 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Memory-Driven Text-to-Image Generation
Aug 15, 2022

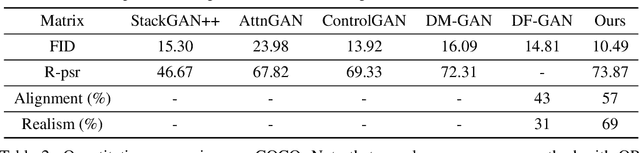

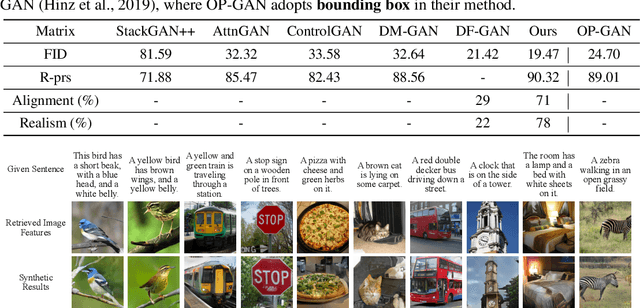
We introduce a memory-driven semi-parametric approach to text-to-image generation, which is based on both parametric and non-parametric techniques. The non-parametric component is a memory bank of image features constructed from a training set of images. The parametric component is a generative adversarial network. Given a new text description at inference time, the memory bank is used to selectively retrieve image features that are provided as basic information of target images, which enables the generator to produce realistic synthetic results. We also incorporate the content information into the discriminator, together with semantic features, allowing the discriminator to make a more reliable prediction. Experimental results demonstrate that the proposed memory-driven semi-parametric approach produces more realistic images than purely parametric approaches, in terms of both visual fidelity and text-image semantic consistency.
Uncovering Bias in Face Generation Models
Feb 22, 2023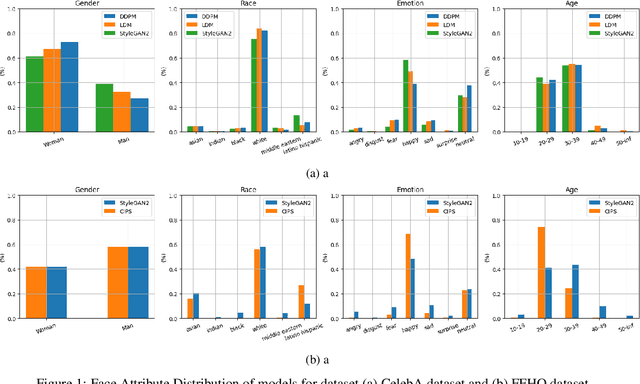
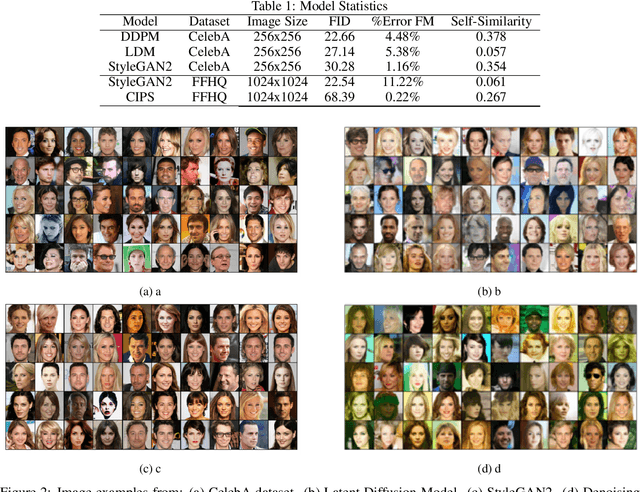

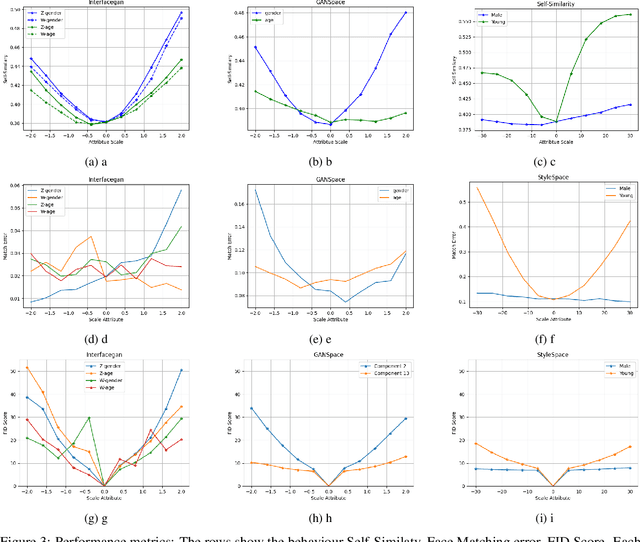
Recent advancements in GANs and diffusion models have enabled the creation of high-resolution, hyper-realistic images. However, these models may misrepresent certain social groups and present bias. Understanding bias in these models remains an important research question, especially for tasks that support critical decision-making and could affect minorities. The contribution of this work is a novel analysis covering architectures and embedding spaces for fine-grained understanding of bias over three approaches: generators, attribute modifier, and post-processing bias mitigators. This work shows that generators suffer from bias across all social groups with attribute preferences such as between 75%-85% for whiteness and 60%-80% for the female gender (for all trained CelebA models) and low probabilities of generating children and older men. Modifier and mitigators work as post-processor and change the generator performance. For instance, attribute channel perturbation strategies modify the embedding spaces. We quantify the influence of this