 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generalizable Medical Image Segmentation via Random Amplitude Mixup and Domain-Specific Image Restoration
Aug 08, 2022
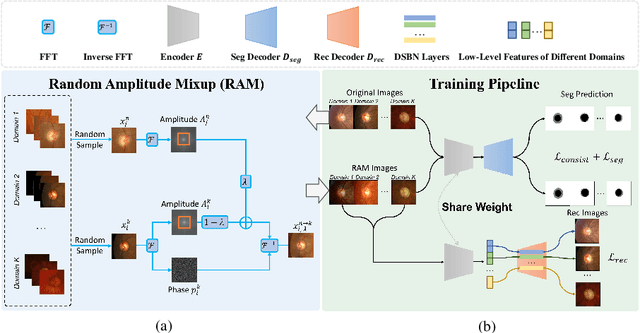
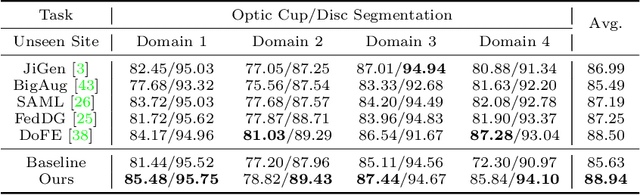
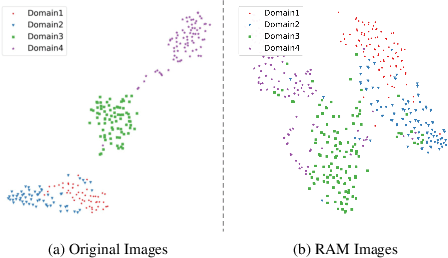
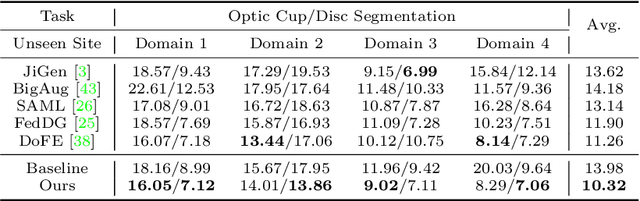
For medical image analysis, segmentation models trained on one or several domains lack generalization ability to unseen domains due to discrepancies between different data acquisition policies. We argue that the degeneration in segmentation performance is mainly attributed to overfitting to source domains and domain shift. To this end, we present a novel generalizable medical image segmentation method. To be specific, we design our approach as a multi-task paradigm by combining the segmentation model with a self-supervision domain-specific image restoration (DSIR) module for model regularization. We also design a random amplitude mixup (RAM) module, which incorporates low-level frequency information of different domain images to synthesize new images. To guide our model be resistant to domain shift, we introduce a semantic consistency loss. We demonstrate the performance of our method on two public generalizable segmentation benchmarks in medical images, which validates our method could achieve the state-of-the-art performance.
