 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Anomaly Detection under Labeling Budget Constraints
Feb 15, 2023
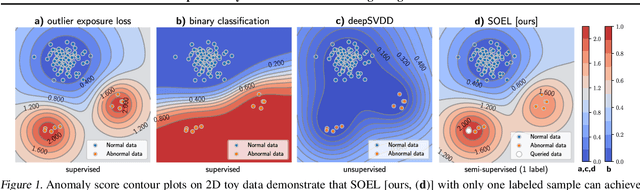

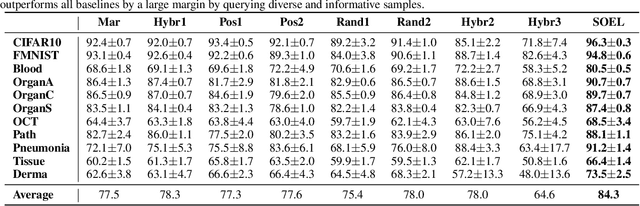
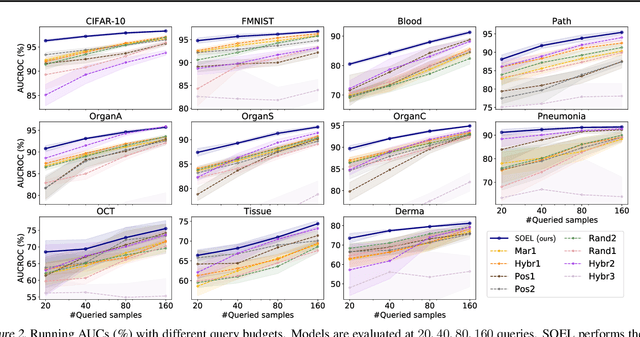
Selecting informative data points for expert feedback can significantly improve the performance of anomaly detection (AD) in various contexts, such as medical diagnostics or fraud detection. In this paper, we determine a set of theoretical conditions under which anomaly scores generalize from labeled queries to unlabeled data. Motivated by these results, we propose a data labeling strategy with optimal data coverage under labeling budget constraints. In addition, we propose a new learning framework for semi-supervised AD. Extensive experiments on image, tabular, and video data sets show that our approach results in state-of-the-art semi-supervised AD performance under labeling budget constraints.
Images as Weight Matrices: Sequential Image Generation Through Synaptic Learning Rules
Oct 07, 2022
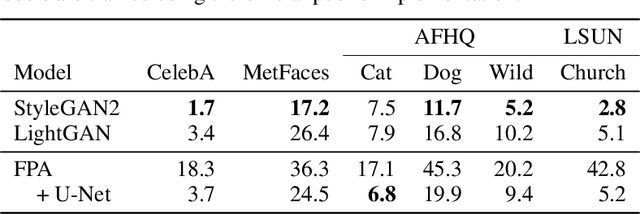
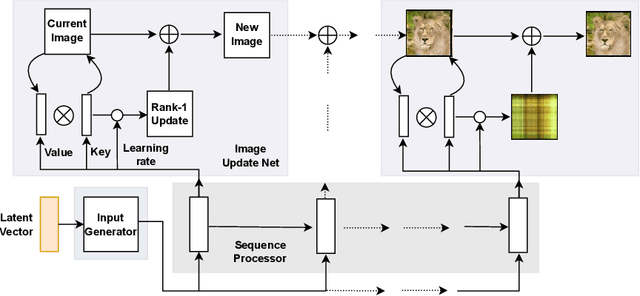
Work on fast weight programmers has demonstrated the effectiveness of key/value outer product-based learning rules for sequentially generating a weight matrix (WM) of a neural net (NN) by another NN or itself. However, the weight generation steps are typically not visually interpretable by humans, because the contents stored in the WM of an NN are not. Here we apply the same principle to generate natural images. The resulting fast weight painters (FPAs) learn to execute sequences of delta learning rules to sequentially generate images as sums of outer products of self-invented keys and values, one rank at a time, as if each image was a WM of an NN. We train our FPAs in the generative adversarial networks framework, and evaluate on various image datasets. We show how these generic learning rules can generate images with respectable visual quality without any explicit inductive bias for images. While the performance largely lags behind the one of specialised state-of-the-art image generators, our approach allows for visualising how synaptic learning rules iteratively produce complex connection patterns, yielding human-interpretable meaningful images. Finally, we also show that an additional convolutional U-Net (now popular in diffusion models) at the output of an FPA can learn one-step "denoising" of FPA-generated images to enhance their quality. Our code is public.
