 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Siamese Neural Networks for Skin Cancer Classification and New Class Detection using Clinical and Dermoscopic Image Datasets
Dec 12, 2022

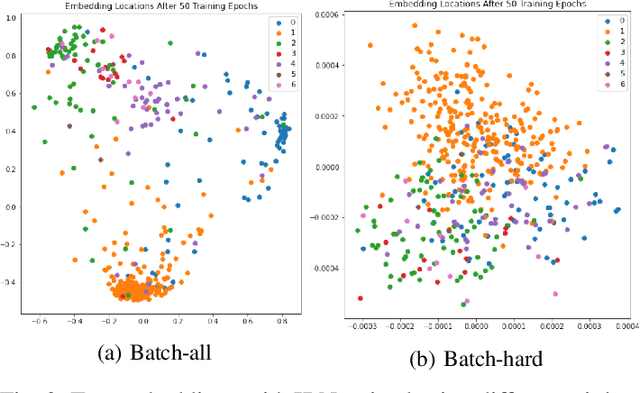
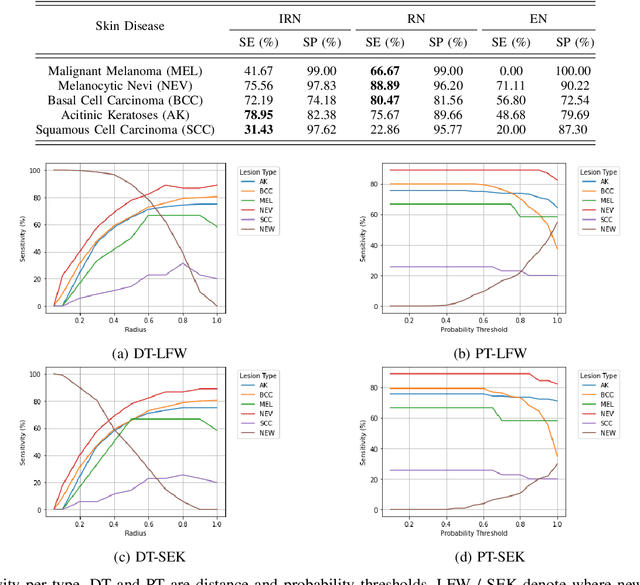
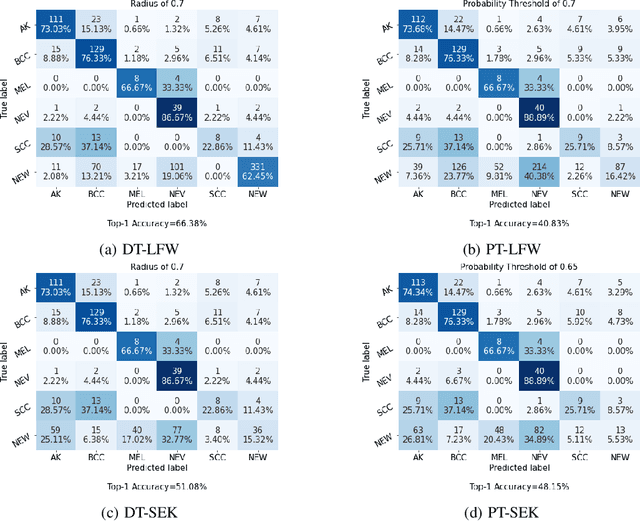
Skin cancer is the most common malignancy in the world. Automated skin cancer detection would significantly improve early detection rates and prevent deaths. To help with this aim, a number of datasets have been released which can be used to train Deep Learning systems - these have produced impressive results for classification. However, this only works for the classes they are trained on whilst they are incapable of identifying skin lesions from previously unseen classes, making them unconducive for clinical use. We could look to massively increase the datasets by including all possible skin lesions, though this would always leave out some classes. Instead, we evaluate Siamese Neural Networks (SNNs), which not only allows us to classify images of skin lesions, but also allow us to identify those images which are different from the trained classes - allowing us to determine that an image is not an example of our training classes. We evaluate SNNs on both dermoscopic and clinical images of skin lesions. We obtain top-1 classification accuracy levels of 74.33% and 85.61% on clinical and dermoscopic datasets, respectively. Although this is slightly lower than the state-of-the-art results, the SNN approach has the advantage that it can detect out-of-class examples. Our results highlight the potential of an SNN approach as well as pathways towards future clinical deployment.
Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
Feb 24, 2023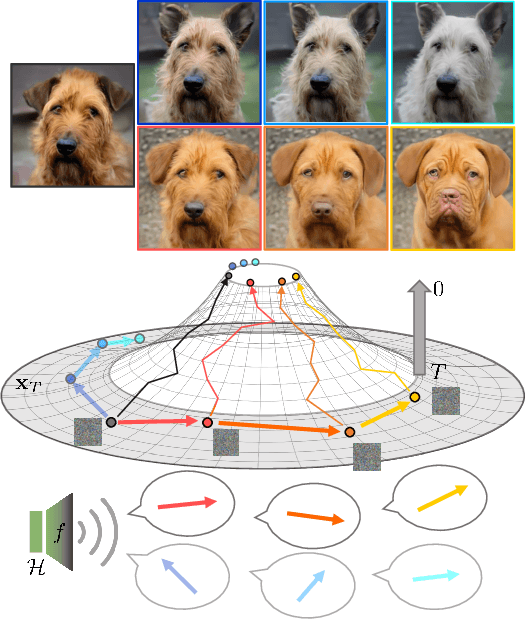
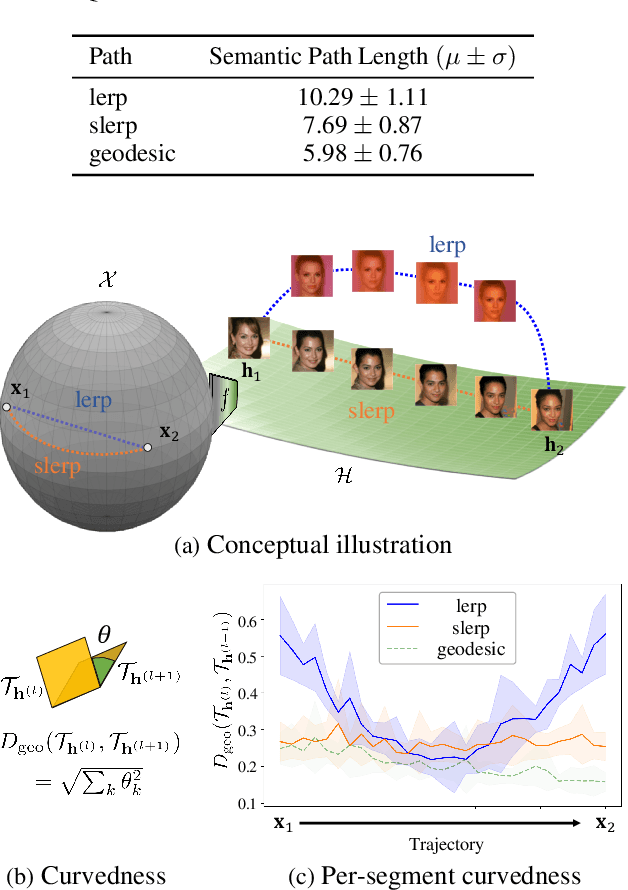


Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. While image editing with GANs builds upon latent space, DMs rely on editing the conditions such as text prompts. We present an unsupervised method to discover interpretable editing directions for the latent variables $\mathbf{x}_t \in \mathcal{X}$ of DMs. Our method adopts Riemannian geometry between $\mathcal{X}$ and the intermediate feature maps $\mathcal{H}$ of the U-Nets to provide a deep understanding over the geometrical structure of $\mathcal{X}$. The discovered semantic latent directions mostly yield disentangled attribute changes, and they are globally consistent across different samples. Furthermore, editing in earlier timesteps edits coarse attributes, while ones in later timesteps focus on high-frequency details. We define the curvedness of a line segment between samples to show that $\mathcal{X}$ is a curved manifold. Experiments on different baselines and datasets demonstrate the effectiveness of our method even on Stable Diffusion. Our source code will be publicly available for the future researchers.
