 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detecting Severity of Diabetic Retinopathy from Fundus Images using Ensembled Transformers
Jan 03, 2023
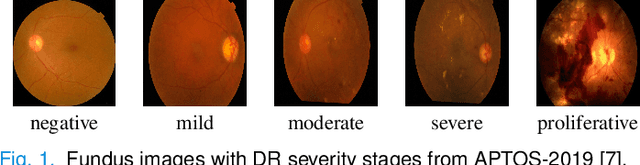
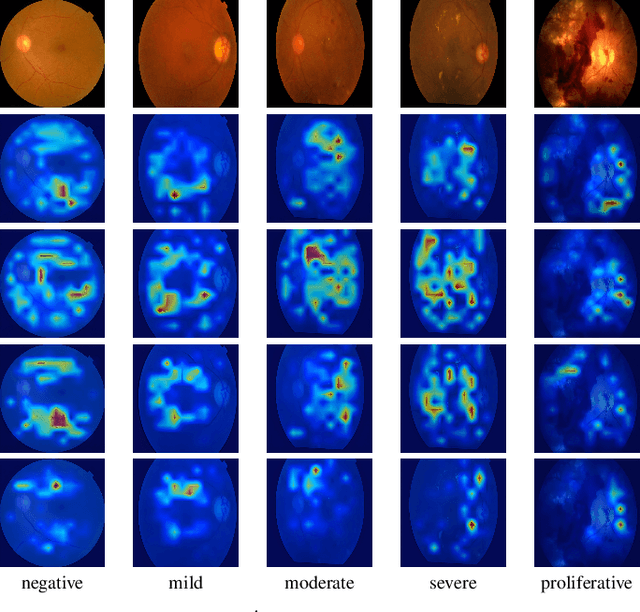
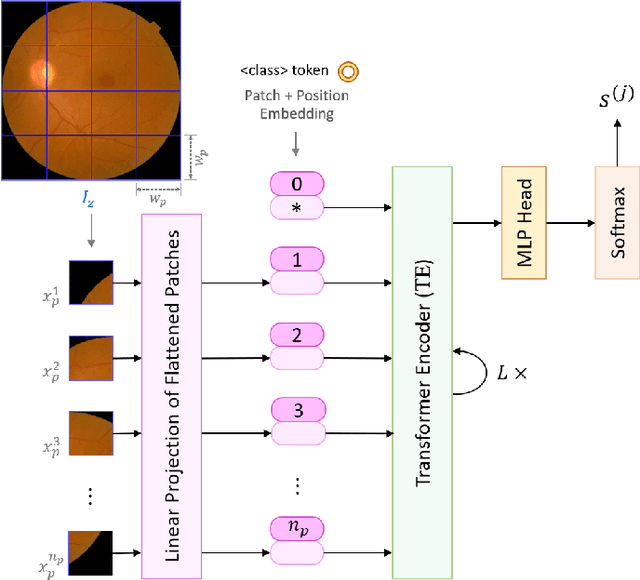
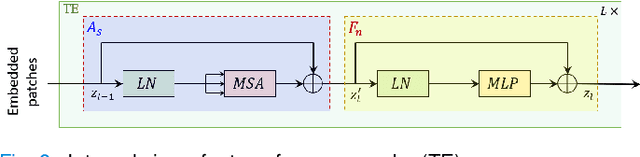
Diabetic Retinopathy (DR) is considered one of the primary concerns due to its effect on vision loss among most people with diabetes globally. The severity of DR is mostly comprehended manually by ophthalmologists from fundus photography-based retina images. This paper deals with an automated understanding of the severity stages of DR. In the literature, researchers have focused on this automation using traditional machine learning-based algorithms and convolutional architectures. However, the past works hardly focused on essential parts of the retinal image to improve the model performance. In this paper, we adopt transformer-based learning models to capture the crucial features of retinal images to understand DR severity better. We work with ensembling image transformers, where we adopt four models, namely ViT (Vision Transformer), BEiT (Bidirectional Encoder representation for image Transformer), CaiT (Class-Attention in Image Transformers), and DeiT (Data efficient image Transformers), to infer the degree of DR severity from fundus photographs. For experiments, we used the publicly available APTOS-2019 blindness detection dataset, where the performances of the transformer-based models were quite encouraging.
