 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022


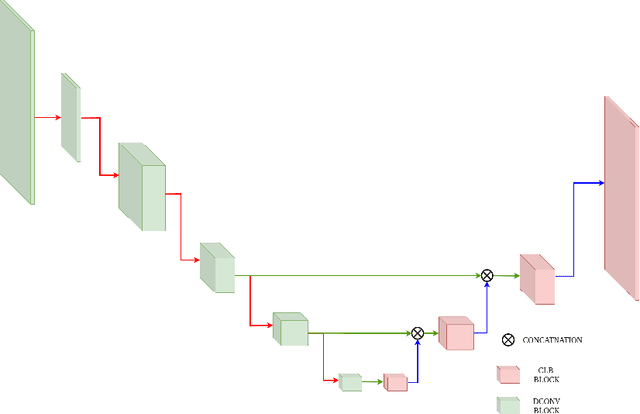
Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
Deep Metric Learning for Unsupervised Remote Sensing Change Detection
Mar 16, 2023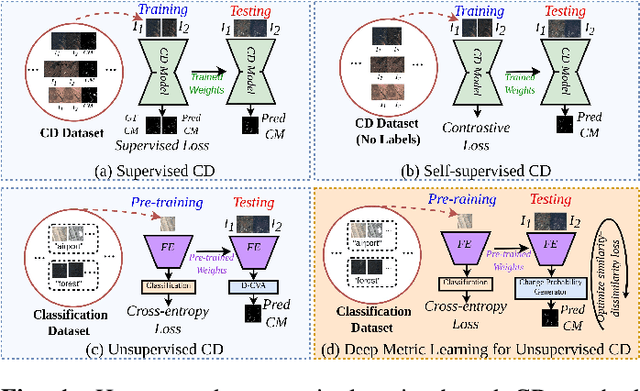
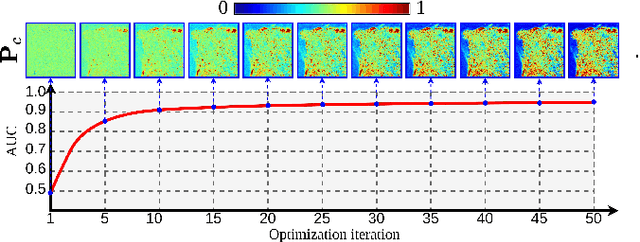
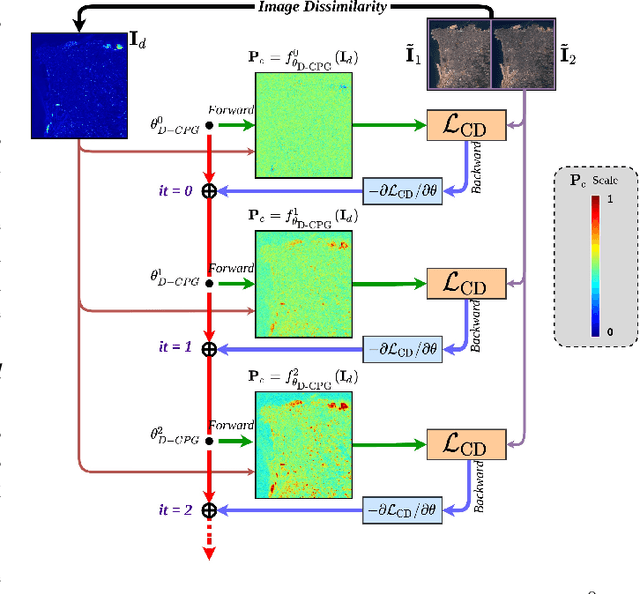
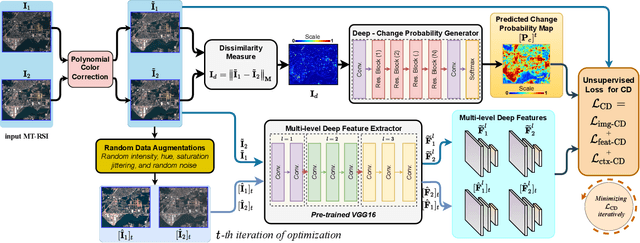
Remote Sensing Change Detection (RS-CD) aims to detect relevant changes from Multi-Temporal Remote Sensing Images (MT-RSIs), which aids in various RS applications such as land cover, land use, human development analysis, and disaster response. The performance of existing RS-CD methods is attributed to training on large annotated datasets. Furthermore, most of these models are less transferable in the sense that the trained model often performs very poorly when there is a domain gap between training and test datasets. This paper proposes an unsupervised CD method based on deep metric learning that can deal with both of these issues. Given an MT-RSI, the proposed method generates corresponding change probability map by iteratively optimizing an unsupervised CD loss without training it on a large dataset. Our unsupervised CD method consists of two interconnected deep networks, namely Deep-Change Probability Generator (D-CPG) and Deep-Feature Extractor (D-FE). The D-CPG is designed to predict change and no change probability maps for a given MT-RSI, while D-FE is used to extract deep features of MT-RSI