 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Online Conformal Prediction via Strongly Adaptive Online Learning
Feb 15, 2023
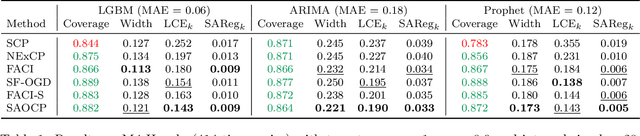
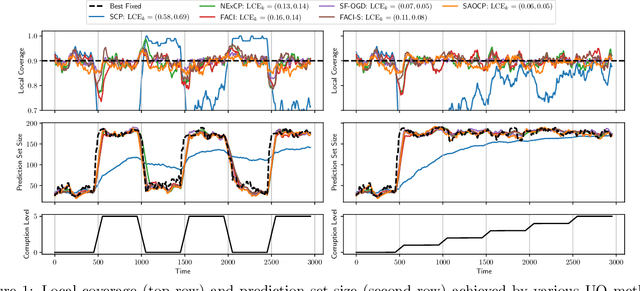

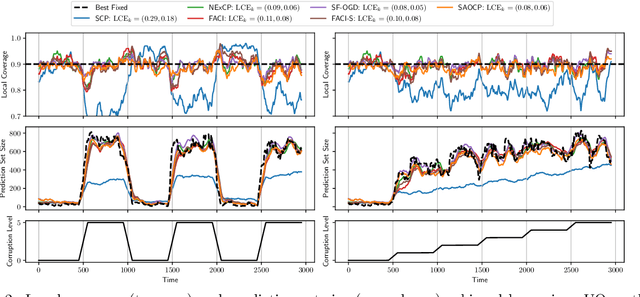
We study the problem of uncertainty quantification via prediction sets, in an online setting where the data distribution may vary arbitrarily over time. Recent work develops online conformal prediction techniques that leverage regret minimization algorithms from the online learning literature to learn prediction sets with approximately valid coverage and small regret. However, standard regret minimization could be insufficient for handling changing environments, where performance guarantees may be desired not only over the full time horizon but also in all (sub-)intervals of time. We develop new online conformal prediction methods that minimize the strongly adaptive regret, which measures the worst-case regret over all intervals of a fixed length. We prove that our methods achieve near-optimal strongly adaptive regret for all interval lengths simultaneously, and approximately valid coverage. Experiments show that our methods consistently obtain better coverage and smaller prediction sets than existing methods on real-world tasks, such as time series forecasting and image classification under distribution shift.
ZScribbleSeg: Zen and the Art of Scribble Supervised Medical Image Segmentation
Jan 12, 2023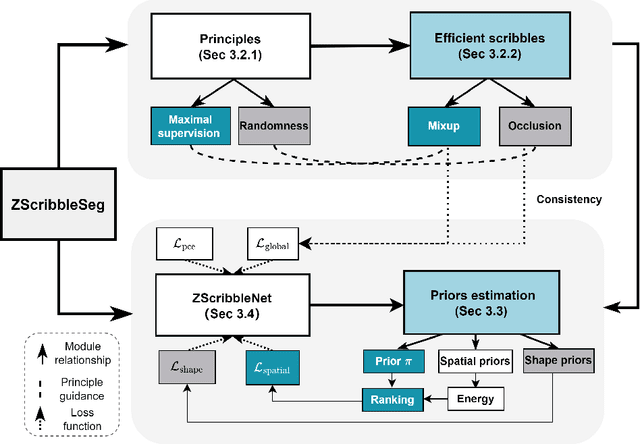

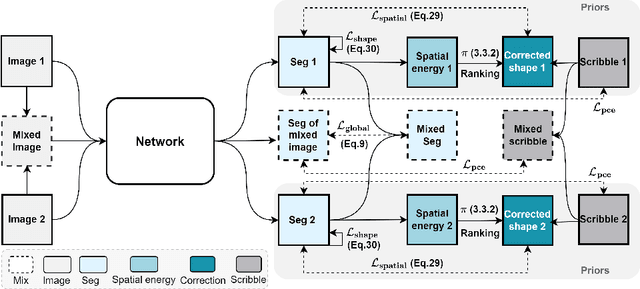
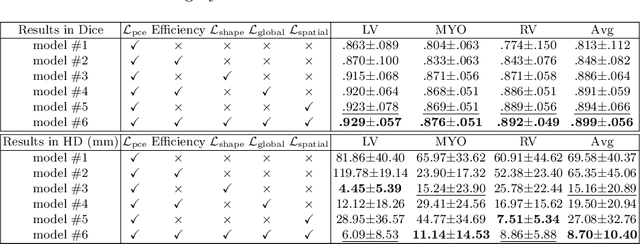
Curating a large scale fully-annotated dataset can be both labour-intensive and expertise-demanding, especially for medical images. To alleviate this problem, we propose to utilize solely scribble annotations for weakly supervised segmentation. Existing solutions mainly leverage selective losses computed solely on annotated areas and generate pseudo gold standard segmentation by propagating labels to adjacent