 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Defending against Adversarial Audio via Diffusion Model
Mar 02, 2023
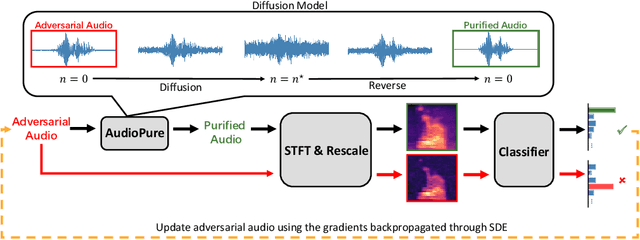

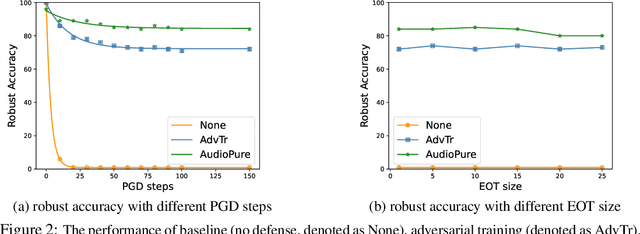

Deep learning models have been widely used in commercial acoustic systems in recent years. However, adversarial audio examples can cause abnormal behaviors for those acoustic systems, while being hard for humans to perceive. Various methods, such as transformation-based defenses and adversarial training, have been proposed to protect acoustic systems from adversarial attacks, but they are less effective against adaptive attacks. Furthermore, directly applying the methods from the image domain can lead to suboptimal results because of the unique properties of audio data. In this paper, we propose an adversarial purification-based defense pipeline, AudioPure, for acoustic systems via off-the-shelf diffusion models. Taking advantage of the strong generation ability of diffusion models, AudioPure first adds a small amount of noise to the adversarial audio and then runs the reverse sampling step to purify the noisy audio and recover clean audio. AudioPure is a plug-and-play method that can be directly applied to any pretrained classifier without any fine-tuning or re-training. We conduct extensive experiments on speech command recognition task to evaluate the robustness of AudioPure. Our method is effective against diverse adversarial attacks (e.g. $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm). It outperforms the