that will be further used in the proposed unsupervised CD loss. We use transfer learning capability to initialize the parameters of D-FE. We iteratively optimize the parameters of D-CPG and D-FE for a given MT-RSI by minimizing the proposed unsupervised ``similarity-dissimilarity loss''. This loss is motivated by the principle of metric learning where we simultaneously maximize the distance between change pair-wise pixels while minimizing the distance between no-change pair-wise pixels in bi-temporal image domain and their deep feature domain. The experiments conducted on three CD datasets show that our unsupervised CD method achieves significant improvements over the state-of-the-art supervised and unsupervised CD methods. Code available at https://github.com/wgcban/Metric-CD
Estimating Head Motion from MR-Images
Feb 28, 2023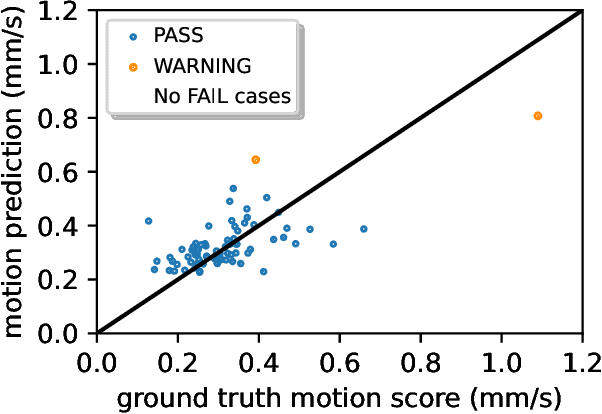
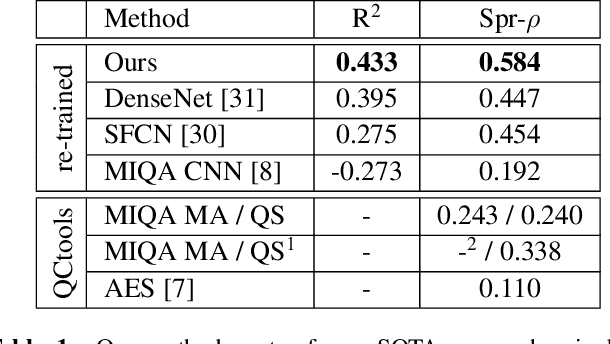
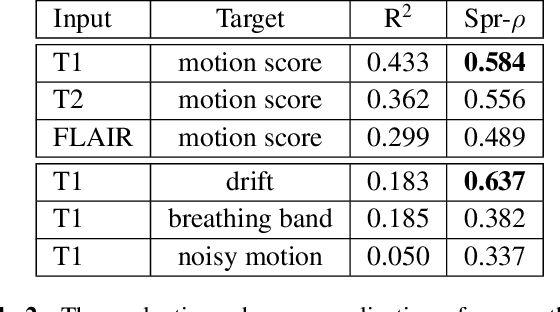
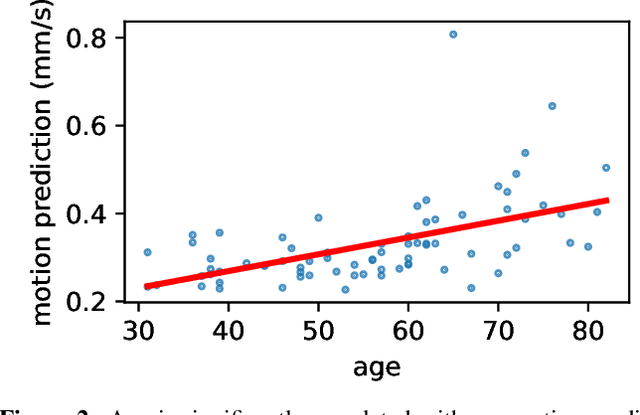
Head motion is an omnipresent confounder of magnetic resonance image (MRI) analyses as it systematically affects morphometric measurements, even when visual quality control is performed. In order to estimate subtle head motion, that remains undetected by experts, we introduce a deep learning method to predict in-scanner head motion directly from T1-weighted (T1w), T2-weighted (T2w) and fluid-attenuated inversion recovery (FLAIR) images using motion estimates from an in-scanner depth camera as ground