A semantic backdoor attack against Graph Convolutional Networks
Feb 28, 2023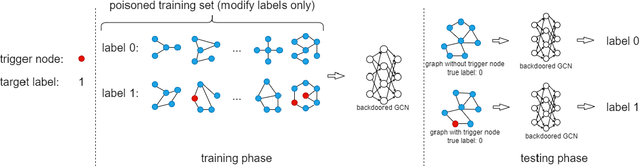
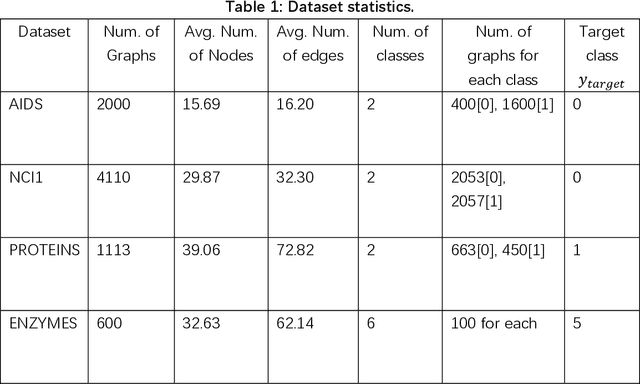
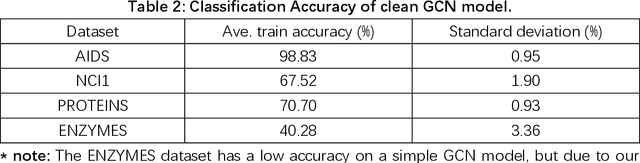
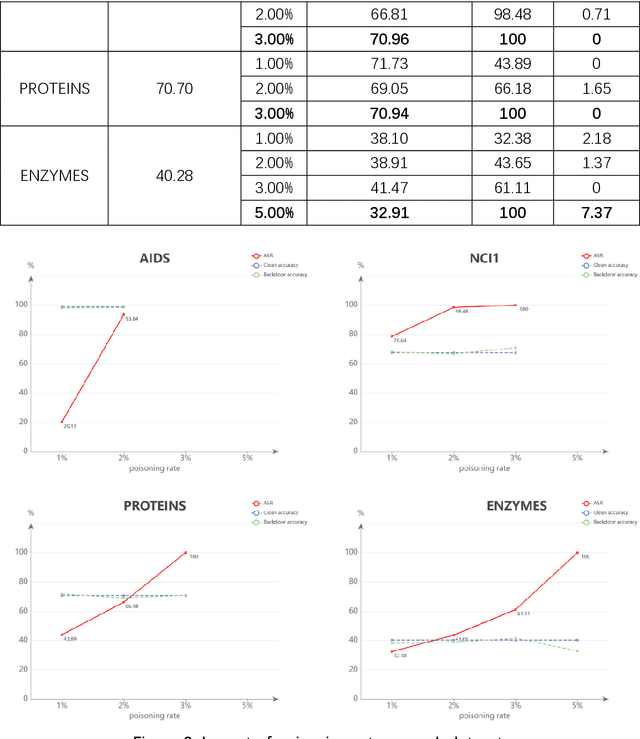
Graph Convolutional Networks (GCNs) have been very effective in addressing the issue of various graph-structured related tasks, such as node classification and graph classification. However, extensive research has shown that GCNs are vulnerable to adversarial attacks. One of the security threats facing GCNs is the backdoor attack, which hides incorrect classification rules in models and activates only when the model encounters specific inputs containing special features (e.g., fixed patterns like subgraphs, called triggers), thus outputting incorrect classification results, while the model behaves normally on benign samples. The semantic backdoor attack is a type of the backdoor attack where the trigger is a semantic part of the sample; i.e., the trigger exists naturally in the original dataset and the attacker can pick a naturally occurring feature as the backdoor trigger, which causes the model to misclassify even unmodified inputs. Meanwhile, it is difficult to detect even if the attacker modifies the input samples in the inference phase as they do not have any anomaly compared to normal samples. Thus, semantic backdoor attacks are more imperceptible than non-semantic ones. However, existed research on semantic backdoor attacks has only focused on image and text domains, which have not been well explored against GCNs. In this work, we propose a black-box Semantic Backdoor Attack (SBA) against GCNs. We assign the trigger as a certain class of nodes in the dataset and our trigger is semantic. Through evaluation on several real-world benchmark graph datasets, the experimental results demonstrate that our proposed SBA can achieve almost 100% attack success rate under the poisoning rate less than 5% while having no impact on normal predictive accuracy.