change on group fairness by measuring the impact on image quality and group features. Specifically, we use the Fr\'echet Inception Distance (FID), the Face Matching Error and the Self-Similarity score. For Interfacegan, we analyze one and two attribute channel perturbations and examine the effect on the fairness distribution and the quality of the image. Finally, we analyzed the post-processing bias mitigators, which are the fastest and most computationally efficient way to mitigate bias. We find that these mitigation techniques show similar results on KL divergence and FID score, however, self-similarity scores show a different feature concentration on the new groups of the data distribution. The weaknesses and ongoing challenges described in this work must be considered in the pursuit of creating fair and unbiased face generation models.
Exemplar-Based Image Colorization with A Learning Framework
Sep 13, 2022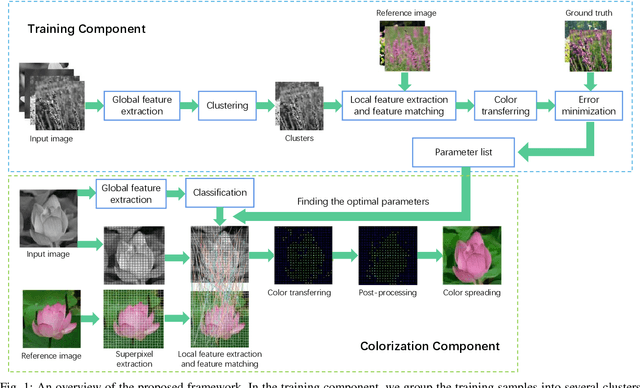



Image learning and colorization are hot spots in multimedia domain. Inspired by the learning capability of humans, in this paper, we propose an automatic colorization method with a learning framework. This method can be viewed as a hybrid of exemplar-based and learning-based method, and it decouples the colorization process and learning process so as to generate various color styles for the same gray image. The matching process in the exemplar-based colorization method can be regarded as a parameterized function, and we employ a large amount of color images as the training samples to fit the parameters. During the training process, the color images are the ground truths, and we learn the optimal parameters for the matching process by minimizing the errors in terms of the parameters for the matching function. To deal with images with various compositions, a global feature is introduced, which can be used to classify the images with respect to their compositions, and then learn the optimal matching parameters for each image category individually. What's more, a spatial consistency based post-processing is design to smooth the extracted color information from the reference image to remove matching errors. Extensive experiments are conducted to verify the effectiveness of the method, and it achieves comparable performance against the state-of-the-art colorization algorithms.
