 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EEG-based Image Feature Extraction for Visual Classification using Deep Learning
Sep 27, 2022
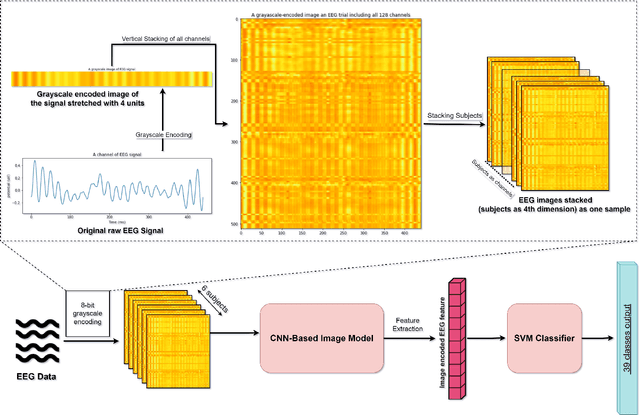
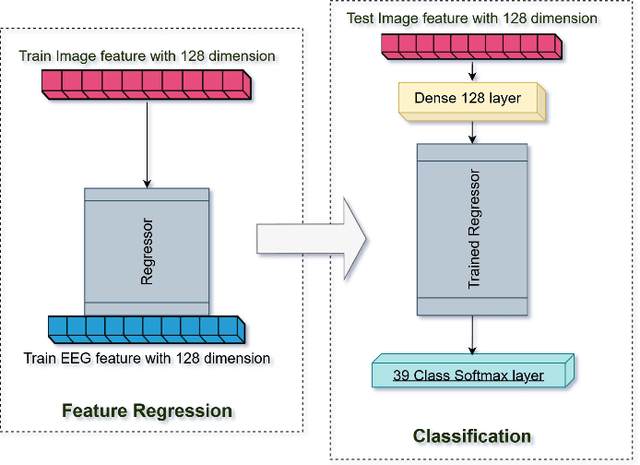
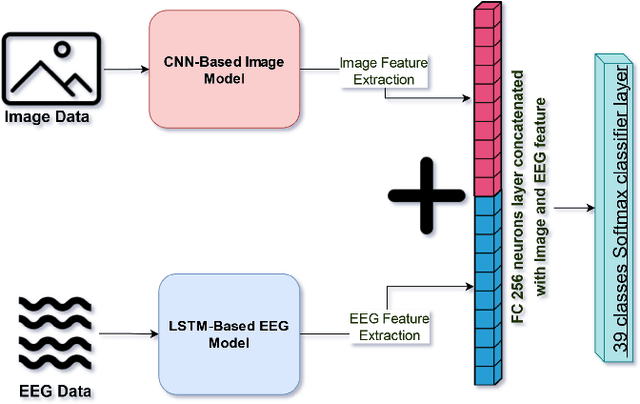
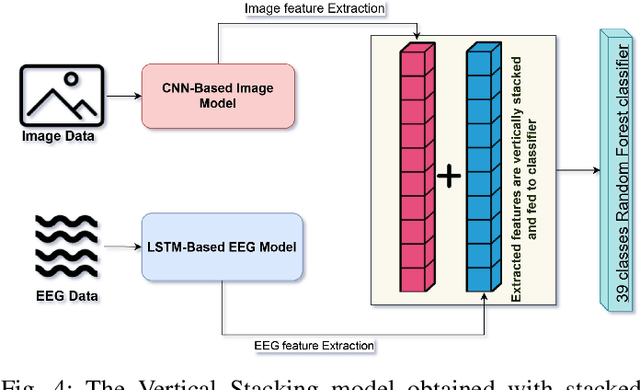
While capable of segregating visual data, humans take time to examine a single piece, let alone thousands or millions of samples. The deep learning models efficiently process sizeable information with the help of modern-day computing. However, their questionable decision-making process has raised considerable concerns. Recent studies have identified a new approach to extract image features from EEG signals and combine them with standard image features. These approaches make deep learning models more interpretable and also enables faster converging of models with fewer samples. Inspired by recent studies, we developed an efficient way of encoding EEG signals as images to facilitate a more subtle understanding of brain signals with deep learning models. Using two variations in such encoding methods, we classified the encoded EEG signals corresponding to 39 image classes with a benchmark accuracy of 70% on the layered dataset of six subjects, which is significantly higher than the existing work. Our image classification approach with combined EEG features achieved an accuracy of 82% compared to the slightly better accuracy of a pure deep learning approach; nevertheless, it demonstrates the viability of the theory.
