 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Sparse Control Tasks from Pixels by Latent Nearest-Neighbor-Guided Explorations
Feb 28, 2023



Recent progress in deep reinforcement learning (RL) and computer vision enables artificial agents to solve complex tasks, including locomotion, manipulation and video games from high-dimensional pixel observations. However, domain specific reward functions are often engineered to provide sufficient learning signals, requiring expert knowledge. While it is possible to train vision-based RL agents using only sparse rewards, additional challenges in exploration arise. We present a novel and efficient method to solve sparse-reward robot manipulation tasks from only image observations by utilizing a few demonstrations. First, we learn an embedded neural dynamics model from demonstration transitions and further fine-tune it with the replay buffer. Next, we reward the agents for staying close to the demonstrated trajectories using a distance metric defined in the embedding space. Finally, we use an off-policy, model-free vision RL algorithm to update the control policies. Our method achieves state-of-the-art sample efficiency in simulation and enables efficient training of a real Franka Emika Panda manipulator.
GradMA: A Gradient-Memory-based Accelerated Federated Learning with Alleviated Catastrophic Forgetting
Feb 28, 2023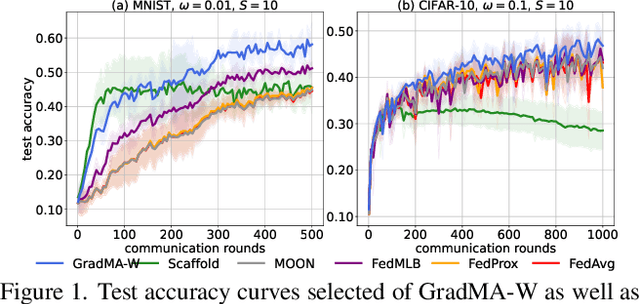
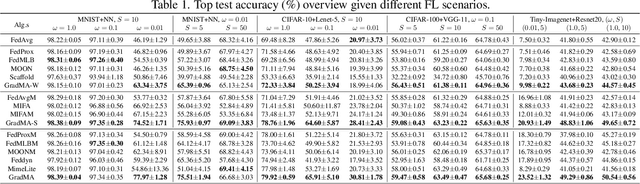
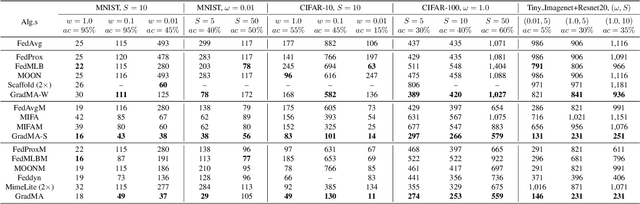
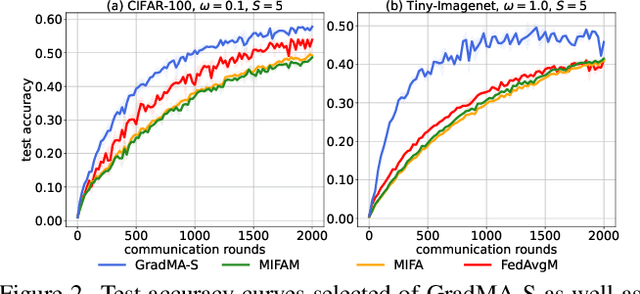
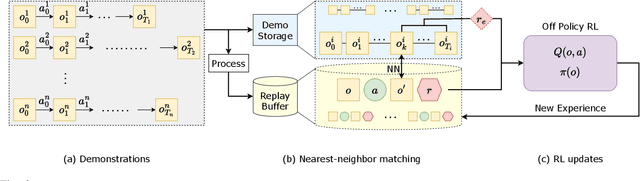
Federated Learning (FL) has emerged as a de facto machine learning area and received rapid increasing research interests from the community. However, catastrophic forgetting caused by data heterogeneity and partial participation poses distinctive challenges for FL, which are detrimental to the performance. To tackle the problems, we propose a new FL approach (namely GradMA), which takes inspiration from continual learning to simultaneously correct the server-side and worker-side update directions as well as take full advantage of server's rich computing and memory resources. Furthermore, we elaborate a memory reduction strategy to enable GradMA to accommodate FL with a large scale of workers. We then analyze convergence of GradMA theoretically under the smooth non-convex setting and show that its convergence rate achieves a linear speed up w.r.t the increasing number of sampled active workers. At last, our extensive experiments on various image classification tasks show that GradMA achieves significant performance gains in accuracy and communication efficiency compared to SOTA baselines.