areas. However, these methods could suffer from the inaccurate and sometimes unrealistic pseudo segmentation due to the insufficient supervision and incomplete shape features. Different from previous efforts, we first investigate the principle of ''good scribble annotations'', which leads to efficient scribble forms via supervision maximization and randomness simulation. Furthermore, we introduce regularization terms to encode the spatial relationship and shape prior, where a new formulation is developed to estimate the mixture ratios of label classes. These ratios are critical in identifying the unlabeled pixels for each class and correcting erroneous predictions, thus the accurate estimation lays the foundation for the incorporation of spatial prior. Finally, we integrate the efficient scribble supervision with the prior into a unified framework, denoted as ZScribbleSeg, and apply the method to multiple scenarios. Leveraging only scribble annotations, ZScribbleSeg set new state-of-the-arts on four segmentation tasks using ACDC, MSCMRseg, MyoPS and PPSS datasets.
Raw or Cooked? Object Detection on RAW Images
Jan 21, 2023


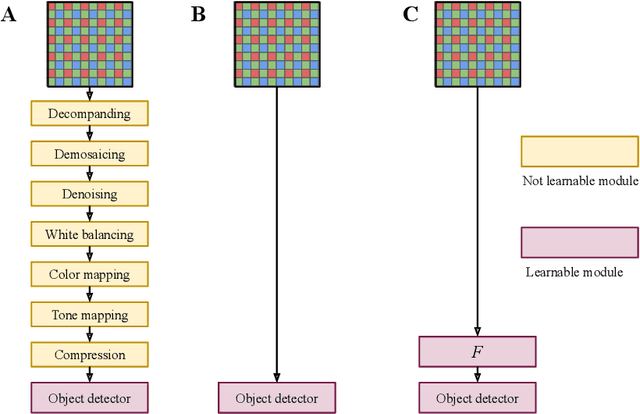
Images fed to a deep neural network have in general undergone several handcrafted image signal processing (ISP) operations, all of which have been optimized to produce visually pleasing images. In this work, we investigate the hypothesis that the intermediate representation of visually pleasing images is sub-optimal for downstream computer vision tasks compared to the RAW image representation. We suggest that the operations of the ISP instead should be optimized towards the end task, by learning the parameters of the operations jointly during training. We extend previous works on this topic and propose a new learnable operation that enables an object detector to achieve superior performance when compared to both previous works and traditional RGB images. In experiments on the open PASCALRAW dataset, we empirically confirm our hypothesis.