existing methods under both strong adaptive white-box and black-box attacks bounded by $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm (up to +20\% in robust accuracy). Besides, we also evaluate the certified robustness for perturbations bounded by $\mathcal{L}_2$-norm via randomized smoothing. Our pipeline achieves a higher certified accuracy than baselines.
Learning Visual Explanations for DCNN-Based Image Classifiers Using an Attention Mechanism
Sep 22, 2022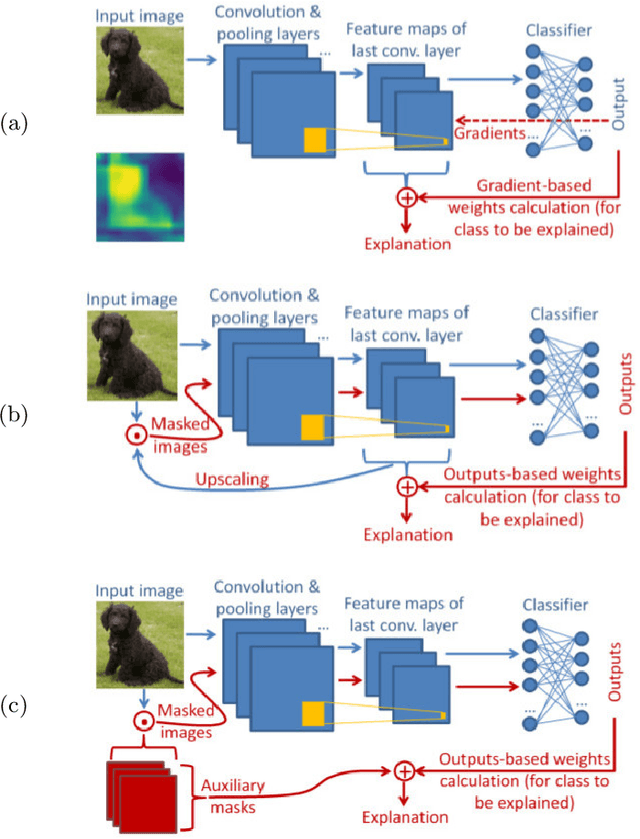
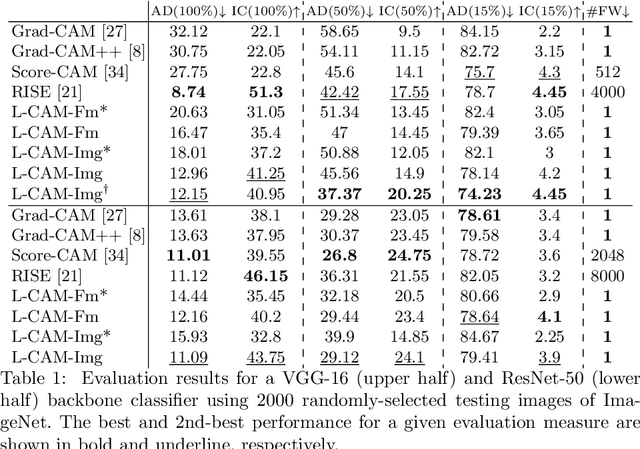
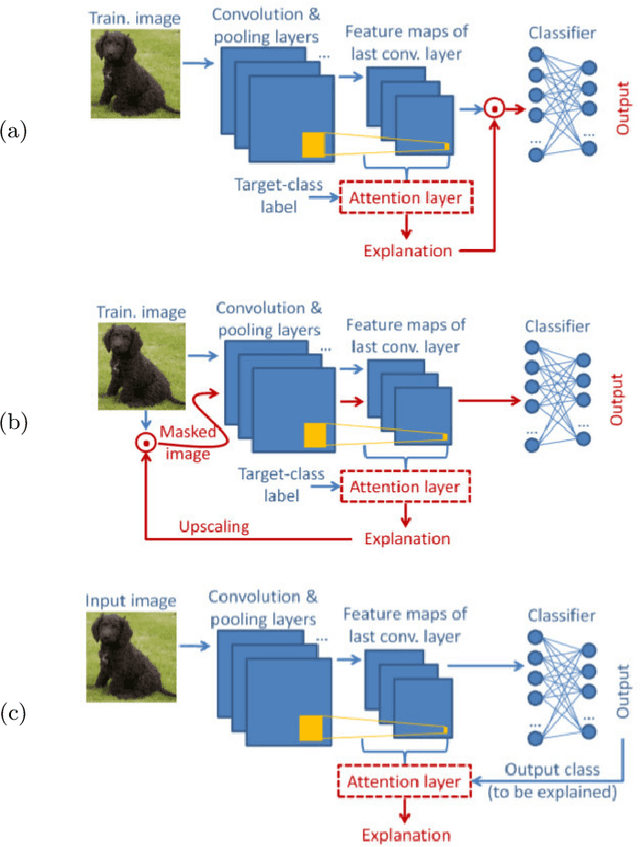

In this paper two new learning-based eXplainable AI (XAI) methods for deep convolutional neural network (DCNN) image classifiers, called L-CAM-Fm and L-CAM-Img, are proposed. Both methods use an attention mechanism that is inserted in the original (frozen) DCNN and is trained to derive class activation maps (CAMs) from the last convolutional layer's feature maps. During training, CAMs are applied to the feature maps (L-CAM-Fm) or the input image (L-CAM-Img) forcing the attention mechanism to learn the image regions explaining the DCNN's outcome. Experimental evaluation on ImageNet shows that the proposed methods achieve competitive results while requiring a single forward pass at the inference stage. Moreover, based on the derived explanations a comprehensive qualitative analysis is performed providing valuable insight for understanding the reasons behind classification errors, including possible dataset biases affecting the trained classifier.