Backdoor Attacks in the Supply Chain of Masked Image Modeling
Oct 04, 2022

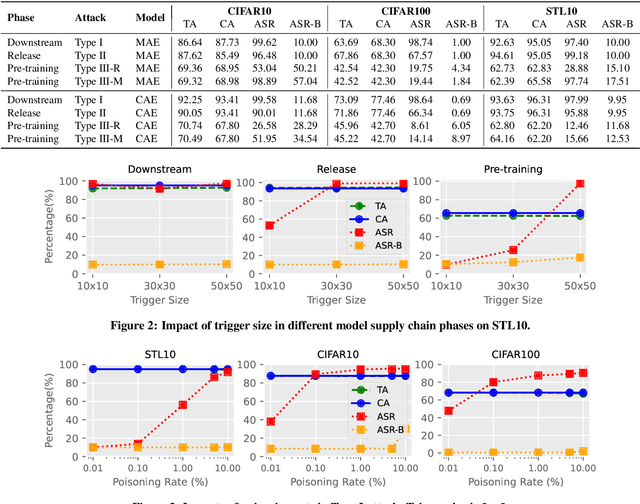
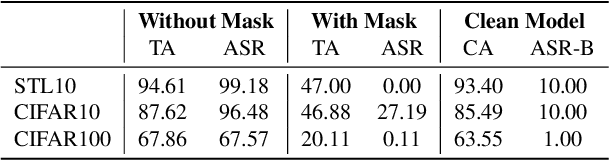
Masked image modeling (MIM) revolutionizes self-supervised learning (SSL) for image pre-training. In contrast to previous dominating self-supervised methods, i.e., contrastive learning, MIM attains state-of-the-art performance by masking and reconstructing random patches of the input image. However, the associated security and privacy risks of this novel generative method are unexplored. In this paper, we perform the first security risk quantification of MIM through the lens of backdoor attacks. Different from previous work, we are the first to systematically threat modeling on SSL in every phase of the model supply chain, i.e., pre-training, release, and downstream phases. Our evaluation shows that models built with MIM are vulnerable to existing backdoor attacks in release and downstream phases and are compromised by our proposed method in pre-training phase. For instance, on CIFAR10, the attack success rate can reach 99.62%, 96.48%, and 98.89% in the downstream phase, release phase, and pre-training phase, respectively. We also take the first step to investigate the success factors of backdoor attacks in the pre-training phase and find the trigger number and trigger pattern play key roles in the success of backdoor attacks while trigger location has only tiny effects. In the end, our empirical study of the defense mechanisms across three detection-level on model supply chain phases indicates that different defenses are suitable for backdoor attacks in different phases. However, backdoor attacks in the release phase cannot be detected by all three detection-level methods, calling for more effective defenses in future research.
Position Regression for Unsupervised Anomaly Detection
Jan 19, 2023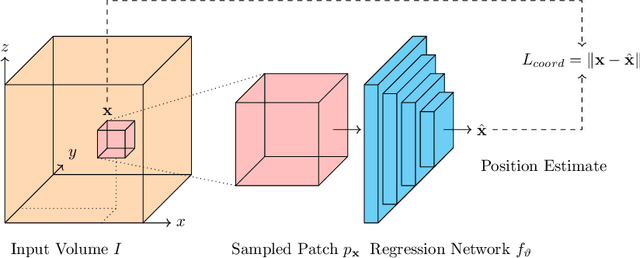
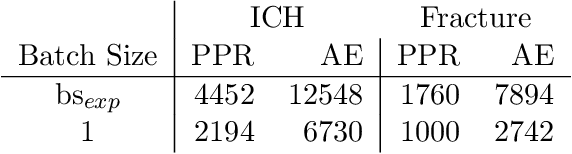

In recent years, anomaly detection has become an essential field in medical image analysis. Most current anomaly detection methods for medical images are based on image reconstruction. In this work, we propose a novel anomaly detection approach based on coordinate regression. Our method estimates the position of patches within a volume, and is trained only on data of healthy subjects. During inference, we can detect and localize anomalies by considering the error of the position estimate of a given patch. We apply our method to 3D CT volumes and evaluate it on patients with intracranial haemorrhages and cranial fractures. The results show that our method performs well in detecting these anomalies. Furthermore, we show that our method requires less memory than comparable approaches that involve image reconstruction. This is highly relevant for processing large 3D volumes, for instance, CT or MRI scans.