SPARC: Sparse Render-and-Compare for CAD model alignment in a single RGB image
Oct 03, 2022

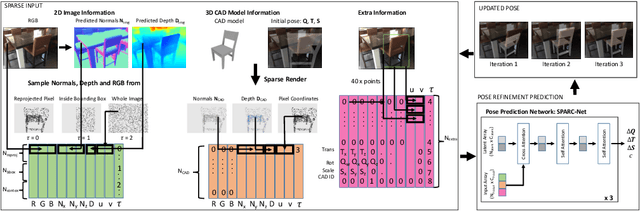
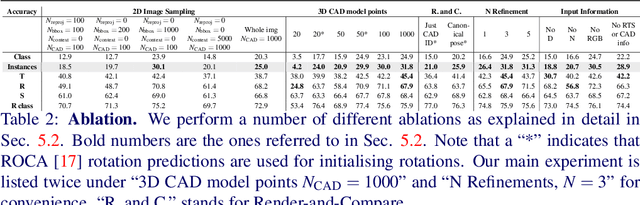
Estimating 3D shapes and poses of static objects from a single image has important applications for robotics, augmented reality and digital content creation. Often this is done through direct mesh predictions which produces unrealistic, overly tessellated shapes or by formulating shape prediction as a retrieval task followed by CAD model alignment. Directly predicting CAD model poses from 2D image features is difficult and inaccurate. Some works, such as ROCA, regress normalised object coordinates and use those for computing poses. While this can produce more accurate pose estimates, predicting normalised object coordinates is susceptible to systematic failure. Leveraging efficient transformer architectures we demonstrate that a sparse, iterative, render-and-compare approach is more accurate and robust than relying on normalised object coordinates. For this we combine 2D image information including sparse depth and surface normal values which we estimate directly from the image with 3D CAD model information in early fusion. In particular, we reproject points sampled from the CAD model in an initial, random pose and compute their depth and surface normal values. This combined information is the input to a pose prediction network, SPARC-Net which we train to predict a 9 DoF CAD model pose update. The CAD model is reprojected again and the next pose update is predicted. Our alignment procedure converges after just 3 iterations, improving the state-of-the-art performance on the challenging real-world dataset ScanNet from 25.0% to 31.8% instance alignment accuracy. Code will be released at https://github.com/florianlanger/SPARC .
A Privacy Preserving Method with a Random Orthogonal Matrix for ConvMixer Models
Jan 17, 2023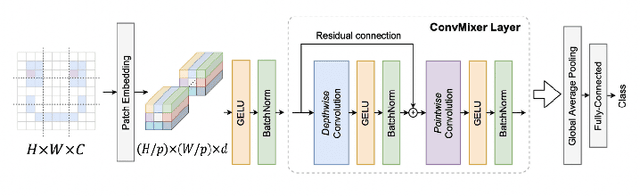

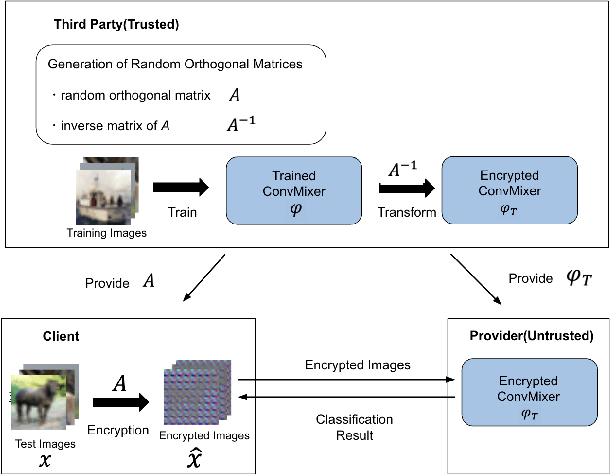
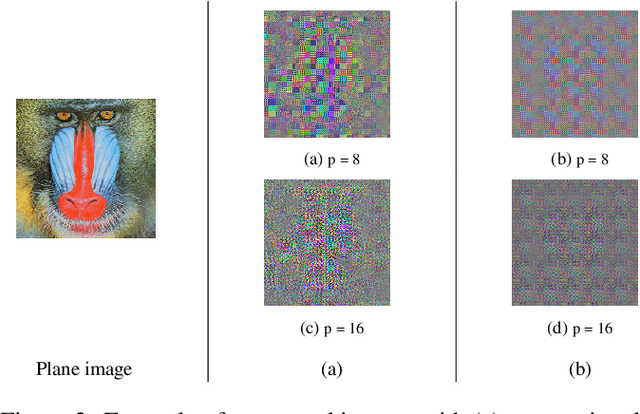
In this paper, a privacy preserving image classification method is proposed under the use of ConvMixer models. To protect the visual information of test images, a test image is divided into blocks, and then every block is encrypted by using a random orthogonal matrix. Moreover, a ConvMixer model trained with plain images is transformed by the random orthogonal matrix used for encrypting test images, on the basis of the embedding structure of ConvMixer. The proposed method allows us not only to use the same classification accuracy as that of ConvMixer models without considering privacy protection but to also enhance robustness against various attacks compared to conventional privacy-preserving learning.
