 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022
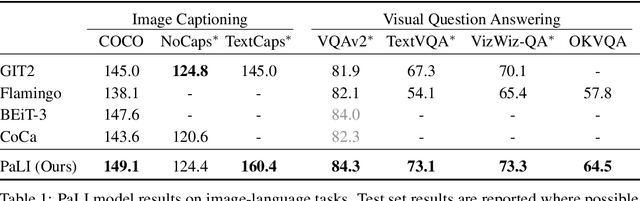

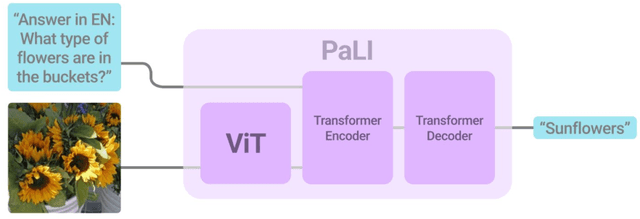

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
Visual Story Generation Based on Emotion and Keywords
Jan 07, 2023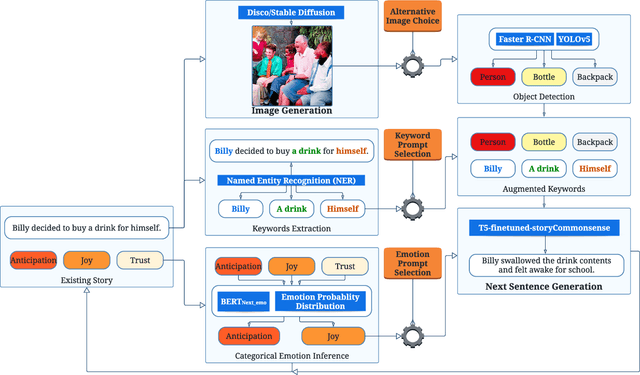

Automated visual story generation aims to produce stories with corresponding illustrations that exhibit coherence, progression, and adherence to characters' emotional development. This work proposes a story generation pipeline to co-create visual stories with the users. The pipeline allows the user to control events and emotions on the generated content. The pipeline includes two parts: narrative and image generation. For narrative generation, the system generates the next sentence using user-specified keywords and emotion labels. For image generation, diffusion models are used to create a visually appealing image corresponding to each generated sentence. Further, object recognition is applied to the generated images to allow objects in these images to be mentioned in future story development.
Geometry-Complete Diffusion for 3D Molecule Generation
Feb 15, 2023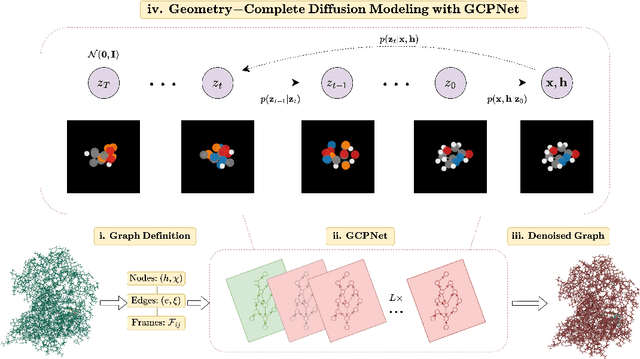
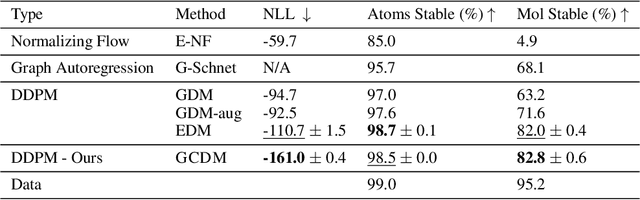
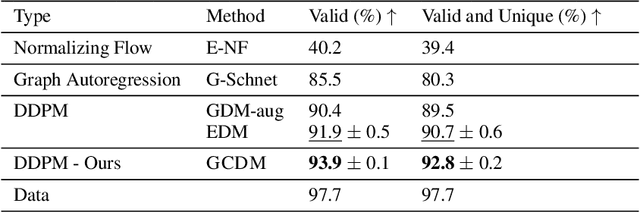
Denoising diffusion probabilistic models (DDPMs) have recently taken the field of generative modeling by storm, pioneering new state-of-the-art results in disciplines such as computer vision and computational biology for diverse tasks ranging from text-guided image generation to structure-guided protein design. Along this latter line of research, methods such as those of Hoogeboom et al. 2022 have been proposed for unconditionally generating 3D molecules using equivariant graph neural networks (GNNs) within a DDPM framework. Toward this end, we propose GCDM, a geometry-complete diffusion model that achieves new state-of-the-art results for 3D molecule diffusion generation by leveraging the representation learning strengths offered by GNNs that perform geometry-complete message-passing. Our results with GCDM also offer preliminary insights into how physical inductive biases impact the generative dynamics of molecular DDPMs. The source code, data, and instructions to train new models or reproduce our results are freely available at https://github.com/BioinfoMachineLearning/bio-diffusion.