A Capsule Network for Hierarchical Multi-Label Image Classification
Sep 13, 2022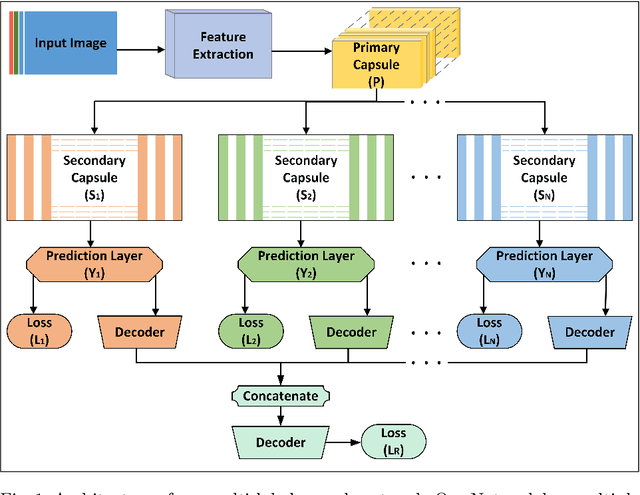
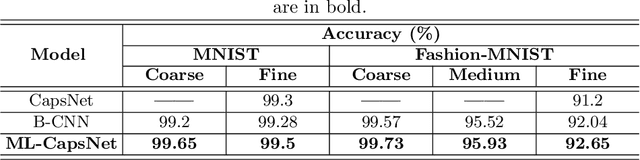
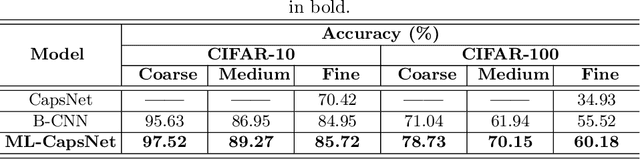
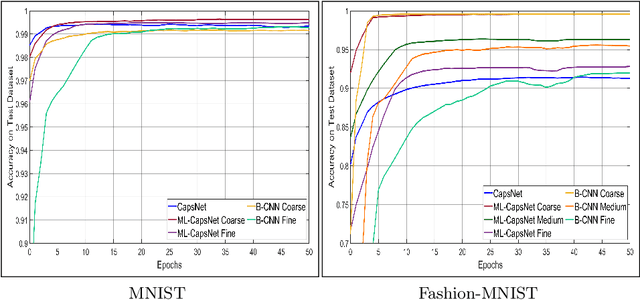
Image classification is one of the most important areas in computer vision. Hierarchical multi-label classification applies when a multi-class image classification problem is arranged into smaller ones based upon a hierarchy or taxonomy. Thus, hierarchical classification modes generally provide multiple class predictions on each instance, whereby these are expected to reflect the structure of image classes as related to one another. In this paper, we propose a multi-label capsule network (ML-CapsNet) for hierarchical classification. Our ML-CapsNet predicts multiple image classes based on a hierarchical class-label tree structure. To this end, we present a loss function that takes into account the multi-label predictions of the network. As a result, the training approach for our ML-CapsNet uses a coarse to fine paradigm while maintaining consistency with the structure in the classification levels in the label-hierarchy. We also perform experiments using widely available datasets and compare the model with alternatives elsewhere in the literature. In our experiments, our ML-CapsNet yields a margin of improvement with respect to these alternative methods.
