 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learned Distributed Image Compression with Multi-Scale Patch Matching in Feature Domai
Sep 06, 2022

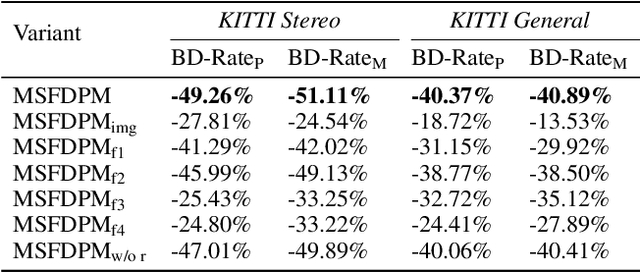
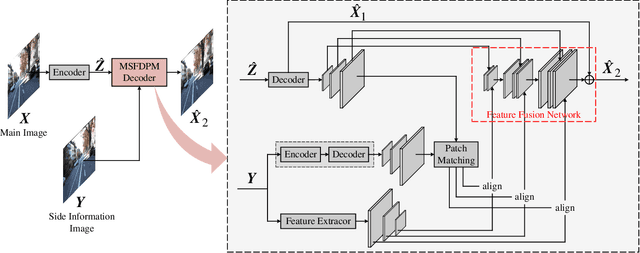

Beyond achieving higher compression efficiency over classical image compression codecs, deep image compression is expected to be improved with additional side information, e.g., another image from a different perspective of the same scene. To better utilize the side information under the distributed compression scenario, the existing method (Ayzik and Avidan 2020) only implements patch matching at the image domain to solve the parallax problem caused by the difference in viewing points. However, the patch matching at the image domain is not robust to the variance of scale, shape, and illumination caused by the different viewing angles, and can not make full use of the rich texture information of the side information image. To resolve this issue, we propose Multi-Scale Feature Domain Patch Matching (MSFDPM) to fully utilizes side information at the decoder of the distributed image compression model. Specifically, MSFDPM consists of a side information feature extractor, a multi-scale feature domain patch matching module, and a multi-scale feature fusion network. Furthermore, we reuse inter-patch correlation from the shallow layer to accelerate the patch matching of the deep layer. Finally, we nd that our patch matching in a multi-scale feature domain further improves compression rate by about 20% compared with the patch matching method at image domain (Ayzik and Avidan 2020).
OnePose++: Keypoint-Free One-Shot Object Pose Estimation without CAD Models
Jan 18, 2023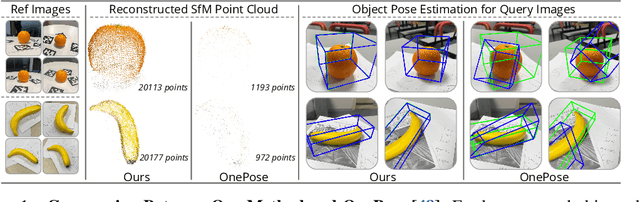
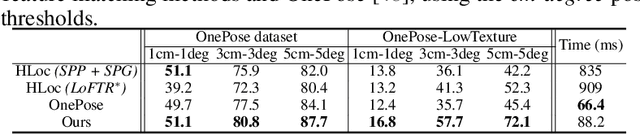
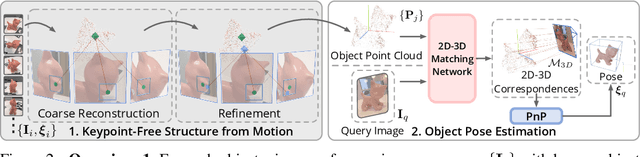

We propose a new method for object pose estimation without CAD models. The previous feature-matching-based method OnePose has shown promising results under a one-shot setting which eliminates the need for CAD models or object-specific training. However, OnePose relies on detecting repeatable image keypoints and is thus prone to failure on low-textured objects. We propose a keypoint-free pose estimation pipeline to remove the need for repeatable keypoint detection. Built upon the detector-free feature matching method LoFTR, we devise a new keypoint-free SfM method to reconstruct a semi-dense point-cloud model for the object. Given a query image for object pose estimation, a 2D-3D matching network directly establishes 2D-3D correspondences between the query image and the reconstructed point-cloud model without first detecting keypoints in the image. Experiments show that the proposed pipeline outperforms existing one-shot CAD-model-free methods by a large margin and is comparable to CAD-model-based methods on LINEMOD even for low-textured objects. We also collect a new dataset composed of 80 sequences of 40 low-textured objects to facilitate future research on one-shot object pose estimation. The supplementary material, code and dataset are available on the project page: https://zju3dv.github.io/onepose_plus_plus/.
