 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Are Diffusion Models Vulnerable to Membership Inference Attacks?
Feb 02, 2023
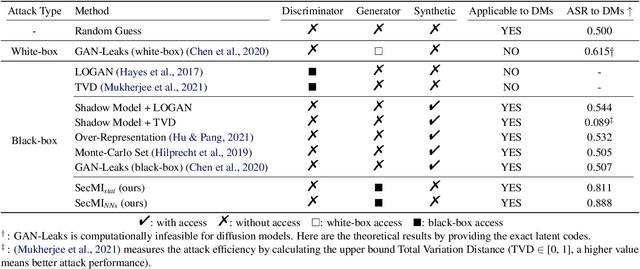
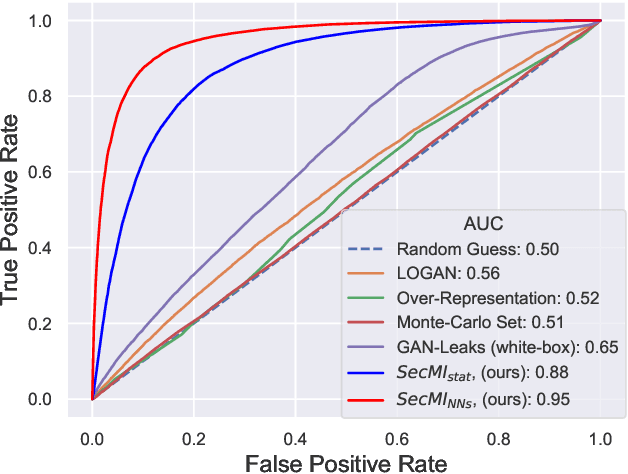
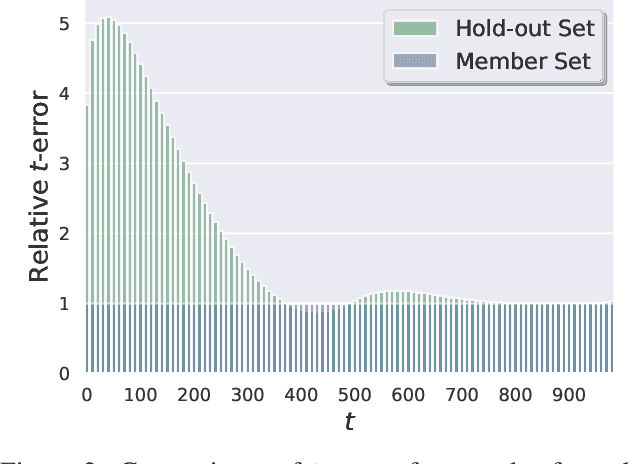
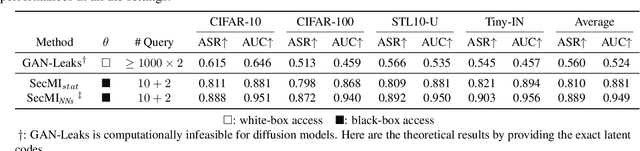
Diffusion-based generative models have shown great potential for image synthesis, but there is a lack of research on the security and privacy risks they may pose. In this paper, we investigate the vulnerability of diffusion models to Membership Inference Attacks (MIAs), a common privacy concern. Our results indicate that existing MIAs designed for GANs or VAE are largely ineffective on diffusion models, either due to inapplicable scenarios (e.g., requiring the discriminator of GANs) or inappropriate assumptions (e.g., closer distances between synthetic images and member images). To address this gap, we propose Step-wise Error Comparing Membership Inference (SecMI), a black-box MIA that infers memberships by assessing the matching of forward process posterior estimation at each timestep. SecMI follows the common overfitting assumption in MIA where member samples normally have smaller estimation errors, compared with hold-out samples. We consider both the standard diffusion models, e.g., DDPM, and the text-to-image diffusion models, e.g., Stable Diffusion. Experimental results demonstrate that our methods precisely infer the membership with high confidence on both of the two scenarios across six different datasets
Exploring Invariant Representation for Visible-Infrared Person Re-Identification
Feb 02, 2023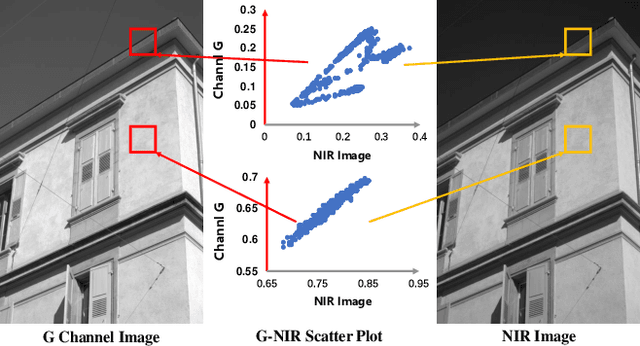

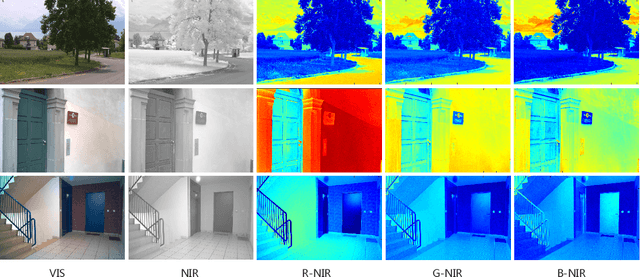