Energy-Aware JPEG Image Compression: A Multi-Objective Approach
Sep 09, 2022
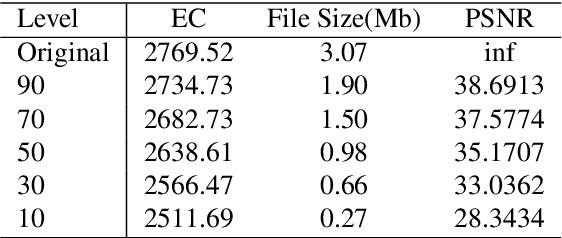
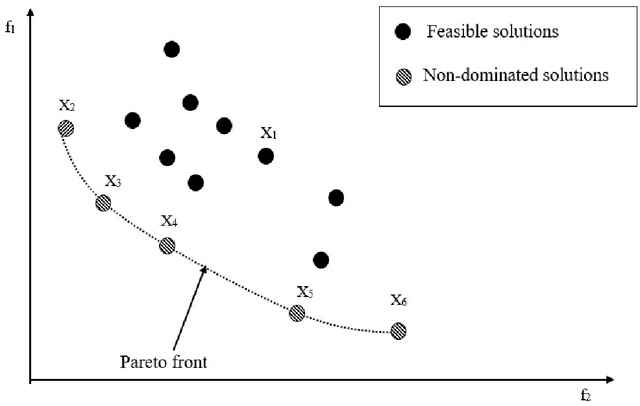
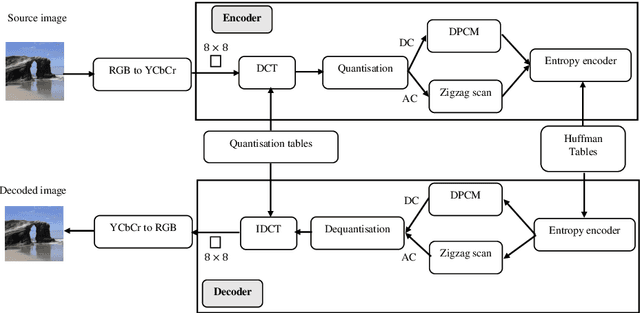
Customer satisfaction is crucially affected by energy consumption in mobile devices. One of the most energy-consuming parts of an application is images. While different images with different quality consume different amounts of energy, there are no straightforward methods to calculate the energy consumption of an operation in a typical image. This paper, first, investigates that there is a correlation between energy consumption and image quality as well as image file size. Therefore, these two can be considered as a proxy for energy consumption. Then, we propose a multi-objective strategy to enhance image quality and reduce image file size based on the quantisation tables in JPEG image compression. To this end, we have used two general multi-objective metaheuristic approaches: scalarisation and Pareto-based. Scalarisation methods find a single optimal solution based on combining different objectives, while Pareto-based techniques aim to achieve a set of solutions. In this paper, we embed our strategy into five scalarisation algorithms, including energy-aware multi-objective genetic algorithm (EnMOGA), energy-aware multi-objective particle swarm optimisation (EnMOPSO), energy-aware multi-objective differential evolution (EnMODE), energy-aware multi-objective evolutionary strategy (EnMOES), and energy-aware multi-objective pattern search (EnMOPS). Also, two Pareto-based methods, including a non-dominated sorting genetic algorithm (NSGA-II) and a reference-point-based NSGA-II (NSGA-III) are used for the embedding scheme, and two Pareto-based algorithms, EnNSGAII and EnNSGAIII, are presented. Experimental studies show that the performance of the baseline algorithm is improved by embedding the proposed strategy into metaheuristic algorithms.
Targeted Image Reconstruction by Sampling Pre-trained Diffusion Model
Jan 18, 2023
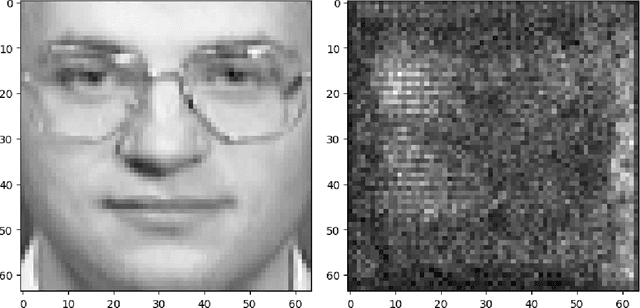
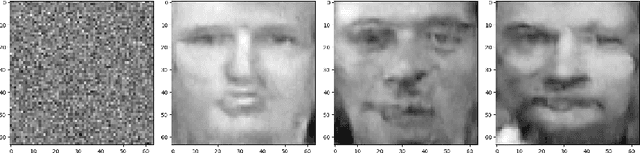

A trained neural network model contains information on the training data. Given such a model, malicious parties can leverage the "knowledge" in this model and design ways to print out any usable information (known as model inversion attack). Therefore, it is valuable to explore the ways to conduct a such attack and demonstrate its severity. In this work, we proposed ways to generate a data point of the target class without prior knowledge of the exact target distribution by using a pre-trained diffusion model.
