 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Decomposing Disease Descriptions for Enhanced Pathology Detection: A Multi-Aspect Vision-Language Matching Framework
Mar 12, 2024
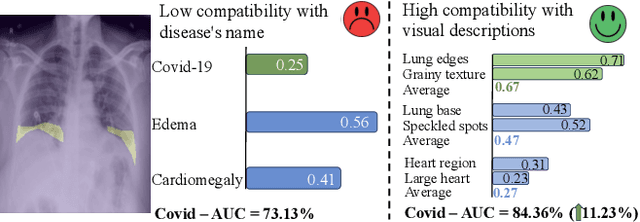
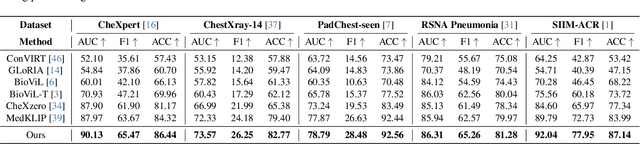

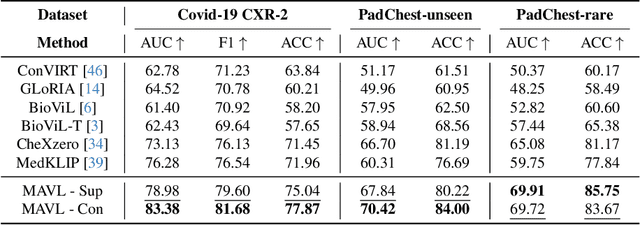
Medical vision language pre-training (VLP) has emerged as a frontier of research, enabling zero-shot pathological recognition by comparing the query image with the textual descriptions for each disease. Due to the complex semantics of biomedical texts, current methods struggle to align medical images with key pathological findings in unstructured reports. This leads to the misalignment with the target disease's textual representation. In this paper, we introduce a novel VLP framework designed to dissect disease descriptions into their fundamental aspects, leveraging prior knowledge about the visual manifestations of pathologies. This is achieved by consulting a large language model and medical experts. Integrating a Transformer module, our approach aligns an input image with the diverse elements of a disease, generating aspect-centric image representations. By consolidating the matches from each aspect, we improve the compatibility between an image and its associated disease. Additionally, capitalizing on the aspect-oriented representations, we present a dual-head Transformer tailored to process known and unknown diseases, optimizing the comprehensive detection efficacy. Conducting experiments on seven downstream datasets, ours outperforms recent methods by up to 8.07% and 11.23% in AUC scores for seen and novel categories, respectively. Our code is released at \href{https://github.com/HieuPhan33/MAVL}{https://github.com/HieuPhan33/MAVL}.
Quantifying the Resolution of a Template after Image Registration
Feb 27, 2024In many image processing applications (e.g. computational anatomy) a groupwise registration is performed on a sample of images and a template image is simultaneously generated. From the template alone it is in general unclear to which extent the registered images are still misaligned, which means that some regions of the template represent the structural features in the sample images less reliably than others. In a sense, the template exhibits a lower resolution there. Guided by characteristic examples of misaligned image features in one dimension, we develop a visual measure to quantify the resolution at each location of a template which is based on the observation that misalignments between the registered sample images are reduced by smoothing with the strength of the smoothing being related to the magnitude of the misalignment. Finally the resulting resolution measure is applied to example datasets in two and three dimensions. The corresponding code is publicly available on GitHub.
