 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SETGen: Scalable and Efficient Template Generation Framework for Groupwise Medical Image Registration
Nov 10, 2022
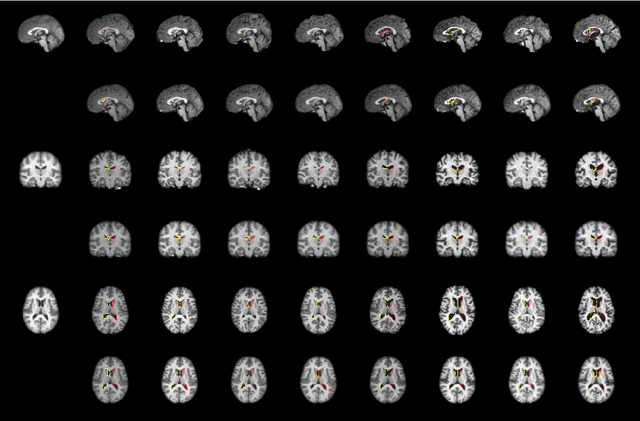
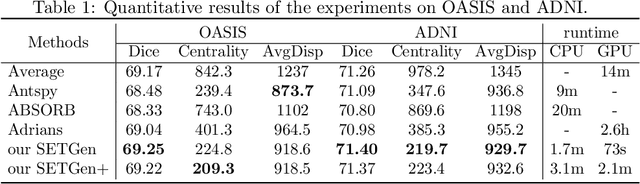
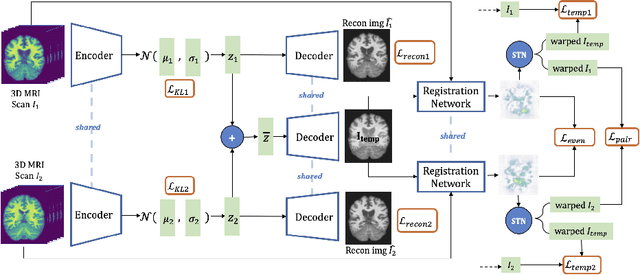
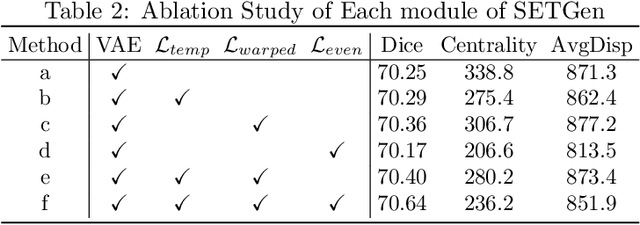
Template generation is a crucial step of groupwise image registration which deforms a group of subjects into a common space. Existing traditional and deep learning-based methods can generate high-quality template images. However, they suffer from substantial time costs or limited application scenarios like fixed group size. In this paper, we propose an efficient groupwise template generative framework based on variational autoencoder models utilizing the arithmetic property of latent representation of input images. We acquire the latent vectors of each input and use the average vector to construct the template through the decoder. Therefore, the method can be applied to groups of any scale. Secondly, we explore a siamese training scheme that feeds two images to the shared-weight twin networks and compares the distances between inputs and the generated template to prompt the template to be close to the implicit center. We conduct experiments on 3D brain MRI scans of groups of different sizes. Results show that our framework can achieve comparable and even better performance to baselines, with runtime decreased to seconds.