Cross-spectral person re-identification, which aims to associate identities to pedestrians across different spectra, faces a main challenge of the modality discrepancy. In this paper, we address the problem from both image-level and feature-level in an end-to-end hybrid learning framework named robust feature mining network (RFM). In particular, we observe that the reflective intensity of the same surface in photos shot in different wavelengths could be transformed using a linear model. Besides, we show the variable linear factor across the different surfaces is the main culprit which initiates the modality discrepancy. We integrate such a reflection observation into an image-level data augmentation by proposing the linear transformation generator (LTG). Moreover, at the feature level, we introduce a cross-center loss to explore a more compact intra-class distribution and modality-aware spatial attention to take advantage of textured regions more efficiently. Experiment results on two standard cross-spectral person re-identification datasets, i.e., RegDB and SYSU-MM01, have demonstrated state-of-the-art performance.
STB-VMM: Swin Transformer Based Video Motion Magnification
Feb 20, 2023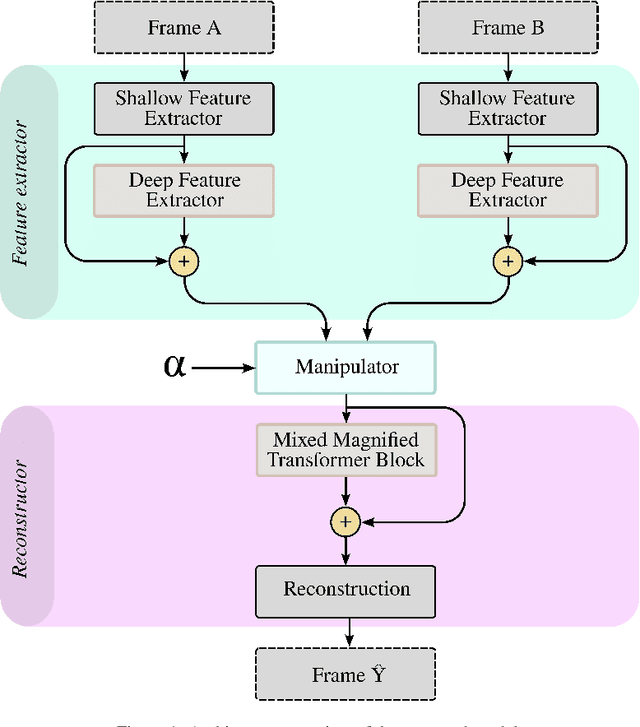
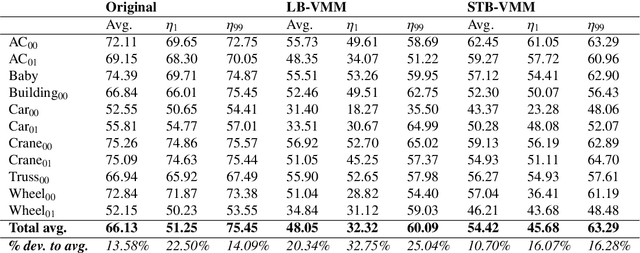
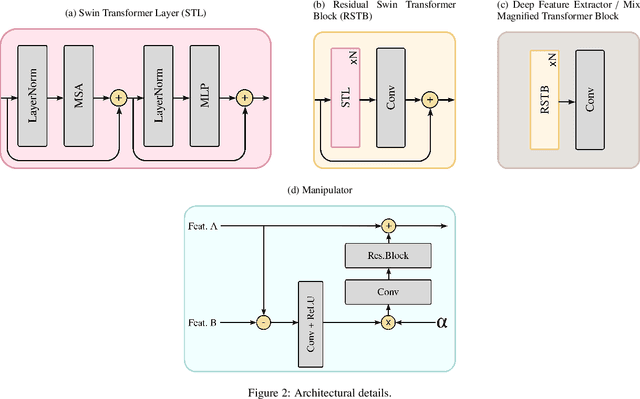
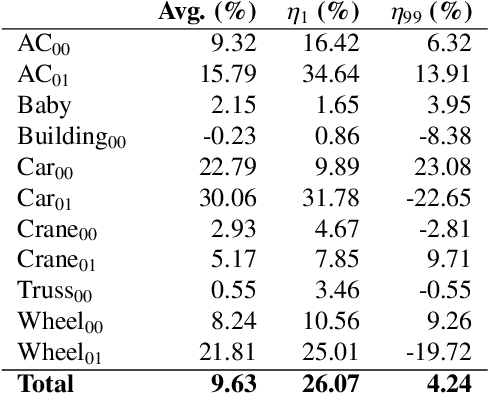
The goal of video motion magnification techniques is to magnify small motions in a video to reveal previously invisible or unseen movement. Its uses extend from bio-medical applications and deep fake detection to structural modal analysis and predictive maintenance. However, discerning small motion from noise is a complex task, especially when attempting to magnify very subtle often sub-pixel movement. As a result, motion magnification techniques generally suffer from noisy and blurry outputs. This work presents a new state-of-the-art model based on the Swin Transformer, which offers better tolerance to noisy inputs as well as higher-quality outputs that