 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
Feb 24, 2023
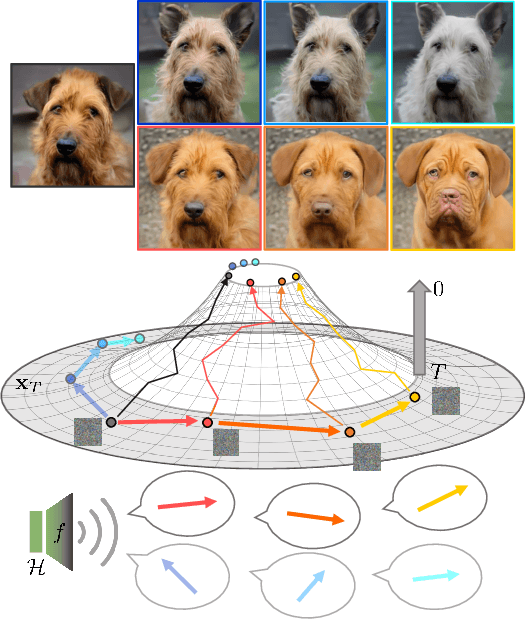
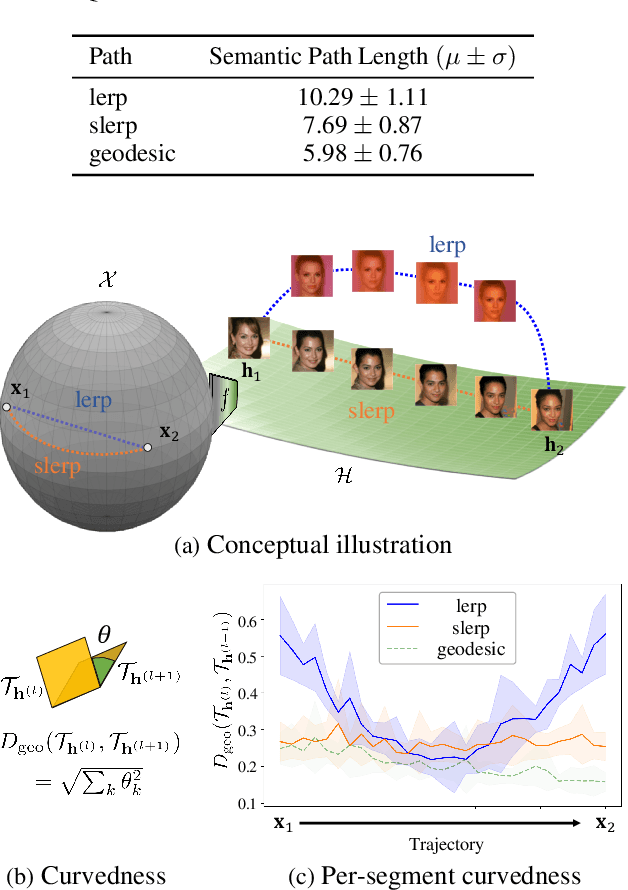


Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. While image editing with GANs builds upon latent space, DMs rely on editing the conditions such as text prompts. We present an unsupervised method to discover interpretable editing directions for the latent variables $\mathbf{x}_t \in \mathcal{X}$ of DMs. Our method adopts Riemannian geometry between $\mathcal{X}$ and the intermediate feature maps $\mathcal{H}$ of the U-Nets to provide a deep understanding over the geometrical structure of $\mathcal{X}$. The discovered semantic latent directions mostly yield disentangled attribute changes, and they are globally consistent across different samples. Furthermore, editing in earlier timesteps edits coarse attributes, while ones in later timesteps focus on high-frequency details. We define the curvedness of a line segment between samples to show that $\mathcal{X}$ is a curved manifold. Experiments on different baselines and datasets demonstrate the effectiveness of our method even on Stable Diffusion. Our source code will be publicly available for the future researchers.