The Influences of Color and Shape Features in Visual Contrastive Learning
Jan 29, 2023



In the field of visual representation learning, performance of contrastive learning has been catching up with the supervised method which is commonly a classification convolutional neural network. However, most of the research work focuses on improving the accuracy of downstream tasks such as image classification and object detection. For visual contrastive learning, the influences of individual image features (e.g., color and shape) to model performance remain ambiguous. This paper investigates such influences by designing various ablation experiments, the results of which are evaluated by specifically designed metrics. While these metrics are not invented by us, we first use them in the field of representation evaluation. Specifically, we assess the contribution of two primary image features (i.e., color and shape) in a quantitative way. Experimental results show that compared with supervised representations, contrastive representations tend to cluster with objects of similar color in the representation space, and contain less shape information than supervised representations. Finally, we discuss that the current data augmentation is responsible for these results. We believe that exploring an unsupervised augmentation method that
Understanding Social Media Cross-Modality Discourse in Linguistic Space
Feb 26, 2023
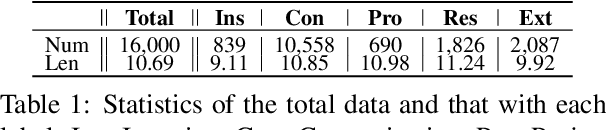

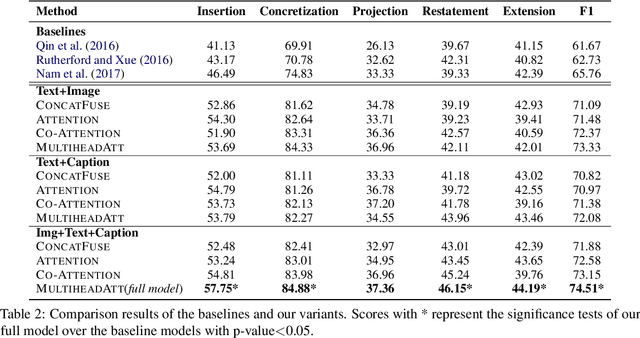
The multimedia communications with texts and images are popular on social media. However, limited studies concern how images are structured with texts to form coherent meanings in human cognition. To fill in the gap, we present a novel concept of cross-modality discourse, reflecting how human readers couple image and text understandings. Text descriptions are first derived from images (named as subtitles) in the multimedia contexts. Five labels -- entity-level insertion, projection and concretization and scene-level restatement and extension -- are further employed to shape the structure of subtitles and texts and present their joint meanings. As a pilot study, we also build the very first dataset containing 16K multimedia tweets with manually annotated discourse labels. The experimental results show that the multimedia encoder based on multi-head attention with captions is able to obtain the-state-of-the-art results.
On the Importance of Noise Scheduling for Diffusion Models
Jan 26, 2023
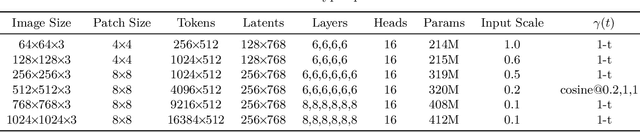

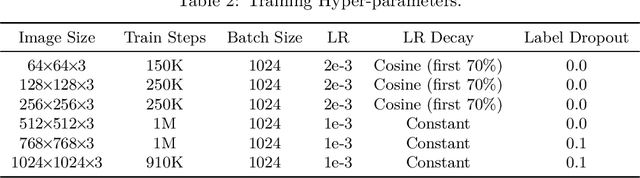
We empirically study the effect of noise scheduling strategies for denoising diffusion generative models. There are three findings: (1) the noise scheduling is crucial for the performance, and the optimal one depends on the task (e.g., image sizes), (2) when increasing the image size, the optimal noise scheduling shifts towards a noisier one (due to increased redundancy in pixels), and (3) simply scaling the input data by a factor of $b$ while keeping the noise schedule function fixed (equivalent to shifting the logSNR by $\log b$) is a good strategy across image sizes. This simple recipe, when combined with recently proposed Recurrent Interface Network (RIN), yields state-of-the-art pixel-based diffusion models for high-resolution images on ImageNet, enabling single-stage, end-to-end generation of diverse and high-fidelity images at 1024$\times$1024 resolution for the first time (without upsampling/cascades).