Towards Explainable Visual Anomaly Detection
Feb 13, 2023

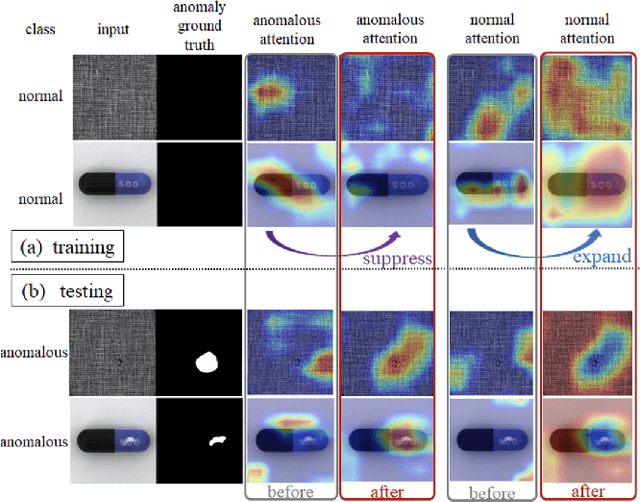

Anomaly detection and localization of visual data, including images and videos, are of great significance in both machine learning academia and applied real-world scenarios. Despite the rapid development of visual anomaly detection techniques in recent years, the interpretations of these black-box models and reasonable explanations of why anomalies can be distinguished out are scarce. This paper provides the first survey concentrated on explainable visual anomaly detection methods. We first introduce the basic background of image-level anomaly detection and video-level anomaly detection, followed by the current explainable approaches for visual anomaly detection. Then, as the main content of this survey, a comprehensive and exhaustive literature review of explainable anomaly detection methods for both images and videos is presented. Finally, we discuss several promising future directions and open problems to explore on the explainability of visual anomaly detection.
Chaotic Variational Auto encoder-based Adversarial Machine Learning
Feb 25, 2023
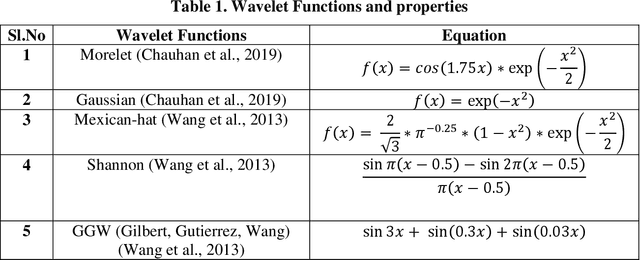
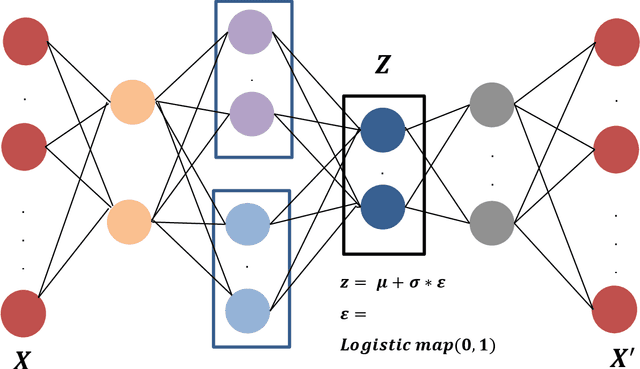
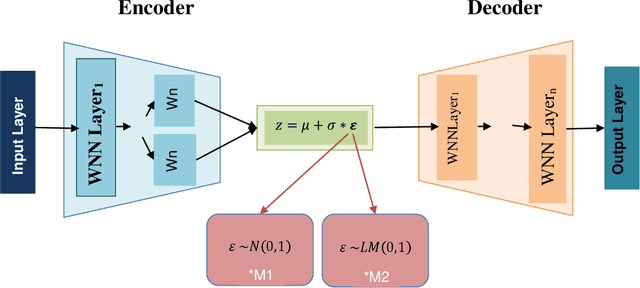
Machine Learning (ML) has become the new contrivance in almost every field. This makes them a target of fraudsters by various adversary attacks, thereby hindering the performance of ML models. Evasion and Data-Poison-based attacks are well acclaimed, especially in finance, healthcare, etc. This motivated us to propose a novel computationally less expensive attack mechanism based on the adversarial sample generation by Variational Auto Encoder (VAE). It is well known that Wavelet Neural Network (WNN) is considered computationally efficient in solving image and audio processing, speech recognition, and time-series forecasting. This paper proposed VAE-Deep-Wavelet Neural Network (VAE-Deep-WNN), where Encoder and Decoder employ WNN networks. Further, we proposed chaotic variants of both VAE with Multi-layer perceptron (MLP) and Deep-WNN and named them C-VAE-MLP and C-VAE-Deep-WNN, respectively. Here, we employed a Logistic map to generate random noise in the latent space. In this paper, we performed VAE-based adversary sample generation and applied it to various problems related to finance and cybersecurity domain-related problems such as loan default, credit card fraud, and churn modelling, etc., We performed both Evasion and Data-Poison attacks on Logistic Regression (LR) and Decision Tree (DT) models. The results indicated that VAE-Deep-WNN outperformed the rest in the majority of the datasets and models. However, its chaotic variant C-VAE-Deep-WNN performed almost similarly to VAE-Deep-WNN in the majority of the datasets.