Stereo X-ray Tomography
Feb 26, 2023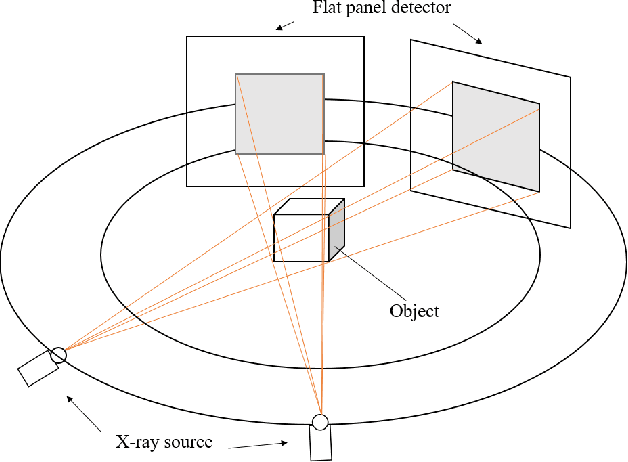

X-ray tomography is a powerful volumetric imaging technique, but detailed three dimensional (3D) imaging requires the acquisition of a large number of individual X-ray images, which is time consuming. For applications where spatial information needs to be collected quickly, for example, when studying dynamic processes, standard X-ray tomography is therefore not applicable. Inspired by stereo vision, in this paper, we develop X-ray imaging methods that work with two X-ray projection images. In this setting, without the use of additional strong prior information, we no longer have enough information to fully recover the 3D tomographic images. However, up to a point, we are nevertheless able to extract spatial locations of point and line features. From stereo vision, it is well known that, for a known imaging geometry, once the same point is identified in two images taken from different directions, then the point's location in 3D space is exactly specified. The challenge is the matching of points between images. As X-ray transmission images are fundamentally different from the surface reflection images used in standard computer vision, we here develop a different feature identification and matching approach. In fact, once point like features are identified, if there are limited points in the image, then they can often be matched exactly. In fact, by utilising a third observation from an appropriate direction, matching becomes unique. Once matched, point locations in 3D space are easily computed using geometric considerations. Linear features, with clear end points, can be located using a similar approach.