exhibit less noise, blurriness and artifacts than prior-art. Improvements in output image quality will enable more precise measurements for any application reliant on magnified video sequences, and may enable further development of video motion magnification techniques in new technical fields.
Multi-domain stain normalization for digital pathology: A cycle-consistent adversarial network for whole slide images
Jan 23, 2023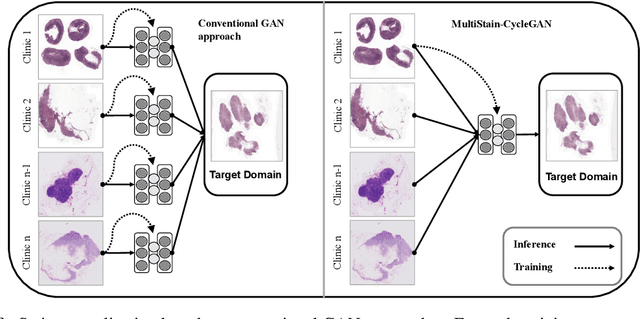
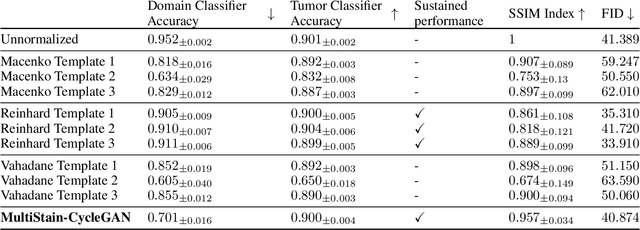
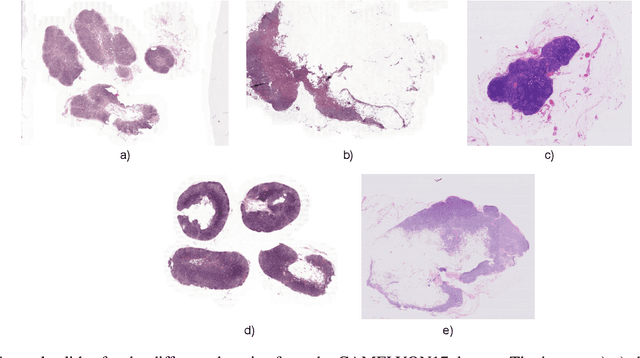
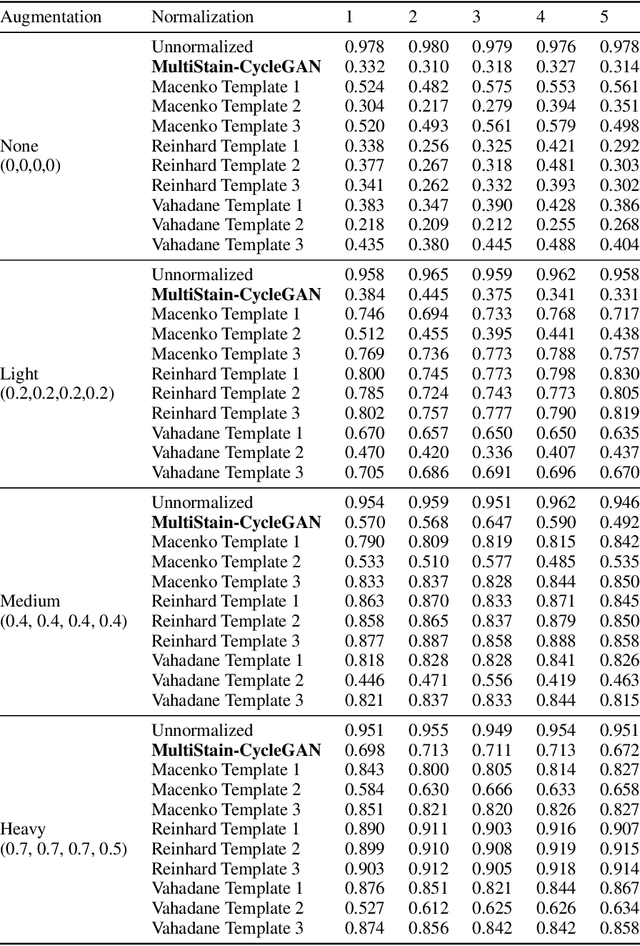
The variation in histologic staining between different medical centers is one of the most profound challenges in the field of computer-aided diagnosis. The appearance disparity of pathological whole slide images causes algorithms to become less reliable, which in turn impedes the wide-spread applicability of downstream tasks like cancer diagnosis. Furthermore, different stainings lead to biases in the training which in case of domain shifts negatively affect the test performance. Therefore, in this paper we propose MultiStain-CycleGAN, a multi-domain approach to stain normalization based on CycleGAN. Our modifications to CycleGAN allow us to normalize images of different origins without retraining or using different models. We perform an extensive evaluation of our method using various metrics and compare it to commonly used methods that are multi-domain capable. First, we evaluate how well our method fools a domain classifier that tries to assign a medical center to an image. Then, we test our normalization on the tumor classification performance of a downstream classifier. Furthermore, we evaluate the image quality of the normalized images using the Structural similarity index and the ability to reduce the domain shift using the Fr\'echet inception distance. We