Bayesian Layer Graph Convolutioanl Network for Hyperspetral Image Classification
Nov 14, 2022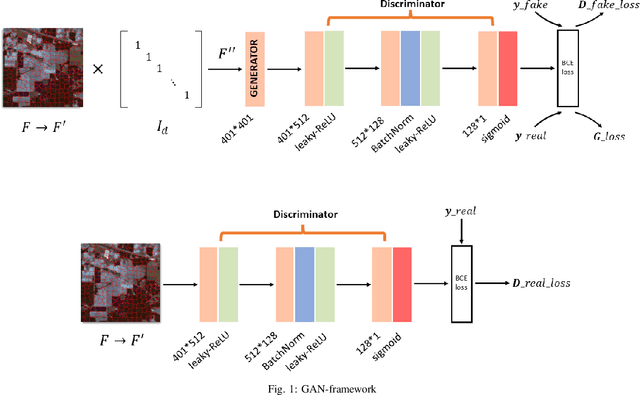
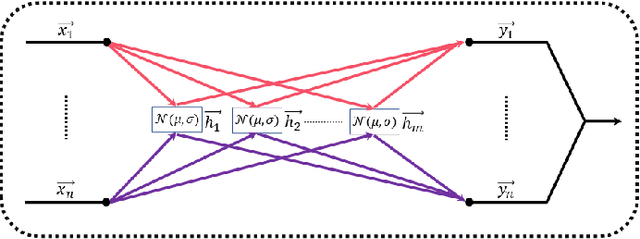
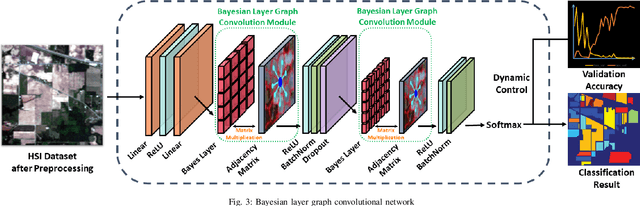

In recent years, research on hyperspectral image (HSI) classification has continuous progress on introducing deep network models, and recently the graph convolutional network (GCN) based models have shown impressive performance. However, these deep learning frameworks based on point estimation suffer from low generalization and inability to quantify the classification results uncertainty. On the other hand, simply applying the Bayesian Neural Network (BNN) based on distribution estimation to classify the HSI is unable to achieve high classification accuracy due to the large amount of parameters. In this paper, we design a Bayesian layer with Bayesian idea as an insertion layer into point estimation based neural networks, and propose a Bayesian Layer Graph Convolutional Network (BLGCN) model by combining graph convolution operations, which can effectively extract graph information and estimate the uncertainty of classification results. Moreover, a Generative Adversarial Network (GAN) is built to solve the sample imbalance problem of HSI dataset. Finally, we design a dynamic control training strategy based on the confidence interval of the classification results, which will terminate the training early when the confidence interval reaches the preseted threshold. The experimental results show that our model achieves a balance between high classification accuracy and strong generalization. In addition, it can quantifies the uncertainty of the classification results.