Improved Online Conformal Prediction via Strongly Adaptive Online Learning
Feb 15, 2023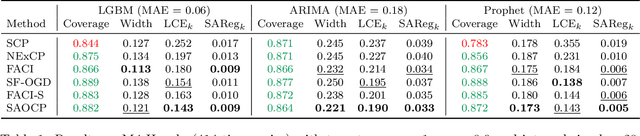
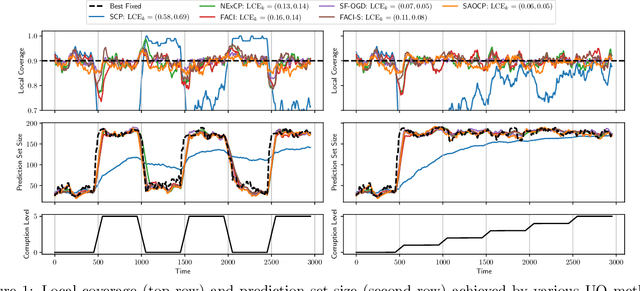

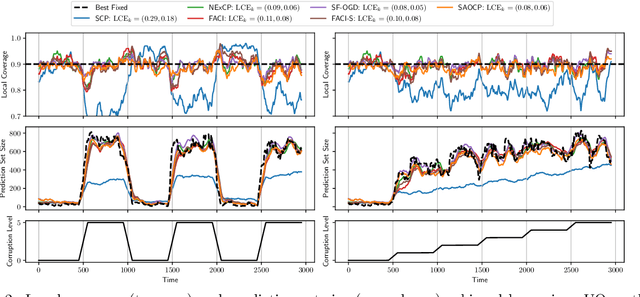
We study the problem of uncertainty quantification via prediction sets, in an online setting where the data distribution may vary arbitrarily over time. Recent work develops online conformal prediction techniques that leverage regret minimization algorithms from the online learning literature to learn prediction sets with approximately valid coverage and small regret. However, standard regret minimization could be insufficient for handling changing environments, where performance guarantees may be desired not only over the full time horizon but also in all (sub-)intervals of time. We develop new online conformal prediction methods that minimize the strongly adaptive regret, which measures the worst-case regret over all intervals of a fixed length. We prove that our methods achieve near-optimal strongly adaptive regret for all interval lengths simultaneously, and approximately valid coverage. Experiments show that our methods consistently obtain better coverage and smaller prediction sets than existing methods on real-world tasks, such as time series forecasting and image classification under distribution shift.