QP Chaser: Polynomial Trajectory Generation for Autonomous Aerial Tracking
Feb 28, 2023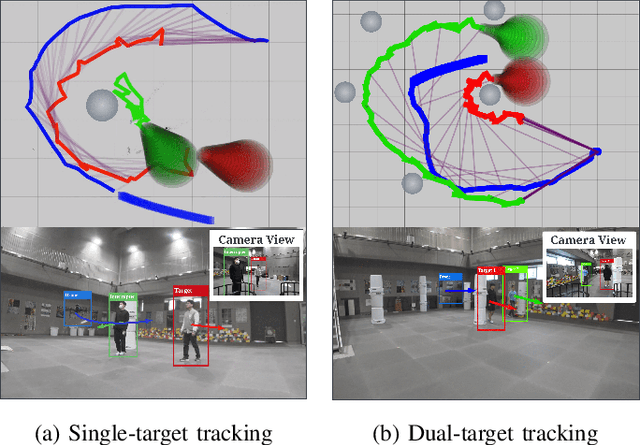
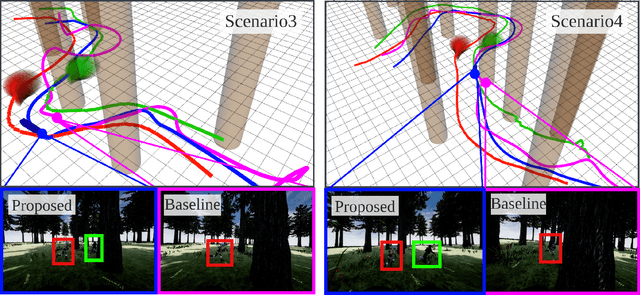
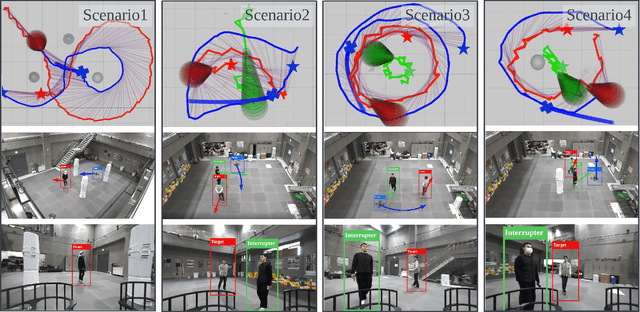

Maintaining the visibility of the targets is one of the major objectives of aerial tracking applications. This paper proposes QP Chaser, a trajectory planning pipeline that can enhance the visibility of single- and dual-target in both static and dynamic environments. As the name suggests, the proposed planner generates a target-visible trajectory via quadratic programming problems. First, the predictor forecasts the reachable sets of moving objects with a sample-and-check strategy considering obstacles. Subsequently, the trajectory planner reinforces the visibility of targets with consideration of 1) path topology and 2) reachable sets of targets and obstacles. We define a target-visible region (TVR) with topology analysis of not only static obstacles but also dynamic obstacles, and it reflects reachable sets of moving targets and obstacles to maintain the whole body of the target within the camera image robustly and ceaselessly. The online performance of the proposed planner is validated in multiple scenarios, including high-fidelity simulations and real-world experiments.