Self-similarity Driven Scale-invariant Learning for Weakly Supervised Person Search
Feb 25, 2023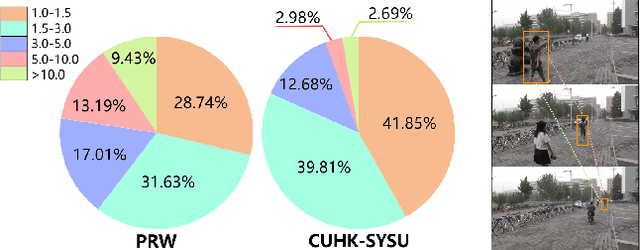
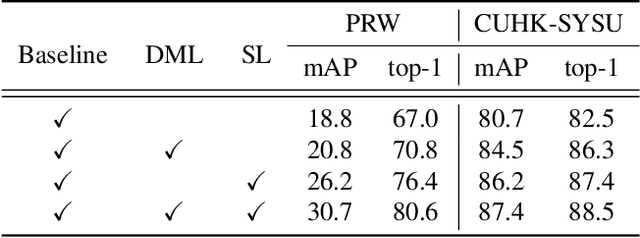
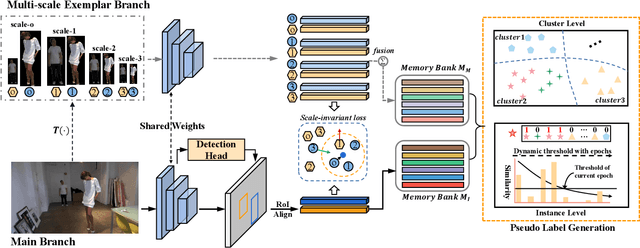
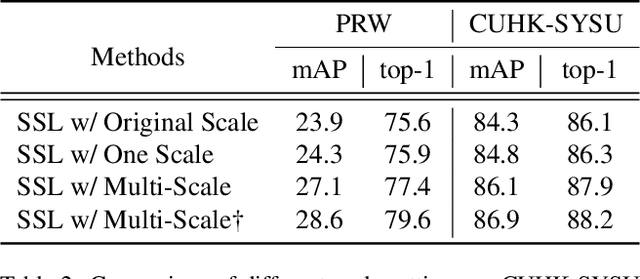
Weakly supervised person search aims to jointly detect and match persons with only bounding box annotations. Existing approaches typically focus on improving the features by exploring relations of persons. However, scale variation problem is a more severe obstacle and under-studied that a person often owns images with different scales (resolutions). On the one hand, small-scale images contain less information of a person, thus affecting the accuracy of the generated pseudo labels. On the other hand, the similarity of cross-scale images is often smaller than that of images with the same scale for a person, which will increase the difficulty of matching. In this paper, we address this problem by proposing a novel one-step framework, named Self-similarity driven Scale-invariant Learning (SSL). Scale invariance can be explored based on the self-similarity prior that it shows the same statistical properties of an image at different scales. To this end, we introduce a Multi-scale Exemplar Branch to guide the network in concentrating on the foreground and learning scale-invariant features by hard exemplars mining. To enhance the discriminative power of the features in an unsupervised manner, we introduce a dynamic multi-label prediction which progressively seeks true labels for training. It is adaptable to different types of unlabeled data and serves as a compensation for clustering based strategy. Experiments on PRW and CUHK-SYSU databases demonstrate the effectiveness of our method.