Unsupervised Hashing via Similarity Distribution Calibration
Feb 15, 2023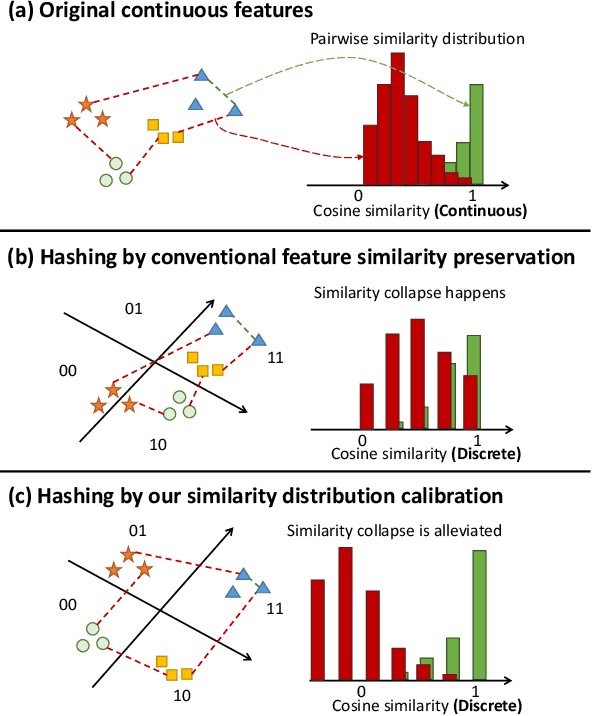
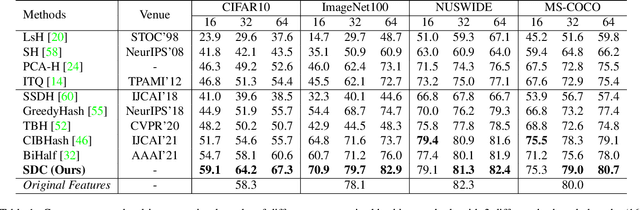
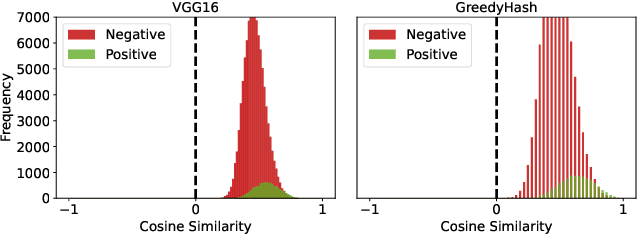

Existing unsupervised hashing methods typically adopt a feature similarity preservation paradigm. As a result, they overlook the intrinsic similarity capacity discrepancy between the continuous feature and discrete hash code spaces. Specifically, since the feature similarity distribution is intrinsically biased (e.g., moderately positive similarity scores on negative pairs), the hash code similarities of positive and negative pairs often become inseparable (i.e., the similarity collapse problem). To solve this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. Instead of matching individual pairwise similarity scores, SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity capacity/range, to alleviate the similarity collapse problem. Extensive experiments show that our SDC outperforms the state-of-the-art alternatives on both coarse category-level and instance-level image retrieval tasks, often by a large margin. Code is available at https://github.com/kamwoh/sdc.