SFI-Swin: Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components Distributions
Jan 09, 2023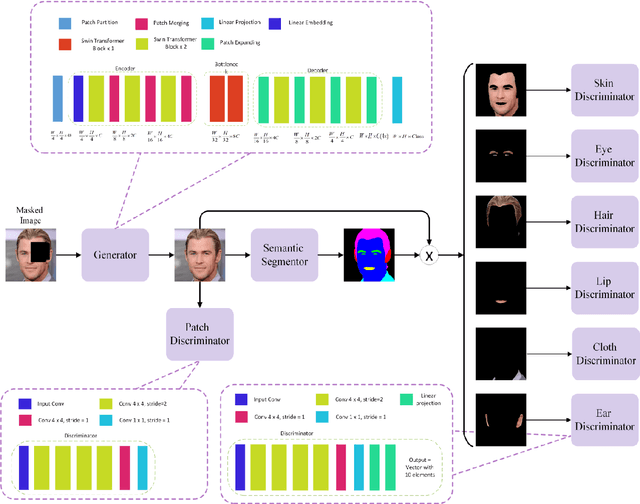
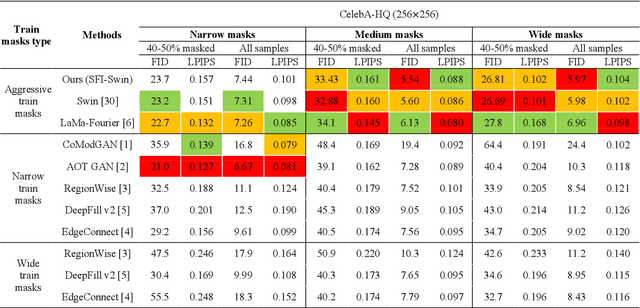


Image inpainting consists of filling holes or missing parts of an image. Inpainting face images with symmetric characteristics is more challenging than inpainting a natural scene. None of the powerful existing models can fill out the missing parts of an image while considering the symmetry and homogeneity of the picture. Moreover, the metrics that assess a repaired face image quality cannot measure the preservation of symmetry between the rebuilt and existing parts of a face. In this paper, we intend to solve the symmetry problem in the face inpainting task by using multiple discriminators that check each face organ's reality separately and a transformer-based network. We also propose "symmetry concentration score" as a new metric for measuring the symmetry of a repaired face image. The quantitative and qualitative results show the superiority of our proposed method compared to some of the recently proposed algorithms in terms of the reality, symmetry, and homogeneity of the inpainted parts.
Hierarchical and Progressive Image Matting
Oct 13, 2022
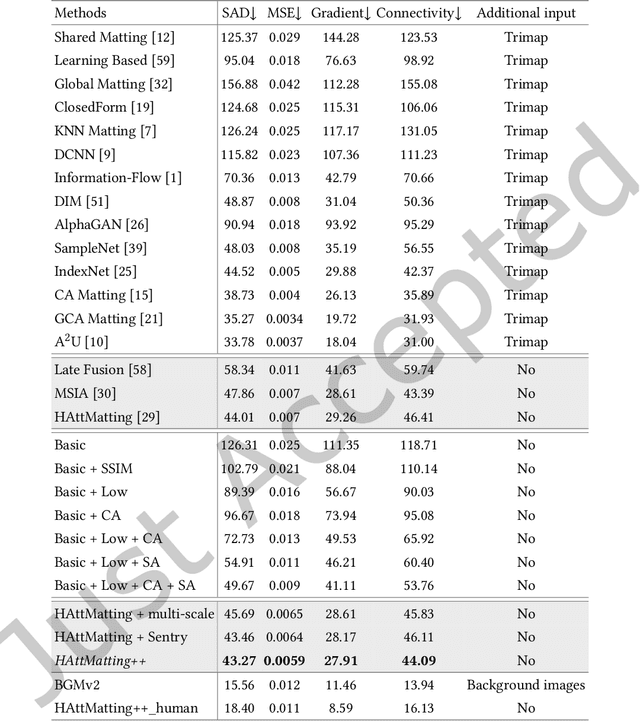
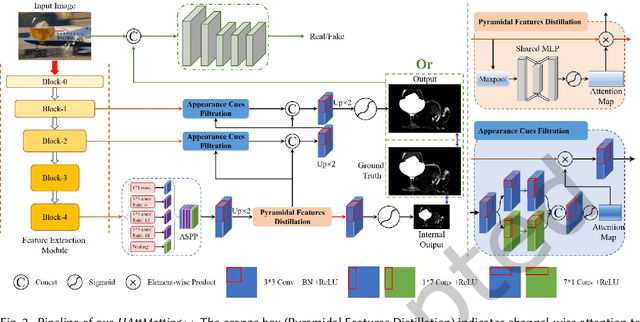
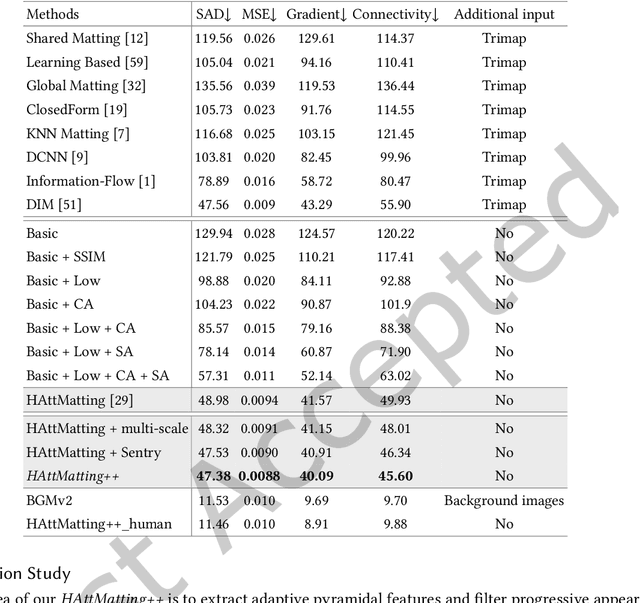
Most matting researches resort to advanced semantics to achieve high-quality alpha mattes, and direct low-level features combination is usually explored to complement alpha details. However, we argue that appearance-agnostic integration can only provide biased foreground details and alpha mattes require different-level feature aggregation for better pixel-wise opacity perception. In this paper, we propose an end-to-end Hierarchical and Progressive Attention Matting Network (HAttMatting++), which can better predict the opacity of the foreground from single RGB images without additional input. Specifically, we utilize channel-wise attention to distill pyramidal features and employ spatial attention at different levels to filter appearance cues. This progressive attention mechanism can estimate alpha mattes from adaptive semantics and semantics-indicated boundaries. We also introduce a hybrid loss function fusing Structural SIMilarity (SSIM), Mean Square Error (MSE), Adversarial loss, and sentry supervision to guide the network to further improve the overall foreground structure. Besides, we construct a large-scale and challenging image matting dataset comprised of 59, 600 training images and 1000 test images (a total of 646 distinct foreground alpha mattes), which can further improve the robustness of our hierarchical and progressive aggregation model. Extensive experiments demonstrate that the proposed HAttMatting++ can capture sophisticated foreground structures and achieve state-of-the-art performance with single RGB images as input.
