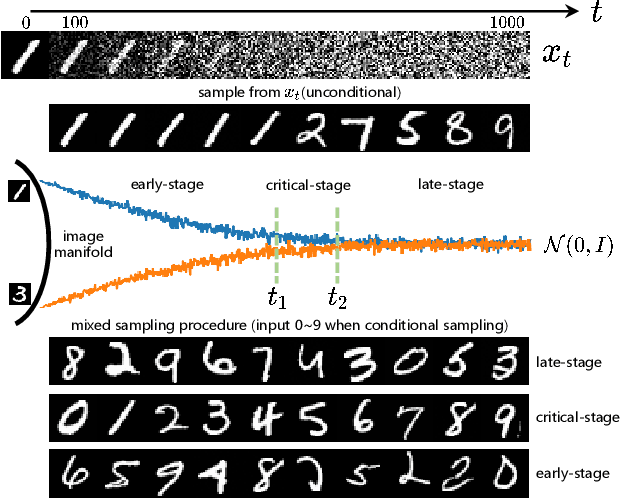
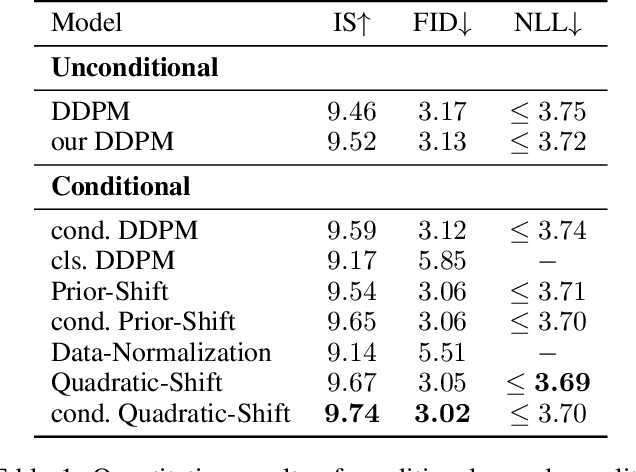
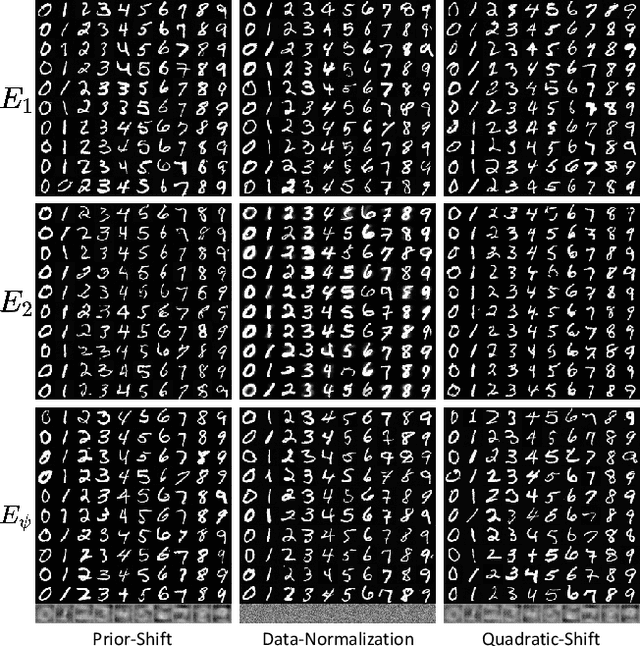
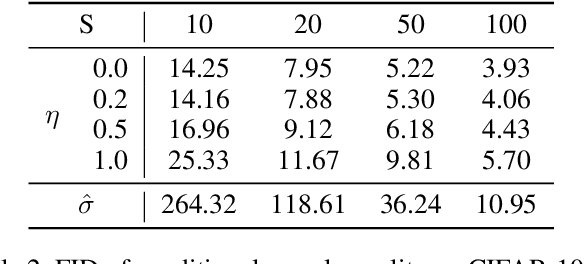
Diffusion models have recently exhibited remarkable abilities to synthesize striking image samples since the introduction of denoising diffusion probabilistic models (DDPMs). Their key idea is to disrupt images into noise through a fixed forward process and learn its reverse process to generate samples from noise in a denoising way. For conditional DDPMs, most existing practices relate conditions only to the reverse process and fit it to the reversal of unconditional forward process. We find this will limit the condition modeling and generation in a small time window. In this paper, we propose a novel and flexible conditional diffusion model by introducing conditions into the forward process. We utilize extra latent space to allocate an exclusive diffusion trajectory for each condition based on some shifting rules, which will disperse condition modeling to all timesteps and improve the learning capacity of model. We formulate our method, which we call \textbf{ShiftDDPMs}, and provide a unified point of view on existing related methods. Extensive qualitative and quantitative experiments on image synthesis demonstrate the feasibility and effectiveness of ShiftDDPMs.