HALSIE - Hybrid Approach to Learning Segmentation by Simultaneously Exploiting Image and Event Modalities
Nov 22, 2022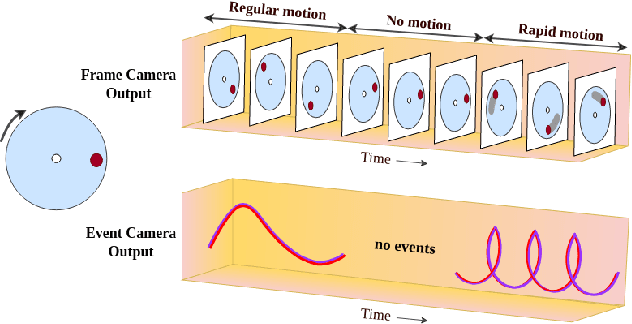
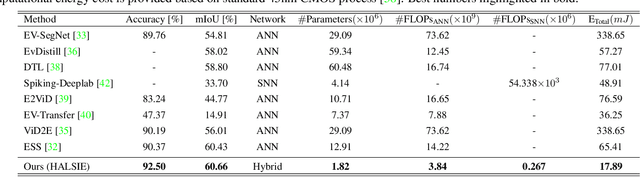


Standard frame-based algorithms fail to retrieve accurate segmentation maps in challenging real-time applications like autonomous navigation, owing to the limited dynamic range and motion blur prevalent in traditional cameras. Event cameras address these limitations by asynchronously detecting changes in per-pixel intensity to generate event streams with high temporal resolution, high dynamic range, and no motion blur. However, event camera outputs cannot be directly used to generate reliable segmentation maps as they only capture information at the pixels in motion. To augment the missing contextual information, we postulate that fusing spatially dense frames with temporally dense events can generate semantic maps with fine-grained predictions. To this end, we propose HALSIE, a hybrid approach to learning segmentation by simultaneously leveraging image and event modalities. To enable efficient learning across modalities, our proposed hybrid framework comprises two input branches, a Spiking Neural Network (SNN) branch and a standard Artificial Neural Network (ANN) branch to process event and frame data respectively, while exploiting their corresponding neural dynamics. Our hybrid network outperforms the state-of-the-art semantic segmentation benchmarks on DDD17 and MVSEC datasets and shows comparable performance on the DSEC-Semantic dataset with upto 33.23$\times$ reduction in network parameters. Further, our method shows upto 18.92$\times$ improvement in inference cost compared to existing SOTA approaches, making it suitable for resource-constrained edge applications.
OliVaR: Improving Olive Variety Recognition using Deep Neural Networks
Mar 01, 2023

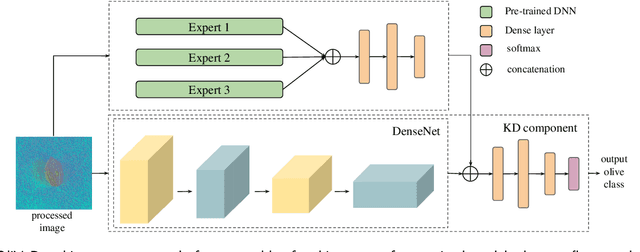

The easy and accurate identification of varieties is fundamental in agriculture, especially in the olive sector, where more than 1200 olive varieties are currently known worldwide. Varietal misidentification leads to many potential problems for all the actors in the sector: farmers and nursery workers may establish the wrong variety, leading to its maladaptation in the field; olive oil and table olive producers may label and sell a non-authentic product; consumers may be misled; and breeders may commit errors during targeted crossings between different varieties. To date, the standard for varietal identification and certification consists of two methods: morphological classification and genetic analysis. The morphological classification consists of the visual pairwise comparison of different organs of the olive tree, where the most important organ is considered to be the endocarp. In contrast, different methods for genetic classification exist (RAPDs, SSR, and SNP). Both classification methods present advantages and disadvantages. Visual morphological classification requires highly specialized personnel and is prone to human error. Genetic identification methods are more accurate but incur a high cost and are difficult to implement. This paper introduces OliVaR, a novel approach to olive varietal identification. OliVaR uses a teacher-student deep learning architecture to learn the defining characteristics of the endocarp of each specific olive variety and perform classification. We construct what is, to the best of our knowledge, the largest olive variety dataset to date, comprising image data for 131 varieties from the Mediterranean basin. We thoroughly test OliVaR on this dataset and show that it correctly predicts olive varieties with over 86% accuracy.