show that our method proves to be multi-domain capable, provides the highest image quality among the compared methods, and can most reliably fool the domain classifier while keeping the tumor classifier performance high. By reducing the domain influence, biases in the data can be removed on the one hand and the origin of the whole slide image can be disguised on the other, thus enhancing patient data privacy.
HST: Hierarchical Swin Transformer for Compressed Image Super-resolution
Aug 21, 2022

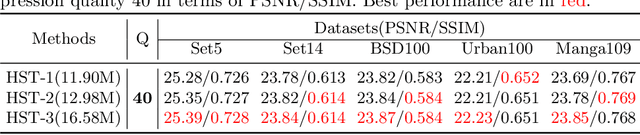
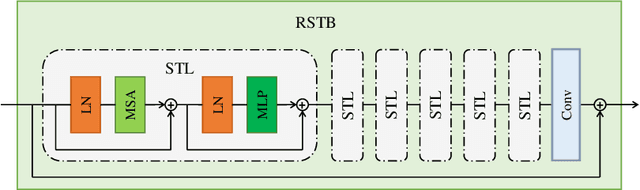
Compressed Image Super-resolution has achieved great attention in recent years, where images are degraded with compression artifacts and low-resolution artifacts. Since the complex hybrid distortions, it is hard to restore the distorted image with the simple cooperation of super-resolution and compression artifacts removing. In this paper, we take a step forward to propose the Hierarchical Swin Transformer (HST) network to restore the low-resolution compressed image, which jointly captures the hierarchical feature representations and enhances each-scale representation with Swin transformer, respectively. Moreover, we find that the pretraining with Super-resolution (SR) task is vital in compressed image super-resolution. To explore the effects of different SR pretraining, we take the commonly-used SR tasks (e.g., bicubic and different real super-resolution simulations) as our pretraining tasks, and reveal that SR plays an irreplaceable role in the compressed image super-resolution. With the cooperation of HST and pre-training, our HST achieves the fifth place in AIM 2022 challenge on the low-quality compressed image super-resolution track, with the PSNR of 23.51dB. Extensive experiments and ablation studies have validated the effectiveness of our proposed methods.