Directed Diffusion: Direct Control of Object Placement through Attention Guidance
Feb 25, 2023

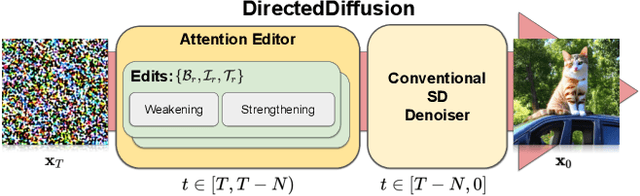
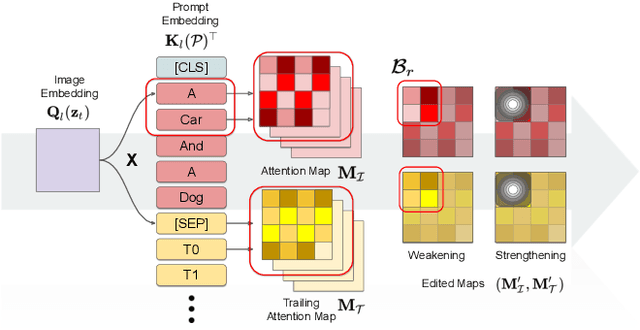
Text-guided diffusion models such as DALLE-2, IMAGEN, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are very high quality as well. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. Unfortunately, this capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work we take a particularly straightforward approach to providing the needed direction, by injecting ``activation'' at desired positions in the cross-attention maps corresponding to the objects under control, while attenuating the remainder of the map. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. To the best of our knowledge, our Directed Diffusion method is the first diffusion technique that provides positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
A Surrogate-Assisted Highly Cooperative Coevolutionary Algorithm for Hyperparameter Optimization in Deep Convolutional Neural Network
Feb 25, 2023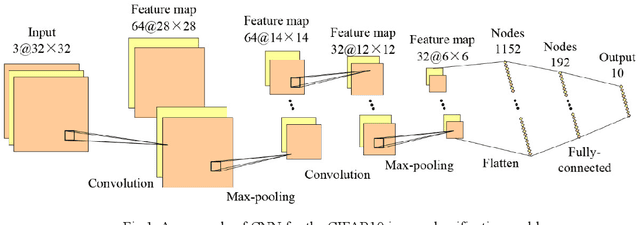
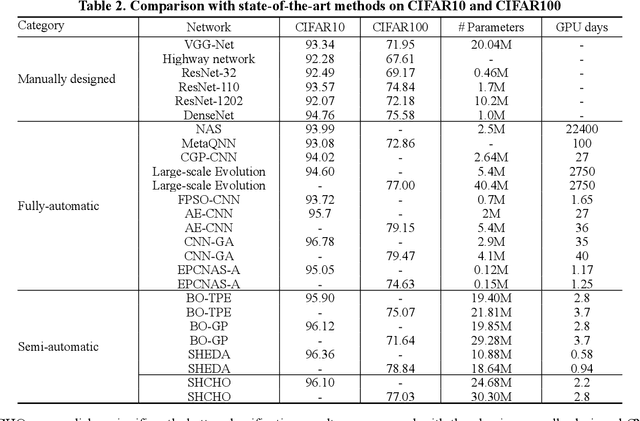

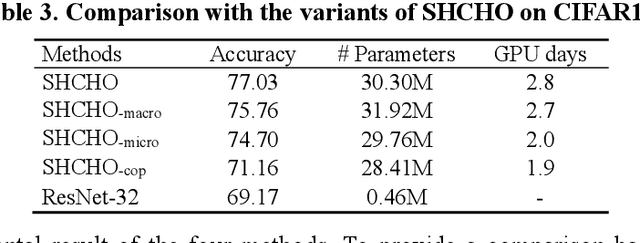
Convolutional neural networks (CNNs) have gained remarkable success in recent years. However, their performance highly relies on the architecture hyperparameters, and finding proper hyperparameters for a deep CNN is a challenging optimization problem owing to its high-dimensional and computationally expensive characteristics. Given these difficulties, this study proposes a surrogate-assisted highly cooperative hyperparameter optimization (SHCHO) algorithm for chain-styled CNNs. To narrow the large search space, SHCHO first decomposes the whole CNN into several overlapping sub-CNNs in accordance with the overlapping hyperparameter interaction structure and then cooperatively optimizes these hyperparameter subsets. Two cooperation mechanisms are designed during this process. One coordinates all the sub-CNNs to reproduce the information flow in the whole CNN and achieve macro cooperation among them, and the other tackles the overlapping components by simultaneously considering the involved two sub-CNNs and facilitates micro cooperation between them. As a result, a proper hyperparameter configuration can be effectively located for the whole CNN. Besides, SHCHO also employs the well-performing surrogate technique to assist in the hyperparameter optimization of each sub-CNN, thereby greatly reducing the expensive computational cost. Extensive experimental results on two widely-used image classification datasets indicate that SHCHO can significantly improve the performance of CNNs.