Spatio-spectral Image Reconstruction Using Non-local Filtering
Sep 16, 2022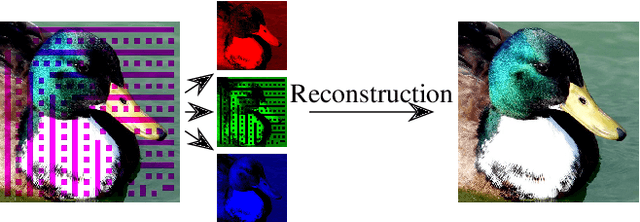
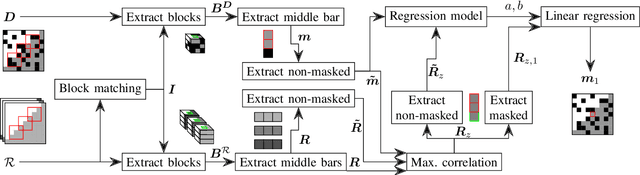

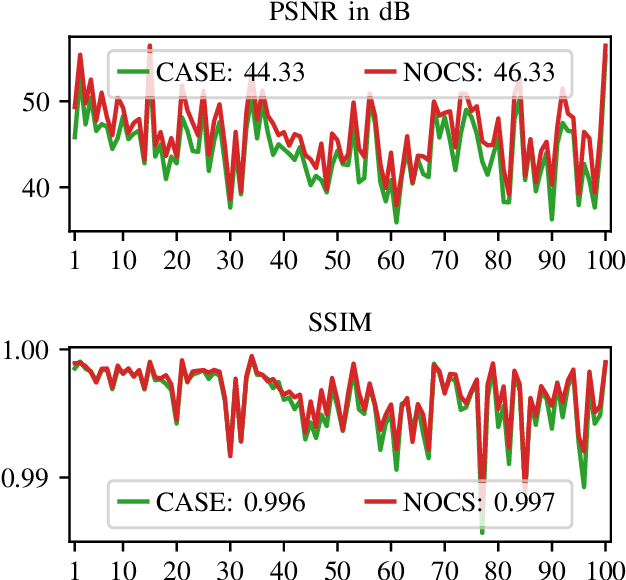
In many image processing tasks it occurs that pixels or blocks of pixels are missing or lost in only some channels. For example during defective transmissions of RGB images, it may happen that one or more blocks in one color channel are lost. Nearly all modern applications in image processing and transmission use at least three color channels, some of the applications employ even more bands, for example in the infrared and ultraviolet area of the light spectrum. Typically, only some pixels and blocks in a subset of color channels are distorted. Thus, other channels can be used to reconstruct the missing pixels, which is called spatio-spectral reconstruction. Current state-of-the-art methods purely rely on the local neighborhood, which works well for homogeneous regions. However, in high-frequency regions like edges or textures, these methods fail to properly model the relationship between color bands. Hence, this paper introduces non-local filtering for building a linear regression model that describes the inter-band relationship and is used to reconstruct the missing pixels. Our novel method is able to increase the PSNR on average by 2 dB and yields visually much more appealing images in high-frequency regions.
Pretraining is All You Need for Image-to-Image Translation
May 25, 2022



We propose to use pretraining to boost general image-to-image translation. Prior image-to-image translation methods usually need dedicated architectural design and train individual translation models from scratch, struggling for high-quality generation of complex scenes, especially when paired training data are not abundant. In this paper, we regard each image-to-image translation problem as a downstream task and introduce a simple and generic framework that adapts a pretrained diffusion model to accommodate various kinds of image-to-image translation. We also propose adversarial training to enhance the texture synthesis in the diffusion model training, in conjunction with normalized guidance sampling to improve the generation quality. We present extensive empirical comparison across various tasks on challenging benchmarks such as ADE20K, COCO-Stuff, and DIODE, showing the proposed pretraining-based image-to-image translation (PITI) is capable of synthesizing images of unprecedented realism and faithfulness.
Diffusion Models For Stronger Face Morphing Attacks
Jan 10, 2023
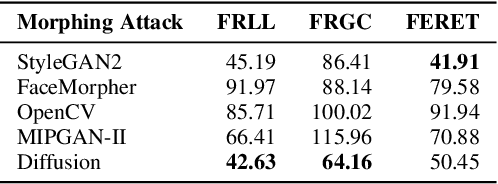
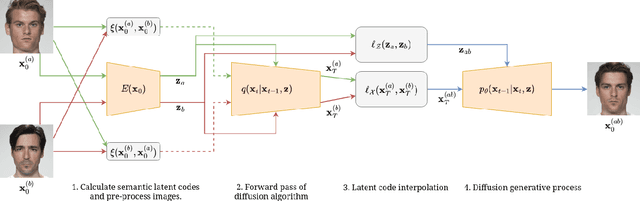
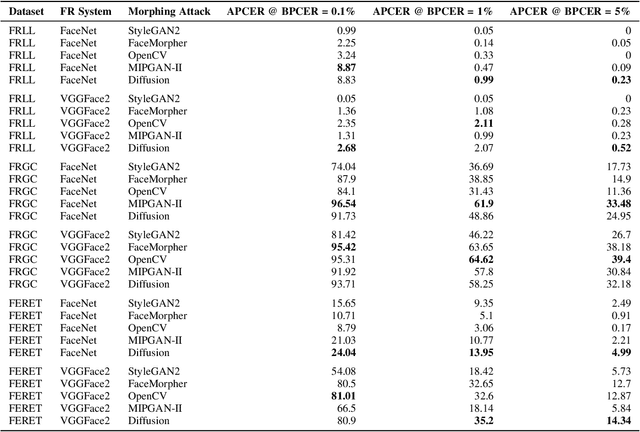