Intrinsic and extrinsic deep learning on manifolds
Feb 16, 2023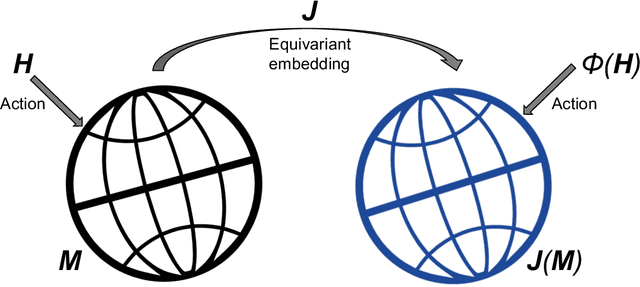
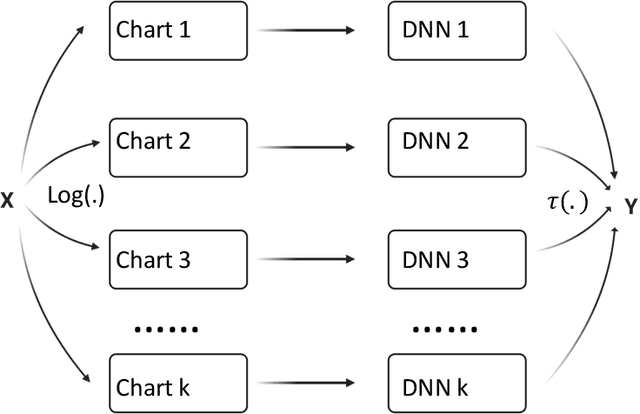

We propose extrinsic and intrinsic deep neural network architectures as general frameworks for deep learning on manifolds. Specifically, extrinsic deep neural networks (eDNNs) preserve geometric features on manifolds by utilizing an equivariant embedding from the manifold to its image in the Euclidean space. Moreover, intrinsic deep neural networks (iDNNs) incorporate the underlying intrinsic geometry of manifolds via exponential and log maps with respect to a Riemannian structure. Consequently, we prove that the empirical risk of the empirical risk minimizers (ERM) of eDNNs and iDNNs converge in optimal rates. Overall, The eDNNs framework is simple and easy to compute, while the iDNNs framework is accurate and fast converging. To demonstrate the utilities of our framework, various simulation studies, and real data analyses are presented with eDNNs and iDNNs.
To Make Yourself Invisible with Adversarial Semantic Contours
Mar 01, 2023
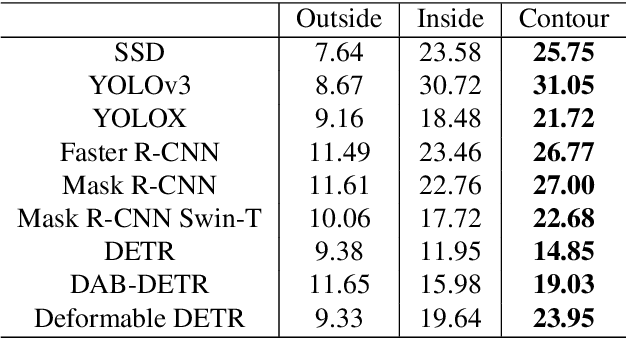

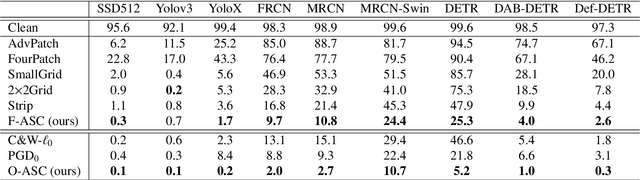
Modern object detectors are vulnerable to adversarial examples, which may bring risks to real-world applications. The sparse attack is an important task which, compared with the popular adversarial perturbation on the whole image, needs to select the potential pixels that is generally regularized by an $\ell_0$-norm constraint, and simultaneously optimize the corresponding texture. The non-differentiability of $\ell_0$ norm brings challenges and many works on attacking object detection adopted manually-designed patterns to address them, which are meaningless and independent of objects, and therefore lead to relatively poor attack performance. In this paper, we propose Adversarial Semantic Contour (ASC), an MAP estimate of a Bayesian formulation of sparse attack with a deceived prior of object contour. The object contour prior effectively reduces the search space of pixel selection and improves the attack by introducing more semantic bias. Extensive experiments demonstrate that ASC can corrupt the prediction of 9 modern detectors with different architectures (\e.g., one-stage, two-stage and Transformer) by modifying fewer than 5\% of the pixels of the object area in COCO in white-box scenario and around 10\% of those in black-box scenario. We further extend the attack to datasets for autonomous driving systems to verify the effectiveness. We conclude with cautions about contour being the common weakness of object detectors with various architecture and the care needed in applying them in safety-sensitive scenarios.