A Comprehensive Review of Modern Object Segmentation Approaches
Jan 13, 2023
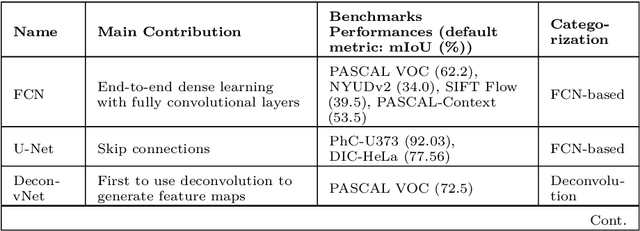
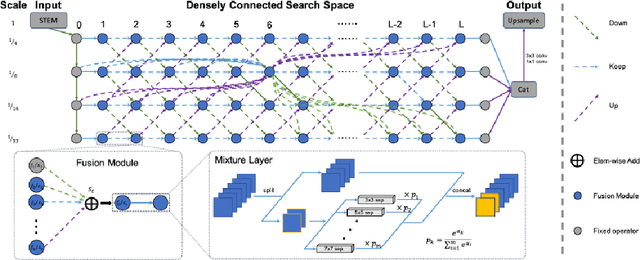
Image segmentation is the task of associating pixels in an image with their respective object class labels. It has a wide range of applications in many industries including healthcare, transportation, robotics, fashion, home improvement, and tourism. Many deep learning-based approaches have been developed for image-level object recognition and pixel-level scene understanding-with the latter requiring a much denser annotation of scenes with a large set of objects. Extensions of image segmentation tasks include 3D and video segmentation, where units of voxels, point clouds, and video frames are classified into different objects. We use "Object Segmentation" to refer to the union of these segmentation tasks. In this monograph, we investigate both traditional and modern object segmentation approaches, comparing their strengths, weaknesses, and utilities. We examine in detail the wide range of deep learning-based segmentation techniques developed in recent years, provide a review of the widely used datasets and evaluation metrics, and discuss potential future research directions.
* 173 pages, 49 figures, published in Foundations and Trends in Computer Graphics and Vision on 10/4/22. Authors retain copyright
Exploring the Limits of Synthetic Creation of Solar EUV Images via Image-to-Image Translation
Aug 19, 2022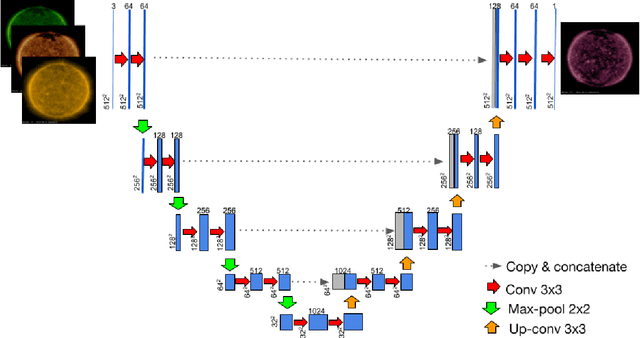
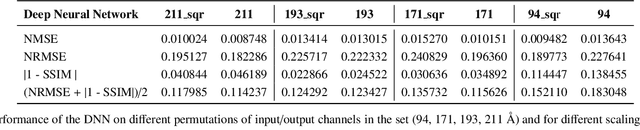
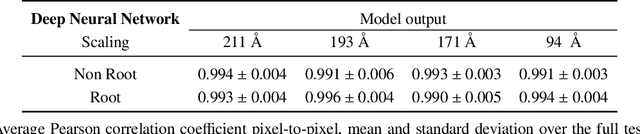
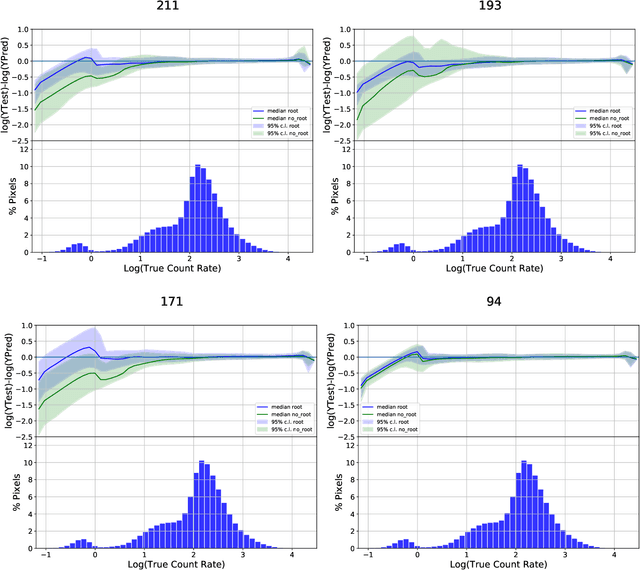
The Solar Dynamics Observatory (SDO), a NASA multi-spectral decade-long mission that has been daily producing terabytes of observational data from the Sun, has been recently used as a use-case to demonstrate the potential of machine learning methodologies and to pave the way for future deep-space mission planning. In particular, the idea of using image-to-image translation to virtually produce extreme ultra-violet