Learnt Deep Hyperparameter selection in Adversarial Training for compressed video enhancement with perceptual critic
Feb 28, 2023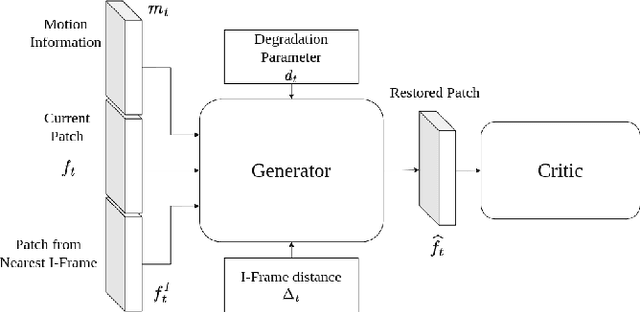
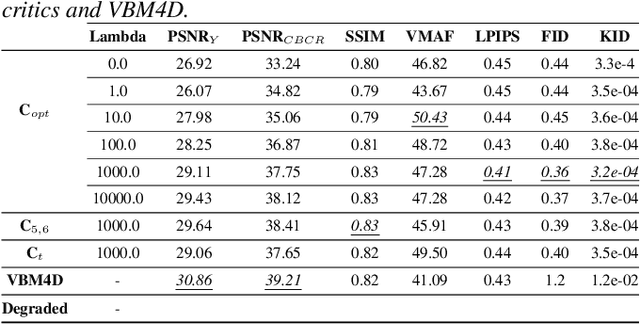
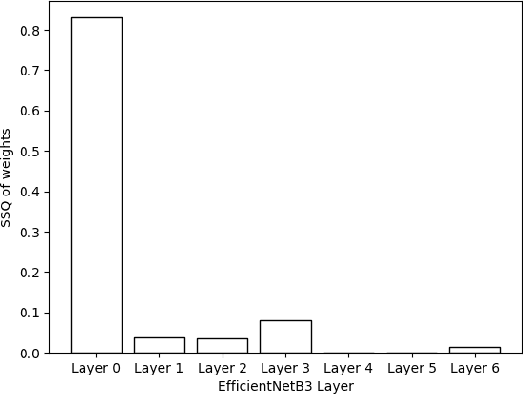
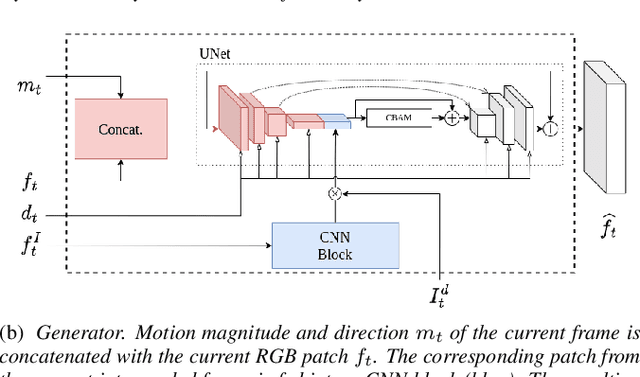
Image based Deep Feature Quality Metrics (DFQMs) have been shown to better correlate with subjective perceptual scores over traditional metrics. The fundamental focus of these DFQMs is to exploit internal representations from a large scale classification network as the metric feature space. Previously, no attention has been given to the problem of identifying which layers are most perceptually relevant. In this paper we present a new method for selecting perceptually relevant layers from such a network, based on a neuroscience interpretation of layer behaviour. The selected layers are treated as a hyperparameter to the critic network in a W-GAN. The critic uses the output from these layers in the preliminary stages to extract perceptual information. A video enhancement network is trained adversarially with this critic. Our results show that the introduction of these selected features into the critic yields up to 10% (FID) and 15% (KID) performance increase against other critic networks that do not exploit the idea of optimised feature selection.