DOMINO: Domain-aware Model Calibration in Medical Image Segmentation
Sep 13, 2022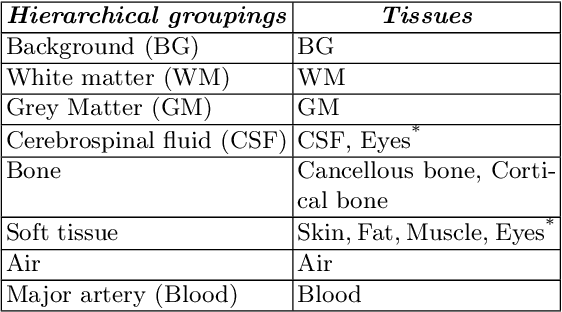
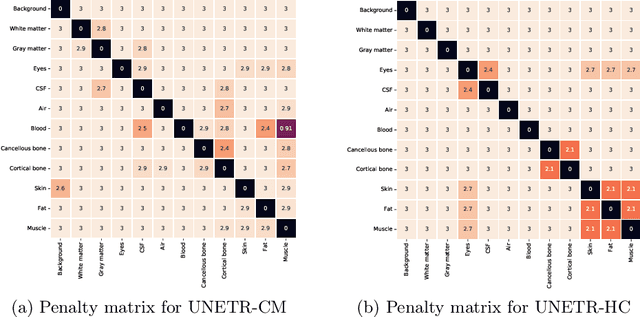
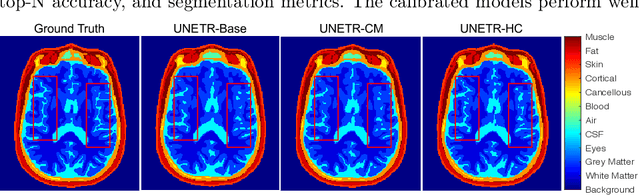
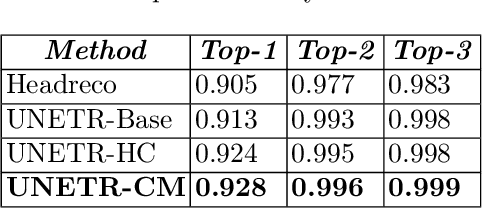
Model calibration measures the agreement between the predicted probability estimates and the true correctness likelihood. Proper model calibration is vital for high-risk applications. Unfortunately, modern deep neural networks are poorly calibrated, compromising trustworthiness and reliability. Medical image segmentation particularly suffers from this due to the natural uncertainty of tissue boundaries. This is exasperated by their loss functions, which favor overconfidence in the majority classes. We address these challenges with DOMINO, a domain-aware model calibration method that leverages the semantic confusability and hierarchical similarity between class labels. Our experiments demonstrate that our DOMINO-calibrated deep neural networks outperform non-calibrated models and state-of-the-art morphometric methods in head image segmentation. Our results show that our method can consistently achieve better calibration, higher accuracy, and faster inference times than these methods, especially on rarer classes. This performance is attributed to our domain-aware regularization to inform semantic model calibration. These findings show the importance of semantic ties between class labels in building confidence in deep learning models. The framework has the potential to improve the trustworthiness and reliability of generic medical image segmentation models. The code for this article is available at: https://github.com/lab-smile/DOMINO.