Structured Generative Models for Scene Understanding
Feb 07, 2023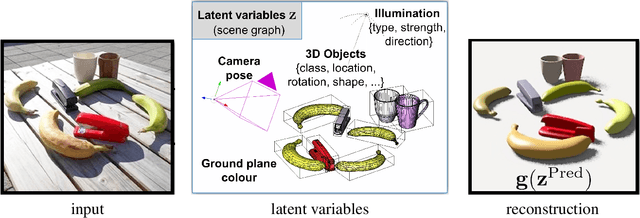



This position paper argues for the use of \emph{structured generative models} (SGMs) for scene understanding. This requires the reconstruction of a 3D scene from an input image, whereby the contents of the image are causally explained in terms of models of instantiated objects, each with their own type, shape, appearance and pose, along with global variables like scene lighting and camera parameters. This approach also requires scene models which account for the co-occurrences and inter-relationships of objects in a scene. The SGM approach has the merits that it is compositional and generative, which lead to interpretability. To pursue the SGM agenda, we need models for objects and scenes, and approaches to carry out inference. We first review models for objects, which include ``things'' (object categories that have a well defined shape), and ``stuff'' (categories which have amorphous spatial extent). We then move on to review \emph{scene models} which describe the inter-relationships of objects. Perhaps the most challenging problem for SGMs is \emph{inference} of the objects, lighting and camera parameters, and scene inter-relationships from input consisting of a single or multiple images. We conclude with a discussion of issues that need addressing to advance the SGM agenda.
HDRfeat: A Feature-Rich Network for High Dynamic Range Image Reconstruction
Nov 08, 2022
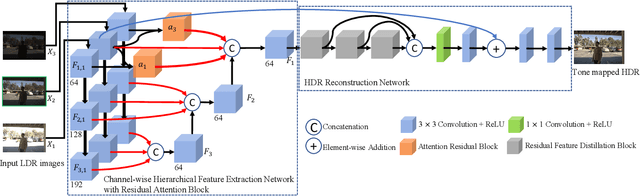
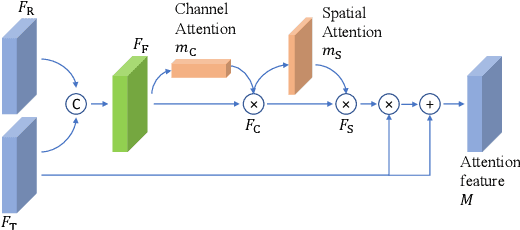

A major challenge for high dynamic range (HDR) image reconstruction from multi-exposed low dynamic range (LDR) images, especially with dynamic scenes, is the extraction and merging of relevant contextual features in order to suppress any ghosting and blurring artifacts from moving objects. To tackle this, in this work we propose a novel network for HDR reconstruction with deep and rich feature extraction layers, including residual attention blocks with sequential channel and spatial attention. For the compression of the rich-features to the HDR domain, a residual feature distillation block (RFDB) based architecture is adopted. In contrast to earlier deep-learning methods for HDR, the above contributions shift focus from merging/compression to feature extraction, the added value of which we demonstrate with ablation experiments. We present qualitative and quantitative comparisons on a public benchmark dataset, showing that our proposed method outperforms the state-of-the-art.
Siamese Neural Networks for Skin Cancer Classification and New Class Detection using Clinical and Dermoscopic Image Datasets
Dec 12, 2022
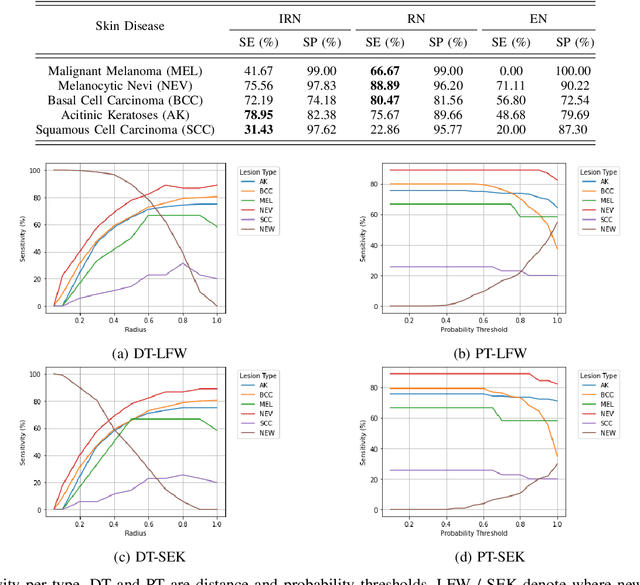
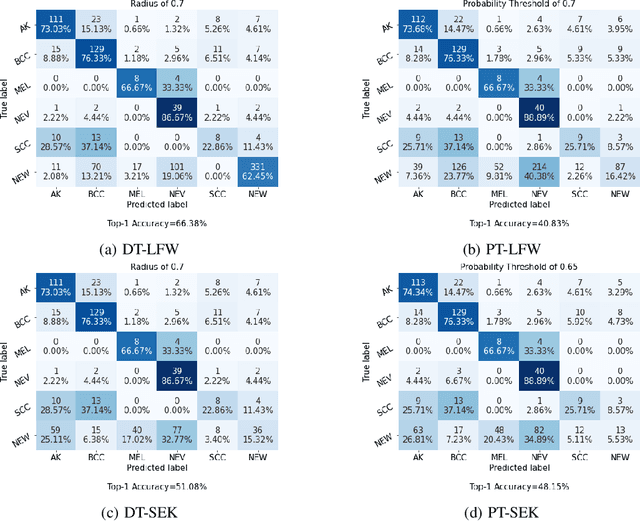