Interpretable and Intervenable Ultrasonography-based Machine Learning Models for Pediatric Appendicitis
Feb 28, 2023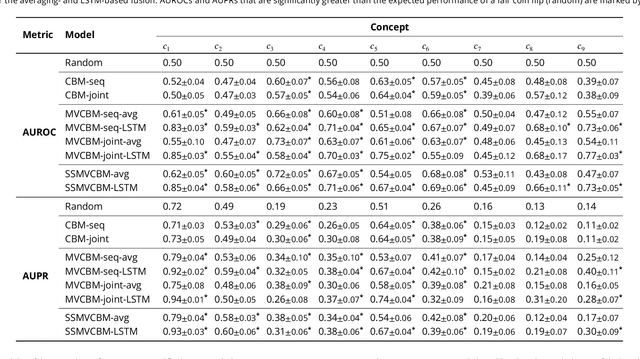
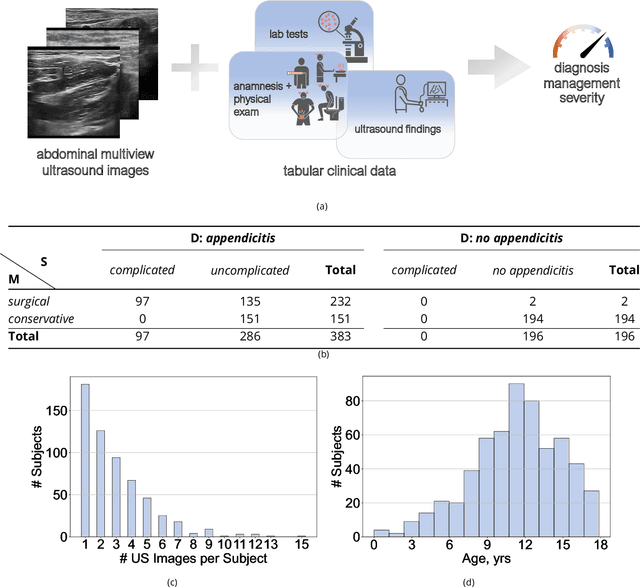
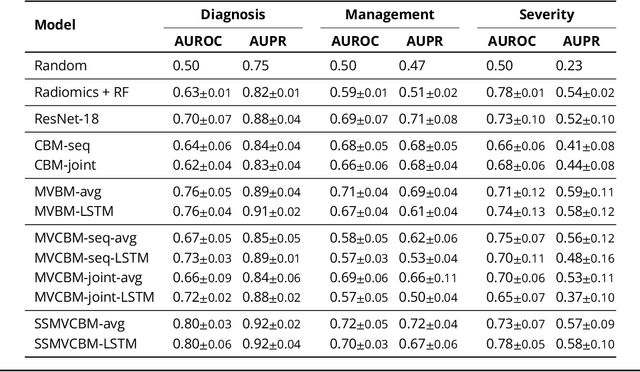
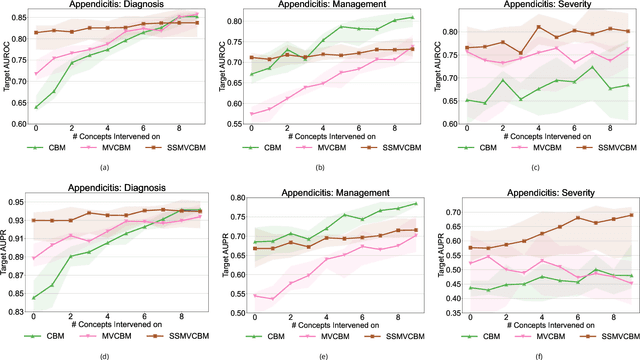
Appendicitis is among the most frequent reasons for pediatric abdominal surgeries. With recent advances in machine learning, data-driven decision support could help clinicians diagnose and manage patients while reducing the number of non-critical surgeries. Previous decision support systems for appendicitis focused on clinical, laboratory, scoring and computed tomography data, mainly ignoring abdominal ultrasound, a noninvasive and readily available diagnostic modality. To this end, we developed and validated interpretable machine learning models for predicting the diagnosis, management and severity of suspected appendicitis using ultrasound images. Our models were trained on a dataset comprising 579 pediatric patients with 1709 ultrasound images accompanied by clinical and laboratory data. Our methodological contribution is the generalization of concept bottleneck models to prediction problems with multiple views and incomplete concept sets. Notably, such models lend themselves to interpretation and interaction via high-level concepts understandable to clinicians without sacrificing performance or requiring time-consuming image annotation when deployed.