Generating corneal panoramic images from contact specular microscope images
Jan 06, 2023

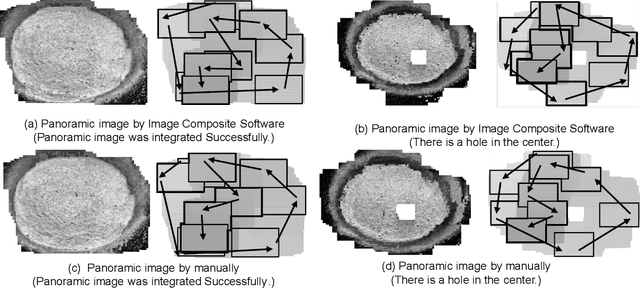
The contact specular microscope has a wider angle of view than that of the non-contact specular microscope but still cannot capture an image of the entire cornea. To obtain such an image, it is necessary to prepare film on the parts of the image captured sequentially and combine them to create a complete image. This study proposes a framework to automatically generate an entire corneal image from videos captured using a contact specular microscope. Relatively focused images were extracted from the videos and panoramic compositing was performed. If an entire image can be generated, it is possible to detect guttae from the image and examine the extent of their presence. The system was implemented and the effectiveness of the proposed framework was examined. The system was implemented using custom-made composite software, Image Composite Software (ICS, K.I. Technology Co., Ltd., Japan, internal algorithms not disclosed), and a supervised learning model using U-Net was used for guttae detection. Several images were correctly synthesized when the constructed system was applied to 94 different corneal videos obtained from Fuchs endothelial corneal dystrophy (FECD) mouse model. The implementation and application of the method to the data in this study confirmed its effectiveness. Owing to the minimal quantitative evaluation performed, such as accuracy with implementation, it may pose some limitations for future investigations.
Aligning Bag of Regions for Open-Vocabulary Object Detection
Feb 27, 2023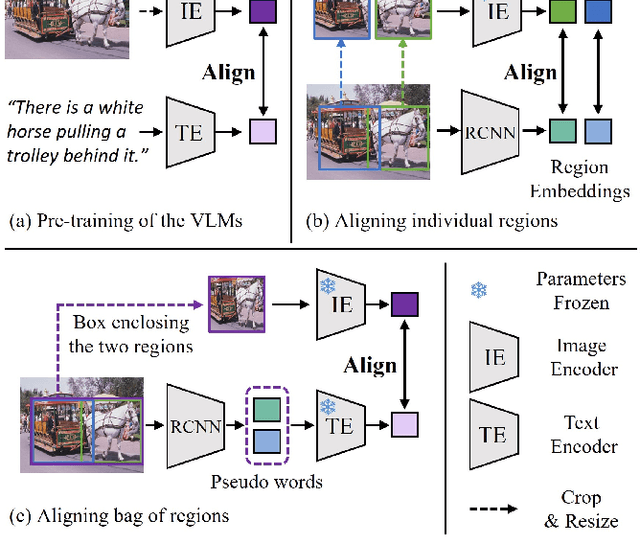

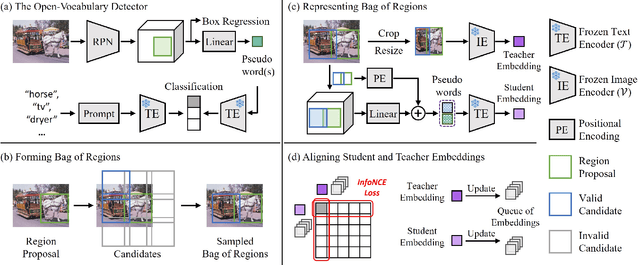
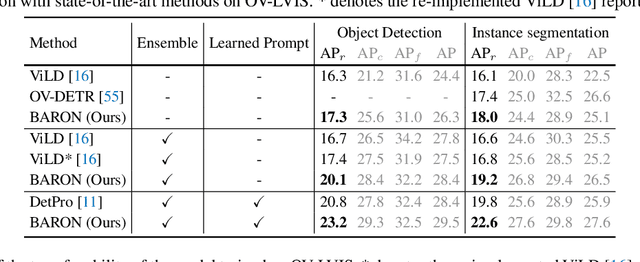
Pre-trained vision-language models (VLMs) learn to align vision and language representations on large-scale datasets, where each image-text pair usually contains a bag of semantic concepts. However, existing open-vocabulary object detectors only align region embeddings individually with the corresponding features extracted from the VLMs. Such a design leaves the compositional structure of semantic concepts in a scene under-exploited, although the structure may be implicitly learned by the VLMs. In this work, we propose to align