Skin cancer is the most common malignancy in the world. Automated skin cancer detection would significantly improve early detection rates and prevent deaths. To help with this aim, a number of datasets have been released which can be used to train Deep Learning systems - these have produced impressive results for classification. However, this only works for the classes they are trained on whilst they are incapable of identifying skin lesions from previously unseen classes, making them unconducive for clinical use. We could look to massively increase the datasets by including all possible skin lesions, though this would always leave out some classes. Instead, we evaluate Siamese Neural Networks (SNNs), which not only allows us to classify images of skin lesions, but also allow us to identify those images which are different from the trained classes - allowing us to determine that an image is not an example of our training classes. We evaluate SNNs on both dermoscopic and clinical images of skin lesions. We obtain top-1 classification accuracy levels of 74.33% and 85.61% on clinical and dermoscopic datasets, respectively. Although this is slightly lower than the state-of-the-art results, the SNN approach has the advantage that it can detect out-of-class examples. Our results highlight the potential of an SNN approach as well as pathways towards future clinical deployment.
Finding Things in the Unknown: Semantic Object-Centric Exploration with an MAV
Mar 03, 2023
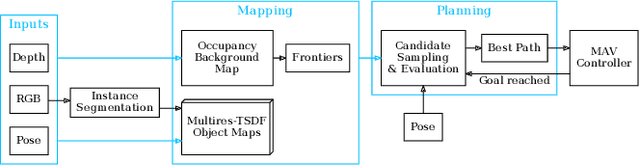
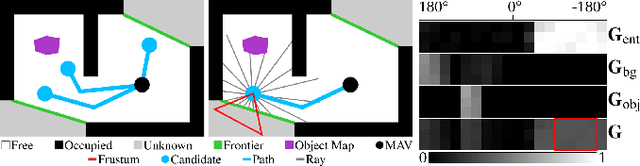

Exploration of unknown space with an autonomous mobile robot is a well-studied problem. In this work we broaden the scope of exploration, moving beyond the pure geometric goal of uncovering as much free space as possible. We believe that for many practical applications, exploration should be contextualised with semantic and object-level understanding of the environment for task-specific exploration. Here, we study the task of both finding specific objects in unknown space as well as reconstructing them to a target level of detail. We therefore extend our environment reconstruction to not only consist of a background map, but also object-level and semantically fused submaps. Importantly, we adapt our previous objective function of uncovering as much free space as possible in as little time as possible with two additional elements: first, we require a maximum observation distance of background surfaces to ensure target objects are not missed by image-based detectors because they are too small to be detected. Second, we require an even smaller maximum distance to the found objects in order to reconstruct them with the desired accuracy. We further created a Micro Aerial Vehicle (MAV) semantic exploration simulator based on Habitat in order to quantitatively demonstrate how our framework can be used to efficiently find specific objects as part of exploration. Finally, we showcase this capability can be deployed in real-world scenes involving our drone equipped with an Intel RealSense D455 RGB-D camera.