High-Fidelity Image Inpainting with GAN Inversion
Aug 25, 2022
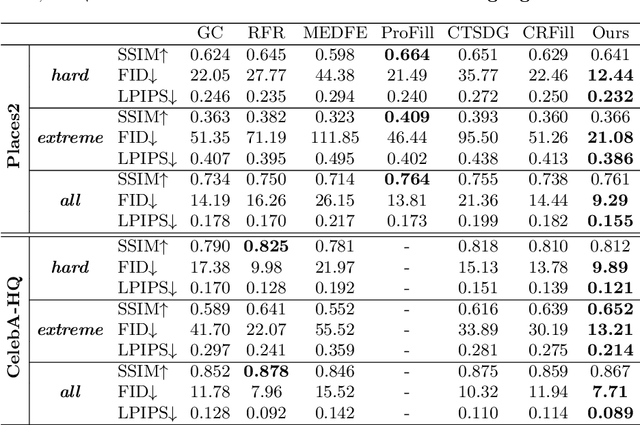
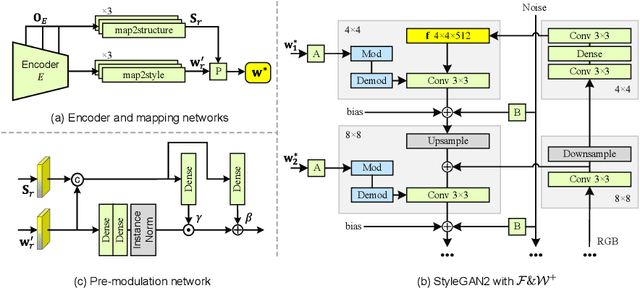
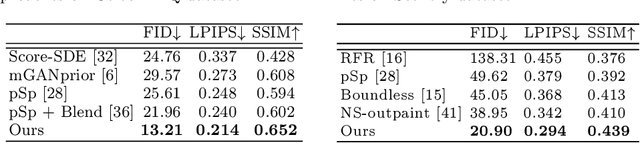
Image inpainting seeks a semantically consistent way to recover the corrupted image in the light of its unmasked content. Previous approaches usually reuse the well-trained GAN as effective prior to generate realistic patches for missing holes with GAN inversion. Nevertheless, the ignorance of a hard constraint in these algorithms may yield the gap between GAN inversion and image inpainting. Addressing this problem, in this paper, we devise a novel GAN inversion model for image inpainting, dubbed InvertFill, mainly consisting of an encoder with a pre-modulation module and a GAN generator with F&W+ latent space. Within the encoder, the pre-modulation network leverages multi-scale structures to encode more discriminative semantics into style vectors. In order to bridge the gap between GAN inversion and image inpainting, F&W+ latent space is proposed to eliminate glaring color discrepancy and semantic inconsistency. To reconstruct faithful and photorealistic images, a simple yet effective Soft-update Mean Latent module is designed to capture more diverse in-domain patterns that synthesize high-fidelity textures for large corruptions. Comprehensive experiments on four challenging datasets, including Places2, CelebA-HQ, MetFaces, and Scenery, demonstrate that our InvertFill outperforms the advanced approaches qualitatively and quantitatively and supports the completion of out-of-domain images well.