the embedding of bag of regions beyond individual regions. The proposed method groups contextually interrelated regions as a bag. The embeddings of regions in a bag are treated as embeddings of words in a sentence, and they are sent to the text encoder of a VLM to obtain the bag-of-regions embedding, which is learned to be aligned to the corresponding features extracted by a frozen VLM. Applied to the commonly used Faster R-CNN, our approach surpasses the previous best results by 4.6 box AP50 and 2.8 mask AP on novel categories of open-vocabulary COCO and LVIS benchmarks, respectively. Code and models are available at https://github.com/wusize/ovdet.
Dirichlet-based Uncertainty Calibration for Active Domain Adaptation
Feb 27, 2023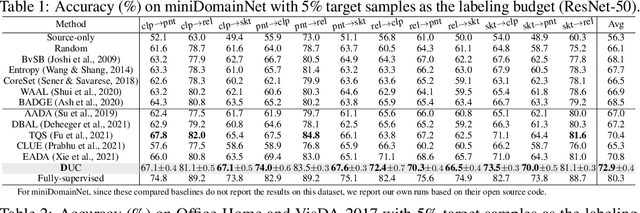
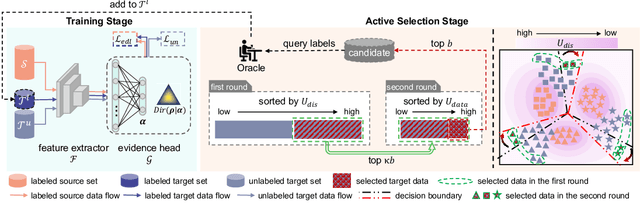
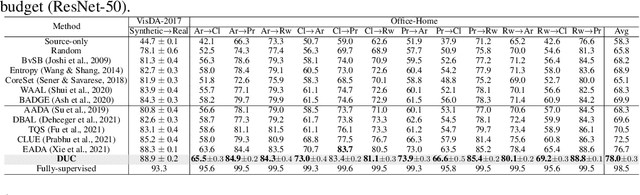
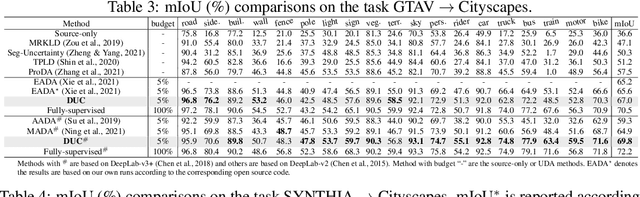
Active domain adaptation (DA) aims to maximally boost the model adaptation on a new target domain by actively selecting limited target data to annotate, whereas traditional active learning methods may be less effective since they do not consider the domain shift issue. Despite active DA methods address this by further proposing targetness to measure the representativeness of target domain characteristics, their predictive uncertainty is usually based on the prediction of deterministic models, which can easily be miscalibrated on data with distribution shift. Considering this, we propose a \textit{Dirichlet-based Uncertainty Calibration} (DUC) approach for active DA, which simultaneously achieves the mitigation of miscalibration and the selection of informative target samples. Specifically, we place a Dirichlet prior on the prediction and interpret the prediction as a distribution on the probability simplex, rather than a point estimate like deterministic models. This manner enables us to consider all possible predictions, mitigating the miscalibration of unilateral prediction. Then a two-round selection strategy based on different uncertainty origins is designed to select target samples that are both representative of target domain and conducive to discriminability. Extensive experiments on cross-domain image classification and semantic segmentation validate the superiority of DUC.