Cross-Modal Learning of Housing Quality in Amsterdam
Mar 13, 2024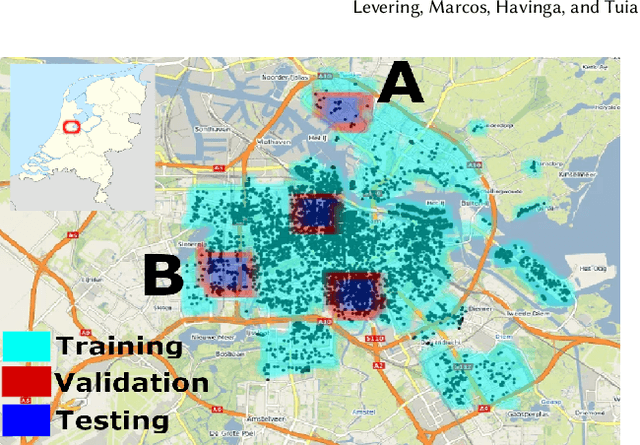
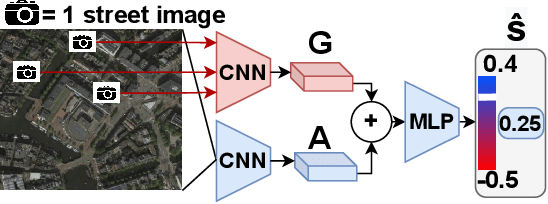

In our research we test data and models for the recognition of housing quality in the city of Amsterdam from ground-level and aerial imagery. For ground-level images we compare Google StreetView (GSV) to Flickr images. Our results show that GSV predicts the most accurate building quality scores, approximately 30% better than using only aerial images. However, we find that through careful filtering and by using the right pre-trained model, Flickr image features combined with aerial image features are able to halve the performance gap to GSV features from 30% to 15%. Our results indicate that there are viable alternatives to GSV for liveability factor prediction, which is encouraging as GSV images are more difficult to acquire and not always available.
Histo-Genomic Knowledge Distillation For Cancer Prognosis From Histopathology Whole Slide Images
Mar 18, 2024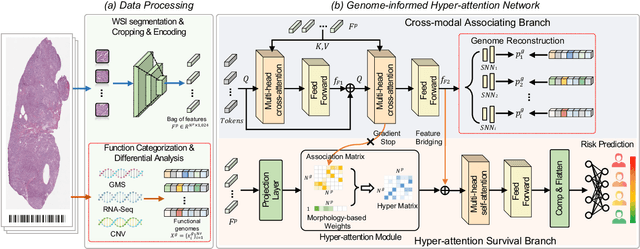
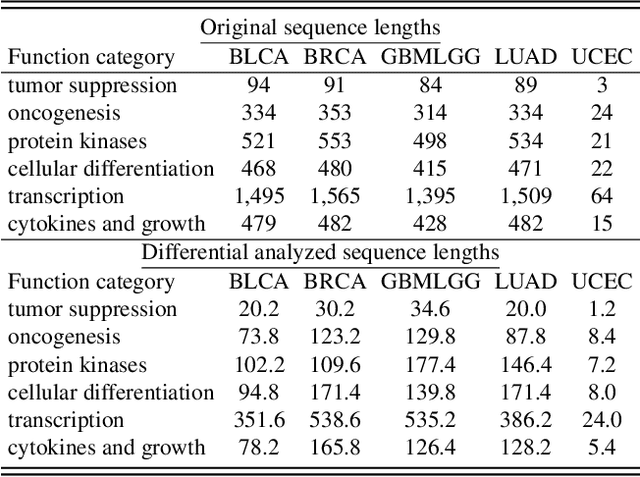
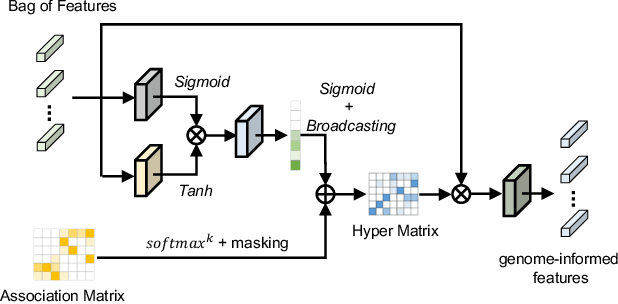
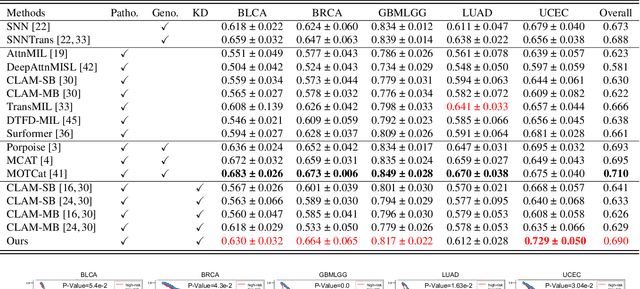
Histo-genomic multi-modal methods have recently emerged as a powerful paradigm, demonstrating significant potential for improving cancer prognosis. However, genome sequencing, unlike histopathology imaging, is still not widely accessible in underdeveloped regions, limiting the application of these multi-modal approaches in clinical settings. To address this, we propose a novel Genome-informed Hyper-Attention Network, termed G-HANet, which is capable of effectively distilling the histo-genomic knowledge during training to elevate uni-modal whole slide image (WSI)-based inference for the first time. Compared with traditional knowledge distillation methods (i.e., teacher-student architecture) in other tasks, our end-to-end model is superior in terms of training efficiency and learning cross-modal interactions. Specifically, the network comprises the cross-modal associating branch (CAB) and hyper-attention survival branch (HSB). Through the genomic data reconstruction from WSIs, CAB effectively distills the associations between functional genotypes and morphological phenotypes and offers insights into the gene expression profiles in the feature space. Subsequently, HSB leverages the distilled histo-genomic associations as well as the generated morphology-based weights to achieve the