* 11 pages, 7 figures, published in Computer Vision and Image Understanding in 2023
GOLLIC: Learning Global Context beyond Patches for Lossless High-Resolution Image Compression
Oct 07, 2022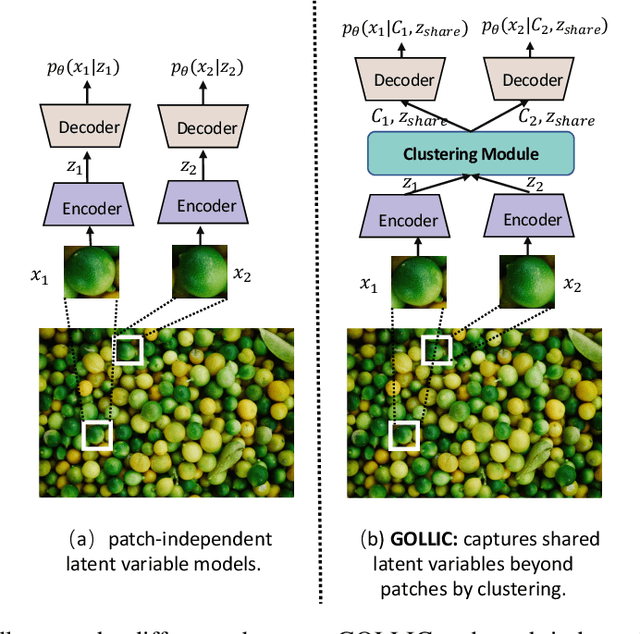
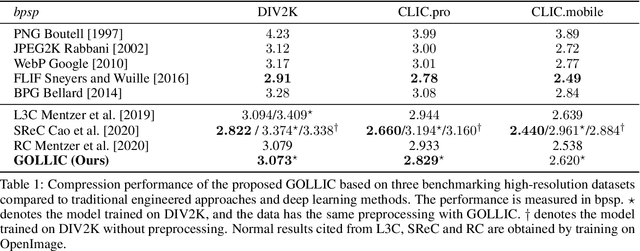
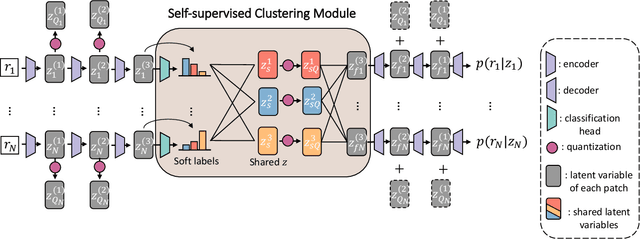

Neural-network-based approaches recently emerged in the field of data compression and have already led to significant progress in image compression, especially in achieving a higher compression ratio. In the lossless image compression scenario, however, existing methods often struggle to learn a probability model of full-size high-resolution images due to the limitation of the computation source. The current strategy is to crop high-resolution images into multiple non-overlapping patches and process them independently. This strategy ignores long-term dependencies beyond patches, thus limiting modeling performance. To address this problem, we propose a hierarchical latent variable model with a global context to capture the long-term dependencies of high-resolution images. Besides the latent variable unique to each patch, we introduce shared latent variables between patches to construct the global context. The shared latent variables are extracted by a self-supervised clustering module inside the model's encoder. This clustering module assigns each patch the confidence that it belongs to any cluster. Later, shared latent variables are learned according to latent variables of patches and their confidence, which reflects the similarity of patches in the same cluster and benefits the global context modeling. Experimental results show that our global context model improves compression ratio compared to the engineered codecs and deep learning models on three benchmark high-resolution image datasets, DIV2K, CLIC.pro, and CLIC.mobile.