SPARC: Sparse Render-and-Compare for CAD model alignment in a single RGB image
Oct 03, 2022

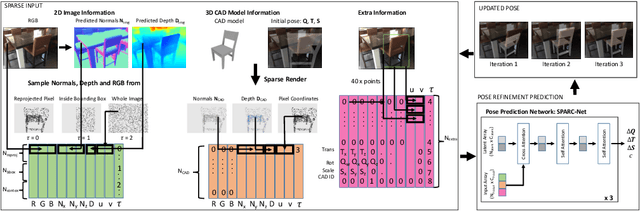
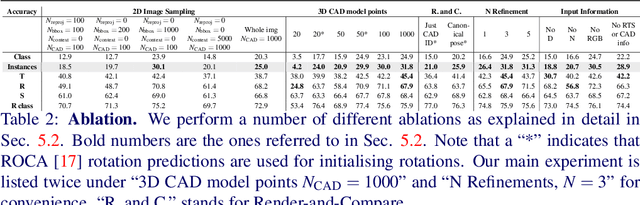
Estimating 3D shapes and poses of static objects from a single image has important applications for robotics, augmented reality and digital content creation. Often this is done through direct mesh predictions which produces unrealistic, overly tessellated shapes or by formulating shape prediction as a retrieval task followed by CAD model alignment. Directly predicting CAD model poses from 2D image features is difficult and inaccurate. Some works, such as ROCA, regress normalised object coordinates and use those for computing poses. While this can produce more accurate pose estimates, predicting normalised object coordinates is susceptible to systematic failure. Leveraging efficient transformer architectures we demonstrate that a sparse, iterative, render-and-compare approach is more accurate and robust than relying on normalised object coordinates. For this we combine 2D image information including sparse depth and surface normal values which we estimate directly from the image with 3D CAD model information in early fusion. In particular, we reproject points sampled from the CAD model in an initial, random pose and compute their depth and surface normal values. This combined information is the input to a pose prediction network, SPARC-Net which we train to predict a 9 DoF CAD model pose update. The CAD model is reprojected again and the next pose update is predicted. Our alignment procedure converges after just 3 iterations, improving the state-of-the-art performance on the challenging real-world dataset ScanNet from 25.0% to 31.8% instance alignment accuracy. Code will be released at https://github.com/florianlanger/SPARC .
Zero-shot-Learning Cross-Modality Data Translation Through Mutual Information Guided Stochastic Diffusion
Jan 31, 2023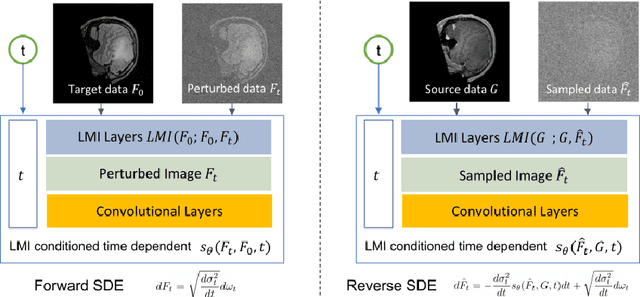
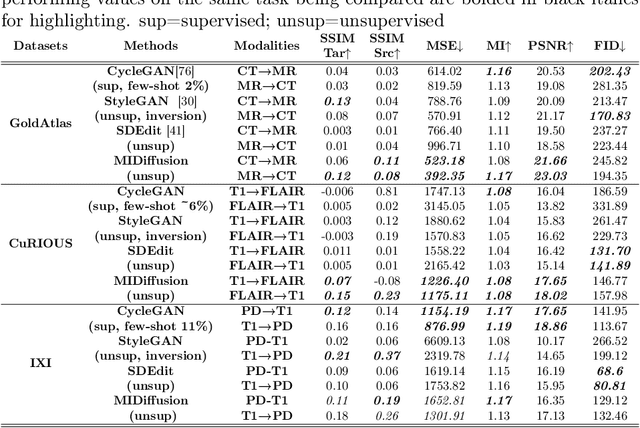
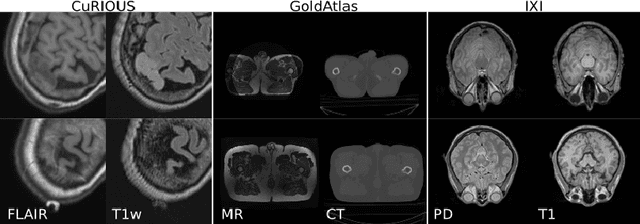

Cross-modality data translation has attracted great interest in image computing. Deep generative models (\textit{e.g.