hyper-attention modeling of the patients from both histopathology and genomic perspectives to improve cancer prognosis. Extensive experiments are conducted on five TCGA benchmarking datasets and the results demonstrate that G-HANet significantly outperforms the state-of-the-art WSI-based methods and achieves competitive performance with genome-based and multi-modal methods. G-HANet is expected to be explored as a useful tool by the research community to address the current bottleneck of insufficient histo-genomic data pairing in the context of cancer prognosis and precision oncology.
VideoMV: Consistent Multi-View Generation Based on Large Video Generative Model
Mar 18, 2024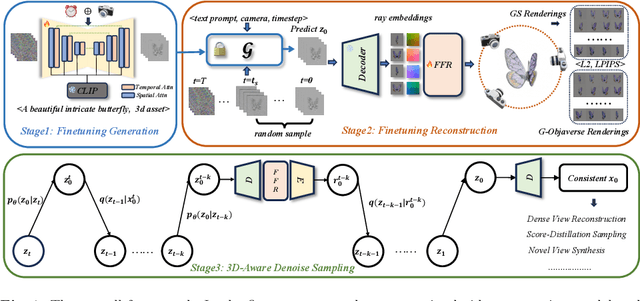
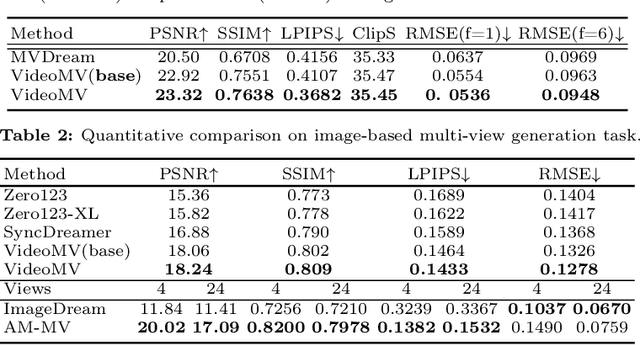


Generating multi-view images based on text or single-image prompts is a critical capability for the creation of 3D content. Two fundamental questions on this topic are what data we use for training and how to ensure multi-view consistency. This paper introduces a novel framework that makes fundamental contributions to both questions. Unlike leveraging images from 2D diffusion models for training, we propose a dense consistent multi-view generation model that is fine-tuned from off-the-shelf video generative models. Images from video generative models are more suitable for multi-view generation because the underlying network architecture that generates them employs a temporal module to enforce frame consistency. Moreover, the video data sets used to train these models are abundant and diverse, leading to a reduced train-finetuning domain gap. To enhance multi-view consistency, we introduce a 3D-Aware Denoising Sampling, which first employs a feed-forward reconstruction module to get an explicit global 3D model, and then adopts a sampling strategy that effectively involves images rendered from the global 3D model into the denoising sampling loop to improve the multi-view consistency of the final images. As a by-product, this module also provides a fast way to create 3D assets represented by 3D Gaussians within a few seconds. Our approach can generate 24 dense views and converges much faster in training than state-of-the-art approaches (4 GPU hours versus many thousand GPU hours) with comparable visual quality and consistency. By further fine-tuning, our approach outperforms existing state-of-the-art methods in both quantitative metrics and visual effects. Our project page is aigc3d.github.io/VideoMV.