channels has been proposed in several recent studies, as a way to both enhance missions with less available channels and to alleviate the challenges due to the low downlink rate in deep space. This paper investigates the potential and the limitations of such a deep learning approach by focusing on the permutation of four channels and an encoder--decoder based architecture, with particular attention to how morphological traits and brightness of the solar surface affect the neural network predictions. In this work we want to answer the question: can synthetic images of the solar corona produced via image-to-image translation be used for scientific studies of the Sun? The analysis highlights that the neural network produces high-quality images over three orders of magnitude in count rate (pixel intensity) and can generally reproduce the covariance across channels within a 1% error. However the model performance drastically diminishes in correspondence of extremely high energetic events like flares, and we argue that the reason is related to the rareness of such events posing a challenge to model training.
Generalizable Medical Image Segmentation via Random Amplitude Mixup and Domain-Specific Image Restoration
Aug 08, 2022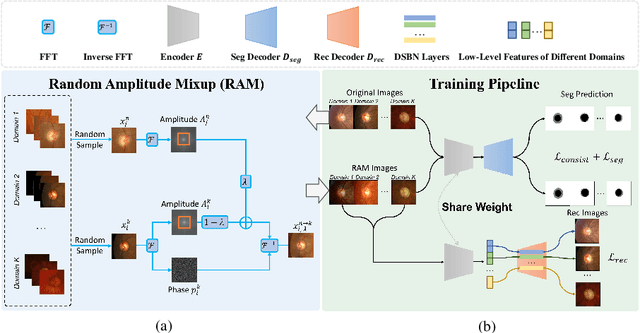
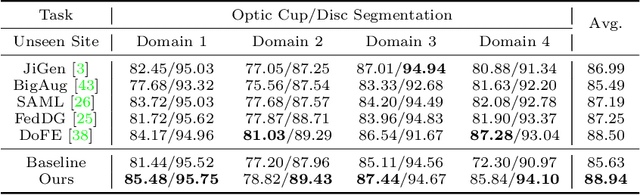
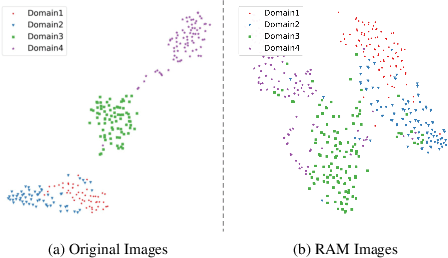
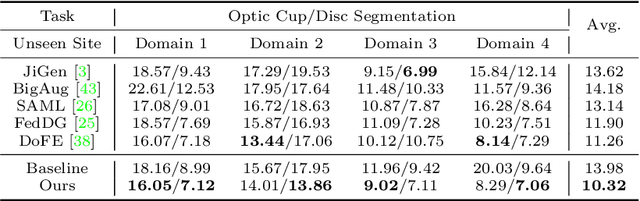
For medical image analysis, segmentation models trained on one or several domains lack generalization ability to unseen domains due to discrepancies between different data acquisition policies. We argue that the degeneration in segmentation performance is mainly attributed to overfitting to source domains and domain shift. To this end, we present a novel generalizable medical image segmentation method. To be specific, we design our approach as a multi-task paradigm by combining the segmentation model with a self-supervision domain-specific image restoration (DSIR) module for model regularization. We also design a random amplitude mixup (RAM) module, which incorporates