Face morphing attacks seek to deceive a Face Recognition (FR) system by presenting a morphed image consisting of the biometric qualities from two different identities with the aim of triggering a false acceptance with one of the two identities, thereby presenting a significant threat to biometric systems. The success of a morphing attack is dependent on the ability of the morphed image to represent the biometric characteristics of both identities that were used to create the image. We present a novel morphing attack that uses a Diffusion-based architecture to improve the visual fidelity of the image and improve the ability of the morphing attack to represent characteristics from both identities. We demonstrate the high fidelity of the proposed attack by evaluating its visual fidelity via the Frechet Inception Distance. Extensive experiments are conducted to measure the vulnerability of FR systems to the proposed attack. The proposed attack is compared to two state-of-the-art GAN-based morphing attacks along with two Landmark-based attacks. The ability of a morphing attack detector to detect the proposed attack is measured and compared against the other attacks. Additionally, a novel metric to measure the relative strength between morphing attacks is introduced and evaluated.
Unsupervised visualization of image datasets using contrastive learning
Oct 18, 2022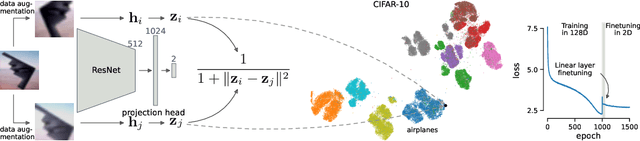
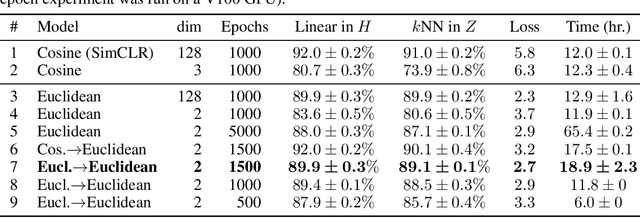
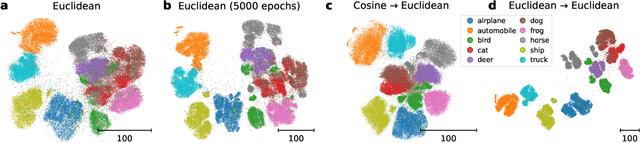
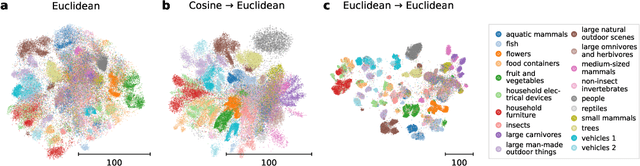
Visualization methods based on the nearest neighbor graph, such as t-SNE or UMAP, are widely used for visualizing high-dimensional data. Yet, these approaches only produce meaningful results if the nearest neighbors themselves are meaningful. For images represented in pixel space this is not the case, as distances in pixel space are often not capturing our sense of similarity and therefore neighbors are not semantically close. This problem can be circumvented by self-supervised approaches based on contrastive learning, such as SimCLR, relying on data augmentation to generate implicit neighbors, but these methods do not produce two-dimensional embeddings suitable for visualization. Here, we present a new method, called t-SimCNE, for unsupervised visualization of image data. T-SimCNE combines ideas from contrastive learning and neighbor embeddings, and trains a parametric mapping from the high-dimensional pixel space into two dimensions. We show that the resulting 2D embeddings achieve classification accuracy comparable to the state-of-the-art high-dimensional SimCLR representations, thus faithfully capturing semantic relationships. Using t-SimCNE, we obtain informative visualizations of the CIFAR-10 and CIFAR-100 datasets, showing rich cluster structure and highlighting artifacts and outliers.