DEANet: Decomposition Enhancement and Adjustment Network for Low-Light Image Enhancement
Sep 14, 2022
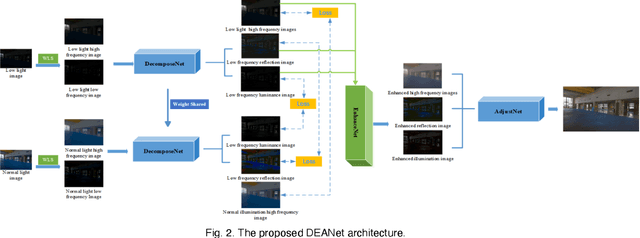
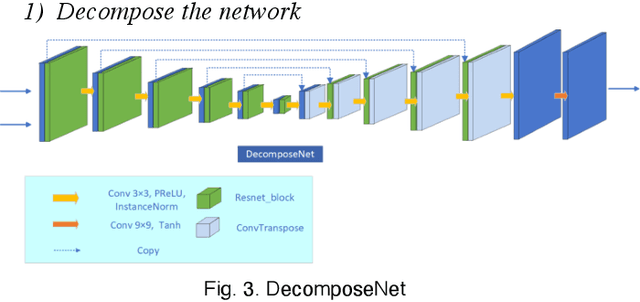
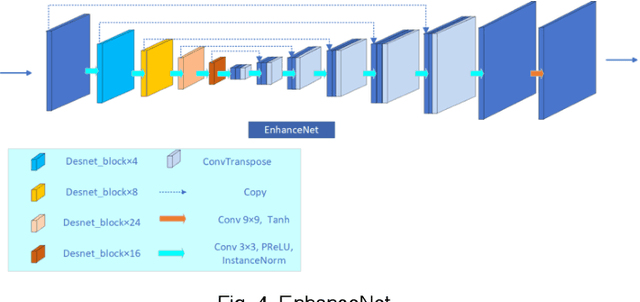
Images obtained under low-light conditions will seriously affect the quality of the images. Solving the problem of poor low-light image quality can effectively improve the visual quality of images and better improve the usability of computer vision. In addition, it has very important applications in many fields. This paper proposes a DEANet based on Retinex for low-light image enhancement. It combines the frequency information and content information of the image into three sub-networks: decomposition network, enhancement network and adjustment network. These three sub-networks are respectively used for decomposition, denoising, contrast enhancement and detail preservation, adjustment, and image generation. Our model has good robust results for all low-light images. The model is trained on the public data set LOL, and the experimental results show that our method is better than the existing state-of-the-art methods in terms of vision and quality.
Diffusion Models for Medical Image Analysis: A Comprehensive Survey
Nov 14, 2022



Denoising diffusion models, a class of generative models, have garnered immense interest lately in various deep-learning problems. A diffusion probabilistic model defines a forward diffusion stage where the input data is gradually perturbed over several steps by adding Gaussian noise and then learns to reverse the diffusion process to retrieve the desired noise-free data from noisy data samples. Diffusion models are widely appreciated for their strong mode coverage and quality of the generated samples despite their known computational burdens. Capitalizing on the advances in computer vision, the field of medical imaging has also observed a growing interest in diffusion models. To help the researcher navigate this profusion, this survey intends to provide a comprehensive overview of diffusion models in the discipline of medical image analysis. Specifically, we introduce the solid theoretical foundation and fundamental concepts behind diffusion models and the three generic diffusion modelling frameworks: diffusion probabilistic models, noise-conditioned score networks, and stochastic differential equations. Then, we provide a systematic taxonomy of diffusion models in the medical domain and propose a multi-perspective categorization based on their application, imaging modality, organ of interest, and algorithms. To this end, we cover extensive applications of diffusion models in the medical domain. Furthermore, we emphasize the practical use case of some selected approaches, and then we discuss the limitations of the diffusion models in the medical domain and propose several directions to fulfill the demands of this field. Finally, we gather the overviewed studies with their available open-source implementations at https://github.com/amirhossein-kz/Awesome-Diffusion-Models-in-Medical-Imaging.