truth. Since we work with data from compliant healthy participants of the Rhineland Study, head motion and resulting imaging artifacts are less prevalent than in most clinical cohorts and more difficult to detect. Our method demonstrates improved performance compared to state-of-the-art motion estimation methods and can quantify drift and respiration movement independently. Finally, on unseen data, our predictions preserve the known, significant correlation with age.
RoPAWS: Robust Semi-supervised Representation Learning from Uncurated Data
Feb 28, 2023
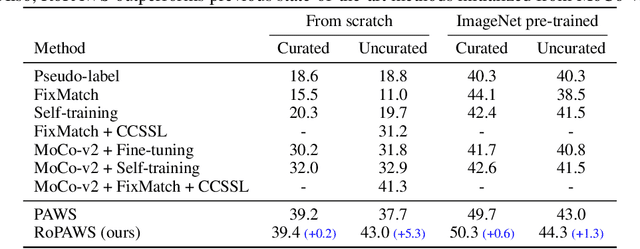
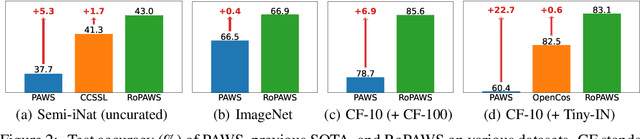

Semi-supervised learning aims to train a model using limited labels. State-of-the-art semi-supervised methods for image classification such as PAWS rely on self-supervised representations learned with large-scale unlabeled but curated data. However, PAWS is often less effective when using real-world unlabeled data that is uncurated, e.g., contains out-of-class data. We propose RoPAWS, a robust extension of PAWS that can work with real-world unlabeled data. We first reinterpret PAWS as a generative classifier that models densities using kernel density estimation. From this probabilistic perspective, we calibrate its prediction based on the densities of labeled and unlabeled data, which leads to a simple closed-form solution from the Bayes' rule. We demonstrate that RoPAWS significantly improves PAWS for uncurated Semi-iNat by +5.3% and curated ImageNet by +0.4%.