TIC: Text-Guided Image Colorization
Aug 04, 2022

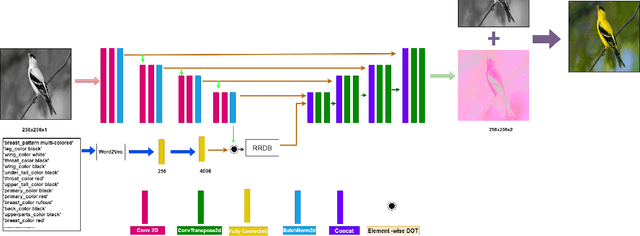
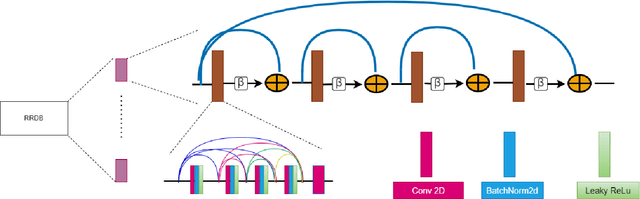
Image colorization is a well-known problem in computer vision. However, due to the ill-posed nature of the task, image colorization is inherently challenging. Though several attempts have been made by researchers to make the colorization pipeline automatic, these processes often produce unrealistic results due to a lack of conditioning. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To the best of our knowledge, this is one of the first attempts to incorporate textual conditioning in the colorization pipeline. To do so, we have proposed a novel deep network that takes two inputs (the grayscale image and the respective encoded text description) and tries to predict the relevant color gamut. As the respective textual descriptions contain color information of the objects present in the scene, the text encoding helps to improve the overall quality of the predicted colors. We have evaluated our proposed model using different metrics and found that it outperforms the state-of-the-art colorization algorithms both qualitatively and quantitatively.
An Investigation into Pre-Training Object-Centric Representations for Reinforcement Learning
Feb 09, 2023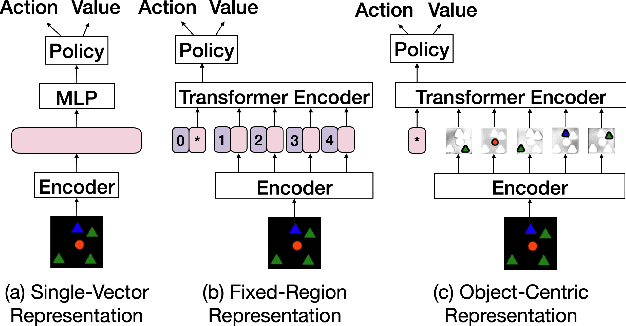
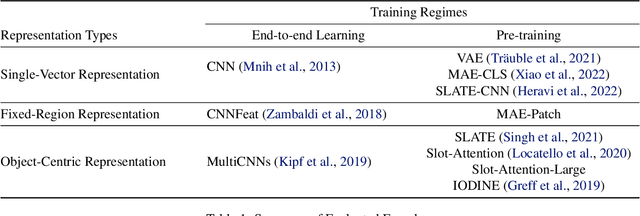
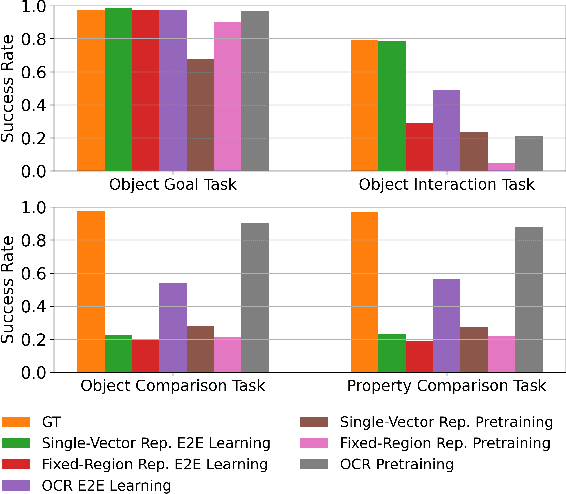
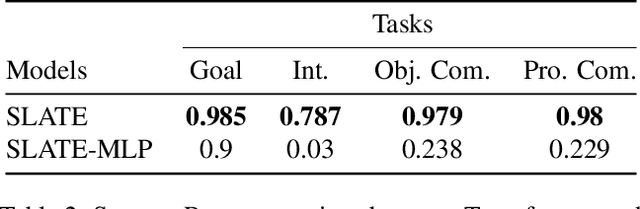
Unsupervised object-centric representation (OCR) learning has recently drawn attention as a new paradigm of visual representation. This is because of its potential of being an effective pre-training technique for various downstream tasks in terms of sample efficiency, systematic generalization, and reasoning. Although image-based reinforcement learning (RL) is one of the most important and thus frequently mentioned such downstream tasks, the benefit in RL has surprisingly not been investigated systematically thus far. Instead, most of the evaluations have focused on rather indirect metrics such as segmentation quality and object property prediction accuracy. In this paper, we investigate the effectiveness of OCR pre-training for image-based reinforcement learning via empirical experiments. For systematic evaluation, we introduce a simple object-centric visual RL benchmark and conduct experiments to answer questions such as ``Does OCR pre-training improve performance on object-centric tasks?'' and ``Can OCR pre-training help with out-of-distribution generalization?''. Our results provide empirical evidence for valuable insights into the effectiveness of OCR pre-training for RL and the potential limitations of its use in certain scenarios. Additionally, this study also examines the critical aspects of incorporating OCR pre-training in RL, including performance in a visually complex environment and the appropriate pooling layer to aggregate the object representations.