low-level frequency information of different domain images to synthesize new images. To guide our model be resistant to domain shift, we introduce a semantic consistency loss. We demonstrate the performance of our method on two public generalizable segmentation benchmarks in medical images, which validates our method could achieve the state-of-the-art performance.
To Make Yourself Invisible with Adversarial Semantic Contours
Mar 01, 2023
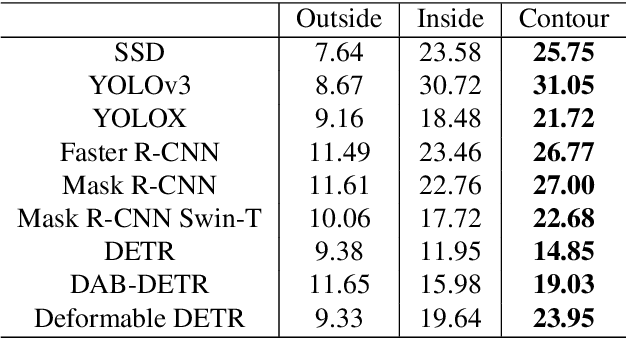

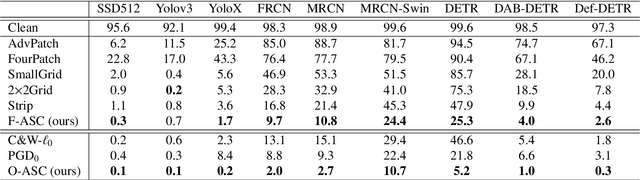
Modern object detectors are vulnerable to adversarial examples, which may bring risks to real-world applications. The sparse attack is an important task which, compared with the popular adversarial perturbation on the whole image, needs to select the potential pixels that is generally regularized by an $\ell_0$-norm constraint, and simultaneously optimize the corresponding texture. The non-differentiability of $\ell_0$ norm brings challenges and many works on attacking object detection adopted manually-designed patterns to address them, which are meaningless and independent of objects, and therefore lead to relatively poor attack performance. In this paper, we propose Adversarial Semantic Contour (ASC), an MAP estimate of a Bayesian formulation of sparse attack with a deceived prior of object contour. The object contour prior effectively reduces the search space of pixel selection and improves the attack by introducing more semantic bias. Extensive experiments demonstrate that ASC can corrupt the prediction of 9 modern detectors with different architectures (\e.g., one-stage, two-stage and Transformer) by modifying fewer than 5\% of the pixels of the object area in COCO in white-box scenario and around 10\% of those in black-box scenario. We further extend the attack to datasets for autonomous driving systems to verify the effectiveness. We conclude with cautions about contour being the common weakness of object detectors with various architecture and the care needed in applying them in safety-sensitive scenarios.