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Feb 27, 2023

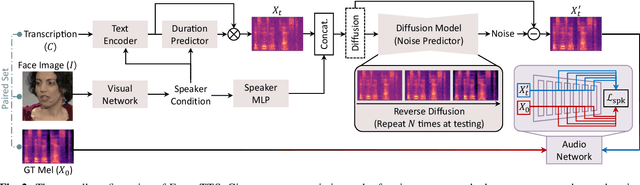
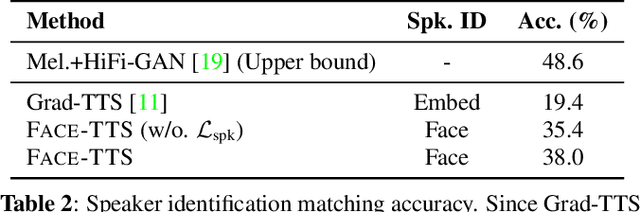
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.
Reconstruction-based Out-of-Distribution Detection for Short-Range FMCW Radar
Feb 27, 2023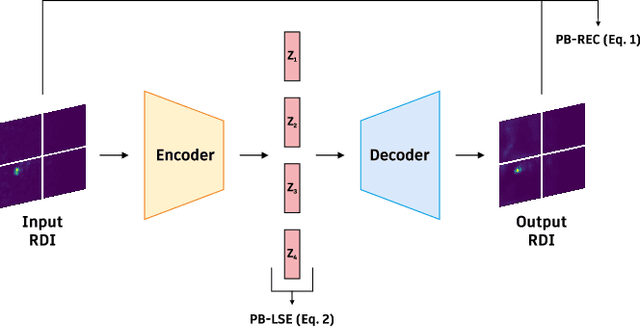
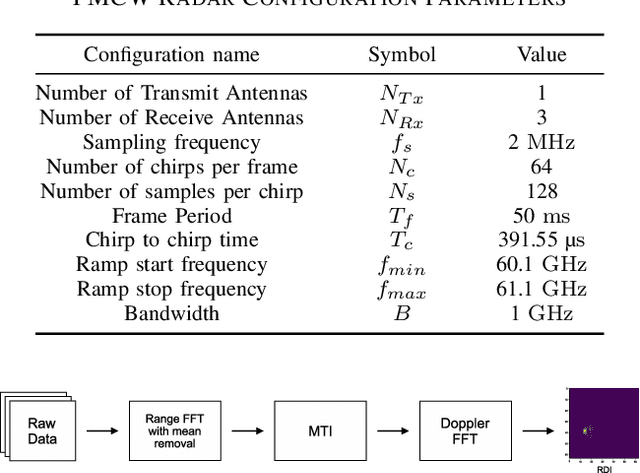
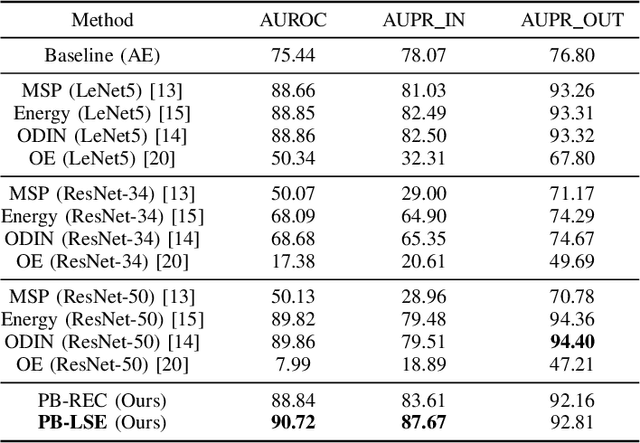
Out-of-distribution (OOD) detection recently has drawn attention due to its critical role in the safe deployment of modern neural network architectures in real-world applications. The OOD detectors aim to distinguish samples that lie outside the training distribution in order to avoid the overconfident predictions of machine learning models on OOD data. Existing detectors, which mainly rely on the logit, intermediate feature space, softmax score, or reconstruction loss, manage to produce promising results. However, most of these methods are developed for the image domain. In this study, we propose a novel reconstruction-based OOD detector to operate on the radar domain. Our method exploits an autoencoder (AE) and its latent representation to detect the OOD samples. We propose two scores incorporating the patch-based reconstruction loss and the energy value calculated from the latent representations of each patch. We achieve an AUROC of 90.72% on our dataset collected by using 60 GHz short-range FMCW Radar. The experiments demonstrate that, in terms of AUROC and AUPR, our method outperforms the baseline (AE) and the other state-of-the-art methods. Also, thanks to its model size of 641 kB, our detector is suitable for embedded usage.