SimCon Loss with Multiple Views for Text Supervised Semantic Segmentation
Feb 07, 2023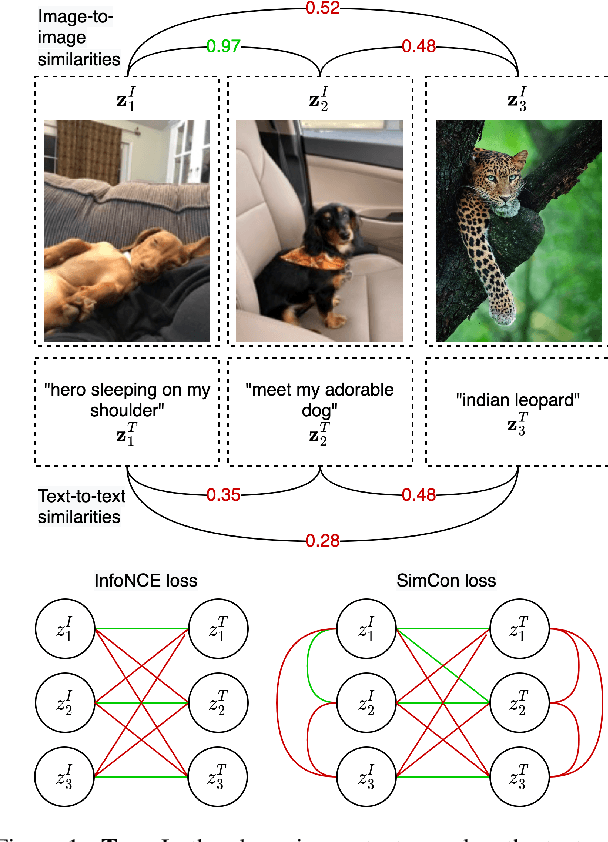
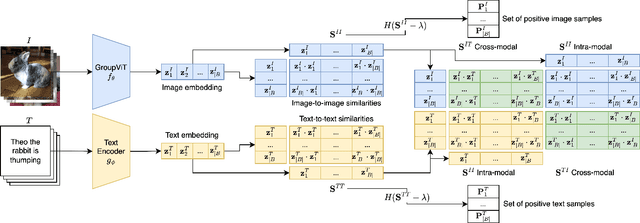
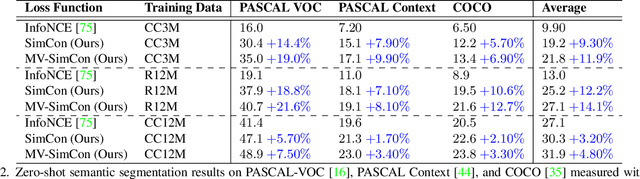
Learning to segment images purely by relying on the image-text alignment from web data can lead to sub-optimal performance due to noise in the data. The noise comes from the samples where the associated text does not correlate with the image's visual content. Instead of purely relying on the alignment from the noisy data, this paper proposes a novel loss function termed SimCon, which accounts for intra-modal similarities to determine the appropriate set of positive samples to align. Further, using multiple views of the image (created synthetically) for training and combining the SimCon loss with it makes the training more robust. This version of the loss is termed MV-SimCon. The empirical results demonstrate that using the proposed loss function leads to consistent improvements on zero-shot, text supervised semantic segmentation and outperforms state-of-the-art by $+3.0\%$, $+3.3\%$ and $+6.9\%$ on PASCAL VOC, PASCAL Context and MSCOCO, respectively. With test time augmentations, we set a new record by improving these results further to $58.7\%$, $26.6\%$, and $33.3\%$ on PASCAL VOC, PASCAL Context, and MSCOCO, respectively. In addition, using the proposed loss function leads to robust training and faster convergence.