Self Correspondence Distillation for End-to-End Weakly-Supervised Semantic Segmentation
Feb 27, 2023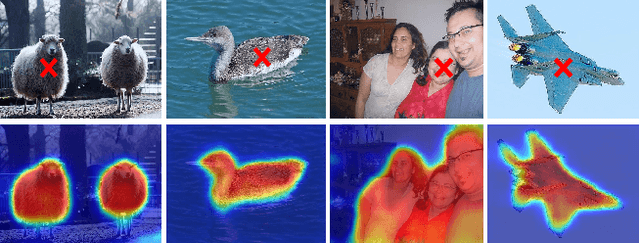
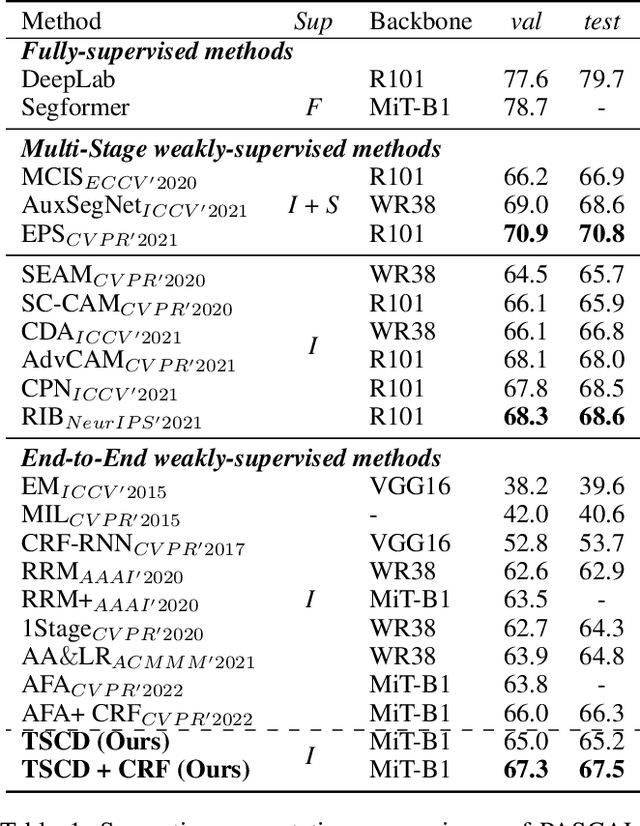
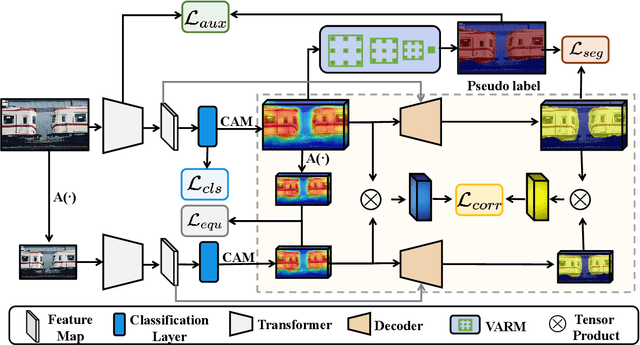
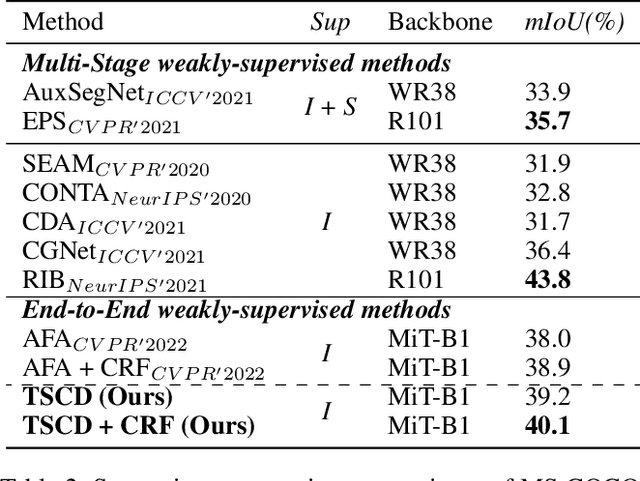
Efficiently training accurate deep models for weakly supervised semantic segmentation (WSSS) with image-level labels is challenging and important. Recently, end-to-end WSSS methods have become the focus of research due to their high training efficiency. However, current methods suffer from insufficient extraction of comprehensive semantic information, resulting in low-quality pseudo-labels and sub-optimal solutions for end-to-end WSSS. To this end, we propose a simple and novel Self Correspondence Distillation (SCD) method to refine pseudo-labels without introducing external supervision. Our SCD enables the network to utilize feature correspondence derived from itself as a distillation target, which can enhance the network's feature learning process by complementing semantic information. In addition, to further improve the segmentation accuracy, we design a Variation-aware Refine Module to enhance the local consistency of pseudo-labels by computing pixel-level variation. Finally, we present an efficient end-to-end Transformer-based framework (TSCD) via SCD and Variation-aware Refine Module for the accurate WSSS task. Extensive experiments on the PASCAL VOC 2012 and MS COCO 2014 datasets demonstrate that our method significantly outperforms other state-of-the-art methods. Our code is available at {https://github.com/Rongtao-Xu/RepresentationLearning/tree/main/SCD-AAAI2023}.