Collaborative Learning with a Drone Orchestrator
Mar 03, 2023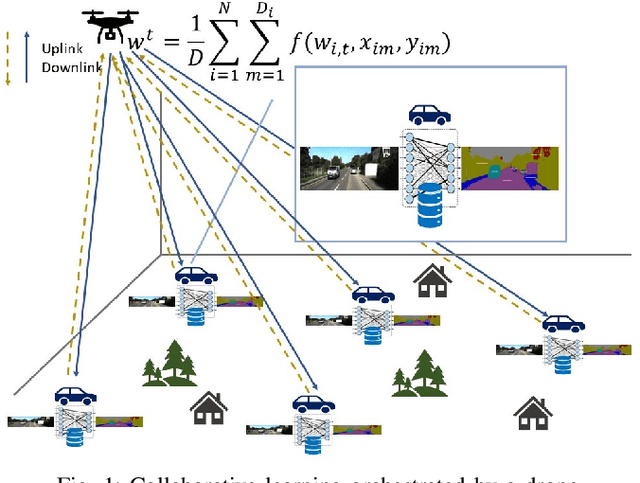
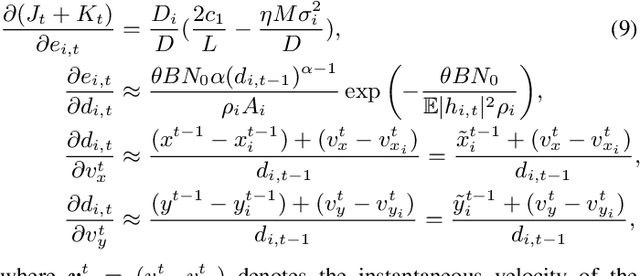
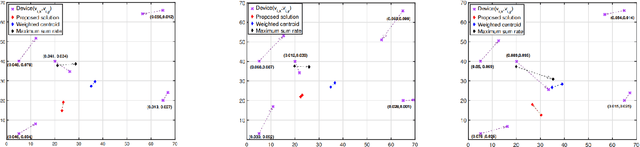
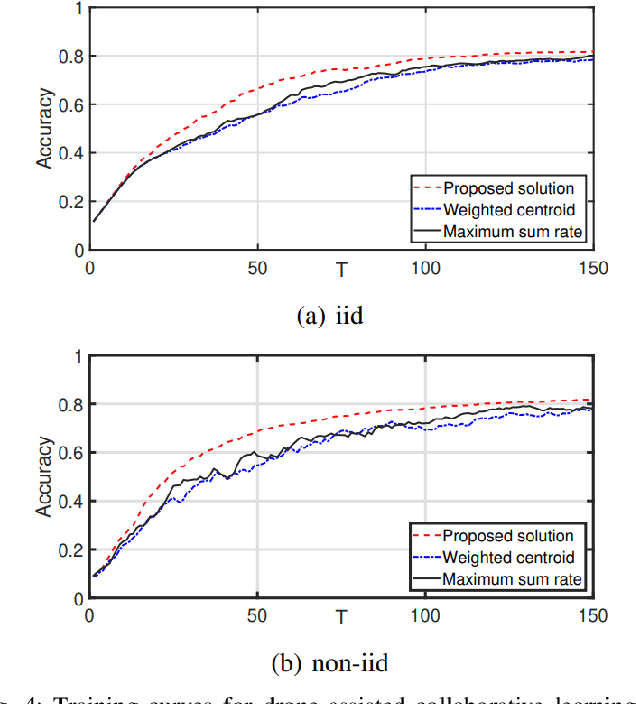
In this paper, the problem of drone-assisted collaborative learning is considered. In this scenario, swarm of intelligent wireless devices train a shared neural network (NN) model with the help of a drone. Using its sensors, each device records samples from its environment to gather a local dataset for training. The training data is severely heterogeneous as various devices have different amount of data and sensor noise level. The intelligent devices iteratively train the NN on their local datasets and exchange the model parameters with the drone for aggregation. For this system, the convergence rate of collaborative learning is derived while considering data heterogeneity, sensor noise levels, and communication errors, then, the drone trajectory that maximizes the final accuracy of the trained NN is obtained. The proposed trajectory optimization approach is aware of both the devices data characteristics (i.e., local dataset size and noise level) and their wireless channel conditions, and significantly improves the convergence rate and final accuracy in comparison with baselines that only consider data characteristics or channel conditions. Compared to state-of-the-art baselines, the proposed approach achieves an average 3.85% and 3.54% improvement in the final accuracy of the trained NN on benchmark datasets for image recognition and semantic segmentation tasks, respectively. Moreover, the proposed framework achieves a significant speedup in training, leading to an average 24% and 87% saving in the drone hovering time, communication overhead, and battery usage, respectively for these tasks.