Development of a Prototype Application for Rice Disease Detection Using Convolutional Neural Networks
Jan 13, 2023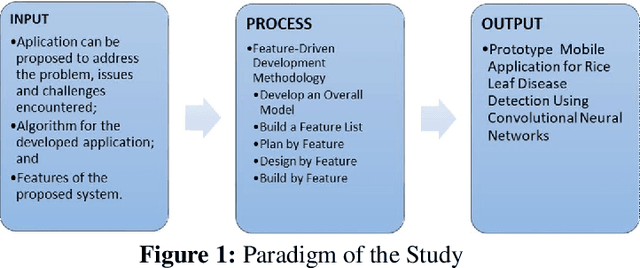
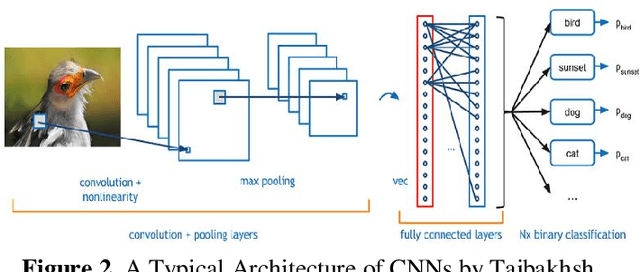
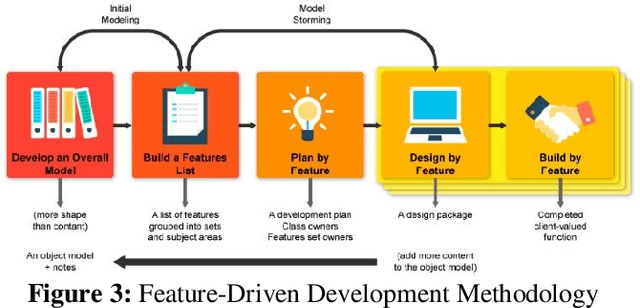

Rice is the number one staple food in the country, as this serves as the primary livelihood for thousands of Filipino households. However, as the tradition continues, farmers are not familiar with the different types of rice leaf diseases that might compromise the entire rice crop. The need to address the common bacterial leaf blight in rice is a serious disease that can lead to reduced yields and even crop loss of up to 75%. This paper is a design and development of a rice leaf disease detection mobile application prototype using an algorithm used for image analysis. The researchers also used the Rice Disease Image Dataset by Huy Minh Do available at https://www.kaggle.com/ to train state-of-the-art convolutional neural networks using transfer learning. Moreover, we used image augmentation to increase the number of image samples and the accuracy of the neural networks as well
Preconditioned Score-based Generative Models
Feb 13, 2023
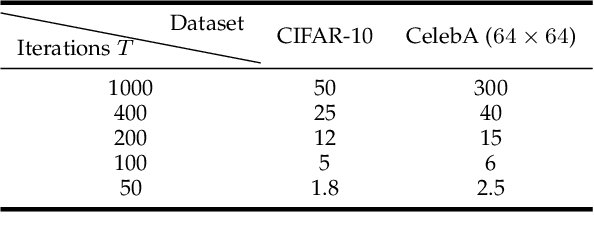
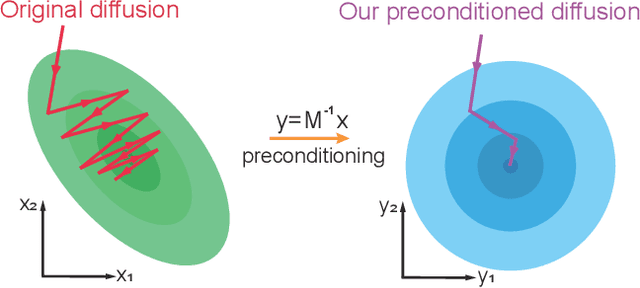

Score-based generative models (SGMs) have recently emerged as a promising class of generative models. However, a fundamental limitation is that their sampling process is slow due to a need for many (\eg, $2000$) iterations of sequential computations. An intuitive acceleration method is to reduce the sampling iterations which however causes severe performance degradation. We assault this problem to the ill-conditioned issues of the Langevin dynamics and reverse diffusion in the sampling process. Under this insight, we propose a model-agnostic {\bf\em preconditioned diffusion sampling} (PDS) method that leverages matrix preconditioning to alleviate the aforementioned problem. PDS alters the sampling process of a vanilla SGM at marginal extra computation cost, and without model retraining. Theoretically, we prove that PDS preserves the output distribution of the SGM, no risk of inducing systematical bias to the original sampling process. We further theoretically reveal a relation between the parameter of PDS and the sampling iterations,easing the parameter estimation under varying sampling iterations. Extensive experiments on various image datasets with a variety of resolutions and diversity validate that our PDS consistently accelerates off-the-shelf SGMs whilst maintaining the synthesis quality. In particular, PDS can accelerate by up to $29\times$ on more challenging high resolution (1024$\times$1024) image generation. Compared with the latest generative models (\eg, CLD-SGM, DDIM, and Analytic-DDIM), PDS can achieve the best sampling quality on CIFAR-10 at a FID score of 1.99. Our code is made publicly available to foster any further research https://github.com/fudan-zvg/PDS.