EvHandPose: Event-based 3D Hand Pose Estimation with Sparse Supervision
Mar 06, 2023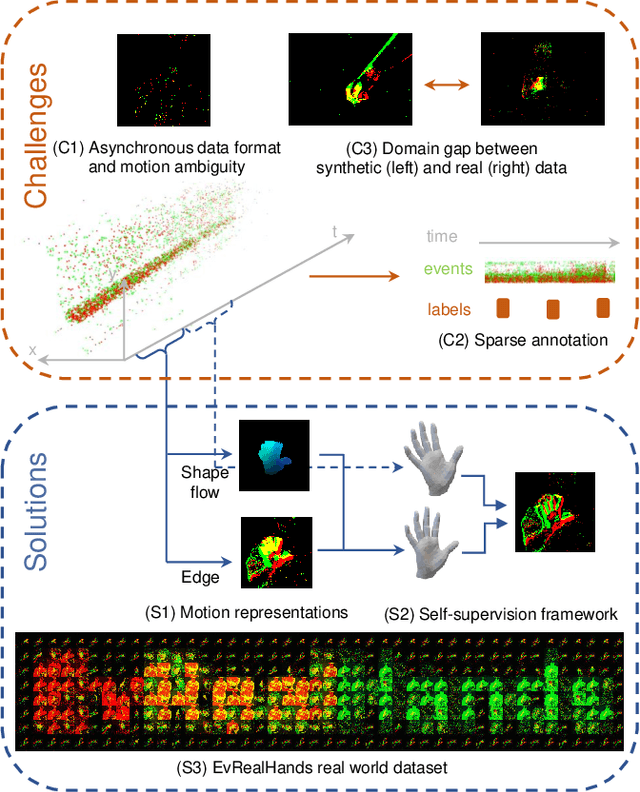

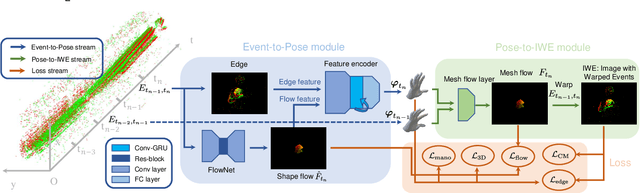

Event camera shows great potential in 3D hand pose estimation, especially addressing the challenges of fast motion and high dynamic range in a low-power way. However, due to the asynchronous differential imaging mechanism, it is challenging to design event representation to encode hand motion information especially when the hands are not moving (causing motion ambiguity), and it is infeasible to fully annotate the temporally dense event stream. In this paper, we propose EvHandPose with novel hand flow representations in Event-to-Pose module for accurate hand pose estimation and alleviating the motion ambiguity issue. To solve the problem under sparse annotation, we design contrast maximization and edge constraints in Pose-to-IWE (Image with Warped Events) module and formulate EvHandPose in a self-supervision framework. We further build EvRealHands, the first large-scale real-world event-based hand pose dataset on several challenging scenes to bridge the domain gap due to relying on synthetic data and facilitate future research. Experiments on EvRealHands demonstrate that EvHandPose outperforms previous event-based method under all evaluation scenes with 15 $\sim$ 20 mm lower MPJPE and achieves accurate and stable hand pose estimation in fast motion and strong light scenes compared with RGB-based methods. Furthermore, EvHandPose demonstrates 3D hand pose estimation at 120 fps or higher.