Understanding Social Media Cross-Modality Discourse in Linguistic Space
Feb 26, 2023
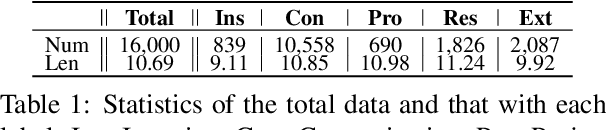

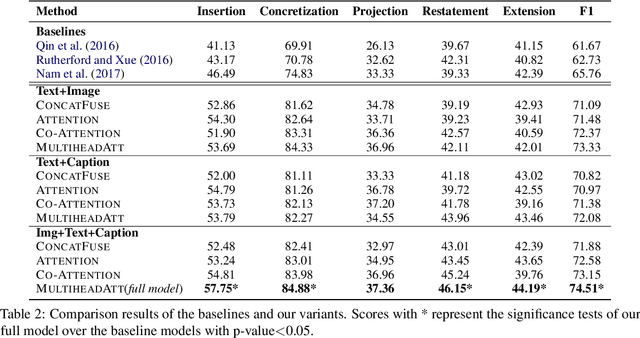
The multimedia communications with texts and images are popular on social media. However, limited studies concern how images are structured with texts to form coherent meanings in human cognition. To fill in the gap, we present a novel concept of cross-modality discourse, reflecting how human readers couple image and text understandings. Text descriptions are first derived from images (named as subtitles) in the multimedia contexts. Five labels -- entity-level insertion, projection and concretization and scene-level restatement and extension -- are further employed to shape the structure of subtitles and texts and present their joint meanings. As a pilot study, we also build the very first dataset containing 16K multimedia tweets with manually annotated discourse labels. The experimental results show that the multimedia encoder based on multi-head attention with captions is able to obtain the-state-of-the-art results.
GDIP: Gated Differentiable Image Processing for Object-Detection in Adverse Conditions
Sep 29, 2022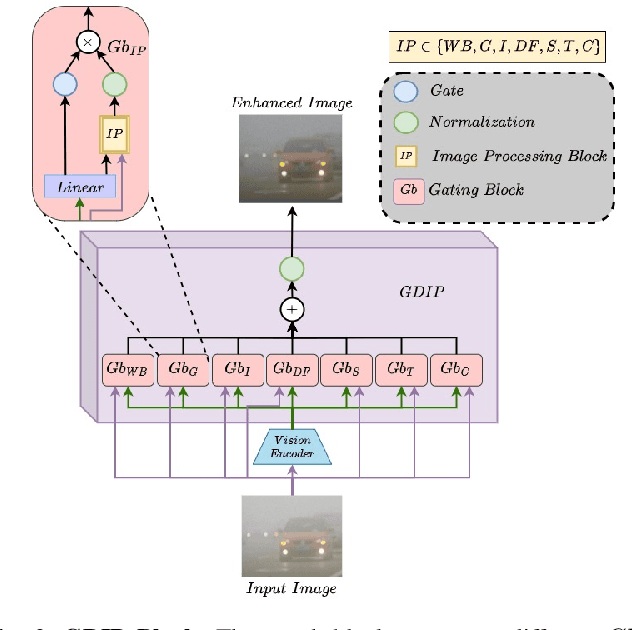
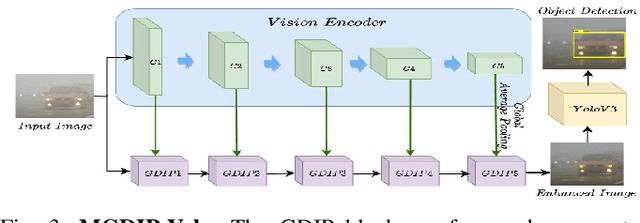
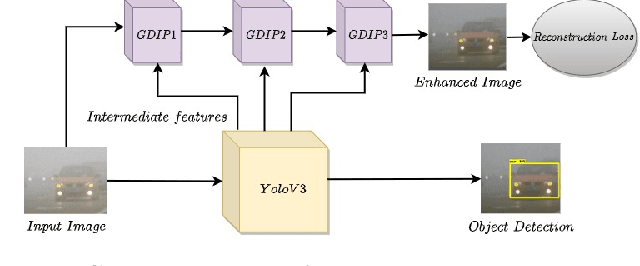
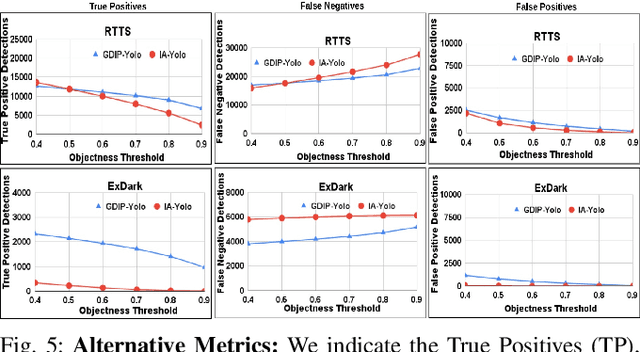
Detecting objects under adverse weather and lighting conditions is crucial for the safe and continuous operation of an autonomous vehicle, and remains an unsolved problem. We present a Gated Differentiable Image Processing (GDIP) block, a domain-agnostic network architecture, which can be plugged into existing object detection networks (e.g., Yolo) and trained end-to-end with adverse condition images such as those captured under fog and low lighting. Our proposed GDIP block learns to enhance images directly through the downstream object detection loss. This