End-to-end deep multi-score model for No-reference stereoscopic image quality assessment
Nov 02, 2022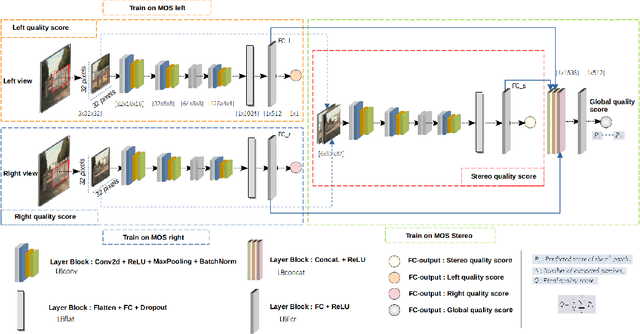
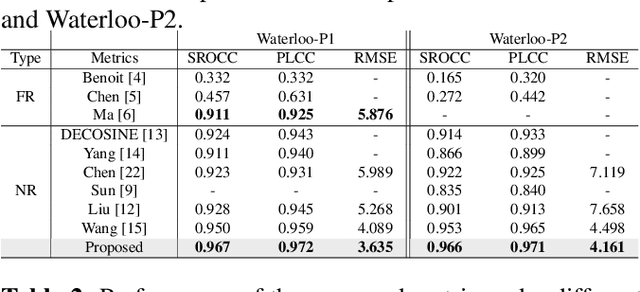
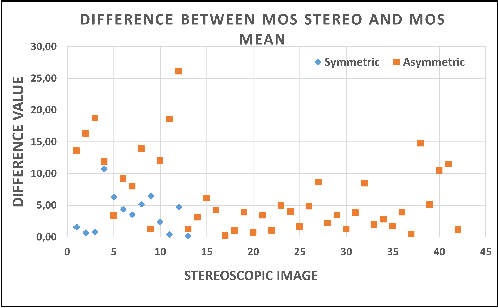
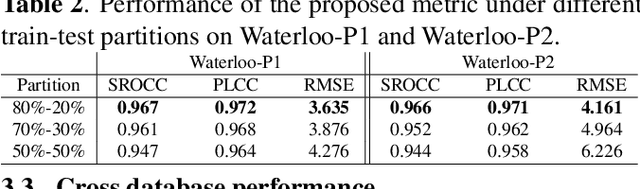
Deep learning-based quality metrics have recently given significant improvement in Image Quality Assessment (IQA). In the field of stereoscopic vision, information is evenly distributed with slight disparity to the left and right eyes. However, due to asymmetric distortion, the objective quality ratings for the left and right images would differ, necessitating the learning of unique quality indicators for each view. Unlike existing stereoscopic IQA measures which focus mainly on estimating a global human score, we suggest incorporating left, right, and stereoscopic objective scores to extract the corresponding properties of each view, and so forth estimating stereoscopic image quality without reference. Therefore, we use a deep multi-score Convolutional Neural Network (CNN). Our model has been trained to perform four tasks: First, predict the left view's quality. Second, predict the quality of the left view. Third and fourth, predict the quality of the stereo view and global quality, respectively, with the global score serving as the ultimate quality. Experiments are conducted on Waterloo IVC 3D Phase 1 and Phase 2 databases. The results obtained show the superiority of our method when comparing with those of the state-of-the-art. The implementation code can be found at: https://github.com/o-messai/multi-score-SIQA
Finding Things in the Unknown: Semantic Object-Centric Exploration with an MAV
Mar 03, 2023
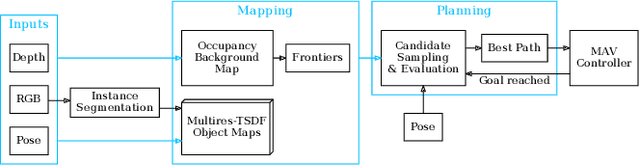
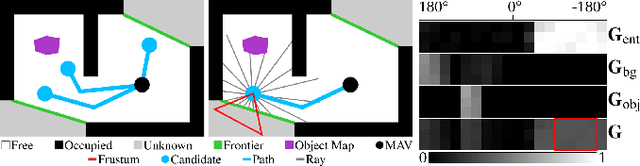

Exploration of unknown space with an autonomous mobile robot is a well-studied problem. In this work we broaden the scope of exploration, moving beyond the pure geometric goal of uncovering as much free space as possible. We believe that for many practical applications, exploration should be contextualised with semantic and