* 11 pages, 7 figures, published in Computer Vision and Image Understanding in 2023
STB-VMM: Swin Transformer Based Video Motion Magnification
Feb 20, 2023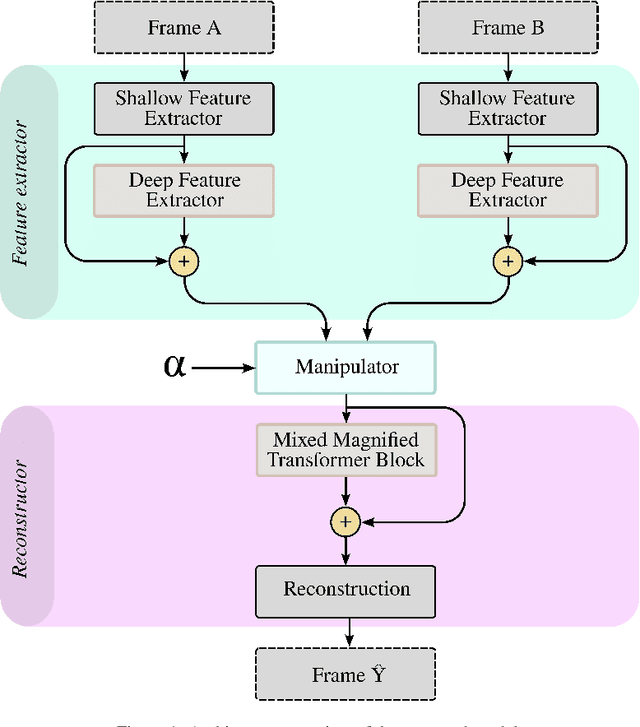
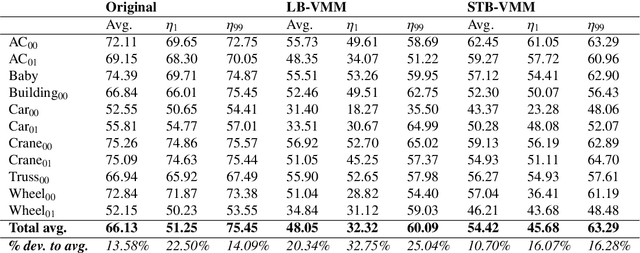
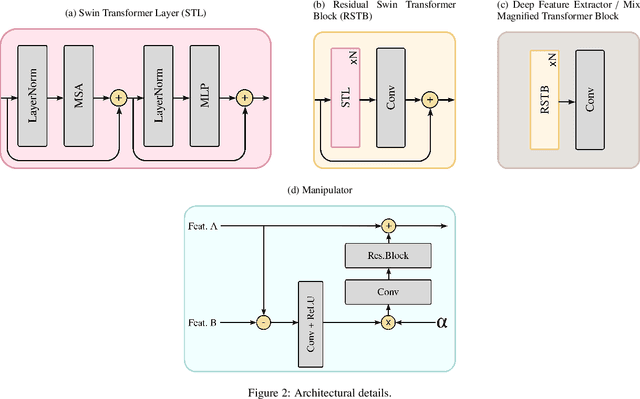
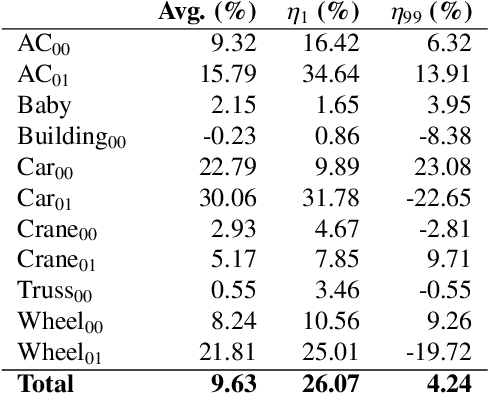
The goal of video motion magnification techniques is to magnify small motions in a video to reveal previously invisible or unseen movement. Its uses extend from bio-medical applications and deep fake detection to structural modal analysis and predictive maintenance. However, discerning small motion from noise is a complex task, especially when attempting to magnify very subtle often sub-pixel movement. As a result, motion magnification techniques generally suffer from noisy and blurry outputs. This work presents a new state-of-the-art model based on the Swin Transformer, which offers better tolerance to noisy inputs as well as higher-quality outputs that exhibit less noise, blurriness and artifacts than prior-art. Improvements in output image quality will enable more precise measurements for any application reliant on magnified video sequences, and may enable further development of video motion magnification techniques in new technical fields.