MixVPR: Feature Mixing for Visual Place Recognition
Mar 03, 2023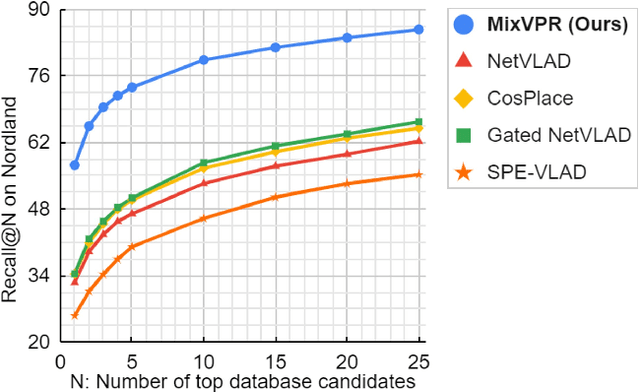
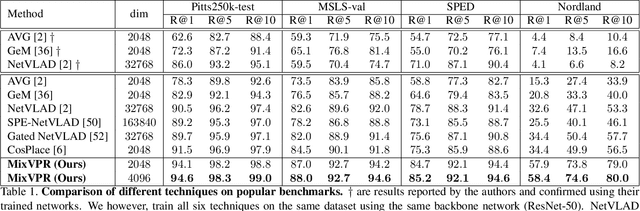
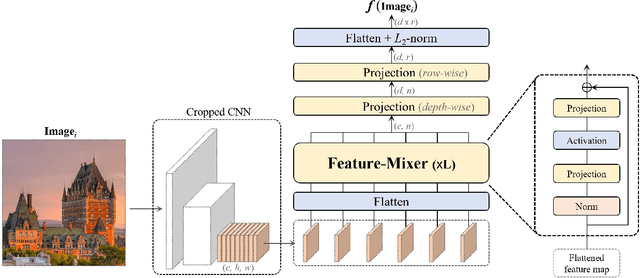
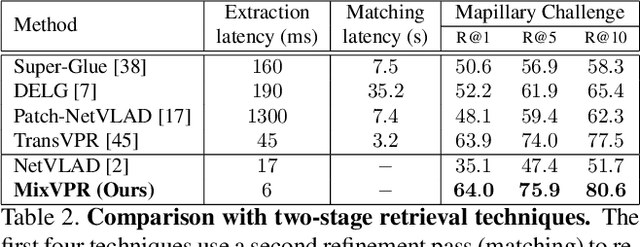
Visual Place Recognition (VPR) is a crucial part of mobile robotics and autonomous driving as well as other computer vision tasks. It refers to the process of identifying a place depicted in a query image using only computer vision. At large scale, repetitive structures, weather and illumination changes pose a real challenge, as appearances can drastically change over time. Along with tackling these challenges, an efficient VPR technique must also be practical in real-world scenarios where latency matters. To address this, we introduce MixVPR, a new holistic feature aggregation technique that takes feature maps from pre-trained backbones as a set of global features. Then, it incorporates a global relationship between elements in each feature map in a cascade of feature mixing, eliminating the need for local or pyramidal aggregation as done in NetVLAD or TransVPR. We demonstrate the effectiveness of our technique through extensive experiments on multiple large-scale benchmarks. Our method outperforms all existing techniques by a large margin while having less than half the number of parameters compared to CosPlace and NetVLAD. We achieve a new all-time high recall@1 score of 94.6% on Pitts250k-test, 88.0% on MapillarySLS, and more importantly, 58.4% on Nordland. Finally, our method outperforms two-stage retrieval techniques such as Patch-NetVLAD, TransVPR and SuperGLUE all while being orders of magnitude faster. Our code and trained models are available at https://github.com/amaralibey/MixVPR.