}, GANs) show performance improvement in tackling those problems. Nevertheless, as a fundamental challenge in image translation, the problem of Zero-shot-Learning Cross-Modality Data Translation with fidelity remains unanswered. This paper proposes a new unsupervised zero-shot-learning method named Mutual Information guided Diffusion cross-modality data translation Model (MIDiffusion), which learns to translate the unseen source data to the target domain. The MIDiffusion leverages a score-matching-based generative model, which learns the prior knowledge in the target domain. We propose a differentiable local-wise-MI-Layer ($LMI$) for conditioning the iterative denoising sampling. The $LMI$ captures the identical cross-modality features in the statistical domain for the diffusion guidance; thus, our method does not require retraining when the source domain is changed, as it does not rely on any direct mapping between the source and target domains. This advantage is critical for applying cross-modality data translation methods in practice, as a reasonable amount of source domain dataset is not always available for supervised training. We empirically show the advanced performance of MIDiffusion in comparison with an influential group of generative models, including adversarial-based and other score-matching-based models.
Mind the (optimality) Gap: A Gap-Aware Learning Rate Scheduler for Adversarial Nets
Jan 31, 2023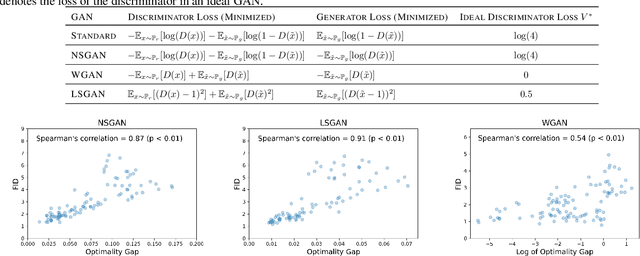
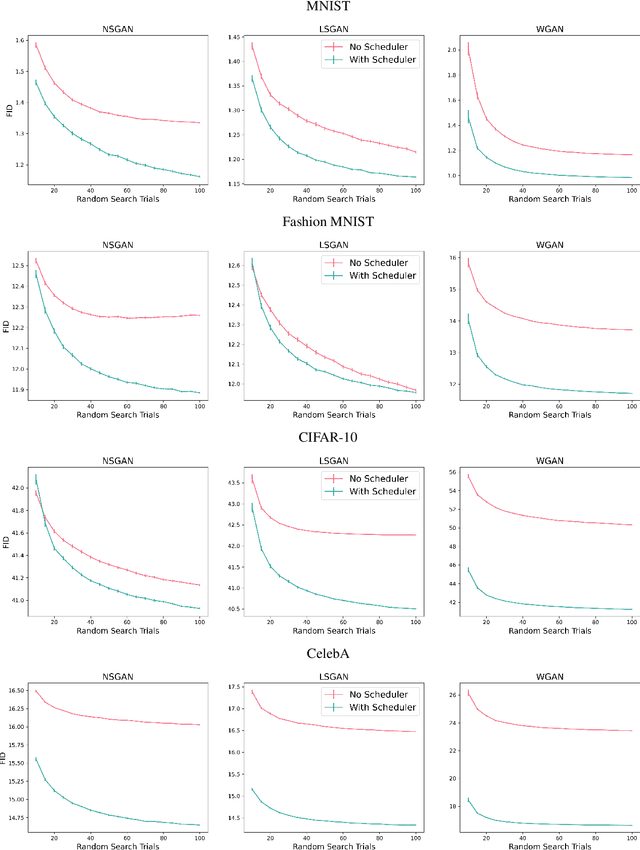

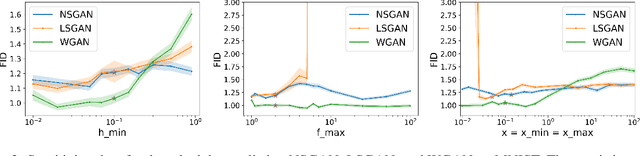
Adversarial nets have proved to be powerful in various domains including generative modeling (GANs), transfer learning, and fairness. However, successfully training adversarial nets using first-order methods remains a major challenge. Typically, careful choices of the learning rates are needed to maintain the delicate balance between the competing networks. In this paper, we design a novel learning rate scheduler that dynamically adapts the learning rate of the adversary to maintain the right balance. The scheduler is driven by the fact that the loss of an ideal adversarial net is a constant known a priori. The scheduler is thus designed to keep the loss of the optimized adversarial net close to that of an ideal network. We run large-scale experiments to study the effectiveness of the scheduler on two popular applications: GANs for image generation and adversarial nets for domain adaptation. Our experiments indicate that adversarial nets trained with the scheduler are less likely to diverge and require significantly less tuning. For example, on CelebA, a GAN with the scheduler requires only one-tenth of the tuning budget needed without a scheduler. Moreover, the scheduler leads to statistically significant improvements in model quality, reaching up to $27\%$ in Frechet Inception Distance for image generation and $3\%$ in test accuracy for domain adaptation.