Learning to Estimate Single-View Volumetric Flow Motions without 3D Supervision
Feb 28, 2023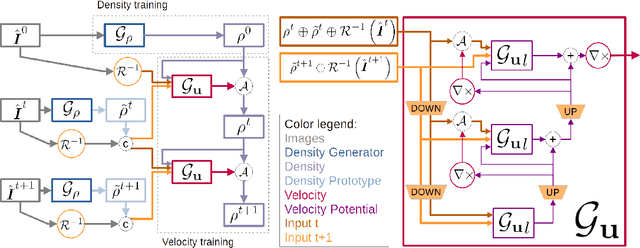
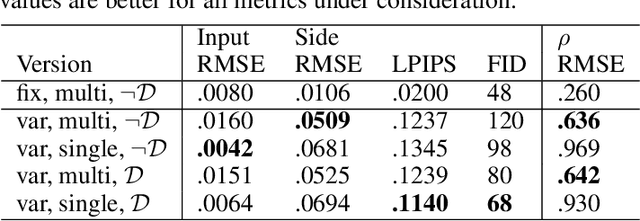

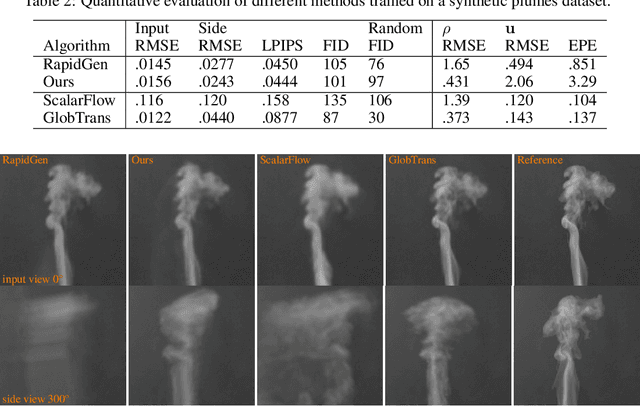
We address the challenging problem of jointly inferring the 3D flow and volumetric densities moving in a fluid from a monocular input video with a deep neural network. Despite the complexity of this task, we show that it is possible to train the corresponding networks without requiring any 3D ground truth for training. In the absence of ground truth data we can train our model with observations from real-world capture setups instead of relying on synthetic reconstructions. We make this unsupervised training approach possible by first generating an initial prototype volume which is then moved and transported over time without the need for volumetric supervision. Our approach relies purely on image-based losses, an adversarial discriminator network, and regularization. Our method can estimate long-term sequences in a stable manner, while achieving closely matching targets for inputs such as rising smoke plumes.
CUTS: A Fully Unsupervised Framework for Medical Image Segmentation
Sep 23, 2022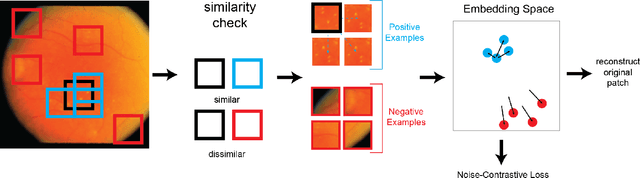

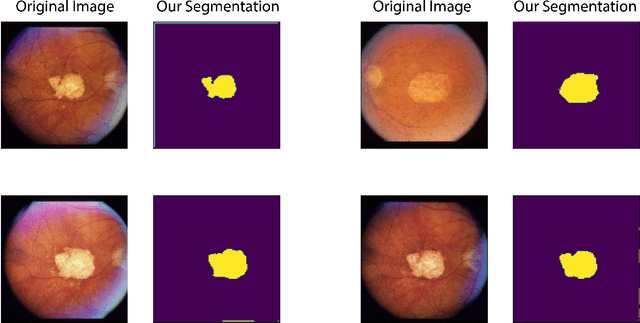
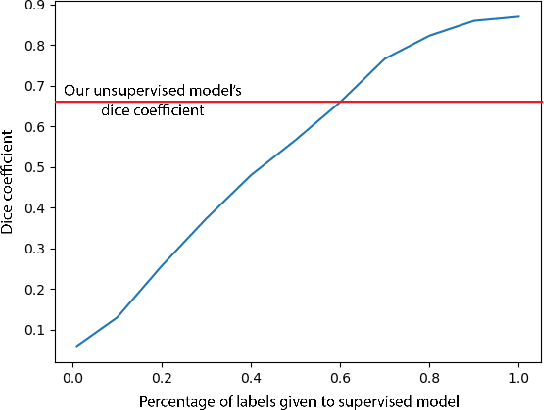
In this work we introduce CUTS (Contrastive and Unsupervised Training for Segmentation) the first fully unsupervised deep learning framework for medical image segmentation, facilitating the use of the vast majority of imaging data that is not labeled or annotated. Segmenting medical images into regions of interest is a critical task for facilitating both patient diagnoses and quantitative research. A major limiting factor in this segmentation is the lack of labeled data, as getting expert annotations for each new set of imaging data or task can be expensive, labor intensive, and inconsistent across annotators: thus, we utilize self-supervision based on pixel-centered patches from the images themselves. Our unsupervised approach is based on a training objective with both contrastive learning and autoencoding aspects. Previous contrastive learning approaches for medical image segmentation have focused on image-level contrastive training, rather than our intra-image patch-level approach or have used this as a pre-training task where the network needed further supervised training afterwards. By contrast, we build the first entirely unsupervised framework that operates at the pixel-centered-patch level. Specifically, we add novel augmentations, a patch reconstruction loss, and introduce a new pixel clustering and identification framework. Our model achieves improved results on several key medical imaging tasks, as verified by held-out expert annotations on the task of segmenting geographic atrophy (GA) regions of images of the retina.