sMRI-PatchNet: A novel explainable patch-based deep learning network for Alzheimer's disease diagnosis and discriminative atrophy localisation with Structural MRI
Feb 17, 2023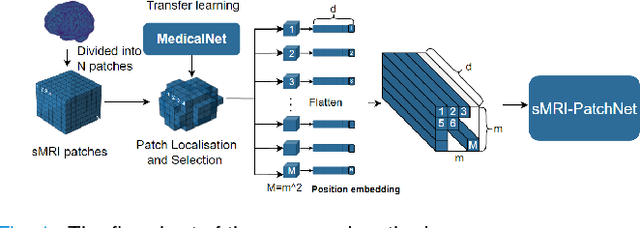
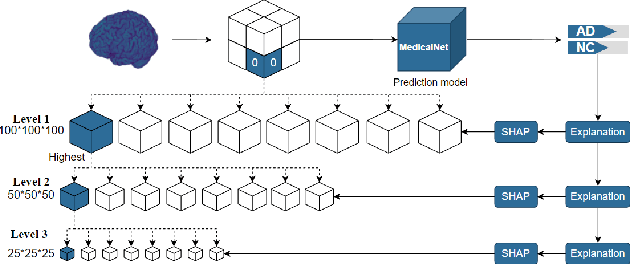

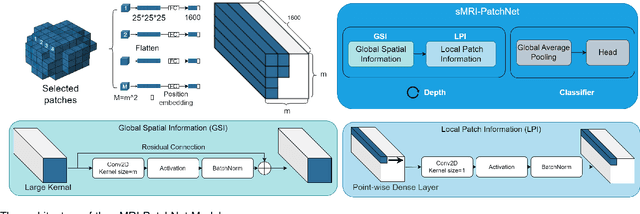
Structural magnetic resonance imaging (sMRI) can identify subtle brain changes due to its high contrast for soft tissues and high spatial resolution. It has been widely used in diagnosing neurological brain diseases, such as Alzheimer disease (AD). However, the size of 3D high-resolution data poses a significant challenge for data analysis and processing. Since only a few areas of the brain show structural changes highly associated with AD, the patch-based methods dividing the whole image data into several small regular patches have shown promising for more efficient sMRI-based image analysis. The major challenges of the patch-based methods on sMRI include identifying the discriminative patches, combining features from the discrete discriminative patches, and designing appropriate classifiers. This work proposes a novel patch-based deep learning network (sMRI-PatchNet) with explainable patch localisation and selection for AD diagnosis using sMRI. Specifically, it consists of two primary components: 1) A fast and efficient explainable patch selection mechanism for determining the most discriminative patches based on computing the SHapley Additive exPlanations (SHAP) contribution to a transfer learning model for AD diagnosis on massive medical data; and 2) A novel patch-based network for extracting deep features and AD classfication from the selected patches with position embeddings to retain position information, capable of capturing the global and local information of inter- and intra-patches. This method has been applied for the AD classification and the prediction of the transitional state moderate cognitive impairment (MCI) conversion with real datasets.
High-Fidelity Image Inpainting with GAN Inversion
Aug 25, 2022
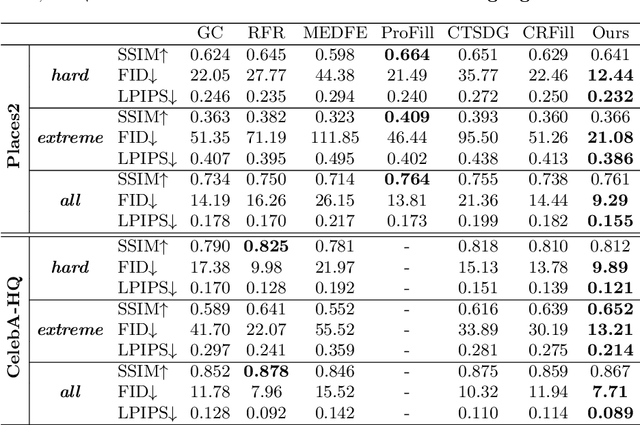
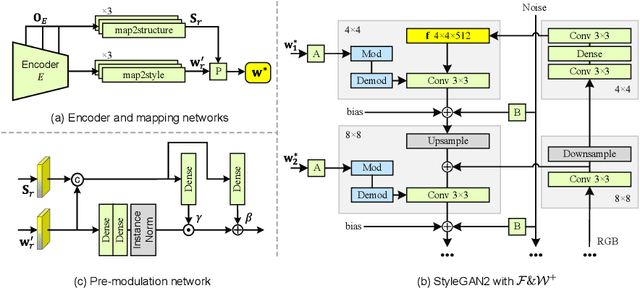
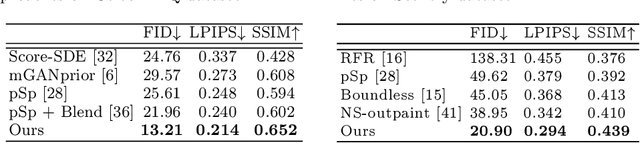
Image inpainting seeks a semantically consistent way to recover the corrupted image in the light of its unmasked content. Previous approaches usually reuse the well-trained GAN as effective prior to generate realistic patches for missing holes with GAN inversion. Nevertheless, the ignorance of a hard constraint in these algorithms may yield the gap between GAN inversion and image inpainting. Addressing this problem, in this paper, we devise a novel GAN inversion model for image inpainting, dubbed InvertFill, mainly consisting of an encoder with a pre-modulation module and a GAN generator with F&W+ latent space. Within the encoder, the pre-modulation network leverages multi-scale structures to encode more discriminative semantics into style vectors. In order to bridge the gap between GAN inversion and image inpainting, F&W+ latent space is proposed to eliminate glaring color discrepancy and semantic inconsistency. To reconstruct faithful and photorealistic images, a simple yet effective Soft-update Mean Latent module is designed to capture more diverse in-domain patterns that synthesize high-fidelity textures for large corruptions. Comprehensive experiments on four challenging datasets, including Places2, CelebA-HQ, MetFaces, and Scenery, demonstrate that our InvertFill outperforms the advanced approaches qualitatively and quantitatively and supports the completion of out-of-domain images well.