Diffusion Models and Semi-Supervised Learners Benefit Mutually with Few Labels
Feb 21, 2023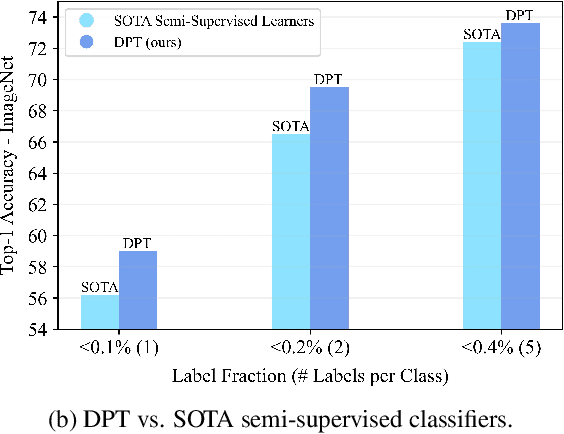
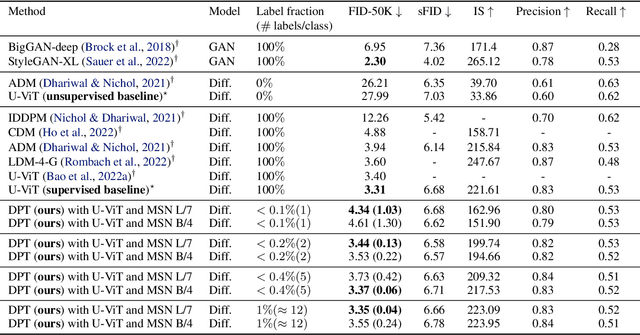

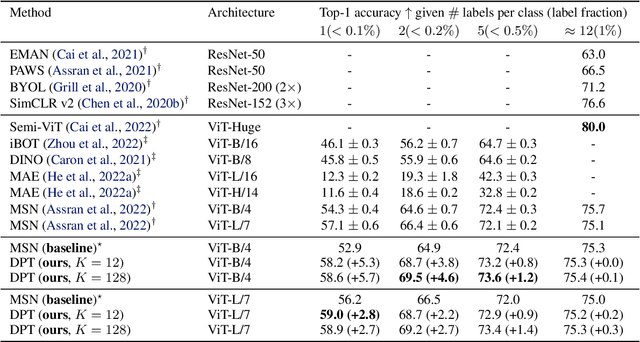
We propose a three-stage training strategy called dual pseudo training (DPT) for conditional image generation and classification in semi-supervised learning. First, a classifier is trained on partially labeled data and predicts pseudo labels for all data. Second, a conditional generative model is trained on all data with pseudo labels and generates pseudo images given labels. Finally, the classifier is trained on real data augmented by pseudo images with labels. We demonstrate large-scale diffusion models and semi-supervised learners benefit mutually with a few labels via DPT. In particular, on the ImageNet 256x256 generation benchmark, DPT can generate realistic, diverse, and semantically correct images with very few labels. With two (i.e., < 0.2%) and five (i.e., < 0.4%) labels per class, DPT achieves an FID of 3.44 and 3.37 respectively, outperforming strong diffusion models with full labels, such as IDDPM, CDM, ADM, and LDM. Besides, DPT outperforms competitive semi-supervised baselines substantially on ImageNet classification benchmarks with one, two, and five labels per class, achieving state-of-the-art top-1 accuracies of 59.0 (+2.8), 69.5 (+3.0), and 73.6 (+1.2) respectively.