Neural inverse procedural modeling of knitting yarns from images
Mar 01, 2023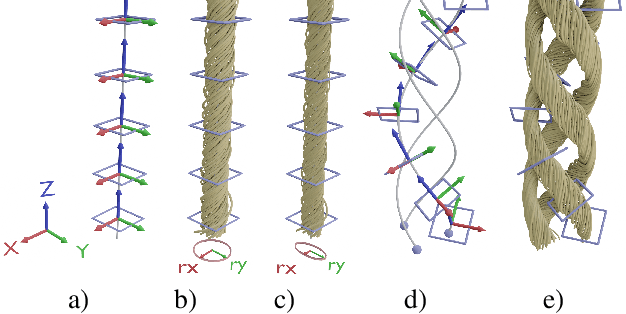
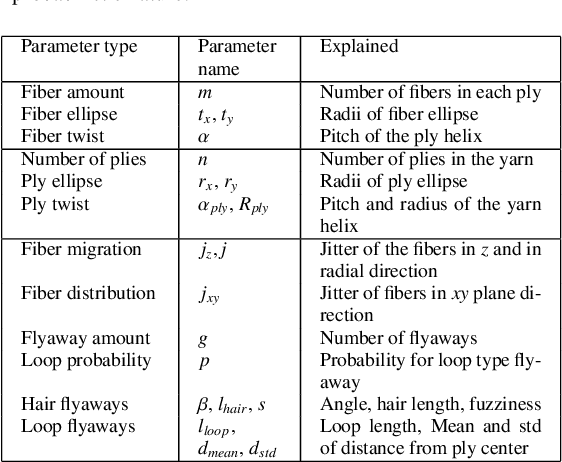

We investigate the capabilities of neural inverse procedural modeling to infer high-quality procedural yarn models with fiber-level details from single images of depicted yarn samples. While directly inferring all parameters of the underlying yarn model based on a single neural network may seem an intuitive choice, we show that the complexity of yarn structures in terms of twisting and migration characteristics of the involved fibers can be better encountered in terms of ensembles of networks that focus on individual characteristics. We analyze the effect of different loss functions including a parameter loss to penalize the deviation of inferred parameters to ground truth annotations, a reconstruction loss to enforce similar statistics of the image generated for the estimated parameters in comparison to training images as well as an additional regularization term to explicitly penalize deviations between latent codes of synthetic images and the average latent code of real images in the latent space of the encoder. We demonstrate that the combination of a carefully designed parametric, procedural yarn model with respective network ensembles as well as loss functions even allows robust parameter inference when solely trained on synthetic data. Since our approach relies on the availability of a yarn database with parameter annotations and we are not aware of such a respectively available dataset, we additionally provide, to the best of our knowledge, the first dataset of yarn images with annotations regarding the respective yarn parameters. For this purpose, we use a novel yarn generator that improves the realism of the produced results over previous approaches.
A Novel Collaborative Self-Supervised Learning Method for Radiomic Data
Feb 20, 2023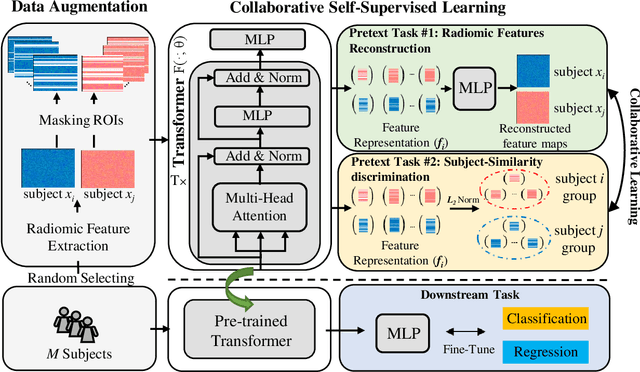
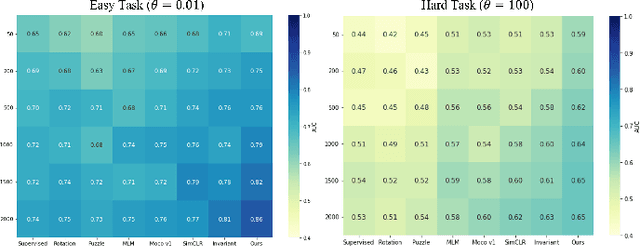
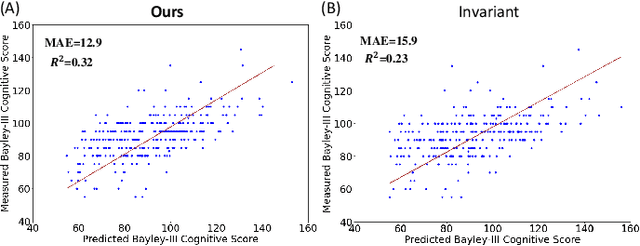
The computer-aided disease diagnosis from radiomic data is important in many medical applications. However, developing such a technique relies on annotating radiological images, which is a time-consuming, labor-intensive, and expensive process. In this work, we present the first novel collaborative self-supervised learning method to solve the challenge of insufficient labeled radiomic data, whose characteristics are different from text and image data. To achieve this, we present two collaborative pretext tasks that explore the latent pathological or biological relationships between regions of interest and the similarity and dissimilarity information between subjects. Our method collaboratively learns the robust latent feature representations from radiomic data in a self-supervised manner to reduce human annotation efforts, which benefits the disease diagnosis. We compared our proposed method with other state-of-the-art self-supervised learning methods on a simulation study and two independent datasets. Extensive experimental results demonstrated that our method outperforms other self-supervised learning methods on both classification and regression tasks. With further refinement, our method shows the potential advantage in automatic disease diagnosis with large-scale unlabeled data available.