Multimodal Deep Learning to Differentiate Tumor Recurrence from Treatment Effect in Human Glioblastoma
Feb 27, 2023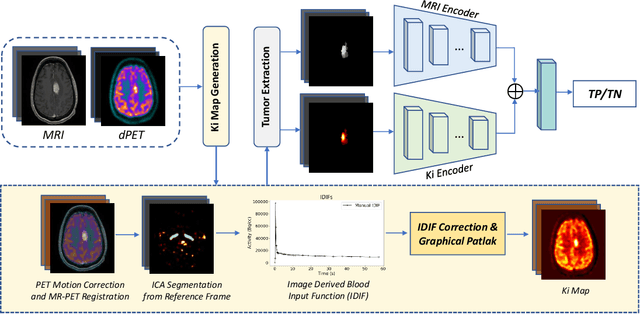
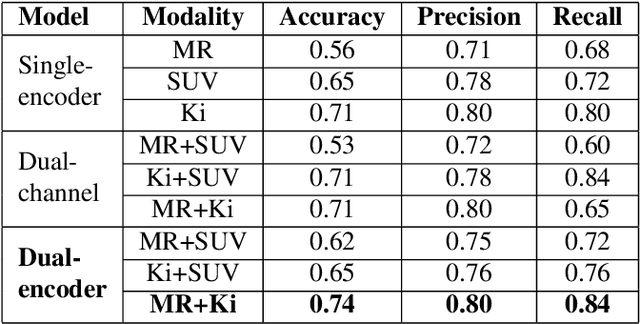

Differentiating tumor progression (TP) from treatment-related necrosis (TN) is critical for clinical management decisions in glioblastoma (GBM). Dynamic FDG PET (dPET), an advance from traditional static FDG PET, may prove advantageous in clinical staging. dPET includes novel methods of a model-corrected blood input function that accounts for partial volume averaging to compute parametric maps that reveal kinetic information. In a preliminary study, a convolution neural network (CNN) was trained to predict classification accuracy between TP and TN for $35$ brain tumors from $26$ subjects in the PET-MR image space. 3D parametric PET Ki (from dPET), traditional static PET standardized uptake values (SUV), and also the brain tumor MR voxels formed the input for the CNN. The average test accuracy across all leave-one-out cross-validation iterations adjusting for class weights was $0.56$ using only the MR, $0.65$ using only the SUV, and $0.71$ using only the Ki voxels. Combining SUV and MR voxels increased the test accuracy to $0.62$. On the other hand, MR and Ki voxels increased the test accuracy to $0.74$. Thus, dPET features alone or with MR features in deep learning models would enhance prediction accuracy in differentiating TP vs TN in GBM.