object-level understanding of the environment for task-specific exploration. Here, we study the task of both finding specific objects in unknown space as well as reconstructing them to a target level of detail. We therefore extend our environment reconstruction to not only consist of a background map, but also object-level and semantically fused submaps. Importantly, we adapt our previous objective function of uncovering as much free space as possible in as little time as possible with two additional elements: first, we require a maximum observation distance of background surfaces to ensure target objects are not missed by image-based detectors because they are too small to be detected. Second, we require an even smaller maximum distance to the found objects in order to reconstruct them with the desired accuracy. We further created a Micro Aerial Vehicle (MAV) semantic exploration simulator based on Habitat in order to quantitatively demonstrate how our framework can be used to efficiently find specific objects as part of exploration. Finally, we showcase this capability can be deployed in real-world scenes involving our drone equipped with an Intel RealSense D455 RGB-D camera.
MixVPR: Feature Mixing for Visual Place Recognition
Mar 03, 2023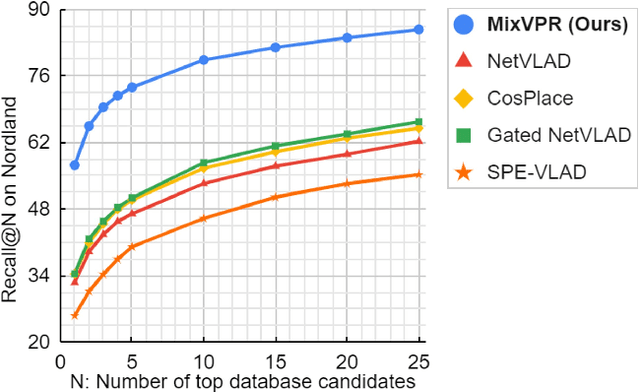
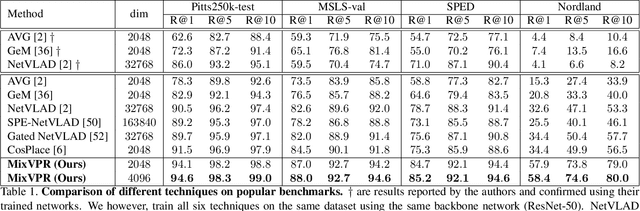
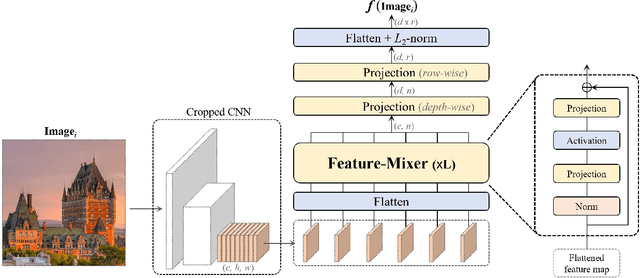
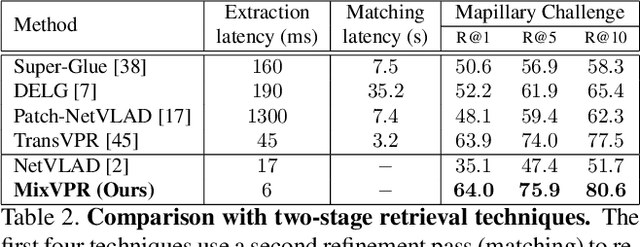
Visual Place Recognition (VPR) is a crucial part of mobile robotics and autonomous driving as well as other computer vision tasks. It refers to the process of identifying a place depicted in a query image using only computer vision. At large scale, repetitive structures, weather and illumination changes pose a real challenge, as appearances can drastically change over time. Along with tackling these challenges, an efficient VPR technique must also be practical in real-world scenarios where latency matters. To address this, we introduce MixVPR, a new holistic feature aggregation technique that takes feature maps from pre-trained backbones as a set of global features. Then, it