Provable Copyright Protection for Generative Models
Feb 21, 2023
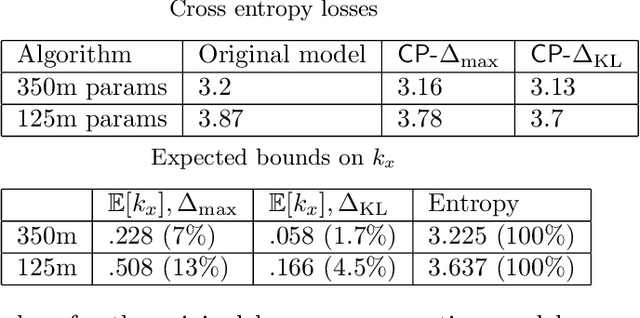
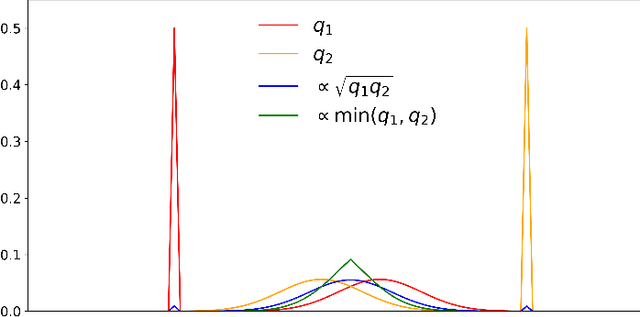
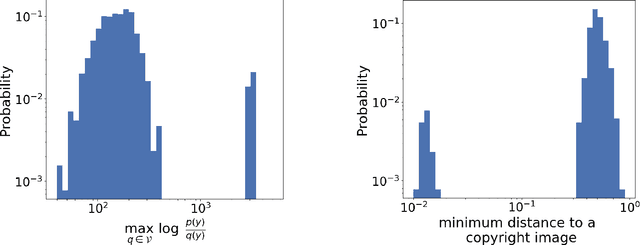
There is a growing concern that learned conditional generative models may output samples that are substantially similar to some copyrighted data $C$ that was in their training set. We give a formal definition of $\textit{near access-freeness (NAF)}$ and prove bounds on the probability that a model satisfying this definition outputs a sample similar to $C$, even if $C$ is included in its training set. Roughly speaking, a generative model $p$ is $\textit{$k$-NAF}$ if for every potentially copyrighted data $C$, the output of $p$ diverges by at most $k$-bits from the output of a model $q$ that $\textit{did not access $C$ at all}$. We also give generative model learning algorithms, which efficiently modify the original generative model learning algorithm in a black box manner, that output generative models with strong bounds on the probability of sampling protected content. Furthermore, we provide promising experiments for both language (transformers) and image (diffusion) generative models, showing minimal degradation in output quality while ensuring strong protections against sampling protected content.