Spatial Steerability of GANs via Self-Supervision from Discriminator
Jan 20, 2023
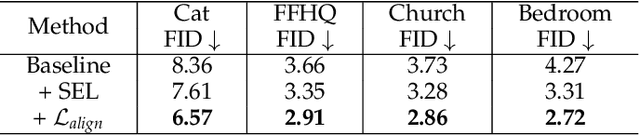
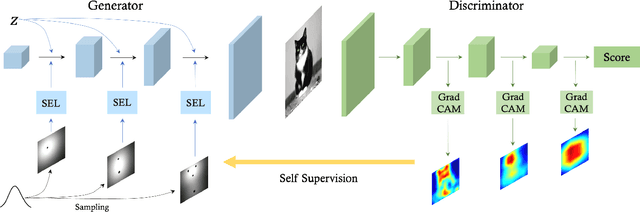
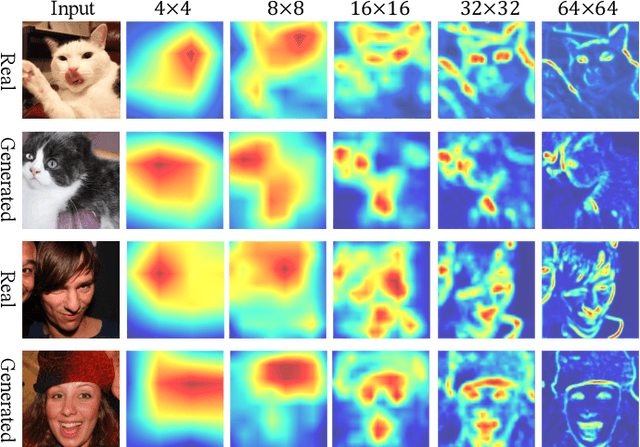
Generative models make huge progress to the photorealistic image synthesis in recent years. To enable human to steer the image generation process and customize the output, many works explore the interpretable dimensions of the latent space in GANs. Existing methods edit the attributes of the output image such as orientation or color scheme by varying the latent code along certain directions. However, these methods usually require additional human annotations for each pretrained model, and they mostly focus on editing global attributes. In this work, we propose a self-supervised approach to improve the spatial steerability of GANs without searching for steerable directions in the latent space or requiring extra annotations. Specifically, we design randomly sampled Gaussian heatmaps to be encoded into the intermediate layers of generative models as spatial inductive bias. Along with training the GAN model from scratch, these heatmaps are being aligned with the emerging attention of the GAN's discriminator in a self-supervised learning manner. During inference, human users can intuitively interact with the spatial heatmaps to edit the output image, such as varying the scene layout or moving objects in the scene. Extensive experiments show that the proposed method not only enables spatial editing over human faces, animal faces, outdoor scenes, and complicated indoor scenes, but also brings improvement in synthesis quality.