Uncertainty-Calibrated Test-Time Model Adaptation without Forgetting
Mar 18, 2024
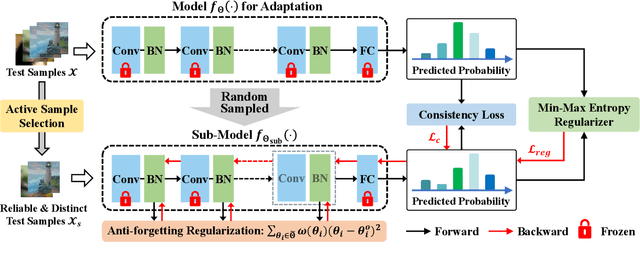
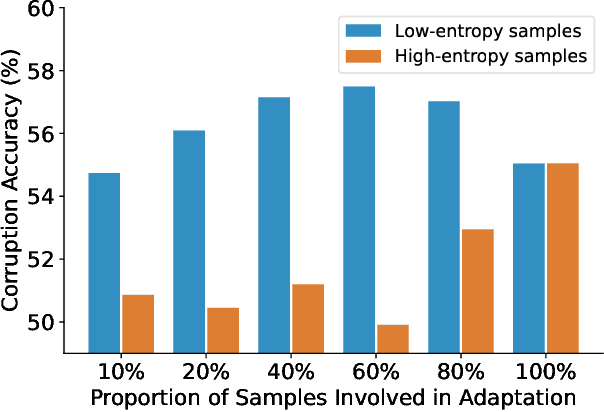
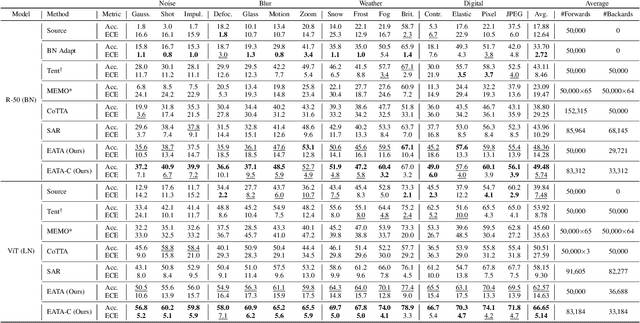
Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and test data by adapting a given model w.r.t. any test sample. Although recent TTA has shown promising performance, we still face two key challenges: 1) prior methods perform backpropagation for each test sample, resulting in unbearable optimization costs to many applications; 2) while existing TTA can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as forgetting). To this end, we have proposed an Efficient Anti-Forgetting Test-Time Adaptation (EATA) method which develops an active sample selection criterion to identify reliable and non-redundant samples for test-time entropy minimization. To alleviate forgetting, EATA introduces a Fisher regularizer estimated from test samples to constrain important model parameters from drastic changes. However, in EATA, the adopted entropy loss consistently assigns higher confidence to predictions even for samples that are underlying uncertain, leading to overconfident predictions. To tackle this, we further propose EATA with Calibration (EATA-C) to separately exploit the reducible model uncertainty and the inherent data uncertainty for calibrated TTA. Specifically, we measure the model uncertainty by the divergence between predictions from the full network and its sub-networks, on which we propose a divergence loss to encourage consistent predictions instead of overconfident ones. To further recalibrate prediction confidence, we utilize the disagreement among predicted labels as an indicator of the data uncertainty, and then devise a min-max entropy regularizer to selectively increase and decrease prediction confidence for different samples. Experiments on image classification and semantic segmentation verify the effectiveness of our methods.