Gradient-based Wang-Landau Algorithm: A Novel Sampler for Output Distribution of Neural Networks over the Input Space
Feb 21, 2023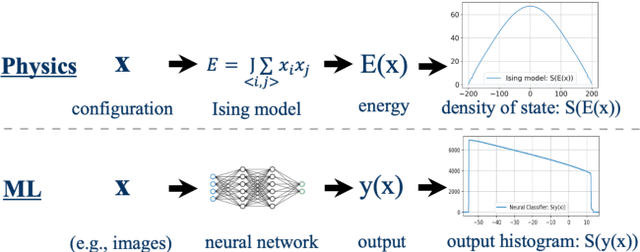
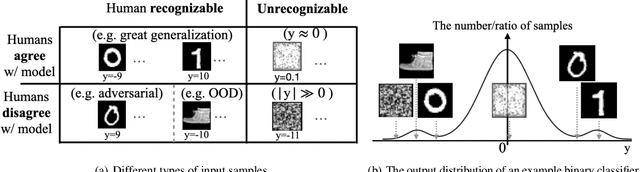
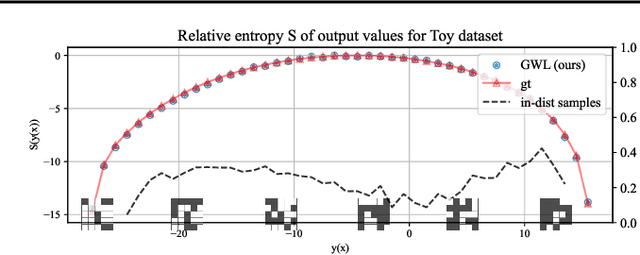
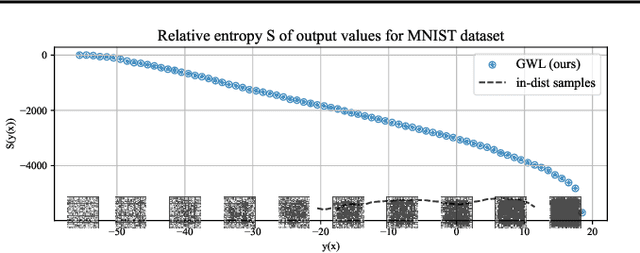
The output distribution of a neural network (NN) over the entire input space captures the complete input-output mapping relationship, offering insights toward a more comprehensive NN understanding. Exhaustive enumeration or traditional Monte Carlo methods for the entire input space can exhibit impractical sampling time, especially for high-dimensional inputs. To make such difficult sampling computationally feasible, in this paper, we propose a novel Gradient-based Wang-Landau (GWL) sampler. We first draw the connection between the output distribution of a NN and the density of states (DOS) of a physical system. Then, we renovate the classic sampler for the DOS problem, the Wang-Landau algorithm, by replacing its random proposals with gradient-based Monte Carlo proposals. This way, our GWL sampler investigates the under-explored subsets of the input space much more efficiently. Extensive experiments have verified the accuracy of the output distribution generated by GWL and also showcased several interesting findings - for example, in a binary image classification task, both CNN and ResNet mapped the majority of human unrecognizable images to very negative logit values.
Fact or Artifact? Revise Layer-wise Relevance Propagation on various ANN Architectures
Feb 23, 2023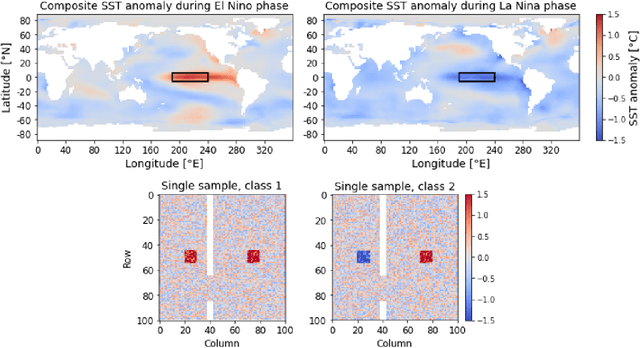
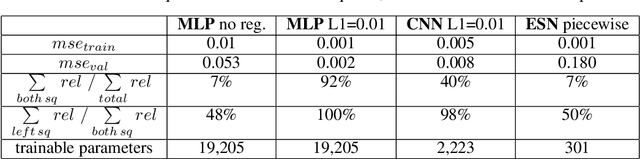
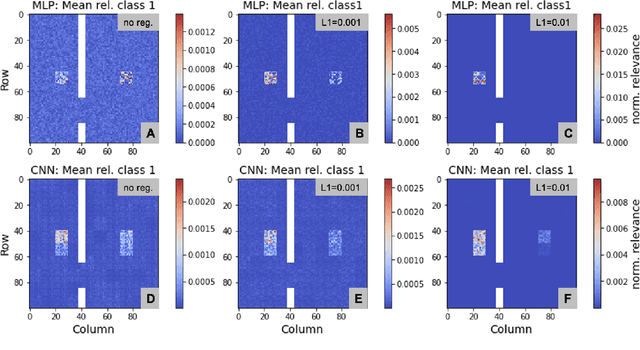
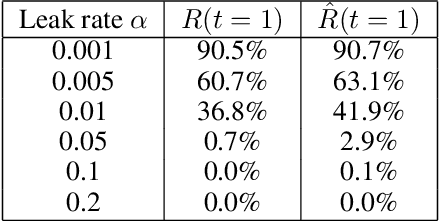
Layer-wise relevance propagation (LRP) is a widely used and powerful technique to reveal insights into various artificial neural network (ANN) architectures. LRP is often used in the context of image classification. The aim is to understand, which parts of the input sample have highest relevance and hence most influence on the model prediction. Relevance can be traced back through the network to attribute a certain score to each input pixel. Relevance scores are then combined