SFI-Swin: Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components Distributions
Jan 09, 2023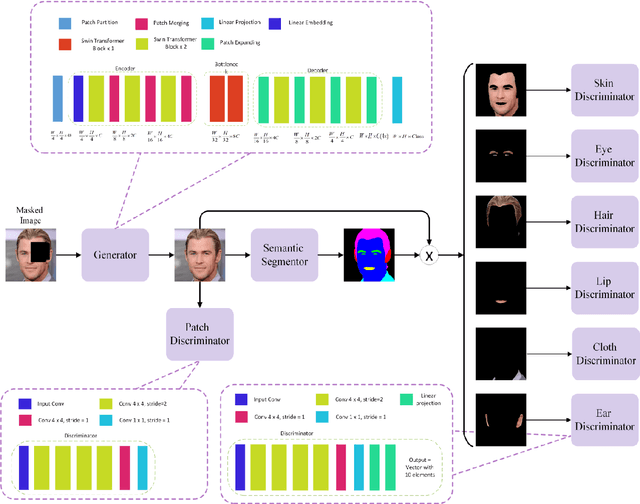
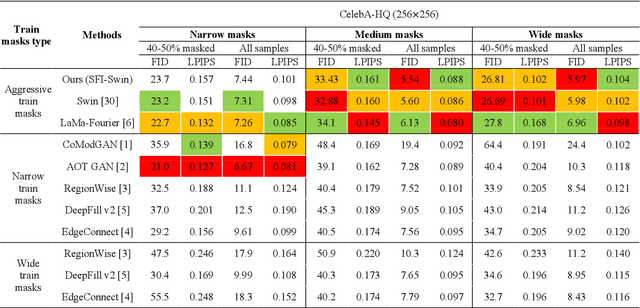


Image inpainting consists of filling holes or missing parts of an image. Inpainting face images with symmetric characteristics is more challenging than inpainting a natural scene. None of the powerful existing models can fill out the missing parts of an image while considering the symmetry and homogeneity of the picture. Moreover, the metrics that assess a repaired face image quality cannot measure the preservation of symmetry between the rebuilt and existing parts of a face. In this paper, we intend to solve the symmetry problem in the face inpainting task by using multiple discriminators that check each face organ's reality separately and a transformer-based network. We also propose "symmetry concentration score" as a new metric for measuring the symmetry of a repaired face image. The quantitative and qualitative results show the superiority of our proposed method compared to some of the recently proposed algorithms in terms of the reality, symmetry, and homogeneity of the inpainted parts.