Invariant Layers for Graphs with Nodes of Different Types
Feb 27, 2023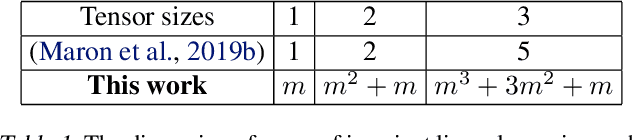

Neural networks that satisfy invariance with respect to input permutations have been widely studied in machine learning literature. However, in many applications, only a subset of all input permutations is of interest. For heterogeneous graph data, one can focus on permutations that preserve node types. We fully characterize linear layers invariant to such permutations. We verify experimentally that implementing these layers in graph neural network architectures allows learning important node interactions more effectively than existing techniques. We show that the dimension of space of these layers is given by a generalization of Bell numbers, extending the work (Maron et al., 2019). We further narrow the invariant network design space by addressing a question about the sizes of tensor layers necessary for function approximation on graph data. Our findings suggest that function approximation on a graph with $n$ nodes can be done with tensors of sizes $\leq n$, which is tighter than the best-known bound $\leq n(n-1)/2$. For $d \times d$ image data with translation symmetry, our methods give a tight upper bound $2d - 1$ (instead of $d^{4}$) on sizes of invariant tensor generators via a surprising connection to Davenport constants.
Neural Congealing: Aligning Images to a Joint Semantic Atlas
Feb 08, 2023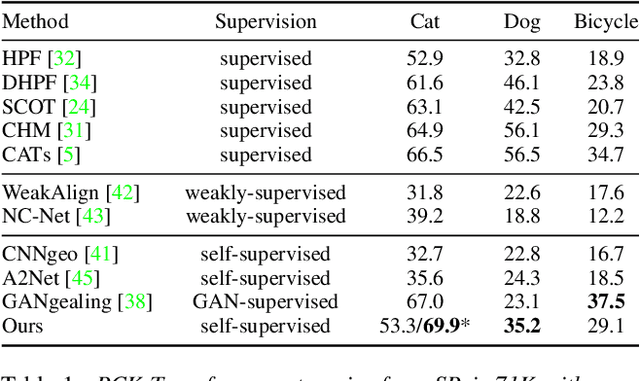