GraVIS: Grouping Augmented Views from Independent Sources for Dermatology Analysis
Jan 11, 2023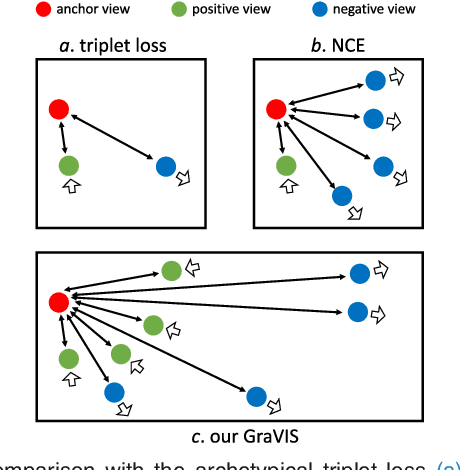
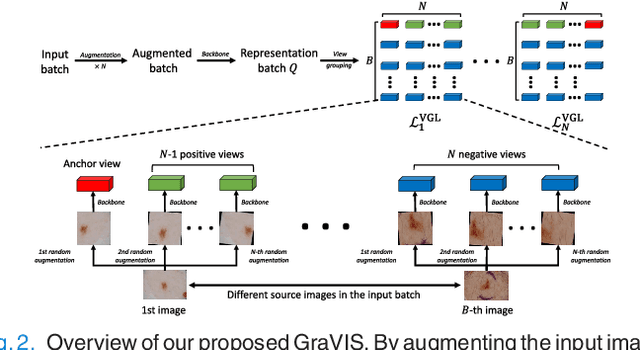
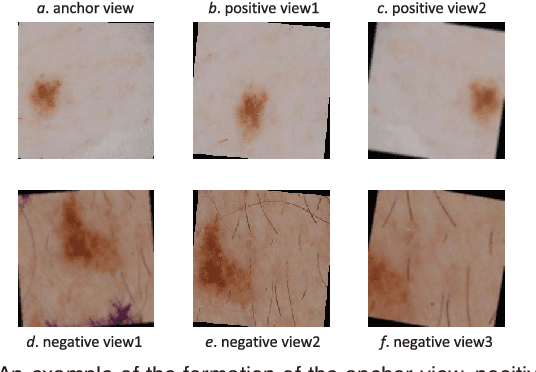
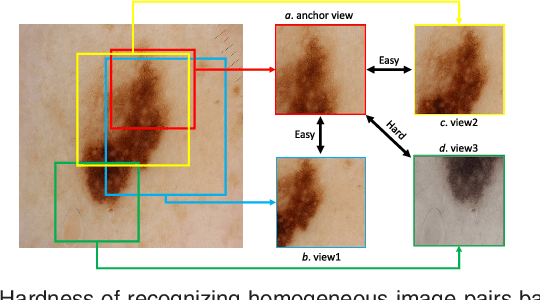
Self-supervised representation learning has been extremely successful in medical image analysis, as it requires no human annotations to provide transferable representations for downstream tasks. Recent self-supervised learning methods are dominated by noise-contrastive estimation (NCE, also known as contrastive learning), which aims to learn invariant visual representations by contrasting one homogeneous image pair with a large number of heterogeneous image pairs in each training step. Nonetheless, NCE-based approaches still suffer from one major problem that is one homogeneous pair is not enough to extract robust and invariant semantic information. Inspired by the archetypical triplet loss, we propose GraVIS, which is specifically optimized for learning self-supervised features from dermatology images, to group homogeneous dermatology images while separating heterogeneous ones. In addition, a hardness-aware attention is introduced and incorporated to address the importance of homogeneous image views with similar appearance instead of those dissimilar homogeneous ones. GraVIS significantly outperforms its transfer learning and self-supervised learning counterparts in both lesion segmentation and disease classification tasks, sometimes by 5 percents under extremely limited supervision. More importantly, when equipped with the pre-trained weights provided by GraVIS, a single model could achieve better results than winners that heavily rely on ensemble strategies in the well-known ISIC 2017 challenge.