and displayed as heat maps and give humans an intuitive visual understanding of classification models. Opening the black box to understand the classification engine in great detail is essential for domain experts to gain trust in ANN models. However, there are pitfalls in terms of model-inherent artifacts included in the obtained relevance maps, that can easily be missed. But for a valid interpretation, these artifacts must not be ignored. Here, we apply and revise LRP on various ANN architectures trained as classifiers on geospatial and synthetic data. Depending on the network architecture, we show techniques to control model focus and give guidance to improve the quality of obtained relevance maps to separate facts from artifacts.
Out-of-Domain Robustness via Targeted Augmentations
Feb 23, 2023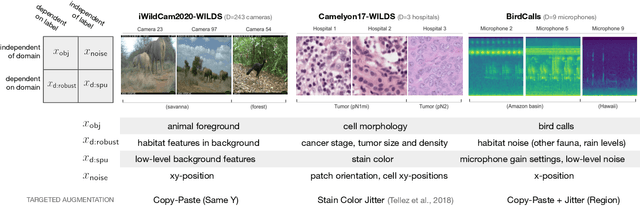

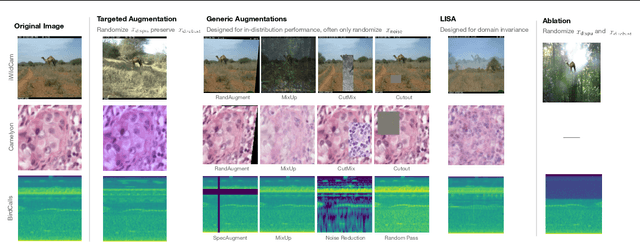
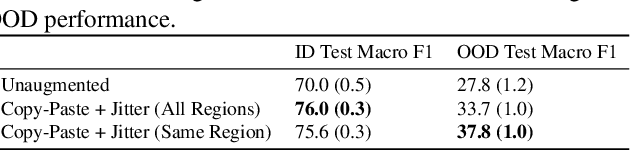
Models trained on one set of domains often suffer performance drops on unseen domains, e.g., when wildlife monitoring models are deployed in new camera locations. In this work, we study principles for designing data augmentations for out-of-domain (OOD) generalization. In particular, we focus on real-world scenarios in which some domain-dependent features are robust, i.e., some features that vary across domains are predictive OOD. For example, in the wildlife monitoring application above, image backgrounds vary across camera locations but indicate habitat type, which helps predict the species of photographed animals. Motivated by theoretical analysis on a linear setting, we propose targeted augmentations, which selectively randomize spurious domain-dependent features while preserving robust ones. We prove that targeted augmentations improve OOD performance, allowing models to generalize better with fewer domains. In contrast, existing approaches such as generic augmentations, which fail to randomize domain-dependent features, and domain-invariant augmentations, which randomize all domain-dependent features, both perform poorly OOD. In experiments on three real-world datasets, we show that targeted augmentations set new states-of-the-art for OOD performance by 3.2-15.2%.