Joint Learning of Blind Super-Resolution and Crack Segmentation for Realistic Degraded Images
Feb 24, 2023

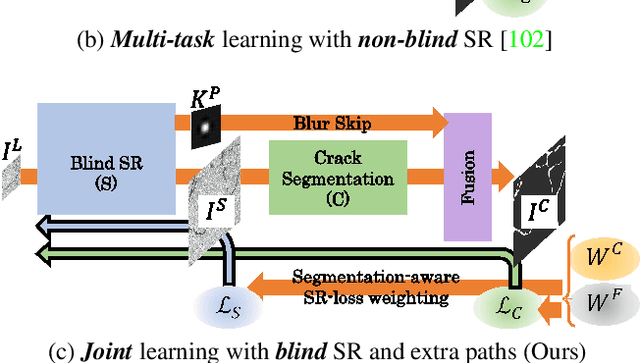
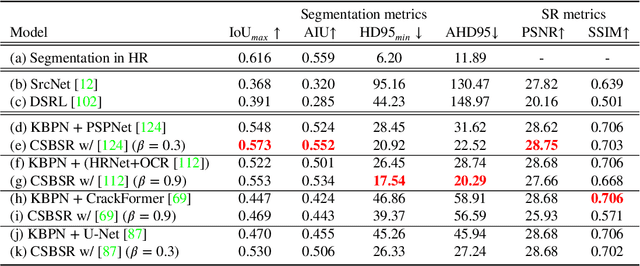
This paper proposes crack segmentation augmented by super resolution (SR) with deep neural networks. In the proposed method, a SR network is jointly trained with a binary segmentation network in an end-to-end manner. This joint learning allows the SR network to be optimized for improving segmentation results. For realistic scenarios, the SR network is extended from non-blind to blind for processing a low-resolution image degraded by unknown blurs. The joint network is improved by our proposed two extra paths that further encourage the mutual optimization between SR and segmentation. Comparative experiments with SoTA segmentation methods demonstrate the superiority of our joint learning, and various ablation studies prove the effects of our contributions.