incorporates a global relationship between elements in each feature map in a cascade of feature mixing, eliminating the need for local or pyramidal aggregation as done in NetVLAD or TransVPR. We demonstrate the effectiveness of our technique through extensive experiments on multiple large-scale benchmarks. Our method outperforms all existing techniques by a large margin while having less than half the number of parameters compared to CosPlace and NetVLAD. We achieve a new all-time high recall@1 score of 94.6% on Pitts250k-test, 88.0% on MapillarySLS, and more importantly, 58.4% on Nordland. Finally, our method outperforms two-stage retrieval techniques such as Patch-NetVLAD, TransVPR and SuperGLUE all while being orders of magnitude faster. Our code and trained models are available at https://github.com/amaralibey/MixVPR.
Collaborative Learning with a Drone Orchestrator
Mar 03, 2023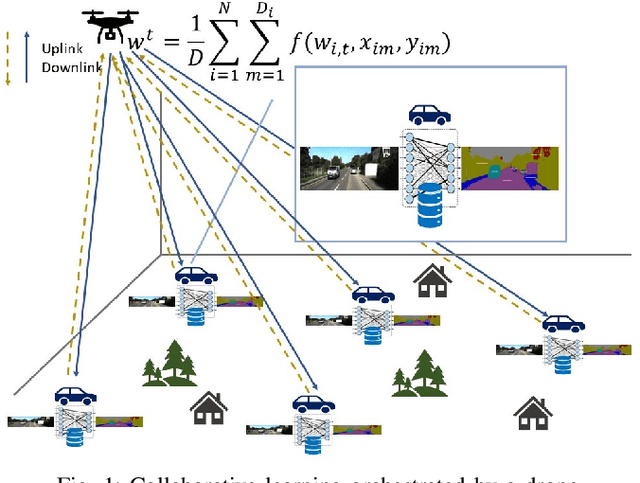
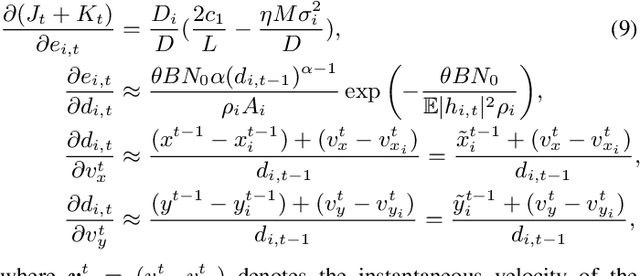
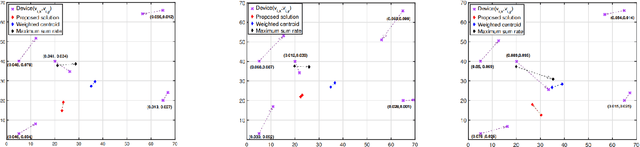
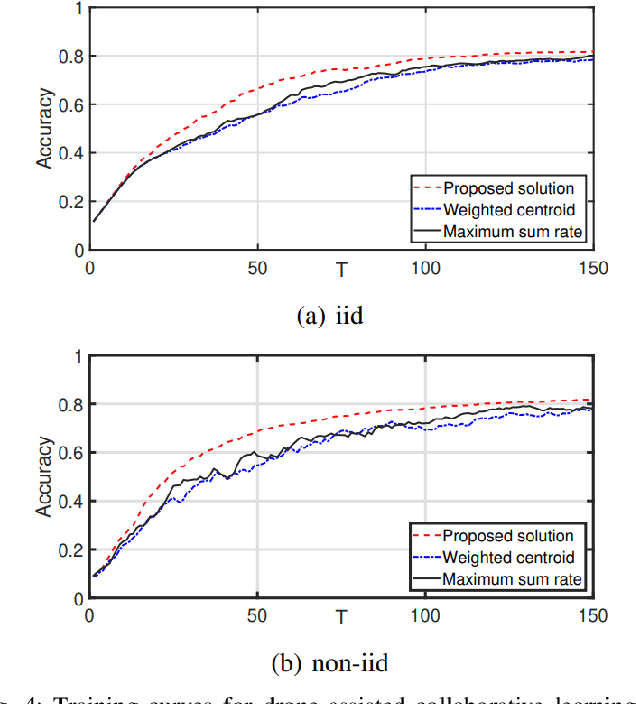
In this paper, the problem of drone-assisted collaborative learning is considered. In this scenario, swarm of intelligent wireless devices train a shared neural network (NN) model with the help of a drone. Using its sensors, each device records samples from its environment to gather a local dataset for training. The training data is severely heterogeneous as various devices have different amount of data and sensor noise level. The intelligent devices iteratively train the NN on their local datasets and exchange the model parameters with the drone for aggregation. For this system, the convergence rate of collaborative learning is derived while considering data heterogeneity, sensor noise levels, and communication errors, then, the drone trajectory that maximizes the final accuracy of the trained NN is obtained. The proposed trajectory optimization approach is aware of both the devices data characteristics (i.e., local dataset size and noise level) and their wireless channel conditions, and significantly improves the convergence rate and final