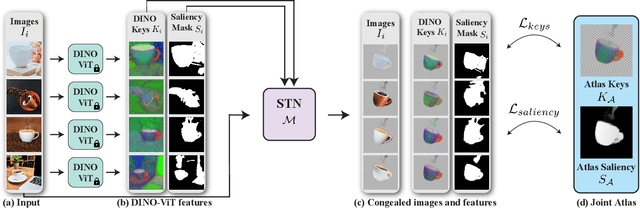
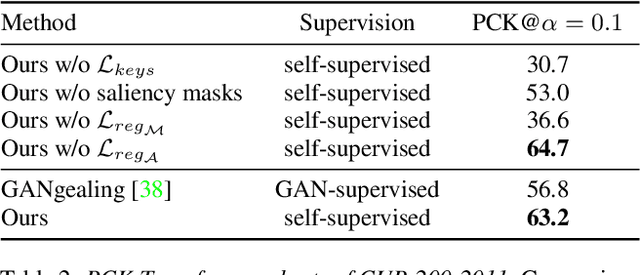
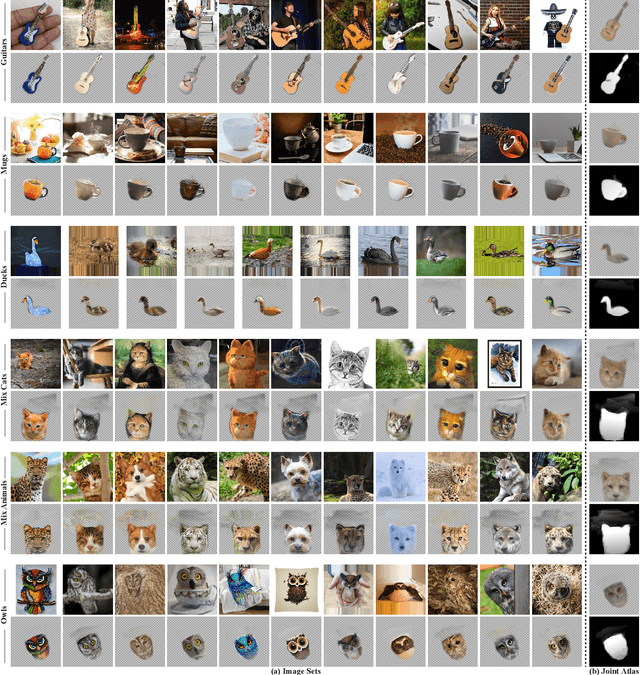
We present Neural Congealing -- a zero-shot self-supervised framework for detecting and jointly aligning semantically-common content across a given set of images. Our approach harnesses the power of pre-trained DINO-ViT features to learn: (i) a joint semantic atlas -- a 2D grid that captures the mode of DINO-ViT features in the input set, and (ii) dense mappings from the unified atlas to each of the input images. We derive a new robust self-supervised framework that optimizes the atlas representation and mappings per image set, requiring only a few real-world images as input without any additional input information (e.g., segmentation masks). Notably, we design our losses and training paradigm to account only for the shared content under severe variations in appearance, pose, background clutter or other distracting objects. We demonstrate results on a plethora of challenging image sets including sets of mixed domains (e.g., aligning images depicting sculpture and artwork of cats), sets depicting related yet different object categories (e.g., dogs and tigers), or domains for which large-scale training data is scarce (e.g., coffee mugs). We thoroughly evaluate our method and show that our test-time optimization approach performs favorably compared to a state-of-the-art method that requires extensive training on large-scale datasets.