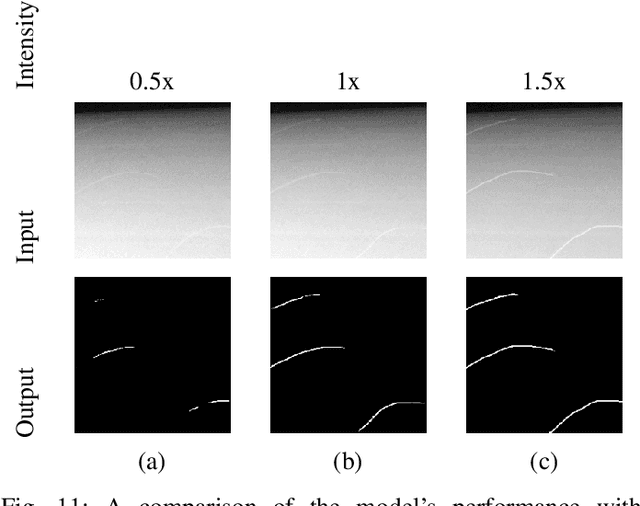
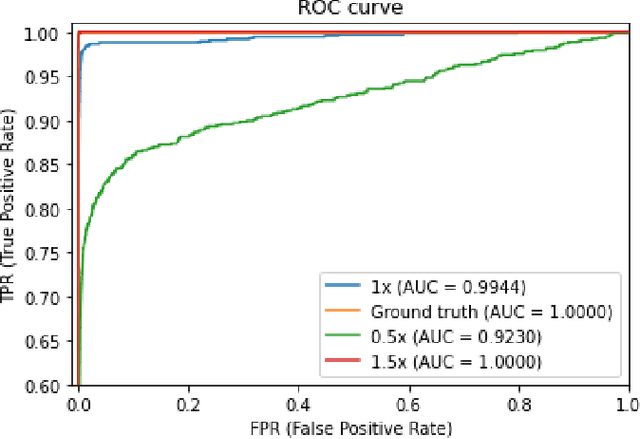
Lightweight Real-time Semantic Segmentation Network with Efficient Transformer and CNN
Feb 21, 2023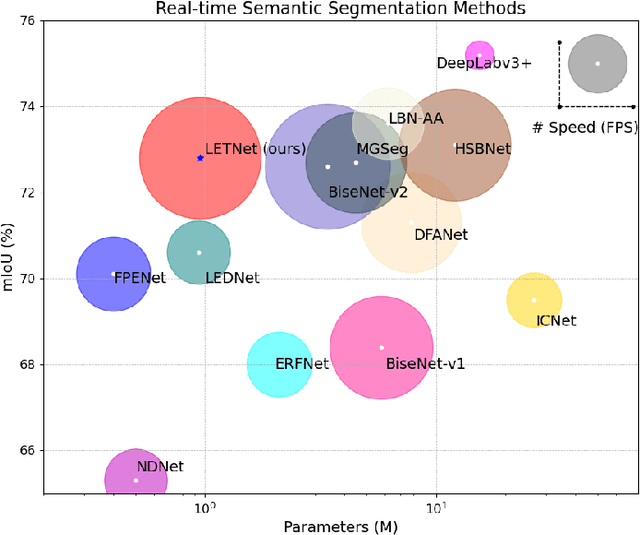
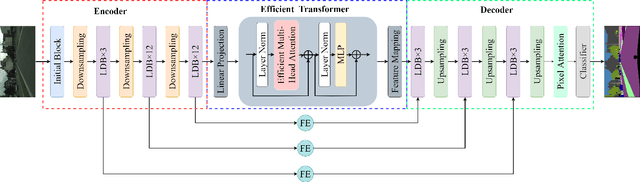
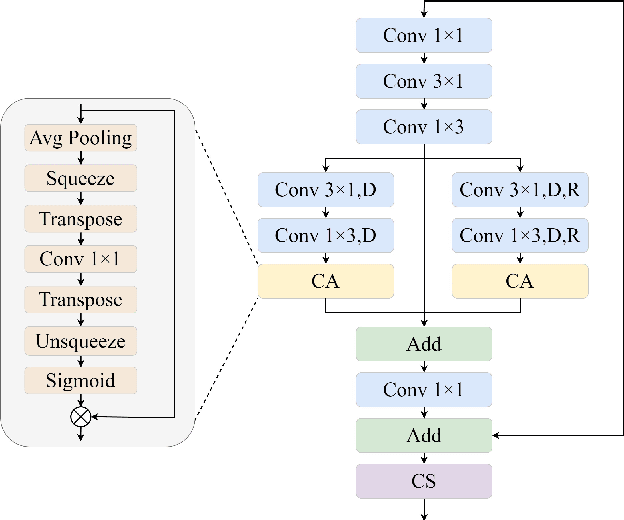
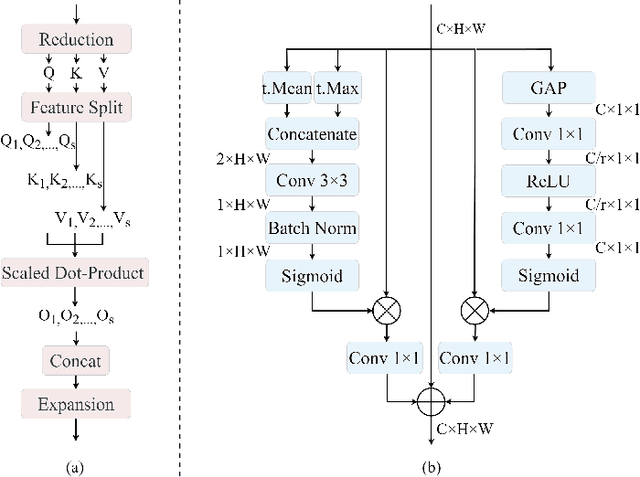
In the past decade, convolutional neural networks (CNNs) have shown prominence for semantic segmentation. Although CNN models have very impressive performance, the ability to capture global representation is still insufficient, which results in suboptimal results. Recently, Transformer achieved huge success in NLP tasks, demonstrating its advantages in modeling long-range dependency. Recently, Transformer has also attracted tremendous attention from computer vision researchers who reformulate the image processing tasks as a sequence-to-sequence prediction but resulted in deteriorating local feature details. In this work, we propose a lightweight real-time semantic segmentation network called LETNet. LETNet combines a U-shaped CNN with Transformer effectively in a capsule embedding style to compensate for respective deficiencies. Meanwhile, the elaborately designed Lightweight Dilated Bottleneck (LDB) module and Feature Enhancement (FE) module cultivate a positive impact on training from scratch simultaneously. Extensive experiments performed on challenging datasets demonstrate that LETNet achieves superior performances in accuracy and efficiency balance. Specifically, It only contains 0.95M parameters and 13.6G FLOPs but yields 72.8\% mIoU at 120 FPS on the Cityscapes test set and 70.5\% mIoU at 250 FPS on the CamVid test dataset using a single RTX 3090 GPU. The source code will be available at https://github.com/IVIPLab/LETNet.