A relaxed proximal gradient descent algorithm for convergent plug-and-play with proximal denoiser
Jan 31, 2023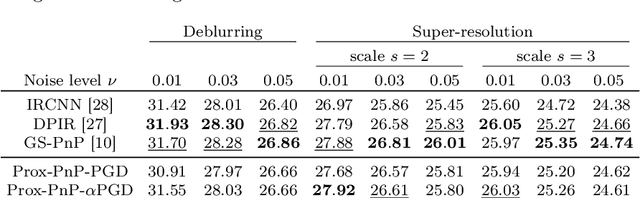
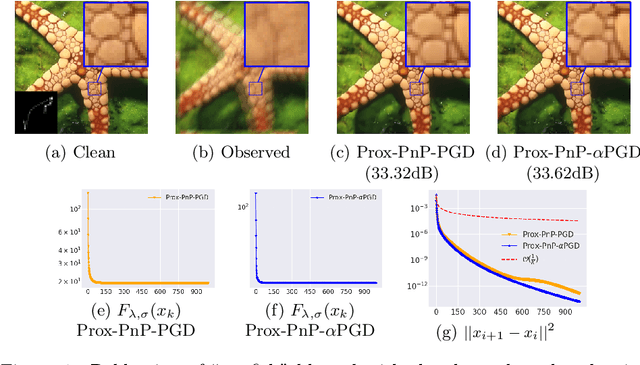
This paper presents a new convergent Plug-and-Play (PnP) algorithm. PnP methods are efficient iterative algorithms for solving image inverse problems formulated as the minimization of the sum of a data-fidelity term and a regularization term. PnP methods perform regularization by plugging a pre-trained denoiser in a proximal algorithm, such as Proximal Gradient Descent (PGD). To ensure convergence of PnP schemes, many works study specific parametrizations of deep denoisers. However, existing results require either unverifiable or suboptimal hypotheses on the denoiser, or assume restrictive conditions on the parameters of the inverse problem. Observing that these limitations can be due to the proximal algorithm in use, we study a relaxed version of the PGD algorithm for minimizing the sum of a convex function and a weakly convex one. When plugged with a relaxed proximal denoiser, we show that the proposed PnP-$\alpha$PGD algorithm converges for a wider range of regularization parameters, thus allowing more accurate image restoration.
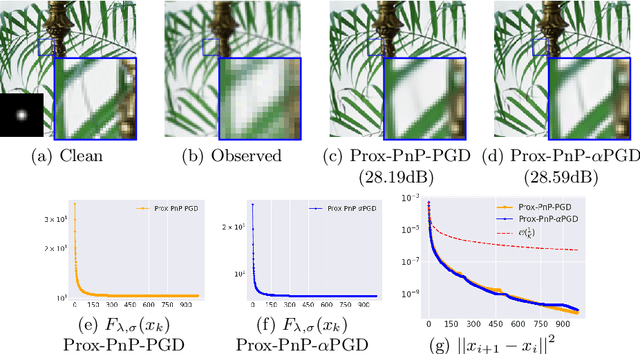
Rethinking Blur Synthesis for Deep Real-World Image Deblurring
Sep 28, 2022
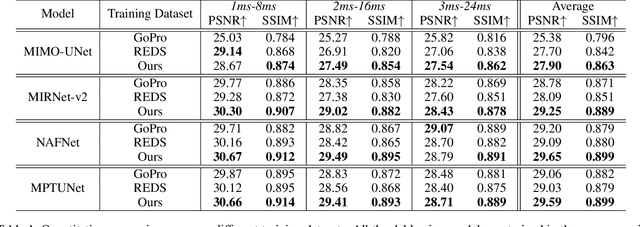

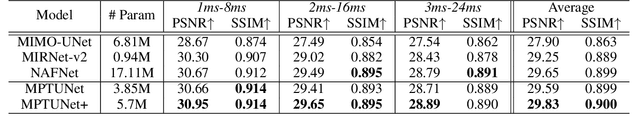
In this paper, we examine the problem of real-world image deblurring and take into account two key factors for improving the performance of the deep image deblurring model, namely, training data synthesis and network architecture design. Deblurring models trained on existing synthetic datasets perform poorly on real blurry images due to domain shift. To reduce the domain gap between synthetic and real domains, we propose a novel realistic blur synthesis pipeline to simulate the camera imaging process. As a result of our proposed synthesis method, existing deblurring models could be made more robust to handle real-world blur. Furthermore, we develop an effective deblurring model that captures non-local dependencies and local context in the feature domain simultaneously. Specifically, we introduce the multi-path transformer module to UNet architecture for enriched multi-scale features learning. A comprehensive experiment on three real-world datasets shows that the proposed deblurring model performs better than state-of-the-art methods.