Aligning Bag of Regions for Open-Vocabulary Object Detection
Feb 27, 2023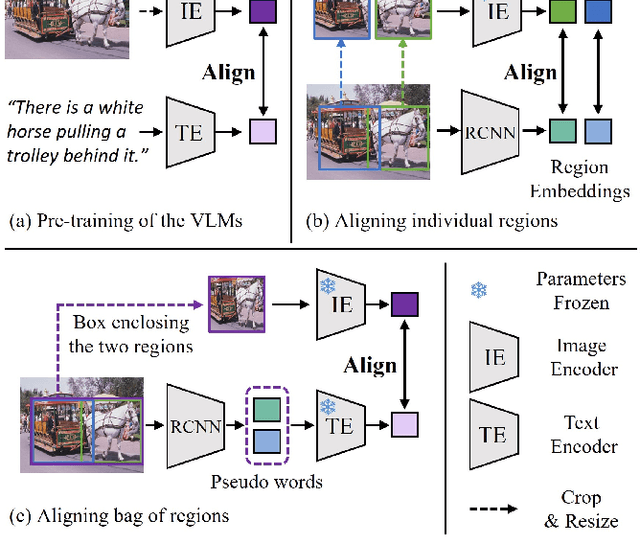

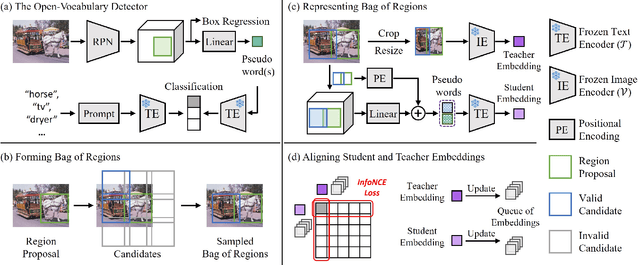
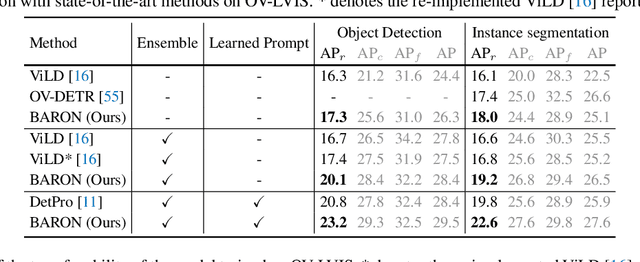
Pre-trained vision-language models (VLMs) learn to align vision and language representations on large-scale datasets, where each image-text pair usually contains a bag of semantic concepts. However, existing open-vocabulary object detectors only align region embeddings individually with the corresponding features extracted from the VLMs. Such a design leaves the compositional structure of semantic concepts in a scene under-exploited, although the structure may be implicitly learned by the VLMs. In this work, we propose to align the embedding of bag of regions beyond individual regions. The proposed method groups contextually interrelated regions as a bag. The embeddings of regions in a bag are treated as embeddings of words in a sentence, and they are sent to the text encoder of a VLM to obtain the bag-of-regions embedding, which is learned to be aligned to the corresponding features extracted by a frozen VLM. Applied to the commonly used Faster R-CNN, our approach surpasses the previous best results by 4.6 box AP50 and 2.8 mask AP on novel categories of open-vocabulary COCO and LVIS benchmarks, respectively. Code and models are available at https://github.com/wusize/ovdet.
Dirichlet-based Uncertainty Calibration for Active Domain Adaptation
Feb 27, 2023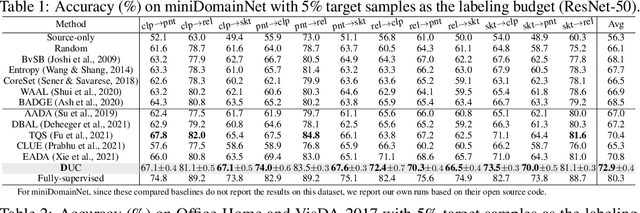
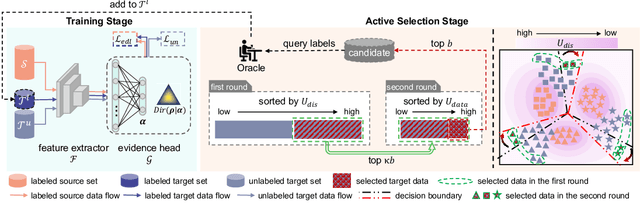
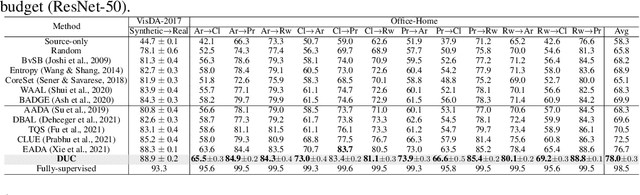
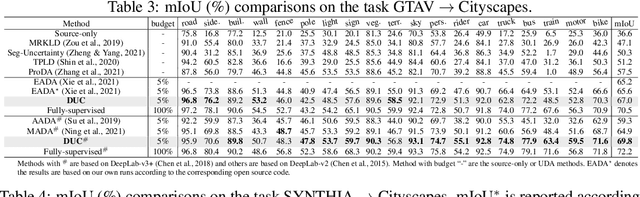
Active domain adaptation (DA) aims to maximally boost the model adaptation on a new target domain by actively selecting limited target data to annotate, whereas traditional active learning methods may be less effective since they do not consider the domain shift issue. Despite active DA methods address this by further proposing targetness to measure the representativeness of target domain characteristics, their predictive uncertainty is usually based on the prediction of deterministic models, which can easily be miscalibrated on data with distribution shift. Considering this, we propose a \textit{Dirichlet-based Uncertainty Calibration} (DUC) approach for active DA, which