Spatiotemporal Representation Learning for Short and Long Medical Image Time Series
Mar 12, 2024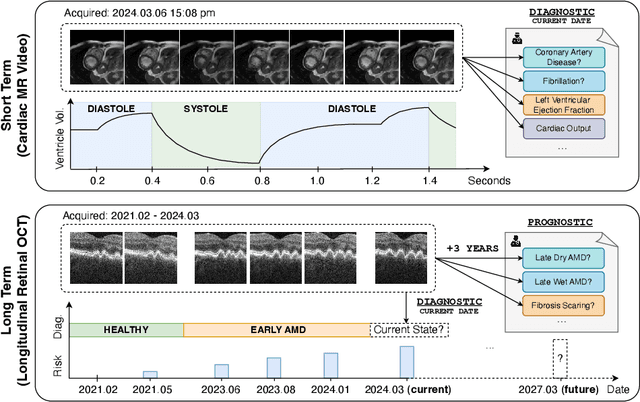
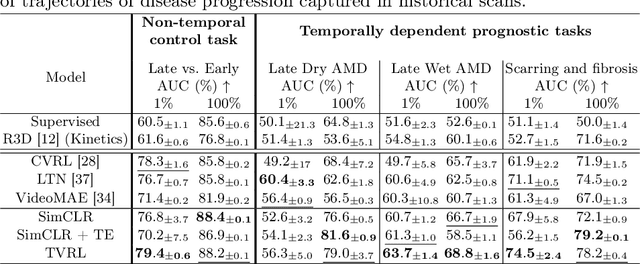
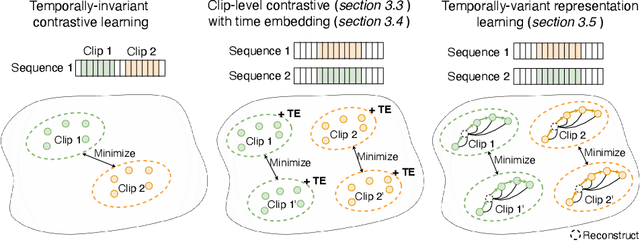
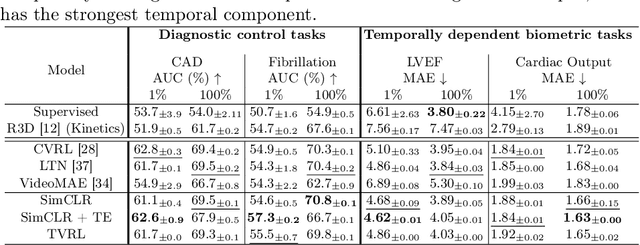
Analyzing temporal developments is crucial for the accurate prognosis of many medical conditions. Temporal changes that occur over short time scales are key to assessing the health of physiological functions, such as the cardiac cycle. Moreover, tracking longer term developments that occur over months or years in evolving processes, such as age-related macular degeneration (AMD), is essential for accurate prognosis. Despite the importance of both short and long term analysis to clinical decision making, they remain understudied in medical deep learning. State of the art methods for spatiotemporal representation learning, developed for short natural videos, prioritize the detection of temporal constants rather than temporal developments. Moreover, they do not account for varying time intervals between acquisitions, which are essential for contextualizing observed changes. To address these issues, we propose two approaches. First, we combine clip-level contrastive learning with a novel temporal embedding to adapt to irregular time series. Second, we propose masking and predicting latent frame representations of the temporal sequence. Our two approaches outperform all prior methods on temporally-dependent tasks including cardiac output estimation and three prognostic AMD tasks. Overall, this enables the automated analysis of temporal patterns which are typically overlooked in applications of deep learning to medicine.
Stitching Gaps: Fusing Situated Perceptual Knowledge with Vision Transformers for High-Level Image Classification
Feb 29, 2024The increasing demand for automatic high-level image understanding, particularly in detecting abstract concepts (AC) within images, underscores the necessity for innovative and more interpretable approaches. These approaches need to harmonize traditional deep vision methods with the nuanced, context-dependent knowledge humans employ to interpret images at intricate semantic levels. In this work, we leverage situated perceptual knowledge of cultural images to enhance performance and interpretability in AC image classification. We automatically extract perceptual semantic units from images, which we then model and integrate into the ARTstract Knowledge Graph (AKG). This resource captures situated perceptual semantics gleaned from over 14,000 cultural images labeled with ACs. Additionally, we enhance the AKG with high-level linguistic frames. We compute KG embeddings and experiment with relative representations and hybrid approaches that fuse these embeddings with visual transformer embeddings. Finally, for interpretability, we conduct posthoc qualitative analyses by examining model similarities with training instances. Our results show that our hybrid KGE-ViT methods outperform existing techniques in AC image classification. The posthoc interpretability analyses reveal the visual transformer's proficiency in capturing pixel-level visual attributes, contrasting with our method's efficacy in representing more abstract and semantic scene elements. We demonstrate the synergy and complementarity between KGE embeddings' situated perceptual knowledge and deep visual model's sensory-perceptual understanding for AC image classification. This work suggests a strong potential of neuro-symbolic methods for knowledge integration and robust image representation for use in downstream intricate visual comprehension tasks. All the materials and code are available online.