accuracy in comparison with baselines that only consider data characteristics or channel conditions. Compared to state-of-the-art baselines, the proposed approach achieves an average 3.85% and 3.54% improvement in the final accuracy of the trained NN on benchmark datasets for image recognition and semantic segmentation tasks, respectively. Moreover, the proposed framework achieves a significant speedup in training, leading to an average 24% and 87% saving in the drone hovering time, communication overhead, and battery usage, respectively for these tasks.
OnePose++: Keypoint-Free One-Shot Object Pose Estimation without CAD Models
Jan 18, 2023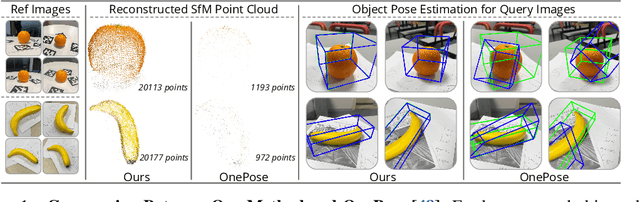
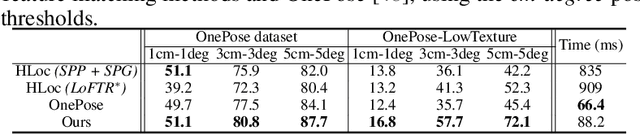
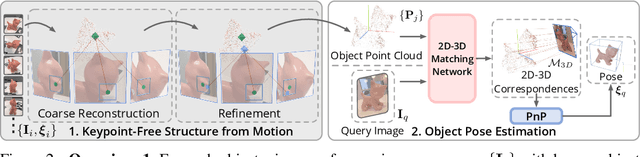

We propose a new method for object pose estimation without CAD models. The previous feature-matching-based method OnePose has shown promising results under a one-shot setting which eliminates the need for CAD models or object-specific training. However, OnePose relies on detecting repeatable image keypoints and is thus prone to failure on low-textured objects. We propose a keypoint-free pose estimation pipeline to remove the need for repeatable keypoint detection. Built upon the detector-free feature matching method LoFTR, we devise a new keypoint-free SfM method to reconstruct a semi-dense point-cloud model for the object. Given a query image for object pose estimation, a 2D-3D matching network directly establishes 2D-3D correspondences between the query image and the reconstructed point-cloud model without first detecting keypoints in the image. Experiments show that the proposed pipeline outperforms existing one-shot CAD-model-free methods by a large margin and is comparable to CAD-model-based methods on LINEMOD even for low-textured objects. We also collect a new dataset composed of 80 sequences of 40 low-textured objects to facilitate future research on one-shot object pose estimation. The supplementary material, code and dataset are available on the project page: https://zju3dv.github.io/onepose_plus_plus/.