Towards Simultaneous Segmentation of Liver Tumors and Intrahepatic Vessels via Cross-attention Mechanism
Feb 20, 2023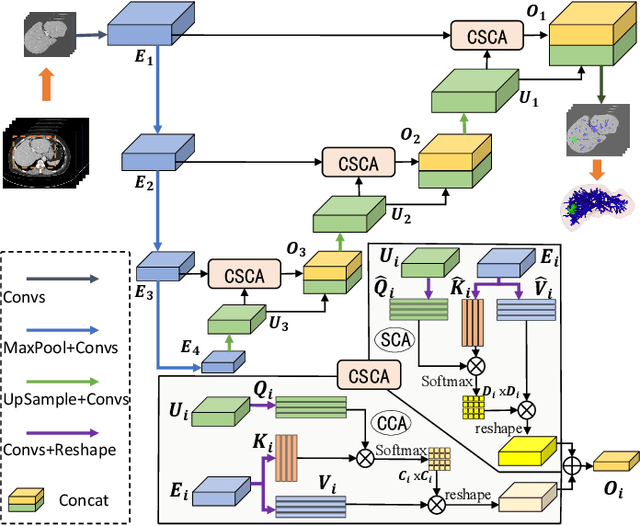

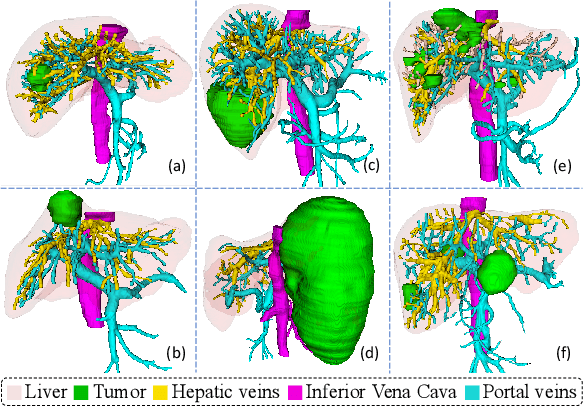
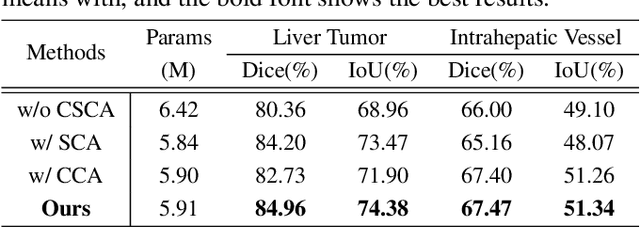
Accurate visualization of liver tumors and their surrounding blood vessels is essential for noninvasive diagnosis and prognosis prediction of tumors. In medical image segmentation, there is still a lack of in-depth research on the simultaneous segmentation of liver tumors and peritumoral blood vessels. To this end, we collect the first liver tumor, and vessel segmentation benchmark datasets containing 52 portal vein phase computed tomography images with liver, liver tumor, and vessel annotations. In this case, we propose a 3D U-shaped Cross-Attention Network (UCA-Net) that utilizes a tailored cross-attention mechanism instead of the traditional skip connection to effectively model the encoder and decoder feature. Specifically, the UCA-Net uses a channel-wise cross-attention module to reduce the semantic gap between encoder and decoder and a slice-wise cross-attention module to enhance the contextual semantic learning ability among distinct slices. Experimental results show that the proposed UCA-Net can accurately segment 3D medical images and achieve state-of-the-art performance on the liver tumor and intrahepatic vessel segmentation task.