Classes Are Not Equal: An Empirical Study on Image Recognition Fairness
Feb 28, 2024In this paper, we present an empirical study on image recognition fairness, i.e., extreme class accuracy disparity on balanced data like ImageNet. We experimentally demonstrate that classes are not equal and the fairness issue is prevalent for image classification models across various datasets, network architectures, and model capacities. Moreover, several intriguing properties of fairness are identified. First, the unfairness lies in problematic representation rather than classifier bias. Second, with the proposed concept of Model Prediction Bias, we investigate the origins of problematic representation during optimization. Our findings reveal that models tend to exhibit greater prediction biases for classes that are more challenging to recognize. It means that more other classes will be confused with harder classes. Then the False Positives (FPs) will dominate the learning in optimization, thus leading to their poor accuracy. Further, we conclude that data augmentation and representation learning algorithms improve overall performance by promoting fairness to some degree in image classification.
TTA-Nav: Test-time Adaptive Reconstruction for Point-Goal Navigation under Visual Corruptions
Mar 14, 2024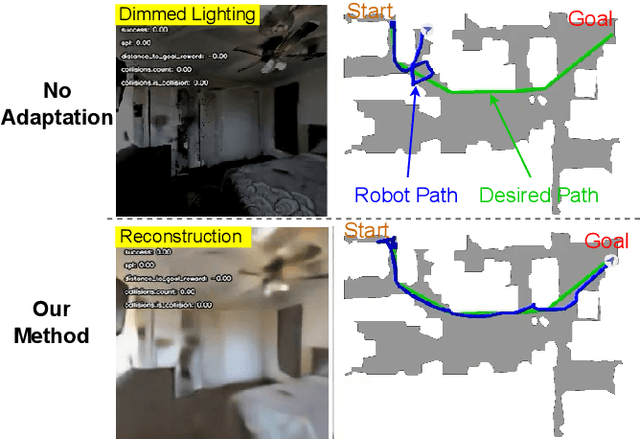
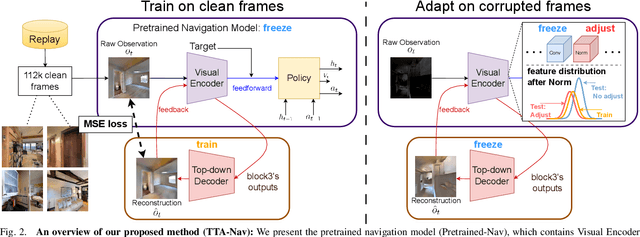


Robot navigation under visual corruption presents a formidable challenge. To address this, we propose a Test-time Adaptation (TTA) method, named as TTA-Nav, for point-goal navigation under visual corruptions. Our "plug-and-play" method incorporates a top-down decoder to a pre-trained navigation model. Firstly, the pre-trained navigation model gets a corrupted image and extracts features. Secondly, the top-down decoder produces the reconstruction given the high-level features extracted by the pre-trained model. Then, it feeds the reconstruction of a corrupted image back to the pre-trained model. Finally, the pre-trained model does forward pass again to output action. Despite being trained solely on clean images, the top-down decoder can reconstruct cleaner images from corrupted ones without the need for gradient-based adaptation. The pre-trained navigation model with our top-down decoder significantly enhances navigation performance across almost all visual corruptions in our benchmarks. Our method improves the success rate of point-goal navigation from the state-of-the-art result of 46% to 94% on the most severe corruption. This suggests its potential for broader application in robotic visual navigation. Project page: https://sites.google.com/view/tta-nav