is achieved by learning parameters of multiple image pre-processing (IP) techniques that operate concurrently, with their outputs combined using weights learned through a novel gating mechanism. We further improve GDIP through a multi-stage guidance procedure for progressive image enhancement. Finally, trading off accuracy for speed, we propose a variant of GDIP that can be used as a regularizer for training Yolo, which eliminates the need for GDIP-based image enhancement during inference, resulting in higher throughput and plausible real-world deployment. We demonstrate significant improvement in detection performance over several state-of-the-art methods through quantitative and qualitative studies on synthetic datasets such as PascalVOC, and real-world foggy (RTTS) and low-lighting (ExDark) datasets.
CGAN-ECT: Tomography Image Reconstruction from Electrical Capacitance Measurements Using CGANs
Sep 12, 2022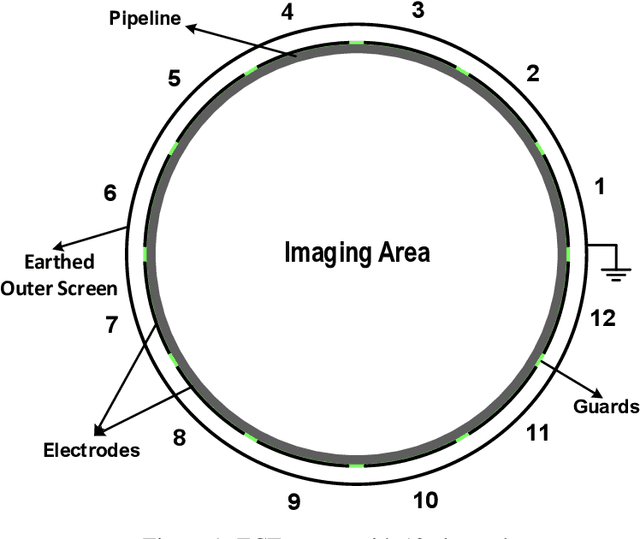
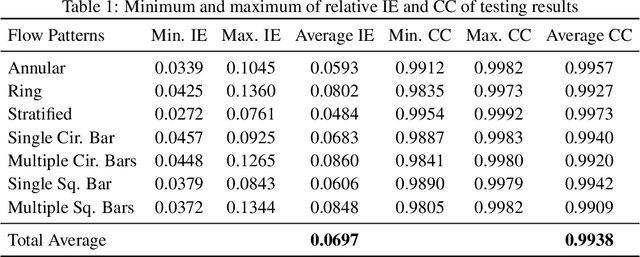
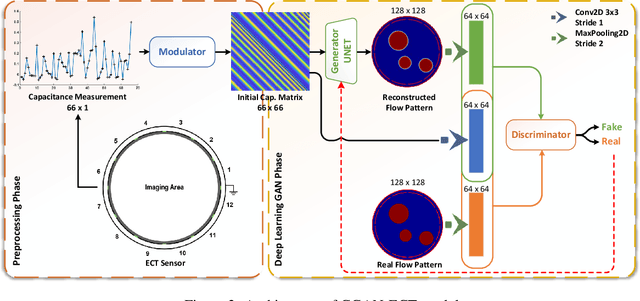
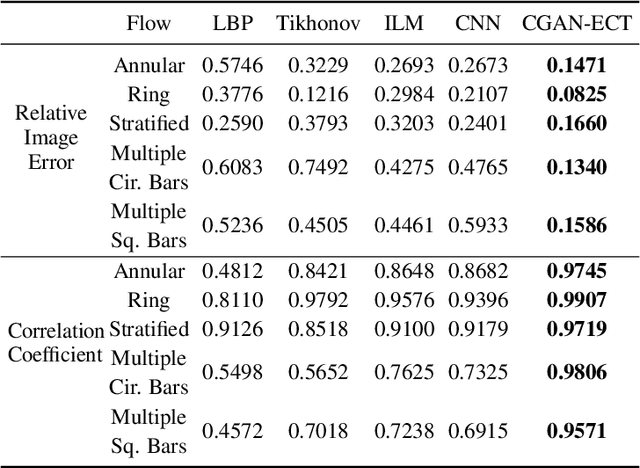
Due to the rapid growth of Electrical Capacitance Tomography (ECT) applications in several industrial fields, there is a crucial need for developing high quality, yet fast, methodologies of image reconstruction from raw capacitance measurements. Deep learning, as an effective non-linear mapping tool for complicated functions, has been going viral in many fields including electrical tomography. In this paper, we propose a Conditional Generative Adversarial Network (CGAN) model for reconstructing ECT images from capacitance measurements. The initial image of the CGAN model is constructed from the capacitance measurement. To our knowledge, this is the first time to represent the capacitance measurements in an image form. We have created a new massive ECT dataset of 320K synthetic image measurements pairs for training, and testing