Model-based feature selection for neural networks: A mixed-integer programming approach
Feb 20, 2023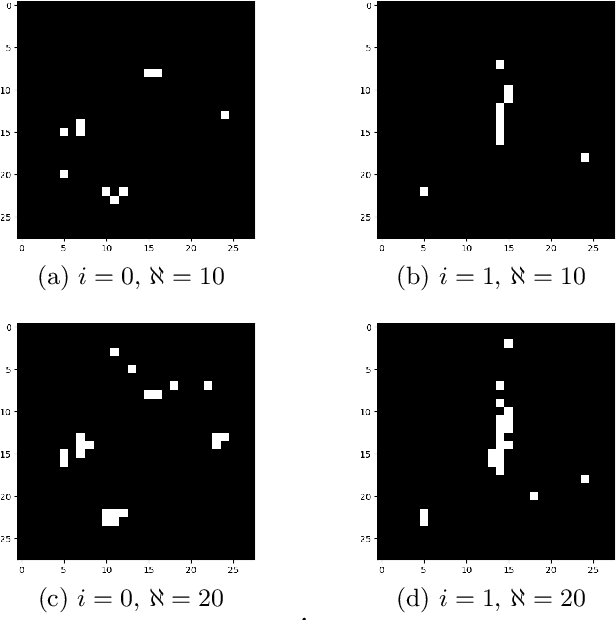
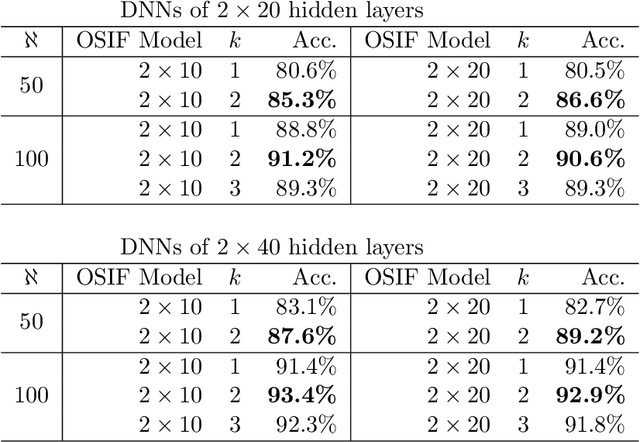
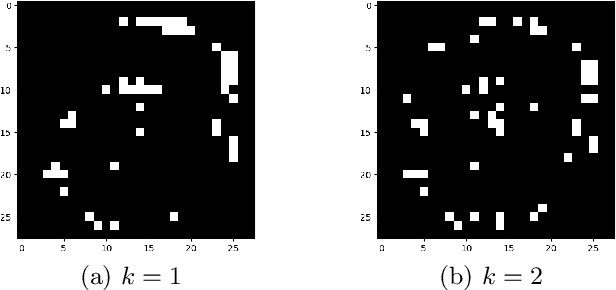
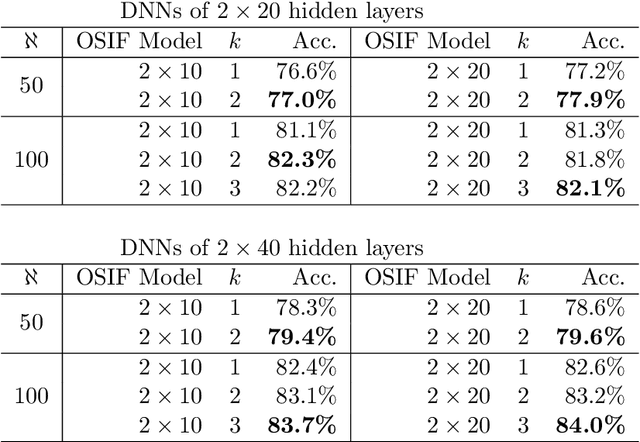
In this work, we develop a novel input feature selection framework for ReLU-based deep neural networks (DNNs), which builds upon a mixed-integer optimization approach. While the method is generally applicable to various classification tasks, we focus on finding input features for image classification for clarity of presentation. The idea is to use a trained DNN, or an ensemble of trained DNNs, to identify the salient input features. The input feature selection is formulated as a sequence of mixed-integer linear programming (MILP) problems that find sets of sparse inputs that maximize the classification confidence of each category. These ''inverse'' problems are regularized by the number of inputs selected for each category and by distribution constraints. Numerical results on the well-known MNIST and FashionMNIST datasets show that the proposed input feature selection allows us to drastically reduce the size of the input to $\sim$15\% while maintaining a good classification accuracy. This allows us to design DNNs with significantly fewer connections, reducing computational effort and producing DNNs that are more robust towards adversarial attacks.