ZScribbleSeg: Zen and the Art of Scribble Supervised Medical Image Segmentation
Jan 12, 2023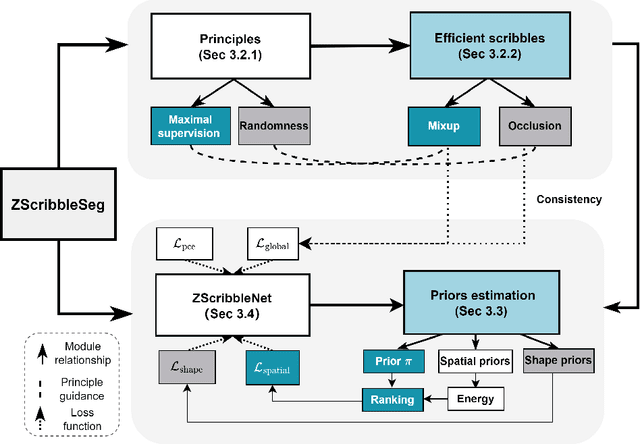

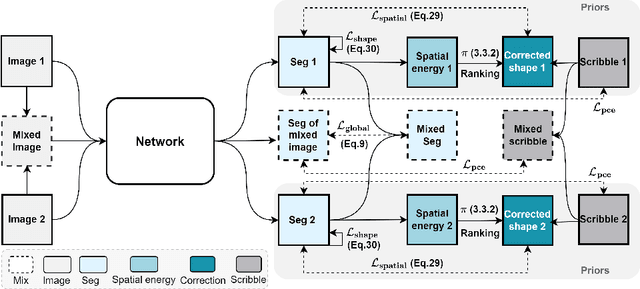
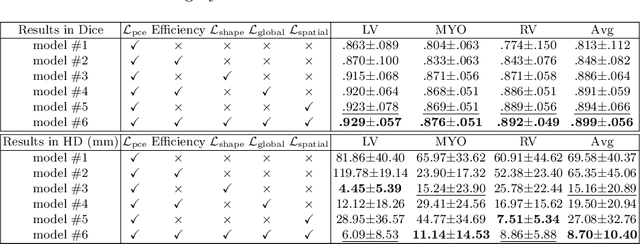
Curating a large scale fully-annotated dataset can be both labour-intensive and expertise-demanding, especially for medical images. To alleviate this problem, we propose to utilize solely scribble annotations for weakly supervised segmentation. Existing solutions mainly leverage selective losses computed solely on annotated areas and generate pseudo gold standard segmentation by propagating labels to adjacent areas. However, these methods could suffer from the inaccurate and sometimes unrealistic pseudo segmentation due to the insufficient supervision and incomplete shape features. Different from previous efforts, we first investigate the principle of ''good scribble annotations'', which leads to efficient scribble forms via supervision maximization and randomness simulation. Furthermore, we introduce regularization terms to encode the spatial relationship and shape prior, where a new formulation is developed to estimate the mixture ratios of label classes. These ratios are critical in identifying the unlabeled pixels for each class and correcting erroneous predictions, thus the accurate estimation lays the foundation for the incorporation of spatial prior. Finally, we integrate the efficient scribble supervision with the prior into a unified framework, denoted as ZScribbleSeg, and apply the method to multiple scenarios. Leveraging only scribble annotations, ZScribbleSeg set new state-of-the-arts on four segmentation tasks using ACDC, MSCMRseg, MyoPS and PPSS datasets.