MCAE: Masked Contrastive Autoencoder for Face Anti-Spoofing
Feb 17, 2023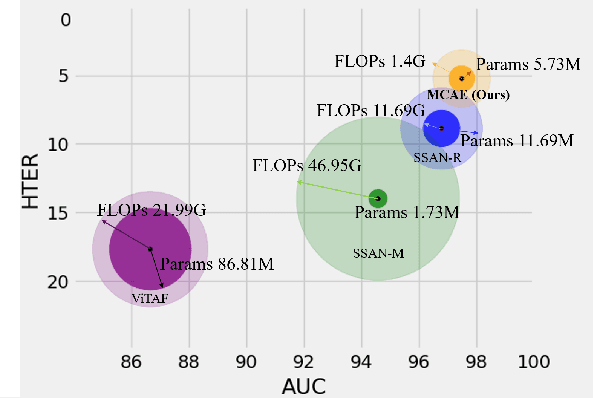
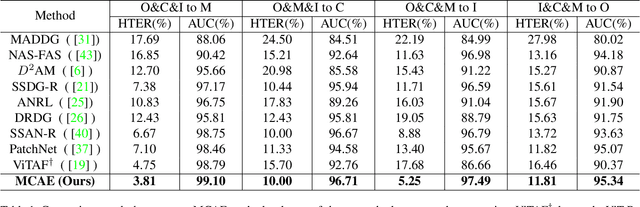
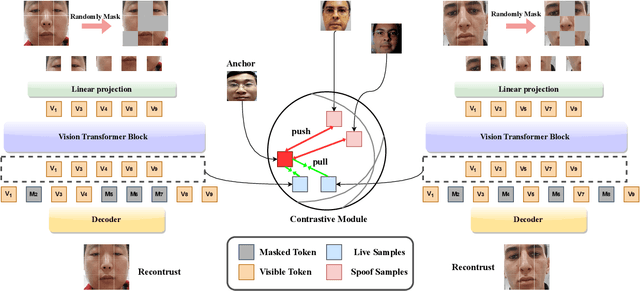
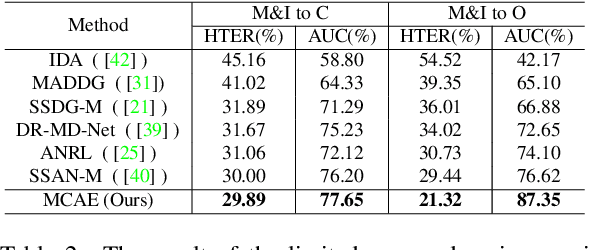
Face anti-spoofing (FAS) method performs well under the intra-domain setups. But cross-domain performance of the model is not satisfying. Domain generalization method has been used to align the feature from different domain extracted by convolutional neural network (CNN) backbone. However, the improvement is limited. Recently, the Vision Transformer (ViT) model has performed well on various visual tasks. But ViT model relies heavily on pre-training of large-scale dataset, which cannot be satisfied by existing FAS datasets. In this paper, taking the FAS task as an example, we propose Masked Contrastive Autoencoder (MCAE) method to solve this problem using only limited data. Meanwhile in order for a feature extractor to extract common features in live samples from different domains, we combine Masked Image Model (MIM) with supervised contrastive learning to train our model.Some intriguing design principles are summarized for performing MIM pre-training for downstream tasks.We also provide insightful analysis for our method from an information theory perspective. Experimental results show our approach has good performance on extensive public datasets and outperforms the state-of-the-art methods.
SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
Nov 22, 2022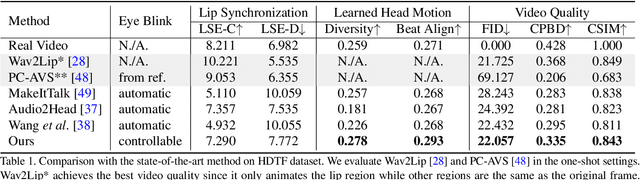
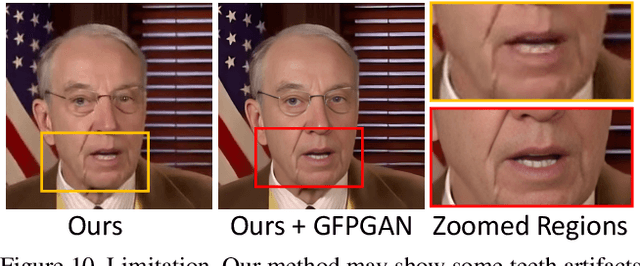
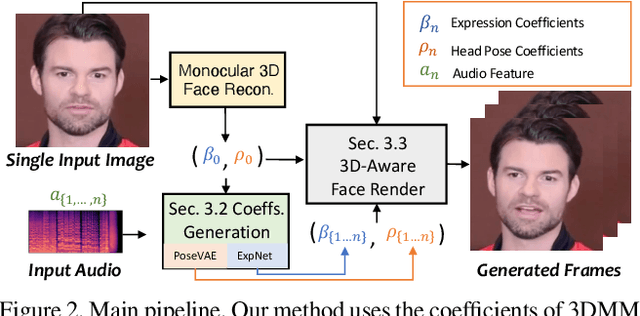
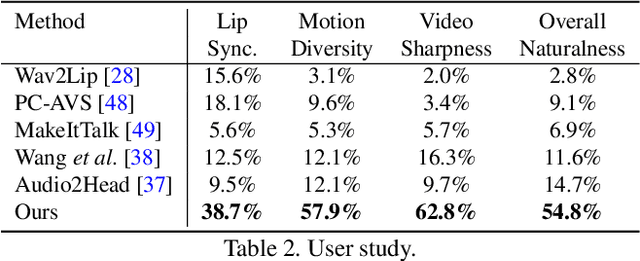
Generating talking head videos through a face image and a piece of speech audio still contains many challenges. ie, unnatural head movement, distorted expression, and identity modification. We argue that these issues are mainly because of learning from the coupled 2D motion fields. On the other hand, explicitly using 3D information also suffers problems of stiff expression and incoherent video. We present SadTalker, which generates 3D motion coefficients (head pose, expression) of the 3DMM from audio and implicitly modulates a novel 3D-aware face render for talking head generation. To learn the realistic motion coefficients, we explicitly model the connections between audio and different types of motion coefficients individually. Precisely, we present ExpNet to learn the accurate facial expression from audio by distilling both coefficients and 3D-rendered faces. As for the head pose, we design PoseVAE via a conditional VAE to synthesize head motion in different styles. Finally, the generated 3D motion coefficients are mapped to the unsupervised 3D keypoints space of the proposed face render, and synthesize the final video. We conduct extensive experiments to show the superior of our method in terms of motion and video quality.