Take Me Home: Reversing Distribution Shifts using Reinforcement Learning
Feb 24, 2023

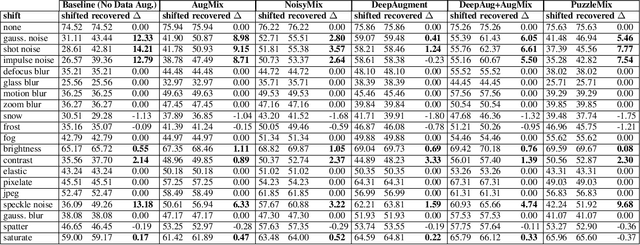
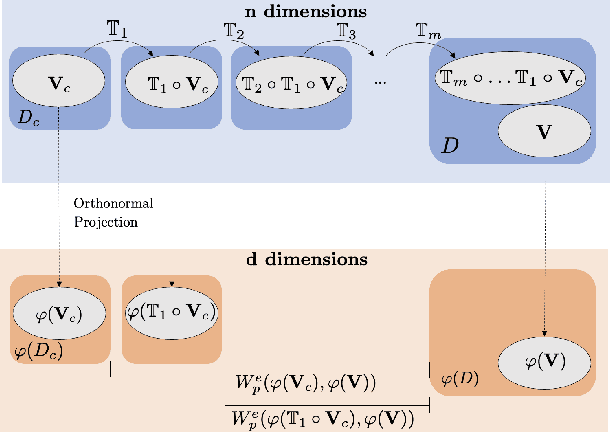
Deep neural networks have repeatedly been shown to be non-robust to the uncertainties of the real world. Even subtle adversarial attacks and naturally occurring distribution shifts wreak havoc on systems relying on deep neural networks. In response to this, current state-of-the-art techniques use data-augmentation to enrich the training distribution of the model and consequently improve robustness to natural distribution shifts. We propose an alternative approach that allows the system to recover from distribution shifts online. Specifically, our method applies a sequence of semantic-preserving transformations to bring the shifted data closer in distribution to the training set, as measured by the Wasserstein distance. We formulate the problem of sequence selection as an MDP, which we solve using reinforcement learning. To aid in our estimates of Wasserstein distance, we employ dimensionality reduction through orthonormal projection. We provide both theoretical and empirical evidence that orthonormal projection preserves characteristics of the data at the distributional level. Finally, we apply our distribution shift recovery approach to the ImageNet-C benchmark for distribution shifts, targeting shifts due to additive noise and image histogram modifications. We demonstrate an improvement in average accuracy up to 14.21% across a variety of state-of-the-art ImageNet classifiers.