TT-TFHE: a Torus Fully Homomorphic Encryption-Friendly Neural Network Architecture
Feb 03, 2023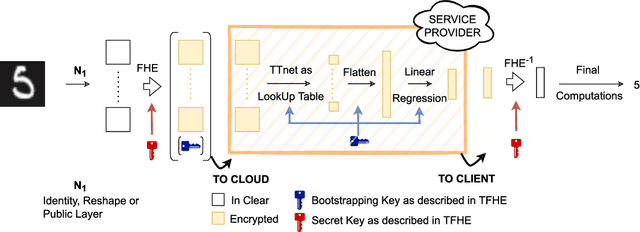
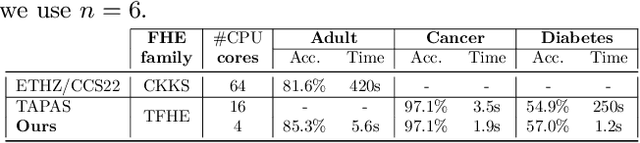
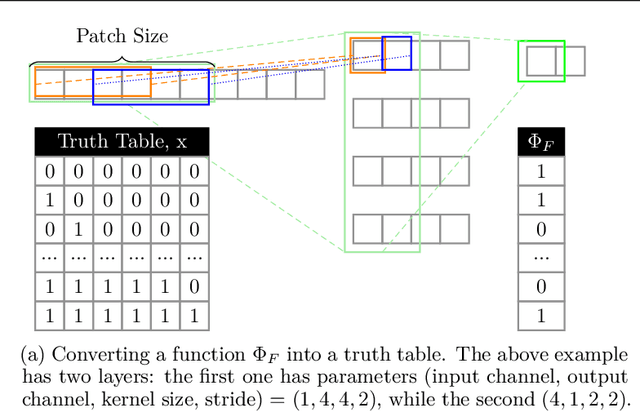
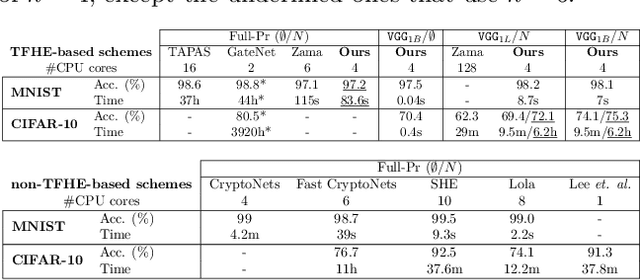
This paper presents TT-TFHE, a deep neural network Fully Homomorphic Encryption (FHE) framework that effectively scales Torus FHE (TFHE) usage to tabular and image datasets using a recent family of convolutional neural networks called Truth-Table Neural Networks (TTnet). The proposed framework provides an easy-to-implement, automated TTnet-based design toolbox with an underlying (python-based) open-source Concrete implementation (CPU-based and implementing lookup tables) for inference over encrypted data. Experimental evaluation shows that TT-TFHE greatly outperforms in terms of time and accuracy all Homomorphic Encryption (HE) set-ups on three tabular datasets, all other features being equal. On image datasets such as MNIST and CIFAR-10, we show that TT-TFHE consistently and largely outperforms other TFHE set-ups and is competitive against other HE variants such as BFV or CKKS (while maintaining the same level of 128-bit encryption security guarantees). In addition, our solutions present a very low memory footprint (down to dozens of MBs for MNIST), which is in sharp contrast with other HE set-ups that typically require tens to hundreds of GBs of memory per user (in addition to their communication overheads). This is the first work presenting a fully practical solution of private inference (i.e. a few seconds for inference time and a few dozens MBs of memory) on both tabular datasets and MNIST, that can easily scale to multiple threads and users on server side.