Intrinsic and extrinsic deep learning on manifolds
Feb 16, 2023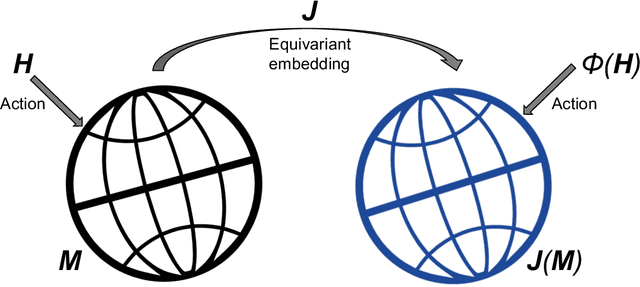
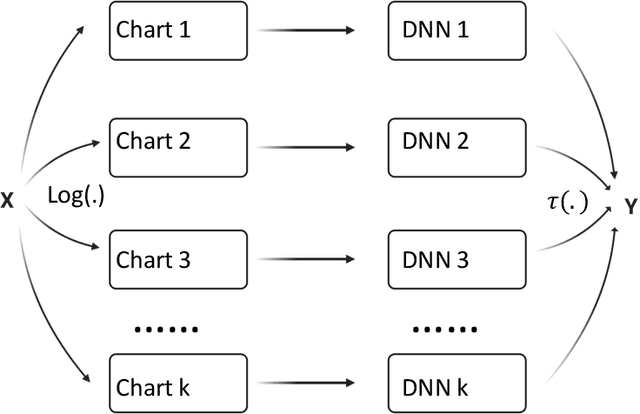

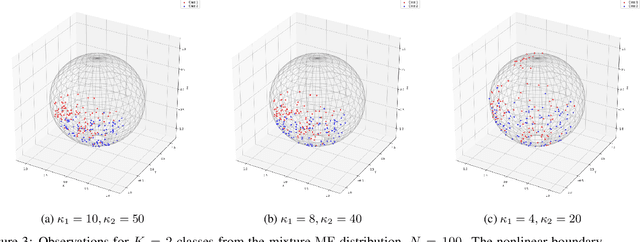
We propose extrinsic and intrinsic deep neural network architectures as general frameworks for deep learning on manifolds. Specifically, extrinsic deep neural networks (eDNNs) preserve geometric features on manifolds by utilizing an equivariant embedding from the manifold to its image in the Euclidean space. Moreover, intrinsic deep neural networks (iDNNs) incorporate the underlying intrinsic geometry of manifolds via exponential and log maps with respect to a Riemannian structure. Consequently, we prove that the empirical risk of the empirical risk minimizers (ERM) of eDNNs and iDNNs converge in optimal rates. Overall, The eDNNs framework is simple and easy to compute, while the iDNNs framework is accurate and fast converging. To demonstrate the utilities of our framework, various simulation studies, and real data analyses are presented with eDNNs and iDNNs.