Selective compression learning of latent representations for variable-rate image compression
Nov 08, 2022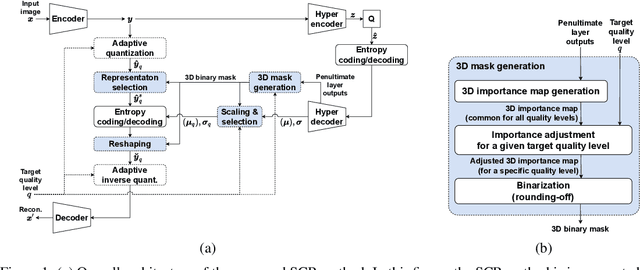
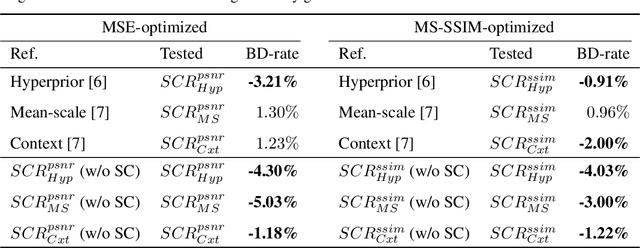

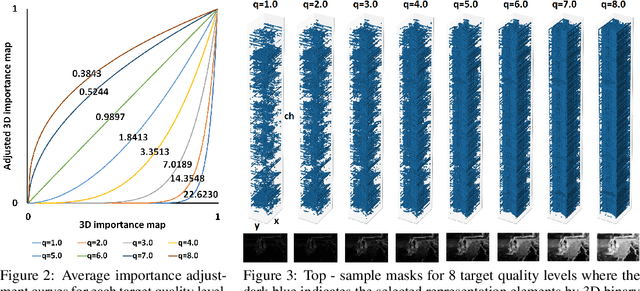
Recently, many neural network-based image compression methods have shown promising results superior to the existing tool-based conventional codecs. However, most of them are often trained as separate models for different target bit rates, thus increasing the model complexity. Therefore, several studies have been conducted for learned compression that supports variable rates with single models, but they require additional network modules, layers, or inputs that often lead to complexity overhead, or do not provide sufficient coding efficiency. In this paper, we firstly propose a selective compression method that partially encodes the latent representations in a fully generalized manner for deep learning-based variable-rate image compression. The proposed method adaptively determines essential representation elements for compression of different target quality levels. For this, we first generate a 3D importance map as the nature of input content to represent the underlying importance of the representation elements. The 3D importance map is then adjusted for different target quality levels using importance adjustment curves. The adjusted 3D importance map is finally converted into a 3D binary mask to determine the essential representation elements for compression. The proposed method can be easily integrated with the existing compression models with a negligible amount of overhead increase. Our method can also enable continuously variable-rate compression via simple interpolation of the importance adjustment curves among different quality levels. The extensive experimental results show that the proposed method can achieve comparable compression efficiency as those of the separately trained reference compression models and can reduce decoding time owing to the selective compression. The sample codes are publicly available at https://github.com/JooyoungLeeETRI/SCR.