simultaneously achieves the mitigation of miscalibration and the selection of informative target samples. Specifically, we place a Dirichlet prior on the prediction and interpret the prediction as a distribution on the probability simplex, rather than a point estimate like deterministic models. This manner enables us to consider all possible predictions, mitigating the miscalibration of unilateral prediction. Then a two-round selection strategy based on different uncertainty origins is designed to select target samples that are both representative of target domain and conducive to discriminability. Extensive experiments on cross-domain image classification and semantic segmentation validate the superiority of DUC.
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Feb 27, 2023

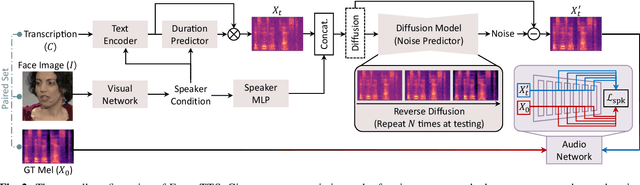
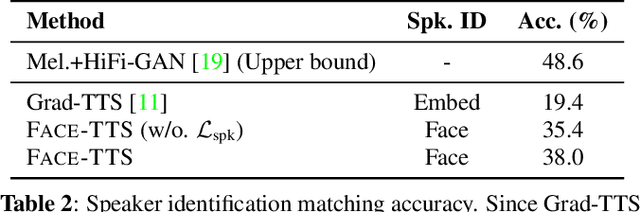
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.
Invariant Layers for Graphs with Nodes of Different Types
Feb 27, 2023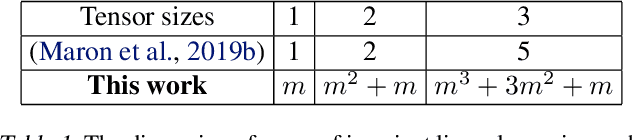
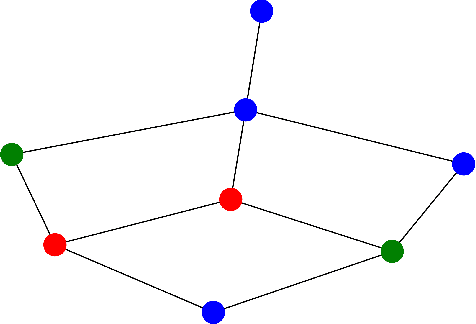

Neural networks that satisfy invariance with respect to input permutations have been widely studied in machine learning literature. However, in many applications, only a subset of all input permutations is of interest. For heterogeneous graph data, one can focus on permutations that preserve node types. We fully characterize linear layers invariant to such permutations. We verify experimentally that implementing these layers in graph neural network architectures allows learning important node interactions more effectively than existing techniques. We show that the dimension of space of these layers is given by a generalization of Bell numbers, extending the work (Maron et al., 2019). We further narrow the invariant network design space by addressing a question about the sizes of tensor layers necessary for function approximation on graph data. Our findings suggest that function approximation on a graph with $n$ nodes can be done with tensors of sizes $\leq n$, which is tighter than the best-known bound $\leq n(n-1)/2$. For $d \times d$ image data with translation symmetry, our methods give a tight upper bound $2d - 1$ (instead of $d^{4}$) on sizes of invariant tensor generators via a surprising connection to Davenport constants.