the proposed model. The feasibility and generalization ability of the proposed CGAN-ECT model are evaluated using testing dataset, contaminated data and flow patterns that are not exposed to the model during the training phase. The evaluation results prove that the proposed CGAN-ECT model can efficiently create more accurate ECT images than traditional and other deep learning-based image reconstruction algorithms. CGAN-ECT achieved an average image correlation coefficient of more than 99.3% and an average relative image error about 0.07.
The Influences of Color and Shape Features in Visual Contrastive Learning
Jan 29, 2023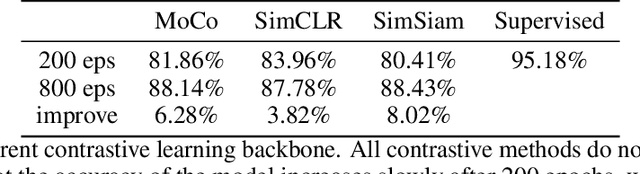



In the field of visual representation learning, performance of contrastive learning has been catching up with the supervised method which is commonly a classification convolutional neural network. However, most of the research work focuses on improving the accuracy of downstream tasks such as image classification and object detection. For visual contrastive learning, the influences of individual image features (e.g., color and shape) to model performance remain ambiguous. This paper investigates such influences by designing various ablation experiments, the results of which are evaluated by specifically designed metrics. While these metrics are not invented by us, we first use them in the field of representation evaluation. Specifically, we assess the contribution of two primary image features (i.e., color and shape) in a quantitative way. Experimental results show that compared with supervised representations, contrastive representations tend to cluster with objects of similar color in the representation space, and contain less shape information than supervised representations. Finally, we discuss that the current data augmentation is responsible for these results. We believe that exploring an unsupervised augmentation method that