Flow-based GAN for 3D Point Cloud Generation from a Single Image
Oct 08, 2022

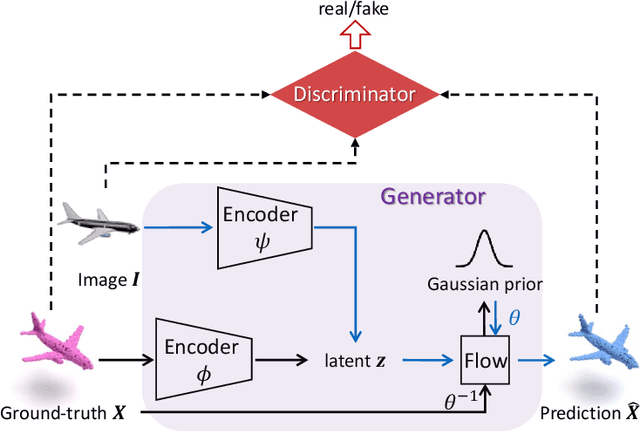
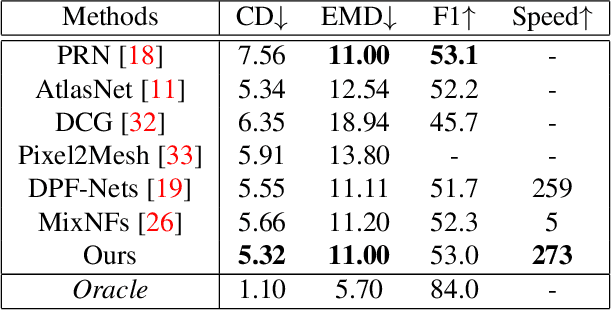
Generating a 3D point cloud from a single 2D image is of great importance for 3D scene understanding applications. To reconstruct the whole 3D shape of the object shown in the image, the existing deep learning based approaches use either explicit or implicit generative modeling of point clouds, which, however, suffer from limited quality. In this work, we aim to alleviate this issue by introducing a hybrid explicit-implicit generative modeling scheme, which inherits the flow-based explicit generative models for sampling point clouds with arbitrary resolutions while improving the detailed 3D structures of point clouds by leveraging the implicit generative adversarial networks (GANs). We evaluate on the large-scale synthetic dataset ShapeNet, with the experimental results demonstrating the superior performance of the proposed method. In addition, the generalization ability of our method is demonstrated by performing on cross-category synthetic images as well as by testing on real images from PASCAL3D+ dataset.
Benchmarks for Automated Commonsense Reasoning: A Survey
Feb 22, 2023

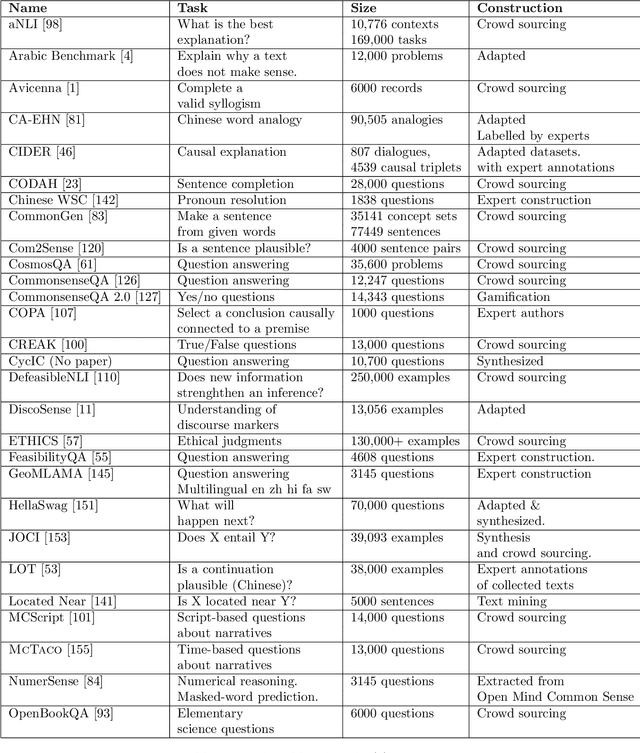

More than one hundred benchmarks have been developed to test the commonsense knowledge and commonsense reasoning abilities of artificial intelligence (AI) systems. However, these benchmarks are often flawed and many aspects of common sense remain untested. Consequently, we do not currently have any reliable way of measuring to what extent existing AI systems have achieved these abilities. This paper surveys the development and uses of AI commonsense benchmarks. We discuss the nature of common sense; the role of common sense in AI; the goals served by constructing commonsense benchmarks; and desirable features of commonsense benchmarks. We analyze the common flaws in benchmarks, and we argue that it is worthwhile to invest the work needed ensure that benchmark examples are consistently high quality. We survey the various methods of constructing commonsense benchmarks. We enumerate 139 commonsense benchmarks that have been developed: 102 text-based, 18 image-based, 12 video based, and 7 simulated physical environments. We discuss the gaps in the existing benchmarks and aspects of commonsense reasoning that are not addressed in any existing benchmark. We conclude with a number of recommendations for future development of commonsense AI benchmarks.