Face Generation from Textual Features using Conditionally Trained Inputs to Generative Adversarial Networks
Jan 22, 2023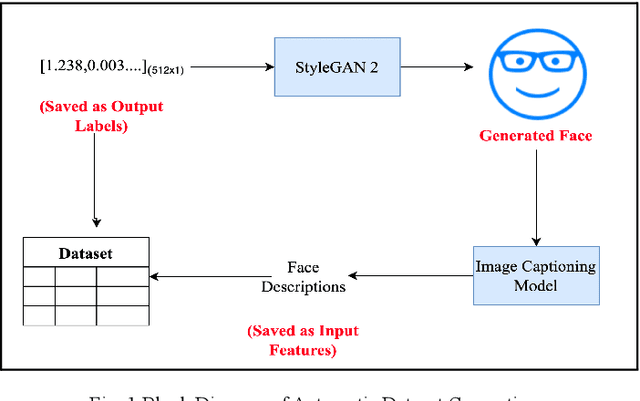
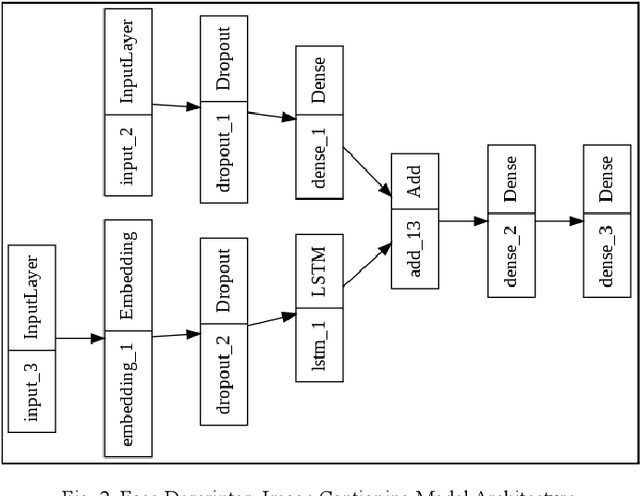
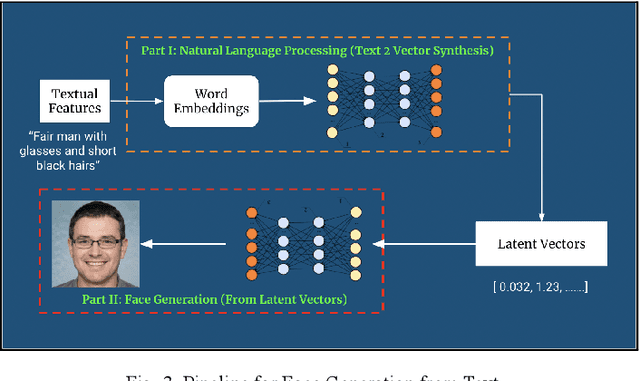
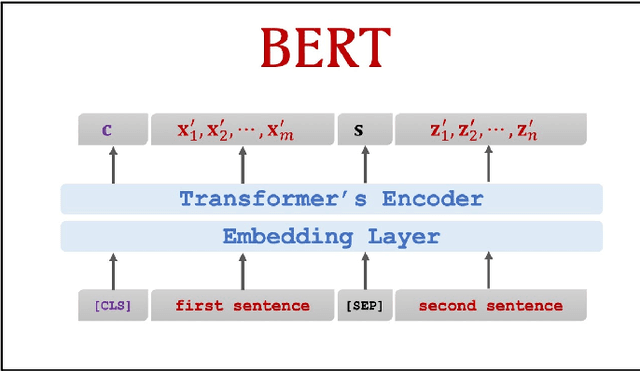
Generative Networks have proved to be extremely effective in image restoration and reconstruction in the past few years. Generating faces from textual descriptions is one such application where the power of generative algorithms can be used. The task of generating faces can be useful for a number of applications such as finding missing persons, identifying criminals, etc. This paper discusses a novel approach to generating human faces given a textual description regarding the facial features. We use the power of state of the art natural language processing models to convert face descriptions into learnable latent vectors which are then fed to a generative adversarial network which generates faces corresponding to those features. While this paper focuses on high level descriptions of faces only, the same approach can be tailored to generate any image based on fine grained textual features.