A Survey of Feature detection methods for localisation of plain sections of Axial Brain Magnetic Resonance Imaging
Feb 08, 2023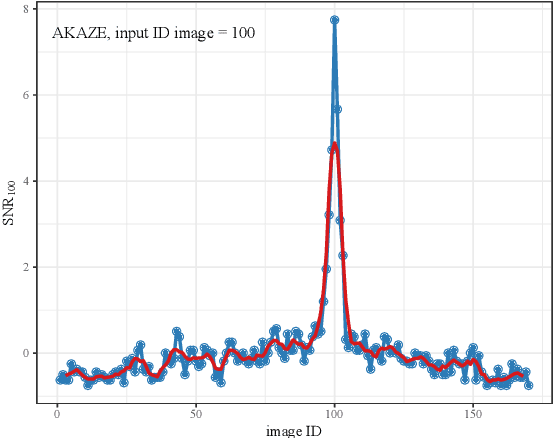
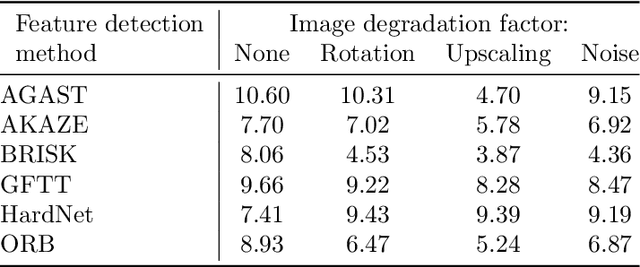
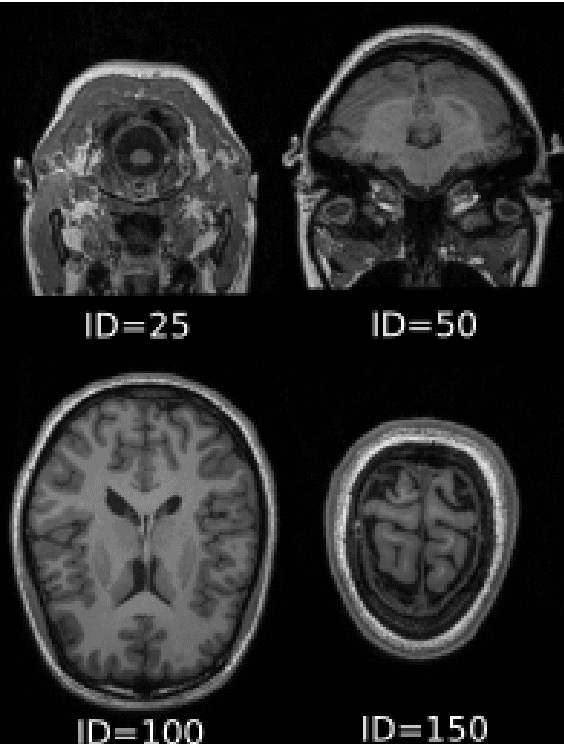
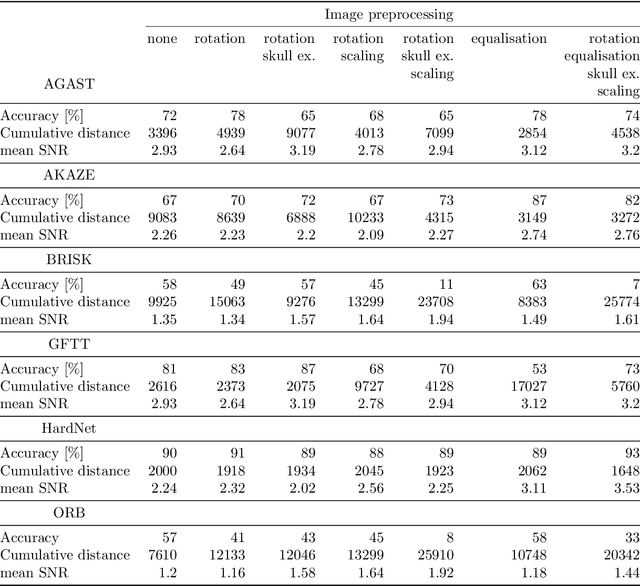
Matching MRI brain images between patients or mapping patients' MRI slices to the simulated atlas of a brain is key to the automatic registration of MRI of a brain. The ability to match MRI images would also enable such applications as indexing and searching MRI images among multiple patients or selecting images from the region of interest. In this work, we have introduced robustness, accuracy and cumulative distance metrics and methodology that allows us to compare different techniques and approaches in matching brain MRI of different patients or matching MRI brain slice to a position in the brain atlas. To that end, we have used feature detection methods AGAST, AKAZE, BRISK, GFTT, HardNet, and ORB, which are established methods in image processing, and compared them on their resistance to image degradation and their ability to match the same brain MRI slice of different patients. We have demonstrated that some of these techniques can correctly match most of the brain MRI slices of different patients. When matching is performed with the atlas of the human brain, their performance is significantly lower. The best performing feature detection method was a combination of SIFT detector and HardNet descriptor that achieved 93% accuracy in matching images with other patients and only 52% accurately matched images when compared to atlas.