CLIP-guided Prototype Modulating for Few-shot Action Recognition
Mar 06, 2023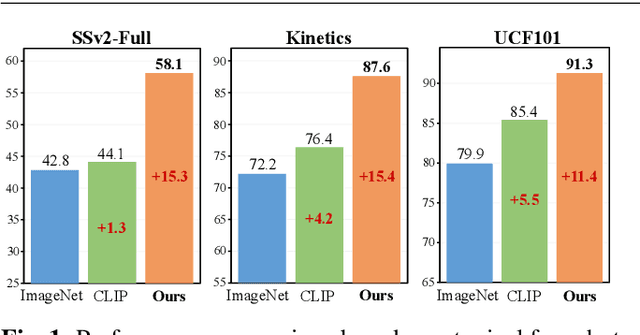
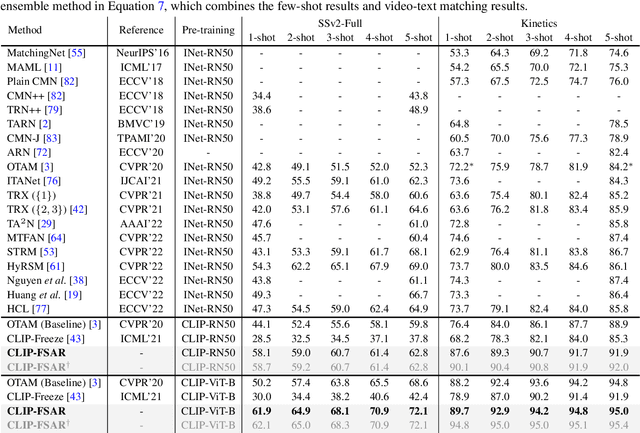
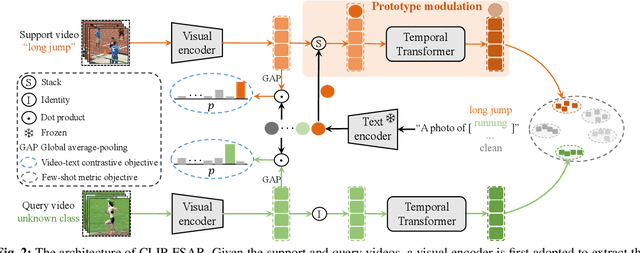
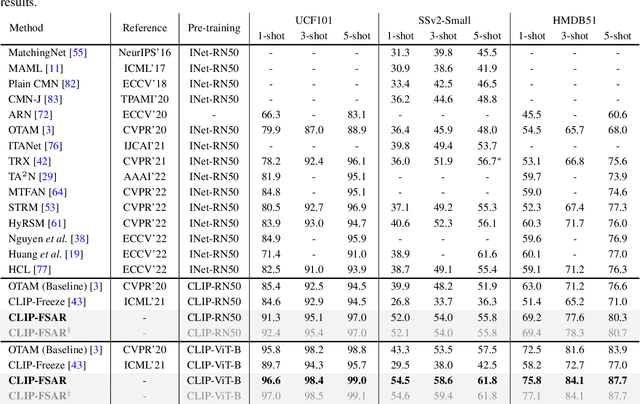
Learning from large-scale contrastive language-image pre-training like CLIP has shown remarkable success in a wide range of downstream tasks recently, but it is still under-explored on the challenging few-shot action recognition (FSAR) task. In this work, we aim to transfer the powerful multimodal knowledge of CLIP to alleviate the inaccurate prototype estimation issue due to data scarcity, which is a critical problem in low-shot regimes. To this end, we present a CLIP-guided prototype modulating framework called CLIP-FSAR, which consists of two key components: a video-text contrastive objective and a prototype modulation. Specifically, the former bridges the task discrepancy between CLIP and the few-shot video task by contrasting videos and corresponding class text descriptions. The latter leverages the transferable textual concepts from CLIP to adaptively refine visual prototypes with a temporal Transformer. By this means, CLIP-FSAR can take full advantage of the rich semantic priors in CLIP to obtain reliable prototypes and achieve accurate few-shot classification. Extensive experiments on five commonly used benchmarks demonstrate the effectiveness of our proposed method, and CLIP-FSAR significantly outperforms existing state-of-the-art methods under various settings. The source code and models will be publicly available at https://github.com/alibaba-mmai-research/CLIP-FSAR.