A Comprehensive Review of Modern Object Segmentation Approaches
Jan 13, 2023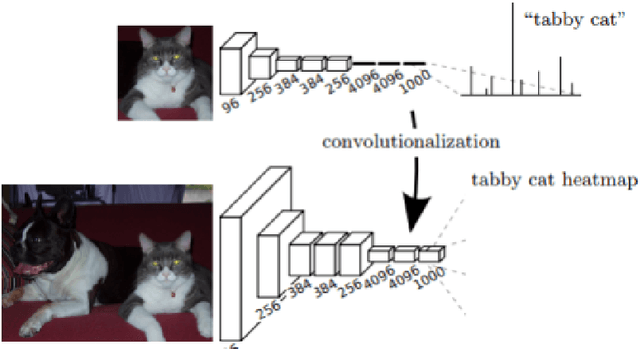
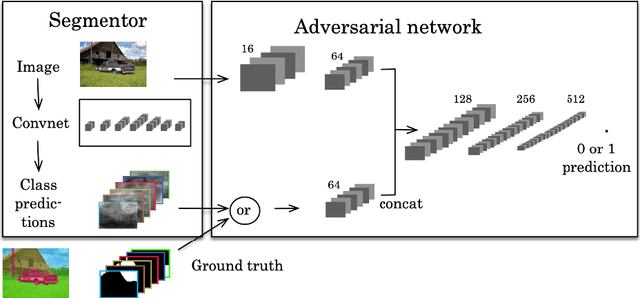
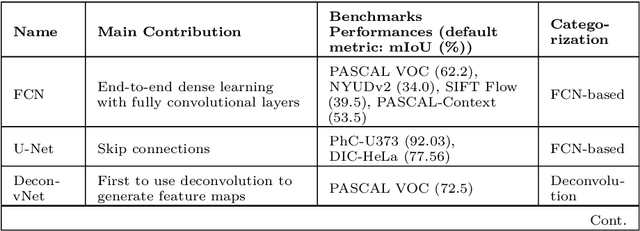
Image segmentation is the task of associating pixels in an image with their respective object class labels. It has a wide range of applications in many industries including healthcare, transportation, robotics, fashion, home improvement, and tourism. Many deep learning-based approaches have been developed for image-level object recognition and pixel-level scene understanding-with the latter requiring a much denser annotation of scenes with a large set of objects. Extensions of image segmentation tasks include 3D and video segmentation, where units of voxels, point clouds, and video frames are classified into different objects. We use "Object Segmentation" to refer to the union of these segmentation tasks. In this monograph, we investigate both traditional and modern object segmentation approaches, comparing their strengths, weaknesses, and utilities. We examine in detail the wide range of deep learning-based segmentation techniques developed in recent years, provide a review of the widely used datasets and evaluation metrics, and discuss potential future research directions.
* 173 pages, 49 figures, published in Foundations and Trends in Computer Graphics and Vision on 10/4/22. Authors retain copyright