Reproducibility in medical image radiomic studies: contribution of dynamic histogram binning
Nov 09, 2022
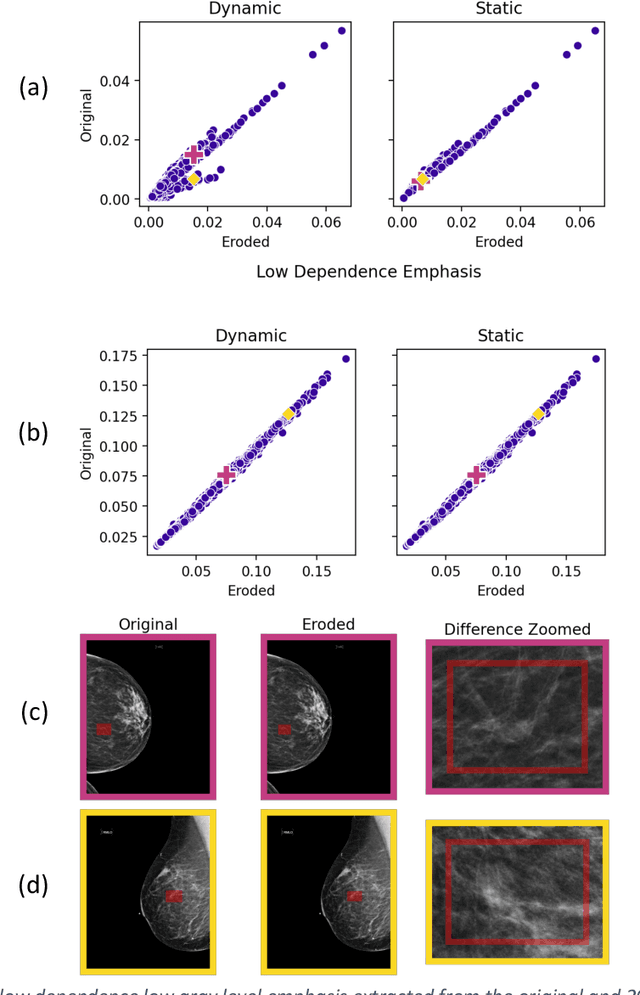
The de facto standard of dynamic histogram binning for radiomic feature extraction leads to an elevated sensitivity to fluctuations in annotated regions. This may impact the majority of radiomic studies published recently and contribute to issues regarding poor reproducibility of radiomic-based machine learning that has led to significant efforts for data harmonization; however, we believe the issues highlighted here are comparatively neglected, but often remedied by choosing static binning. The field of radiomics has improved through the development of community standards and open-source libraries such as PyRadiomics. But differences in image acquisition, systematic differences between observers' annotations, and preprocessing steps still pose challenges. These can change the distribution of voxels altering extracted features and can be exacerbated with dynamic binning.
DeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023
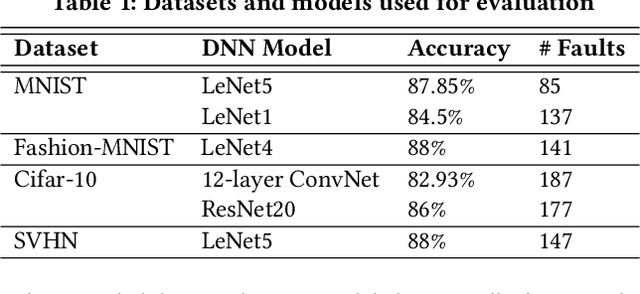
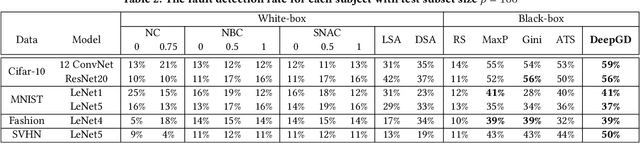
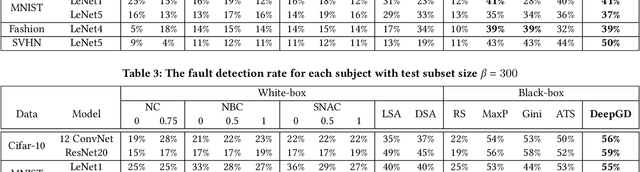
Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
Improved Image Classification with Token Fusion
Aug 19, 2022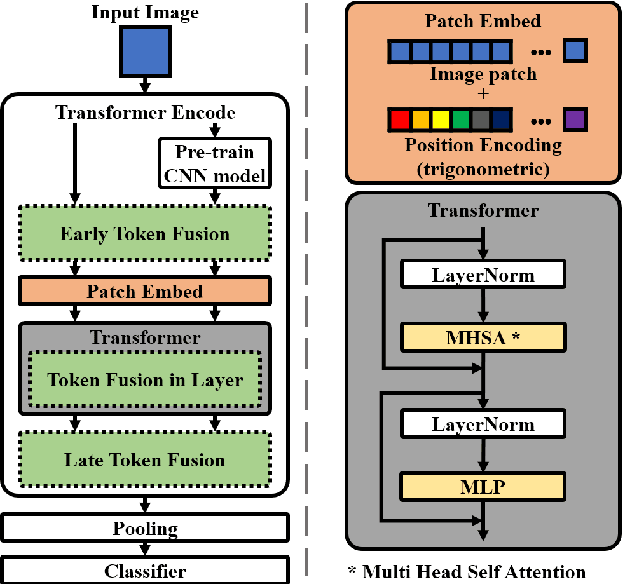
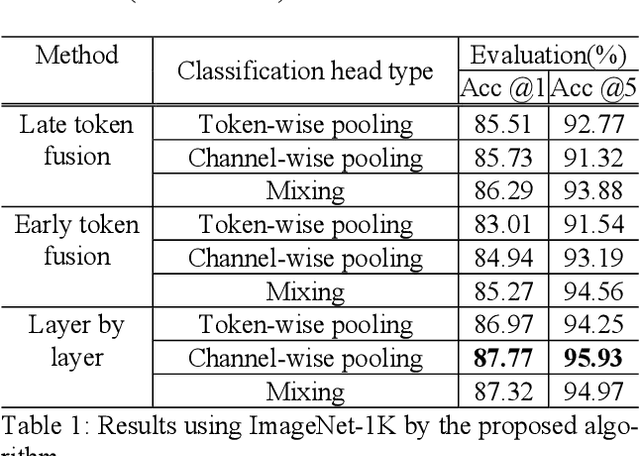
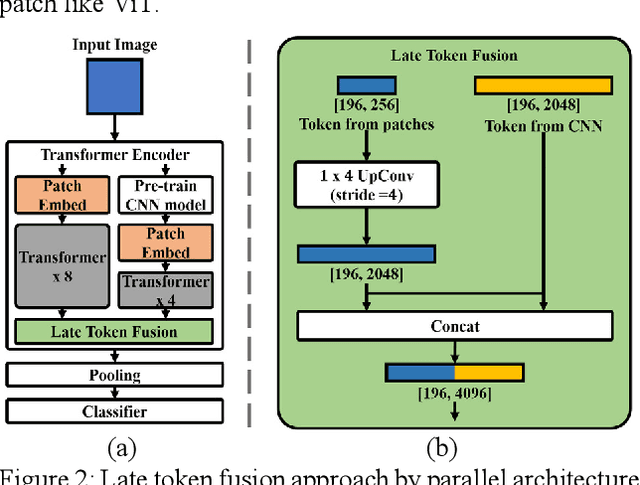
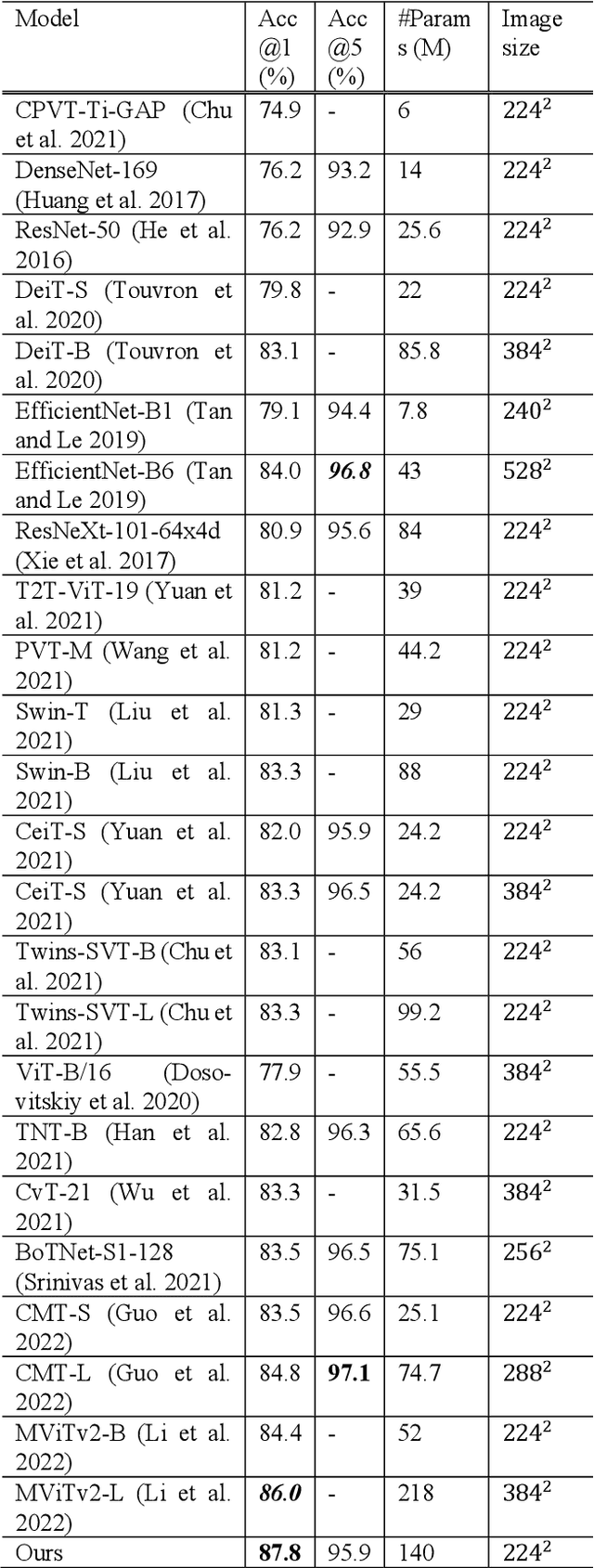
In this paper, we propose a method using the fusion of CNN and transformer structure to improve image classification performance. In the case of CNN, information about a local area on an image can be extracted well, but there is a limit to the extraction of global information. On the other hand, the transformer has an advantage in relatively global extraction, but has a disadvantage in that it requires a lot of memory for local feature value extraction. In the case of an image, it is converted into a feature map through CNN, and each feature map's pixel is considered a token. At the same time, the image is divided into patch areas and then fused with the transformer method that views them as tokens. For the fusion of tokens with two different characteristics, we propose three methods: (1) late token fusion with parallel structure, (2) early token fusion, (3) token fusion in a layer by layer. In an experiment using ImageNet 1k, the proposed method shows the best classification performance.