Closed-loop Analysis of Vision-based Autonomous Systems: A Case Study
Feb 06, 2023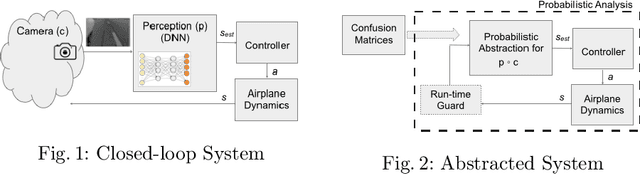

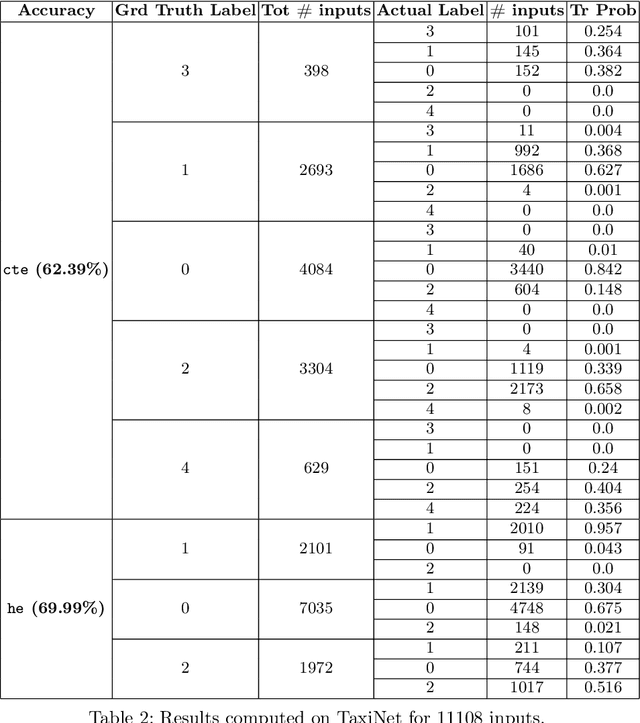
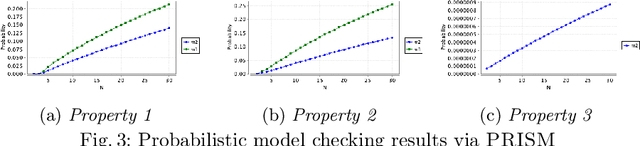
Deep neural networks (DNNs) are increasingly used in safety-critical autonomous systems as perception components processing high-dimensional image data. Formal analysis of these systems is particularly challenging due to the complexity of the perception DNNs, the sensors (cameras), and the environment conditions. We present a case study applying formal probabilistic analysis techniques to an experimental autonomous system that guides airplanes on taxiways using a perception DNN. We address the above challenges by replacing the camera and the network with a compact probabilistic abstraction built from the confusion matrices computed for the DNN on a representative image data set. We also show how to leverage local, DNN-specific analyses as run-time guards to increase the safety of the overall system. Our findings are applicable to other autonomous systems that use complex DNNs for perception.
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Jan 19, 2023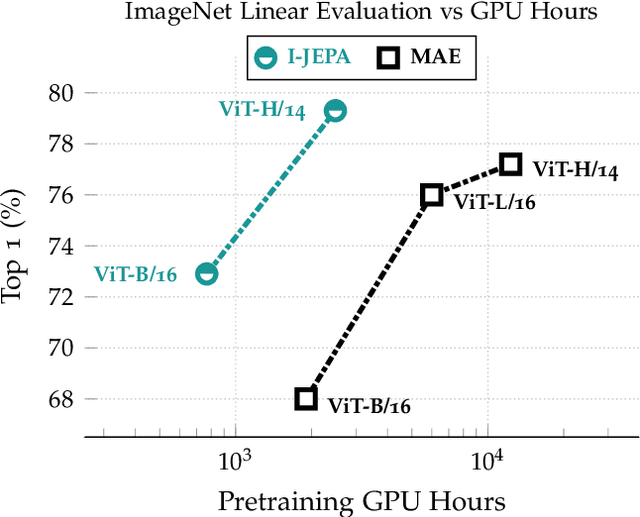


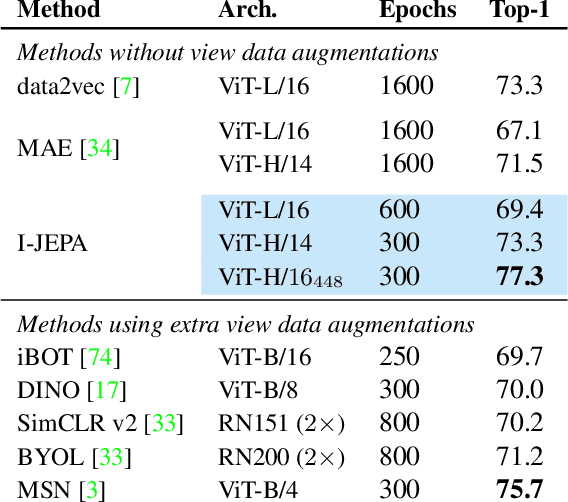
This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervised learning from images. The idea behind I-JEPA is simple: from a single context block, predict the representations of various target blocks in the same image. A core design choice to guide I-JEPA towards producing semantic representations is the masking strategy; specifically, it is crucial to (a) predict several target blocks in the image, (b) sample target blocks with sufficiently large scale (occupying 15%-20% of the image), and (c) use a sufficiently informative (spatially distributed) context block. Empirically, when combined with Vision Transformers, we find I-JEPA to be highly scalable. For instance, we train a ViT-Huge/16 on ImageNet using 32 A100 GPUs in under 38 hours to achieve strong downstream performance across a wide range of tasks requiring various levels of abstraction, from linear classification to object counting and depth prediction.