ST-KeyS: Self-Supervised Transformer for Keyword Spotting in Historical Handwritten Documents
Mar 06, 2023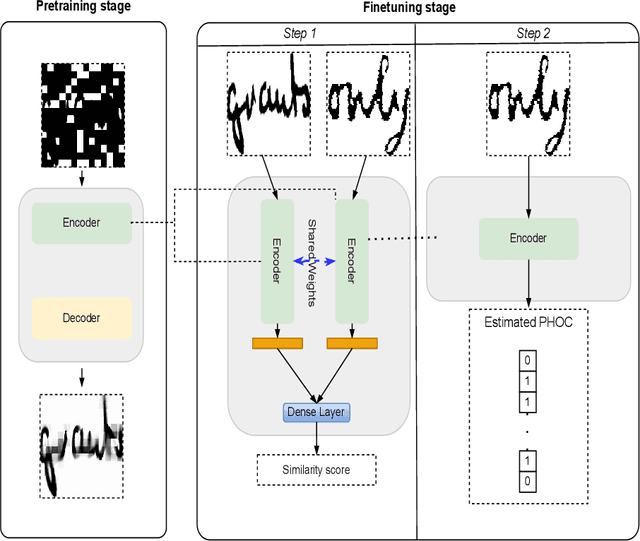

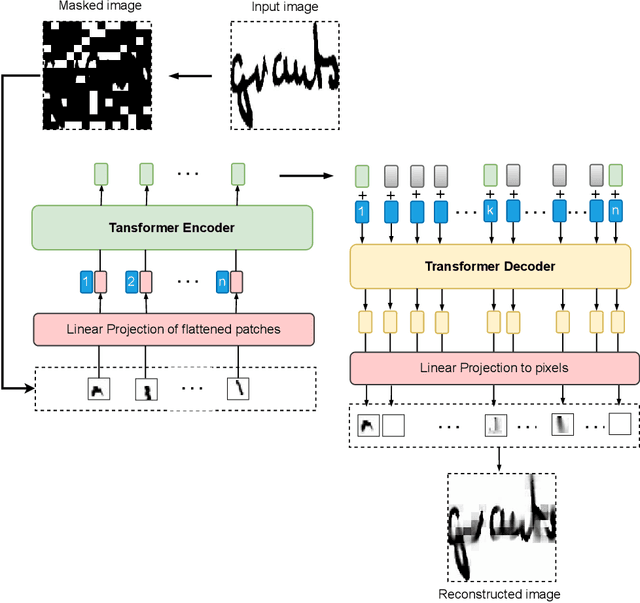
Keyword spotting (KWS) in historical documents is an important tool for the initial exploration of digitized collections. Nowadays, the most efficient KWS methods are relying on machine learning techniques that require a large amount of annotated training data. However, in the case of historical manuscripts, there is a lack of annotated corpus for training. To handle the data scarcity issue, we investigate the merits of the self-supervised learning to extract useful representations of the input data without relying on human annotations and then using these representations in the downstream task. We propose ST-KeyS, a masked auto-encoder model based on vision transformers where the pretraining stage is based on the mask-and-predict paradigm, without the need of labeled data. In the fine-tuning stage, the pre-trained encoder is integrated into a siamese neural network model that is fine-tuned to improve feature embedding from the input images. We further improve the image representation using pyramidal histogram of characters (PHOC) embedding to create and exploit an intermediate representation of images based on text attributes. In an exhaustive experimental evaluation on three widely used benchmark datasets (Botany, Alvermann Konzilsprotokolle and George Washington), the proposed approach outperforms state-of-the-art methods trained on the same datasets.
Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples
Feb 09, 2023



Diffusion Models (DMs) achieve state-of-the-art performance in generative tasks, boosting a wave in AI for Art. Despite the success of commercialization, DMs meanwhile provide tools for copyright violations, where infringers benefit from illegally using paintings created by human artists to train DMs and generate novel paintings in a similar style. In this paper, we show that it is possible to create an image $x'$ that is similar to an image $x$ for human vision but unrecognizable for DMs. We build a framework to define and evaluate this adversarial example for diffusion models. Based on the framework, we further propose AdvDM, an algorithm to generate adversarial examples for DMs. By optimizing upon different latent variables sampled from the reverse process of DMs, AdvDM conducts a Monte-Carlo estimation of adversarial examples for DMs. Extensive experiments show that the estimated adversarial examples can effectively hinder DMs from extracting their features. Our method can be a powerful tool for human artists to protect their copyright against infringers with DM-based AI-for-Art applications.